目录
引入DataX
在数据仓库建设、数据迁移、离线数据分析等场景中,经常需要实现不同数据源之间的批量数据同步。不同数据源(如MySQL、HDFS、Oracle、Hive、Redis等)的存储格式、访问协议存在差异,直接开发同步程序需适配多种数据源,开发成本高、复用性差。
DataX是阿里巴巴开源的一款离线数据同步工具,致力于解决异构数据源之间的高效、稳定数据同步问题。它通过"插件化"架构统一了各类数据源的同步接口,用户无需关注数据源底层细节,只需配置同步任务即可实现不同数据源之间的全量/增量数据同步,广泛应用于离线数据仓库ETL、数据迁移、数据备份等场景。
优势:支持多种异构数据源、无侵入式同步、配置简单、性能可优化、监控完善、社区活跃且文档丰富。
DataX概述
DataX是一款基于Java开发的离线数据同步工具,采用"单进程多线程"架构,通过读取源数据源的数据,经过数据转换(可选),再写入目标数据源,实现端到端的离线数据同步。
-
定位:离线异构数据源同步中间件,专注于批量数据传输,不支持实时同步(实时同步可搭配Maxwell、Canal等工具使用)。
-
支持的数据源:覆盖关系型数据库(MySQL、Oracle、SQL Server、PostgreSQL等)、NoSQL数据库(MongoDB、Redis等)、文件存储(HDFS、Hive、HBase、本地文件、FTP/SFTP等)、数仓工具(ClickHouse、Greenplum等),具体支持类型可参考DataX官方插件列表。
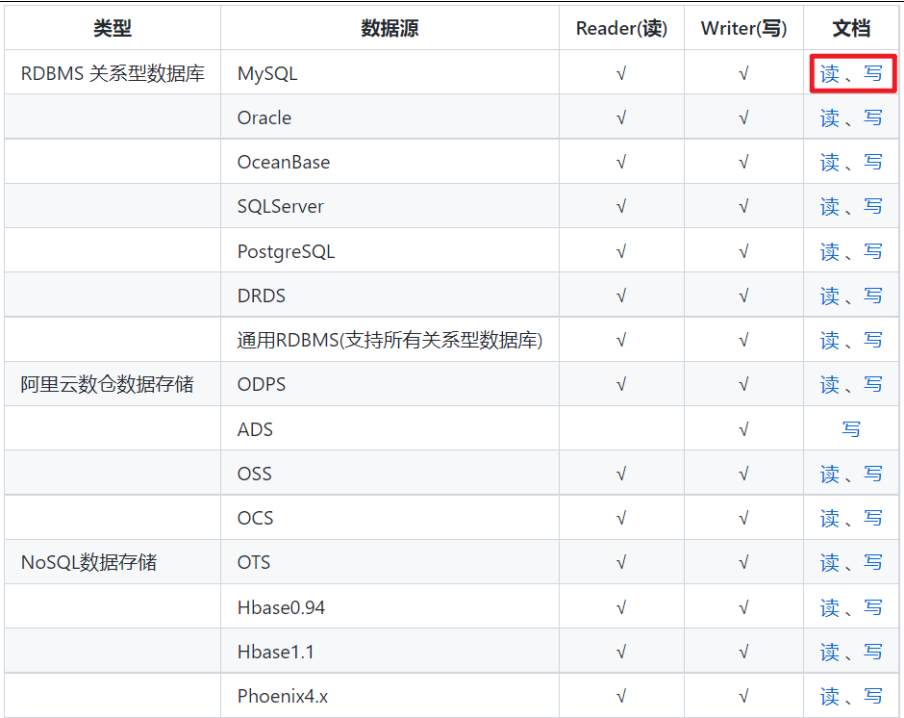
- 特性:
-
异构数据源适配:通过插件化设计支持多种数据源,新增数据源只需开发对应的Reader和Writer插件;
-
高效数据传输:支持并发读取/写入、数据分片、流控限速等机制,提升同步性能;
-
数据质量保障:提供数据校验(如记录数校验、空值校验)、脏数据过滤、失败重试等机制,确保同步数据的准确性和完整性;
-
轻量化部署:无需依赖复杂集群,单节点即可部署运行,配置简单;
-
完善的监控:支持任务进度监控、日志输出、统计信息汇总(如同步数据量、耗时、速率)。
DataX设计理念
DataX的设计理念是"解耦异构数据源,统一同步框架",通过分层架构和插件化设计,实现"多源异构、一键同步"的目标,具体可拆解为以下3点:
①异构数据源解耦
不同数据源的存储结构、访问协议差异较大(如MySQL通过JDBC访问,HDFS通过Hadoop API访问)。DataX通过抽象"Reader"和"Writer"接口,将数据源的读取和写入操作解耦:
-
Reader:负责从源数据源读取数据,不同数据源对应不同的Reader插件(如MySQLReader、HdfsReader);
-
Writer:负责将数据写入目标数据源,不同数据源对应不同的Writer插件(如HiveWriter、RedisWriter)。
DataX框架统一协调Reader和Writer的交互,屏蔽了不同数据源的底层差异,用户无需关注数据读取/写入的具体实现。
②中间数据标准化
为了解决不同数据源数据格式不兼容的问题,DataX定义了统一的中间数据格式(DataX Record)。Reader从源数据源读取数据后,将其转换为标准的Record格式;Writer从框架获取Record格式数据,再转换为目标数据源支持的格式写入。
中间数据标准化使得Reader和Writer完全解耦,任意Reader插件可与任意Writer插件组合,实现"多对多"的数据源同步能力(如MySQL→HDFS、Oracle→Hive、本地文件→Redis等)。
③分布式与单机结合的灵活架构
DataX默认支持单机运行,满足中小规模数据同步需求;同时支持通过DataX Web、调度系统(如Airflow、Azkaban)实现分布式部署和任务调度,应对大规模、多任务的同步场景。思路是"单机高效执行,分布式灵活扩展",平衡了部署复杂度和同步性能。
DataX框架设计

DataX采用分层架构设计,从上到下分为"任务配置层"、"框架层"、"插件层"三层,具体架构如下:
①任务配置层
用户与DataX交互的入口,负责接收用户的同步任务配置(JSON格式),并将配置解析为框架可识别的任务结构。用户无需编写代码,只需通过JSON文件定义"源数据源信息"、"目标数据源信息"、"同步字段映射"、"同步参数(如并发数、分片规则)"等。
作用:简化用户操作,降低使用门槛,实现"配置即任务"。
②框架层
DataX的中枢,负责任务的解析、调度、协调、监控等逻辑,是整个框架的"大脑"。各组件及职责如下:
-
TaskSplitter(任务拆分器):将用户配置的同步任务拆分为多个子任务(Task)。例如,同步一张1000万行的MySQL表时,可按主键范围拆分为10个Task,每个Task同步100万行数据,通过并发执行提升效率;
-
Scheduler(调度器):负责子任务的调度执行,管理线程池(默认使用线程池并发执行子任务),协调Reader和Writer的同步节奏,避免数据积压或读取/写入失衡;
-
Transport(传输层):负责在Reader和Writer之间传输数据,基于内存队列实现,支持数据缓存和流量控制。Reader读取的数据转换为Record后写入队列,Writer从队列中获取Record并写入目标数据源;
-
Monitor(监控层):实时监控任务执行状态,收集同步指标(如读取行数、写入行数、耗时、速率、错误数),输出日志信息,支持任务失败报警和重试。
③插件层
支持数据源扩展,包含各类数据源的Reader插件和Writer插件。插件需实现框架定义的统一接口(Reader接口、Writer接口),框架通过反射机制加载插件,实现对不同数据源的适配。
插件分类:
-
Reader插件:用于读取源数据,如MySQLReader(读取MySQL数据)、HdfsReader(读取HDFS文件)、MongoDBReader(读取MongoDB数据)等;
-
Writer插件:用于写入目标数据,如HiveWriter(写入Hive表)、RedisWriter(写入Redis)、OracleWriter(写入Oracle)等;
-
Transformer插件(可选):用于数据转换(如字段映射、数据过滤、格式转换),如FilterTransformer(过滤符合条件的数据)、ReplaceTransformer(替换字段值)等。
Tip:用户可根据自定义数据源需求,开发自定义Reader/Writer插件,只需遵循DataX的插件开发规范,即可集成到框架中使用。
DataX运行流程
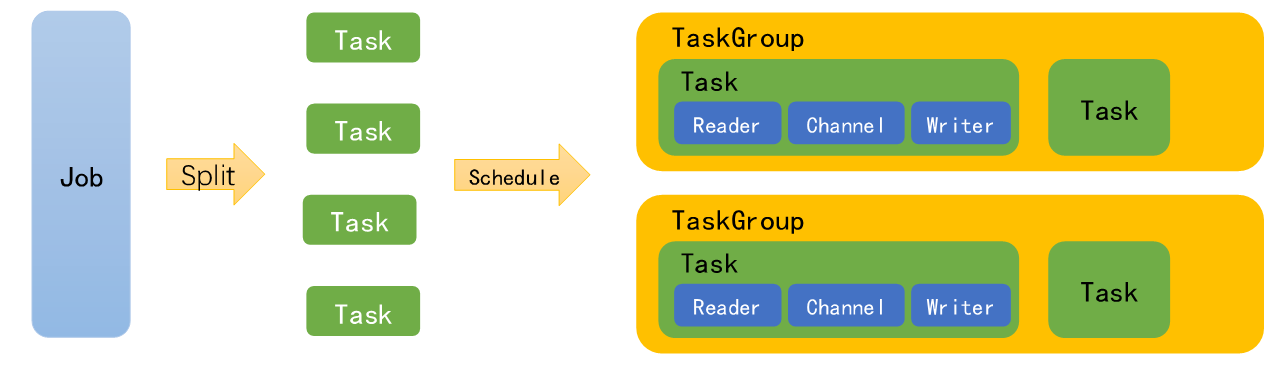
具体流程如下:
-
任务配置:用户编写JSON格式的任务配置文件,明确源数据源(Reader)、目标数据源(Writer)、同步字段、并发数、分片规则等信息;
-
任务提交与解析:用户通过DataX命令行工具提交任务,框架读取配置文件,解析为任务对象,验证配置的合法性(如数据源连接信息是否正确、字段映射是否匹配);
-
任务拆分:TaskSplitter根据配置的分片规则(如按主键范围、按文件分区),将原始任务拆分为多个子任务(Task)。拆分的目的是并行执行子任务,提升整体同步效率;
-
任务调度:Scheduler初始化线程池,将子任务分配到不同线程中执行,同时启动Reader和Writer插件;
-
数据读取与转换:Reader插件从源数据源读取数据,按照配置的字段映射转换为标准的DataX Record格式,写入传输层的内存队列;
-
数据传输与写入:Writer插件从内存队列中获取Record,转换为目标数据源支持的格式,写入目标数据源。传输层通过流量控制机制,协调Reader和Writer的速率,避免队列溢出或空转;
-
任务监控与结束:监控层实时收集各子任务的执行状态(成功/失败)和同步指标(读取/写入行数、速率),输出日志。所有子任务执行完成后,汇总同步结果(总数据量、总耗时、错误数等),任务结束;若出现失败,根据配置执行重试或直接终止任务。
简化:用户配置 → 框架解析拆分 → 并发执行子任务 → Reader读数据→Record传输→Writer写数据 → 汇总结果。
DataX与Sqoop对比
Sqoop是Apache开源的离线数据同步工具(基于Hadoop生态),与DataX功能定位相似,均用于异构数据源之间的离线数据同步。具体对比如下:
| 对比维度 | DataX | Sqoop |
|---|---|---|
| 开源厂商 | 阿里巴巴 | Apache(基于Hadoop生态) |
| 架构 | 插件化架构,单机多线程,支持分布式调度扩展 | 基于MapReduce架构,依赖Hadoop集群(MR任务执行) |
| 支持数据源 | 丰富,覆盖关系型数据库、NoSQL、文件存储、数仓工具等,插件生态完善 | 主要支持关系型数据库与Hadoop生态(HDFS、Hive)之间的同步,其他数据源支持较少 |
| 部署复杂度 | 轻量化,单节点即可部署,无需依赖集群,部署成本低 | 依赖Hadoop集群(HDFS、YARN),部署复杂度高,需维护Hadoop生态 |
| 同步性能 | 单机并发性能优异,支持数据分片和流量控制,中小规模数据同步效率高;大规模数据需分布式扩展 | 基于MapReduce分布式计算,大规模数据同步性能有优势;小规模数据同步因MR启动开销大,效率较低 |
| 使用成本 | 配置简单(JSON文件),无需编写代码,学习成本低;支持数据转换,功能灵活 | 基于命令行参数配置,部分场景需编写SQL或自定义函数;依赖Hadoop知识,学习成本较高 |
| 数据质量保障 | 内置脏数据过滤、数据校验、失败重试机制,监控完善 | 数据校验能力较弱,需额外开发脚本保障数据质量;监控依赖Hadoop生态工具(如YARN UI) |
| 适用场景 | 中小规模离线数据同步、多异构数据源同步、数据迁移、数据仓库ETL(非Hadoop依赖场景) | 大规模数据同步(TB/PB级)、关系型数据库与Hadoop生态之间的同步、依赖Hadoop集群的场景 |
选型建议:若无需依赖Hadoop集群、追求轻量化部署和简单配置,或需要同步多种异构数据源,优先选择DataX;若已部署Hadoop集群、需处理大规模数据同步,且主要同步关系型数据库与Hadoop生态之间的数据,可选择Sqoop。
DataX安装部署
DataX部署轻量化,无需依赖集群,单节点即可完成部署,步骤包括"环境准备→下载解压→验证部署",具体如下:
①环境依赖JDK1.8以上,若需自定义插件或源码编译需安装Maven,端口可访问。不做详细讲解。
②下载DataX安装包
从DataX官方GitHub下载稳定版本安装包(推荐使用预编译包,无需源码编译)并安装,不做讲解。
③验证部署
DataX提供了官方测试任务(读取本地文件写入本地文件),用于验证部署是否成功:
cd /usr/local/datax python bin/datax.py job/job.json若输出以下信息,说明部署成功:
...
任务启动时刻 : 2025-08-01 10:00:00
任务结束时刻 : 2025-08-01 10:00:05
任务总计耗时 : 5s
任务平均流量 : 1024.00 KB/s
记录写入速度 : 10000 条/s
读出记录总数 : 50000
读写失败总数 : 0
...
任务执行成功!DataX使用
DataX和Flume类似,使用方式是"编写JSON任务配置文件 + 执行命令提交任务"。
①配置规范(JSON配置文件结构)
DataX任务配置文件为JSON格式,包含"job"、"setting"、"content"三个一级节点,具体结构如下:
{
"job": {
"setting": {
"speed": {
"channel": 3, // 并发数(子任务数),默认1,可根据服务器性能调整
"byte": 1048576 // 流量控制(每秒最大传输字节数),可选
},
"errorLimit": {
"record": 0, // 允许的脏数据记录数,0表示不允许脏数据
"percentage": 0.02 // 允许的脏数据百分比,可选
}
},
"content": [
{
"reader": { // 源数据源Reader配置
"name": "mysqlreader", // Reader插件名称(如mysqlreader、hdfsreader)
"parameter": {
"username": "root", // 源数据源用户名
"password": "123456", // 源数据源密码
"column": ["id", "name", "age"], // 同步的字段列表,支持*表示所有字段
"connection": [
{
"table": ["user"], // 同步的表名列表
"jdbcUrl": ["jdbc:mysql://192.168.1.100:3306/test_db?useSSL=false"] // 源数据源JDBC连接地址
}
],
"where": "age > 18", // 过滤条件(可选,只同步符合条件的数据)
"splitPk": "id" // 分片字段(可选,用于任务拆分,建议为主键)
}
},
"writer": { // 目标数据源Writer配置
"name": "hivewriter", // Writer插件名称(如hivewriter、localfilereader)
"parameter": {
"defaultFS": "hdfs://192.168.1.101:9000", // HDFS地址
"fileType": "text", // 文件类型(text/orc/parquet)
"path": "/user/hive/warehouse/test_db.db/user", // Hive表存储路径
"fileName": "user_data", // 输出文件名前缀
"column": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "age", "type": "int"}
], // 目标字段名和类型
"writeMode": "append", // 写入模式(append/overwrite)
"fieldDelimiter": "\t" // 字段分隔符
}
}
}
]
}
}配置说明:
-
setting.speed.channel:并发数,决定子任务数量,并发数越高,同步速度越快(需结合服务器CPU、内存调整,避免资源耗尽);
-
errorLimit:脏数据限制,超过限制任务会失败,可根据业务需求调整;
-
reader.name:必须与插件名称一致(如MySQLReader对应"mysqlreader"),可在DataX安装目录的plugin/reader目录下查看所有支持的Reader;
-
writer.name:必须与插件名称一致,可在plugin/writer目录下查看所有支持的Writer;
-
column:同步字段列表,源和目标的字段名、类型需匹配,支持字段映射(如源字段id对应目标字段user_id)。
②常用场景示例
示例1:MySQL→Hive全量同步
需求:将MySQL test_db库的user表(id、name、age、email)全量同步到Hive test_db.db.user表,并发数3,不允许脏数据。
配置文件(mysql2hive.json):
{
"job": {
"setting": {
"speed": {"channel": 3},
"errorLimit": {"record": 0, "percentage": 0}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "maxwell",
"password": "maxwell123",
"column": ["id", "name", "age", "email"],
"connection": [
{
"table": ["user"],
"jdbcUrl": ["jdbc:mysql://192.168.1.100:3306/test_db?useSSL=false&serverTimezone=UTC"]
}
],
"splitPk": "id"
}
},
"writer": {
"name": "hivewriter",
"parameter": {
"defaultFS": "hdfs://192.168.1.101:9000",
"fileType": "text",
"path": "/user/hive/warehouse/test_db.db/user",
"fileName": "user_mysql_sync",
"column": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "email", "type": "string"}
],
"writeMode": "overwrite",
"fieldDelimiter": "\t",
"hiveMetaStore": "thrift://192.168.1.101:9083" // Hive Metastore地址
}
}
}
]
}
}执行命令:
python /usr/local/datax/bin/datax.py /path/to/mysql2hive.json示例2:本地文件→MySQL增量同步
需求:将本地CSV文件(/data/local/user.csv)中的增量数据(id>1000)同步到MySQL test_db库的user表,字段分隔符为逗号,允许5条脏数据。
配置文件(local2mysql.json):
{
"job": {
"setting": {
"speed": {"channel": 2},
"errorLimit": {"record": 5, "percentage": 0.01}
},
"content": [
{
"reader": {
"name": "localfilereader",
"parameter": {
"path": ["/data/local/user.csv"],
"fileName": "user.csv",
"column": [
{"index": 0, "type": "int", "name": "id"},
{"index": 1, "type": "string", "name": "name"},
{"index": 2, "type": "int", "name": "age"},
{"index": 3, "type": "string", "name": "email"}
],
"fieldDelimiter": ",", // CSV文件分隔符
"skipHeader": "true" // 跳过表头
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"column": ["id", "name", "age", "email"],
"connection": [
{
"table": ["user"],
"jdbcUrl": ["jdbc:mysql://192.168.1.100:3306/test_db?useSSL=false"]
}
],
"writeMode": "insert", // 增量插入
"preSql": ["DELETE FROM user WHERE id > 1000"] // 同步前删除旧增量数据(避免重复)
}
}
}
]
}
}执行命令:
python /usr/local/datax/bin/datax.py /path/to/local2mysql.json