| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之RunnableParallel |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
31、零基础学AI大模型之Milvus索引实战
32、零基础学AI大模型之Milvus DML实战
33、零基础学AI大模型之Milvus向量Search查询综合案例实战
33、零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
34、零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
35、零基础学AI大模型之LangChain整合Milvus:新增与删除数据实战
36、零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析
37、零基础学AI大模型之LangChain Retriever
38、零基础学AI大模型之MultiQueryRetriever多查询检索全解析
39、零基础学AI大模型之LangChain核心:Runnable接口底层实现
40、零基础学AI大模型之RunnablePassthrough
41、零基础学AI大模型之RunnableParallel
本文章目录
-
- 前情摘要
- [1. 什么是RunnableLambda?------ 普通函数的"LangChain通行证"](#1. 什么是RunnableLambda?—— 普通函数的“LangChain通行证”)
-
- [1.1 核心设计初衷](#1.1 核心设计初衷)
- [1.2 类定义简化理解](#1.2 类定义简化理解)
- [2. 核心功能与价值------为什么需要RunnableLambda?](#2. 核心功能与价值——为什么需要RunnableLambda?)
- [3. 与普通函数的核心区别------一张表看懂](#3. 与普通函数的核心区别——一张表看懂)
- [4. API快速上手------3分钟入门](#4. API快速上手——3分钟入门)
-
- [4.1 基础用法:包装函数并调用](#4.1 基础用法:包装函数并调用)
- [4.2 核心方法速查](#4.2 核心方法速查)
- [4.3 关键注意点](#4.3 关键注意点)
- [5. 实战案例------从基础到进阶(5个场景)](#5. 实战案例——从基础到进阶(5个场景))
-
- 案例1:基础文本清洗链(入门)
- 案例2:链中插入日志+敏感词过滤(实用)
- 案例3:异步处理实战(高并发场景)
- 案例4:批量数据处理(大数据量场景)
- [案例5:结合RAG与Output Parser(复杂链路)](#案例5:结合RAG与Output Parser(复杂链路))
- [6. 常见问题与注意事项](#6. 常见问题与注意事项)
-
- [6.1 踩坑指南](#6.1 踩坑指南)
- [6.2 性能优化建议](#6.2 性能优化建议)
- [7. 总结与展望](#7. 总结与展望)
脉脉AI创作者活动推荐
目前脉脉正在进行【AI创作者xAMA】活动,奖励丰富,感兴趣的小伙伴可以在评论区评论哦!


1. 什么是RunnableLambda?------ 普通函数的"LangChain通行证"
在之前的文章中,我们学习了LangChain的链(Chain) 是由多个Runnable对象通过|符号组合而成的(比如 PromptTemplate | ChatModel | OutputParser)。但如果我们想在链中插入自己写的普通Python函数(比如数据清洗、日志记录、调用外部API),直接放进去会报错------因为普通函数不遵守Runnable协议,无法被LangChain的链识别和调用。
这时候,RunnableLambda 就派上用场了!
它的核心定位是:将任意Python函数/可调用对象,快速转换为符合LangChain Runnable 协议的对象,让普通函数拥有"通行证",无缝融入LCEL(LangChain Expression Language)链中。
1.1 核心设计初衷
- 解决"普通函数无法接入LangChain链"的痛点
- 无需复杂封装,一行代码实现函数与LangChain生态的兼容
- 支持自定义逻辑(日志、数据处理、外部系统调用)的灵活插入
1.2 类定义简化理解
python
from langchain_core.runnables import RunnableLambda
# 本质:包装一个函数,让它继承Runnable的所有能力
class RunnableLambda(Runnable[Input, Output]):
def __init__(self, func: Callable[[Input], Output]):
self.func = func # 传入的普通函数
# 实现Runnable的核心方法(invoke/batch/ainvoke等)
def invoke(self, input: Input, config=None) -> Output:
return self.func(input) # 调用原始函数并返回结果简单说:RunnableLambda 就是一个"包装器",把普通函数包一层,让它拥有invoke、batch、ainvoke等Runnable的核心能力。
2. 核心功能与价值------为什么需要RunnableLambda?
RunnableLambda的价值不在于"创造新功能",而在于"打通兼容性",它的核心功能可以总结为3点:
| 核心功能 | 具体说明 | 应用场景 |
|---|---|---|
| 函数转Runnable | 普通函数 → Runnable对象 | 插入LangChain链中执行 |
| 无缝链式组合 | 支持` | `符号与其他Runnable(PromptTemplate、Model、Parser)组合 |
| 原生支持高级特性 | 无需额外编码,自动支持异步(ainvoke)、批量(batch)、流式(stream) | 高并发、大数据量场景 |
3. 与普通函数的核心区别------一张表看懂
很多同学会问:"我直接在链中调用函数不行吗?为什么要多包一层?" 下面用表格清晰对比:
| 特性 | 普通函数 | RunnableLambda包装后 | 关键说明 |
|---|---|---|---|
| 可组合性 | ❌ 无法直接用` | `接入链 | ✅ 支持` |
| 类型校验 | ❌ 无原生支持 | ✅ 支持静态类型检查 | 配合TypeHint,IDE可自动提示参数/返回值类型 |
| 异步支持 | ❌ 需手动实现async | ✅ 原生支持ainvoke |
传入async函数即可异步执行,无需额外封装 |
| 批量处理 | ❌ 需手动循环 | ✅ 原生支持batch |
自动优化批量请求(如批量调用大模型时减少网络开销) |
| LangChain生态兼容 | ❌ 无法接入Chain | ✅ 无缝集成所有Runnable链路 | 可与PromptTemplate、Retriever、Parser等直接组合 |
举个直观例子:
普通函数实现"文本清洗+调用模型"
python
# 嵌套调用,繁琐且不易扩展
def clean_text(x):
return x.strip().lower()
input_text = " Hello LangChain! "
cleaned = clean_text(input_text)
result = model.invoke(cleaned) # 手动传递参数RunnableLambda链式实现
python
# 链式组合,清晰且可扩展
chain = RunnableLambda(clean_text) | model
result = chain.invoke(" Hello LangChain! ") # 自动传递参数4. API快速上手------3分钟入门
4.1 基础用法:包装函数并调用
python
from langchain_core.runnables import RunnableLambda
# 1. 定义普通函数
def log_input(x):
print(f"[日志] 输入内容:{x}")
return x # 必须返回值,供下一个环节使用
# 2. 包装为RunnableLambda
log_runnable = RunnableLambda(log_input)
# 3. 调用(支持invoke/batch/ainvoke)
# 单个调用
log_runnable.invoke("测试输入") # 输出:[日志] 输入内容:测试输入
# 批量调用(自动优化)
log_runnable.batch(["输入1", "输入2", "输入3"])4.2 核心方法速查
| 方法 | 作用 | 示例 |
|---|---|---|
invoke(input) |
单个输入执行 | runnable.invoke("hello") |
batch(inputs) |
批量输入执行 | runnable.batch(["a", "b", "c"]) |
ainvoke(input) |
异步单个执行(需传入async函数) | await runnable.ainvoke("hello") |
astream(input) |
异步流式输出 | async for chunk in runnable.astream("hello") |
4.3 关键注意点
- 包装的函数必须返回值 (否则下一个环节会接收
None) - 函数参数建议保持简洁(输入输出尽量是字符串/字典,便于链传递)
- 若函数有副作用(如写文件、调用外部API),建议做好异常处理
5. 实战案例------从基础到进阶(5个场景)
结合之前学过的LangChain知识,用5个实战案例带你掌握RunnableLambda的核心用法!
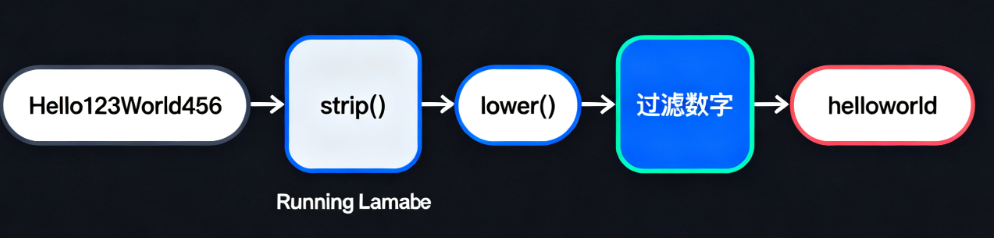
案例1:基础文本清洗链(入门)
需求:去除首尾空格 → 转为小写 → 过滤数字
python
from langchain_core.runnables import RunnableLambda
# 构建链式清洗流程
text_clean_chain = (
RunnableLambda(lambda x: x.strip()) # 去除空格
| RunnableLambda(lambda x: x.lower()) # 转为小写
| RunnableLambda(lambda x: ''.join([c for c in x if not c.isdigit()])) # 过滤数字
)
# 执行
result = text_clean_chain.invoke(" Hello123World456 ")
print(result) # 输出:helloworld案例2:链中插入日志+敏感词过滤(实用)
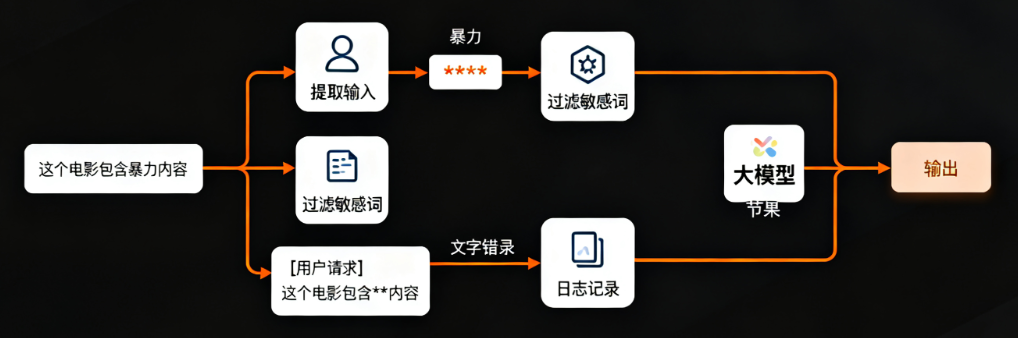
需求:解析用户输入 → 过滤敏感词 → 记录日志 → 调用大模型
python
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
import os
# 1. 配置模型(建议用环境变量存储密钥,避免硬编码)
model = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量读取
temperature=0.7
)
# 2. 自定义函数:过滤敏感词
def filter_sensitive(text: str) -> str:
sensitive_words = ["暴力", "色情", "赌博"]
for word in sensitive_words:
text = text.replace(word, "***")
return text
# 3. 自定义函数:记录请求日志
def log_request(text: str) -> str:
print(f"[用户请求] {text}")
return text
# 4. 构建链(解析输入→过滤→日志→模型)
chain = (
RunnableLambda(lambda x: x["user_input"]) # 从字典中提取输入
| RunnableLambda(filter_sensitive) # 过滤敏感词
| RunnableLambda(log_request) # 记录日志
| model # 调用大模型
)
# 执行
result = chain.invoke({"user_input": "这个电影包含暴力内容"})
print(result.content) # 输出:这个电影包含***内容(大模型处理后的结果)案例3:异步处理实战(高并发场景)
需求:异步调用外部API(如翻译接口),融入链中
python
import asyncio
import aiohttp
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import ChatPromptTemplate
# 1. 异步函数:调用外部翻译API(示例用百度翻译测试)
async def translate_to_en(text: str) -> str:
async with aiohttp.ClientSession() as session:
url = "https://fanyi.baidu.com/sug"
params = {"kw": text}
async with session.get(url, params=params) as resp:
data = await resp.json()
return data["data"][0]["v"] # 简化处理,实际需异常捕获
# 2. 构建链:翻译→Prompt→模型
prompt = ChatPromptTemplate.from_template("解释这个英文短语:{text}")
chain = (
RunnableLambda(translate_to_en) # 异步翻译(传入async函数)
| prompt # 构建Prompt
| model # 调用模型解释
)
# 3. 异步执行
async def main():
result = await chain.ainvoke("你好世界") # 用ainvoke异步调用
print(result.content)
asyncio.run(main())案例4:批量数据处理(大数据量场景)
需求:批量处理10条用户评论,清洗后批量调用模型生成回复
python
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model_name="qwen-plus", api_key=os.getenv("DASHSCOPE_API_KEY"))
# 1. 文本清洗函数
def clean_comment(comment: str) -> str:
return comment.strip().replace("垃圾", "***").replace("卧槽", "**")
# 2. 构建链:清洗→生成回复
chain = (
RunnableLambda(clean_comment)
| ChatPromptTemplate.from_template("回复用户评论:{input}")
| model
)
# 3. 批量执行(自动优化请求,比循环invoke更高效)
comments = [
" 这个产品太垃圾了! ",
"卧槽,体验超差!",
"很好用,推荐!",
# ... 更多评论(共10条)
]
# 批量调用
results = chain.batch(comments)
for idx, res in enumerate(results):
print(f"回复{idx+1}:{res.content}")案例5:结合RAG与Output Parser(复杂链路)
需求:RAG检索后,用RunnableLambda处理检索结果,再通过PydanticOutputParser格式化输出
python
from langchain_core.runnables import RunnableLambda
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_milvus import Milvus
from langchain_core.embeddings import FakeEmbeddings
# 1. 定义输出格式(Pydantic)
class CommentSummary(BaseModel):
sentiment: str = Field(description="情感倾向:正面/负面/中性")
reason: str = Field(description="判断理由")
reply: str = Field(description="回复建议")
parser = PydanticOutputParser(pydantic_object=CommentSummary)
# 2. RAG检索(简化:用FakeEmbeddings模拟)
embeddings = FakeEmbeddings(size=100)
vector_db = Milvus(
embedding_function=embeddings,
connection_args={"uri": "http://localhost:19530"},
collection_name="comments",
)
# 3. 自定义函数:处理检索结果(提取前3条相关评论)
def process_retrieval(results):
comments = [doc.page_content for doc in results[:3]]
return "\n".join(comments)
# 4. 构建链:检索→处理结果→Prompt→模型→解析
chain = (
vector_db.as_retriever() # RAG检索
| RunnableLambda(process_retrieval) # 处理检索结果
| ChatPromptTemplate.from_template("""
分析以下用户评论,按要求输出:
{comments}
{format_instructions}
""")
| model
| parser # 格式化输出
)
# 执行
result = chain.invoke("产品质量相关评论")
print(result.sentiment) # 输出:负面
print(result.reply) # 输出:针对质量问题的回复建议6. 常见问题与注意事项
6.1 踩坑指南
-
函数无返回值导致链中断
❌ 错误:
def log(x): print(x)(无返回值)✅ 正确:
def log(x): print(x); return x(必须返回输入或处理后的值) -
批量处理时函数不支持迭代
若函数只能处理单个输入,
batch会自动循环调用(无需手动处理),但建议确保函数是"无状态"的(不依赖全局变量)。 -
异步函数必须用
ainvoke调用传入async函数时,用
invoke会报错,必须用await ainvoke()或astream()。
6.2 性能优化建议
- 批量处理优先用
batch而非循环invoke(LangChain会自动优化网络请求和资源占用) - 若函数耗时较长(如调用外部API),优先用异步版本(
ainvoke),避免阻塞主线程 - 复杂逻辑建议拆分多个小函数,通过链式组合(便于调试和复用)
7. 总结与展望
RunnableLambda是LangChain中"灵活性的关键"------它让我们摆脱了LangChain内置组件的限制,能够将任意自定义逻辑(数据处理、日志、外部系统调用)无缝融入AI链路中。
核心要点回顾
- 定位:普通函数的"LangChain通行证",实现函数与Runnable的兼容
- 核心价值:可组合性、异步支持、批量处理、生态兼容
- 适用场景:插入自定义逻辑、打通外部系统、数据格式转换、日志监控等
如果本文对你有帮助,欢迎点赞+关注+收藏🌟 ,有任何问题或实战需求,欢迎在评论区留言交流~ 我是工藤学编程,陪你从零到一玩转AI大模型!