SVM NN等分类方法是基于连续实数或离散值的特征向量的模式识别问题,这类问题都涉及了向量间距离度量的问题,比如KNN中直接使用了点之间的距离,N中隐含了距离信息,如果两个输入向量足够接近,那么输出也会很相似,SVM让各个点离超平面的距离最远
但是现实中的模式识别问题,样本属性不一定是可度量的,这种属性没有相似概念,也没有次序关系。非度量语义属性表示的模式常用属性d元组。另一种方式就是用不等长语义属性的列表


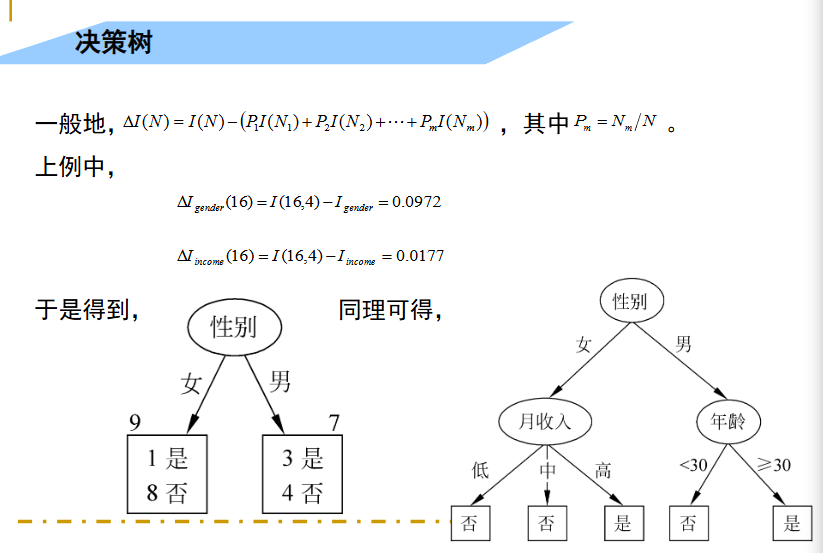
二、决策树


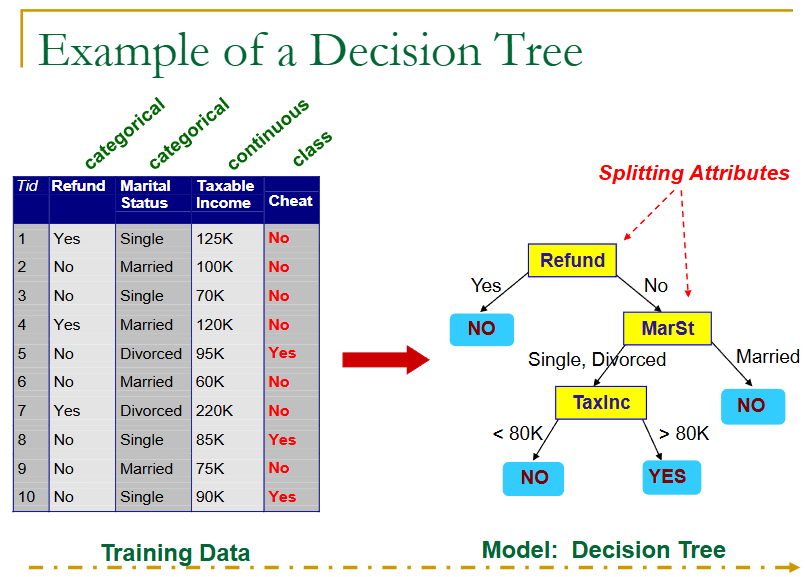
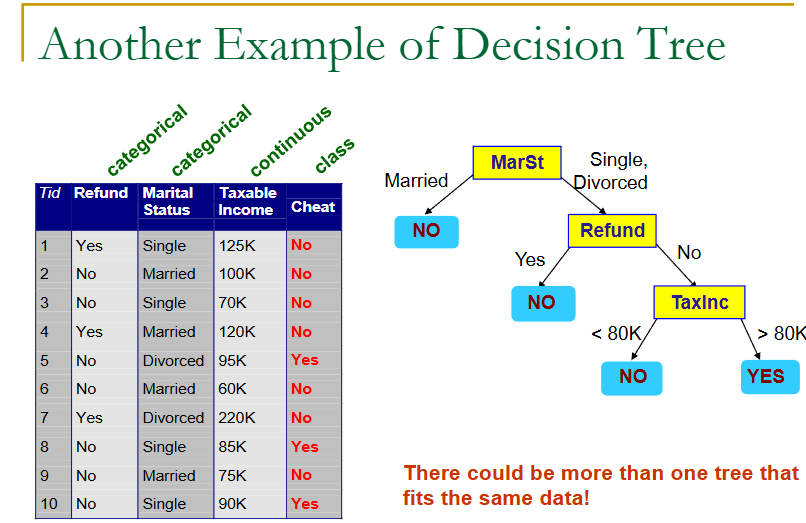
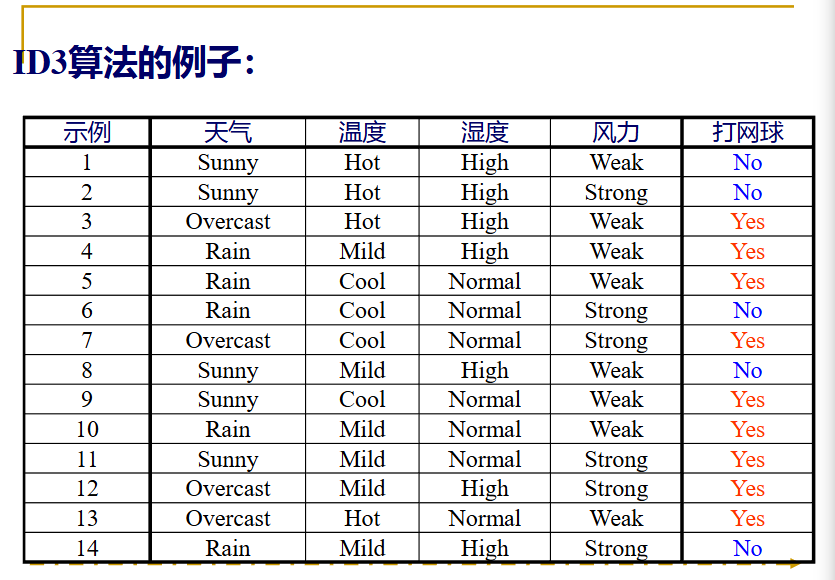
来看一个例子:
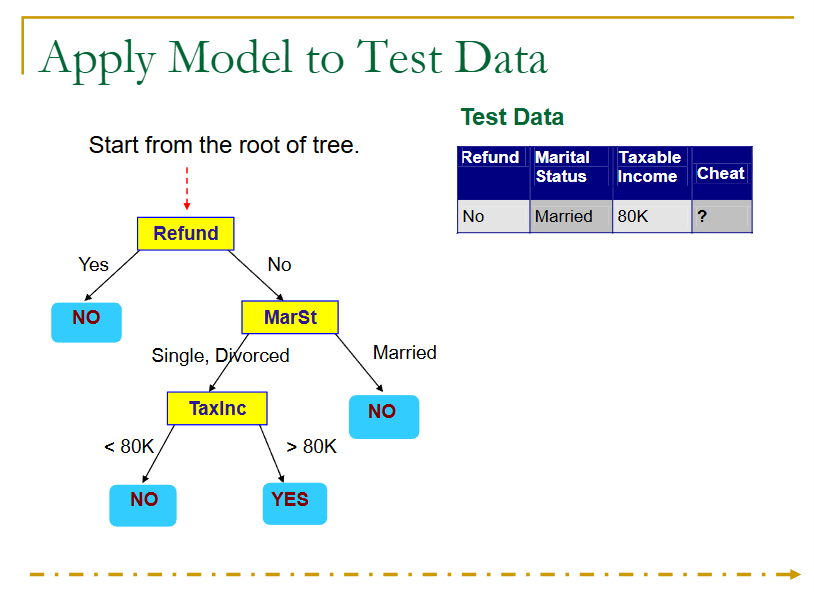
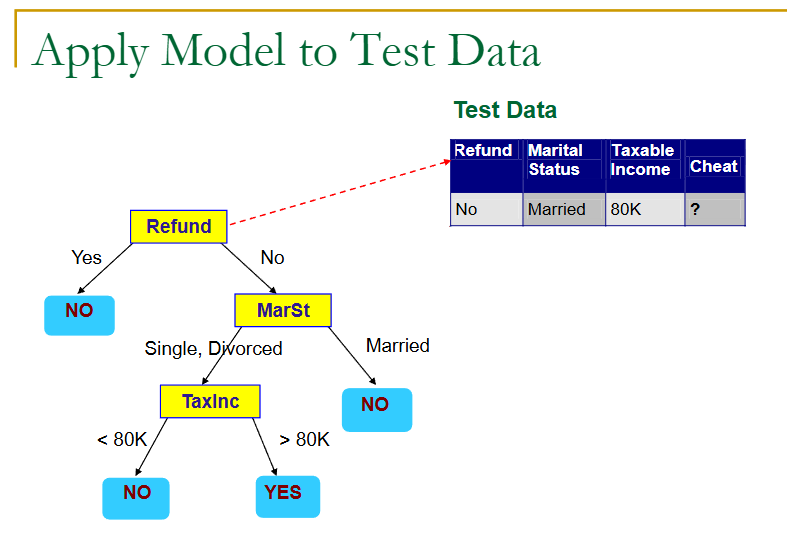
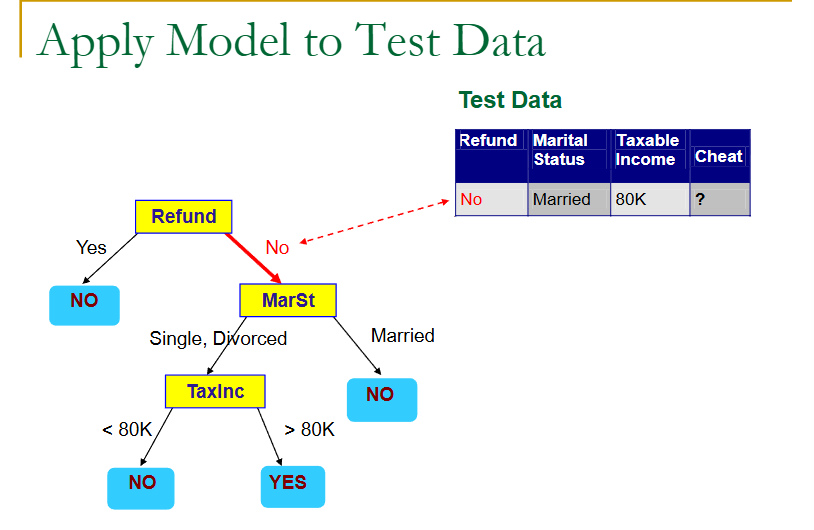
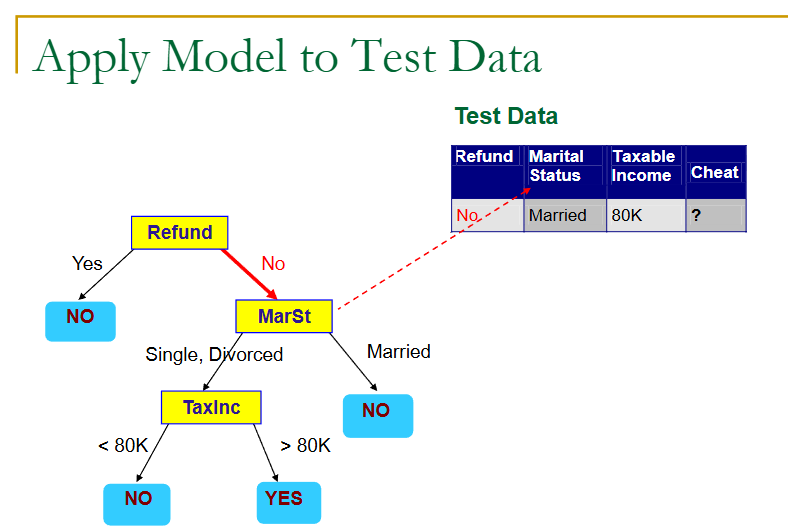
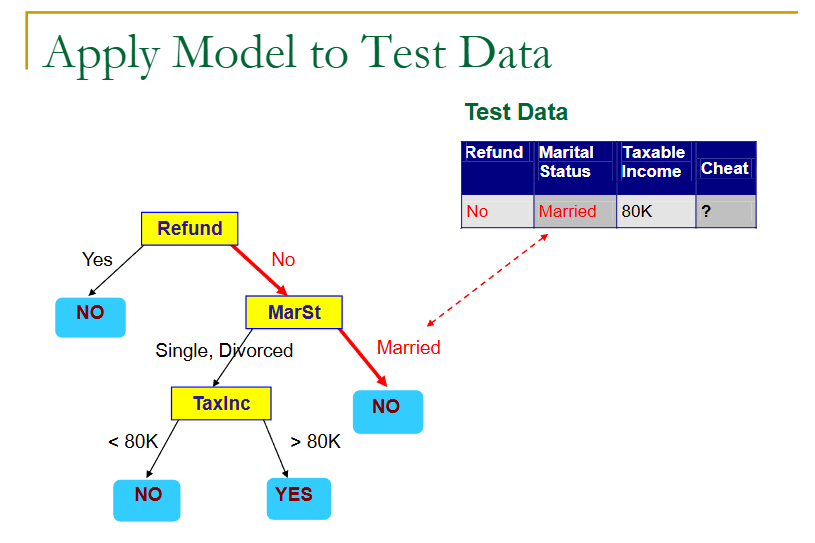
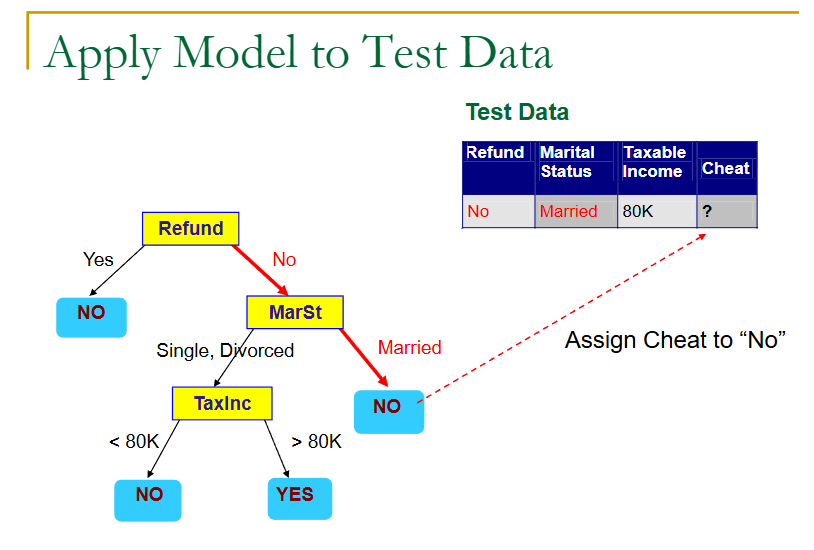
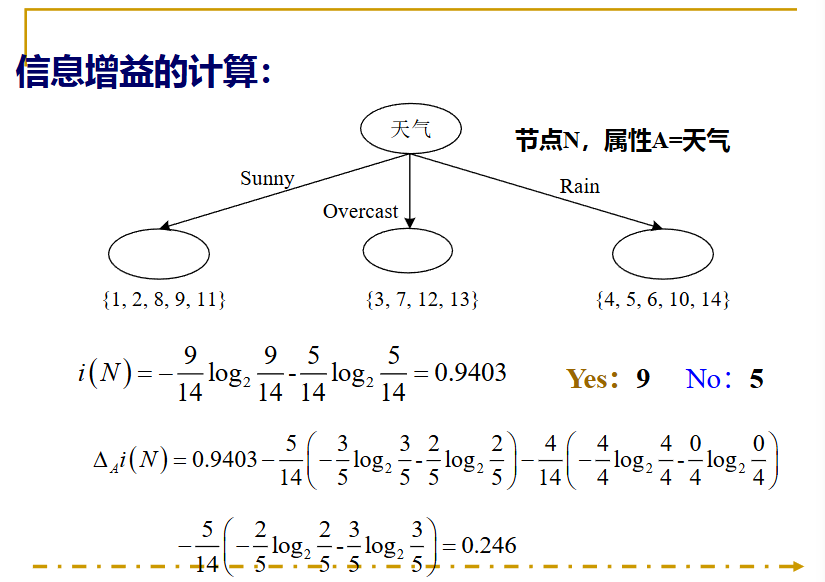
上面就是一个树的生成,但是用用的判定树生成,是如何根据训练样本来生成一棵树呢?

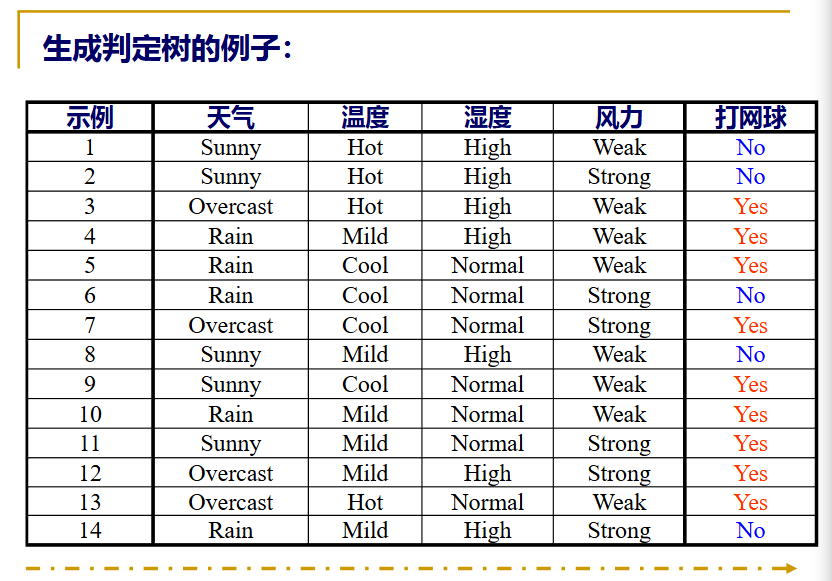
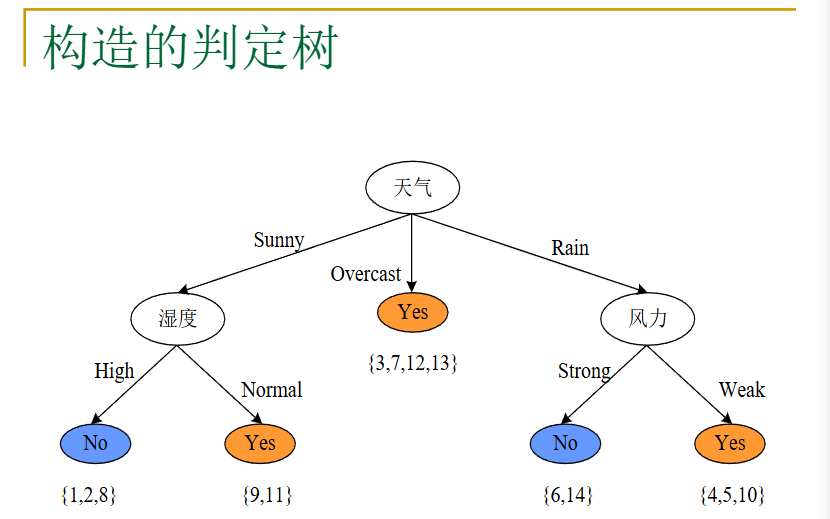


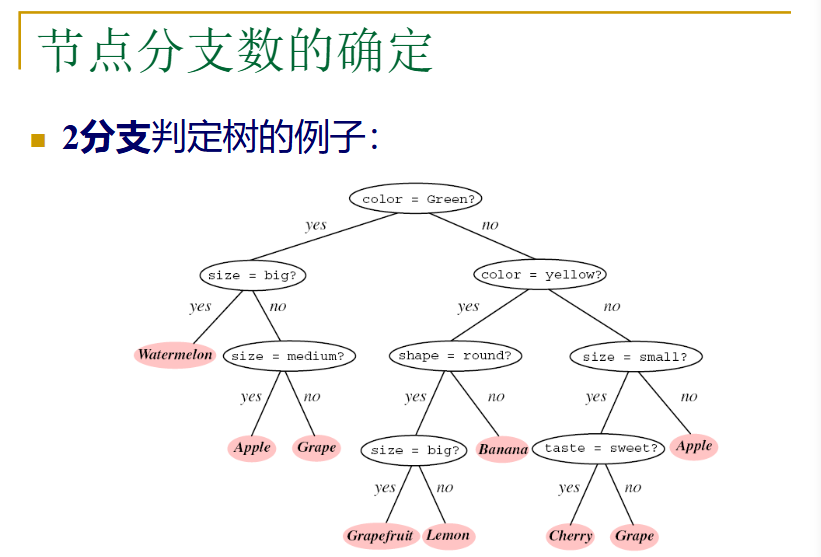

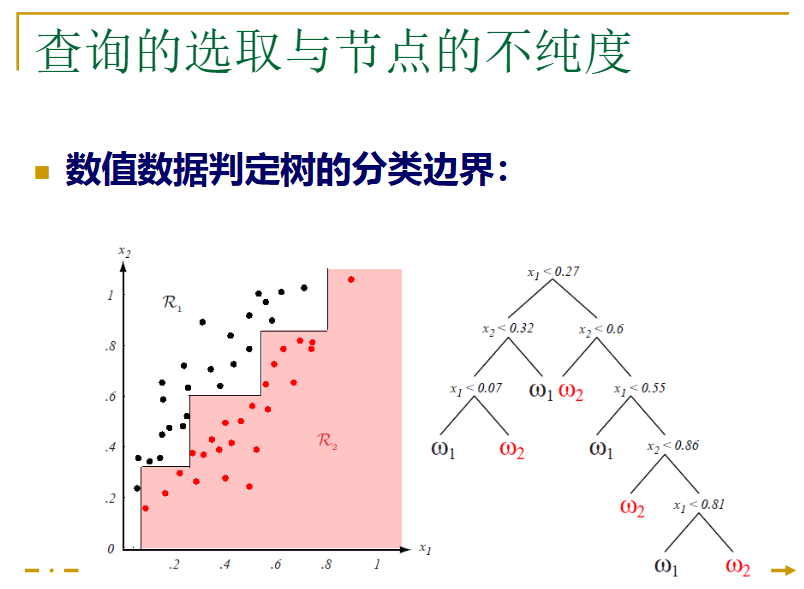


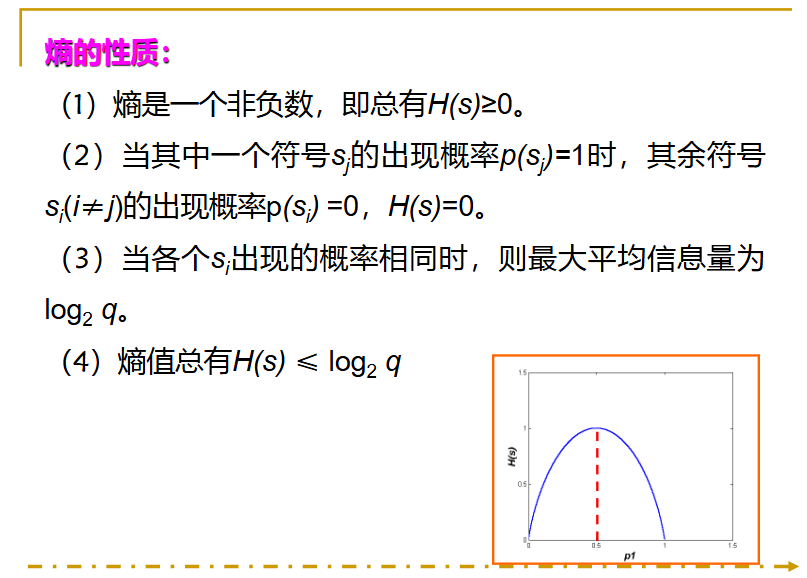













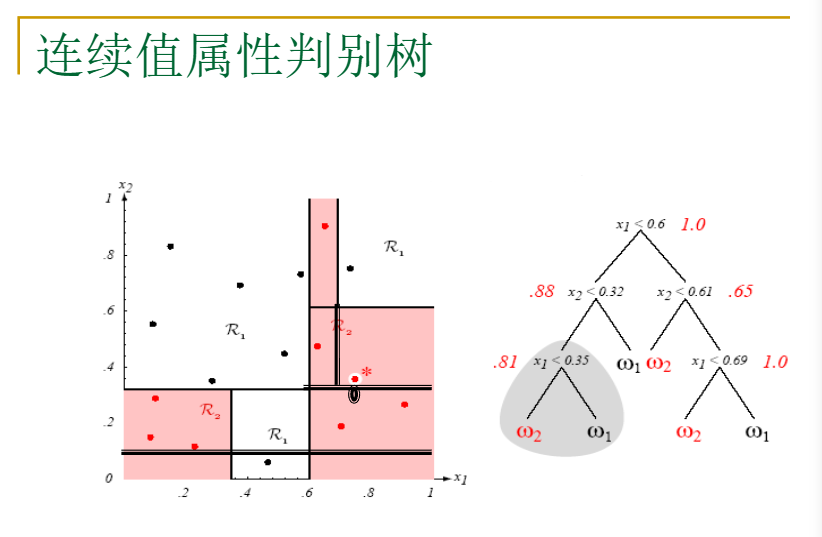
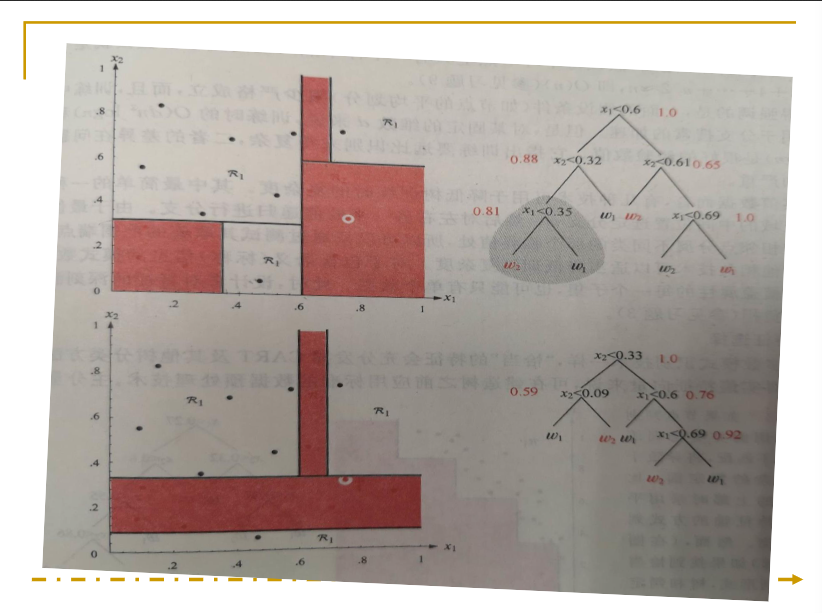
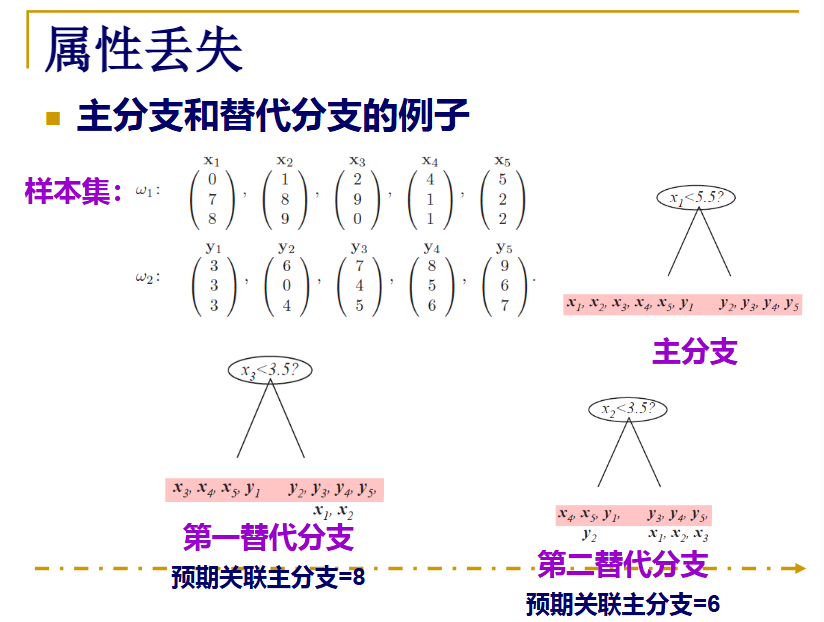
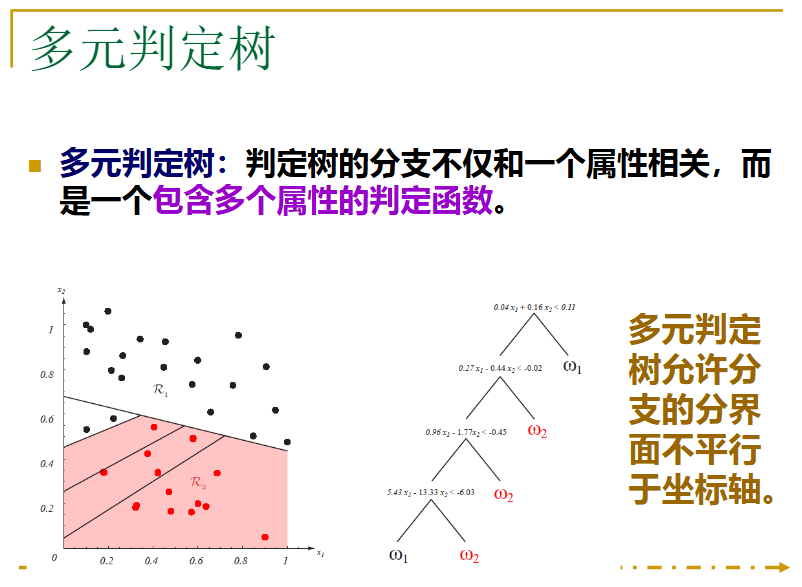
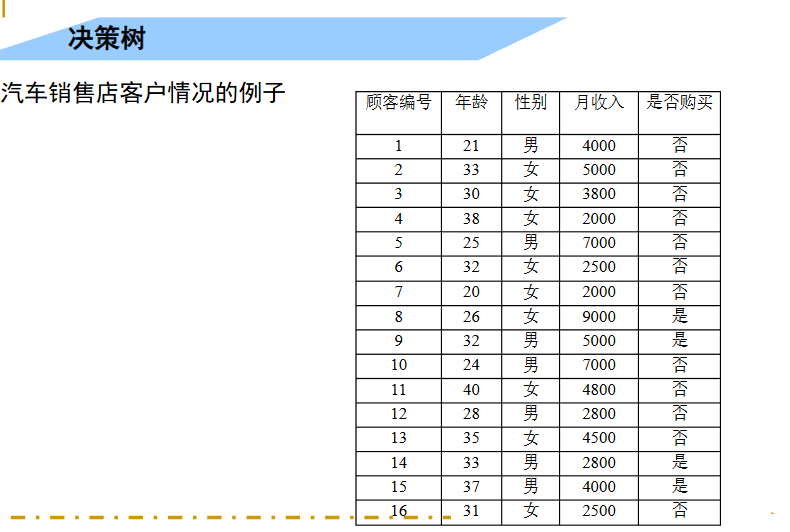
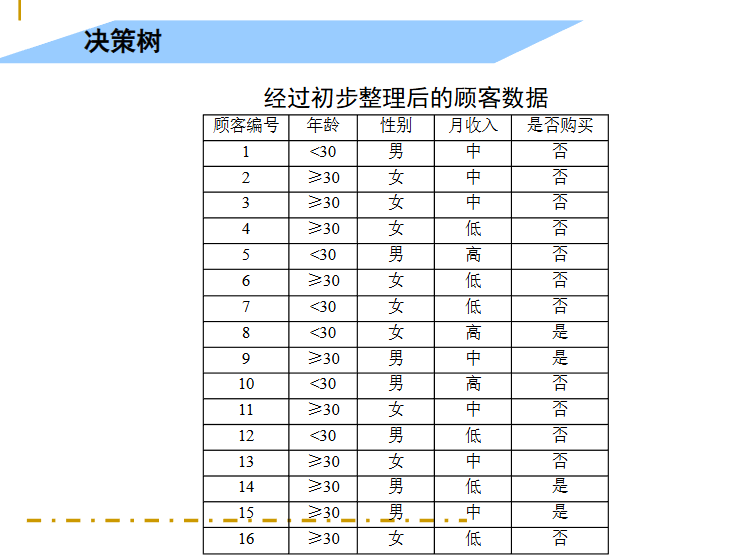
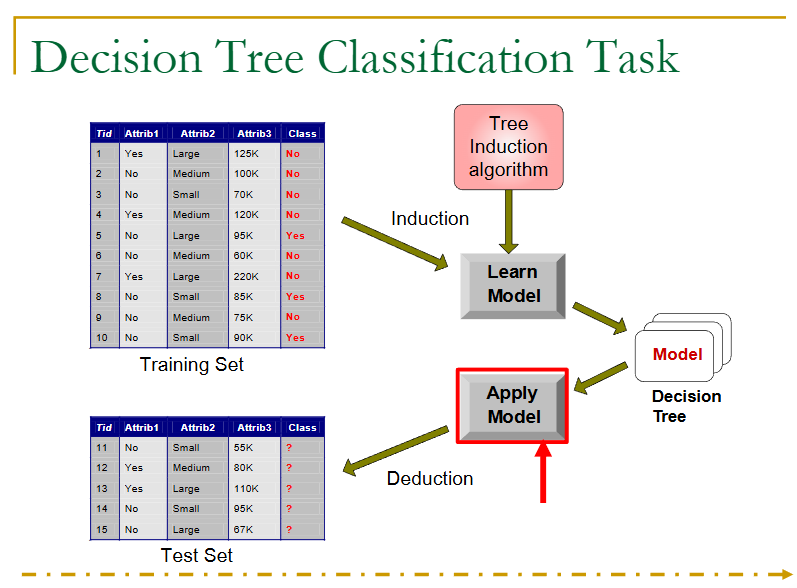
看下面一个例子: