
文章目录
前言
之前我们介绍了线程的基本概念,对线程有了一个初步的认识,这篇文章我们就来介绍一下线程控制相关话题。
创建
Linux中,创建线程可以使用如下函数:
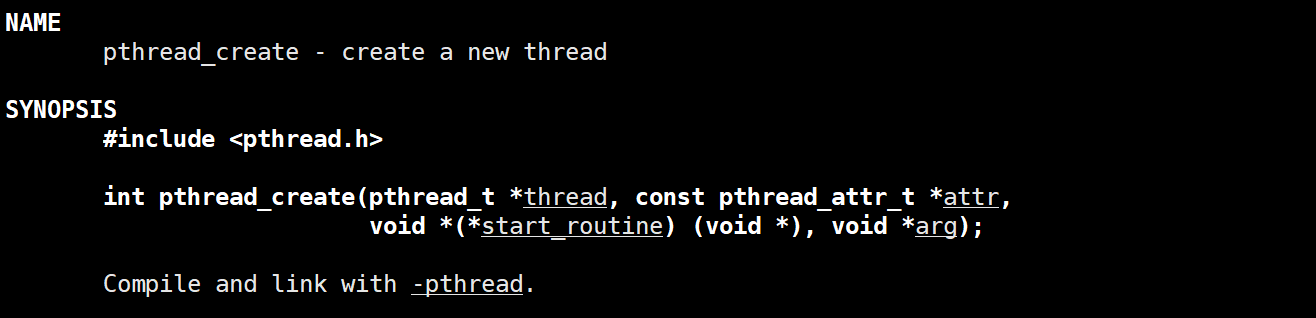
第一个参数为输出型的参数,代表获得线程的id,第二个参数为线程的相关属性,第三个参数为函数指针,相当于回调函数,第四个参数为要给回调函数start_routine传递的参数。
主线程会得到创建函数的返回,如果创建新线程创建成功,函数返回0;如果创建新线程失败,函数会返回对应的错误码。创建的新线程会去执行传入的函数。
使用示例如下:
cpp
//#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
void *Routine(void *args)
{
std::string name = static_cast<const char*>(args);
while (1)
{
std::cout << "我是新线程: " << name << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, Routine, (void*)"thread-1");
(void)n;
while (1)
{
std::cout << "我是主线程" << std::endl;
sleep(1);
}
return 0;
}这个函数在某些系统下需要手动链接库,运行结果如下:
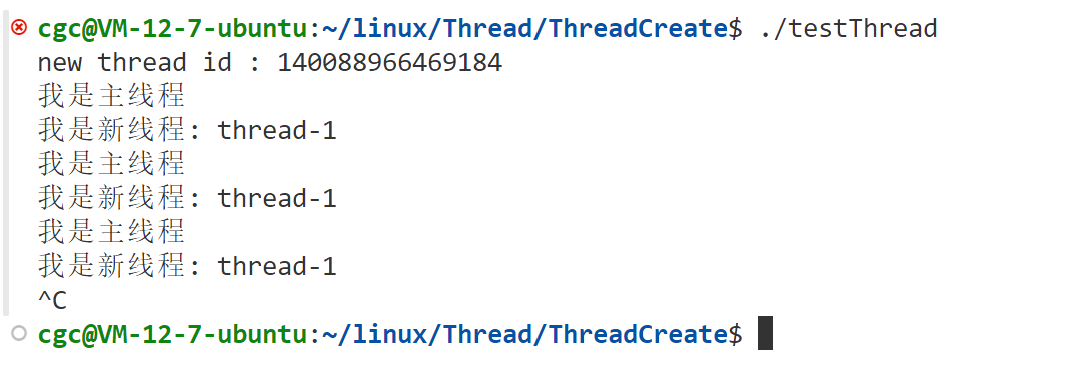
我们发现,打印出来,两个线程pid是一样的,同时,也可以使用"ps -aL"查看Linux系统下所有的轻量级进程,如下所示:
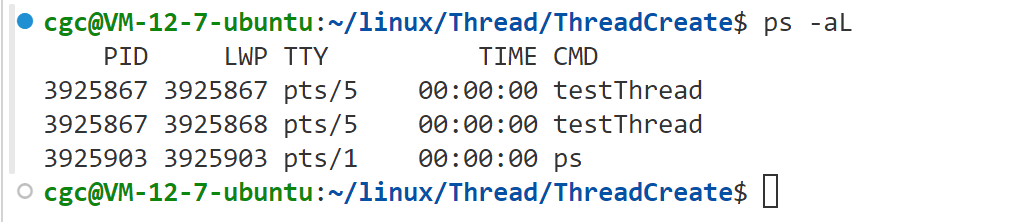
轻量级进程为LWP(Light Weight Process),LWP为轻量级进程的编号。LWP和PID的值相等的执行流为主线程。我们发现获得的新线程id和对应的LWP不一样,这是因为C语言对相关内容进行了封装,获得的新线程的id我们会在后面进行介绍。
进程中的任意一个线程出现异常时,整个进程的线程都会退出。
pthread_self
这个函数可以获得线程自身的id,我们在上述代码中的Routine函数中将线程的id打印出来,结果如下:
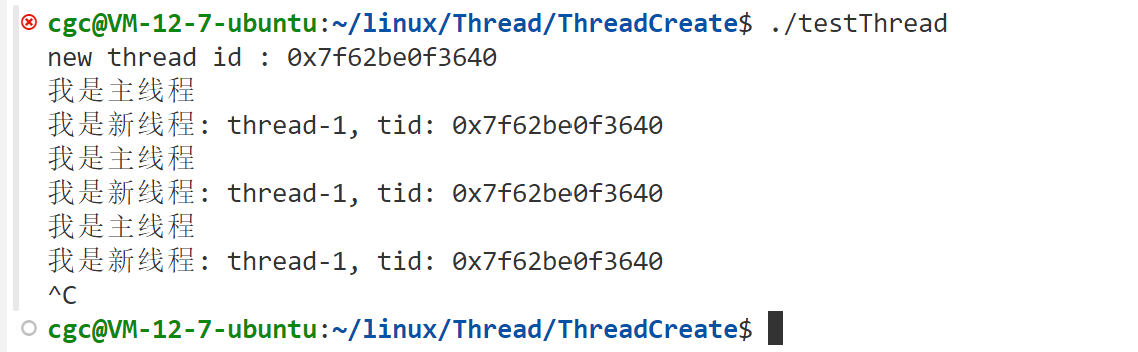
我们发现,新线程自己获得的线程id和主线程获得的线程id是相同的。
存在问题
共享问题
我们再来看如下代码:
cpp
// #include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
int gval = 100;
void PrintName(std::string name)
{
printf("我是新线程: %s, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", name.c_str(), pthread_self(), getpid(), gval, &gval);
}
void *Routine(void *args)
{
std::string name = static_cast<const char *>(args);
PrintName(name);
printf("--------------------------------\n");
while (1)
{
// std::cout << "我是新线程: " << name << std::endl;
sleep(1);
gval++;
}
}
int main()
{
const int num = 10;
for (int i = 0; i < num; i++)
{
pthread_t tid;
char threadname[64];
snprintf(threadname, sizeof(threadname), "thread-%d", i + 1);
int n = pthread_create(&tid, nullptr, Routine, threadname);
(void)n;
//sleep(1);
}
while (1)
{
printf("我是主线程, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", pthread_self(), getpid(), gval, &gval);
sleep(1);
}
return 0;
}运行代码,其中一次运行的结果如下:
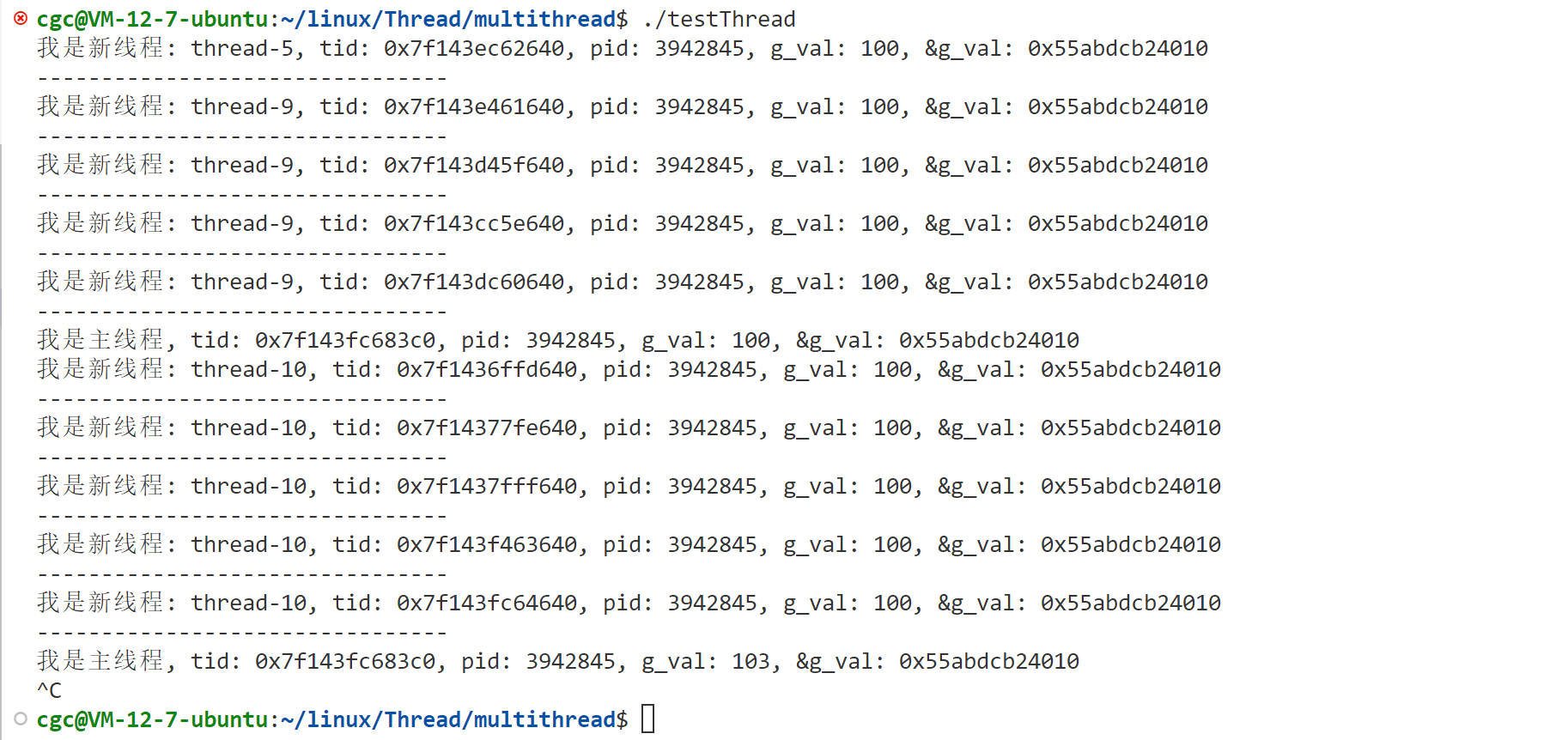
我们发现,这个输出结果是非常混乱的,这是因为,当上一个线程将threadname传给函数时,可能还没来得及拷贝,下一个线程又对threadname进行了修改,导致输出的结果是混乱的,threadname是一个共享资源。多线程对一个共享资源进行并发访问,可能会导致其它线程读取数据异常,这就是数据不一致问题。
解决这个问题,只需要为每个进程都分配一个堆区空间即可。如下所示:
cpp
// #include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
int gval = 100;
void PrintName(std::string name)
{
printf("我是新线程: %s, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", name.c_str(), pthread_self(), getpid(), gval, &gval);
}
void *Routine(void *args)
{
std::string name = static_cast<const char *>(args);
PrintName(name);
printf("--------------------------------\n");
while (1)
{
// std::cout << "我是新线程: " << name << std::endl;
sleep(1);
gval++;
}
}
int main()
{
const int num = 10;
for (int i = 0; i < num; i++)
{
pthread_t tid;
char *threadname = new char[64];
sprintf(threadname, "thread-%d", i + 1);
int n = pthread_create(&tid, nullptr, Routine, threadname);
(void)n;
//sleep(1);
}
while (1)
{
printf("我是主线程, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", pthread_self(), getpid(), gval, &gval);
sleep(1);
}
return 0;
}参数问题
创建线程的函数,传递的函数的arg参数不一定只能传void*类型的,而是可以传递任意类型,包括类、结构体和任务等。示例如下:
cpp
//Task.hpp
#pragma once
#include <string>
class Task
{
public:
Task(int x, int y)
:_x(x),_y(y)
{}
void Excute()
{
_result = _x + _y;
}
std::string Result()
{
return std::to_string(_x) + "+" + std::to_string(_y) + "=" + std::to_string(_result);
}
~Task(){}
private:
int _x;
int _y;
int _result;
};
cpp
// #include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
#include "Task.hpp"
#include <cstdlib>
int gval = 100;
void PrintName(std::string name)
{
printf("我是新线程: %s, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", name.c_str(), pthread_self(), getpid(), gval, &gval);
}
void *Routine(void *args)
{
sleep(3);
Task *t = static_cast<Task *>(args);
t->Excute();
std::cout << t->Result() << std::endl;
return nullptr;
// std::string name = static_cast<const char *>(args);
// PrintName(name);
// printf("--------------------------------\n");
// while (1)
// {
// // std::cout << "我是新线程: " << name << std::endl;
// sleep(1);
// gval++;
// }
}
int main()
{
srand(time(nullptr) ^ getpid());
const int num = 10;
for (int i = 0; i < num; i++)
{
pthread_t tid;
// char *threadname = new char[64];
// sprintf(threadname, "thread-%d", i + 1);
int x = rand() % 10 + 1;
usleep(236);
int y = rand() % 10 + 1;
Task *t = new Task(x, y);
int n = pthread_create(&tid, nullptr, Routine, t);
(void)n;
// sleep(1);
}
while (1)
{
printf("我是主线程, tid: 0x%lx, pid: %d, g_val: %d, &g_val: %p\n", pthread_self(), getpid(), gval, &gval);
sleep(1);
}
return 0;
}线程终止
终止做法
线程的终止方式有常见的以下三种:
- 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
- 线程可以调用pthread_exit终止自己。
- 一个线程可以调用pthread_cancel终止同一进程中的另一个线程。
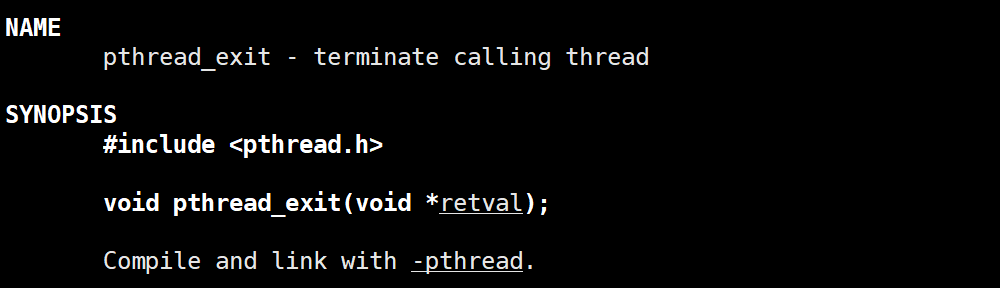
pthread_exit
该函数的声明如下:
pthread_cancel
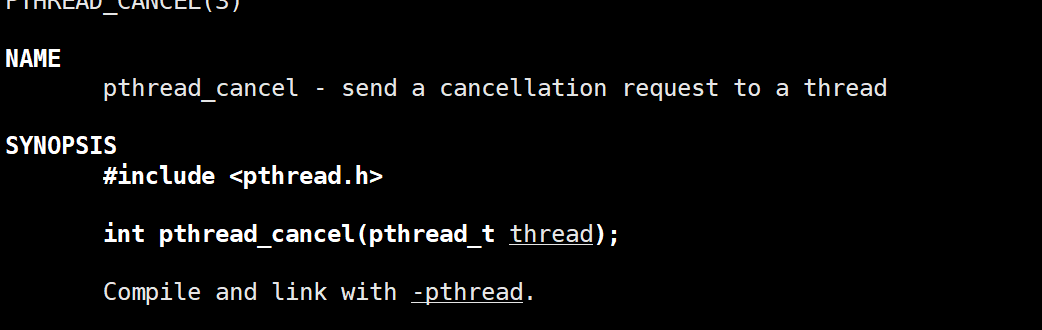
该函数可以杀死指定的线程,参数为要杀死线程的编号。若函数执行成功,返回0,否则返回对应的错误码。
这里要注意,创建出来的新线程不能杀掉主线程,只有主线程可以杀掉新线程。
设置名字
设置和获得线程名字的相关函数声明如下:
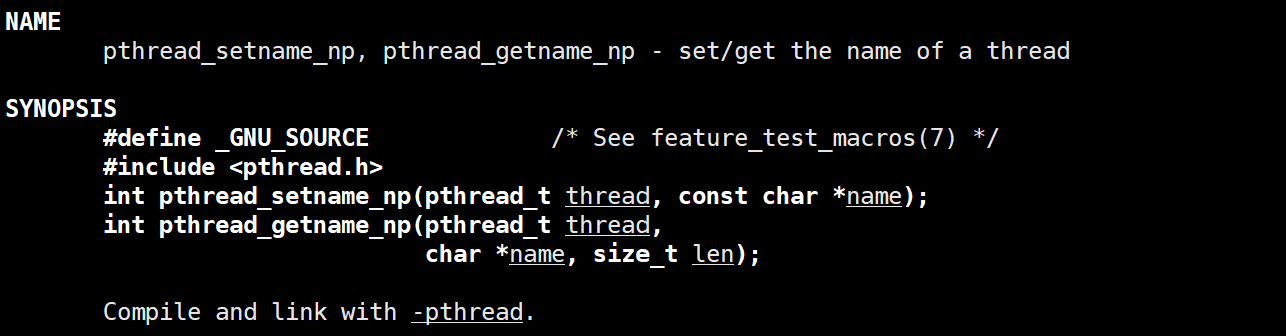
这两个函数可以在内核中将对应线程的名字修改,但在Linux中,线程最大的名称长度为16字符(包括结尾的\0),如果名称超过这个长度,会被截断。同时,通常只有线程自身可以设置自己的名称,尝试设置其它线程的名称可能会导致错误。
线程等待
新线程必须被主线程等待,若不等待,会出现类似于子进程退出的僵尸问题;同时,创建新线程是为了完成对应的任务,因此,主线程必须得到新线程的执行结果。
线程等待函数如下:
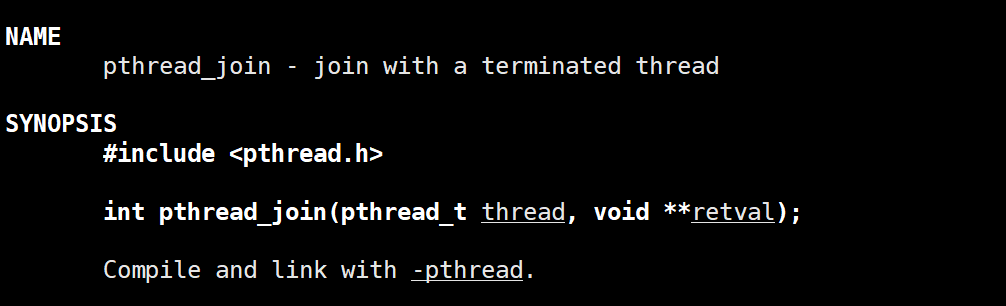
若要等待的线程不终止,必须阻塞等待。第一个参数为要等到线程的编号,第二个参数为一个输出型参数,用来保存新线程的退出信息。但是与进程退出不同的是,线程退出没有退出信号,这是因为,新线程出异常,进程会全部退出,根本就不会join成功,不需要关心异常,而如果真的出现了异常,也是由线程所在的进程的父进程来分析异常的,所以join只会关心正常情况。
传参时可以传任意类型的对象,返回值也可以返回任意类型的对象。示例如下所示:
cpp
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
#include <cstdlib>
#include <vector>
#include "Task.hpp"
void* Routine(void* args)
{
Task *t = static_cast<Task*>(args);
t->Excute();
return (void*)t;
}
int main()
{
Task t(10, 20);
pthread_t tid;
pthread_create(&tid, nullptr,Routine, (void*)&t);
sleep(7);
//1. 一般而言必须会回收等待新线程退出,如果不等待,就会导致类似僵尸问题
//2. 为了获取新线程执行的结果
Task* task;
int n = pthread_join(tid, (void**)&task);
if(n == 0)
{
std::cout << "join success: " << task->Result() << std::endl;
}
return 0;
}当某一线程调用该函数时,调用该函数的线程将挂起等待,直到对应的线程终止,对应的线程以不同的方法终止,通过该函数得到的终止状态是不同的,情况如下:
- 如果thread线程通过return返回,retval所指向的单元里存放的是thread线程函数的返回值。
- 如果thread线程被别的线程调用thread_cancel异常终止掉,retval所指向的单元里存放的是常数PTHREAD_CANCELED,这个常数为-1。
分离线程
如果我们在线程执行的函数中调用了程序替换函数,那么就相当于进程调用了程序替换函数,会影响其它线程的执行,因此如果要进行线程的程序替换,可以通过分离线程来实现,可以在线程执行的函数中fork进程并进行函数替换,但这个方式解决起来较为麻烦,可以采用分离线程来解决。
若一个主线程要回收新线程,就必须阻塞等待,若用户想让线程自动全部结束掉,主线程不想等待,那么就可以将被等待的线程设置为分离状态。
一旦分离线程后,主线程就不对创建出来的线程进行管理了,分离是一种状态。分离线程的函数声明如下:
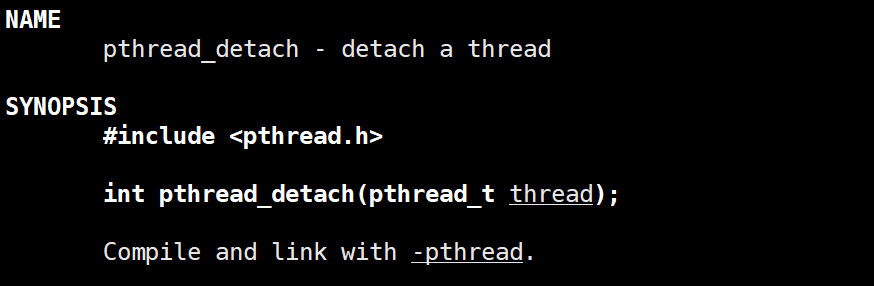
若主线程分离线程后仍继续等待,会分离失败,返回错误对应的码。测试代码如下所示:
cpp
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
#include <cstdlib>
#include <vector>
#include "Task.hpp"
class Res
{
public:
int code;
std::string name;
std::string info;
};
void* Routine(void* args)
{
int cnt = 5;
while(cnt)
{
std::cout << "新线程在运行" << cnt-- << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
Task t(10, 20);
pthread_t tid;
pthread_create(&tid, nullptr,Routine, (void*)&t);
sleep(1);
std::cout << "main thread 分离线程" << std::endl;
pthread_detach(tid);
void* ret = nullptr;
int n = pthread_join(tid, &ret);
if(n == 0)
{
std::cout << "join success: " << (long long)ret << std::endl;
}
else
{
std::cout << "join error: " << n << std::endl;
}
return 0;
}运行结果如下:

除此之外,线程也可以自己将自己分离,分离后主线程同样不需要join。一旦线程要被设置为分离,一般主线程不能提前退,甚至主线程是个死循环。当线程分离后,若出现除0错误等,整个进程依旧会出错退出,分离只是表示主线程不用等待新线程。
线程ID及进程地址空间布局
整体认识
虽然在内核中没有线程的具体结构体,但在pthread库中,为了对线程进行管理,在库中包含了线程的数据结构,如下图所示:
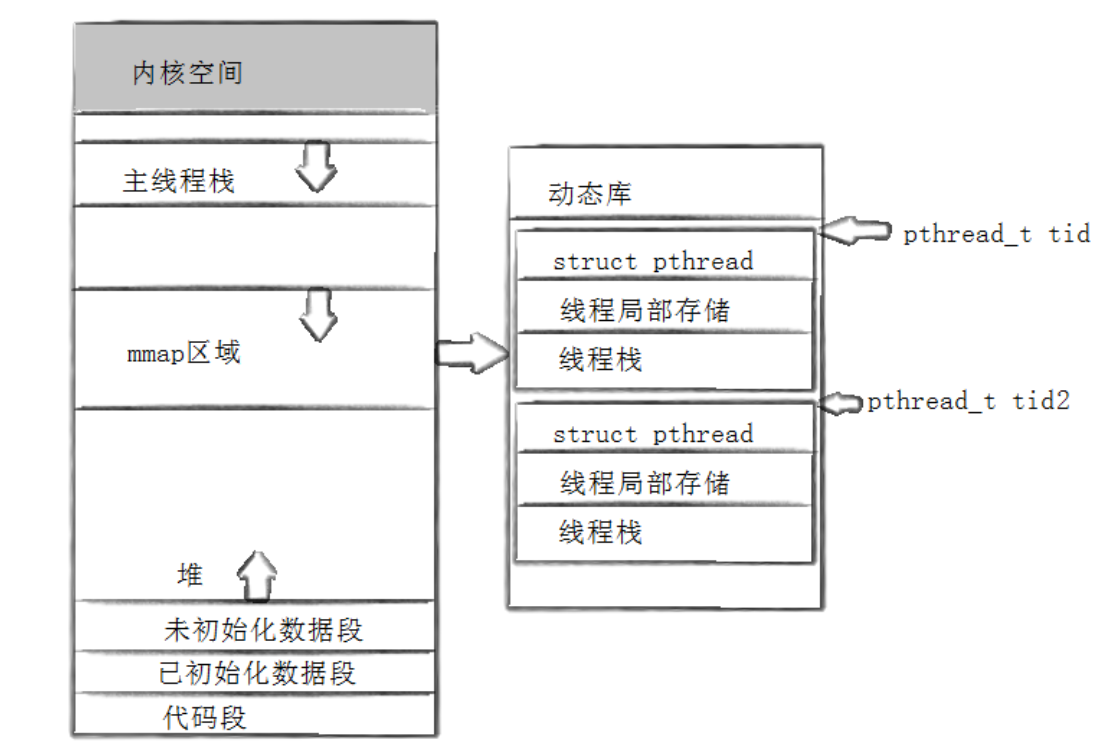
每创建一个线程,就会在库中创建一批这样的属性集,第一个struct pthread,就相当于描述线程的结构体,即TCB,而struct pthread、线程局部存储和线程栈构成的集合有一个起始地址,这个起始地址就是线程id,通过这个id,就可以直接找到对应的TCB。
进程的虚拟地址空间中,会为主线程单独分配一个栈空间,称为主线程栈,这个是属于线程自动申请的;新线程的栈是在自己对应的属性集里,是在动态库中申请的,属于用户级。
当线程退出时,内核级相关数据结构被释放了,但是,库中描述线程的结构体并没有被释放,因此,要通过pthread_join进行回收,如果不处理,就是在库中导致的内存泄漏。只有进行回收,才能获取退出信息,释放掉在库中申请的空间。
局部存储
线程的局部存储就是有些变量只想让线程自己使用,若只想线程自己使用,可以使用__thread关键字,这个关键字是用来进行线程局部存储的,可以将全局变量为每个线程的线程局部存储区域开辟一份,每个线程各自访问各自的,使用示例如下:
cpp
#include <pthread.h>
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <iostream>
#include <cstdlib>
#include <vector>
__thread pid_t id = 0;
void *Routine(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "new thread id : " << id << std::endl;
printf("new thread id: %p\n", &id);
id++;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, Routine, (void *)"thread-1");
while (true)
{
std::cout << "main thread id: " << id << std::endl;
printf("main thread id: %p\n", &id);
sleep(1);
}
return 0;
}运行结果如下:
线程局部存储只能用来存储内置类型,常见的是整形,可以让不同的线程用同样的变量名,访问不同的内存块,各自访问各自的局部存储。
C++多线程
C++中多线程的简单使用如下:
cpp
#include <iostream>
#include <thread>
#include <unistd.h>
void routine(int cnt)
{
while(cnt)
{
std::cout << "new thread: " << cnt <<std::endl;
sleep(1);
cnt--;
}
return ;
}
int main()
{
std::thread t(routine, 10);
while(true)
{
std::cout << "main thread" <<std::endl;
sleep(1);
}
t.join();
return 0;
}运行结果如下:
C++中的线程是具有跨平台性的,在Windows下也可以使用,C++多线程本质是在Linux系统中对pthread库的封装,针对Windows系统和Linux系统中封装的方式不同,C++把所有的平台对应的线程代码都进行了封装,并对外提供统一的接口。