深入剖析阻塞队列:ArrayBlockingQueue如何用Lock与Condition实现高效并发控制
-
《解密ArrayBlockingQueue:Lock+Condition如何超越synchronized的并发性能》
-
《阻塞队列核心技术揭秘:从等待通知机制到高性能并发设计》
-
《深入Java并发:为什么ArrayBlockingQueue选择Lock而非synchronized?》
-
《高并发编程实战:掌握ArrayBlockingQueue的锁与条件变量实现原理》
-
《从源码看本质:ArrayBlockingQueue如何优雅实现生产者-消费者模式》
正文内容
在并发编程的世界中,阻塞队列扮演着至关重要的角色。它不仅是生产者-消费者模式的经典实现,更是Java并发工具包(JUC)的核心组件之一。今天,我们将深入剖析ArrayBlockingQueue这一典型阻塞队列的底层实现,揭示其如何巧妙地结合可重入锁(ReentrantLock)和条件变量(Condition)来实现高效的线程协作。
一、阻塞队列的核心需求与设计挑战
在多线程环境中,当生产者生产数据的速度与消费者处理数据的速度不匹配时,就需要一种机制来协调两者的节奏。阻塞队列正是为此而生:当队列为空时,消费者线程会被阻塞,直到有新的元素可用;当队列已满时,生产者线程会被阻塞,直到队列有空间容纳新元素。
这种阻塞/唤醒机制需要解决几个关键问题:
-
线程安全的队列操作(入队/出队)
-
高效的线程等待与唤醒机制
-
避免忙等待(busy-waiting)造成的CPU资源浪费
-
支持公平或非公平的线程调度策略
二、ArrayBlockingQueue的核心架构
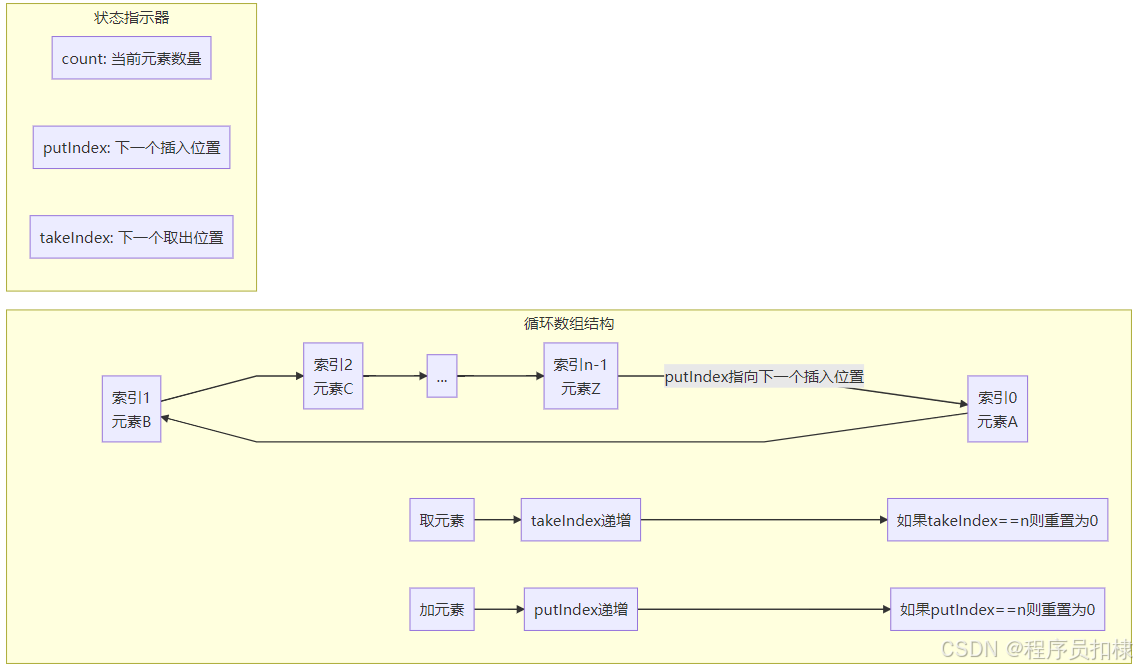
ArrayBlockingQueue采用了一个固定大小的循环数组作为底层存储,这种设计既保证了内存的连续性,又通过循环利用数组空间提高了内存使用效率。但数组本身并不是线程安全的,因此需要同步机制来保护共享数据。
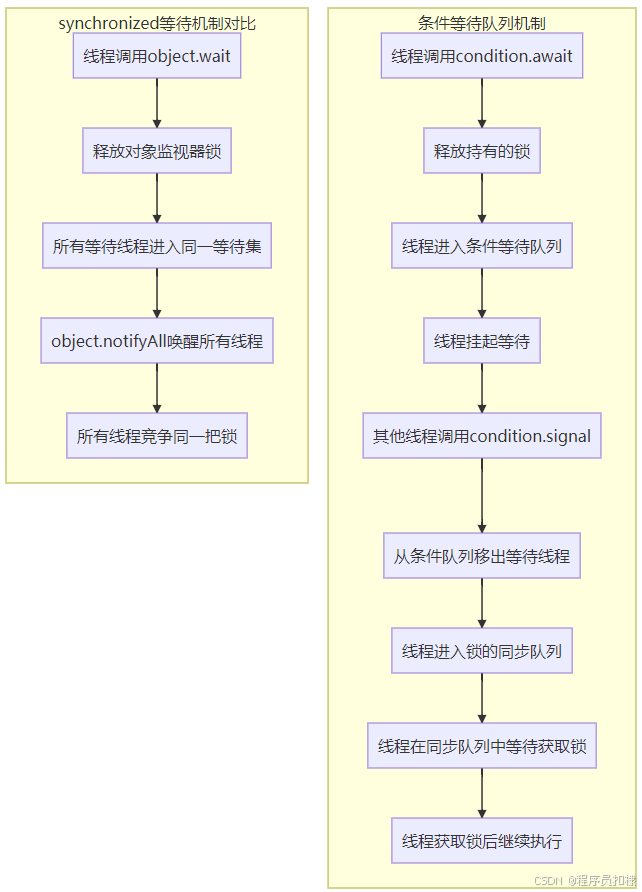
2.1 传统方案:synchronized + wait/notify
在Java早期,我们可以使用synchronized关键字配合Object.wait()和Object.notify()方法实现阻塞队列:
java
public class SimpleBlockingQueue<T> {
private final Object[] items;
private int count = 0;
private int putIndex = 0;
private int takeIndex = 0;
public synchronized void put(T item) throws InterruptedException {
while (count == items.length) {
wait(); // 队列满时等待
}
items[putIndex] = item;
putIndex = (putIndex + 1) % items.length;
count++;
notifyAll(); // 唤醒等待的消费者
}
public synchronized T take() throws InterruptedException {
while (count == 0) {
wait(); // 队列空时等待
}
T item = (T) items[takeIndex];
takeIndex = (takeIndex + 1) % items.length;
count--;
notifyAll(); // 唤醒等待的生产者
return item;
}
}这种实现虽然简单,但存在几个明显缺陷:
-
锁粒度粗 :整个方法都被
synchronized修饰,同一时刻只能有一个线程执行入队或出队操作 -
虚假唤醒问题 :必须使用
while循环而不是if来检查条件 -
无法区分通知对象 :
notifyAll()会唤醒所有等待线程,无论它们是在等待队列非空还是队列非满
2.2 现代方案:ReentrantLock + Condition
ArrayBlockingQueue采用了更先进的并发控制机制:
java
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// 底层存储:循环数组
final Object[] items;
// 并发控制的核心:可重入锁
final ReentrantLock lock;
// 两个条件变量:分别对应不同的等待条件
private final Condition notEmpty;
private final Condition notFull;
// 队列状态指示器
int count; // 当前元素数量
int putIndex; // 下一个插入位置
int takeIndex; // 下一个取出位置
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
// 创建可重入锁,fair决定是否公平锁
lock = new ReentrantLock(fair);
// 从锁创建两个条件变量
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
}三、Condition机制深度解析
3.1 Condition的工作原理
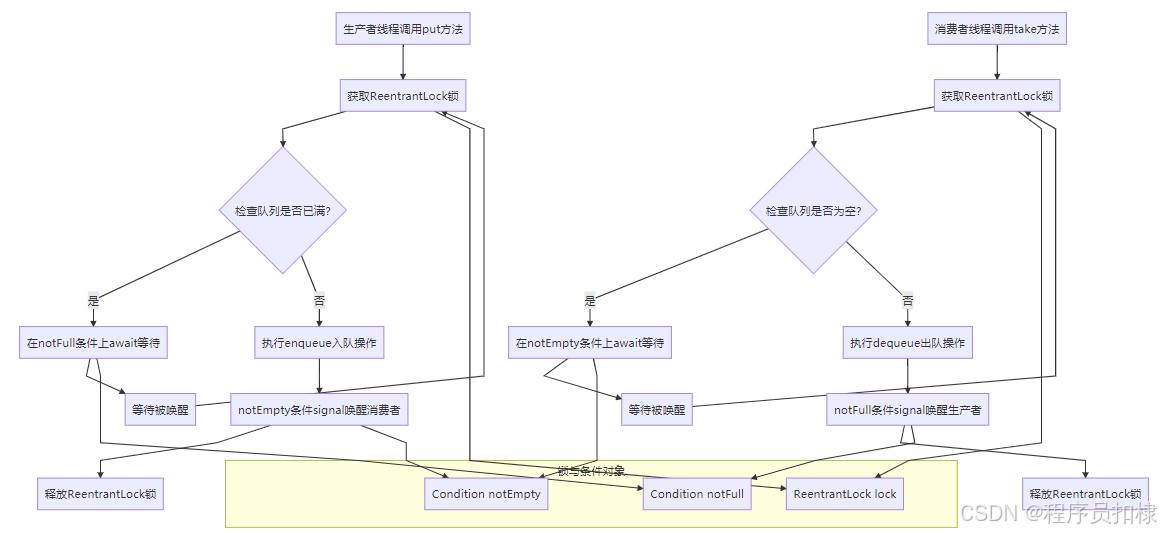
Condition本质上是一个等待队列(wait queue),它与Lock对象绑定。每个Condition对象都维护着一个等待线程的队列。当线程调用condition.await()时,它会被添加到该条件队列中并释放锁;当其他线程调用condition.signal()时,会从条件队列中移出一个线程并将其放入锁的同步队列中,等待获取锁。
这种设计带来了两大优势:
-
精准通知:可以针对不同的等待条件(队列空、队列满)分别进行通知
-
减少竞争:避免不必要的线程唤醒,减少线程上下文切换的开销
3.2 put()方法的实现细节
让我们看看ArrayBlockingQueue.put()方法的完整实现逻辑:
java
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly(); // 获取锁,支持中断
try {
while (count == items.length) {
// 队列已满,在notFull条件上等待
notFull.await();
}
// 执行入队操作
enqueue(e);
} finally {
lock.unlock(); // 释放锁
}
}
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0; // 循环数组:到达末尾时回到开头
count++;
// 入队后队列肯定非空,唤醒等待的消费者
notEmpty.signal();
}关键点分析:
-
锁的可中断获取 :
lockInterruptibly()允许线程在等待锁的过程中响应中断 -
条件等待的循环检查 :必须使用
while而不是if,防止虚假唤醒 -
精准信号发送:只在状态改变时发送必要的信号
3.3 take()方法的对称实现
java
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
// 队列为空,在notEmpty条件上等待
notEmpty.await();
}
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null; // 帮助GC
if (++takeIndex == items.length)
takeIndex = 0; // 循环数组处理
count--;
// 出队后队列肯定非满,唤醒等待的生产者
notFull.signal();
return x;
}四、Lock+Condition vs synchronized+wait/notify:优势对比
4.1 灵活性差异
-
多条件变量支持:
-
Lock可以创建多个Condition对象,每个条件对应不同的等待集 -
synchronized只有一个等待集,所有等待线程都在同一个队列中
-
-
锁的公平性控制:
-
ReentrantLock可以指定公平锁或非公平锁 -
synchronized只提供非公平锁
-
-
锁获取方式:
-
Lock.tryLock():尝试获取锁,立即返回结果 -
Lock.lockInterruptibly():可中断的锁获取 -
synchronized无法实现这些灵活的锁获取策略
-
4.2 性能考量
在低竞争场景下,两者的性能差异不大。但在高竞争环境下:
-
吞吐量 :
ReentrantLock的非公平模式通常比synchronized有更高的吞吐量 -
可伸缩性 :
Lock的实现通常提供更好的可伸缩性 -
适应性自旋 :现代JVM对
synchronized进行了大量优化(如偏向锁、轻量级锁),但在特定场景下Lock仍有优势
4.3 功能性增强
-
锁超时机制 :
Lock.tryLock(long, TimeUnit)支持超时等待 -
锁状态查询 :
Lock.isLocked()、Lock.getQueueLength()等方法 -
条件等待超时 :
Condition.await(long, TimeUnit)支持超时等待
五、实际应用场景与最佳实践
5.1 何时选择ArrayBlockingQueue
-
固定大小队列:当需要限制队列大小,防止内存溢出时
-
公平性需求:当需要公平的线程调度(先等待的线程先获得服务)时
-
简单场景:当不需要LinkedBlockingQueue那样的高吞吐量时
5.2 使用注意事项
-
避免死锁:确保锁总是在finally块中释放
-
正确处理中断:考虑业务逻辑对中断的响应方式
-
合理设置队列容量:根据生产者和消费者的处理能力平衡设置
5.3 性能调优建议
java
// 根据场景选择公平性
// 公平锁:保证线程按等待顺序获取锁,吞吐量较低
ArrayBlockingQueue<String> fairQueue =
new ArrayBlockingQueue<>(1000, true);
// 非公平锁:吞吐量较高,但可能导致线程饥饿
ArrayBlockingQueue<String> unfairQueue =
new ArrayBlockingQueue<>(1000, false);六、扩展思考:与现代并发模式的结合
6.1 与CompletableFuture结合
java
ArrayBlockingQueue<Task> taskQueue = new ArrayBlockingQueue<>(100);
// 生产者
CompletableFuture.runAsync(() -> {
taskQueue.put(new Task());
});
// 消费者
CompletableFuture.supplyAsync(() -> {
try {
return taskQueue.take().process();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});6.2 在响应式编程中的应用
在响应式系统中,ArrayBlockingQueue可以作为背压(backpressure)策略的一部分,控制数据流的速度,防止快速生产者淹没慢速消费者。
七、总结
ArrayBlockingQueue通过ReentrantLock和Condition的组合,提供了一个高效、灵活、可靠的阻塞队列实现。这种设计不仅解决了线程安全问题,还通过分离的等待条件(notEmpty和notFull)实现了精准的线程唤醒,大大减少了不必要的线程竞争和上下文切换。
选择Lock+Condition而非synchronized+wait/notify,体现了Java并发编程的演进:从简单的互斥同步到细粒度的条件控制,从基础的线程协作到高性能的并发数据结构。理解这些底层机制,不仅有助于我们更好地使用ArrayBlockingQueue,更能提升我们设计高并发系统的能力。
在日益复杂的分布式和高并发场景下,掌握这些核心并发原语的工作原理,是每一位Java开发者的必备技能。ArrayBlockingQueue的设计思想,正是这种并发编程智慧的集中体现。