目录
-
- 一、研究背景与意义
- 二、时间序列异常检测基础概念
- [三、时间序列异常检测方法分类(过程中心分类学 taxonomy)](#三、时间序列异常检测方法分类(过程中心分类学 taxonomy))
- 四、方法演化与元分析(1980-2023)
- 五、评估基准与度量
-
- [(一)主流基准数据集(Table 4)](#(一)主流基准数据集(Table 4))
- (二)评估度量
- 六、研究挑战与未来方向
- `基于流程的时间序列异常检测分类法:三大类方法的二级子类别及核心原理差异`
-
- 一、距离基方法(Distance-based)
-
- [1. 二级子类别及核心原理](#1. 二级子类别及核心原理)
- 二、密度基方法(Density-based)
-
- [1. 二级子类别及核心原理](#1. 二级子类别及核心原理)
- 三、预测基方法(Prediction-based)
-
- [1. 二级子类别及核心原理](#1. 二级子类别及核心原理)
- 二、三大类方法及子类别核心原理差异总结
- `时间序列异常检测评估指标分析:优缺点与选择策略`
-
- 一、两类评估指标的核心定义与分类
- 二、阈值依赖型评估指标:优缺点与适用场景
-
- [1. 核心优缺点](#1. 核心优缺点)
- [2. 典型指标及场景补充](#2. 典型指标及场景补充)
- 三、阈值独立型评估指标:优缺点与适用场景
-
- [1. 核心优缺点](#1. 核心优缺点)
- [2. 典型指标及场景补充](#2. 典型指标及场景补充)
- 四、实际应用中的评估指标选择策略
-
- [1. 优先考虑业务决策需求](#1. 优先考虑业务决策需求)
- [2. 结合数据特性选择](#2. 结合数据特性选择)
- [3. 考虑评估场景(离线vs.实时)](#3. 考虑评估场景(离线vs.实时))
- [4. 避免单一指标依赖,采用"核心指标+辅助指标"组合](#4. 避免单一指标依赖,采用“核心指标+辅助指标”组合)
- 五、总结
- `时间序列异常检测基准数据集差异及对方法选择的影响`
-
- 一、核心基准数据集的关键差异
-
- [1. 数据集核心属性对比表](#1. 数据集核心属性对比表)
- [2. 关键差异维度分类](#2. 关键差异维度分类)
- 二、数据集差异对异常检测方法选择的影响
-
- [1. 方法的"维度兼容性":单变量 vs 多变量](#1. 方法的“维度兼容性”:单变量 vs 多变量)
- [2. 方法的"序列建模能力":点异常 vs 子序列异常](#2. 方法的“序列建模能力”:点异常 vs 子序列异常)
- [3. 方法的"扩展性需求":小规模 vs 大规模数据](#3. 方法的“扩展性需求”:小规模 vs 大规模数据)
- [4. 方法的"监督模式适配性":无监督 vs 半监督](#4. 方法的“监督模式适配性”:无监督 vs 半监督)
- [5. 方法的"可解释性匹配":纯精度 vs 可解释性](#5. 方法的“可解释性匹配”:纯精度 vs 可解释性)
- 三、总结:方法选择的核心决策路径
- `特定时间序列异常检测任务的方法选择指南`
-
- 一、先明确任务核心约束:四大关键维度定位
-
- [1. 数据特性:维度与规模](#1. 数据特性:维度与规模)
- [2. 异常类型:点/上下文/集体异常](#2. 异常类型:点/上下文/集体异常)
- [3. 监督模式:无监督/半监督/有监督](#3. 监督模式:无监督/半监督/有监督)
- [4. 任务需求:实时性、可解释性、鲁棒性](#4. 任务需求:实时性、可解释性、鲁棒性)
- 二、方法选择的五步决策流程
- 三、典型场景的方法选择案例
- 四、常见误区与避坑指南
- 五、总结
一、研究背景与意义
- 时间序列数据增长驱动需求:随着数据采集技术的进步,流数据的体量和速度持续上升,时间序列分析的重要性日益凸显。时间序列异常检测作为关键任务,在网络安全、金融市场、执法、医疗健康等多个领域有重要应用,例如医疗领域的心电图异常心跳检测、工业领域的设备故障预警等。
- 传统研究的局限与新需求:传统异常检测文献以统计度量为核心,而近年来机器学习算法数量激增,亟需一套结构化、通用的时间序列异常检测研究方法表征体系,以解决不同研究社区方法分散、评估基准不统一等问题。
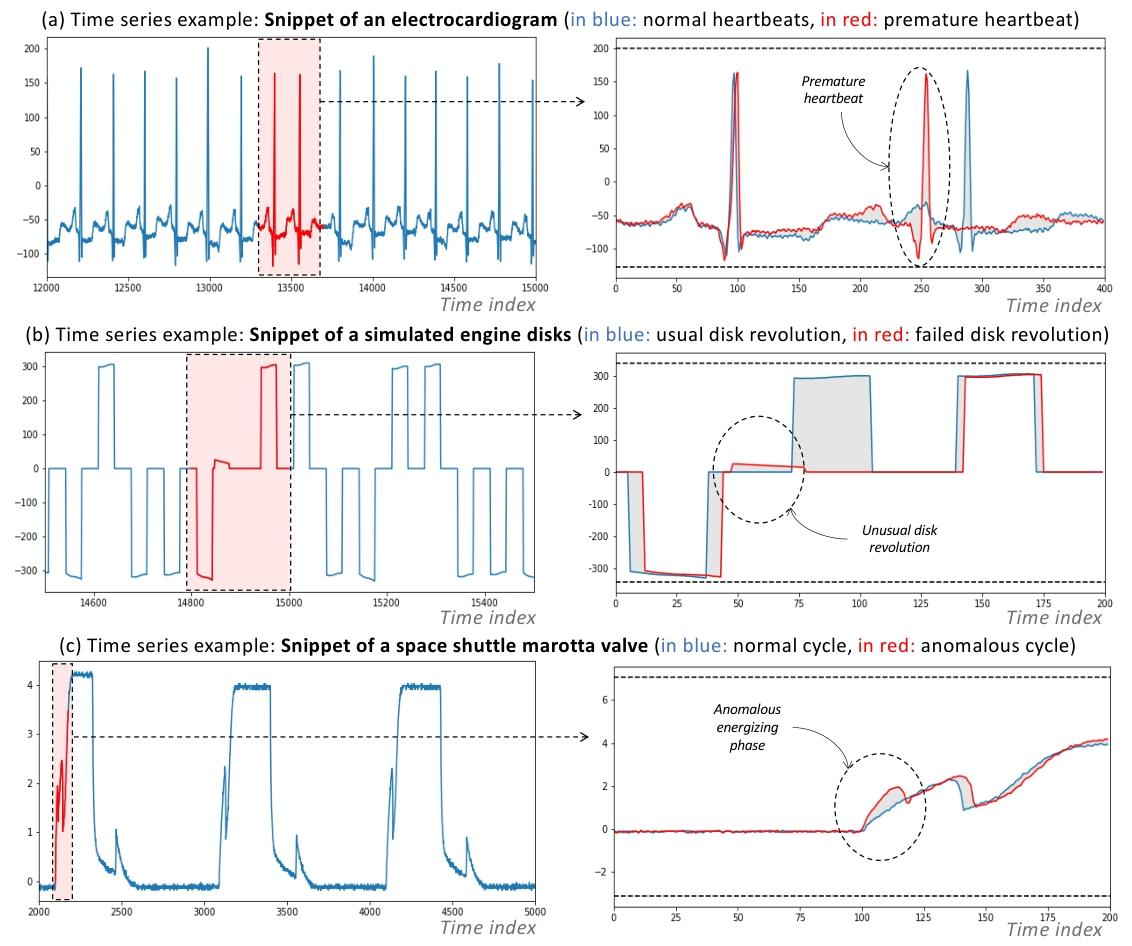
图1所示。不同时间序列应用和异常类型的示例。
论文:Dive into Time-Series Anomaly Detection: A Decade Review
作者 & 单位:PAUL BONIOL, Inria, DI ENS, PSL, CNRS, France QINGHUA LIU, The Ohio State University, USA MINGYI HUANG, The Ohio State University, USA THEMIS PALPANAS, Université Paris Cité; IUF, France JOHN PAPARRIZOS, The Ohio State University, USA请各位同学给我点赞,激励我创作更好、更多、更优质的内容!^_^
关注微信公众号 ,获取更多资讯

二、时间序列异常检测基础概念
(一)异常的定义与分类
- 异常定义:指不符合"正常性"概念或基于历史观测数据的预期行为的数据点或数据组,也被称为离群值、新奇值等。根据应用场景,异常可分为两类:一是干扰数据分析的噪声或错误数据,需去除或修正;二是具有实际意义的异常事件数据,可作为后续分析的基础。
- 异常类型(基于时间序列特性)
- 点异常(Point Anomalies):单个数据点显著偏离其他数据,如某一时刻的数值超出正常范围(图2(a))。
- 上下文异常(Contextual Anomalies):数据点在整体分布的正常范围内,但在特定上下文(如局部窗口)中偏离预期分布(图2(b))。
- 集体异常(Collective Anomalies):序列数据组不重复以往观察到的典型模式,单个数据点可能正常,但整体序列异常(图2©)。
- 其他分类维度
- 数据维度:单变量时间序列(仅单个特征维度)和多变量时间序列(多个特征维度,需综合多特征判断异常)。
- 监督方式:无监督(无异常标注,自动检测未知异常)、半监督(仅基于正常数据标注训练)、有监督(有明确异常标注样本训练)。
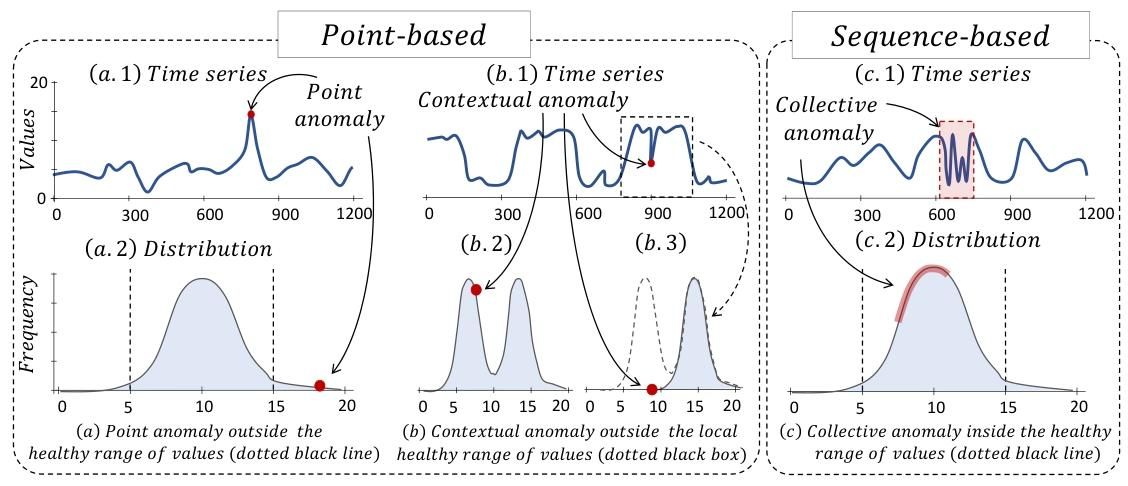
图2. 三种时间序列异常类型的合成示意图:(a)点异常;(b)上下文异常;(c)集体异常。
(二)异常检测流程
时间序列异常检测遵循统一流程,分为四步(图4):
- 数据预处理:将时间序列通过滑动窗口转换为矩阵,再进行统计特征提取、机器学习模型拟合等额外处理。
- 检测方法执行:对处理后的数据应用检测方法,如计算子序列距离、拟合分类超平面、生成并对比重构子序列等。
- 异常评分:将检测结果转换为异常分数(如异常概率),评估子序列异常程度,并推导单个数据点的分数,形成与原时间序列长度一致的分数序列。
- 后处理:设定阈值,将异常分数超过阈值的数据点或区间标记为异常。
三、时间序列异常检测方法分类(过程中心分类学 taxonomy)
(一)基于距离的方法(Distance-based)
- 核心思想:直接利用原始时间序列的距离度量检测异常,不额外修改数据(如去除季节性),常用距离包括欧氏距离、Z-归一化欧氏距离、动态时间规整(DTW)等。
- 子类方法
- 近邻基于(Proximity-based):通过子序列与其近邻的距离判断异常,如K近邻(KNN)计算第k个近邻的距离作为异常分数,局部离群因子(LOF)基于局部密度判断离群程度。
- 聚类基于(Clustering-based):对时间序列子序列聚类,通过子序列与聚类中心的距离、聚类成员关系等评估异常,如K-means(基于聚类中心距离)、DBSCAN(标记非核心/非边界点为异常)。
- 不和谐基于(Discord-based):识别"不和谐子序列(Discord)",即近邻距离最大的子序列,如矩阵轮廓(Matrix Profile)通过计算子序列与其最近邻的距离构建元数据,快速定位Top-k异常。
(二)基于密度的方法(Density-based)
- 核心思想:将时间序列映射为复杂结构(图、树、直方图等),通过度量数据点或子序列空间的密度检测异常。
- 子类方法
- 分布基于(Distribution-based):基于正常子序列的统计特征构建分布模型,如最小协方差行列式(MCD)、单类支持向量机(OCSVM)、直方图异常评分(HBOS)。
- 图基于(Graph-based):将子序列表示为图节点,边表示子序列间的转移频率,通过图特征(节点权重、边权重)检测异常,如Series2Graph(图14)、有限状态机(FSM)。
- 树基于(Tree-based):用树结构划分数据,通过树的特性(如深度)判断异常,如孤立森林(IForest)通过随机划分隔离异常点。
- 编码基于(Encoding-based):将时间序列压缩为符号或 latent 空间表示,如主成分分析(PCA)、隐马尔可夫模型(HMM)、贝叶斯网络(Dynamic Bayesian Network)。
(三)基于预测的方法(Prediction-based)
- 核心思想:基于训练数据预测正常行为,通过预测误差(或重构误差)作为异常分数,假设正常数据易预测,异常数据预测误差大,适用于半监督场景。
- 子类方法
- 预测基于(Forecasting-based):用历史数据预测未来值,通过预测值与实际值的误差判断异常,如指数平滑(ES/DES/TES)、ARIMA、长短期记忆网络(LSTM)、门控循环单元(GRU)。
- 重构基于(Reconstruction-based):将时间序列压缩到 latent 空间再重构,通过输入与重构的误差判断异常,如自编码器(Autoencoder)、生成对抗网络(GAN)(图18、19)。
四、方法演化与元分析(1980-2023)
- 方法数量趋势:1990-2016年方法数量稳定,2016年后显著增长,主要由基于预测的方法(尤其是LSTM和自编码器)推动,占2020-2023年新方法的近50%(图20)。
- 数据维度趋势:1990-2016年多变量方法为主,2016年后单变量方法增多,因子序列异常检测在多变量场景中定义更复杂(图21右)。
- 监督方式趋势:1980-2000年无监督方法占65%,2012-2018年无监督方法占比降至50%,半监督方法因对标注需求适中,应用逐渐广泛(图21左)。
五、评估基准与度量
(一)主流基准数据集(Table 4)
| 基准名称 | 时间序列数量 | 平均长度 | 平均异常数 | 平均异常长度 | 维度 | 异常类型 |
|---|---|---|---|---|---|---|
| NAB | 58 | 6301.7 | 2 | 287.8 | 单变量 | 点+子序列 |
| Yahoo | 367 | 1561.2 | 5.9 | 1.8 | 单变量 | 点+子序列 |
| Exathlon | 93 | 25115.9 | 1 | 9537.6 | 多变量 | 子序列 |
| TimeEval | 976 | 30991 | 5.5 | 106.7 | 单+多变量 | 点+子序列 |
| TSB-AD | 1070(精选) | 105485.2 | 104.2 | 409.5 | 单+多变量 | 点+子序列 |
- 基准局限性:部分数据集存在 triviality、异常密度不真实、标签错误、"故障前偏差"等问题,TSB-AD 作为最新基准,通过人工标注+模型辅助提升可靠性。
(二)评估度量
- 基于阈值的度量:需设定阈值分类正常/异常,包括精确率(Precision)、召回率(Recall)、F分数(F-Score)、假阳性率(FPR)等,需注意"点调整"以应对连续异常,但可能高估性能。
- 无阈值的度量 :无需设定阈值,综合所有可能阈值的性能,包括:
- AUC-ROC/AUC-PR:ROC曲线(TPR vs FPR)或PR曲线(Precision vs Recall)下面积,适用于点异常。
- Range-AUC:扩展ROC/PR曲线,通过异常边界缓冲区域适配子序列异常,解决标签容忍度和时间滞后问题。
- 表面下体积(VUS):计算不同缓冲长度的Range-AUC,构建三维表面体积,无参数依赖,适用于点和子序列异常。
六、研究挑战与未来方向
- 基准统一:目前无社区公认的统一基准,现有基准在时间序列多样性、异常类型、标签可靠性上存在局限,需建立通用对比基础。
- 模型集成与选择:无单一方法在所有数据集上最优,未来需研究集成学习、模型选择、AutoML,提升泛化性能(如简单分类基线可使异常检测精度提升2倍)。
- 复杂场景适配:现有方法多关注单变量无缺失数据,需加强对多变量、流数据、含缺失值、非连续时间戳、异构时间序列的异常检测研究。
基于流程的时间序列异常检测分类法:三大类方法的二级子类别及核心原理差异
该综述提出的基于流程的时间序列异常检测分类法 ,将主流方法划分为距离基(Distance-based) 、密度基(Density-based) 和预测基(Prediction-based) 三大类,每类下又包含多个二级子类别。不同子类别方法的核心原理差异主要体现在"如何表征时间序列特征""如何定义'异常'"以及"如何计算异常分数"三个维度,具体如下:
一、距离基方法(Distance-based)
核心思想:直接利用距离度量(如欧氏距离、动态时间规整DTW)分析时间序列子序列的相似性,通过"子序列与邻居/聚类的距离"判断异常。适用于时间序列的数值特征可直接比较的场景,不依赖复杂数据结构转换。
1. 二级子类别及核心原理
| 二级子类别 | 核心原理 | 关键特点与典型方法 |
|---|---|---|
| 邻近基(Proximity-based) | 以"子序列与其近邻的孤立程度"为异常判定标准:孤立性越强(与近邻距离越远),异常概率越高。 | - 不依赖全局分布,仅关注局部邻居关系; - 典型方法:K近邻(KNN)、局部异常因子(LOF)。 - KNN:计算子序列到第k个近邻的距离作为异常分数,距离越大越异常; - LOF:通过"局部可达密度"(邻居密度与自身密度的比值)量化异常,比值>1表示更可能是异常。 |
| 聚类基(Clustering-based) | 先将子序列聚类(划分成多个簇),再通过"子序列与所属簇的契合度"判断异常:契合度越低(与簇中心距离越远),异常概率越高。 | - 依赖簇的划分质量,需预先定义簇数量或密度阈值; - 典型方法:K均值(K-means)、DBSCAN、CBLOF。 - K-means:将子序列分配到最近簇,以"子序列到簇中心的距离"为异常分数; - DBSCAN:通过"核心点/边界点/噪声点"分类,噪声点即为异常(无所属簇)。 |
| 不和谐基(Discord-based) | 专门针对时间序列设计,定义"不和谐子序列(Discord)"为"与所有其他子序列的最近邻距离最大的子序列",通过搜索这类子序列检测异常。 | - 是邻近基方法的时间序列专属扩展,优化了时间序列子序列的距离计算效率; - 典型方法:HOT SAX、Matrix Profile(矩阵轮廓)。 - Matrix Profile:为每个子序列计算"到最近非重叠子序列的距离",距离最大的子序列即为顶级异常。 |
二、密度基方法(Density-based)
核心思想:不直接使用原始数值距离,而是先将时间序列转换为密度相关的复杂表征(如分布、图、树、符号编码),再通过"子序列在表征空间中的密度"判断异常(密度越低越可能是异常)。适用于时间序列存在复杂结构(如周期性、非线性)或需捕捉全局模式的场景。
1. 二级子类别及核心原理
| 二级子类别 | 核心原理 | 关键特点与典型方法 |
|---|---|---|
| 分布基(Distribution-based) | 假设"正常子序列服从特定统计分布",通过"子序列在分布中的概率"判断异常:概率越低(偏离分布越远),异常概率越高。 | - 依赖统计分布假设(如正态分布、混合分布),需先从正常数据中学习分布参数; - 典型方法:最小协方差行列式(MCD)、单类支持向量机(OCSVM)、直方图异常分数(HBOS)。 - MCD:找到"最不可能包含异常的子序列子集",用马氏距离计算子序列到该子集分布的距离作为异常分数; - HBOS:对每个维度构建直方图,子序列的异常分数为"各维度直方图频率的倒数乘积",频率越低分数越高。 |
| 图基(Graph-based) | 将时间序列子序列映射为图结构(节点=子序列/模式,边=子序列间的转换关系),通过"子序列在图中的拓扑特征"判断异常:拓扑重要性越低(如节点度小、边权重低),异常概率越高。 | - 需先构建图结构,能捕捉子序列的时序转换模式; - 典型方法:Series2Graph、有限状态机(FSM)。 - Series2Graph:节点代表"频繁出现的子序列模式",边代表"模式间的转换频率",异常子序列对应图中"低权重边连接的节点"; - FSM:通过状态转移规则(如斜率聚类后的转换)定义正常行为,违反规则的子序列即为异常。 |
| 树基(Tree-based) | 将子序列通过树结构(如孤立树、决策树)划分,通过"子序列在树中的隔离难度"判断异常:隔离难度越低(树深度越小),异常概率越高。 | - 无需预设分布,通过随机划分实现高效隔离; - 典型方法:孤立森林(IForest)、IF-LOF。 - IForest:构建多棵孤立树,异常子序列因"数值特殊"能更快被隔离(树深度小),异常分数由平均树深度计算; - IF-LOF:结合IForest的隔离能力与LOF的局部密度分析,先筛选候选异常,再用LOF细化。 |
| 编码基(Encoding-based) | 将时间序列编码为低维符号/ latent空间(如符号聚合近似SAX、主成分PCA),通过"编码后的表征与正常模式的契合度"判断异常:契合度越低(重构误差越大),异常概率越高。 | - 需先完成编码转换,能压缩冗余信息、突出关键模式; - 典型方法:SAX+语法归纳、PCA、隐马尔可夫模型(HMM)。 - SAX+语法归纳:将时间序列离散为符号序列,用语法规则描述正常模式,不匹配规则的符号段即为异常; - PCA:通过主成分还原正常数据,子序列的"还原误差"(原始与还原值的差)作为异常分数,误差越大越异常。 |
三、预测基方法(Prediction-based)
核心思想:假设"正常时间序列具有可预测性,异常序列因违背规律导致预测误差更大",通过"预测/重构误差"判断异常。适用于时间序列存在时序依赖性(如趋势、周期性)的场景,且多为半监督学习(仅用正常数据训练)。
1. 二级子类别及核心原理
| 二级子类别 | 核心原理 | 关键特点与典型方法 |
|---|---|---|
| 预测基(Forecasting-based) | 训练模型预测"未来时间步的数值/子序列",通过"预测值与真实值的误差"判断异常:误差越大(预测越不准),异常概率越高。 | - 依赖时序预测能力,需捕捉时间序列的动态依赖(如趋势、周期性); - 典型方法:指数平滑(ES)、ARIMA、长短期记忆网络(LSTM)。 - ARIMA:基于线性自回归模型预测未来值,用"预测值与真实值的残差"作为异常分数; - LSTM:通过深度学习捕捉非线性时序依赖,预测误差越大,说明子序列越偏离正常模式(异常)。 |
| 重构基(Reconstruction-based) | 训练模型将子序列压缩到 latent空间再重构,通过"原始子序列与重构子序列的误差"判断异常:误差越大(重构越不准),异常概率越高。 | - 依赖压缩-重构能力,正常子序列因"符合模型学习的正常模式"重构误差小; - 典型方法:自编码器(AE)、变分自编码器(VAE)、生成对抗网络(GAN)。 - AE:通过编码器-解码器结构学习正常子序列的 latent表征,重构误差大的子序列即为异常; - GAN:生成器学习生成正常子序列,判别器区分"真实正常"与"生成/异常",异常子序列因无法被生成器模拟而被判别为异常。 |
二、三大类方法及子类别核心原理差异总结
| 对比维度 | 距离基方法 | 密度基方法 | 预测基方法 |
|---|---|---|---|
| 数据表征方式 | 直接使用原始子序列的数值特征,不依赖结构转换 | 将子序列转换为分布、图、树、符号等复杂结构,再分析密度 | 不直接表征子序列,而是通过"预测/重构模型"隐式学习正常模式 |
| 异常定义逻辑 | 异常="与近邻/聚类距离远的子序列" | 异常="在表征空间中密度低的子序列" | 异常="预测/重构误差大的子序列" |
| 依赖假设 | 正常子序列的数值相似性高,异常子序列与邻居差异显著 | 正常子序列在表征空间中形成高密度区域,异常子序列孤立于这些区域 | 正常子序列具有时序可预测性,异常子序列违背该可预测性 |
| 适用场景 | 数值特征明确、无复杂结构的时间序列(如简单传感器数据) | 存在复杂模式(如周期性、非线性)或需全局分析的时间序列(如金融交易数据) | 具有强时序依赖性的时间序列(如心电图、工业设备监控数据) |
| 典型局限 | 对高维时间序列计算效率低,对噪声敏感 | 依赖表征质量(如聚类/图的划分),参数调优复杂 | 需足够多的正常数据训练模型,对非时序性异常(如突发值)检测能力弱 |
时间序列异常检测评估指标分析:优缺点与选择策略
在时间序列异常检测领域,评估指标的选择直接影响模型性能判断的准确性。文中将评估指标分为阈值依赖型 与阈值独立型两类,二者在计算逻辑、适用场景上存在显著差异,以下从优缺点分析、实际选择策略两方面展开详细说明。
一、两类评估指标的核心定义与分类
在深入分析前,需明确两类指标的核心逻辑:
- 阈值依赖型评估:需先设定异常分数阈值(如"异常分数>3倍标准差"),将连续的异常分数转化为"正常/异常"的二元标签,再基于混淆矩阵(TP、TN、FP、FN)计算指标。
- 阈值独立型评估:无需预设阈值,通过遍历所有可能阈值并整合性能结果,直接反映模型在全阈值范围内的综合表现。
二、阈值依赖型评估指标:优缺点与适用场景
阈值依赖型指标的核心是"先定阈值,再评性能",常见指标包括精确率(Precision)、召回率(Recall)、F1分数、NAB分数等,其优缺点与适用场景如下:
1. 核心优缺点
| 优点 | 缺点 |
|---|---|
| 1. 直观易懂 :基于"正确/错误分类"的逻辑,结果可直接对应业务场景(如"模型漏检率"对应召回率,"误报率"对应1-精确率),便于业务人员理解。 2. 贴合实际决策 :多数工业场景需明确"是否标记为异常"的二元决策(如服务器告警、金融 fraud 拦截),与阈值依赖型指标的输出形式完全匹配。 3. 计算高效:基于混淆矩阵的计算逻辑简单,无需遍历阈值,适合实时流数据场景下的快速评估。 | 1. 阈值敏感性高 :指标结果严重依赖阈值选择(如同一模型在阈值=2时F1=0.8,阈值=3时F1=0.5),若阈值设定不合理(如未考虑数据分布特性),会导致性能评估偏差。 2. 对异常分数噪声鲁棒性差 :若异常分数受数据噪声影响波动较大(如传感器数据的随机干扰),阈值附近的微小分数变化会导致大量样本分类结果反转,指标稳定性低。 3. 忽略时间序列的连续性 :传统点级指标(如Precision、Recall)将每个时间点视为独立样本,未考虑异常的"连续性"(如一段连续异常中仅检测到1个点,点级Recall可能很高,但实际未覆盖完整异常段)。 4. 对类别不平衡敏感:时间序列中异常占比通常极低(如<1%),高精确率可能源于"极少预测异常"(如全预测正常时精确率=1),无法真实反映模型能力。 |
2. 典型指标及场景补充
- F1分数(含β调整):当业务需平衡"误报"与"漏检"时使用(如工业设备故障检测,漏检会导致停产损失,误报会增加运维成本),β=1时平衡Precision与Recall,β>1时侧重Recall(如医疗异常检测,优先降低漏检),β<1时侧重Precision(如广告点击异常检测,优先降低误报)。
- NAB分数:针对流数据场景设计,引入"时间惩罚"(如早检测异常得高分,晚检测或误报得低分),适合实时监控场景(如服务器性能监控),但计算逻辑复杂,仅支持特定基准数据集(如NAB基准)。
- Range-based F-score:改进传统点级指标,考虑异常段的"覆盖度"(如检测到异常段的50%以上视为有效检测),缓解"忽略时间连续性"的问题,适合 subsequence 异常(如心电图中的异常周期)。
三、阈值独立型评估指标:优缺点与适用场景
阈值独立型指标的核心是"整合全阈值性能",常见指标包括AUC-ROC、AUC-PR、Range-AUC、VUS(Volume Under the Surface)等,其优缺点与适用场景如下:
1. 核心优缺点
| 优点 | 缺点 |
|---|---|
| 1. 无需阈值选择 :避免因阈值设定主观或不合理导致的评估偏差,尤其适合"异常分数分布未知"的场景(如新型设备的传感器数据)。 2. 综合反映模型能力 :遍历所有可能阈值,输出模型在"全决策空间"的性能(如AUC-ROC反映模型区分正常/异常样本的整体能力),便于不同模型间的公平比较。 3. 对时间连续性的适配性强 :扩展指标(如Range-AUC、VUS)通过引入"缓冲区域"(如异常段前后5个时间点视为半异常),适配时间序列的连续性,更准确评估 subsequence 异常检测效果。 4. 对类别不平衡鲁棒性更高:AUC-PR 聚焦"正样本(异常)的预测排序能力",相比AUC-ROC更适合异常占比极低的场景(如金融 fraud 检测,异常占比<0.1%)。 | 1. 结果解读难度高 :指标结果为"曲线下面积"(如AUC-ROC=0.9),无法直接对应业务决策(如无法回答"模型误报率多少"),需结合业务进一步转化。 2. 计算成本高 :需遍历所有可能阈值并计算对应TPR/FPR,对长时序数据(如百万级时间点)或实时场景不友好。 3. 可能掩盖局部性能缺陷:综合指标(如AUC-ROC)可能掩盖"关键阈值区间"的性能不足(如AUC=0.9,但在业务关注的低FPR区间(FPR<0.01)TPR仅为0.5),导致误判模型实用性。 |
2. 典型指标及场景补充
- AUC-ROC:适合评估"正常/异常样本区分能力",但在类别极不平衡场景下可能高估性能(如异常占比<0.1%时,FPR微小变化对AUC影响小),更适合中低不平衡度数据(如异常占比5%-10%)。
- AUC-PR:聚焦"异常样本的精确率-召回率曲线",在极不平衡场景下更可靠(如医疗诊断中的罕见疾病检测),但计算需依赖完整的Precision-Recall曲线,成本高于AUC-ROC。
- VUS(VUS-ROC/VUS-PR):参数无关的扩展指标,通过整合不同"缓冲长度"的Range-AUC,避免因缓冲长度设定导致的偏差,适合"异常段长度未知"的场景(如工业设备的突发故障与渐变故障混合数据),但计算复杂度最高,仅适合离线评估。
四、实际应用中的评估指标选择策略
选择评估指标需结合业务场景、数据特性、模型目标三方面因素,具体策略如下:
1. 优先考虑业务决策需求
- 场景1:需明确二元决策(如告警、拦截)
选择阈值依赖型指标 ,如F1分数(平衡误报/漏检)、NAB分数(实时流监控)。- 示例:服务器CPU使用率异常检测,需输出"是否触发告警",用F1分数评估,并基于历史数据设定阈值(如"异常分数>3倍标准差"),同时监控精确率(避免频繁误告警)和召回率(避免漏检宕机风险)。
- 场景2:模型比较与选型(无明确决策阈值)
选择阈值独立型指标 ,如AUC-PR(极不平衡数据)、VUS(subsequence 异常)。- 示例:为新型工业设备选择异常检测模型,此时异常分数分布未知,用AUC-PR比较不同模型(如LSTM-AD vs. Autoencoder)的整体区分能力,再基于业务需求后续设定阈值。
2. 结合数据特性选择
- 数据维度与异常类型
- 若为univariate 点异常(如单个传感器的瞬时峰值):可选择简单阈值依赖型指标(如Precision@k,取前k个最高异常分数为异常)或AUC-ROC。
- 若为multivariate subsequence 异常(如多个传感器协同的异常周期):优先选择支持连续性的指标(如Range-AUC、VUS),避免传统点级指标低估性能。
- 数据不平衡程度
- 异常占比<1%(极不平衡):优先AUC-PR、Range-AUC,避免AUC-ROC高估性能;
- 异常占比5%-20%(中低不平衡):AUC-ROC、F1分数均可,若需决策则用F1。
3. 考虑评估场景(离线vs.实时)
- 离线评估(如模型训练与调参):可选择计算成本高但更准确的指标(如VUS、AUC-PR),充分评估模型在全场景下的性能。
- 实时评估(如流数据监控):优先选择阈值依赖型指标(如F1分数、NAB分数),平衡计算效率与业务决策需求。
4. 避免单一指标依赖,采用"核心指标+辅助指标"组合
- 示例1:金融 fraud 检测(极不平衡、需低误报)
核心指标:AUC-PR(评估整体区分能力)+ 精确率@0.1%FPR(评估低误报下的召回率);
辅助指标:F1分数(基于业务阈值设定,如FPR=0.01时的F1)。 - 示例2:工业设备故障检测(需覆盖完整异常段)
核心指标:Range-AUC(评估 subsequence 异常检测能力);
辅助指标:Range-based F-score(基于业务设定的异常段覆盖阈值,如覆盖70%视为有效检测)。
五、总结
时间序列异常检测的评估指标选择无"最优解",需围绕业务决策目标、数据特性、评估场景三者平衡:
- 若需明确二元决策、实时反馈,优先选择阈值依赖型指标(如F1、NAB),但需结合数据分布合理设定阈值;
- 若需公平比较模型、处理未知异常分布,优先选择阈值独立型指标(如AUC-PR、VUS),但需注意结果解读与业务需求的衔接;
- 实际应用中建议采用"核心指标+辅助指标"组合,避免单一指标的局限性,确保评估结果既符合模型能力,又贴合业务实际价值。
时间序列异常检测基准数据集差异及对方法选择的影响
该综述(Dive into Time-Series Anomaly Detection: A Decade Review )系统梳理了8个核心时间序列异常检测基准数据集,这些数据集在时间序列数量、长度、异常特征等维度差异显著,直接影响异常检测方法的选型与评估有效性。以下从数据集核心差异对比 和差异对方法选择的影响两方面展开分析。
一、核心基准数据集的关键差异
综述中提及的8个主流基准数据集(NAB、Yahoo、Exathlon、KDD21、TODS、TimeEval、TSB-UAD、TSB-AD)在核心属性上存在明显分化,具体差异如下表及分类说明:
1. 数据集核心属性对比表
| 基准数据集 | 时间序列数量 | 平均长度 | 平均异常数 | 平均异常长度 | 维度(单/多变量) | 异常类型(点/子序列) | 核心特点与应用场景 |
|---|---|---|---|---|---|---|---|
| NAB 126 | 58 | 6301.7 | 2 | 287.8 | 单变量(I) | 点(P)+子序列(S) | 聚焦流数据实时检测,覆盖AWS metrics、交通等真实场景 |
| Yahoo 125 | 367 | 1561.2 | 5.9 | 1.8 | 单变量(I) | 点(P)+子序列(S) | 基于Yahoo生产流量,含真实与合成数据,异常以短点异常为主 |
| Exathlon 108 | 93 | 25115.9 | 1 | 9537.6 | 多变量(M) | 子序列(S) | 高维可解释性检测,基于Apache Spark集群作业轨迹 |
| KDD21 113 | 250 | 77415.1 | 1 | 196.5 | 单变量(I) | 点(P)+子序列(S) | 跨领域(医疗、航天),修正早期基准缺陷(如标签错误) |
| TODS 123 | 54 | 13469.9 | 266.7 | 2.3 | 单+多变量(I&M) | 点(P)+子序列(S) | 行为驱动分类(如季节性、趋势异常),含5类异常场景 |
| TimeEval 216 | 976 | 30991 | 5.5 | 106.7 | 单+多变量(I&M) | 点(P)+子序列(S) | 过滤极端失衡数据(异常占比≤10%),确保方法可区分性 |
| TSB-UAD 185 | 14046 | 34043.6 | 86.3 | 24.9 | 单变量(I) | 点(P)+子序列(S) | 最大单变量基准,含11种异常变换,模拟真实相似性差异 |
| TSB-AD 142 | 1070(精选) | 105485.2 | 104.2 | 409.5 | 单+多变量(I&M) | 点(P)+子序列(S) | 最新精选基准,人工+模型验证标签,覆盖40种方法对比 |
2. 关键差异维度分类
(1)数据规模与复杂度
- 小规模低复杂度:NAB(58条)、TODS(54条),平均长度较短(NAB约6k点),适合验证方法的基础有效性,尤其对计算资源有限的场景(如边缘设备检测)。
- 中大规模高复杂度:TSB-UAD(1.4万条)、TimeEval(976条),平均长度超3万点,且TSB-UAD含大量合成异常变换,适合评估方法的** scalability(扩展性)** 和对复杂异常的鲁棒性。
- 超大规模精选集 :TSB-AD(1070条精选),平均长度超10万点,标签经过人工验证,适合作为方法性能的最终验证基准,避免" cherry-picking(选择性验证)"问题。
(2)异常特征与类型
- 短点异常主导 :Yahoo(平均异常长度1.8点)、TODS(平均异常长度2.3点),异常以孤立点为主,适合评估点异常检测方法(如基于统计的ESD、LOF)。
- 长序列异常主导 :Exathlon(平均异常长度9537.6点)、TSB-AD(平均异常长度409.5点),异常为持续子序列(如设备故障周期),需方法具备序列模式学习能力(如LSTM-VAE、Matrix Profile)。
- 异常密度差异:TODS(平均266.7个异常)为高异常密度数据集,适合评估方法对"密集异常重叠"的区分能力;Exathlon(平均1个异常)为低异常密度,更贴近真实工业场景(如航天设备故障)。
(3)维度与可解释性
- 单变量聚焦 :Yahoo、KDD21、TSB-UAD,仅需处理单一特征维度,适合验证单变量方法(如ARIMA、HOT SAX),或作为多变量方法的基础模块验证。
- 多变量场景 :Exathlon、TSB-AD、TimeEval,需捕捉特征间相关性(如传感器网络、金融多指标),强制要求方法支持多变量建模(如MTAD-GAT、OmniAnomaly)。
- 可解释性需求 :Exathlon专为"可解释异常检测"设计,数据集含详细的异常成因标注(如Spark作业资源瓶颈),适合评估可解释性方法(如基于图的Series2Graph、因果推断模型)。
二、数据集差异对异常检测方法选择的影响
数据集的核心差异直接决定了方法的"适配性"------错误选择基准可能导致方法性能评估失真,或无法满足实际场景需求。具体影响可分为以下5个维度:
1. 方法的"维度兼容性":单变量 vs 多变量
-
单变量数据集(如Yahoo、TSB-UAD):
- 适配方法:无需处理特征间依赖的算法,如基于距离的Discord检测(HOT SAX)、单变量预测模型(ARIMA、LSTM-AD)。
- 排除方法:仅支持多变量的方法(如MGDD、MERLIN++的多变量扩展版),或依赖跨特征相关性的模型(如RobustPCA)。
-
多变量数据集(如Exathlon、TSB-AD):
- 适配方法:需建模特征间动态关联的算法,如注意力机制模型(MTAD-GAT)、多变量自编码器(OmniAnomaly)、图基方法(Series2Graph)。
- 排除方法:纯单变量方法(如传统ESD、HBOS),此类方法会忽略跨特征异常信号(如"温度升高+压力下降"的协同故障)。
2. 方法的"序列建模能力":点异常 vs 子序列异常
-
短点异常数据集(如Yahoo、TODS):
- 适配方法:擅长捕捉局部离群点的算法,如统计方法(S-ESD、HBOS)、局部密度方法(LOF、DBSCAN),此类方法无需长期序列记忆,计算效率高。
- 风险点:若使用长序列建模方法(如LSTM-VAE),可能因过度拟合正常序列的短期波动,导致异常点漏检。
-
长序列异常数据集(如Exathlon、TSB-AD):
- 适配方法:需学习序列模式的算法,如基于矩阵轮廓的Discord检测(STAMPI、DAMP)、序列预测模型(LSTM-AD、Telemanom)、生成式模型(MAD-GAN)。
- 风险点:纯点异常方法(如KNN)会将长序列异常拆分为多个"正常点",导致异常被碎片化忽略(如ECG中的持续心律失常)。
3. 方法的"扩展性需求":小规模 vs 大规模数据
-
小规模数据集(如NAB、TODS):
- 适配方法:计算复杂度较高但精度优的算法,如基于聚类的CBLOF、语法归纳方法(GrammarViz),无需担心算力瓶颈。
-
大规模/流数据(如TSB-UAD、TimeEval):
- 适配方法:低复杂度、增量更新的算法,如流聚类方法(DBStream)、增量异常检测(DILOF、STAMPI)、轻量级预测模型(ESN、HTM)。
- 排除方法:离线批处理方法(如DeepkMeans、MERLIN),此类方法无法实时处理流数据,且在百万级数据上计算成本过高。
4. 方法的"监督模式适配性":无监督 vs 半监督
-
无标签数据集(如TSB-UAD、KDD21):
- 适配方法:无监督/自监督算法,如基于密度的IForest、自编码器(EncDec-AD)、矩阵轮廓(SCAMP),无需人工标注正常/异常样本。
-
半监督场景(如Exathlon、TSB-AD):
- 适配方法:需利用正常样本训练的半监督方法,如One-Class SVM(OCSVM)、重构模型(VAE-GAN)、预测模型(LSTM-AD),此类方法在有少量正常标注时性能更优。
- 注意:TSB-AD提供部分异常标签,可用于监督方法的微调(如DeepAnT),但需避免"过拟合标注偏差"。
5. 方法的"可解释性匹配":纯精度 vs 可解释性
-
可解释性需求数据集(如Exathlon):
- 适配方法:可解释性强的模型,如基于统计的MCD、图基方法(Series2Graph)、因果推断模型,需输出异常的成因(如"CPU利用率高导致Spark作业延迟")。
- 排除方法:黑箱模型(如GAN、复杂LSTM),此类方法虽精度高,但无法解释异常产生的物理/业务逻辑。
-
纯精度需求数据集(如Yahoo、KDD21):
- 适配方法:高精度黑箱模型(如MAD-GAN、USAD),无需解释性,仅需优化AUC-ROC、VUS等指标。
三、总结:方法选择的核心决策路径
基于上述差异,可按照以下步骤选择适配的异常检测方法:
- 明确数据场景:先确定实际数据的维度(单/多变量)、规模(长度/数量)、异常类型(点/子序列),选择属性匹配的基准数据集(如工业多变量流数据→TimeEval/TSB-AD)。
- 筛选方法兼容性:排除与数据集维度、异常类型不兼容的方法(如单变量数据→排除多变量GAT模型)。
- 平衡性能与成本:小规模数据可优先精度(如CBLOF),大规模/流数据优先扩展性(如STAMPI、DAMP)。
- 验证与最终选择:先在适配的基准数据集(如短点异常→Yahoo)上初步筛选,再在TSB-AD等精选集上做最终验证,避免"基准偏倚"。
例如:若需检测"AWS服务器的实时流数据异常(单变量、短点异常为主)",可优先选择Yahoo数据集验证LOF、ESD等方法,再通过NAB验证其流处理能力,最终确定最优方案。
特定时间序列异常检测任务的方法选择指南
在时间序列异常检测任务中,方法选择需紧密结合数据特性、异常类型、任务约束及评估目标。综述《Dive into Time-Series Anomaly Detection: A Decade Review》提出的过程中心型分类法(距离基、密度基、预测基)为核心框架,结合数据维度、监督模式、实时性需求等关键因素,可构建一套系统性的方法选择流程。
一、先明确任务核心约束:四大关键维度定位
在选择方法前,需先明确任务的核心约束条件,这些条件直接决定方法的"适配性",是后续筛选的基础。
1. 数据特性:维度与规模
数据的维度(单变量/多变量)和规模(长度、样本量)是方法选择的首要前提,直接限制算法的兼容性和效率。
-
单变量时间序列(如单传感器温度数据、股价单指标):
- 适配方法:无需处理跨特征依赖的算法,如基于距离的Discord检测(HOT SAX、Matrix Profile)、单变量预测模型(ARIMA、LSTM-AD)、统计方法(ESD、HBOS)。
- 排除方法:仅支持多变量的模型(如MGDD、MERLIN++多变量扩展版),或依赖跨特征相关性的算法(如RobustPCA、OmniAnomaly)。
-
多变量时间序列(如工业传感器网络、金融多指标、医疗多参数监护):
- 适配方法:需建模特征间动态关联的算法,如注意力机制模型(MTAD-GAT)、多变量自编码器(OmniAnomaly)、图基方法(Series2Graph)、分布基方法(MCD、COPOD)。
- 排除方法:纯单变量方法(如传统ESD、HBOS),此类方法会忽略"温度升高+压力下降"等跨特征协同异常信号。
-
大规模/流数据(如IoT实时数据流、高频交易数据):
- 适配方法:低复杂度、增量更新的算法,如流聚类(DBStream)、增量异常检测(DILOF、STAMPI)、轻量级预测模型(ESN、HTM)、矩阵轮廓的流扩展(DAMP、LAMP)。
- 排除方法:离线批处理方法(如DeepkMeans、MERLIN),此类方法无法实时处理流数据,且在百万级数据上计算成本过高(如KNN的O(n²)复杂度)。
2. 异常类型:点/上下文/集体异常
时间序列异常分为点异常、上下文异常、集体异常,不同类型需算法具备不同的"序列建模能力",是方法选择的核心依据。
-
点异常(孤立异常值,如传感器瞬时故障、金融数据突刺):
- 特征:单个数据点显著偏离正常范围,无序列依赖。
- 适配方法:擅长捕捉局部离群点的算法,如统计方法(S-ESD、SH-ESD+)、局部密度方法(LOF、DBSCAN)、直方图基方法(HBOS)。
- 案例:Yahoo数据集(平均异常长度1.8点)适合用HBOS或ESD检测。
-
上下文异常(局部窗口内异常,如电商促销期的流量波动):
- 特征:数据点在全局范围内正常,但在局部窗口(如日/周周期)内异常,需结合上下文判断。
- 适配方法:支持窗口建模的算法,如基于距离的近邻方法(KNN、LOF)、矩阵轮廓(STOMP、SCAMP)、预测基方法(LSTM-AD、Telemanom)。
- 案例:NAB数据集中的AWS服务器 metrics(含日周期异常)适合用Matrix Profile或LSTM-AD检测。
-
集体异常(序列模式异常,如设备故障周期、ECG心律失常):
- 特征:单个点正常,但连续点组成的子序列偏离典型模式,需序列建模能力。
- 适配方法:需学习序列模式的算法,如Discord检测(MERLIN、MERLIN++)、预测基方法(LSTM-VAE、MAD-GAN)、编码基方法(GrammarViz、PST)。
- 案例:Exathlon数据集(平均异常长度9537.6点)适合用MERLIN++或MAD-GAN检测。
3. 监督模式:无监督/半监督/有监督
监督模式取决于是否有标注数据(正常样本/异常样本),直接决定算法的"数据依赖"特性。
-
无监督场景(无标注数据,如新系统上线初期):
- 特征:无专家知识,需自动学习正常模式。
- 适配方法:无需标注的算法,如基于密度的IForest、HBOS、COPOD;基于距离的Matrix Profile、DBSCAN;编码基方法(SSA、POLY)。
- 优势:适用于未知异常类型,如工业新设备的故障检测。
-
半监督场景(仅正常样本标注,如已知健康状态的传感器):
- 特征:有正常样本,但无异常样本,需建模"正常边界"。
- 适配方法:基于正常样本训练的算法,如单类SVM(OCSVM、AOSVM)、自编码器(EncDec-AD、OmniAnomaly)、预测基方法(ARIMA、LSTM-AD)。
- 优势:工业场景中最常用,如航天设备的健康状态监测(仅正常数据可获取)。
-
有监督场景(异常样本标注,如已知欺诈模式的金融数据):
- 特征:有标注的正常/异常样本,需分类异常类型。
- 适配方法:支持监督训练的算法,如深度分类模型(DeepAnT、LSTM-AD带标签训练)、有监督Discord检测(TARZAN)、集成方法(Ensemble GI)。
- 注意:需避免过拟合小样本异常,建议用数据增强(如TSB-UAD的合成异常)扩展样本。
4. 任务需求:实时性、可解释性、鲁棒性
除技术特性外,业务需求(如实时告警、异常原因定位)也会影响方法选择,需优先满足核心需求。
-
实时性需求(如工业实时监控、金融高频交易):
- 适配方法:低延迟算法,如流数据专用方法(DBStream、DAMP)、轻量级模型(ESN、HTM)、增量更新方法(AOSVM、STAMPI)。
- 排除方法:高复杂度模型(如MAD-GAN、DeepkMeans),此类模型推理延迟高(>100ms)。
-
可解释性需求(如医疗诊断、工业故障定位):
- 适配方法:可解释性强的算法,如统计方法(ESD、MCD)、图基方法(Series2Graph、DADS)、编码基方法(GrammarViz)。
- 案例:医疗ECG异常检测适合用GrammarViz(可输出异常对应的语法规则)或Series2Graph(可展示异常对应的图路径)。
-
鲁棒性需求(如含噪声的传感器数据):
- 适配方法:抗噪声能力强的算法,如鲁棒统计方法(FAST-MCD、RobustPCA)、预测基方法(LSTM-VAE、DONUT)、集成方法(IF-LOF、Ensemble GI)。
- 案例:含传输噪声的传感器数据适合用RobustPCA或DONUT(带缺失值处理)检测。
二、方法选择的五步决策流程
基于上述约束条件,可按以下流程系统性选择方法,确保适配性和有效性:
步骤1:分析数据与异常特性
- 输出:数据维度(单/多变量)、规模(长度/样本量)、异常类型(点/上下文/集体)。
- 示例:某电商平台的日流量数据(单变量、长度10000点、促销期上下文异常)→ 数据特性:单变量+上下文异常。
步骤2:确定监督模式与任务需求
- 输出:监督模式(无/半/有监督)、核心需求(实时性/可解释性/鲁棒性)。
- 示例:电商平台有历史正常流量数据(无异常标注),需实时检测(延迟<100ms)→ 监督模式:半监督;核心需求:实时性。
步骤3:初步筛选方法池
根据步骤1-2的结果,从三大类方法中筛选适配选项:
- 示例:单变量+上下文异常+半监督+实时性 → 候选方法:Matrix Profile(STOMP)、LSTM-AD、AOSVM。
步骤4:验证方法兼容性
检查候选方法是否满足细节约束(如流数据支持、噪声鲁棒性):
- 示例:
- STOMP(Matrix Profile变体):支持流数据(增量计算)、实时性好(延迟<50ms)、适配上下文异常 → 兼容。
- LSTM-AD:实时性一般(延迟≈200ms)→ 不满足实时性需求,排除。
- AOSVM:支持流数据,但对上下文异常的检测精度低于STOMP → 排除。
步骤5:基准测试与优化
在目标数据集或相似基准(如NAB、TSB-AD)上测试候选方法,用合适指标评估(如VUS-ROC、Range-AUC),并优化参数:
- 示例:在NAB的电商流量子集上测试STOMP,调整窗口长度(如7天周期),用VUS-ROC评估(目标>0.8),最终确定方法。
三、典型场景的方法选择案例
场景1:工业传感器故障检测(多变量+集体异常+半监督+实时性)
- 数据特性:多传感器(温度、压力、振动)、故障为集体异常(连续子序列)、有正常样本标注、需实时告警(延迟<50ms)。
- 适配方法:MTAD-GAT(多变量支持+实时性+半监督)、OmniAnomaly(多变量自编码器+鲁棒性)。
- 排除方法:单变量方法(如HBOS)、高延迟模型(如MAD-GAN)。
场景2:金融欺诈检测(单变量+点异常+有监督+可解释性)
- 数据特性:单指标(交易金额)、欺诈为点异常(突刺)、有标注欺诈样本、需解释异常原因。
- 适配方法:有监督LSTM-AD(可输出预测误差解释)、OCSVM(可输出超平面距离解释)。
- 排除方法:无解释性的模型(如IForest)、集体异常检测方法(如MERLIN)。
场景3:医疗ECG心律失常检测(单变量+集体异常+半监督+鲁棒性)
- 数据特性:单导联ECG、心律失常为集体异常、有正常ECG样本、需抗噪声(信号干扰)。
- 适配方法:LSTM-VAE(鲁棒性+集体异常检测)、MERLIN++(Discord检测+抗噪声)。
- 排除方法:点异常检测方法(如ESD)、无鲁棒性的模型(如KNN)。
四、常见误区与避坑指南
- 忽视异常类型匹配:用点异常方法(如ESD)检测集体异常(如设备故障),导致漏检。→ 避坑:先通过可视化(如时序图)判断异常类型,再选择对应方法。
- 过度依赖深度学习:在小数据场景(如<1000点)用复杂模型(如MAD-GAN),导致过拟合。→ 避坑:小数据用统计方法(如ESD、HBOS),大数据用深度学习。
- 忽略实时性需求:在流数据场景用离线方法(如DeepkMeans),导致延迟超标。→ 避坑:流数据优先选择增量更新方法(如DAMP、AOSVM)。
- 单一方法评估:仅用AUC-ROC评估集体异常检测,忽略序列特性。→ 避坑:集体异常用Range-AUC或VUS-ROC评估,更贴合序列特性。
五、总结
时间序列异常检测的方法选择需遵循"约束优先、特性匹配"原则:先通过数据特性、异常类型、监督模式、任务需求四大维度定位核心约束,再通过五步流程筛选适配方法,最后通过基准测试验证。关键在于避免"一刀切"------例如,单变量点异常适合用HBOS或ESD,多变量集体异常适合用MERLIN++或MAD-GAN,半监督流数据适合用AOSVM或STAMPI。同时,需结合具体场景的基准数据集(如TSB-AD、NAB)进行验证,确保方法的实际有效性。