检索增强生成(RAG)是一种混合人工智能架构,旨在通过整合外部、实时的数据源来增强大型语言模型(LLM)生成响应的准确性和相关性。RAG 的核心价值在于,它将 LLM 从一个依赖于静态训练数据的"闭卷知识库"转变为一个"开卷推理引擎"。
一、RAG 核心概念与价值
RAG 解决的核心问题
传统的 LLM 主要依赖训练期间编码的知识,这导致了几个固有限制:知识截止、领域特定知识不足以及容易产生幻觉(即模型捏造出看似合理但事实错误的信息)。
RAG 通过以下方式解决了这些问题:
- 降低幻觉风险: RAG 通过提供从可靠来源检索到的事实上下文来锚定(Grounding)模型的输出,从而降低了幻觉的可能性。
- 知识即时更新: RAG 将知识与模型参数解耦,允许组织通过自动化索引持续更新知识库,而无需承担重新训练或微调大型模型的高昂成本和时间。
- 提高透明度: 好的 RAG 系统能够为生成的答案提供引用(Citations),增强结果的可信度和可解释性。
RAG 与 Fine-tuning 的对比
| 特性 | Fine-Tuning(微调) | Retrieval-Augmented Generation (RAG) |
|---|---|---|
| 知识更新 | 需要模型重新训练/微调周期 | 即时;更新向量存储/索引 |
| 幻觉风险 | 高;模型依赖内部"概率性"记忆 | 较低;基于检索到的事实上下文提供基础 |
| 透明度 | 低;"黑箱"内部权重 | 高;提供对源文档的引用 |
| 成本 | 高(GPU、数据准备、专家时间) | 低到中等(索引、向量存储) |
| 领域特异性 | 良好,但知识可能过时 | 优秀;始终使用最新数据 |
二、基础 RAG 管道架构
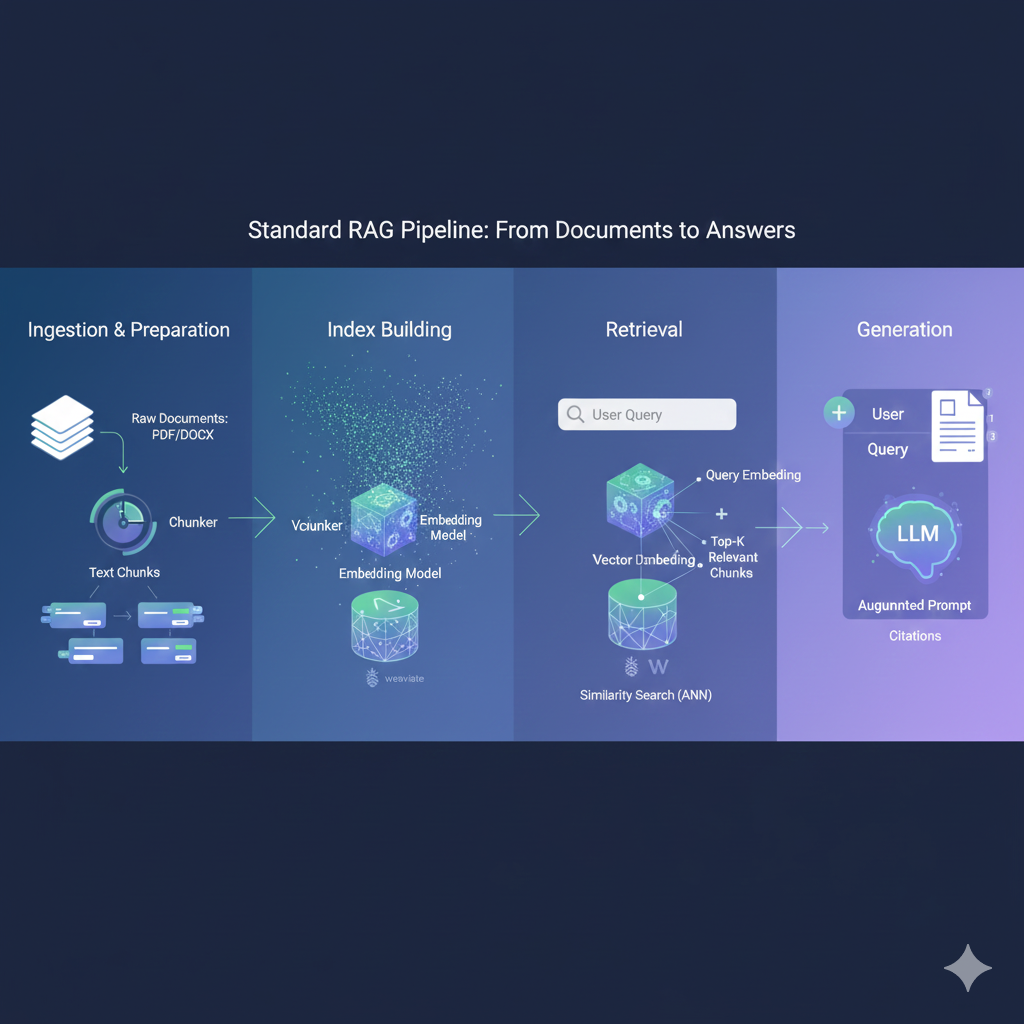
一个标准的 RAG 系统涉及四个主要阶段:内容摄取(数据准备)、索引构建、检索和生成。
阶段 1:内容摄取与准备(Ingestion)
这是 RAG 编程中至关重要的第一步,旨在将原始的非结构化文本转化为适合高维向量搜索的格式。
1. 文档分块(Chunking)
LLM 具有有限的上下文窗口 (Context Window),而知识库往往是巨大的。分块(Chunking)是将长文档分割成更小、可管理的片段,使每个片段捕获一个明确的语义想法,以适应处理约束。
分块的质量直接决定了检索的准确性和答案的清晰度。如果分块太长,可能会稀释上下文(Context Dilution);如果太短,关键信息可能会被分散(Information Fragmentation)。
| 策略 | 机制描述 | 理想用途 | 核心挑战 |
|---|---|---|---|
| 固定长度分块 (Fixed-Length) | 基于字符、词语或 Token 数量进行精确分割。 | 结构化数据(如 FAQ)或代码。 | 经常在句子或语义中间中断。 |
| 递归字符分割 (Recursive Character) | 使用优先级分隔符(如换行符、句号)尝试保留文档的自然结构。 | 通用文档(PDF、Markdown)。 | 需要针对特定内容进行分隔符优化。 |
| 滑动窗口分块 (Sliding Window) | 在相邻分块之间创建重叠区域,以保留上下文并防止信息丢失。 | 密集型参考文本,如学术论文。 | 增加索引大小和存储需求。 |
| 句子分块 (Sentence-Based) | 确保每个块包含完整的句子。 | 对话式 AI 和聊天机器人。 | 块大小不一致,可能影响检索效率。 |
| 语义分块 (Semantic) | 基于句子间的语义相似性进行分组,以保持主题连贯性。 | 复杂的法律或医疗文本。 | 计算成本高,需要 NLP 处理。 |
通常,对于大多数生产 RAG 系统,使用 400-800 个 Token 的递归分块(Recursive Chunking)和 20% 的重叠(Overlap)可以提供性能和效率的最佳平衡。
2. 元数据增强(Metadata Augmentation)
为每个块附加结构化信息(如文档来源、作者、时间戳、章节标题)称为元数据增强。元数据在生产环境中至关重要,它允许系统执行过滤,例如仅搜索 2024 年的财务报告或限制对敏感信息的访问。元数据过滤是一种低成本、高效率的技术,因为它不需要进行大量计算。
3. 嵌入与向量化(Embedding)
使用选定的嵌入模型 (Embedding Model)将每个文本块转换为高维数值表示,即嵌入(Embeddings)。通常会选择针对搜索优化的模型,因为嵌入模型的选择直接影响检索质量。
阶段 2 & 3:索引构建与检索(Indexing & Retrieval)
1. 向量数据库(Vector Database)
向量数据库是 RAG 系统的"引擎室",它存储嵌入并支持快速检索与查询向量在语义上相关的文档(即近似最近邻搜索,ANN)。
主流向量数据库对比(2025 年快照):
| 数据库 | 架构特点 | 最佳用途 | 突出能力 |
|---|---|---|---|
| Pinecone | 托管式,Serverless | 追求零运维、全球规模的商业 AI SaaS | 自动扩展、集成推理和重排序 |
| Milvus | 开源,分布式 | 拥有数据工程团队的数十亿级向量极大规模 | 为大规模吞吐量优化 |
| Weaviate | 开源 + 托管 | 需要混合搜索(向量 + 关键词)和模块化 | 原生支持混合搜索,灵活的模式设计 |
| Qdrant | 开源 + 托管 | 成本敏感、注重性能和过滤的中等规模项目 | 高效的内存使用和强大的过滤功能 |
| Chroma | 轻量级,开源 | 原型设计、小型/内部应用程序 | 开发者优先,本地部署友好 |
核心权衡: 托管服务(如 Pinecone)牺牲了成本控制,换来了运维便利性;自托管/开源方案(如 Milvus)提供了对性能和成本的最大控制权,但需要更专业的运维团队。
2. 检索流程(Retrieval Flow)
当用户发出查询时,RAG 系统在运行时执行以下步骤:
- 查询嵌入: 使用与索引文档相同的嵌入模型将用户查询转换为向量。
- 向量搜索: 在向量数据库中执行相似性搜索(如余弦相似度),找到与查询向量最近的 Top-K 结果。
- 上下文提取: 检索这些 Top-K 向量对应的原始文本块和元数据。
阶段 4:生成(Generation)
在检索到最相关的上下文后,系统将这些信息与原始用户查询和提示词模板(Prompt Template)结合,构建一个增强后的提示(Augmented Prompt),然后发送给 LLM。
RAG 提示词示例:
一个 RAG 提示词通常会指示 LLM 仅根据提供的上下文来回答问题,并在找不到证据时拒绝回答("I don't know")。
## 提示词模板(Prompt Template)示例
"""
你是一个乐于助人的助手。请仅根据以下提供的上下文来回答问题。
如果上下文中不包含回答问题所需的信息,请明确说明"我不知道"。
上下文:
{retrieved_context}
问题: {user_question}
答案:
"""三、基础 RAG 管道实现(使用 LlamaIndex 框架)
RAG 编程需要一个编排层(Orchestration Layer)来管理查询的生命周期,从初始提示到最终生成。以下是使用 LlamaIndex 框架实现一个基本 RAG 管道的步骤和代码片段:
3.1 准备环境与模型
首先,安装必要的库并定义要使用的 LLM 和嵌入模型。
python
# 安装所需的 Python 包
!pip install llama-index-core llama-index-embeddings-openai llama-index-llms-openai python-dotenv
import os
from dotenv import load_dotenv, find_dotenv
# 确保API密钥已加载到环境变量中
load_dotenv(find_dotenv())
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.settings import Settings
# 步骤 1: 定义 LLM 和嵌入模型
# 使用全局设置对象来定义模型。
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1) # LLM用于生成最终答案
Settings.embed_model = OpenAIEmbedding() # Embedding model用于生成向量嵌入3.2 数据加载与分块
加载原始文档,并使用节点解析器(Node Parser)将其分割成可管理的块。
python
# 步骤 2: 加载数据
from llama_index.core import SimpleDirectoryReader
# 假设文档位于 'data' 文件夹中
documents = SimpleDirectoryReader(
input_files=["./data/paul_graham_essay.txt"]
).load_data()
# 步骤 3: 文档分块(创建节点)
from llama_index.core.node_parser import SimpleNodeParser
# 使用 SimpleNodeParser 定义分块大小
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024)
# 从文档中提取节点(即分块)
nodes = node_parser.get_nodes_from_documents(documents) 3.3 索引构建(使用向量存储)
将分块(节点)转换为向量,并存储到向量数据库中。以下示例使用标准的 VectorStoreIndex 来处理节点:
python
# 步骤 4: 构建索引
from llama_index.core import VectorStoreIndex
# VectorStoreIndex 负责将文档分块并编码为嵌入
index = VectorStoreIndex(
nodes,
# 在生产环境中,这里应传入用于连接外部向量数据库的 storage_context
)3.4 检索与查询
设置查询引擎(Query Engine),它结合了检索和生成两个步骤,并运行用户的查询。
python
# 步骤 5: 设置查询引擎
# QueryEngine 类包含了检索器和生成器,用于促进检索和生成步骤
query_engine = index.as_query_engine()
# 步骤 6: 运行 RAG 查询
question = "What is the key idea about task decomposition in this essay?"
response = query_engine.query(question)
# 打印 LLM 生成的答案
print(response)四、高级 RAG 架构和优化原理
基础 RAG(Naive RAG)在处理复杂查询或应对嘈杂结果时往往表现不佳,因此需要引入高级 RAG 技术来改进。
4.1 核心优化阶段
高级 RAG 的优化通常围绕三个阶段展开:
| 阶段 | 核心挑战 | 进阶技术示例 |
|---|---|---|
| 预检索(Pre-Retrieval) | 分块不佳、查询意图模糊、数据噪声。 | 语义分块、元数据过滤、假设文档嵌入(HyDE)、查询分解。 |
| 检索(Retrieval) | 向量搜索可能错过精确关键词。 | 混合检索(Vector + Keyword)、知识图谱检索(GraphRAG)。 |
| 后检索(Post-Retrieval) | 上下文冗余、检索结果不相关。 | 重排序(Reranking)、上下文压缩(Context Distillation)、纠错 RAG (CRAG)。 |
4.2 增强检索:混合搜索(Hybrid Search)
纯向量搜索擅长语义匹配,但可能错过精确的专有名词或代码片段。混合搜索 结合了向量搜索 (基于语义相似性)和关键词搜索(基于 BM25 等词汇匹配)的优势。
检索结果通常使用**倒数排名融合(RRF)**等算法进行合并,以平衡两种方法的排名得分,从而将语义和关键词匹配结合起来检索结果。
代码片段:混合搜索(基于 LlamaIndex)
如果底层向量数据库(如 Weaviate)支持混合搜索,可以在查询引擎中设置 vector_store_query_mode="hybrid" 和 alpha 参数来开启混合检索。
python
# 假设您的向量数据库支持混合搜索(例如 Weaviate 或 Meilisearch)
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid",
alpha=0.5, # 0.5 表示平均分配向量搜索和关键词搜索的权重
)
# 执行查询时将结合语义和关键词匹配来检索结果。
response = query_engine.query("What are the side effects of sertraline?") 4.3 后检索优化:重排序(Reranking)
重排序使用 Cross-Encoder 等更精确的模型对初次检索(Top-K)结果进行重新评分和排序,从而确保发送给 LLM 的最终上下文是质量最高的。重排序通常能带来 20--40% 的精度提升。
代码片段:重排序(基于 LlamaIndex)
实现重排序需要定义一个重排序模型,并将其添加为查询引擎的节点后处理器(Node Postprocessor)。
python
# 安装所需的包
# !pip install torch sentence-transformers
from llama_index.core.postprocessor import SentenceTransformerRerank
# 步骤 1: 定义重排序模型
rerank = SentenceTransformerRerank(
top_n=2,
model="BAAI/bge-reranker-base"
)
# 步骤 2: 将重排序器添加到查询引擎
# 提高 similarity_top_k 以检索更多候选文档,然后由重排序器筛选出 top_n
query_engine = index.as_query_engine(
similarity_top_k=6,
node_postprocessors=[rerank],
)
# 此时,检索器将先获取 Top-6 结果,然后重排序模型从中挑选出最相关的 Top-2。4.4 知识图谱增强检索(GraphRAG)
GraphRAG 通过将知识表示为节点(实体)和边(关系)的知识图谱结构,解决了向量 RAG 无法捕捉实体之间复杂关系的问题。
- 工作原理: 在查询时,系统不只依赖语义相似性,还会利用图遍历(Graph Traversal)或图查询语言(如 Cypher)来提取精确的、跨文档的、关系丰富的子图作为上下文。
- 优势: 知识图谱支持多跳问题 (Multi-hop Questions),即需要连接多个事实才能回答的复杂推理,并提供了可解释性,因为检索路径是可审计的。GraphRAG 在多步推理任务中报告的准确率增益高达 35%。
- 挑战: 构建和维护知识图谱的初始成本高,且比纯向量搜索更复杂。
4.5 Agentic RAG 与自主工作流
Agentic RAG 代表了 RAG 架构的下一代演进,将自主决策组件(Agent)与 RAG 集成。Agentic RAG 不遵循固定的检索-生成流程,而是利用 LLM 实时规划、检索、评估和细化信息。
- Agent 核心组件:
- 编排层(Orchestration Layer): 中央协调器,管理 Agent 之间的通信,分配任务,并规划复杂工作流。
- 检索 Agents: 处理知识库选择、查询重新表述和结果过滤。
- 生成 Agents: 管理提示词构建、上下文整合和输出精炼。
- 专家 Agents: 拥有特定领域知识和工具(如 API 或计算器)。
- 工作流模式: Agents 可以进行规划 (将复杂任务分解为子步骤)、工具使用 (动态选择外部工具)和反射(自我评估检索结果和生成响应的质量)。
- Agentic 工作流的演变: 经历了从固定决策图(Fixed-Decision Graphs)到自主 AI Agents,再到结合人类设计流程的 Agentic Workflows,并最终迈向自动化流程生成(Automated Flow Generation)的四个阶段。