目录
🐼redis中的哈希
redis本身就是键值对结构了,就是通过哈希的方式进行存储的,(key, value)
而redis中的哈希,就是把key这一层组织完了,到了value,value本身也是一种哈希类型,是指值本⾝⼜是⼀个键值对结构,形如 key = "key",value = { { field1, value1 }, ..., {fieldN, valueN } }
哈希类型中的映射关系通常称为 field-value,⽤于区分 Redis 整体的键值对(key-value),注意这⾥的 value 是指 field 对应的值,不是键(key)对应的值,请注意 value 在不同上下⽂的作⽤
**🐼**hash类型的常用命令
**✅**HSET
设置 hash 中指定的字段(field)的值(value)
返回值:添加的字段的个数
cpp
HSET key field value [field value ...]本身就是可以设置多组(file,value),完全等价于hmset
并且多少一嘴,如果已经存在了key,如果你还想新增field ,value,那么还是使用hset
时间复杂度:插⼊⼀组 field 为 O(1), 插⼊ N 组 field 为 O(N)
**✅**HGET
获取 hash 中指定字段的值
时间复杂度:O(1)
返回值:字段对应的值或者 nil。
cpp
HGET key field**✅**HEXISTS
判断 hash 中是否有指定的字段。
cs
HEXISTS key field时间复杂度:O(1)
返回值:1 表示存在,0 表示不存在。
**✅**HDEL
删除 hash 中指定的字段。
返回值:本次操作删除的字段个数
cpp
HDEL key field [field ...]时间复杂度:删除⼀个元素为 O(1). 删除 N 个元素为 O(N).
**✅**HKEYS
获取 hash 中的所有字段。
返回值:字段列表。
时间复杂度:O(N), N 为 field 的个数,这个命令很危险,一旦file过多,那么就是O(N)
cpp
HKEYS key**✅**HVALS
获取 hash 中的所有的值
返回值:所有的值
cpp
HVALS key时间复杂度:O(N), N 为 field 的个数,这个命令也很危险
**✅**HGETALL
获取 hash 中的所有字段以及对应的值。
返回值:字段和对应的值。
cpp
HGETALL key时间复杂度:O(N), N 为 field 的个数.也要慎用!
在使用HGETALL 时,如果哈希元素个数⽐较多,会存在阻塞 Redis 的可能。如果只需要获取部分 field,可以使⽤ HMGET,如果⼀定要获取全部 field,可以尝试使⽤ HSCAN 命令,该命令采⽤渐进式遍历哈希类型
**✅**HMGET
⼀次获取 hash 中多个字段的值。
返回值:字段对应的值或者 nil。
时间复杂度:只查询⼀个元素为 O(1), 查询多个元素为 O(N), N 为查询元素个数.
这里再多说一嘴,hset也可以实现hmset的效果,一次性设置多个f-v。
cpp
HMGET key field [field ...]**✅**HLEN
获取 hash 中的所有字段的个数。
时间复杂度:O(1)
返回值:字段个数
cpp
HLEN key**✅**HSETNX
在字段不存在的情况下,设置 hash 中的字段和值
时间复杂度:O(1)
返回值:1 表示设置成功,0 表示失败。
cpp
HSETNX key field value**✅**HINCRBY
将 hash 中字段对应的数值添加指定的值。
时间复杂度:O(1)
返回值:该字段变化之后的值
cpp
HINCRBY key field increment**✅**HINCRBYFLOAT
HINCRBY 的浮点数版本
cpp
HINCRBYFLOAT key field increment时间复杂度:O(1)
返回值:该字段变化之后的值。
剩下的命令可以参考redis官方文档
🐼hash类型的内部编码
主要有两种:
✅ ziplist(压缩列表):压缩的本质是对数据进行重新编码,目的就是为了节省内存空间。当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认 512 个)、同时所有值都⼩于 hash-max-ziplist-value 配置(默认 64 字节)时,Redis 会使⽤ ziplist 作为哈希的内部实现,ziplist 使⽤更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面⽐hashtable 更加优秀。我们可以在/etc/redis/redis.conf中修改关于默认的配置项
**✅**hashtable(哈希表):当哈希类型⽆法满⾜ ziplist 的条件时,Redis 会使⽤ hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,⽽ hashtable 的读写时间复杂度为 O(1)。
👽来思考一下为什么要有两种编码形式:普通的hash表,本质是一个数组,有的位置没有元素,有的位置有元素,通过这样压缩ziplist,就能节省空间。但是带来的缺点就是在读写的时候是比较慢的,因为要进行压缩和复原。
如果直接使用hashtable时,如果数据量太少,那么会浪费的开销是不成正比的。
所以,如果哈希表中的键值对数量少,使用ziplist表示,如果多,自动转换为hashtable表示。并且如果filed对应的value短,使用ziplist表示,如果file对应的value长,也会自动转换为hashtable
👽再来思考一下为什么redis很重视空间消耗?
因为redis是内存级的,内存空间不像磁盘,所以很关键。
🐼使用场景
我们之前说,string类可以作为缓存来使用。而存储结构化的数据,比如关系型数据,使用hash更合适,假设我们有一张表保存用户信息。我们使用hash就可以这样存储:
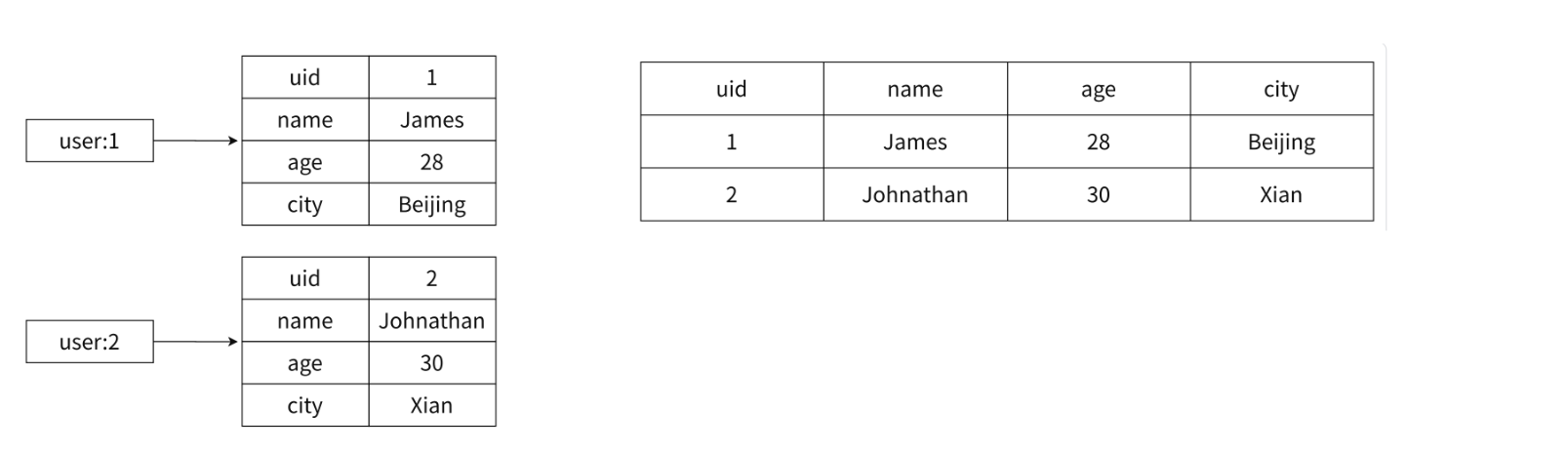
**✅为什么不用string类型来存储呢?**相⽐于使用stringJSON 格式的字符串缓存用户信息,比如现在要对某一个filed进行修改,或者取出某一个filed,如果使用Json,那么还要解析,保存到解析对象中,然后取出file,然后再json化,再返回,不够灵活。本身序列化和反序列需要⼀定开销,
而直接使用hash的方式来表示,就可以非常方便的更新某一个列属性,所以这种结构化数据,本身每个字段就是k-v类型,为啥不用hash类型呢~
不过hash这种做法,也是没有"银弹"的,需要控制ziplist和hashtable的转换,会有一定的内存消耗
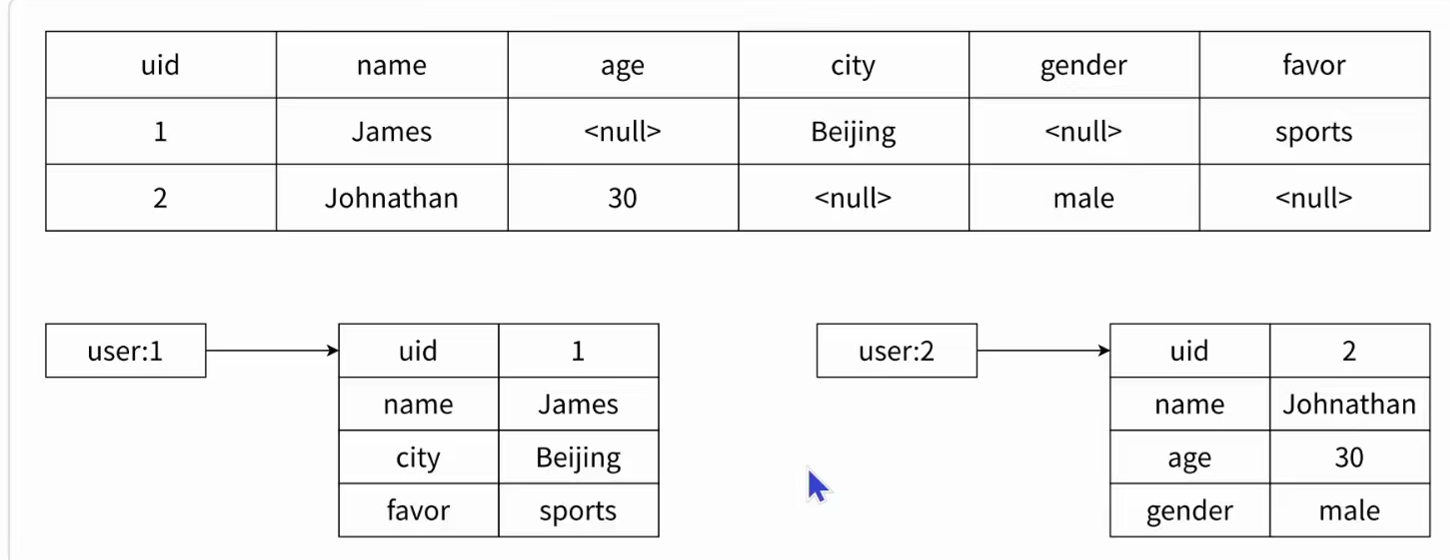
✅哈希类型的稀疏性
哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的 field,一张关系型数据库的字段你可以随机挑选设置嘛!而关系型数据库⼀旦添加新的列,所有行都要为其设置值,即使为 null,数据库你必须都得设置了。如图:
✅为什么不用原生字符串存储呢?
比如直接使用每个属性⼀个键
cpp
set user:1:name James
set user:1:age 23
set user:1:city Beijing如果这样存储,就把同一数据的各个属性分开了,是一种低内聚的表象~
⭐️总结所以,目前,我们已经能够⽤三种⽅法缓存用户信息。
😈1.序列化字符串类型,例如 JSON 格式
cpp
set user:1 经过序列化后的用户对象字符串优点:针对总是以整体作为操作的信息⽐较合适,编程也简单。同时,如果序列化⽅案选择合适,内存的使⽤效率很⾼。
缺点:本⾝序列化和反序列需要⼀定开销,同时如果总是操作个别属性则非常不灵活。
😈2.哈希类型
cs
hmset user:1 name James age 23 city Beijing优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作。
缺点:需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较⼤消耗。
😈3.原⽣字符串类型 ⸺ 使⽤字符串类型,每个属性⼀个键。
cpp
set user:1:name James
set user:1:age 23
set user:1:city Beijing优点:实现简单,针对个别属性变更也很灵活。
缺点:占⽤过多的键,内存占⽤量较⼤,同时用户信息在 Redis 中⽐较分散,缺少内聚性,所以这种⽅案基本没有实⽤性