目录
[1mysql课程介绍 day01-SQL](#1mysql课程介绍 day01-SQL)
[13 更新&插入](#13 更新&插入)
[as可以起别名,但是 不加as直接在名后面写别名也是可以的](#as可以起别名,但是 不加as直接在名后面写别名也是可以的)
[1date_add里面的expr type各指的是?](#1date_add里面的expr type各指的是?)
[3 curdate()和now()有什么区别?](#3 curdate()和now()有什么区别?)
这里再给大家留一个问题,真实项目中,我们的数据库如何设计?具体,想做一个学校教务管理系统,学校教务的分学生和职工端,职工端肯定有层级部分划分,那么其数据库该怎么设计?
1mysql课程介绍 day01-SQL
2数据库相关概念

3mysql安装以及启动
03. 基础-概述-MySQL安装及启动_哔哩哔哩_bilibili
4数据模型
5通用语法及分类


6数据库操作
学习数据库操作的重点?
记忆DDL,DML,DQL,DCL的增删改查即可
7表操作-创建&查询


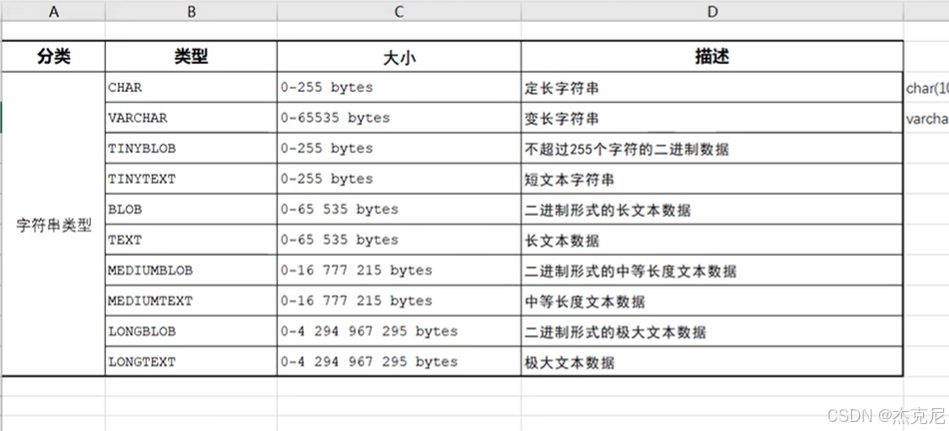
8数据类型及案例
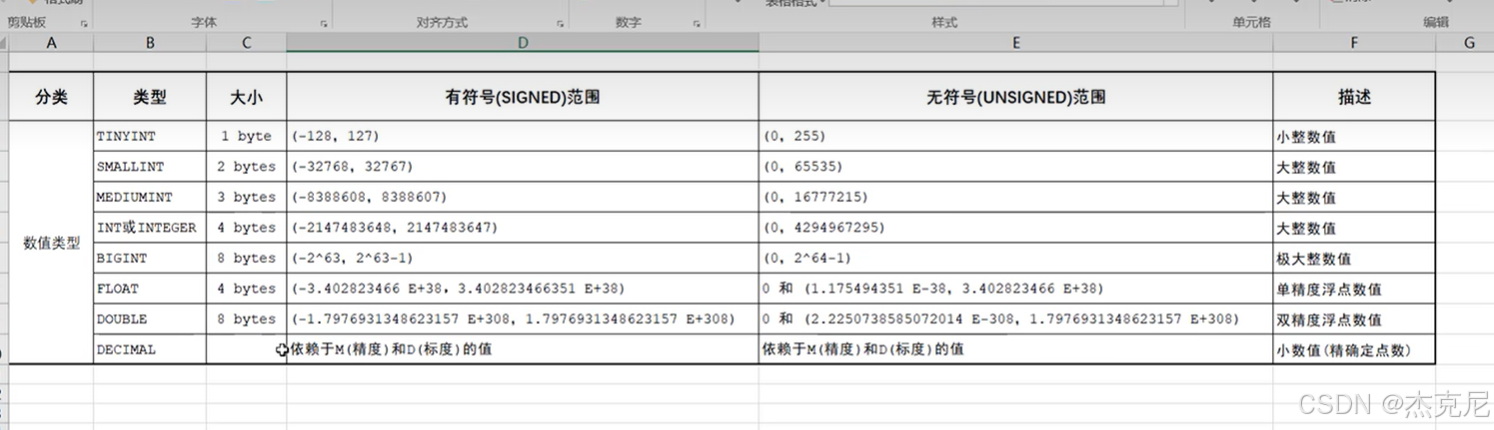

问题:
整数里面怎么表示无符号?
在类型后面加上一个unsigned
该怎么记忆整数类型的数值范围?
其实就是记住其前面的大小即可(字节数换成二进制)
整数类型中decimal里面的精度和标度是什么意思?
举例123.45 精度5(其实就是整个数值的长度),标度2(小数的长度)
学这个类型重点是学会应用
如年龄使用tinyint ,分数 使用double(4,1)
char和varchar的区别?
前者定长,就算用不完固定的长度,也会消耗空间,不定长的是用多少消耗多少
9表操作-修改与删除


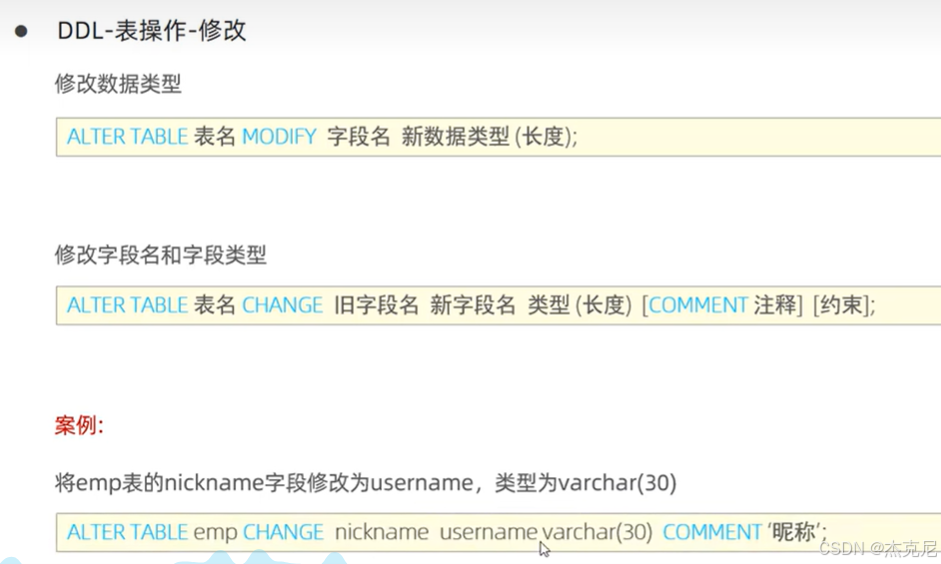


问题:
表修改字段的modify和change操作有什么区别?
前者只能修改数据类型,后者是将数据名等包括在内的全部修改了
10DDL小结

11图形化界面工具DataGrip

11. 基础-SQL-图形化界面工具DataGrip_哔哩哔哩_bilibili
12DML-插入



13 更新&插入

14DML小结

15DQL-基础查询



问题:
尽量不要写*(影响效率)
as可以起别名,但是 不加as直接在名后面写别名也是可以的
16条件查询

17聚合函数(作用于一列)

18分组查询


问题:
where与having的区别?
执行时机不同:where是对分组之前的过滤,having是对分组之后的过滤
判断条件不同:where不能对聚合函数进行判断,而having可以
19排序查询

20分页查询

问题:
1这个查询记录数是总数还是每页显示记录数?
是每页显示记录数
2Limit应用?
可以用于查询前几个数据(如查询前5名符合条件的学生数据)
21案例联系


22执行顺序
问题:
如何验证执行顺序?
可以根据起别名的位置,然后在别的地方使用
23DQL小结
24DCL用户管理


问题:
主机名有哪些?
常用的localhost(本机),%表示所有,另外就是写那台机器的ipv4的ip地址即可
修改密码里面的mysql_native_password是固定写法
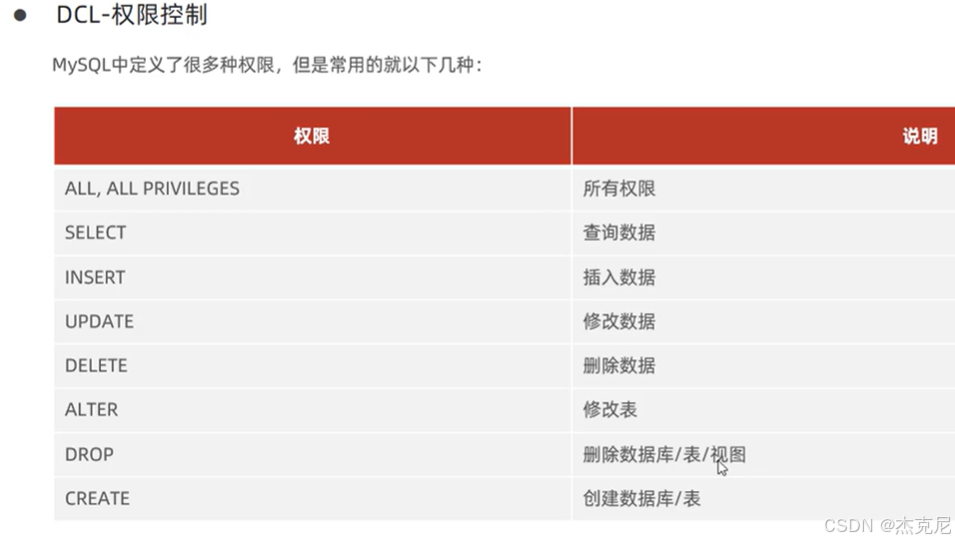
25权限控制

26DCL小结

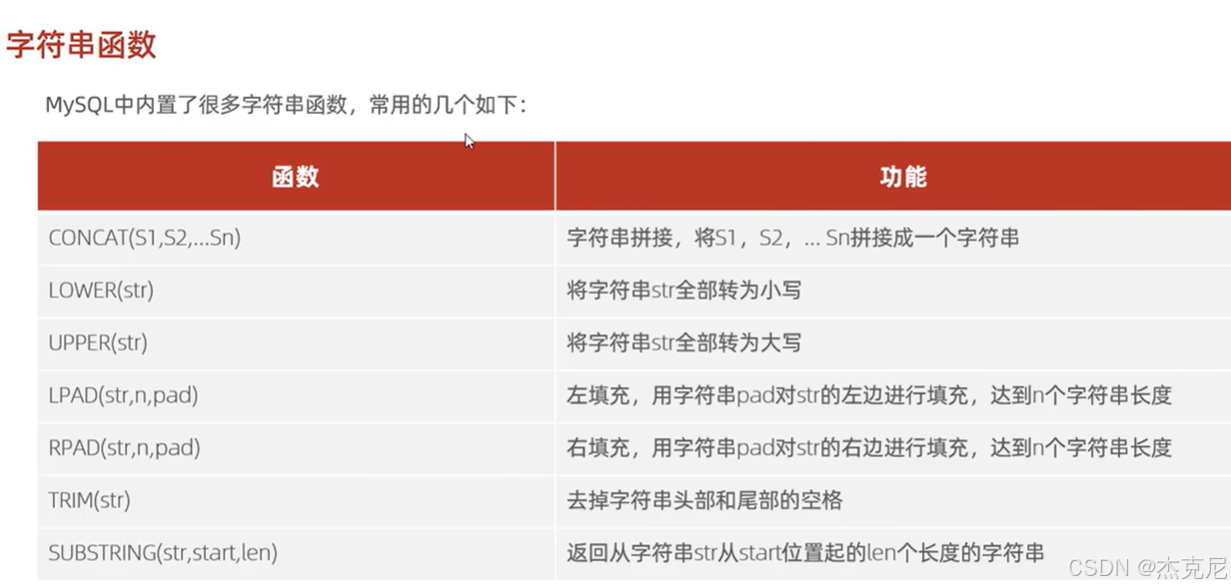
27函数-字符串函数



问题:
怎么显示函数使用的结果?
select+函数即可
注意截取的下标是从1开始的
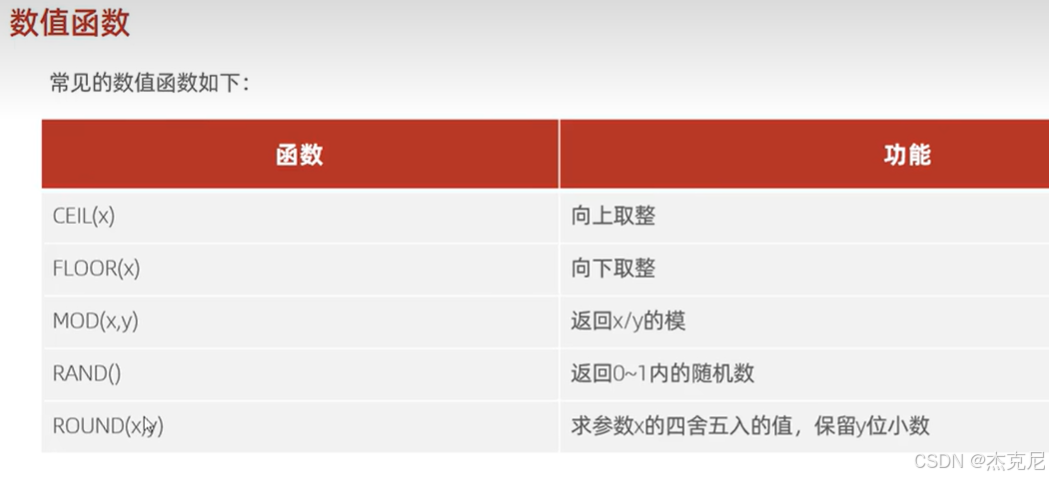
28数值函数


问题:
rand()产生的随机数范围?
0~1(但是小数点至少6位)
注意round后面的y表示的是小数的位数,而不是整体的位数
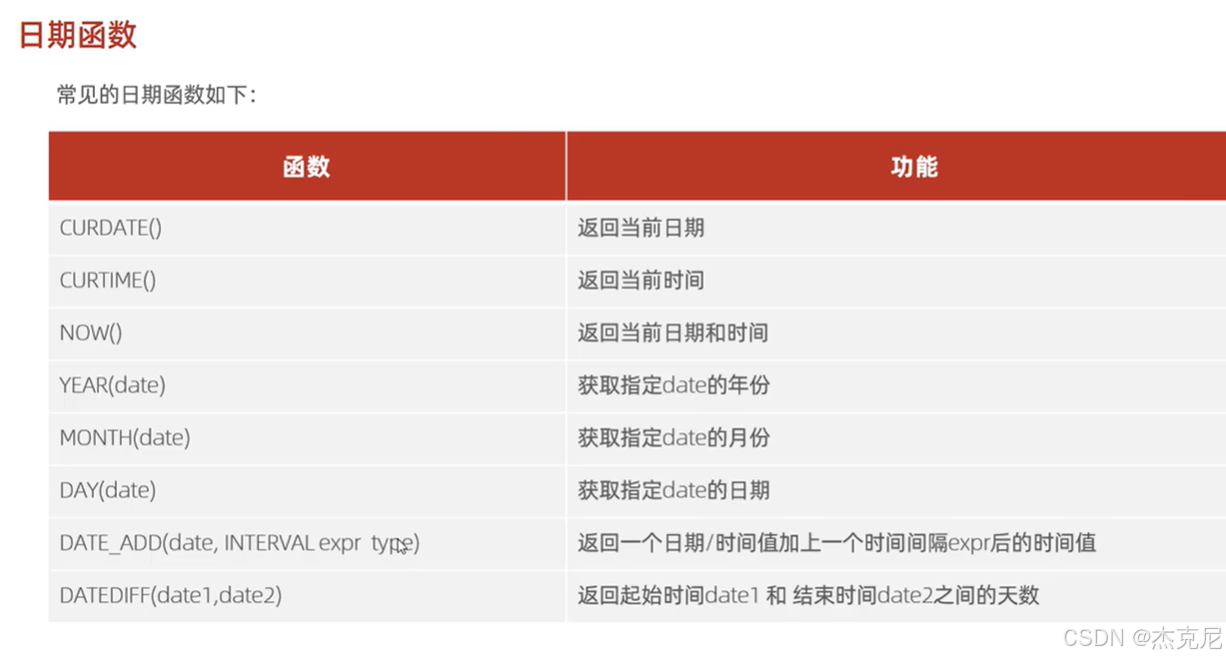
29日期函数


问题:
1date_add里面的expr type各指的是?
expr表示时间,type表示单位
2datediff是谁减谁?
是前面的减去后面的差值
3curdate()和now()有什么区别?

30流程函数
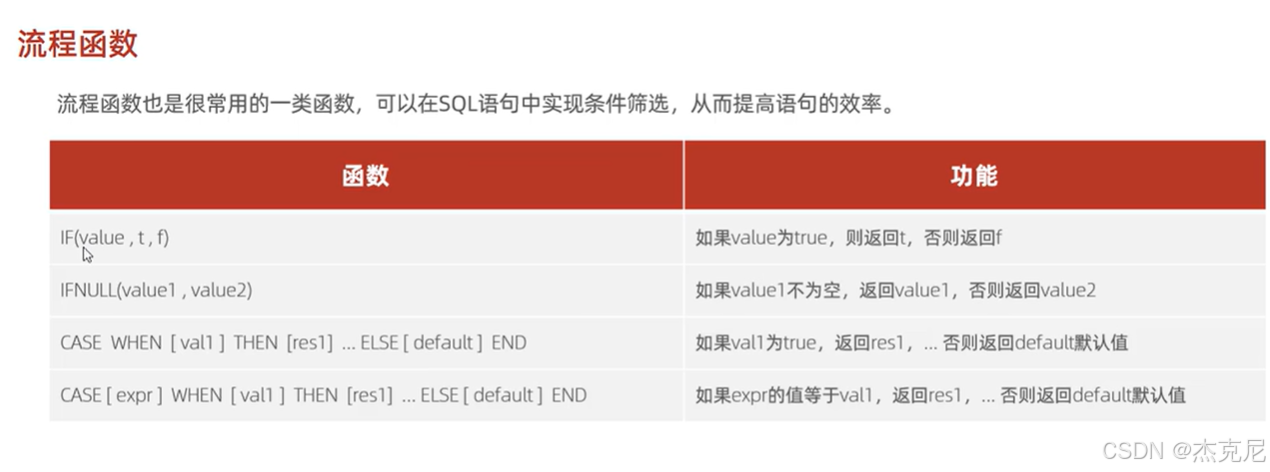



31函数小结


问题:
数值函数全部忘记?
日期函数里面的dateadd忘记?
32约束-概述




问题:
怎么设置自动增长?
auto_increment
33演示
32第二张图片里的案例实现

34外键约束


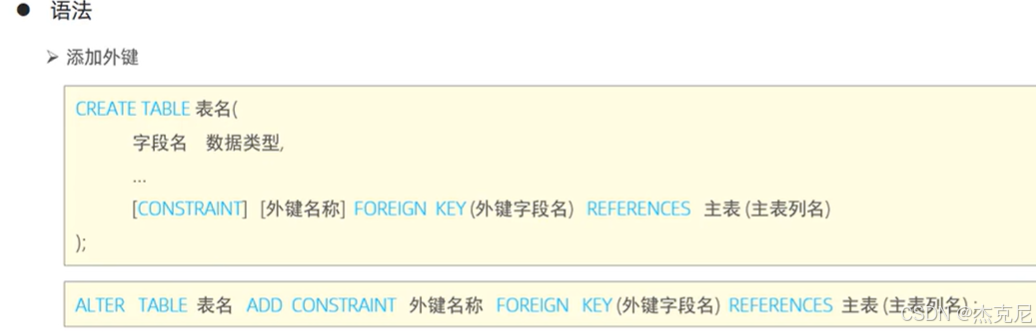
35外键删除更新行为

问题:
这些约束行为应该加在哪里?
加在有外键的位置,就是哪个表需要关联别人的字段就是加在哪里
36小结

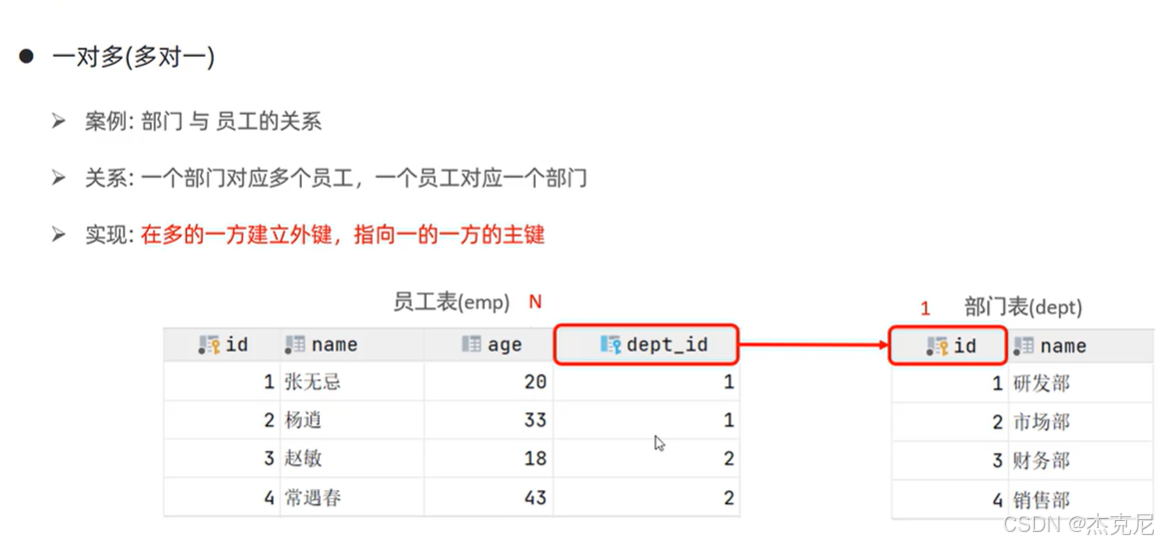
37多表查询-多表关系介绍

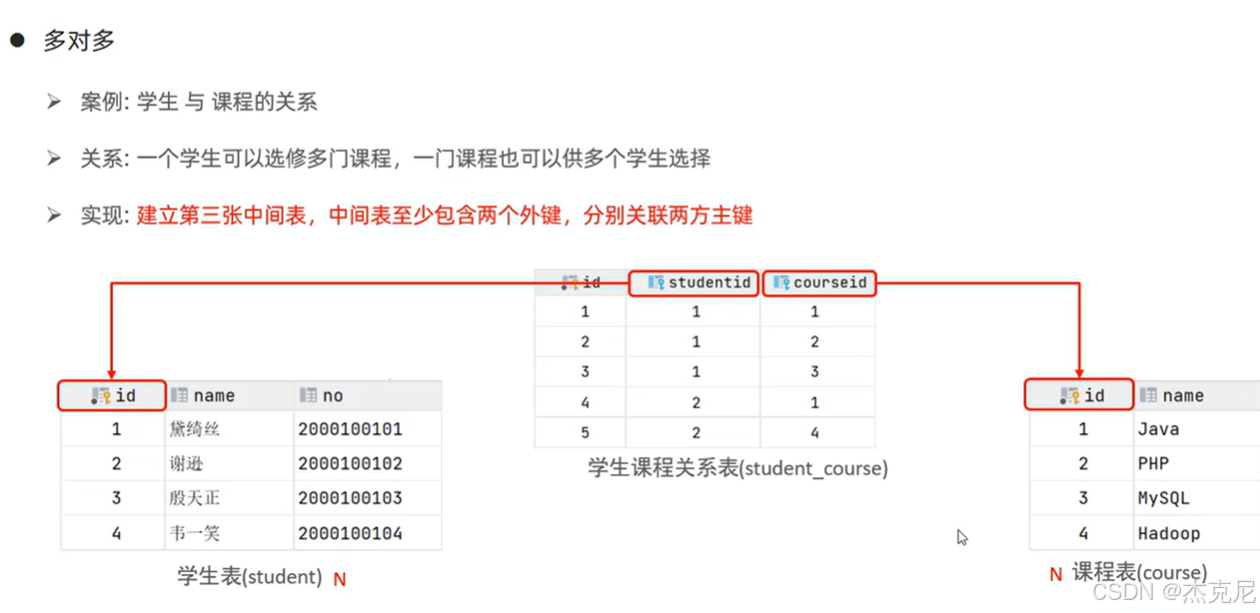
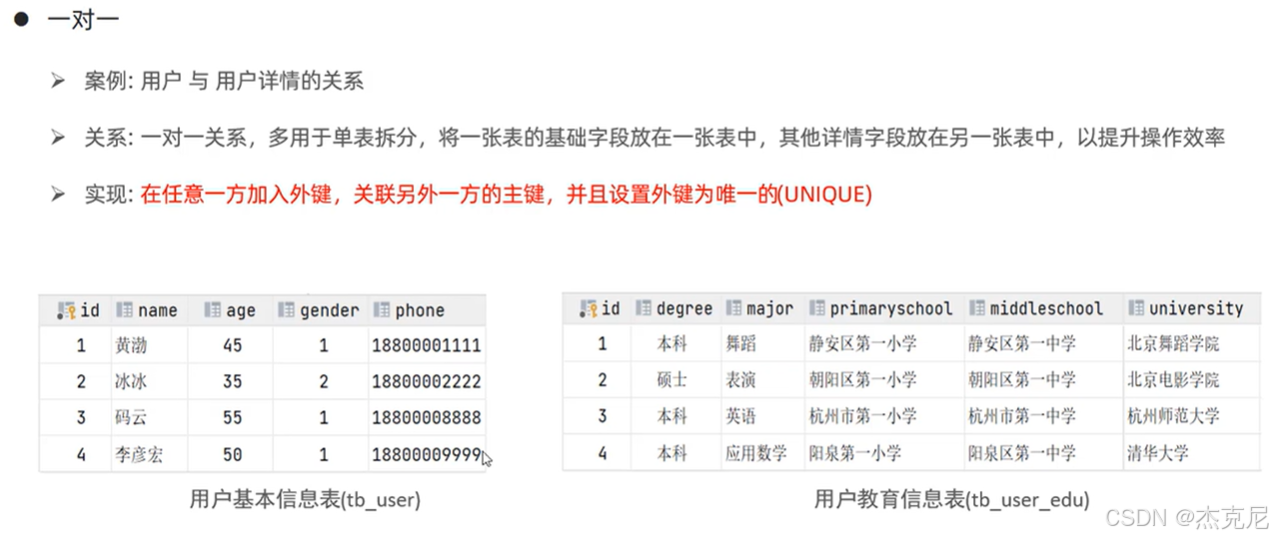
38概述

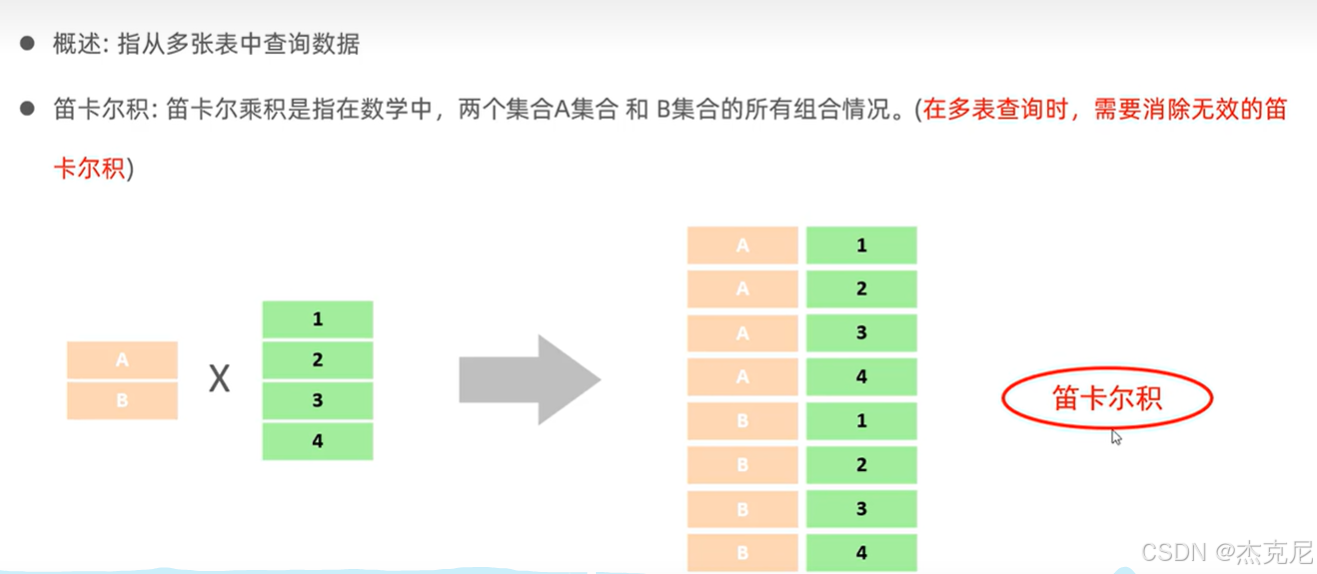
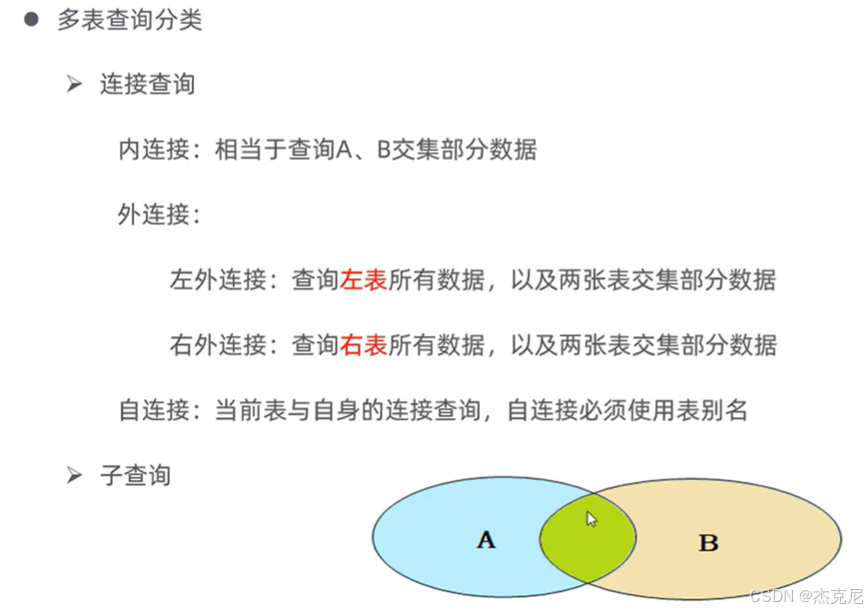
39内连接

问题:
起别名之后后面的还能用原名吗?

根据执行顺序,前面起了别名之后后面只能用它的别名了
40外连接

问题:
左外连接怎么写?以及包含的范围?
left outer join on 包含的范围是左侧所有以及左侧和右侧共有的(共有的主要是涉及左有右侧为null的情况)
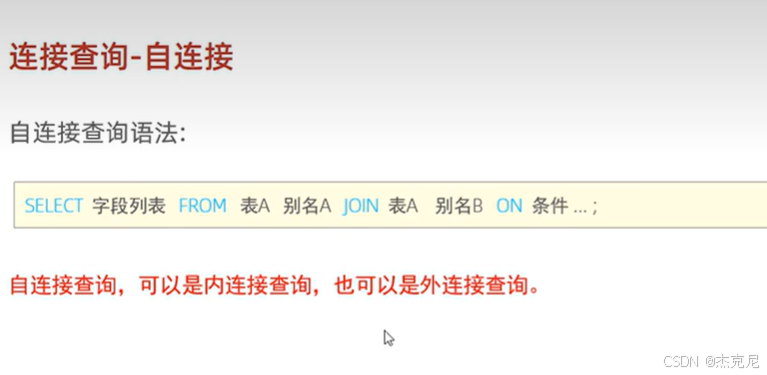
41自连接
42联合查询union

问题:
怎么合并的?与之前在where上or的区别?
UNION:合并后自动去重(会对结果集做唯一性校验,性能略低);UNION ALL:直接合并,保留所有重复记录(性能更高,是常用方式)。
前者是多表查询后者是单表查询
43子查询介绍

44标量子查询

45列子查询
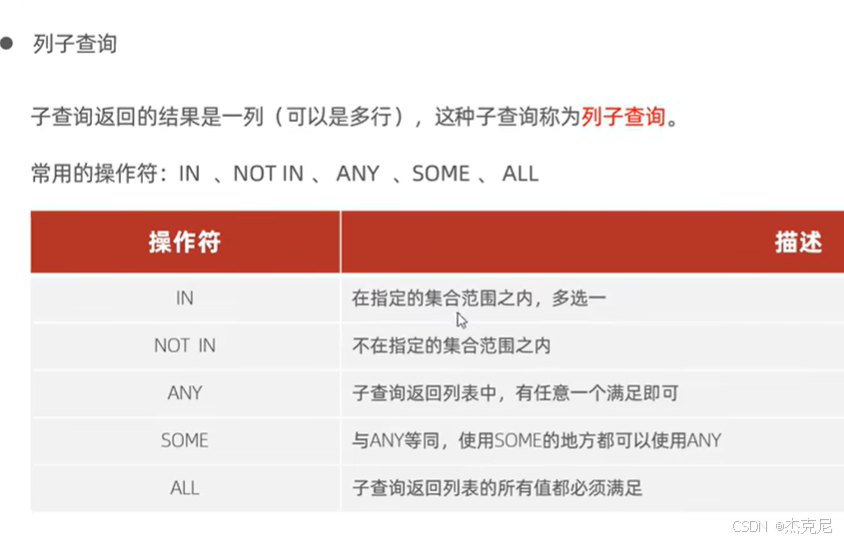

46行子查询


47表子查询

48练习1

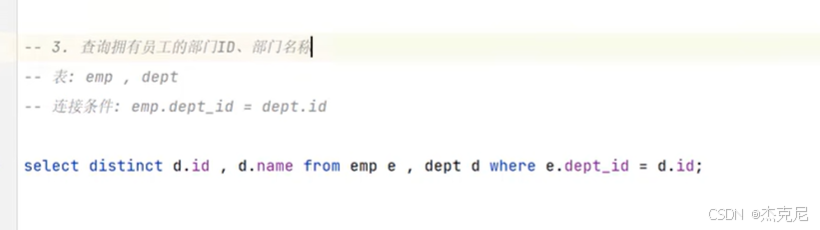
49练习2
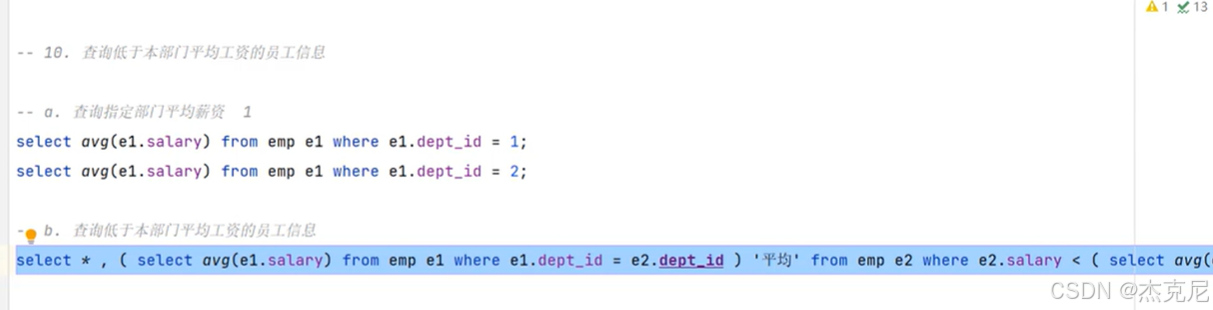
50多表查询-小结

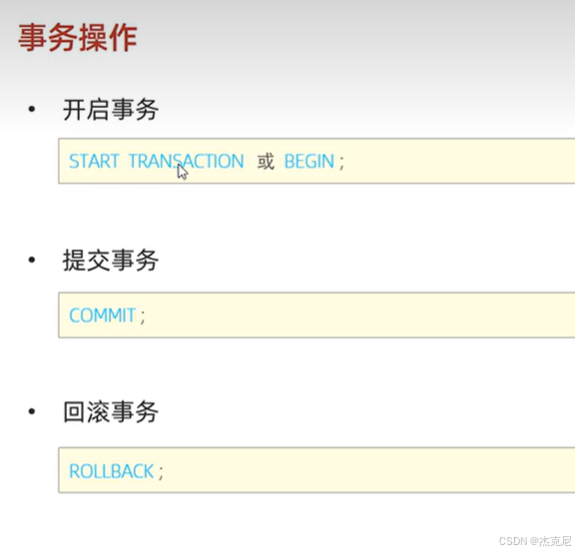
51事物-简介

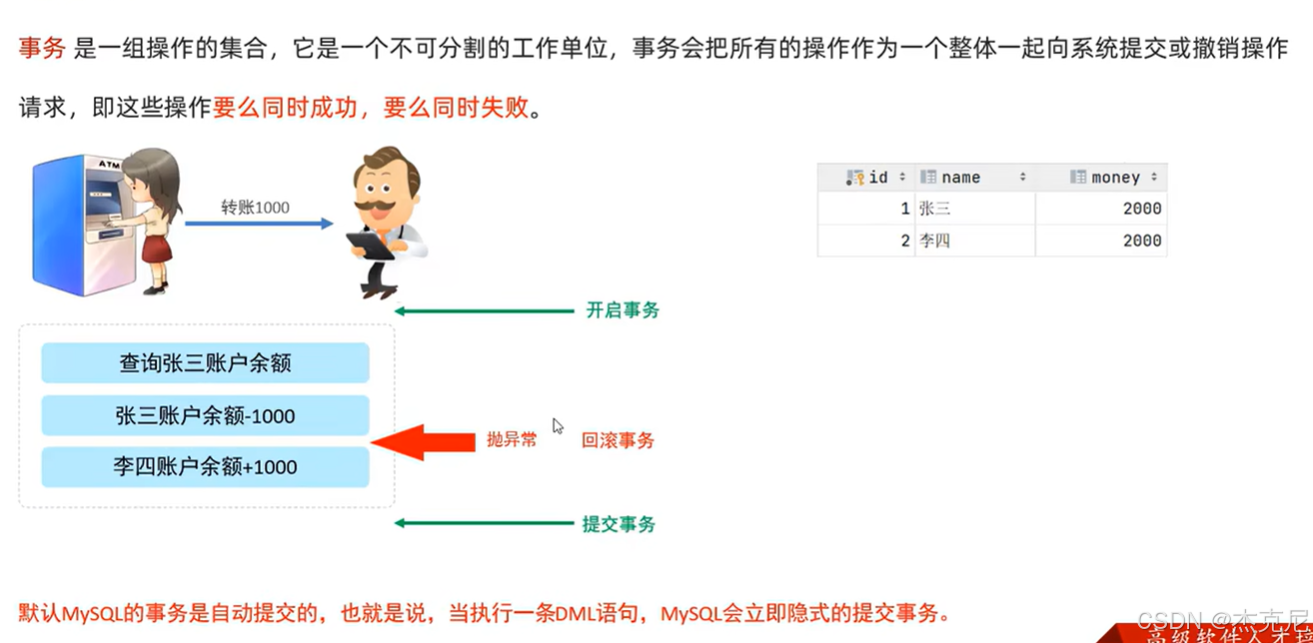
52操作演示

53四大特性ACID

问题:
让你解释这四个特性(ACID)?
原子性:事务是不可分割的最小操作单元,要么全部成功,要么全部失败
一致性:事务完成时,必须使所有的数据保持一致状态
隔离性:数据库系统提供隔离机制o,保证事务在不受外部并发操作影响的独立环境下运行
持久性:事务一旦提交或者回滚,它对数据库中的数据的改变就是永久的
54并发事物问题

55并发事物演示及隔离级别
问题:
一图中的session和global是对什么进行限制的?
ESSION和GLOBAL是作用范围的限定词,决定隔离级别生效的范围:
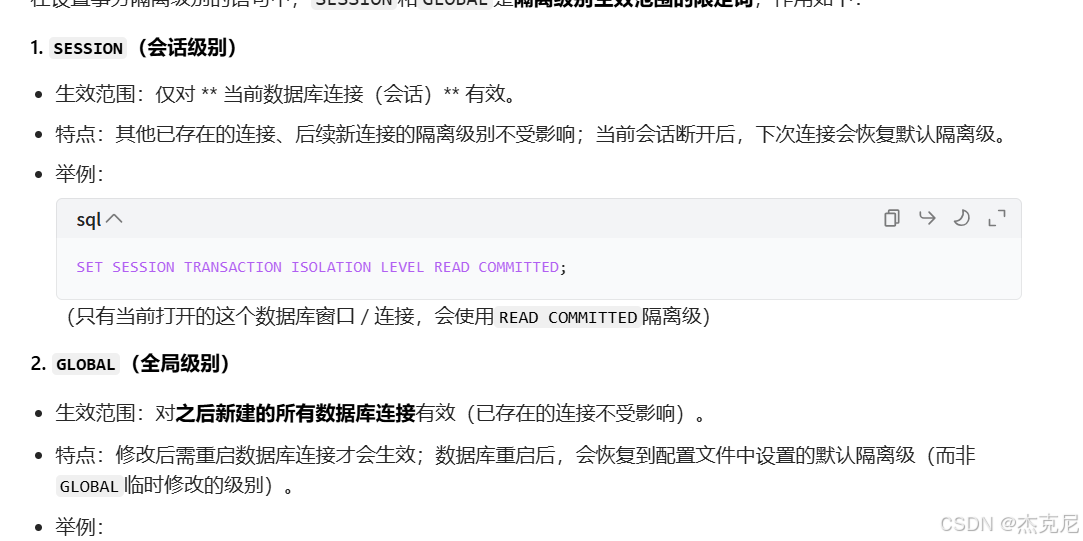
但是只要数据库重启,这两个session,global设置的就会格式化,重新回到默认形式
56事务小结

57基础篇总结
问题:
这里再给大家留一个问题,真实项目中,我们的数据库如何设计?具体,想做一个学校教务管理系统,学校教务的分学生和职工端,职工端肯定有层级部分划分,那么其数据库该怎么设计?
58深度总结
如果真的理解上面内容,那下面详解可以跳过了
从零到一:MySQL 核心知识点全解析(基础篇)
引言
MySQL 作为目前最流行的开源关系型数据库,是后端开发、数据存储领域的 "必备技能"。本文将围绕 MySQL 基础篇的核心知识点(含数据类型、SQL 语法、事务、多表查询等)展开,结合实际场景与常见问题,帮你从入门到精通 MySQL 基础。
一、数据库与 MySQL 基础
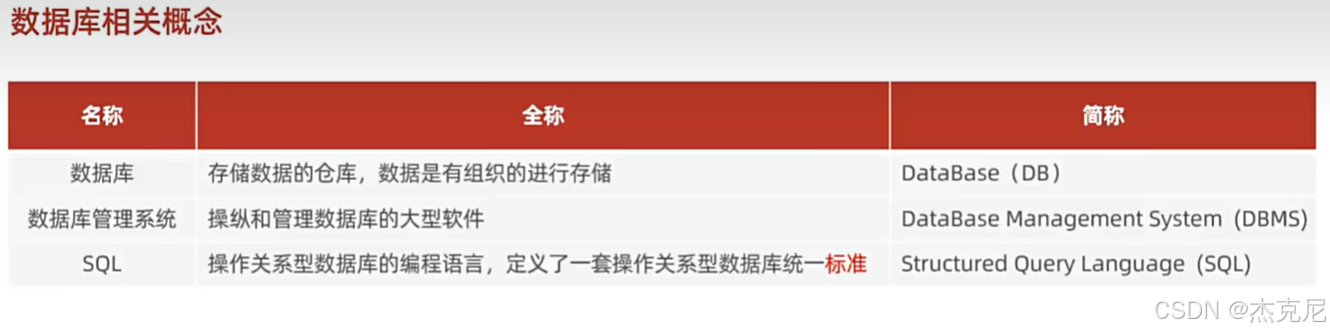
- 数据库相关概念
数据库(DB):存储数据的仓库,按一定结构组织数据(如表格形式)。
数据库管理系统(DBMS):操作和管理数据库的软件(如 MySQL、Oracle)。
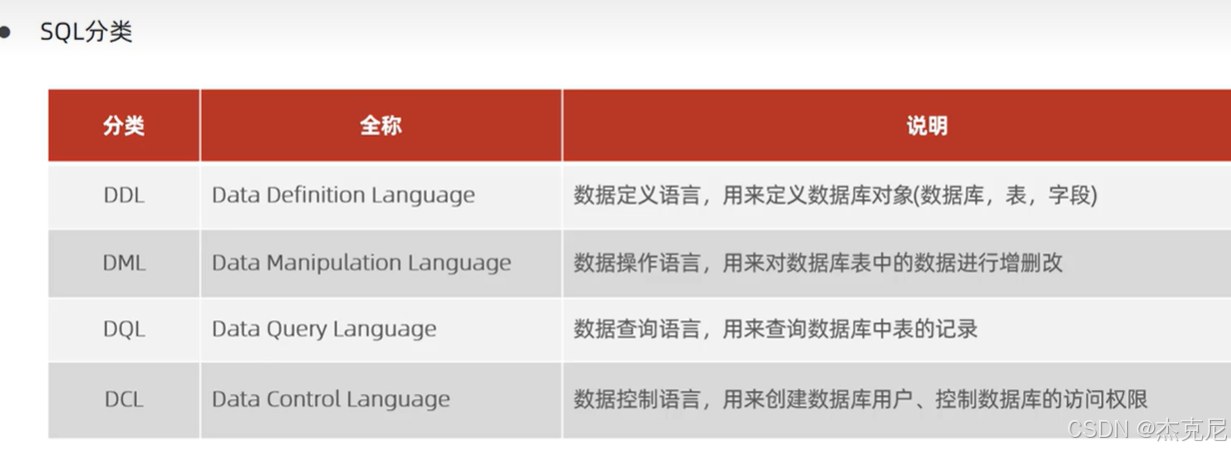
SQL(结构化查询语言):与数据库交互的标准语言,分为 DDL(定义)、DML(操作)、DQL(查询)、DCL(控制)四类。
- MySQL 安装与启动
安装:Windows 可通过官网安装包 / 压缩包部署,Linux 可通过yum/apt命令安装;注意配置环境变量、设置 root 密码。
启动 / 停止:Windows 通过服务管理器或命令net start/stop mysql;Linux 通过systemctl start/stop mysql。
二、数据库与表的核心操作
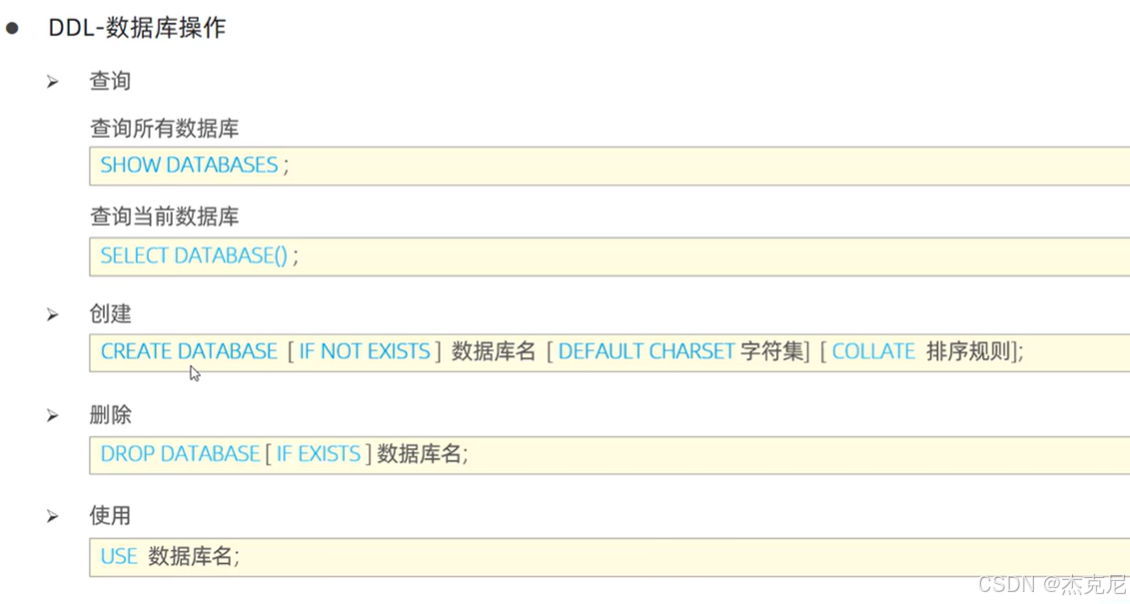
- 数据库操作
创建数据库:
sql
CREATE DATABASE IF NOT EXISTS my_db CHARACTER SET utf8mb4;
(IF NOT EXISTS避免重复创建,utf8mb4支持 emoji 等特殊字符)
查看 / 切换 / 删除数据库:
sql
SHOW DATABASES; -- 查看所有库
USE my_db; -- 切换到my_db库
DROP DATABASE IF EXISTS my_db; -- 删除库
学习重点:掌握 "避免重复操作" 的语法(IF NOT EXISTS)、字符集配置(避免乱码)。
- 表操作:创建、查询、修改、删除
(1)表的创建与查询
创建表:需指定字段名、数据类型、约束(如主键):
sql
CREATE TABLE IF NOT EXISTS user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键+自增
name VARCHAR(20) NOT NULL,
age TINYINT UNSIGNED -- 无符号整数
);
查询表:
sql
SHOW TABLES; -- 查看当前库所有表
DESC user; -- 查看表结构
(2)表的修改:ALTER TABLE
修改字段(MODIFY vs CHANGE):
MODIFY:仅修改字段类型 / 约束,不修改字段名:
sql
ALTER TABLE user MODIFY age INT UNSIGNED;
CHANGE:可同时修改字段名和类型 / 约束:
sql
ALTER TABLE user CHANGE age user_age INT UNSIGNED;
添加 / 删除字段:
sql
ALTER TABLE user ADD COLUMN email VARCHAR(50);
ALTER TABLE user DROP COLUMN email;
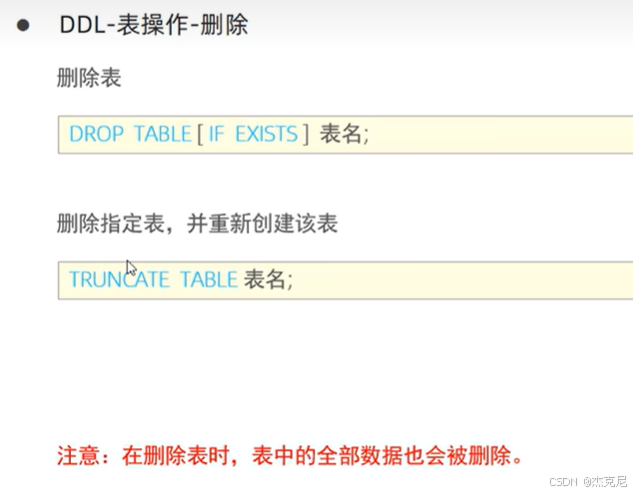
(3)表的删除
sql
DROP TABLE IF EXISTS user; -- 直接删除表
TRUNCATE TABLE user; -- 清空表数据(不可回滚)
三、MySQL 数据类型(重点与案例)
数据类型是表设计的核心,需根据业务场景选择合适类型,避免空间浪费或数据溢出。
- 整数类型
类型范围:
类型 有符号范围 无符号范围(UNSIGNED)
TINYINT -128 ~ 127 0 ~ 255
SMALLINT -32768 ~ 32767 0 ~ 65535
INT -2^31 ~ 2^31-1 0 ~ 2^32-1
BIGINT -2^63 ~ 2^63-1 0 ~ 2^64-1
记忆技巧:整数类型的 "字节数" 决定范围,如TINYINT占 1 字节(8 位),有符号时最高位是符号位,故范围是-2^(n-1) ~ 2^(n-1)-1(n 为位数);无符号则是0 ~ 2^n-1。
无符号表示:字段后加UNSIGNED,如age TINYINT UNSIGNED。
- 小数类型:DECIMAL
语法:DECIMAL(M, D),其中:
M(精度):总位数(整数 + 小数),最大 65;
D(标度):小数部分位数,最大 30 且D ≤ M。
案例:price DECIMAL(8,2)表示价格范围是0.00 ~ 999999.99(整数部分 6 位,小数 2 位)。
- 字符串类型:CHAR vs VARCHAR
CHAR(n):固定长度字符串,n 为字符数(最大 255);存储时不足 n 位会用空格填充,查询时自动去除空格。适合长度固定的场景(如手机号、身份证号)。
VARCHAR(n):可变长度字符串,n 为最大字符数(最大 65535);存储时仅占实际长度 + 1 字节(记录长度)。适合长度不固定的场景(如姓名、地址)。
对比:CHAR查询效率高但费空间,VARCHAR省空间但查询略慢。
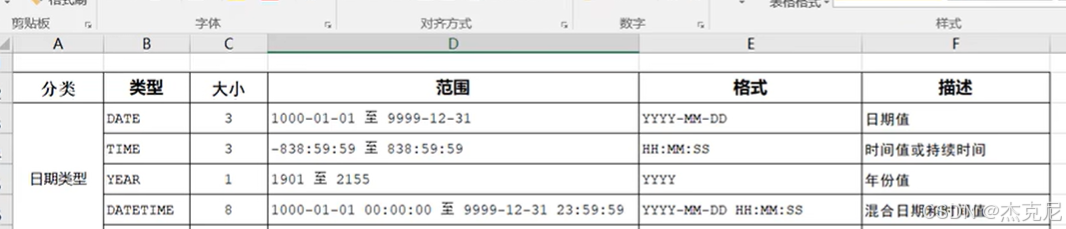
- 日期类型
常用类型:
DATE:日期(YYYY-MM-DD);
TIME:时间(HH:MM:SS);
DATETIME:日期 + 时间(YYYY-MM-DD HH:MM:SS);
TIMESTAMP:时间戳(YYYY-MM-DD HH:MM:SS),范围小(1970-2038),但会随时区自动转换。
四、DML:数据操作语言(增删改)
- 插入数据(INSERT)
基本语法:
sql
INSERT INTO user (name, age) VALUES ('张三', 20), ('李四', 22);
注意:字段顺序需与VALUES对应;若省略字段名,需按表结构顺序填写所有字段。
- 更新数据(UPDATE)
基本语法:
sql
UPDATE user SET age = 21 WHERE name = '张三';
必须加WHERE:否则会更新表中所有数据,造成数据污染!
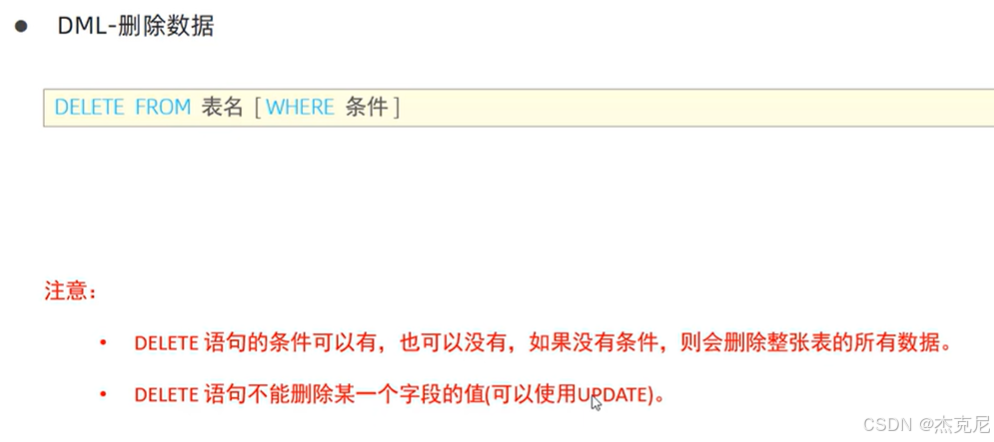
- 删除数据(DELETE)
基本语法:
sql
DELETE FROM user WHERE age > 30;
区别TRUNCATE:DELETE是 DML(可回滚),TRUNCATE是 DDL(不可回滚,效率更高)。
五、DQL:数据查询语言(核心)
查询是 MySQL 中最常用的操作,需掌握基础查询、条件查询、聚合查询、分组查询等。
- 基础查询
语法:
sql
SELECT 字段1, 字段2 AS 别名 FROM 表名;
注意:
尽量避免用*(会查询所有字段,影响效率);
AS可省略,直接写别名(如SELECT name 用户名 FROM user)。
- 条件查询(WHERE)
常用运算符:=、>、<、BETWEEN...AND、IN、LIKE(模糊查询)等。
案例:
sql
SELECT * FROM user WHERE age BETWEEN 18 AND 25; -- 年龄18-25
SELECT * FROM user WHERE name LIKE '张%'; -- 姓张的用户
- 聚合函数(作用于一列)
常用函数:
COUNT():统计行数;
SUM():求和;
AVG():求平均值;
MAX()/MIN():最大 / 最小值。
案例:
sql
SELECT COUNT(id) 总用户数, AVG(age) 平均年龄 FROM user;
- 分组查询(GROUP BY)
语法:
sql
SELECT 分组字段, 聚合函数 FROM 表名 GROUP BY 分组字段 HAVING 条件;
WHERE vs HAVING:
WHERE:分组前过滤数据,不能用聚合函数;
HAVING:分组后过滤数据,可用聚合函数。
案例:
sql
-- 按性别分组,统计每组人数,只显示人数≥5的组
SELECT gender, COUNT(id) 人数 FROM user GROUP BY gender HAVING 人数 ≥ 5;
- 排序查询(ORDER BY)
语法:
sql
SELECT * FROM user ORDER BY age DESC, id ASC;
(DESC降序,ASC升序,默认升序)
- 分页查询(LIMIT)
语法:
sql
SELECT * FROM user LIMIT 起始索引, 每页显示行数;
说明:
起始索引从 0 开始(第一页是LIMIT 0, 10);
"查询记录数" 指每页显示的行数,不是总数。
案例:
sql
SELECT * FROM user LIMIT 10, 10; -- 第2页,显示10条
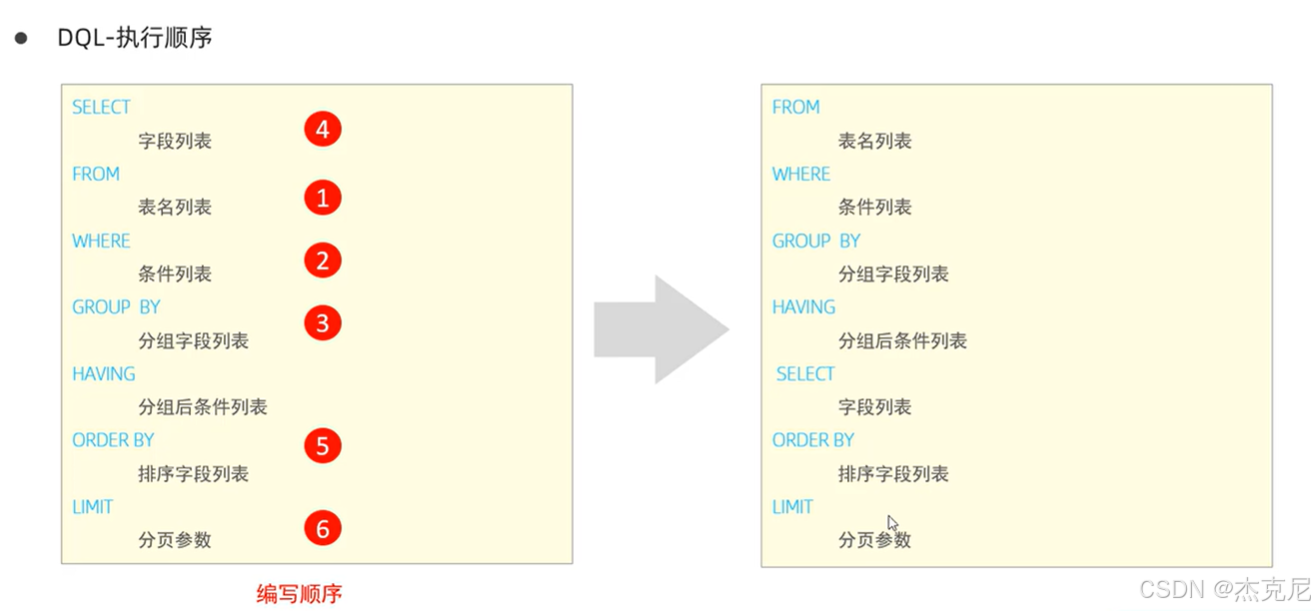
- DQL 执行顺序
MySQL 执行 DQL 的顺序是:FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
验证方法:通过别名验证(SELECT中定义的别名,WHERE不能用,但ORDER BY可以用):
sql
-- 正确:ORDER BY可用SELECT的别名
SELECT name, age 年龄 FROM user ORDER BY 年龄;
-- 错误:WHERE不能用SELECT的别名
SELECT name, age 年龄 FROM user WHERE 年龄 > 20;
六、约束:保证数据完整性
约束是表设计中用于限制字段值的规则,常见约束有:
- 主键约束(PRIMARY KEY)
唯一标识表中每行数据,要求非空且唯一;
通常用INT类型 +AUTO_INCREMENT(自动增长):
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键+自增
name VARCHAR(20)
);
自动增长设置:字段后加AUTO_INCREMENT,需配合主键 / 唯一约束使用。
- 外键约束(FOREIGN KEY)
用于关联两张表,保证数据的一致性和完整性;
语法:
sql
CREATE TABLE order (
order_id INT PRIMARY KEY,
user_id INT,
FOREIGN KEY (user_id) REFERENCES user(id)
);
外键的删除 / 更新行为:
ON DELETE CASCADE:主表记录删除时,从表关联记录也删除;
ON UPDATE SET NULL:主表主键更新时,从表外键设为 NULL;
这些行为需加在从表的外键定义中。
七、多表查询
当数据分散在多张表时,需通过多表查询获取关联数据。
- 多表关系
一对一:如用户表和用户详情表(通过主键关联);
一对多:如用户表和订单表(用户 id 作为订单表的外键);
多对多:如学生表和课程表(需中间表存关联关系)。
- 内连接(INNER JOIN)
只查询两张表中匹配关联条件的记录;
语法:
sql
SELECT u.name, o.order_id
FROM user u INNER JOIN `order` o
ON u.id = o.user_id;
别名:表名起别名后,后续只能用别名(不能用原名)。
- 外连接
左外连接(LEFT JOIN):查询左表所有记录,右表匹配不到则显示 NULL;
sql
SELECT u.name, o.order_id
FROM user u LEFT JOIN `order` o
ON u.id = o.user_id;
(包含所有用户,即使没有订单)
右外连接(RIGHT JOIN):与左外连接相反,包含右表所有记录。
- 自连接
同一张表视为两张表,查询表内关联数据(如员工表查 "员工 - 上级" 关系);
语法:
sql
FROM emp e JOIN emp m
ON e.manager_id = m.id;
- 联合查询(UNION)
合并多个查询的结果集(要求字段数、类型一致);
区别WHERE/ON:WHERE/ON是 "筛选关联数据",UNION是 "合并多个查询结果";
语法:
sql
SELECT name FROM user WHERE age < 20
UNION
SELECT name FROM user WHERE age > 30;
- 子查询
嵌套在其他查询中的查询,根据结果类型分为:
标量子查询:返回单个值(如SELECT name FROM user WHERE id = (SELECT user_id FROM order WHERE order_id = 1001));
列子查询:返回一列值(如SELECT name FROM user WHERE id IN (SELECT user_id FROM order));
表子查询:返回一张表(如SELECT * FROM (SELECT * FROM user WHERE age > 20) t)。
八、事务:保证数据一致性
- 事务简介
事务是一组 SQL 操作的集合,要么全部执行成功,要么全部回滚(避免部分执行导致数据异常)。
- 事务的四大特性(ACID)
原子性(Atomicity):事务是不可分割的最小单元,要么全执行,要么全不执行;
一致性(Consistency):事务执行前后,数据的完整性约束不变(如转账前后总金额不变);
隔离性(Isolation):多个事务同时执行时,相互不干扰;
持久性(Durability):事务提交后,数据永久保存到数据库。
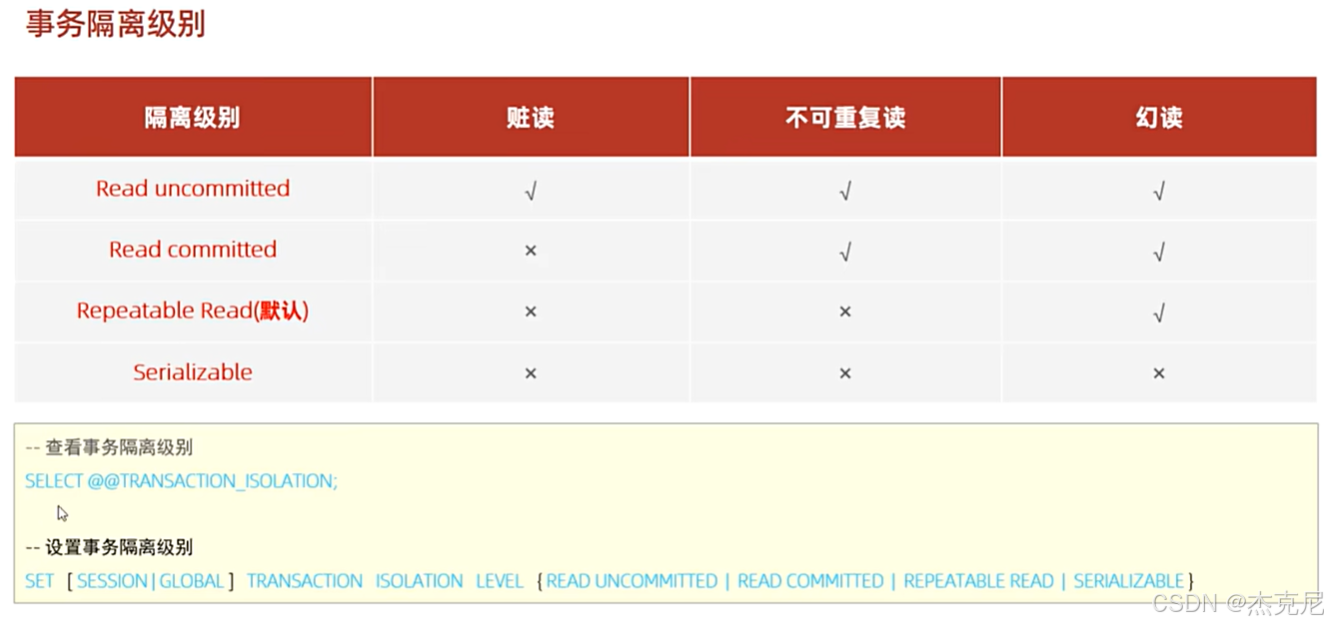
- 并发事务问题
脏读:一个事务读取到另一个事务未提交的数据;
不可重复读:一个事务内多次读取同一数据,结果不一致(被其他事务修改并提交);
幻读:一个事务内多次查询,结果集行数不一致(被其他事务插入 / 删除并提交)。
- 事务隔离级别
MySQL 默认隔离级别是REPEATABLE READ,不同级别解决的并发问题不同:
隔离级别 脏读 不可重复读 幻读
READ UNCOMMITTED ✅ ✅ ✅
READ COMMITTED ❌ ✅ ✅
REPEATABLE READ ❌ ❌ ✅
SERIALIZABLE ❌ ❌ ❌
- 隔离级别的设置与查看
查看隔离级别:
sql
SELECT @@TRANSACTION_ISOLATION;
设置隔离级别:
sql
-- SESSION:仅当前连接生效
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- GLOBAL:后续新连接生效(数据库重启后失效)
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
九、DCL:用户管理与权限控制
- 用户管理
创建用户:
sql
CREATE USER 'test'@'localhost' IDENTIFIED BY '123456';
(localhost表示仅本地访问,%表示允许远程访问)
主机名:常见值有localhost(本地)、%(任意主机)、具体 IP(如192.168.1.1)。
- 权限控制
授予权限:
sql
GRANT SELECT, INSERT ON my_db.user TO 'test'@'localhost';
撤销权限:
sql
REVOKE INSERT ON my_db.user FROM 'test'@'localhost';
查看权限:
sql
SHOW GRANTS FOR 'test'@'localhost';
十、函数:字符串、数值、日期函数
- 字符串函数
常用函数:CONCAT()(拼接)、LENGTH()(长度)、SUBSTRING()(截取)等;
显示函数结果:直接在SELECT中调用函数即可:
sql
SELECT CONCAT('Hello', ' ', 'MySQL') 结果;
- 数值函数
常用函数:ROUND()(四舍五入)、RAND()(随机数)等;
RAND()范围:生成0 ≤ 随机数 < 1的浮点数;
记忆技巧:无需死记所有函数,常用函数(如ROUND、SUM)需掌握,其他可查文档。
- 日期函数
常用函数:DATE_ADD()(日期增减)、DATEDIFF()(日期差)等;
DATE_ADD的expr type:指增减的单位,如DAY(天)、MONTH(月):
sql
SELECT DATE_ADD(NOW(), INTERVAL 7 DAY); -- 当前日期+7天
DATEDIFF的计算逻辑:DATEDIFF(日期1, 日期2) = 日期 1 - 日期 2(结果为天数)。
总结
MySQL 基础篇涵盖了数据库操作、表设计、SQL 语法、事务、多表查询等核心内容,是后续进阶(如索引、优化)的基础。学习时需结合案例练习,重点掌握 "表设计(数据类型 + 约束)""DQL 查询(尤其是多表查询)""事务隔离级别" 等高频知识点,才能在实际开发中高效使用 MySQL。