https://gitee.com/baidumap/GPT_teacher-3.37Mhttps://gitee.com/baidumap/
复现使用python3.9.12版本进行复现,或者使用anaconda环境
整个项目已经打包
保存链接: https://pan.baidu.com/s/1NnzG5qyS9ouu-U7D1YvkOg?pwd=cccc
1. 安装缺失的依赖
在你的终端执行:
pip install -r requirements.txt
pip install tokenizers pyyaml注:由于项目中有 config.yaml,通常还需要 pyyaml 库来读取配置。
2. 重新执行"三步走"流程
安装好依赖后,请严格按照以下顺序执行,这是让模型"开口说话"的必经之路:
第一步:构建分词器
Bash
python -m src.build_tokenizer检查点 :执行完后,你的文件夹里应该会出现一个 tokenizer 目录,里面包含 tokenizer.json。
第二步:简短训练(生成权重)
因为你手里没有 last.pt,需要让 CPU 跑一下训练流程来创建这个文件:
Bash
python -m src.train- 操作技巧 :你不需要真的等它跑 20 分钟。当看到终端开始打印
step 100或step 200并且显示saved checkpoint时,直接按 Ctrl + C 停止它。此时checkpoints/last.pt就已经躺在你的文件夹里了。
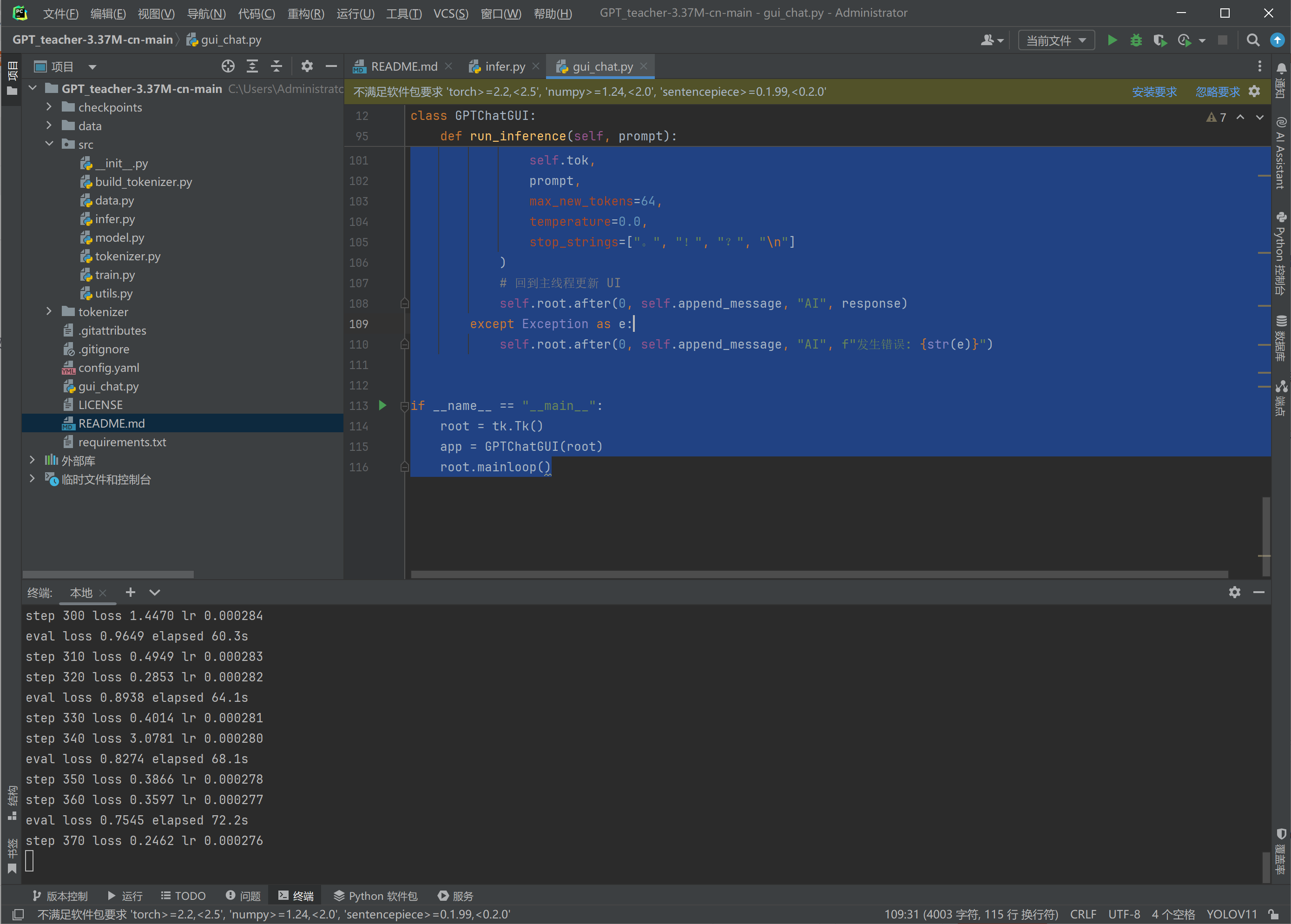
第三步:启动 GUI 聊天
现在,再次运行我之前为你写的脚本:
Bash
python gui_chat.pygui_chat代码
import tkinter as tk
from tkinter import scrolledtext, messagebox
import torch
import threading
import os
# 导入项目中已有的逻辑
from src.model import GPT
from src.tokenizer import load_tokenizer
from src.infer import load_checkpoint, generate
class GPTChatGUI:
def __init__(self, root):
self.root = root
self.root.title("GPT Teacher 3.37M - 极简聊天窗")
self.root.geometry("500x650")
self.root.configure(bg="#f5f5f5") # 浅灰色背景
# 1. 加载模型资产
self.load_model_assets()
# 2. 界面布局
self.create_widgets()
# 3. 打印欢迎语
self.append_message("AI", "你好!我是 GPT Teacher。我已经准备好回答你的问题了。")
def load_model_assets(self):
# 优先查找量化权重,如果没有则找普通权重
ckpt_path = "checkpoints/quantized.pt" if os.path.exists("checkpoints/quantized.pt") else "checkpoints/last.pt"
if not os.path.exists(ckpt_path):
messagebox.showerror("错误", f"未找到模型权重文件!\n请确保已运行训练并生成 {ckpt_path}")
self.root.destroy()
return
try:
obj = load_checkpoint(ckpt_path)
cfg = obj["cfg"]
self.tok = load_tokenizer(cfg.get("tokenizer", {}).get("type", "byte"),
cfg.get("tokenizer", {}).get("path"))
self.model = GPT(
vocab_size=self.tok.vocab_size,
n_layer=cfg["model"]["n_layer"],
n_head=cfg["model"]["n_head"],
n_embd=cfg["model"]["n_embd"],
seq_len=cfg["model"]["seq_len"],
dropout=cfg["model"]["dropout"],
)
sd = obj["model"]
if any("_packed_params" in k for k in sd.keys()):
self.model = torch.quantization.quantize_dynamic(self.model, {torch.nn.Linear}, dtype=torch.qint8)
self.model.load_state_dict(sd)
self.model.eval()
except Exception as e:
messagebox.showerror("加载失败", f"模型初始化失败: {str(e)}")
self.root.destroy()
def create_widgets(self):
# --- 聊天记录显示区 ---
self.chat_display = scrolledtext.ScrolledText(
self.root, wrap=tk.WORD, state='disabled',
font=("Microsoft YaHei", 10),
bg="#f5f5f5", relief=tk.FLAT, padx=10, pady=10
)
self.chat_display.pack(padx=10, pady=10, fill=tk.BOTH, expand=True)
# 定义样式标签
self.chat_display.tag_config("user", foreground="#005a9e", font=("Microsoft YaHei", 10, "bold"))
self.chat_display.tag_config("ai", foreground="#2e7d32", font=("Microsoft YaHei", 10, "bold"))
self.chat_display.tag_config("text", lmargin1=20, lmargin2=20, foreground="#333333")
self.chat_display.tag_config("sep", spacing1=10) # 间距
# --- 输入区 ---
input_container = tk.Frame(self.root, bg="white", height=60)
input_container.pack(fill=tk.X, side=tk.BOTTOM, padx=10, pady=10)
self.user_input = tk.Entry(
input_container, font=("Microsoft YaHei", 11),
relief=tk.FLAT, bd=0
)
self.user_input.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=10, ipady=10)
self.user_input.bind("<Return>", lambda e: self.send_message())
self.user_input.focus_set()
self.send_btn = tk.Button(
input_container, text="发送", command=self.send_message,
bg="#0078d4", fg="white", relief=tk.FLAT,
font=("Microsoft YaHei", 10, "bold"), width=8
)
self.send_btn.pack(side=tk.RIGHT, fill=tk.BOTH)
def append_message(self, role, text):
self.chat_display.config(state='normal')
if role == "User":
self.chat_display.insert(tk.END, "● 你\n", "user")
self.chat_display.insert(tk.END, f"{text}\n", ("text", "sep"))
else:
self.chat_display.insert(tk.END, "● GPT Teacher\n", "ai")
self.chat_display.insert(tk.END, f"{text}\n", ("text", "sep"))
self.chat_display.config(state='disabled')
self.chat_display.see(tk.END)
def send_message(self):
prompt = self.user_input.get().strip()
if not prompt:
return
self.append_message("User", prompt)
self.user_input.delete(0, tk.END)
# 禁用发送按钮,防止连续点击
self.send_btn.config(state=tk.DISABLED)
threading.Thread(target=self.run_inference, args=(prompt,), daemon=True).start()
def run_inference(self, prompt):
try:
# 使用项目推荐的推理设置
response = generate(
self.model, self.tok, prompt,
max_new_tokens=128, # 稍微长一点
temperature=0.0, # 教学模型建议 0.0 最稳定
stop_strings=["。", "!", "?", "\n", "用户:"]
)
# 格式化一下响应文本
response = response.strip()
if not response: response = "(模型没有给出具体回答)"
self.root.after(0, self.update_ui_after_run, response)
except Exception as e:
self.root.after(0, self.update_ui_after_run, f"发生错误: {str(e)}")
def update_ui_after_run(self, response):
self.append_message("AI", response)
self.send_btn.config(state=tk.NORMAL)
if __name__ == "__main__":
root = tk.Tk()
# 尝试设置图标(如果有的话)
app = GPTChatGUI(root)
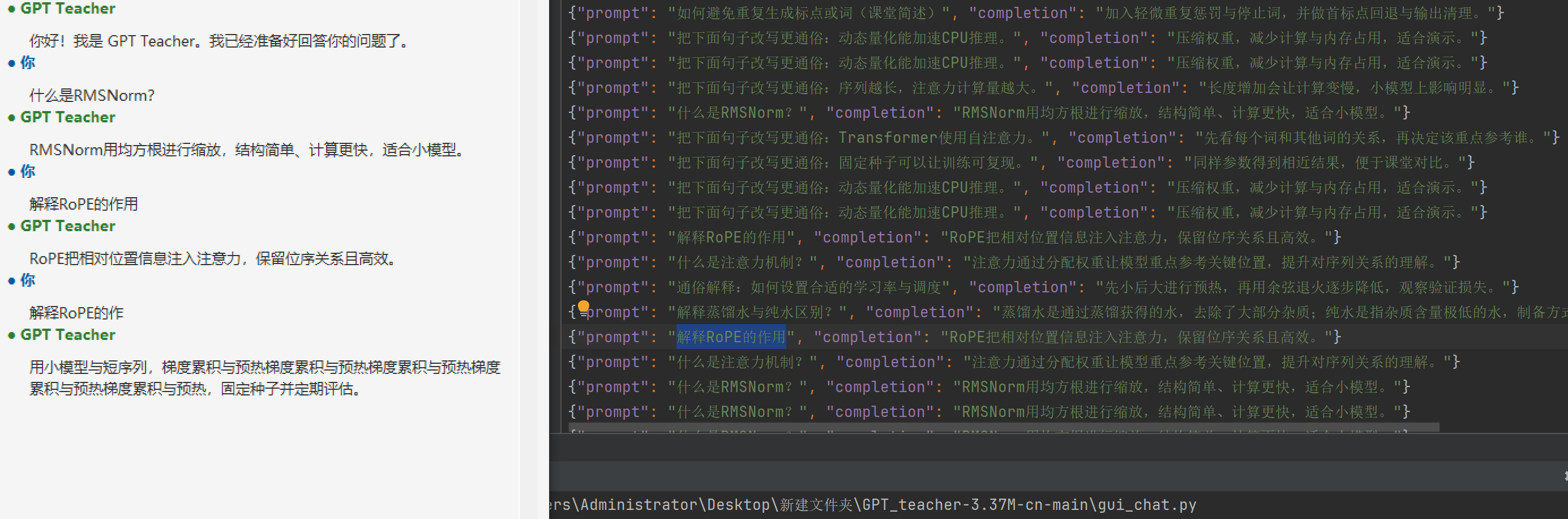
root.mainloop()现在正在训练了
我想在训练和验证的时候就推理,那么就不能说以问题来推理答案,直接以问题来推理会导致推理很久都不能得到答案。
那么应该是要以它学到的东西来推理。
这个模型训练好后只能问相关的问题
什么是注意力机制?
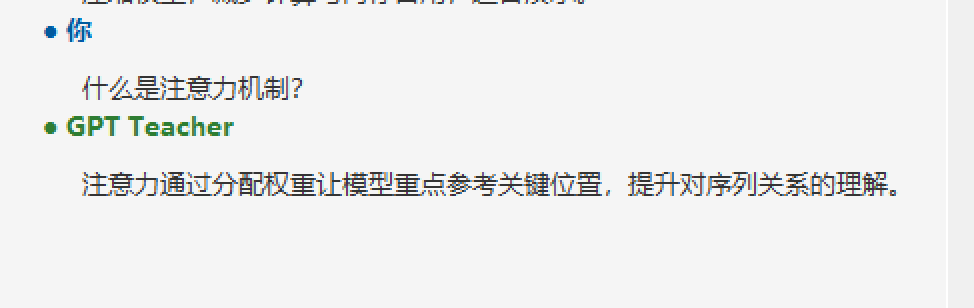

由于数据集太小,只能达到这个程度。
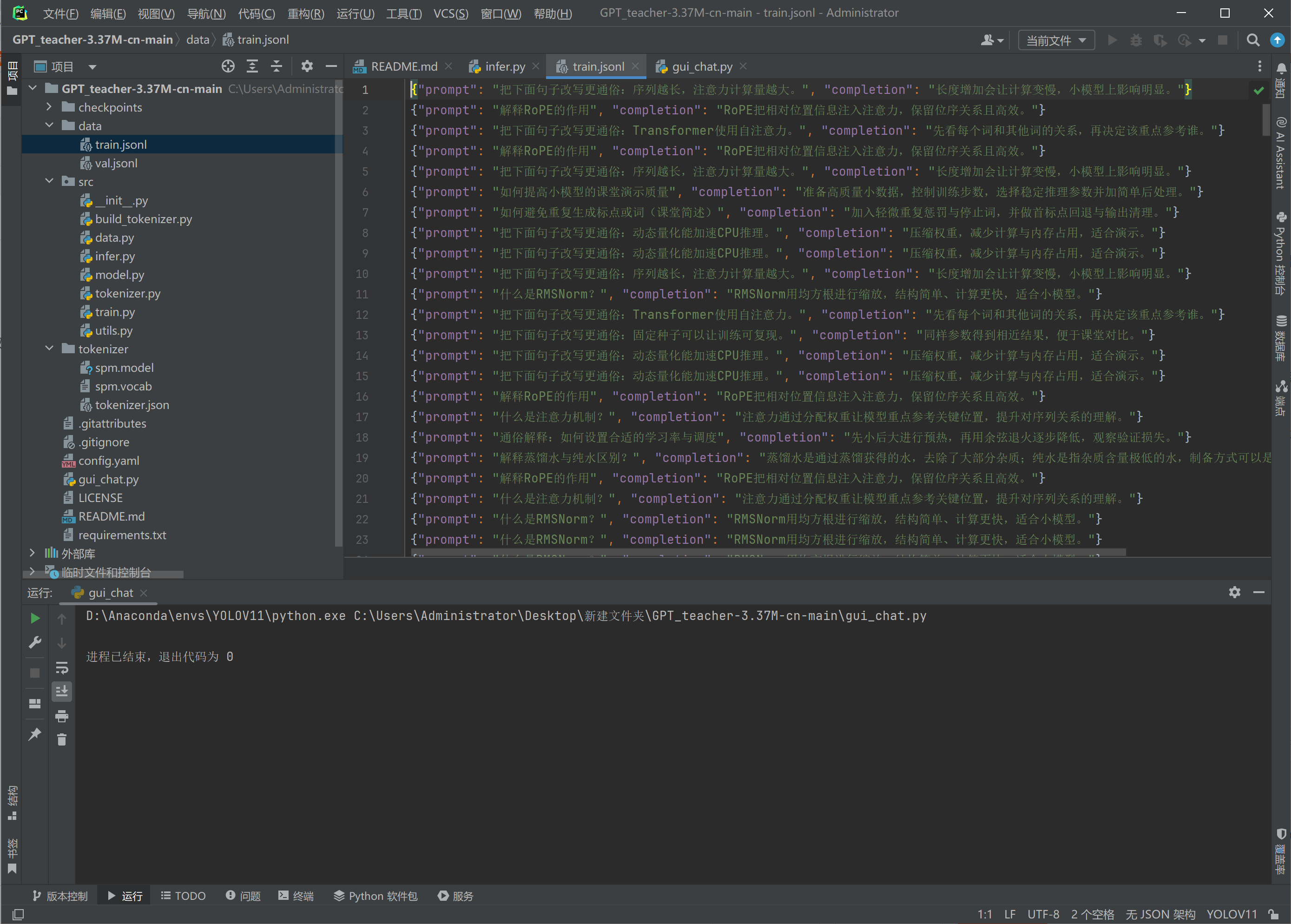
数据集就这么大,所以实际它学到的就是大概的概率。
问题大概是什么,它就回答什么