一、Agent原理深度解析
根据之前的学习,我们知道了Agent的许多定义,这一章我们总结一个本质公式:
大模型+记忆+工具=Agent
与传统的程序相比,Agent具备下面的特征:
自主性:无需人工干预即可独立运行。
反应性:能对环境变化做出实时响应。
主动性:主动追求目标而非被动响应。
社会性:能与其他Agent或人类进行交互。
接下来介绍一些主流的Agent架构:
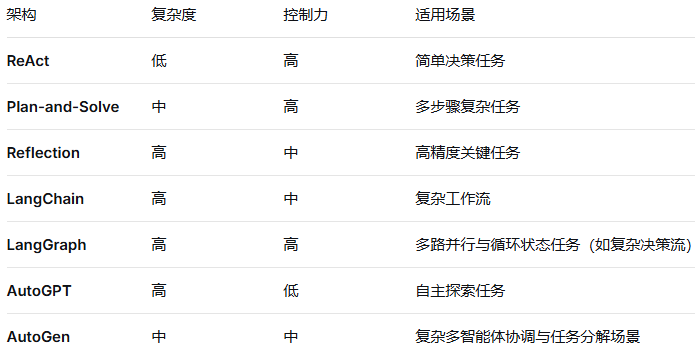
(1) ReAct(推理+行动)
ReAct将思考和行动融合在每个步骤中,通过观察-思考-行动的循环实现决策,适合需要实时响应的动态任务。
(2) Plan-and-Solve(规划-求解)
Plan-and-Solve使用先规划再执行的解耦式架构,制定详细计划计划后严格按照步骤执行,适合需要长远规划的复杂任务。
(3) Reflection(反思优化)
Reflection使用执行-反思-优化的三步循环,通过自我评估和迭代改进提升质量,适合追求高精度的关键任务。
(4) LangChain
LangChain是基于链式调用的Agent框架,支持多种提示模板,拥有丰富的工具集成生态,适合复杂工作流。
(5) LangGraph
LangGraph是基于有向图结构的Agent框架,支持循环与状态管理,拥有灵活的工作流编排能力,适合多路并行与复杂决策任务。
(6) AutoGPT
AutoGPT具有完全自主的目标追求和长期记忆系统,可以进行自我提示生成,适合开放式任务。
(7) AutoGen
AutoGen是基于多智能体对话协作的框架,支持角色定制与自动对话编排,拥有灵活的会话模式管理能力,适合复杂多智能体协调与任务分解场景。
下面是几种架构的对比:
下面我们以ReAct为例对架构进行详解。
二、ReAct架构详解
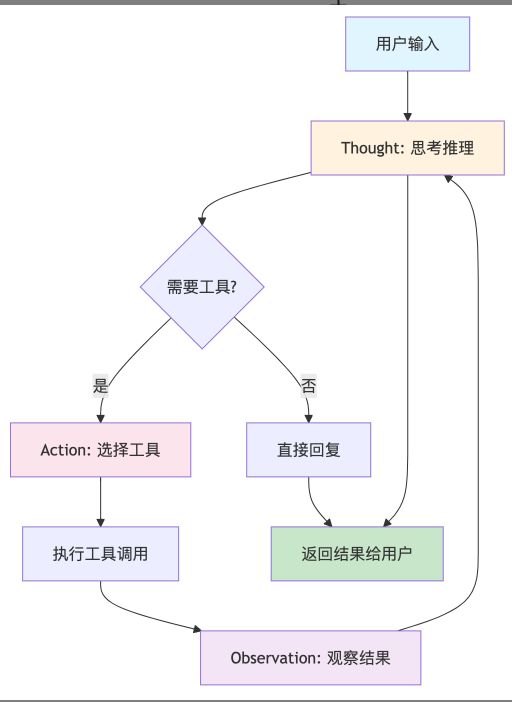
ReAct是目前最简洁有效的Agent架构,其核心思想是:
观察环境-思考推理-采取行动-观察结果-循环
下面给出ReAct的流程图:
接下来给出一个示例:
用户:"北京天气如何?"
Thought:用户询问天气,需要获取北京当前天气信息
Action:weather_query(location="北京")
Observation:{"temperature": 25, "condition": "晴"}
Thought:已获得天气数据,可以回复用户
Action:回复"北京今天25度,晴天"三、从零实现最简React Agent
首先我们需要进行环境准备。
openai
requests
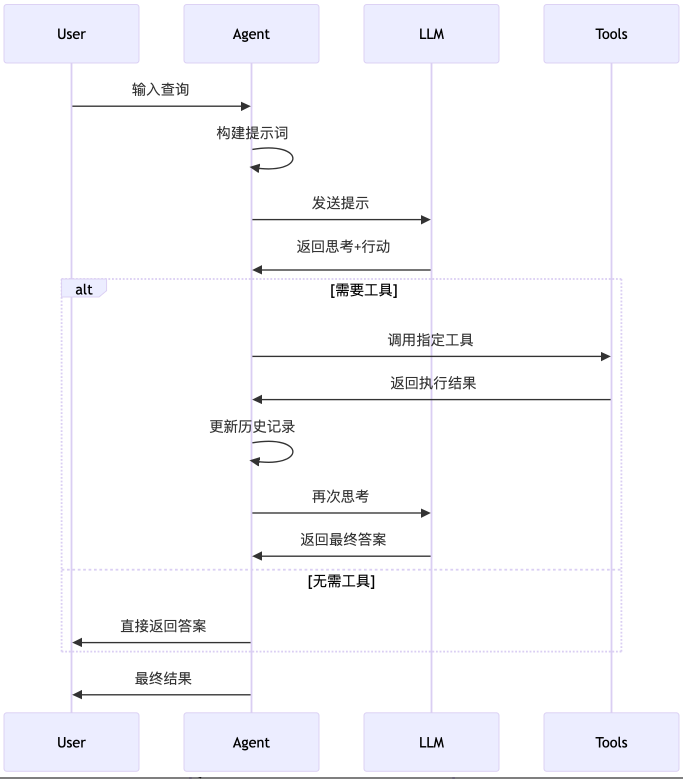
json5下面我们给出Agent内部数据流示意图。
Step 1:构造大模型
首先我们需要一个大模型,这里我们使用Qwen3-30B-A3B-Instruct-2507作为我们的Agent模型(注意尽量使用Instruct模型)。我们先创建一个BaseModel类,我们可以在这个类中定义一些基本的方法,比如chat方法,方便以后扩展使用其他模型。
python
class BaseModel:
def __init__(self, api_key: str = '') -> None:
self.api_key = api_key
def chat(self, prompt: str, history: List[Dict[str, str]], system_prompt: str = "") -> Tuple[str, List[Dict[str, str]]]:
"""
基础聊天接口
Args:
prompt (str): 用户输入的提示信息
history (List[Dict[str, str]]): 聊天历史记录
system_prompt (str): 系统提示信息
Returns:
(模型响应, 更新后的对话历史)
"""
pass接下来,我们创建一个Siliconflow类,这个类继承自BaseModel类,我们在这个类中实现chat方法。我们通过硅基流动平台调用模型。
python
class Siliconflow(BaseModel):
def __init__(self, api_key: str):
self.api_key = api_key
self.client = OpenAI(api_key=self.api_key, base_url="https://api.siliconflow.cn/v1")
def chat(self, prompt: str, history: List[Dict[str, str]] = [], system_prompt: str = "") -> Tuple[str, List[Dict[str, str]]]:
"""
与Siliconflow API 进行聊天
Args:
prompt (str): 用户输入的提示信息
history (List[Dict[str, str]]): 聊天历史记录
system_prompt (str): 系统提示信息
Returns:
(模型响应, 更新后的对话历史)
"""
# 构建消息列表
messages = [
{"role": "system", "content": system_prompt or "You are a helpful assistant."}
]
# 添加历史记录
if history:
messages.extend(history)
# 添加当前用户提示
messages.append({"role": "user", "content": prompt})
# # 调用API
response = self.client.chat.completions.create(
model = "Qwen/Qwen3-30B-A3B-Instruct-2507",
messages=messages,
temperature=0.6,
max_tokens=2000,
)
model_response = response.choices[0].message.content
# 更新对话历史
updated_history = messages.copy()
updated_history.append({"role": "assistant", "content": model_response})
return model_response, updated_historyStep 2:构造工具
下面我们构造一些工具,这里以Google搜索为例。我们构造一个Tools类。在这个类中,我们需要添加一些工具的描述信息和具体实现方式。添加工具的描述信息,是为了构造system_prompt的时候,让模型能够知道可以调用哪些工具,以及工具的描述信息和参数。
python
class ReactTools:
"""
React Agent 工具集
为ReAct Agent 提供各种工具函数
"""
def __init__(self) -> None:
self.toolConfig = self._build_tool_config()
def _build_tool_config(self) -> List[Dict[str, Any]]:
"""
构建工具配置信息
"""
return [
{
'name_for_human': '谷歌搜索',
'name_for_model': 'google_search',
'description_for_model': '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等',
'parameters': [
{
'name': 'search_query',
'description': '搜索关键词或短语',
'required': True,
'schema': {'type': 'string'},
}
]
}
]
def google_search(self, search_query: str) -> str:
"""
执行谷歌搜索
Args:
search_query: 搜索关键词
Returns:
格式化的搜索结果字符串
"""
url = "https://google.serper.dev/search"
payload = json.dumps({"q": search_query})
headers = {
'X-API-KEY': '',
'Content-Type': 'application/json'
}
try:
response = requests.request("POST", url, headers=headers, data=payload).json()
organic_results = response.get('organic', [])
# 格式化搜索结果
formatted_results = []
for idx, result in enumerate(organic_results[:5], 1):
title = result.get('title', '无标题')
snippet = result.get('snippet', '无描述')
link = result.get('link', '')
formatted_results.append(f"{idx}. **{title}**\n {snippet}\n 链接:{link}")
return "\n\n".join(formatted_results) if formatted_results else "未找到相关结果"
except Exception as e:
return f"搜索时出现错误: {str(e)}"
def get_available_tools(self) -> List[str]:
"""获取可用工具名称列表"""
return [tool['name_for_model'] for tool in self.toolConfig]
def get_tool_description(self, tool_name: str) -> str:
"""获取工具描述"""
for tool in self.toolConfig:
if tool['name_for_model'] == tool_name:
return tool['description_for_model']
return "未知工具"Step 3: 构造React Agent
React Agent是整个系统的协调者,负责管理LLM调用、工具执行和状态维护。下面我们来进行实现。
3.1 核心组件设计
React Agent采用了分层架构模式:
接口层:对外暴露简单的run()方法
协调层:管理思考-行动-观察的循环
解析层:从模型输出中提取结构化信息
执行层:调用具体工具完成任务
3.2 系统提示构建
系统提示是React Agent的大脑,它直接决定了Agent的行为模式。一个好的系统提示应该包括:
时间信息:让Agent知道当前时间,避免过时信息
工具清单:明确告诉Agent有哪些工具可用
行为模式:详细的ReAct流程指导
输出格式:规范化的思考-行动-观察格式
这里我们使用f-string动态生成系统提示,这样可以自动包含当前时间、动态加载可用工具列表、保持提示的时效性和准确性。
下面是系统提示模板:
python
prompt = f"""现在时间是 {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())}。你是一位智能助手,可以使用以下工具来回答问题:
{chr(10).join(tool_names)}
请遵循以下ReAct模式:
思考:分析问题和需要使用的工具
行动:选择工具[{','.join(tool_names)}]中的一个
行动输入:提供工具的参数
观察:工具返回的结果
你可以重复以上循环,直到获得足够的信息来回答问题。
最终答案:基于所有信息给出最终答案
开始!"""3.3 行动解析机制
实际应用中,大模型的输出格式往往不够规范,可能出现:
中英文混合的冒号
JSON格式不规范
参数缺失或格式错误
多余的空格或换行
因此,我们需要一个鲁棒的解析机制。
下面是我们的解析思路:
多层匹配:先用正则提取,再用JSON解析
容错设计:解析失败时提供降级方案
格式兼容:支持JSON字符串和纯文本参数
下面是实现代码:
python
def _parse_action(self, text: str, verbose: bool = False) -> tuple[str, dict]:
"""从文本中解析行动和行动输入"""
# 更灵活的正则表达式模式
action_pattern = r"行动[:: ]\s*(\w+)"
action_input_pattern = r"行动输入[:: ]\s*({.*?}|\{.*?\}|[^\n]*)"
action_match = re.search(action_pattern, text, re.IGNORECASE)
action_input_match = re.search(action_input_pattern, text, re.DOTALL)
action = action_match.group(1).strip() if action_match else ""
action_input_str = action_input_match.group(1).strip() if action_input_match else ""
# 清理和解析JSON
action_input_dict = {}
if action_input_str:
try:
# 尝试解析为JSON对象
action_input_str = action_input_str.strip()
if action_input_str.startswith('{') and action_input_str.endswith(')'):
action_input_dict = json5.load(action_input_str)
else:
# 如果不是JSON格式,尝试解析为简单字符串参数
action_input_dict = {"search_query": action_input_str.strip('"\'')}
except Exception as e:
if verbose:
print(f"[ReAct Agent] 解析参数失败,使用字符串作为搜索查询:{e}")
action_input_dict = {"search_query": action_input_str.strip('"\'')}
return action, action_input_dict3.4 ReAct主循环
ReAct循环是Agent的心跳,它能让Agent基于新信息不断调整策略,然后在需要时主动获取外部信息,最后将工具结果与已有知识结合。
整个循环有以下四个阶段:
思考阶段:模型分析问题,决定是否需要工具
行动阶段:选择合适的工具并提供参数
观察阶段:执行工具并获取结果
整合阶段:将信息整合到上下文中
在run函数中我们加入了max_iterations参数,这个参数可以防止模型陷入死循环、限制API调用次数并且避免过长的响应时间。
在每次循环的时候都需要保持上下文、更新输入并且保留历史记录。
python
def run(self, query: str, max_iterations: int = 3, verbose: bool = True) -> str:
"""运行ReAct Agent
Args:
query: 用户查询
max_iterations: 最大迭代次数
verbose: 是否显示中间执行过程
"""
conversation_history = []
current_text = f"问题:{query}"
# 绿色ANSI颜色代码
GREEN = '\033[92m'
RESET = '\033[0m'
if verbose:
print(f"{GREEN}[ReAct Agent] 开始处理问题:{query}{RESET}")
for iteration in range(max_iterations):
if verbose:
print(f"{GREEN}[ReAct Agent] 第 {iteration + 1} 次思考...{RESET}")
# 获取模型响应
response, history = self.model.chat(
current_text,
conversation_history,
self.system_prompt
)
if verbose:
print(f"{GREEN}[ReAct Agent] 模型响应:\n{response}{RESET}")
# 解析行动
action, action_input = self._parse_action(response, verbose=verbose)
if not action or action == "最终答案":
final_answer = self._format_response(response)
if verbose:
print(f"{GREEN}[ReAct Agent] 无需进一步行动,返回最终答案{RESET}")
return final_answer
if verbose:
print(f"{GREEN}[ReAct Agent] 执行行动: {action} | 参数:{action_input}{RESET}")
# 执行行动
observation = self._execute_action(action, action_input)
if verbose:
print(f"{GREEN}[ReAct Agent] 观察结果:\n{observation}{RESET}")
# 更新当前文本以继续对话
current_text = f"{response}\n观察结果:{observation}\n"
conversation_history = history
# 达到最大迭代次数,返回当前响应
if verbose:
print(f"{GREEN}[ReAct Agent] 达到最大迭代次数,返回当前响应{RESET}")
return self._format_response(response)下面是运行结果:
