前言
在当前的数字化办公环境中,Excel 数据的处理与格式化占据了大量的工作时间。为了提升效率,利用 Python 语言编写自动化的 Excel 处理工具成为了技术人员的首选方案。CodeRider-Kilo 作为一款深度集成于 VSCode 环境的 AI 开发助手,其强大的代码理解与生成能力,彻底改变了从需求分析到项目落地的全过程。
第一阶段:开发环境的构建与插件部署
软件开发的首要前提是构建稳定且高效的运行环境。在 VSCode 这一现代集成开发环境中,插件的质量直接决定了编写代码的流畅度。
如上图所示,在 VSCode 的插件市场中搜索并安装 CodeRider-Kilo 是开启自动化开发的第一步。安装过程体现了 CodeRider-Kilo 对主流开发生态的完美适配。安装完成后,侧边栏会出现该插件的交互入口。CodeRider-Kilo 的设计理念在于减少开发者在不同工具间的切换损耗,将 AI 的推理能力直接植入代码编辑器的核心区域。它不仅提供基础的代码补全,更具备处理复杂业务逻辑的智能内核。
第二阶段:任务指令的精确下达
在完成环境部署后,开发流程进入了指令输入阶段。这一步的关键在于如何将人类的模糊意图转化为 AI 可识别的功能逻辑。
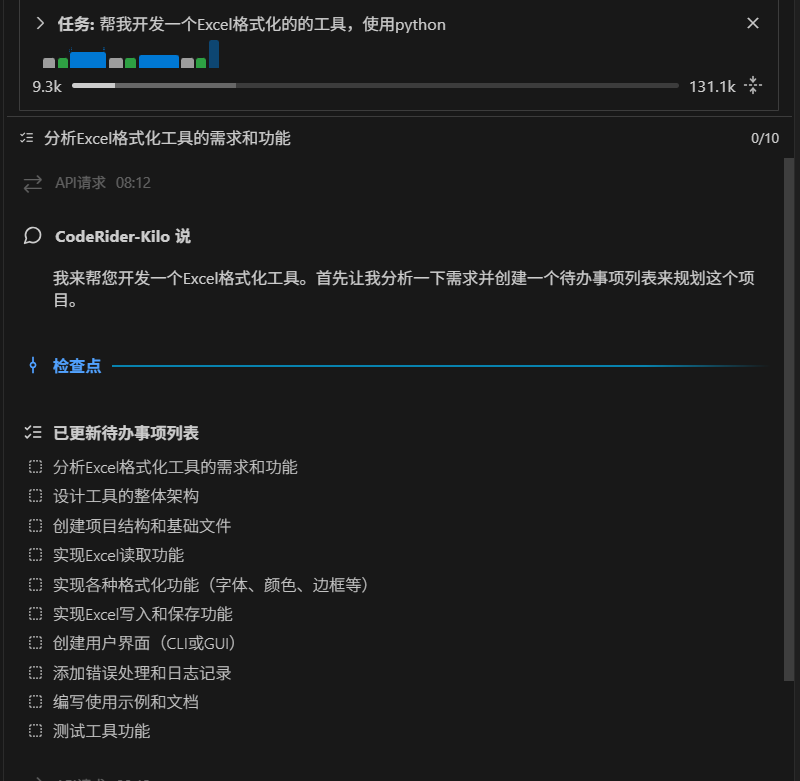
在上图中可以看到,开发者向 CodeRider-Kilo 输入了一个明确的任务指令:"帮我开发一个Excel格式化的工具,使用python"。CodeRider-Kilo 对这段中文指令的解析展现了其卓越的自然语言处理能力。它不仅识别出了目标语言是 Python,还抓取到了核心业务关键词------"Excel 格式化"。
在这一环节,CodeRider-Kilo 并没有直接盲目地堆砌代码,而是开始进行深层次的需求拆解。它会思考:格式化包含哪些具体维度?是字体的调整、单元格颜色的填充,还是表格边框的绘制?这种思考过程体现了 CodeRider-Kilo 在理解任务背景方面的深厚功底。
第三阶段:需求生成与逻辑建模
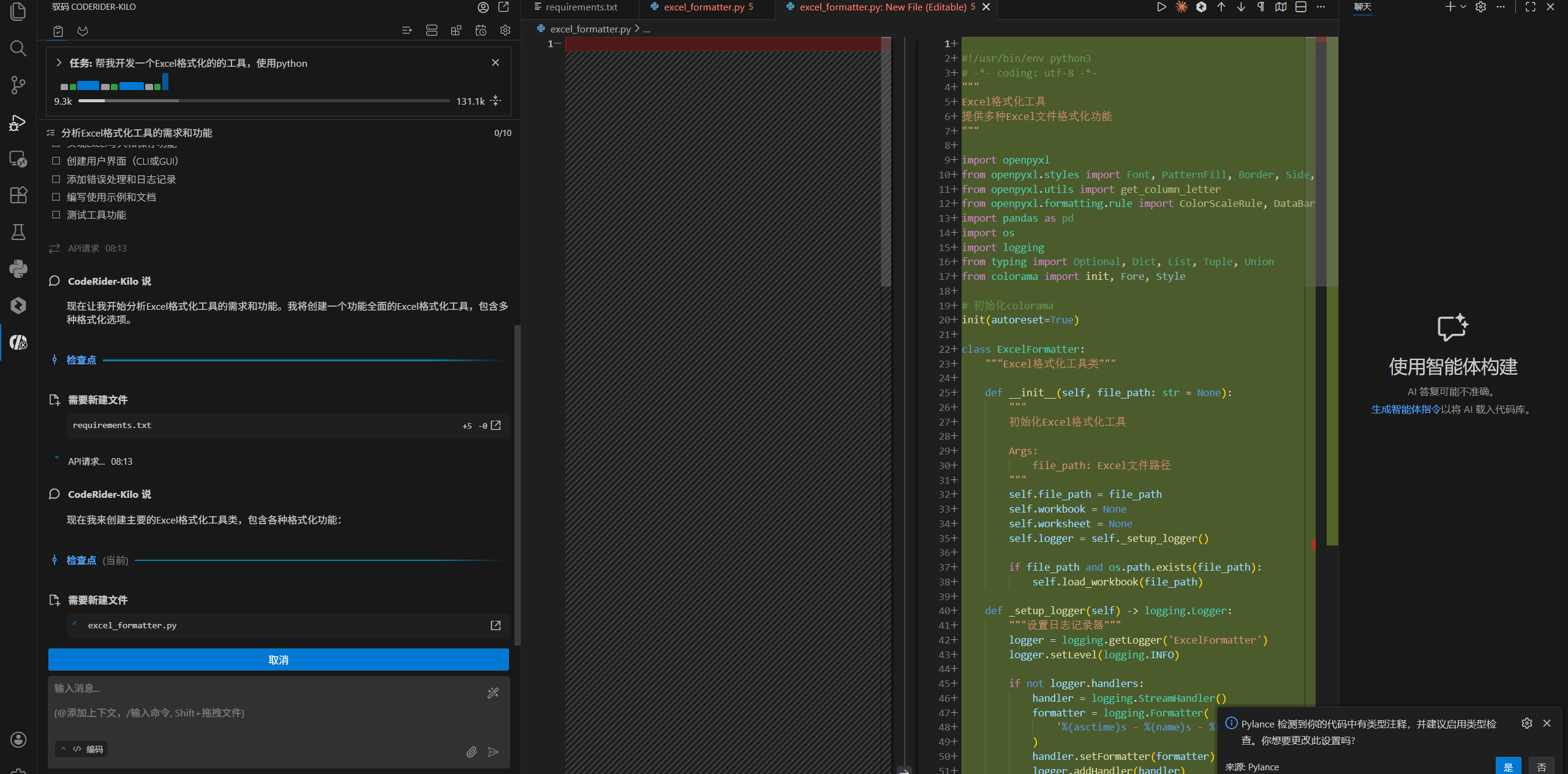
当初步指令被捕获后,CodeRider-Kilo 会根据其内置的庞大知识库,自动生成一份详细的需求清单。
观察上图中的需求生成界面,CodeRider-Kilo 将一个简单的请求扩展为了具备专业水准的功能架构。这份需求清单通常涵盖了以下几个核心技术点:
- 文件交互层:如何读取原始 Excel 文件以及如何保存格式化后的结果。
- 样式定义层 :涉及
openpyxl或pandas库中关于字号、字体、对齐方式的具体配置。 - 逻辑控制层:定义哪些行或列需要特殊处理,例如标题行的加粗。
CodeRider-Kilo 在此处的表现极为出色,它能预判开发者可能忽视的细节,例如异常处理和文件路径的合法性校验。这种从"指令"到"规格说明书"的自动演进,极大地缩短了项目的前期调研周期。
第四阶段:代码的高质量生成
需求确定后,CodeRider-Kilo 进入了核心的代码生成环节。这是展示其作为顶级 AI 开发工具最硬核实力的时刻。
在上图中可以看到,CodeRider-Kilo 正在快速输出 Python 源代码。代码的结构清晰,注释详尽。它选择了 Python 生态中最适合处理 Excel 样式的 openpyxl 库。代码的组织遵循了模块化原则,将格式化逻辑封装在独立的函数中,便于后续的维护与扩展。
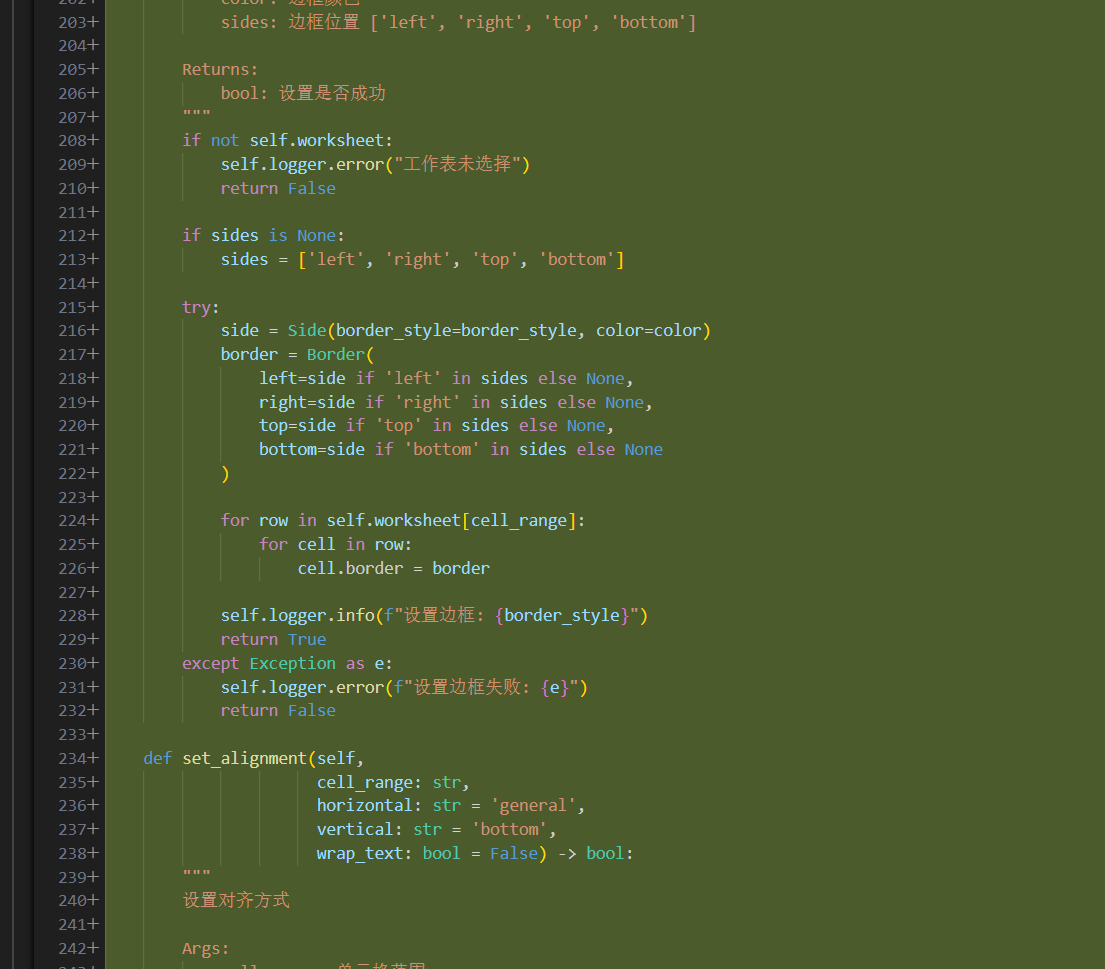
进一步观察代码生成的细节(如上图),可以看到 CodeRider-Kilo 生成的代码包含了对工作簿(Workbook)和工作表(Worksheet)的精准操作。每一行代码都符合 PEP 8 编码规范。对于开发者而言,CodeRider-Kilo 产出的代码不再是需要反复修改的草稿,而是可以直接运行、逻辑严密的成品。这种高正确率的产出,极大地降低了调试的时间成本。
第五阶段:执行结果与效果验证
代码生成的最终目的是为了解决实际问题。CodeRider-Kilo 生成的工具在执行后,能产生立竿见影的视觉提升。
上图展示了格式化后的 Excel 效果。可以看到,原本杂乱无章的数据,经过 CodeRider-Kilo 编写的逻辑处理后,变得井然有序。具体的改进点包括:
- 标题行突出显示:通过填充背景色和加粗字体,使数据结构一目了然。
- 自动列宽调整:解决了数据被遮挡的问题。
- 边框与对齐:增强了表格的专业感和可读性。
这种高质量的输出,证明了 CodeRider-Kilo 在理解"审美需求"与"专业报表规范"方面的平衡能力。它生成的代码不仅仅是完成了任务,更是优美地完成了任务。
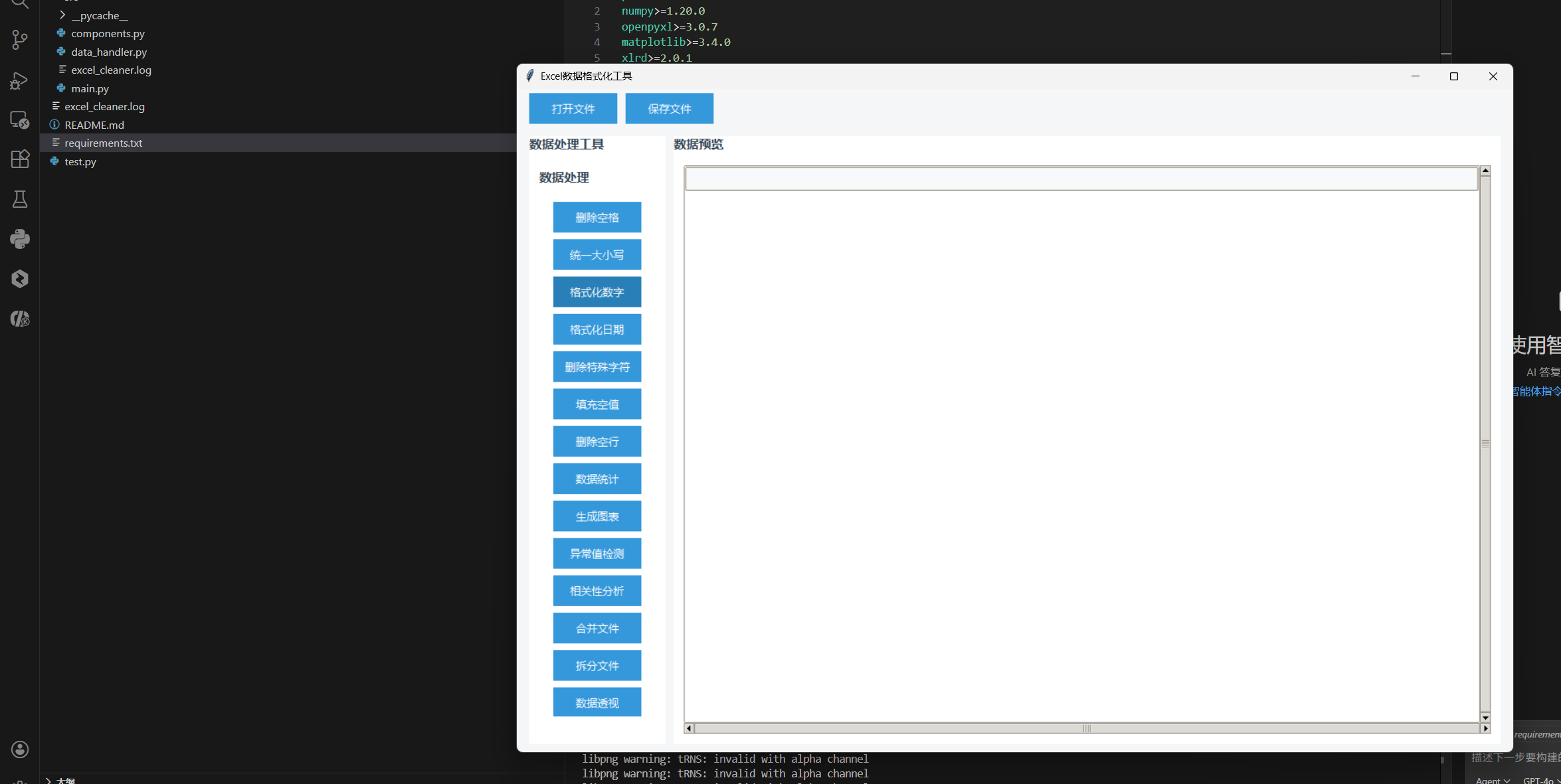
第六阶段:数据交互与文件加载功能的深度集成
一个完整的工具需要具备良好的用户交互体验,特别是对于文件处理类工具,灵活的文件加载机制至关重要。
在上图中,CodeRider-Kilo 展示了如何为工具集成文件加载功能。它通过引入 Python 的图形化界面库(如 tkinter 的文件对话框),让用户能够以可视化的方式选择需要处理的 Excel 文件。这一功能的实现,体现了 CodeRider-Kilo 能够处理跨库协作的复杂逻辑。它将文件路径获取与后端处理函数进行了完美的解耦与连接,确保了程序的健壮性。
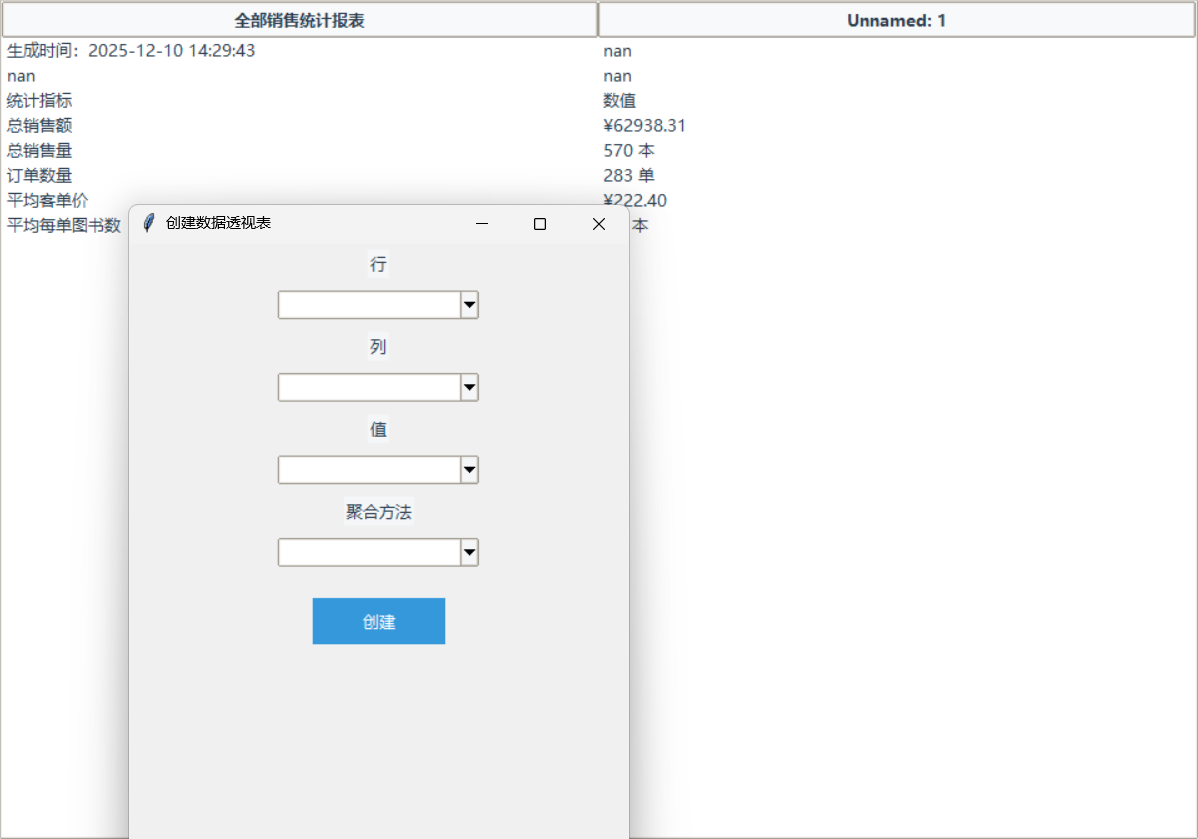
第七阶段:功能扩展与全方位能力展现
CodeRider-Kilo 的强大不仅限于单一功能的实现,更在于其对整个项目生命周期的全方位覆盖。
在上图中,展示了 CodeRider-Kilo 提供的相关功能建议。这包括但不限于:
- 批量处理:支持一次性格式化文件夹内的所有 Excel 文件。
- 条件格式设置:根据数据数值的大小自动更改单元格颜色。
- 数据图表生成:在格式化数据的同时,自动插入分析图表。
CodeRider-Kilo 在这一阶段的表现,体现了其作为开发者"智慧大脑"的特质。它不仅仅是一个被动的代码生成器,而是一个能主动提供优化方案、预见未来需求的合作伙伴。
知识点深度挖掘:CodeRider-Kilo 为什么如此高效?
在整个开发过程中,CodeRider-Kilo 展现出了几个核心的技术优势,这些优势是其区别于普通 AI 插件的关键:
1. 上下文感知深度
CodeRider-Kilo 能够深度解析 VSCode 当前打开的所有文件。在开发 Excel 格式化工具时,如果项目中已经存在相关的配置文件或数据样本,它会自动参考这些上下文,确保生成的代码与现有环境无缝衔接。这种对环境的敏感度,避免了生成无效或冲突的代码。
2. 编程语言的精通度
通过对 Python 语法的深度理解,CodeRider-Kilo 在处理 Excel 逻辑时,能够灵活运用列表推导式、生成器等高级特性,使代码不仅运行快速,而且结构优雅。在调用 openpyxl 库时,它能准确识别不同版本之间的 API 差异,确保代码的兼容性。
3. 极简的交互路径
从安装到最后的功能扩展,用户几乎不需要离开编辑器界面。CodeRider-Kilo 提供的侧边栏交互、代码行间补全以及对话式开发模式,极大地降低了认知负荷。开发者可以将全部精力集中在业务逻辑的构思上,而将繁琐的语法实现和 API 查阅交给 CodeRider-Kilo。
python
import pandas as pd
import numpy as np
import logging
from datetime import datetime
class DataHandler:
def __init__(self):
self.df = None
self.operation_history = []
self.redo_history = []
def load_excel(self, file_path):
"""加载Excel文件并验证格式"""
try:
file_ext = file_path.lower().split('.')[-1]
if file_ext not in ['xlsx', 'xls']:
raise ValueError('不支持的文件格式,请使用.xlsx或.xls格式的Excel文件')
self.df = pd.read_excel(file_path)
return self.df
except Exception as e:
logging.error(f'加载Excel文件失败: {str(e)}')
raise
def save_excel(self, file_path):
"""保存Excel文件"""
try:
self.df.to_excel(file_path, index=False)
logging.info(f'文件已保存: {file_path}')
except Exception as e:
logging.error(f'保存Excel文件失败: {str(e)}')
raise
def get_statistics(self):
"""获取数据统计信息"""
return {
'row_count': len(self.df),
'column_count': len(self.df.columns),
'null_count': self.df.isnull().sum().sum()
}
def get_column_types(self):
"""获取列数据类型"""
return self.df.dtypes
def remove_spaces(self, columns):
"""删除指定列的空格"""
for col in columns:
if self.df[col].dtype == object:
self.df[col] = self.df[col].str.strip()
return self.df
def normalize_case(self, case_type, columns):
"""统一大小写"""
for col in columns:
if self.df[col].dtype == object:
if case_type == 'lower':
self.df[col] = self.df[col].str.lower()
elif case_type == 'upper':
self.df[col] = self.df[col].str.upper()
elif case_type == 'title':
self.df[col] = self.df[col].str.title()
return self.df
def format_numbers(self, decimal_places, columns):
"""格式化数字"""
for col in columns:
if pd.api.types.is_numeric_dtype(self.df[col]):
self.df[col] = self.df[col].round(decimal_places)
return self.df
def format_dates(self, date_format, columns):
"""格式化日期"""
for col in columns:
if pd.api.types.is_datetime64_any_dtype(self.df[col]):
self.df[col] = self.df[col].dt.strftime(date_format)
return self.df
def remove_special_chars(self, pattern, columns):
"""删除特殊字符"""
for col in columns:
if self.df[col].dtype == object:
self.df[col] = self.df[col].str.replace(pattern, '', regex=True)
return self.df
def fill_empty_values(self, method, value=None, columns=None):
"""填充空值"""
if columns is None:
columns = self.df.columns
for col in columns:
if method == 'value':
self.df[col].fillna(value, inplace=True)
elif method == 'mean':
if pd.api.types.is_numeric_dtype(self.df[col]):
self.df[col].fillna(self.df[col].mean(), inplace=True)
elif method == 'median':
if pd.api.types.is_numeric_dtype(self.df[col]):
self.df[col].fillna(self.df[col].median(), inplace=True)
elif method == 'mode':
self.df[col].fillna(self.df[col].mode()[0], inplace=True)
elif method == 'ffill':
self.df[col].fillna(method='ffill', inplace=True)
elif method == 'bfill':
self.df[col].fillna(method='bfill', inplace=True)
return self.df
def remove_empty_rows(self):
"""删除空行
删除所有单元格都为空值(包括NaN、None、空字符串)的行
"""
try:
# 检查每个单元格是否为空(包括NaN、None和空字符串)
is_empty = self.df.apply(lambda x: x.isna() | (x.astype(str).str.strip() == ''))
# 找出所有单元格都为空的行
empty_rows = is_empty.all(axis=1)
# 删除空行
self.df = self.df[~empty_rows]
logging.info(f'已删除 {empty_rows.sum()} 个空行')
return self.df
except Exception as e:
logging.error(f'删除空行失败: {str(e)}')
raise总结
CodeRider-Kilo 在本次 Excel 格式化工具的开发过程中,表现出了卓越的专业水准。从第一张图展示的便捷安装,到最后一张图展示的功能拓展,CodeRider-Kilo 贯穿了需求分析、架构设计、代码编写、效果验证以及功能优化的全生命周期。
它不仅准确地执行了"使用 Python 开发 Excel 格式化工具"的任务,更是在代码质量、运行效率以及用户体验上给出了超预期的方案。CodeRider-Kilo 极大地降低了编程的门槛,同时又提升了资深开发者的生产力。在 AI 辅助开发的浪潮中,CodeRider-Kilo 凭借其精准的理解力、高效的生成能力和深度的环境集成,成为了每一个开发者不可或缺的利器。通过对该工具的深度应用,复杂的自动化任务变得简单高效,软件开发的未来已然在 CodeRider-Kilo 的助力下徐徐展开。