1.模型在 GPU 上训练,主要是将模型和数据迁移到 GPU 设备上。
GPU在计算的时候,相较于cpu多了3个时间上的开销
-
数据传输开销 (CPU 内存 <-> GPU 显存)
-
核心启动开销 (GPU 核心启动时间)
-
性能浪费:计算量和数据批次
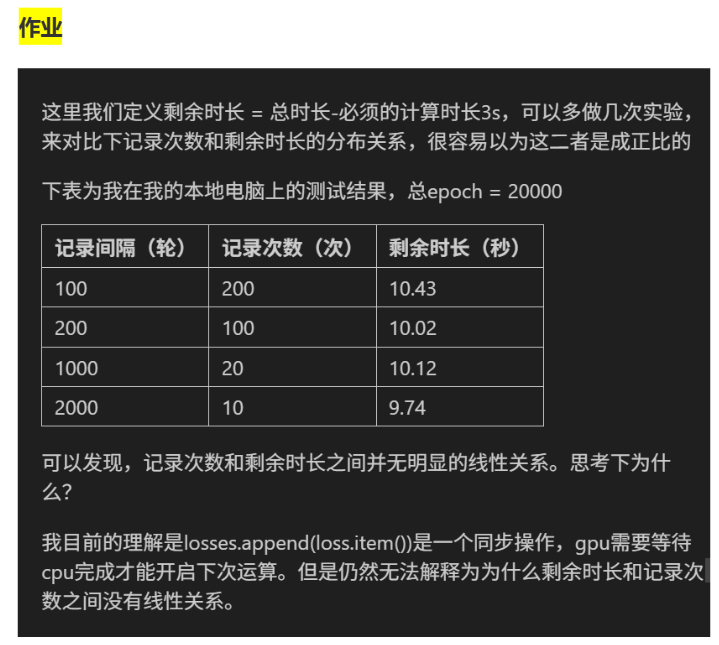
losses.append(loss.item()) 本身是轻量级操作(只是把一个数值存到列表里,耗时极短,可能只有微秒级)。而深度学习训练的主要耗时在:GPU 的前向 / 反向传播(占总耗时的 95% 以上);数据加载、内存拷贝等其他系统操作。且剩余时长本身是估算值,系统动态随机因素影响。
2.__call__方法让类的实例拥有了 "函数调用" 的能力
python
# 定义一个类,实现__call__方法
class MyCalculator:
def __init__(self, factor):
self.factor = factor # 初始化一个乘法因子
def __call__(self, x):
# 当实例被调用时,执行这个方法
return x * self.factor
# 实例化:因子为2
calc = MyCalculator(2)
# 把实例当作函数调用
result = calc(5)
print(result) # 输出10(5*2)