文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
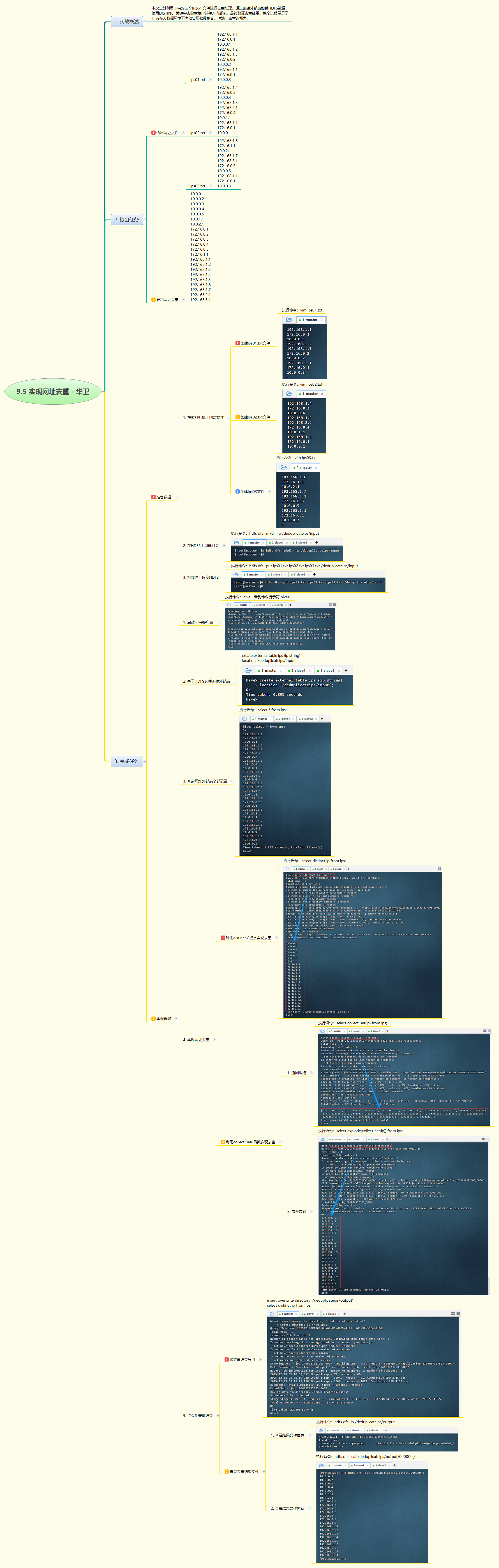
- 本实战通过Hive对三个含重复IP的文本文件进行去重处理,创建外部表加载HDFS数据,使用
DISTINCT或collect_set+explode实现去重,并将唯一IP列表持久化至HDFS输出目录,完整展示了Hive在大数据清洗与去重场景中的高效应用。
2. 实战步骤
3. 实战总结
- 本次实战聚焦于IP地址去重任务,系统完成了从数据准备到结果输出的全流程。首先将三个包含重复IP的本地文件上传至HDFS,创建外部表
ips直接映射目录数据;随后通过SELECT DISTINCT ip快速获取唯一IP集合,同时对比使用collect_set(ip)聚合函数生成无重复数组,并结合explode展开为行,验证了多种去重方法的可行性;最终利用INSERT OVERWRITE DIRECTORY将去重结果导出至HDFS指定路径,便于下游系统使用。整个过程体现了Hive在数据整合、清洗和去重方面的简洁性与高效性,尤其适用于日志分析、用户行为追踪等需处理海量重复标识的场景,为大数据预处理提供了可靠的技术路径。