文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
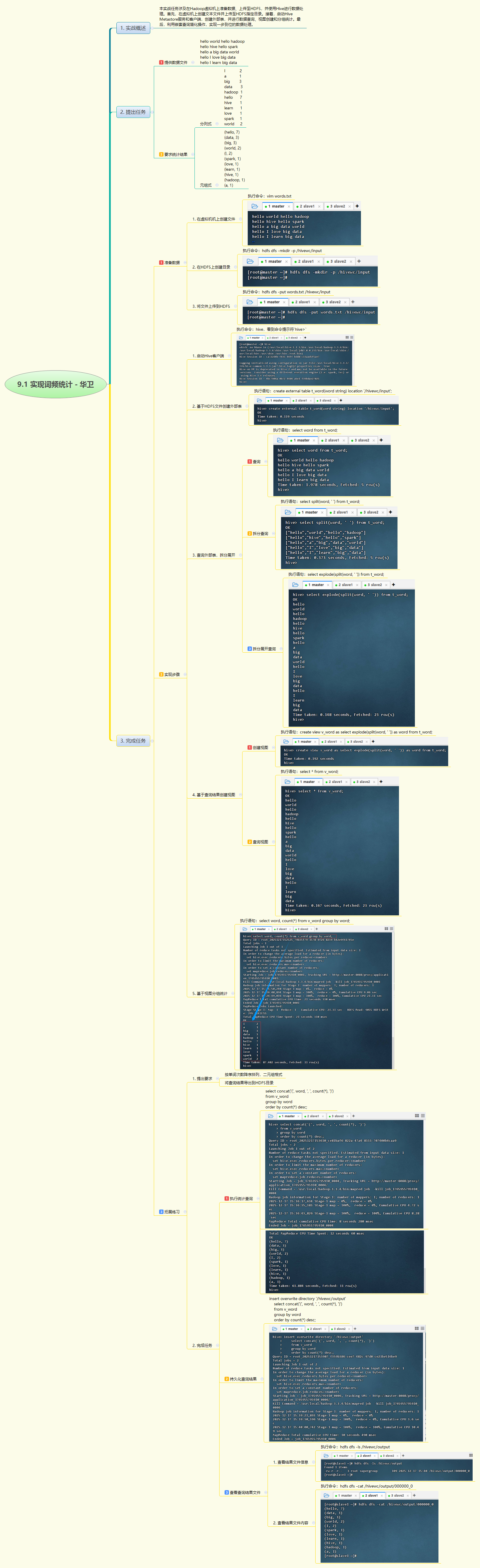
- 本实战在Hadoop环境中完成词频统计任务:将文本数据上传至HDFS,通过Hive创建外部表,利用
split和explode函数拆分单词,建立视图简化操作,最终实现按词频分组统计,并以元组格式导出结果到HDFS,完整展示了从数据准备到分析输出的Hive处理流程。
2. 实战步骤
3. 实战总结
- 本次实战系统演练了基于Hive的大数据词频统计全过程。首先将本地文本文件上传至HDFS,创建外部表关联数据;通过
split按空格切分句子、explode展开为单列单词,再封装为视图v_word提升可读性与复用性;随后使用GROUP BY与COUNT(*)实现词频聚合,并通过ORDER BY降序排列。最终利用concat生成指定格式的二元组结果,并通过INSERT OVERWRITE DIRECTORY将结果持久化到HDFS输出目录。整个过程体现了Hive在文本处理、ETL和批处理分析中的强大能力,也加深了对Hive内置函数、视图机制及外部表特性的理解,为后续复杂数据分析任务奠定基础。