论文阅读笔记:Class-Incremental Learning: A Survey
- [1 背景](#1 背景)
- [2 预备知识](#2 预备知识)
-
- [2.1 问题表述](#2.1 问题表述)
- [2.2 样例和样例集](#2.2 样例和样例集)
- [3 类别增量学习:分类学](#3 类别增量学习:分类学)
-
- [3.1 数据回放](#3.1 数据回放)
- [3.2 数据正则化](#3.2 数据正则化)
- [3.3 动态网络](#3.3 动态网络)
-
- [3.3.1 神经元扩展](#3.3.1 神经元扩展)
- [3.3.2 骨干扩展](#3.3.2 骨干扩展)
- [3.3.3 提示扩展](#3.3.3 提示扩展)
- [3.4 参数正则化](#3.4 参数正则化)
- [3.5 知识蒸馏](#3.5 知识蒸馏)
- [3.6 模型校正](#3.6 模型校正)
- [3.7 基于模板的分类](#3.7 基于模板的分类)
1 背景
深度网络的典型训练过程需要预先收集数据集,例如大规模的图像或文本,然后经过多个Epoch的训练过程。然而,在开放的世界中,训练数据往往是流格式的。这些流式数据由于存储约束或隐私问题而无法长期保存,需要模型只用新的类实例进行增量更新。 这样的需求引发了类别增量学习( Class-Incremental Learning,CIL )领域的繁荣,旨在不断地在所有可见的类别中构建一个整体分类器。CIL中的致命问题被称为灾难性遗忘,即直接用新类优化网络会抹除旧类的知识,从而导致不可逆的性能下降。因此,如何有效地抵抗灾难性遗忘成为构建CIL模型的核心问题。
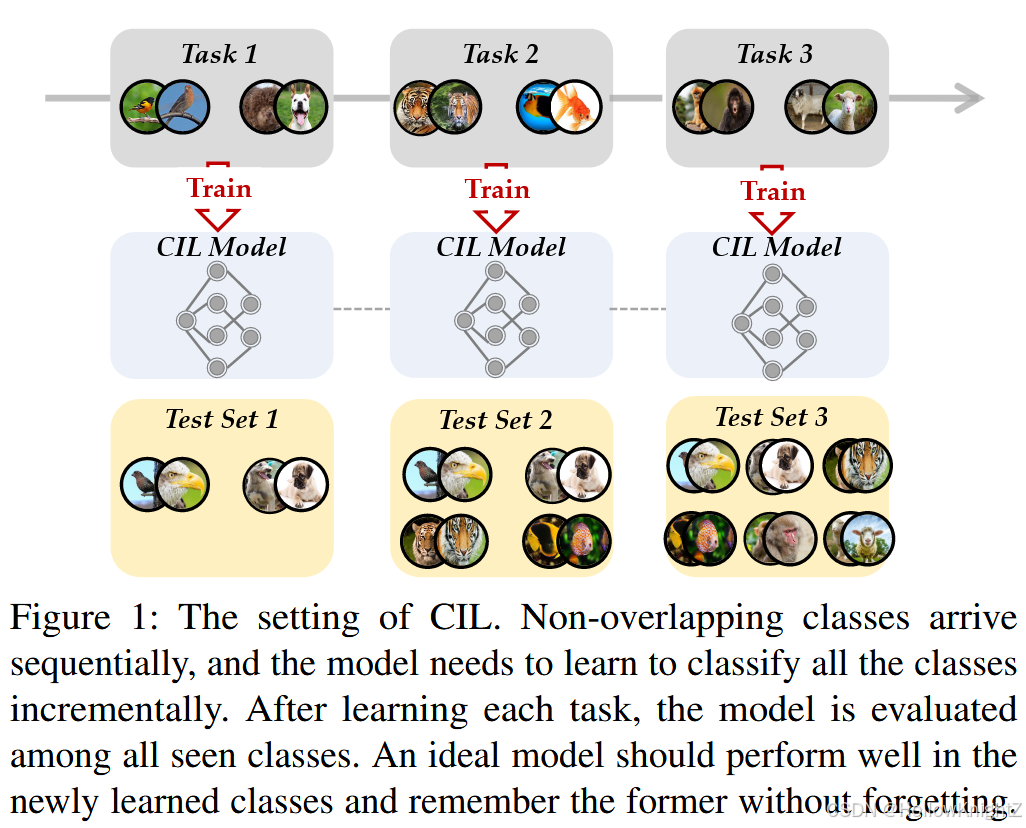
图1描述了CIL的典型设置。训练数据以流的形式出现,在每个时间戳中,可以得到一个新的训练数据集(图中记为"任务"),并且需要用新的类别来更新模型。例如,模型在第一个任务中学习"鸟"和"狗",在第二个任务中学习"老虎"和"鱼",在第三个任务中学习"猴子"和"羊"等。随后,该模型在所有可见的类中进行测试,以评估其是否对他们具有区分性。一个好的模型应该在刻画新类的特征和保留先前学习过的旧类的模式之间取得平衡。这种权衡也被成为神经系统中"稳定性-可塑性两难问题",其中稳定性表示保持原有知识的能力,可塑性表示适应新模式的能力。
由于数据流量是不断的,并且要求训练一个终身的时间,增量学习也被成为"持续学习"或"终身学习"。除了类别增量学习,还有其他细粒度的设置来解决增量学习问题,例如任务增量学习(TIL)和域增量学习(DIL),图2展示了这三种方式。
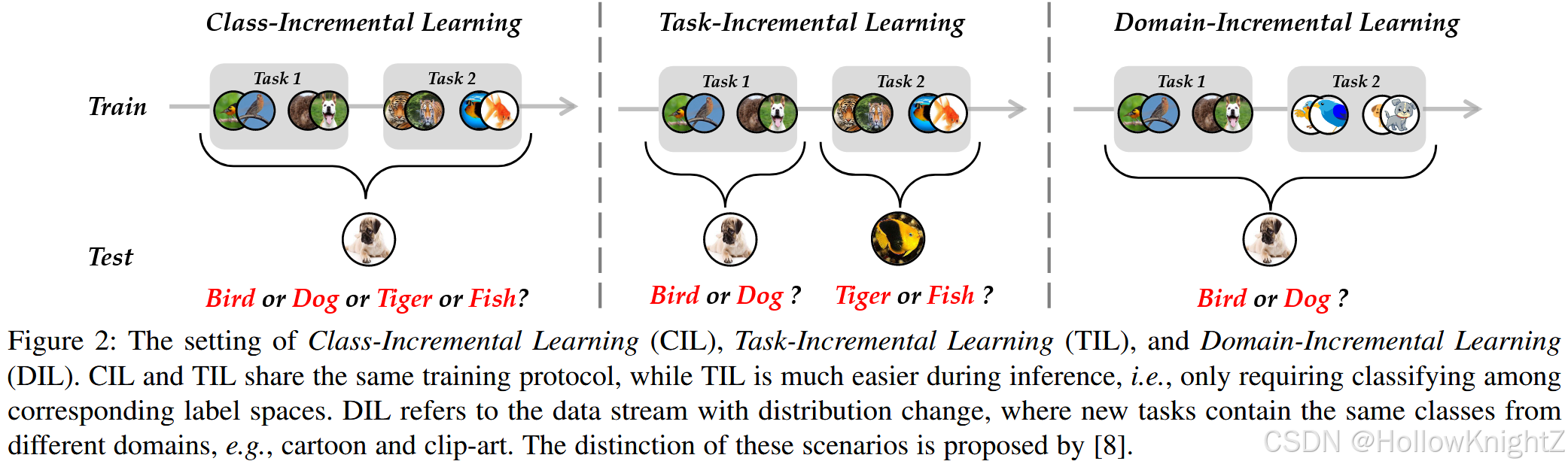
TIL是与CIL类似的设置,两者都是在新的任务中观察新来的类。然而,不同之处在于推理阶段,CIL要求模型在所有类之间进行区分,相比之下,TIL只需要在相应任务空间中对实例进行分类。换句话说,他不需要跨任务区分能力。因此TIL比CIL更容易,可以看做是CIL的一个特例。另一方面,DIL专注于概念漂移或分布变化的场景,其中新任务是包含来自不同域但具有相同标签空间的实例。恩文主要关注CIL设置,这是开放世界中更具有挑战性的场景。
在深度学习繁荣之前也有关于CIL的研究。典型的方法尝试用传统的机器学习模型来解决灾难性遗忘问题。然而,他们中大多数解决了两个任务的内的增量模型,即模型仅用一个新的阶段进行更新。此外,数据收集和处理的快速发展要求模型能够掌握传统机器学习模型无法处理的长时间、海量规模的数据流。相应地,具有强大表征能力的深度神经网络很好地满足了这些需求。因此,基于深度学习的CIL逐渐成为机器学习和计算机视觉领域的研究热点、
本文旨在对增量学习方法进行全面的综述,并将其分为7类。在基准数据集CIFAR100和ImageNet 100/1000上对各种方法进行了全面的比较。另一方面,本文强调CIL模型评估中的一个重要因素,即内存预算,并不主张预算一直的情况下对不同方法进行公平比较,相应地,用预算不可知测度对CIL模型的可扩展性进行整体评估。
总的来说,本研究的贡献可以概括如下:
(1)提供了CIL的全面综述,包括问题定义、基准数据集和不同类型的CIL方法。对这些方法进行了分类组织(表1)并按时间排序(图3),以对当前的技术进行一个整体的概述。
(2)本文在几个公开数据集上提供了不同方法之间的严格和统一的比较,包括传统的CNN方法和现代的ViT方法。
(3)为了促进实际应用,CIL模型不仅应该部署在高性能计算机上,而且应该部署在边缘设备上。因此,提倡通过强调内存预算的作用来整体评估不同的方法。
2 预备知识
2.1 问题表述
定义1 :类增量学习旨在一个具有新类的进化流中学习。假设有一个B个训练任务的序列 { D 1 , D 2 , ... , D B } \{D^1,D^2,...,D^B\} {D1,D2,...,DB},不存在类重叠,其中 D b = { x i b , y i b } i = 1 n b D^b=\{x_i^b,y_i^b\}{i=1}^{n_b} Db={xib,yib}i=1nb 是第 b b b 个增量步,有 n b n_b nb 个训练实例, x i b ∈ R D x_i^b∈R^D xib∈RD 是类别为 y i b ∈ Y b y_i^b∈Y_b yib∈Yb 的实例, Y b Y_b Yb 是任务 b b b 的标签空间。其中对于 b ≠ b ' b≠b' b=b' 时, Y b ∩ Y b ' = ∅ Y_b∩Y{b'}=∅ Yb∩Yb'=∅。当训练任务 b b b 时,只能从 D b D^b Db 中获取数据。CIL的最终目标是不断地为所有类建立分类模型。也就是说,模型不仅要从当前任务 D b D^b Db 中获取知识,还要保留从当前任务中获取的知识,在每个任务之后,训练好的模型在所有可见类别 y b = Y 1 ∪ ... Y b y_b=Y1∪...Y_b yb=Y1∪...Yb 上进行评估。形式上,CIL旨在拟合一个模型 f ( x ) : X → y b f(x):X→y_b f(x):X→yb ,使得期望风险最小化:
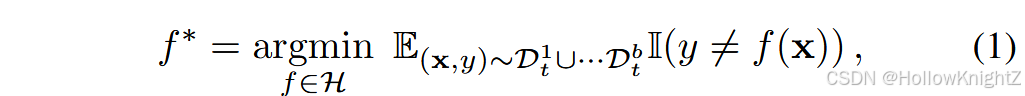
其中 H H H 是假设空间, I ( ⋅ ) I(·) I(⋅) 是指示函数,如果表达式成立,则输出1,否则输出0。 D t b D_t^b Dtb 表示任务 b b b 的任务分布。一个好的CIL模型满足式(1)在所有类中具有可区分性,他不仅对新类有效,而且保留了旧类的知识。
类重叠 :典型的CIL设置假设 b ≠ b ' b≠b' b=b' 时, Y b ∩ Y b ' = ∅ Y_b∩Y_{b'}=∅ Yb∩Yb'=∅,即不同任务重不存在重叠类。然而,现实世界中,观察新任务重出现旧类别是很常见的,当 Y b ∩ Y b ' ≠ ∅ Y_b∩Y_{b'}≠∅ Yb∩Yb'=∅ 时,这种设置被称为模糊类增量学习(Blurry CIL)。他是的模型能够在后期重访以前的实例,从而削弱了学习难度。
实例数量:典型的CIL假设每个类的训练数量是平衡的、充足的。但现实世界中,数据收集可能面临挑战,例如,我们只能收集有限数量的稀有鸟类的训练样例。当新类的训练实例被限制(例如每类只有5个样本)时,这种设置被称为少样本类别增量学习(FewShot Class-Incremental Learning,FSCIL)。当训练实例高度不平衡且长尾时,该设置被称为长尾类增量学习(Long Tailed Class-Incremental Learning,LTCIL)。
在线CIL:虽然数据以流的形式存在,但该模型可以对每个任务进行多个epoch训练,即每个任务内的离线训练。有一些工作解决了完全在线CIL,其中每个批次可以处理一次然后丢弃。这是当前设定的一个特例,本文主要关注广义CIL设定。
在下面的讨论中,我们将CIL模型分解为嵌入模块和线性层,即 f ( x ) = W T ϕ ( x ) f(x)=W^T\phi(x) f(x)=WTϕ(x),其中 ϕ ( ⋅ ) : R D → R d , W ∈ R d × ∣ y b ∣ \phi(·):R^D→R^d,W∈R^{d×|y_b|} ϕ(⋅):RD→Rd,W∈Rd×∣yb∣。线性层可以进一步分解为分类器的组合: W = w 1 , w 2 , ... , w ∣ y b ∣ W=w_1,w_2,...,w_{\|y_b\|} W=w1,w2,...,w∣yb∣,其中 w k ∈ R d w_k∈R^d wk∈Rd, ∣ ⋅ ∣ |·| ∣⋅∣ 表示集合的大小。然后将logits传递给Softmax激活函数进一步优化,即第 k k k 类的输出概率记为:
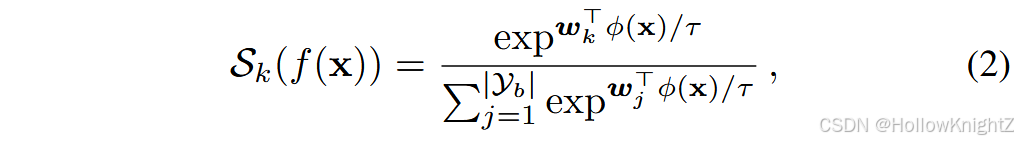
其中 τ \tau τ 是温度因子。
主干网络 :如式(2),将实例 x x x 输入到嵌入函数和线性层得到预测结果,设计嵌入函数将输入实例 投影到嵌入空间以反映其语义信息。因此,理想的CIL算法应该适用于任何类型的骨干网络,例如MLP,CNN,和ViT。具体来说,我们通常将整幅图像作为MLP和CNN的输入,并使用最终的输出作为嵌入。相比之下,ViT将图像转化为patch特征的patch序列。然后将这些补丁前馈到自注意力模块和MLP层,以获得上下文信息。典型的ViT附加一个额外的token,(如 CLS token)到patch集合,并利用 CLS token的最终表示作为嵌入。由于ViT依靠自注意力机制对块特征进行关联和调整,因此通过添加任务特定的令牌作为输入来影响嵌入上下文是直观的。
CIL中的基线 :在CIL中,典型的基线是使用当前数据集 D b D^b Db 对模型进行微调(记为 "Finetune"),其损失函数可以表示为:
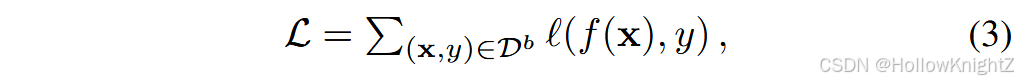
式中 l ( ⋅ , ⋅ ) l(·,·) l(⋅,⋅) 衡量了输入之间的差异,如交叉熵损失。Finetune被称为CIL的基线方法。因为她只专注于学习当前任务中的新概念。由于该模型不关注以前的模型,因此它受到严重的遗忘。
2.2 样例和样例集
如定义1所定义,在每个增量任务重,模型只能访问当前数据集 D b D^b Db。这有助于保护用户隐私和减轻存储负担。然而,这种限制在某种情况下是有所放松的,并且该模型可以保留一个相对较小的样本集,即样例集,用来从以前的任务中保留具有代表性的样例。
定义2 .示例集是前面任务 E = { x j , y j } j = 1 M , y j ∈ Y b − 1 E=\{x_j,y_j\}{j=1}^M,y_j∈Y{b-1} E={xj,yj}j=1M,yj∈Yb−1 的额外实例集合,模型可以利用 E ∪ D b E∪D^b E∪Db 进行每个任务的更新。模型对每个任务的训练过程结束后的样例集进行管理。
样例集管理 :由于数据流是不断演化的,在CIL中主要有两种策略来管理样例集。第一种是每类保持固定数量的样例,例如每类 R R R 个样例。在这种情况下,样本集的大小会随着数据流的演化而增长,模型在第 b b b 个任务后保持 R ∣ Y b ∣ R|Y_b| R∣Yb∣ 数量。这样导致线性增长的内存预算。这在现实世界的学习系统中时不适用的。为此,另一种策略主张保持固定数量的样例,例如, M M M 个。该模型每类保留 M ∣ Y b ∣ \\frac{M}{\|Y_b\|} ∣Yb∣M,其中 ⋅ · ⋅ 表示 floor 函数。它有助于在内存中保持一个固定大小的样例,并减轻内存负担。本文使用第二种册策略。
样本选择 :样本是每个类的代表性实例,需要从整个训练集中进行选择。选择样例的一种直观方法是随机采样,这会导致样例可能缺乏多样性。相比之下,一种常用的被称为群羊效应的策略,旨在选择每个类中最具代表性的个体。给定 y y y 类的实例集 X = { x 1 , x 2 , ... , x n } X=\{x_1,x_2,...,x_n\} X={x1,x2,...,xn} ,羊群首先计算当前嵌入 ϕ ( ⋅ ) \phi(·) ϕ(⋅) 的类中心: μ y ← 1 n ∑ i = 1 n ϕ ( X i ) {\mu}y←\frac{1}{n}{\sum}{i=1}^n\phi(X_i) μy←n1∑i=1nϕ(Xi)。然后,他迭代地将实例添加到示例集中心:
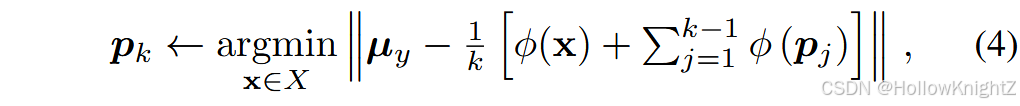
直到 k k k 达到每个类的内存边界 M ∣ Y b ∣ \\frac{M}{\|Y_b\|} ∣Yb∣M。类 y y y 的样本集 { p 1 , p 2 , ... , p M ∣ Y b ∣ } \{p_1,p_2,...,p_{\\frac{M}{\|Y_b\|}}\} {p1,p2,...,p∣Yb∣M}。式4保证了迄今为止所选择的的所有样本的平均特征向量最接近均值。由于类中心可以被看作是每个类最具有代表性的模式,因此选择靠近类中心的样例也增强了代表性。在CIL中,群羊效应是一种常用的样例选择策略,本文也采用了这一策略。
3 类别增量学习:分类学
近年来,针对CIL的研究工作层出不穷,引起了机器学习和计算机视觉界的热烈讨论。本文从7个方面对这些方法进行了分类学整理,如表1所示。
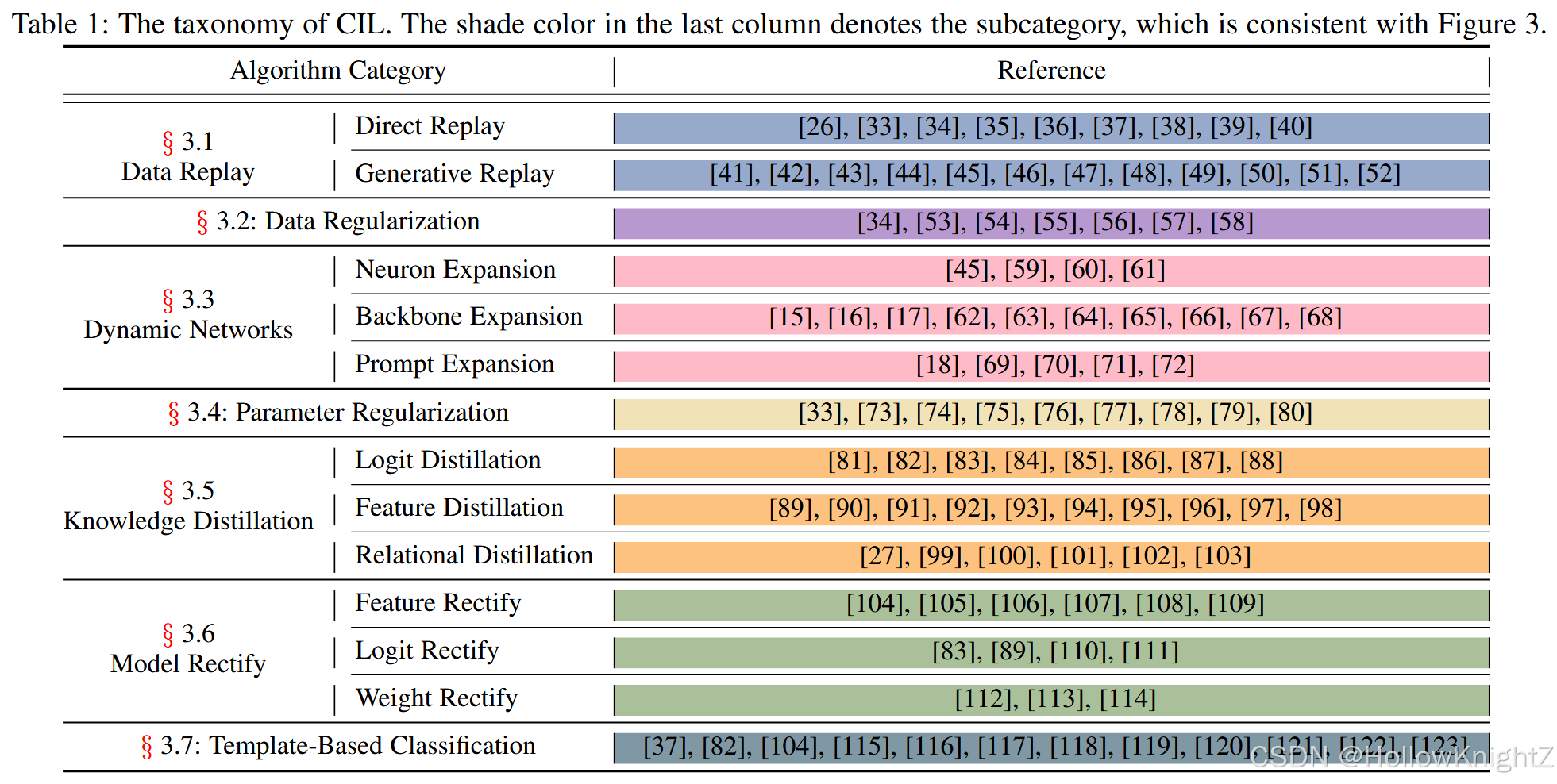
具体来说,数据重放和数据规则化集中于通过示例求解CIL,或者通过重访以前的实例,或者使用它们作为指标来规则化模型更新。动态网络扩展网络结构以获得更强的表征能力,而基于参数正则化的方法则对模型参数进行正则化,防止其漂移以抵抗遗忘。 此外,知识蒸馏构建增量模型之间的映射以抵抗遗忘,模型校正旨在减少增量学习器的有偏预测。基于模板的分类旨在将推理转化为查询与模板的匹配。图3中按时间顺序列出代表性方法,以展示不同时期的研究重点。

注意,这些类别的分类规则是基于每个算法的"关键点" (或特殊焦点)。随着类别增量学习的快速发展,一些技术正在成为各种算法之间共享的公认基准。因此,这7个范畴并不是相互排斥的,它们之间并没有严格的界限。将它们组织成几个类别,以从特定的角度增强对CIL的整体理解。在接下来的章节中,将从这些方面对CIL方法进行讨论。
3.1 数据回放
"回放"是人类认知系统中的一个重要组成部分------学生在期末考试时需要翻阅课本来回忆以前的记忆和知识。这一现象也可以推广到网络训练过程中,网络可以通过重访先前的样本来克服灾难性遗忘。相应地,一种直观的方法是保存一个额外的样本集E (如定义2所定义),并将其纳入模型更新过程:
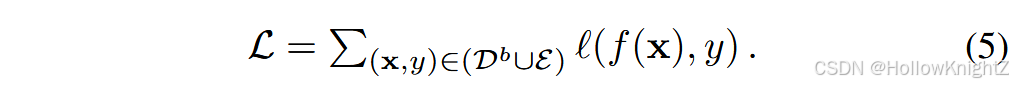
比较式(5)和式(3)。可以发现样例被串接到训练集中进行更新,使得在学习新概念时能够回溯性的回顾先前的知识。
**如何构建范例集?**利用范例集进行回放虽简单却有效,这一方法催生了大量后续研究。范例采样过程与主动学习机制也颇为相似,部分研究提出了相应的采样策略以筛选信息量丰富的样本。例如,
-
建议选取预测熵值较高且靠近决策边界的范例,通过回放这类"困难"样本可提升模型的泛化能力。
-
通过数据增强估计范例的不确定性,其方法聚合多个增强实例的预测结果,进而选择预测差异较大的样本。
-
针对在线增量学习场景,提出采用贪心策略进行范例采样。
证明了样例选择等价于以参数梯度为特征最大化样例的多样性。没有明确的任务边界,探讨取样过程是为了保证样本是独立同分布取样的。《Using hindsight to anchor past knowledge in continual learning》将重放过程形式化为双层优化,并对过去任务的一些锚点保持完整的预测。《Continual prototype evolution: Learning online from non-stationary data streams》介绍了原型网络中的数据重放,并利用范例作为伪原型进行嵌入评估。记忆法剔除了一种将样本参数化并以元学习的方式进行优化的方法。该框架通过模型级和样本级的双层优化进行训练,可与多种CIL算法相结合。
存储高效内存:由于示例是原始图像,直接保存一组实例可能会消耗巨大的内存成本。为此,一些工作被提出来构建一个内存高效的重放缓冲区。《Memory-efficient incremental learning through feature adaptation》认为提取的特征比原始图像具有更低的维度,并提出在样本集中保存特征以减轻负担。类似地,《Memoryefficient class-incremental learning for image classification》提出保留低保真图像而不是原始图像。然而,由于提取的特征和低保真图像的分布可能与原始图像不同,这些方法需要额外的自适应过程,增加了算法的复杂度。
生成式回放:上述方法通过在内存中回放以前的实例来获得有竞争力的性能。除了直接保存样例集合中的样例外,生成模型显示出建模分布和生成样例的潜力,它们也被应用于类别增量学习。将上述直接保存重放实例的方法称为"直接重放",将利用生成模型的方法称为"生成重放"。
在基于生成式回放的CIL中,通常存在两种模型,即用于数据生成的生成式模型和用于预测的分类模型。GR首先提出在CIL中使用生成对抗网络( GAN ) 。在每次更新过程中,使用GAN从旧类中生成实例,然后使用新旧类更新GAN和分类模型。ESGR 通过保存额外的例子来扩展GR。它还提出为每个增量任务训练一个单独的GAN,不需要增量更新GAN。《Overcoming catastrophic forgetting for continual learning via model adaptation》通过引入动态参数生成器对GR进行扩展,使其能够在测试时刻进行模型自适应。FearNet探索大脑启发的CIL,并使用双记忆系统,其中新的记忆从网络中巩固为最近的记忆。
讨论:直接重放是一种简单而有效的策略,已被广泛应用于相机定位、语义分割、视频分类[和行为识别等领域。由于它直接优化了旧范例的损失,因此在优化策略中发现它可以帮助持续学习者保持在先前任务的低损失区域。然而,由于样本集只保存了训练集的一小部分,数据重放可能会出现过拟合问题,削弱泛化能力。考虑到在小规模数据集上重复优化不可避免地会导致决策边界的紧致和不稳定,一些工作通过约束模型关于样本的逐层Lipschitz常数或扩大表示变化以缓解表示崩溃来解决这个问题。此外,数据不平衡问题也是由于少样本样本和多样本训练集之间的差距而产生的。迭代优化不平衡的训练集会在分类器中引入额外的偏差,一些工作用平衡采样来解决这个问题。最后,由于直接重放需要保存以前类别的样本,当原始数据中包含人脸图像时,或者当原始数据中包含稀有动物图像时,会面临隐私问题。在这种情况下,算法应该设计成在没有样例的情况下学习,或者使用隐私友好的策略,如特征重放。
另一方面,生成式重放方法的性能依赖于生成数据的质量。他们被发现在简单的数据集上效果很好,但在复杂的、大规模的输入上效果不佳。为了解决这个问题,一些工作发现生成特征在计算复杂度和语义信息方面比生成原始图像要容易得多。因此,他们要么使用条件GAN来生成特征,要么使用VAE来建模内部表示。此外,扩散模型的最新进展揭示了使用预训练的扩散模型生成实例的一种很有前途的方法,而使用预训练的模型会导致在没有额外信息的情况下与其他方法进行不公平的比较。 此外,当顺序更新生成模型时,灾难性遗忘现象也可以在这些生成模型上观察到。因此,在使用生成式回放时,应该从两个方面设计算法来解决灾难性遗忘(即,分类器方面和生成模型方面)。
3.2 数据正则化
除了直接回放以前的数据外,另一组工作试图利用以前的数据来正则化模型并控制优化方向。由于学习新的类会导致对旧类的灾难性遗忘,因此直观的想法是确保为新类优化模型不会伤害到旧类。GEM的目的是找到模型满足:
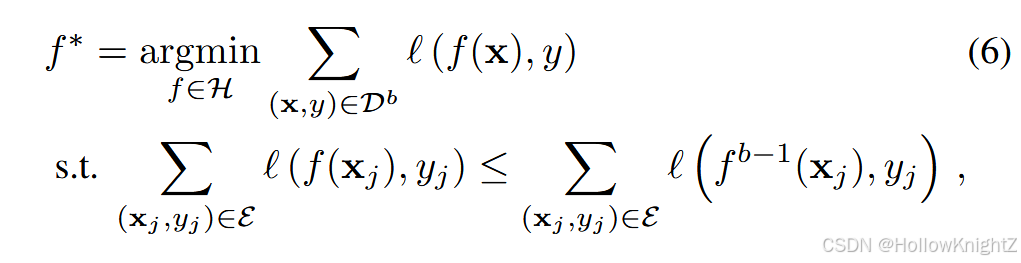
其中 f b − 1 f^{b-1} fb−1 表示训练完最后一个任务 D b − 1 D^{b-1} Db−1 后的增量模型。式6对模型进行了有约束的优化,要求用样例集计算的损失不要超过原模型。由于范例是来自以前类的具有代表性的实例,GEM在学习新类和保留原有知识之间取得了平衡。此外,他还变换了式6中的约束为:
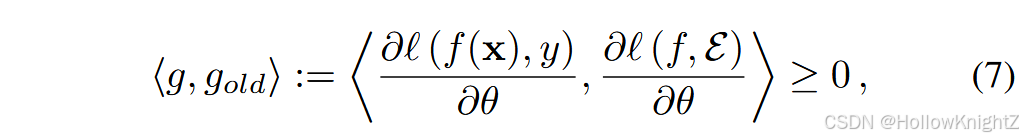
其中, g , g o l d g,g_{old} g,gold 分别表示当前更新步和样本集的梯度。式7中梯度间的夹角为锐角。如果所有不等式约束都得到满足,那么所提出的参数更新不太可能增加先前任务的损失。大师,如果出现违反,GEM建议将梯度 g g g 投影到满足约束的最近梯度 g ' g' g' 上。GEM进一步将优化问题转化为二次规划(QP)问题。但由于式(7)中的正则项是在所有样本中定义的,他需要计算样本集之间的损失,并在每个优化步骤中求解QP问题。因此,优化GEM是非常耗时的。为此,A-GEM提出通过放松式(7)中的约束到一个随机批次来加快优化速度。
还有其他一些解决正则化问题的方法,举例说明。例如,Adam-NSCL 提出通过将候选参数更新投影到所有先前任务的近似零空间中,依次优化网络参数。OWM 只允许在与所有先前学习的输入所张成的子空间正交的方向上修改权重。LOGD 进一步将梯度分解为共享梯度和特定任务梯度。在模型更新中,梯度应接近新任务的梯度,与所有旧任务共享的梯度一致,并与旧任务特有的梯度所张成的空间正交。
讨论:数据正则化方法以另一种方式利用样本集,即将样本集的损失作为遗忘的指标。他们假设样例上的损失与先验任务一致,并将参数更新与样例集合的方向对齐。因此,由于梯度方向的对齐,这些例子可以保留先前的知识。然而,这些假设在某些情况下可能并不成立,从而导致性能不佳。为此,为了摆脱了对样本的要求,手动地将梯度方向投影到与之前的梯度方向正交。另一方面,一些工作假设更新规则可以从一系列相关任务中元学习。 MER 对数据重放的目标进行了正则化处理,使得输入样本上的梯度更可能具有可迁移性,相对于过去的样本更不可能产生干扰;iTAML将通用特征提取模块与任务特定的分类器分离,从而最小化干扰,促进任务之间共享特征空间。《Anti-retroactive interference for lifelong learning》扩展了对抗攻击下的数据重放,元学习一个自适应的融合模块来帮助为不同难度的知识分配容量。
此外,由于数据正则化和数据重放都需要将先前的数据保存在内存中,基于数据正则化的方法也会出现类似的问题,例如,过拟合,泛化问题和隐私问题。因此,设计隐私友好的算法来构建带有中间产品的正则化项对于现实世界的应用来说是很有意义的。
3.3 动态网络
深度神经网络被证明可以产生任务特定的特征。例如,当训练数据集包含"汽车"时,模型倾向于刻画车轮和车窗。然而,如果用包含"猫"的新类来更新模型,特征将适应于胡须和条纹。由于模型的容量是有限的,适应新的特征会导致对旧特征的覆盖和遗忘。因此,利用提取的胡须和跨步特征对汽车进行识别是低效的。为此,设计动态网络来动态调整模型的表示能力,以适应不断演化的数据流。表征能力的拓展有多种方式,本文将其分为三个子群,即神经元扩展、骨干扩展和提示扩展。
3.3.1 神经元扩展
早期的工作主要集中在当表征能力不足以捕获新类别时,增加神经元扩展。DEN 将调节过程描述为选择、扩展、复制和消除。面对一个新的增量任务,模型首先选择性地重新训练与该任务相关的神经元。如果重新训练的损失仍然高于某个阈值,DEN考虑自顶向下扩展新的神经元,并使用组合稀疏正则化消除无用的神经元。之后,它计算神经元逐个优化漂移,并复制与原始值漂移过多的神经元。 除了启发式地扩展和收缩网络结构外,RCL 将网络扩展过程形式化为一个强化学习问题,并为每个传入的任务搜索最佳的神经架构。类似地,神经结构搜索( NAS ) 也被用于为每个连续任务寻找最优结构。
3.3.2 骨干扩展
扩展的神经元表现出可扩展表征的竞争性结果。相应地,一些工作试图复制骨干网络以获得更强的表示能力。PNN提出为每个新任务学习一个新的骨干,并在增量学习中固定前者。它还增加了新旧模型之间的逐层连接,以重用以前的特征。专家门也扩展了每个增量任务的主干,但它需要学习一个额外的门,以便在推理期间将实例映射到最合适的路径。为了降低扩展代价,P&C提出了一种渐进压缩协议- -它首先扩展网络来学习有代表性的表示。然后,进行压缩过程以控制总预算。 AANets部分扩展了稳定块和可塑块,并将它们的预测进行聚合,以增强模型的表示能力。最近,DER被提出用于解决CIL问题。与PNN类似,它在面对新任务时扩展了一个新的骨干,并以更大的FC层来聚合特征。以第二个增量任务为例,其中模型输出被聚合为。
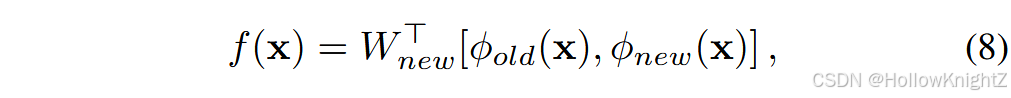
其中 ϕ o l d \phi_{old} ϕold 是之前的骨干, ϕ n e w \phi_{new} ϕnew 是新初始化的骨干。 ⋅ , ⋅ ·,· ⋅,⋅ 表示特征聚合, W n e w ∈ R 2 d × ∣ Y b ∣ W_{new}∈R^{2d×|Y_b|} Wnew∈R2d×∣Yb∣ 是新初始化的FC层。在模型更新过程中,旧的主干被冻结以保持原有的知识:
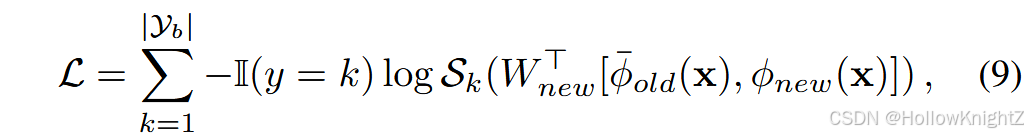
其中 ϕ ‾ o l d ( x ) \overline{\phi}{old}(x) ϕold(x) 表示被冻结的骨干。DER还采用了一个辅助损失来区分旧类和新类。式( 9 )描绘了一种用新的特征不断扩展模型的方法。在这种情况下,如果用"汽车"来优化旧的骨架,那么 ϕ o l d \phi{old} ϕold 提取的特征就代表了车轮和车窗。用"猫"训练的新骨干负责提取胡须和条纹。由于旧的主干在后期被冻结,学习新类不会覆盖旧类的特征,遗忘得到缓解。图4 (左)描述了DER的模型演化。
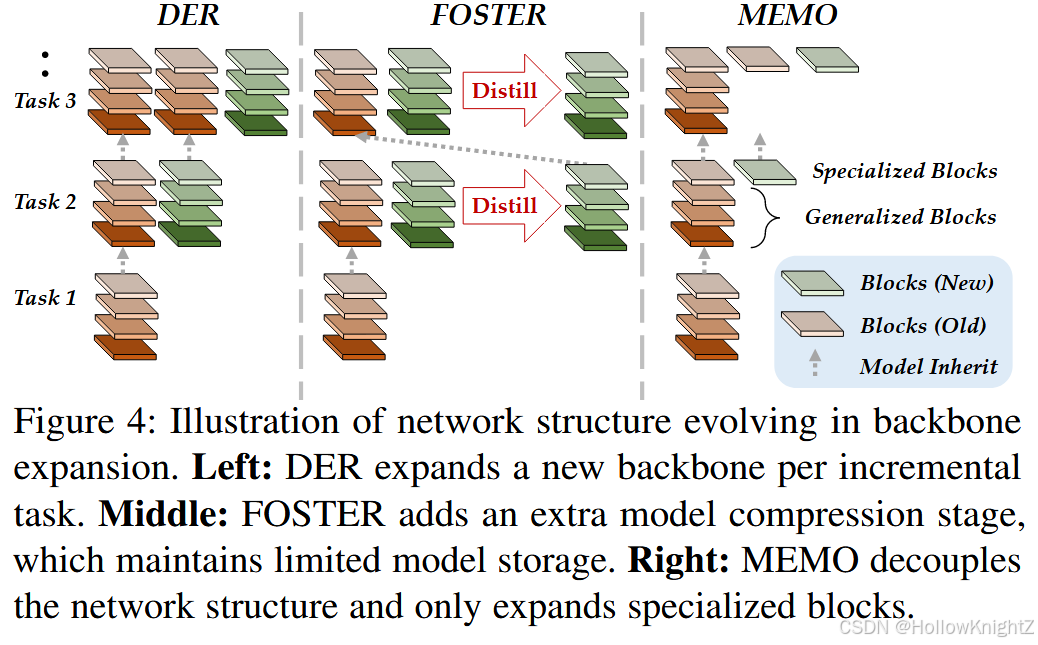
然而,在DER中,每个任务保存一个骨干需要大量的内存大小,并且许多工作都是为了在有限的内存预算下获得可扩展的特征。FOSTER 给出了式(9)的学习过程。作为特征boosting 问题。它认为并非所有的扩展特征都是增量学习所需要的,需要进行集成以减少冗余。例如,假设旧类包含"老虎",新类包含"斑马"。在这种情况下,条纹将是新旧骨架都可以提取的有用特征。在这种情况下,迫使新的骨干提取相同的特征对识别的效果较差。因此,FOSTER通过知识蒸馏增加了一个额外的模型压缩过程:
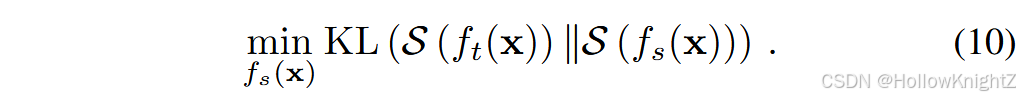
式(10)的目的是通过最小化学生模型和教师模型之间的差异,找到与教师模型 f t f_t ft 具有相同判别能力的学生模型 f s f_s fs。教师是两个骨干的冻结扩展模型: f t ( x ) = W n e w T ϕ o l d ( x ) , ϕ n e w ( x ) f_t ( x ) = W_{new}^T \\phi_{old} ( x ) , \\phi_{new} ( x ) ft(x)=WnewTϕold(x),ϕnew(x),学生是新初始化的模型 f s ( x ) = W ⊤ ϕ ( x ) f_s ( x ) = W^⊤\phi ( x ) fs(x)=W⊤ϕ(x)。因此,骨干网的数量始终被限制在单个骨干网上,并且内存预算不会发生灾难性的膨胀。图4 (中间)描述了FOSTER模型的演化。
MEMO解决了CIL中的内存问题,旨在以最小的预算成本实现模型扩展。研究发现,在CIL中,不同模型的浅层具有相似性,而深层具有差异性。也就是说,浅层更具有概括性,而深层则是针对任务的特定性,使得CIL扩展浅层的存储高效更小。因此,MEMO提出在中间层对骨干网络进行解耦: ϕ ( x ) = ϕ s ( ϕ g ( x ) ) \phi( x ) = \phi_s ( \phi_g ( x ) ) ϕ(x)=ϕs(ϕg(x)),其中特殊块 ϕ s \phi_s ϕs 对应于网络中的深层,而广义块 ϕ g \phi_g ϕg 对应于网络中的其余浅层。与DER相比,MEMO只扩展了专门的块 ϕ s \phi_s ϕs,并将式(9)变换变为:
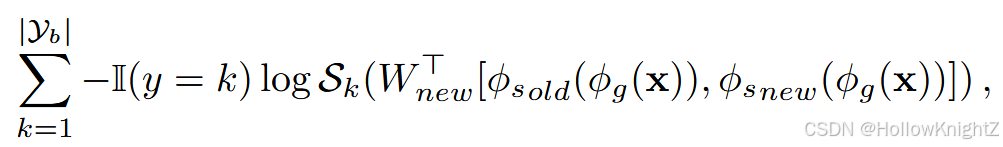
这表明每个任务可以在共享的浅层 ϕ g ( x \phi_g ( x ϕg(x )上建立特定任务的深层层。图4 (右)描述了MEMO的模型演化。
3.3.3 提示扩展
最近,视觉转换器( Vision Transformer,ViT ) 引起了计算机视觉界的关注,许多工作倾向于设计以ViT为骨干的CIL学习器。DyTox 是第一个在CIL中探索ViT的工作,该工作发现ViT中的模型扩展比卷积网络中的模型扩展要容易得多。在DyTox中,每个新任务只扩展任务令牌,这比保存整个骨干所需的内存要少得多。类似地,L2P 和Dual Prompt 探讨了如何利用预训练的ViT构建CIL学习者。他们借鉴了视觉提示调谐( Visual Prompt Tuning,VPT ) 的思想,用提示对模型进行增量微调。在L2P中,预训练的ViT在学习过程中冻结,模型只对提示进行优化以适应新的模式。 提示池定义为: P = { P 1 , P 2 , ⋅ ⋅ ⋅ , P M } P = \{ P1,P2,· · ·,PM \} P={P1,P2,⋅⋅⋅,PM},其中M是提示的总数, P i ∈ R L p × d P_i∈R^{L_p × d} Pi∈RLp×d是令牌长度为 L p L_p Lp 的单个提示,嵌入大小 d d d 与实例嵌入 ϕ ( x ) \phi ( x ) ϕ(x) 相同。将提示信息组织为键值对- -每个实例通过KNN搜索选择提示信息池中最相似的提示信息。它通过调整输入向量为: x p = P s 1 ; ⋅ ⋅ ⋅ ; P s N ; φ ( x ) , 1 ≤ N ≤ M x_p = P_{s_1} ; · · · ; P_{s_N} ; φ ( x ),1≤N≤M xp=Ps1;⋅⋅⋅;PsN;φ(x),1≤N≤M 来获得特定实例的预测,其中 P s j P_{s_j} Psj 是选择的特定实例提示。然后将适应后的嵌入输入到自注意力层中,以获得特定实例的表示。CODA-Prompt 利用注意力机制扩展了提示搜索。 除了预训练的ViT,S-Prompt使用预训练的语言-视觉模型CLIP进行CIL,该模型同时学习语言提示和视觉提示以增强代表性嵌入。除了扩展提示,其他轻量级模块也可以在CIL中动态扩展。
讨论:学习动态网络,特别是骨干扩展方法,在最近几年取得了最先进的性能。然而,它通常需要可扩展的内存预算,这不适用于边缘设备上的增量学习。为了解决这个问题,可以采用进一步的模型压缩,解耦和剪枝来减轻内存预算。此外,训练DER需要为每个任务提供一个单独的骨干,并将所有历史骨干聚合作为特征提取器。它隐式地导致了与具有单一骨干的其他方法的不公平比较。此外,扩展骨干忽略了任务间的语义信息,例如,当旧任务包含"老虎",新任务包含"斑马"时,"条纹"等特征会被多个骨干提取,造成特征冗余。因此,分析任务间的语义关系可以帮助检测特征冗余,而对比学习可以用于泛化特征。
另一方面,大多数快速扩展方法依赖于预先训练好的模型作为初始化。没有这种可泛化的主干,带提示的轻量级模型往往会失败。然而,对于一些特定的下游任务,例如人脸识别和语音识别,预训练的模型并不总是可用的。因此,如何摆脱对预训练模型的依赖对于这些方法在现实世界中的应用至关重要。此外,这些基于提示扩展的方法倾向于根据一批实例选择特定实例的提示。为了准确的快速检索,在推理过程中也需要满足这一要求,这会导致不公平的比较。由于使用了一批实例来得到提示,实例之间的上下文变得可用,这违背了机器学习中独立同分布检验的常识。
3.4 参数正则化
动态网络寻求随着数据的演化来调整模型的容量。然而,如果模型结构是固定不变的,我们如何调节可塑性来抵抗灾难性遗忘。参数正则化方法认为每个参数对任务的贡献是不相等的。因此,他们寻求评估每个参数在网络中的重要性,并将重要的参数保持不变,以保持原有的知识。
典型的工作是在模型参数上估计一个分布,并将其作为学习新任务时的先验。由于参数较多,估计过程往往假设它们是独立的。EWC是第一个研究参数正则化的工作。它保持一个与网络规模相同的重要性矩阵,即 Ω Ω Ω。记第 k k k 个模型参数为 θ k θ_k θk, θ k θ_k θk 的重要性用 Ω k ≥ 0 Ω_k≥0 Ωk≥0 ( Ω k Ω_k Ωk 越大,表明 θ k θ_k θk 越重要)来表示。除了式(3)中的训练损失为了学习新类,EWC构建了一个额外的正则项来记忆旧类:
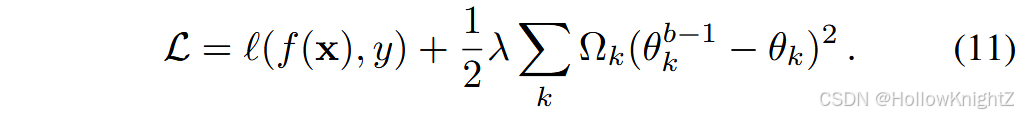
参数正则化项基于两部分计算, θ k b − 1 θ^{b - 1}_k θkb−1 表示学习最后一个任务 D b − 1 D^{b - 1} Db−1 后的第 k k k 个参数。因此, ( θ k b − 1 − θ k ) 2 ( θ^{b - 1}_k - θ_k)^2 (θkb−1−θk)2 表示上一阶段的参数漂移, Ω k Ω_k Ωk 对其进行加权,以保证重要参数不偏离上一阶段。由于最后一个阶段的模型代表的是"旧"知识,对重要参数进行合并可以防止知识被遗忘。
式(11)描述了一种惩罚基本参数的方法,并且有不同的方法来计算重要性矩阵 Ω Ω Ω。在EWC中,Fisher信息矩阵被用来估计 Ω Ω Ω。然而,EWC中的重要性计算是在每个任务结束时进行的,忽略了模型训练轨迹上的优化动态。为此,SI提出在线估计 Ω Ω Ω,并通过其对损失衰减的贡献来衡量其重要性。RWalk结合了这些重要性估计技术。IMM 通过估计的Fisher信息矩阵找到高斯后验混合的最大值。IADM 和CE - IDM分析了不同层的能力和可持续性,发现不同层在CIL中具有不同的特征。
讨论:虽然参数正则化和数据正则都使用正则化项来抵抗遗忘,但它们的基本思想有本质的区别。具体来说,数据正则化依赖于样本集来指导优化方向,而参数正则化则基于参数重要性来构造正则项。如图3所示,参数正则化方法在早期就引起了社会各界的关注。表明,尽管源于不同的动机,SI ]和MAS 都近似Fisher信息的平方根,而Fisher信息是EWC的理论基础。然而,估计参数重要性需要保存与骨干矩阵具有相同规模的矩阵。 它面临着与动态网络相同的风险,因为当学习越来越多的任务时,记忆预算是线性增加的。另一方面,在不同的增量阶段,重要性矩阵可能会发生冲突 88 ,导致模型难以优化,在新任务上表现不佳。因此,尽管这些工作在任务增量学习中取得了有竞争力的结果,但许多工作发现基于参数正则化的方法在类增量学习场景中表现不佳。为此,一些工作试图通过学习一个新的骨干并将它们整合成一个单一的骨干来缓解不传递性。 在这种情况下,新任务的学习不会受到正则化项的影响,参数重要性只会在合并过程中被考虑,使得模型能够充分拟合新任务。
3.5 知识蒸馏
训练数据在学习过程中不断演化,需要不断调整模型。我们可以将上一阶段 f b − 1 f^{b - 1} fb−1 之后的模型称为"旧模型",当前更新的模型f称为"新模型"。假设旧模型对 Y b − 1 Y_{b - 1} Yb−1 中的所有可见类都是一个好的分类器,我们如何利用它来抵抗新模型中的遗忘。为了使旧模型能够辅助新模型,一种直观的方式是知识蒸馏( KD )。KD能够实现从教师模型到学生模型的知识迁移,通过这种知识迁移,我们可以教会新的模型不要忘记。构建蒸馏关系的方法有很多种,我们将这些基于KD的方法分为三个子类,即.logit蒸馏、特征蒸馏和关系蒸馏。
LwF 是第一个将知识蒸馏应用于CIL的成功案例。与式(11)类似。通过知识蒸馏构建正则化项,以抵抗遗忘。
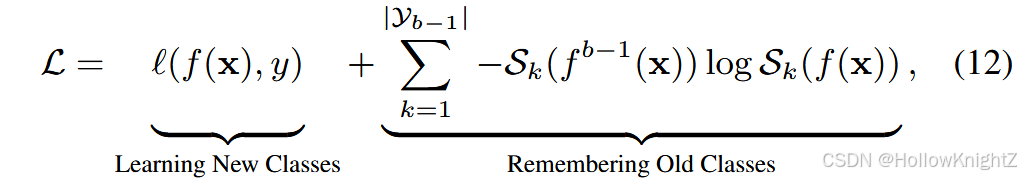
式中:旧模型 f b − 1 f^{b - 1} fb−1 在更新时冻结。正则化项通过迫使旧类之间的预测概率一致来建立新旧模型之间的映射。给定一个特定的输入 x x x,第 k k k 个类的输出概率揭示了输入到该类的语义相似性。因此,式(12)强制新旧模型的语义关系相同,抵抗遗忘。iCaRL 用样例集扩展了LwF,有助于在增量学习过程中进一步回忆以前的知识。此外,它还去掉了全连接层,在推理过程中使用最近平均样本。式(12)在旧类别和新类别之间进行权衡,前一部分旨在学习新类别,后一部分保持旧知识。由于在不同的增量阶段,新旧类的数量可能不同,BiC 通过引入动态权衡项对式( 12 )进行扩展:
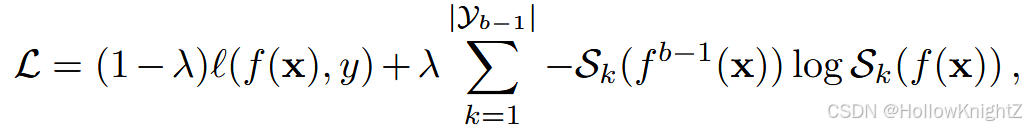
其中 λ = ∣ Y b − 1 ∣ ∣ Y b ∣ \lambda=\frac{|Y_{b-1}|}{|Y_b|} λ=∣Yb∣∣Yb−1∣ 表示旧类在所有类中的比例。随着渐进性任务的演化,该值逐渐增大,说明模型对旧任务的关注程度更高。
LwF启发社区建立模型之间的映射,使知识蒸馏成为CIL中的有用工具。D+R 建议改变式(12)的第一部分。通过训练一个额外的专家模型转化为蒸馏损失。GD 提出了选择野生数据进行模型蒸馏,并设计了一种基于置信度的采样方法来有效地利用外部数据。类似地,DMC 提出在每个增量阶段训练一个新的模型,然后通过一个额外的未标记数据集将它们压缩到单个模型。最后,如果没有额外的数据可用来进行知识蒸馏,ABD 提出提取合成数据进行增量学习。这些方法只专注于利用旧模型来帮助抵抗新模型中的遗忘。然而,COIL 建议使用协同传输进行双向蒸馏,其中旧模型和新模型之间的语义关系都被利用。
除了提取logits之外,一些工作提出提取深度模型的中间产物,例如提取特征。UCIR代替了式(12)中的正则化项变为:
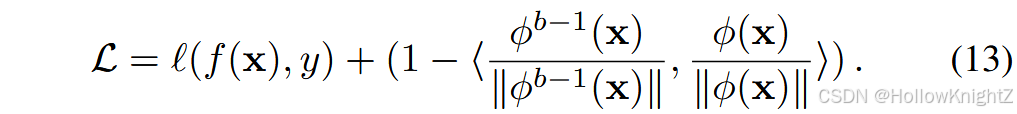
式(13)迫使新嵌入模块提取的特征与旧嵌入模块相同,这是一种比式(12)更强的正则化。随后,一些工作在CIL中使用特征蒸馏,而其他工作则用于提取其他产品。LwM建议通过惩罚分类器注意图的变化来抵抗遗忘。AFC 考虑不同特征图的重要性进行蒸馏。PODNet 将池化的中间特征在高度和宽度方向上的差异最小化,而不是进行逐元素蒸馏。CVIC 将蒸馏项解耦为空间和时间特征用于视频分类。 DDE 从旧训练中提取因果效应以保存旧知识。GeoDL 基于新旧模型两组特征的投影进行蒸馏。
logit和特征蒸馏都解决了新旧模型之间的实例映射问题。为了揭示模型蒸馏中的结构信息,一些工作建议进行关系知识蒸馏。这些知识蒸馏组之间的差异如图5所示。
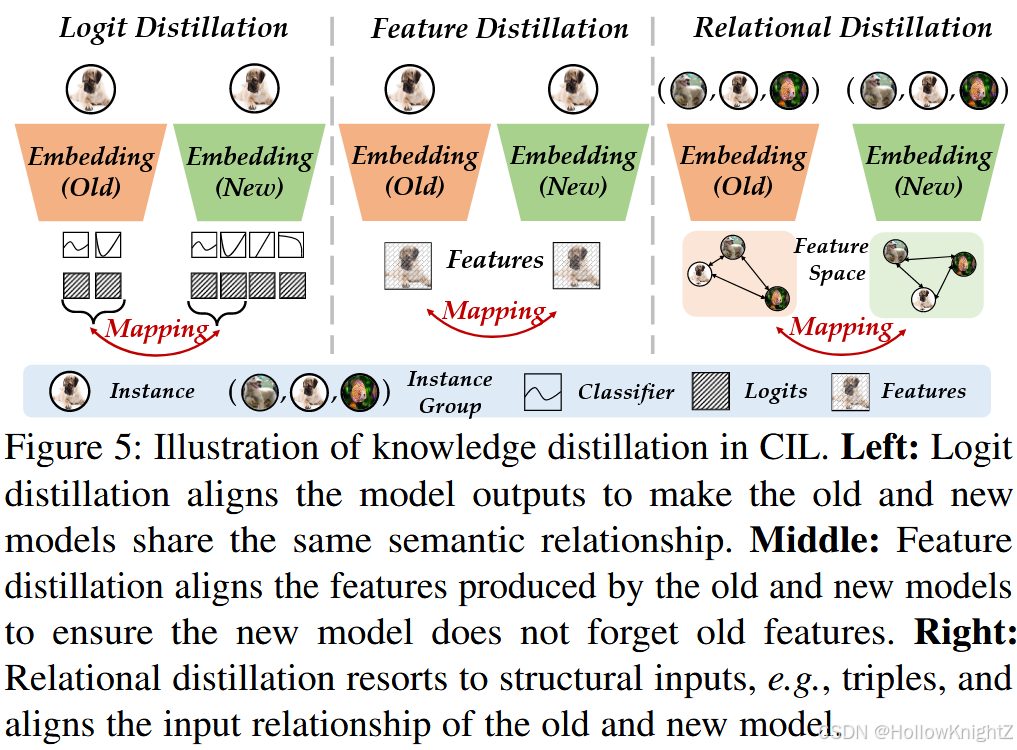
为了进行关系蒸馏,需要提取一组实例,例如三元组。我们将抽取到的三元组记为 { x i , x j , x k } \{ x_i,x_j,x_k \} {xi,xj,xk},其中 x i x_i xi 称为锚点。在一个三元组中,目标邻居 x j x_j xj 与锚点 x i x_i xi 具有相同的类,而冒名者 x k x_k xk 与 x i x_i xi (通常来自不同的类)不相似。R-DFCIL 建议对三元组之间的夹角进行映射:
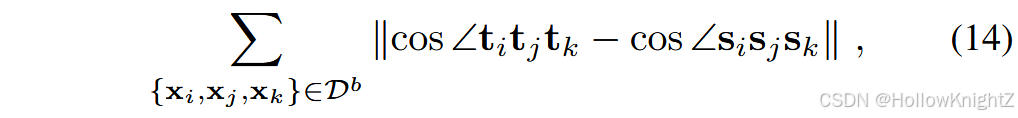
其中, t m = ϕ b − 1 ( x m ) t_m = \phi^{b-1} ( x_m ) tm=ϕb−1(xm) 为旧模型嵌入空间中的表示, s m = ϕ ( x m ) s_m = \phi ( x_m ) sm=ϕ(xm) 为当前模型中的表示。在相应的嵌入空间中计算余弦值。式(14)提供了一种将旧模型的结构信息编码到新模型中,并对特征空间进行柔和对齐的方法。ERL 将这种正则化推广到小样本CIL场景。TPCIL用弹性Hebbian图来建模顶点之间的关系,并惩罚顶点之间拓扑关系的变化。TOPIC进一步探索了神经气体网络来建模类间关系。
讨论::知识蒸馏是建立一组方法之间映射的通用思想,已被广泛应用于多种形式的类增量学习中。由于其灵活性,基于知识蒸馏的方法也被广泛应用到各种增量学习任务中,例如,语义分割,行人再识别,人体动作识别和联邦学习。由于CIL中存在一组模型,因此在CIL中建立学生-教师映射是很直观的,这使得知识蒸馏成为大多数工作的基本解决方案。
3.6 模型校正
假设我们可以一次性得到所有的训练数据集,并将其洗牌以进行多个历元的训练,那么模型不会被遗忘,并且在所有类别中表现良好。这样的协议被称为类增量学习的上界,记为" Oracle "。然而,由于使用增量数据训练的模型会发生灾难性遗忘,一些方法试图发现CIL模型中的异常行为,并像oracle模型那样进行纠正。这些异常行为包括输出日志、分类器权重和特征嵌入。
第一个解决CIL模型偏差的方法是UCIR。发现新类的权重范数明显大于旧类,模型倾向于将实例预测为权重较大的新类。因此,UCIR提出使用余弦分类器来避免有偏分类器的影响: f ( x ) = W ∥ W ∥ ⊤ ϕ ( x ) ∥ ϕ ( x ) ∥ f ( x ) = \frac{W}{∥W∥}^⊤ \frac{\phi( x )}{∥\phi( x )∥} f(x)=∥W∥W⊤∥ϕ(x)∥ϕ(x) 。因此,在增量学习中,权重范数不会影响模型预测。WA 将每一步优化后的权重进一步归一化。它还引入了权重裁剪,以确保预测概率与分类器权重成正比。SS-IL 解释了权重漂移的原因,它是由新旧实例之间的不平衡现象引起的。
另一方面,一些工作发现新类的预测logit比旧类大得多。E2E 提出在每个阶段后使用平衡的数据集对全连接层进行微调。此外,BiC提出附加一个额外的校正层来调整预测。额外层只有两个参数,即重标极差参数α和偏置参数β,第k类的校正输出表示为:
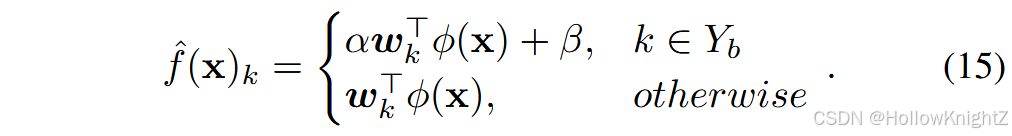
每次增量任务后只对新类 ( k ∈ Y b k∈Y_b k∈Yb)的logit进行修正。BiC从样本集中分离出一个额外的验证集,即 E = E t r a i n ∪ E v a l E = E_{train}∪E_{val} E=Etrain∪Eval,并使用验证集对校正层进行调优。另一方面,IL2M 建议利用历史统计数据对产出进行重新标度。假设一个实例被预测为一个新的类。在这种情况下,logits将被重新调整,以确保旧类和新类的预测遵循相同的分布。
最后,由于CIL中的嵌入模块是顺序更新的,一些工作试图纠正增量模型的有偏表示。例如,SDC使用了最近的样本均值分类器,该分类器计算类中心并将实例分配到最近的类中心。嵌入是增量更新的,上一阶段计算的类中心在下一阶段可能会发生漂移,使得分类结果不可靠。由于旧类实例在当前阶段不可用,SDC旨在随着新类的漂移来校准旧类的类中心。CwD分析了CIL模型和oracle模型的嵌入差异,发现oracle模型的嵌入分布更加均匀。其目的是通过强制特征值接近,使CIL模型类似于Oracle。ConFiT 从中间层缓解特征漂移。MRFA 发现重播样本的全层间隔随着数据的演化而缩小。其他工作涉及模型权重校正。 CCLL 的目的是在增量学习过程中校准旧模型的激活图。RKR 提出在学习新任务时对旧模型的卷积权重进行修正。FACT 为CIL描绘了一种新的训练范式,即前向兼容训练。由于嵌入空间对新类别进行无休止的调整,FACT提出为新类别预分配嵌入空间,以减轻嵌入调优的负担。
讨论:基于模型校正的方法旨在减少CIL模型中的归纳偏差,并将其与Oracle模型对齐。这一工作有助于理解灾难性遗忘的内在因素。除了本节列出的校正方法外,文献还指出CIL模型的偏差来自于不平衡数据流。Zhang等发现使用对比损失训练的嵌入比交叉熵损失具有更少的遗忘。发现批规范化层在CIL中是有偏的,并提出对层输出进行重新规范化。Zhang等发现视觉转换器在增量更新时逐渐丢失局部信息,并提出将局部先验信息插入到自注意力过程中。
除了模仿oracle模型外,还有关于前向兼容性 104 和平坦损失景观的工作。由于CIL的最终目标是在所有任务中找到损失图中的平坦最小值,因此在第一阶段中,一些工作旨在实现这一目标。未来值得探究灾难性遗忘中的其他因素以及相应的解决方法。另一方面,通过监督损失对所有数据进行联合训练得到oracle模型。其他任务无关的特征也可以帮助建立一个整体分类器,例如,通过对比学习,这是oracle模型所不具备的。
3.7 基于模板的分类
最后,我们讨论了CIL中广泛采用的基于模板的分类方法。如果我们可以为每个类建立一个"模板",则可以通过将查询实例匹配到最相似的模板来完成分类。一种流行的方法是使用类原型作为模板,它根植于认知科学。深度神经网络中的原型通常被定义为嵌入空间中的平均向量。例如,我们可以利用当前的嵌入函数φ ( · )来提取第i类的原型:
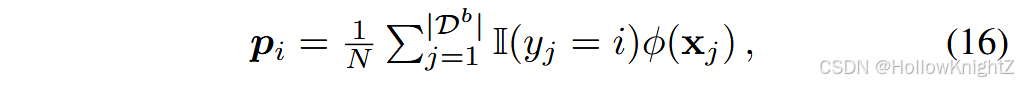
式中:N为第i类的实例数。式(16)通过嵌入空间中的类中心计算类原型。因此,通过将实例匹配到最近的原型,可以不依赖全连接层进行推理:
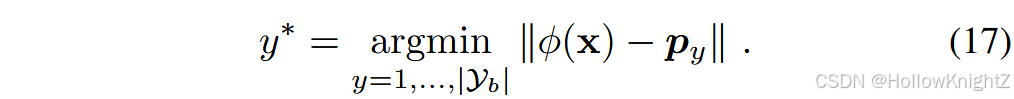
正如基于模型校正的方法所讨论的那样,顺序地更新增量模型将导致全连接层的偏差。相应地,i CaRL 建议通过公式(17)进行推断,也称为最近类均值分类器。由于推理是在同一嵌入空间中通过实例原型匹配进行的,因此可以缓解不同阶段之间的偏差。然而,使用基于原型的推理也面临另一个挑战,即阶段之间的嵌入不匹配。由于嵌入函数在不同阶段之间不断变化,前一阶段的原型可能与后一阶段的查询嵌入不兼容。这种现象也被称为语义漂移。 为了填补这个空白,一个简单的解决方案是利用样例集合,在每个阶段之后重新计算类原型。由于样本集E包含了以前类的实例,因此在每个增量阶段后重新计算所有类原型,保证了原型与最新的嵌入函数之间的兼容性。然而,当样例不可用时,需要设计特定的算法来补偿语义漂移。
基于原型的无样例推理:当样例不可用时,主要有两种方案来维护一个原型分类器。一个朴素的解决方案是在第一个增量阶段之后冻结嵌入函数,这迫使不同阶段的原型是兼容的。这样的学习过程假设使用第一阶段数据训练的嵌入函数对未来任务足够泛化,依赖于D1中的大量训练实例。因此,研究人员倾向于使用D1设计合适的训练技术,以获得未来任务可泛化的特征空间。从对比学习中得到启发,设计前文本任务来增强第一阶段学习到的表征。 CEC 元学习一个图模型来调整新的类原型与已知的类原型,它在分类器之间传播上下文信息以进行自适应。LIMIT 发现使用第一阶段主干提取的原型倾向于将实例预测到第一阶段的类中。它提出通过在旧类和新类之间元学习变压器块来校准预测logits。TEEN 系统地分析了新旧类之间的性能差距,发现原型网络迫使模型将新类预测到最相似的旧类。因此,它建议将新类的原型推向旧类,以校准决策边界。 此外,文献 104 通过为新类预留嵌入空间来增强模型的前向兼容性,使得新类可以插入到嵌入空间中而不会损害已有类。它为新类分配"虚拟原型",并使用双模态目标标签和流形混合为它们显式地保留嵌入空间,以生成新的类实例。它与第一阶段的数据集D1相连接,并将预训练和自适应的嵌入进行原型提取。在ADAM的基础上,RanPAC设计了随机投影,将级联的特征投影到高维空间中,在高维空间中类被更清晰地分离。它还增量更新了一个基于马氏距离的分类器,该分类器在原型和查询嵌入之间表现出比余弦距离更强的性能。Fe CAM 也发现余弦分类器的不足,提出使用贝叶斯分类器代替。
除了冻结嵌入,一些工作试图补偿不同阶段之间的语义漂移。由于原型会随着嵌入函数的不断变化而发生漂移,因此他们旨在估计这种漂移,以便在最新的嵌入空间中估计原型。SDC 旨在测量不同阶段之间的原型漂移,并借鉴当前阶段数据的加权组合。ZSTCI 通过将不同阶段的原型映射到相同的嵌入空间,并设计跨阶段的原型对齐损失来实现这一目标。
最后,另一类工作考虑生成式分类 .不同于将类原型作为模板进行估计,每个类的模板都是一个生成模型。因此,推理过程可以通过查询实例在这种生成模型下的可能性来衡量。然而,与基于原型的方法相比,生成模板在推理过程中需要更多的计算预算。
讨论:基于模板的分类方法有两个优点。首先,当样例集可用时,使用基于模板的分类可以在嵌入空间中实现查询-原型匹配。由于分类器在增量学习后会产生偏差,利用这样的匹配目标可以缓解推断过程中的归纳偏差。其次,当预训练模型(或用大基类训练的模型)可用作为初始化时,特征表示具有可泛化性,可以迁移到下游任务中。因此,冻结嵌入和使用基于模板的分类可以充分利用可泛化的特征,并且这样的非增量学习器不会因为冻结的主干而被遗忘。
但是,也存在一些弊端。当样例集不可用时,重新计算原型是不可能的,需要复杂的调整过程来克服语义漂移。其次,当冻结主干并采用基于模板的分类器时,模型牺牲了对下游任务的自适应性。当预训练的模型与下游数据之间存在显著的领域差距时,基于模板的分类将因无法提取可泛化的特征而失败。在这种情况下,不断调整骨干可能更适合提取特定任务的特征。 最后,我们可以使用基于能量的模型 205 为每个类计算一个能量值而不是一个似然,以缓解生成模型的高成本。