概览
工作流即代码
- 动态性: 代码中定义可以动态生成DAG并且参数化
- 可拓展性: airflow框架包含很多内置的
operators, 可以根据需求进行拓展 - 灵活性: 利用Jinja模板, 允许自定义
DAG
DAG是一个模型(模式), 封装了执行工作流的一切
- 调度: 工作流何时运行
- 任务: 任务是在worker上运行的离散单元
- 任务依赖: 任务执行的顺序和条件
- 回调: 当整个工作流完成时做的事情
- 附加参数: 许多操作细节
优点
批处理平台, 灵活的框架, 内置的operators, 兼容性好(新技术集成)
- 版本控制: 跟踪变更, 会滚代码, 团队协作
- 团队协作: 多个开发者可以处理同一个工作流代码
- 测试: 通过单元测试和集成测试来验证流水线逻辑
- 可拓展型: 庞大的现有组件生态系统来自定义构建自己的组件
缺点
不适用于持续运行的, 事件驱动的或者流式的工作负载, 需要编写代码
核心概念
架构
- 调度器(Scheduler), 触发调度工作流, 将任务(Task)提交给Executor运行, Executor是调度器的配置属性, 而不是独立的组件, 它运行在调度器进程内部. 有多种Executor可以选择, 也可以编写自己的Executor
- 处理器(Processor), 解析DAG文件并且将其序列化到原数据数据库
- Web服务器(WebServer), 提供方便的用户界面来检查, 触发和调试DAGs和任务行为
- 元数据数据库(metadata database), Airflow组件来存储工作流和任务状态
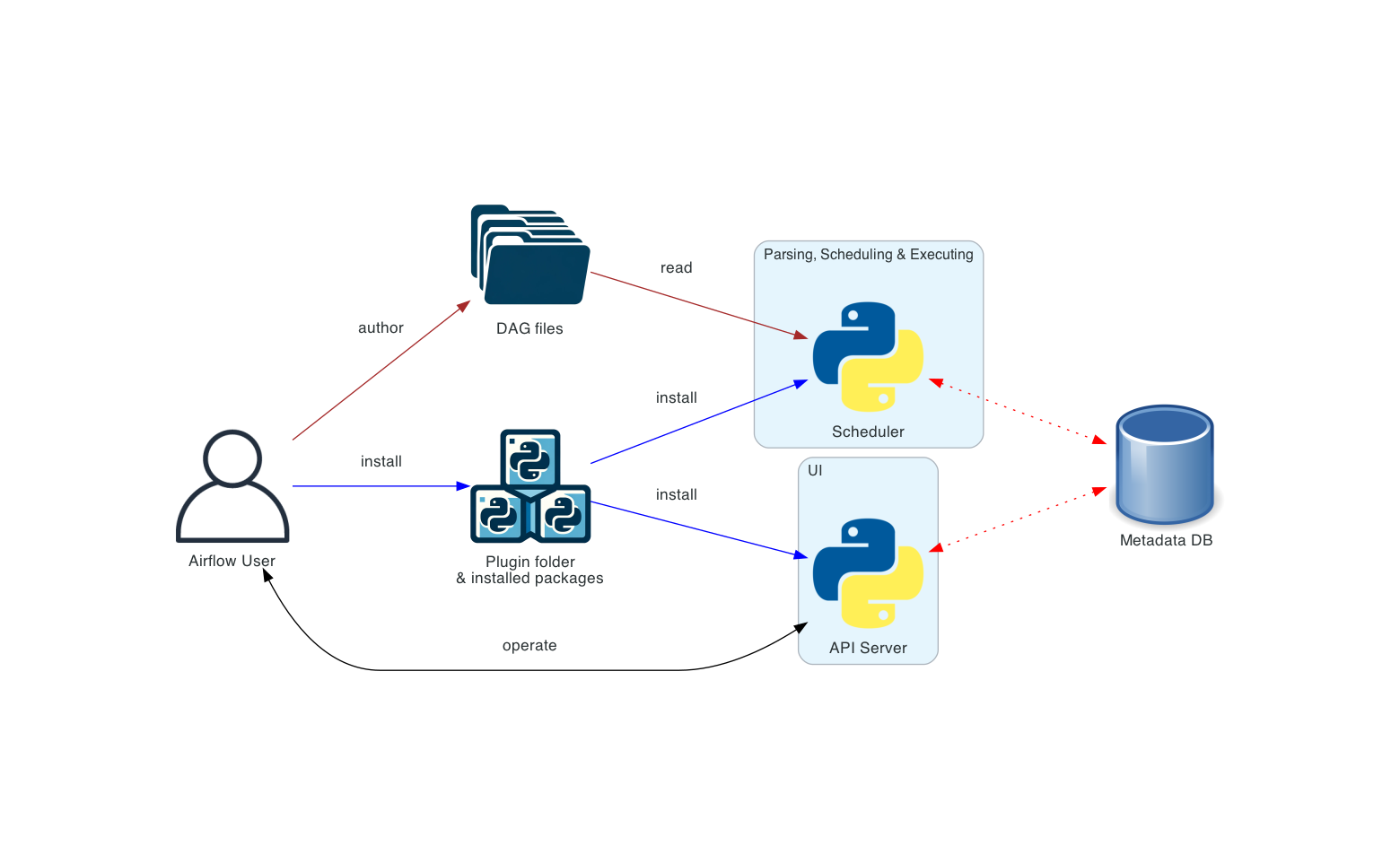
单机架构
单台机器上运行和管理。这种部署方式通常使用 LocalExecutor,其中调度器和工作进程位于同一个 Python 进程中,调度器直接从本地文件系统读取DAG 文件。Web服务器与调度器运行在同一台机器上。由于没有触发组件,因此无法进行任务延迟
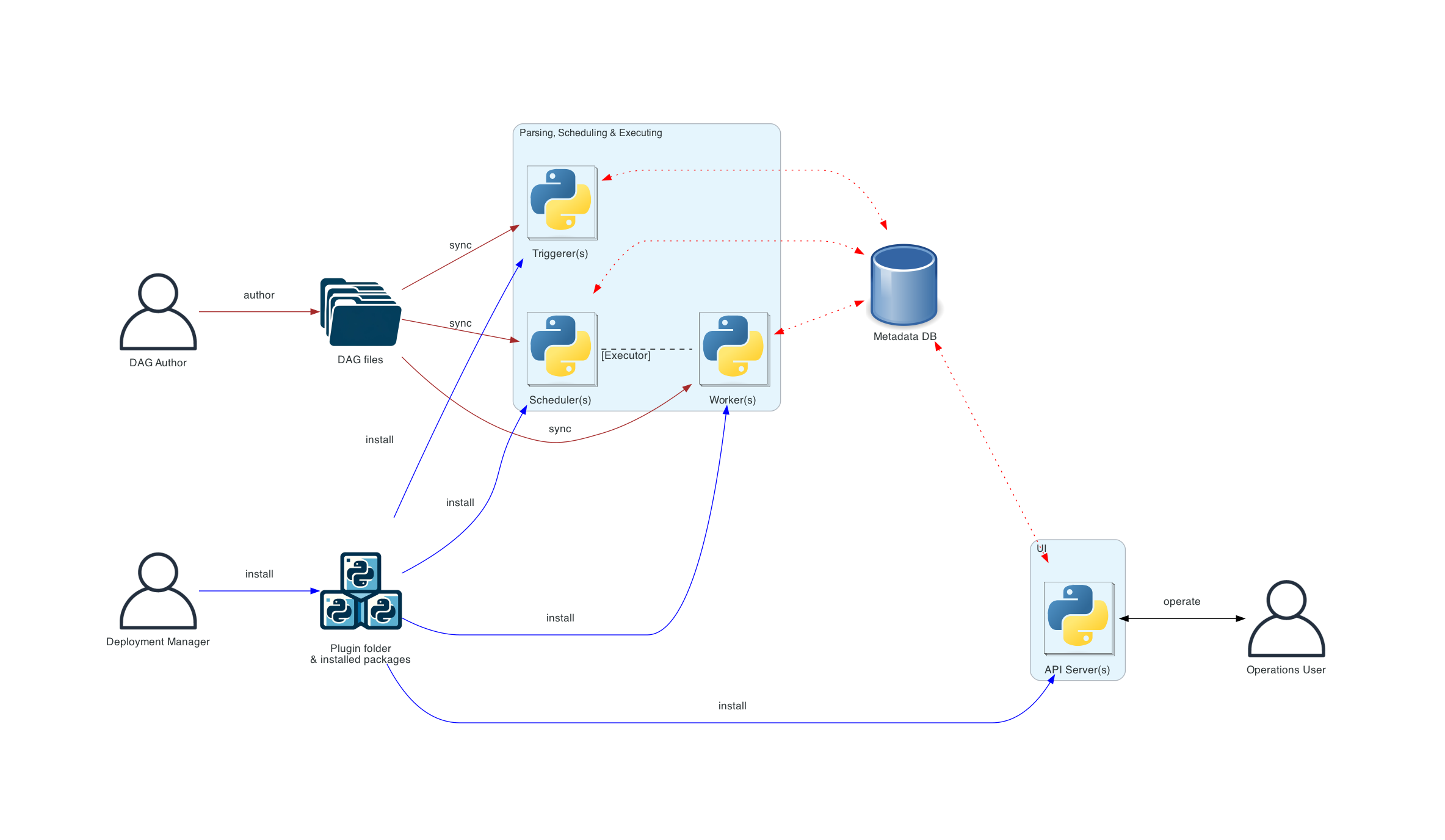
分布式架构
引入了各种用户角色------部署管理员、DAG 作者和 运维用户, Web服务器无法直接访问DAG 文件Code。用户界面选项卡中的代码是从元数据数据库读取的。Web服务器无法执行DAG 作者提交的任何代码,
只能执行部署管理器安装的软件包或插件中的代码。运维用户仅拥有用户界面访问权限,只能触发 DAG 和任务,而不能创建 DAG。
所有使用 DAG 文件的组件(调度器、 触发器和工作进程)都需要保持DAG文件同步
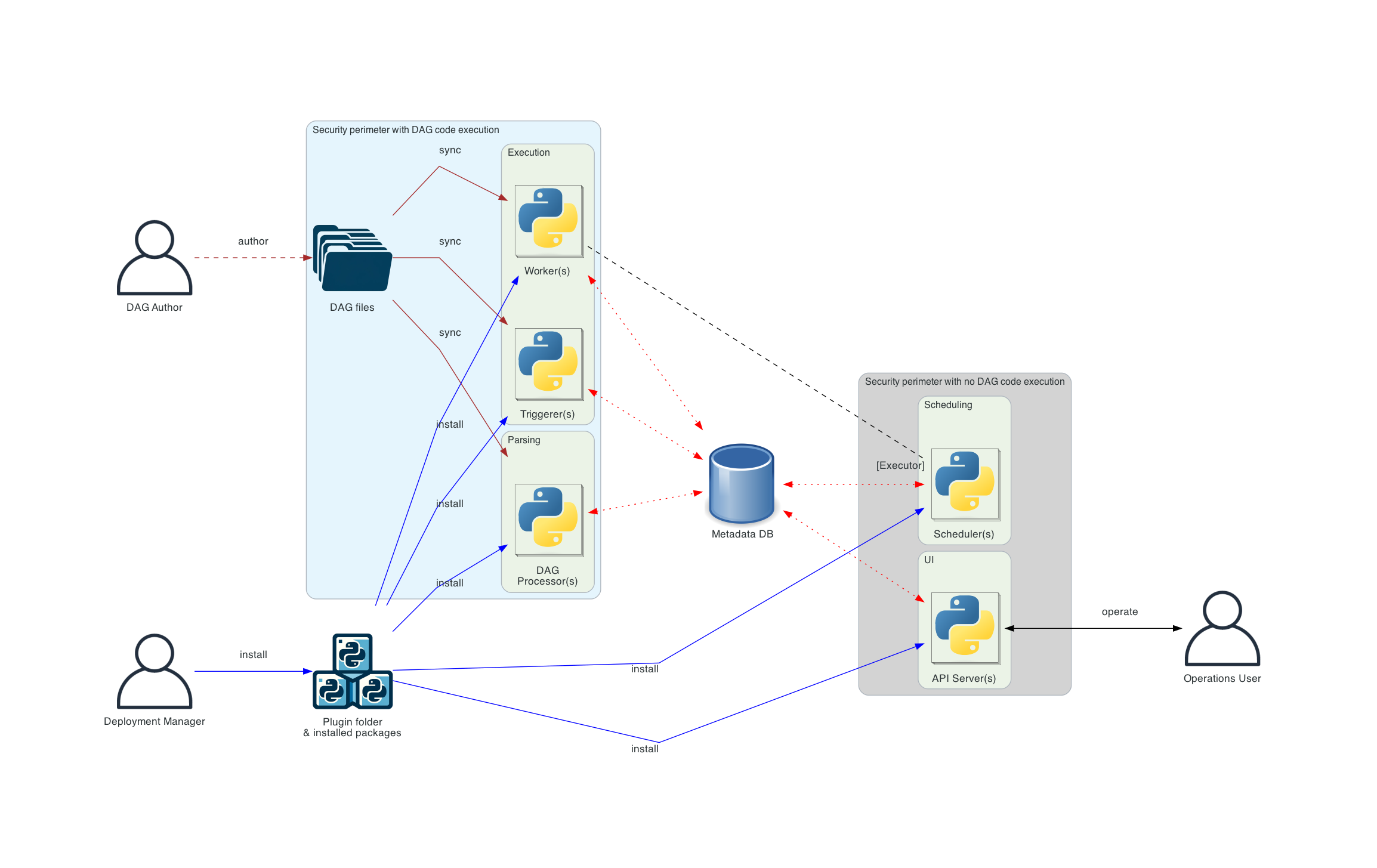
独立的调度器
在安全性和隔离性至关重要的更复杂的部署环境中,您还会看到独立的DAG 处理器组件,它允许将调度器与DAG 文件访问分离。如果部署的重点在于解析任务之间的隔离,则此组件非常适用。虽然 Airflow 目前尚不支持完整的多租户功能,但它可以确保DAG 作者提供的代码永远不会在调度器的上下文中执行
可选组件
- 工作进程(Worker), 执行调度器分配的任务, 作为调度器的一部分
- 触发器(Triggerer), 在asyncio事件循环中执行延迟任务
- 插件(Plugin)文件夹, 拓展airflow功能, 由调度器, DAG处理器, 触发器和Web服务器读取
工作负载
DAG通过一系列任务运行, 会看到三种常见的任务类型
- Operator: 预定义的任务, 可以快速将他们串联构建大部分DAG
- Sensor: Operator的子类, 转门等待外部事件发生
- 由TaskFlow装饰器
@task标记的任务, 打包成任务的自定义Python函数
内部实际都是baseOperator的子类, Task和Operator的概念在某种程度互换, 但是他们视为独立的概览都可以, 本质上Operator和Sensor是模板, 调用时会创建一个Task
控制流
DAG被设计成可以多次运行, 并且可以并行进行多次运行, DAGs是参数化的, 总是包含运行时事件间隔, 但也可以包含其他可选参数
任务之间声明了依赖关系, 例如>>和<<Operator
python
first_task >> [second_task, third_task]
fourth_task << third_task或者使用set_upstream和set_downstream方法
python
first_task.set_downstream([second_task, third_task])
fourth_task.set_upstream(third_task)依赖关系构成了图的边, 默认情况一个任务会等待上游所有的任务成功后才会运行, 也可以使用分支(Branching), 只运行最新(LatestOnly)和触法规则(TriggerRules)等功能进行定制
任务之间传递数据
- XComs(跨任务通信): 一个系统, 任务可以在其中推送和拉取少量元数据
- 从存储服务: 上传和下载大文件
- TaskFlow API: 通过隐式的
XComs自动在任务之间传递数据
DAGs
DAG是一种模型, 封装了执行工作流所需的一切, 属性包括
- 调度: 工作流应该在什么时候运行
- 任务: 是在Worker上运行的离散单元
- 任务依赖: 任务执行的顺序和条件
- 回调: 整个工作流完成时要采取的行动
- 附加参数: 以及其他操作细节
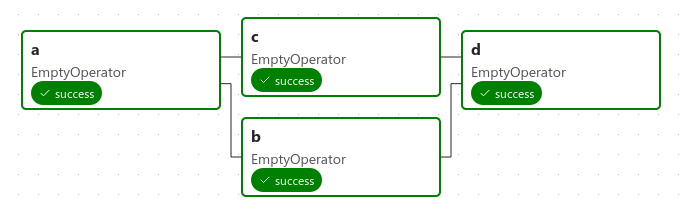
它定义了四个任务------A、B、C 和 D------并规定了它们的运行顺序,以及哪些任务依赖于其他任务。它还会说明 DAG 运行的频率------也许是"从明天开始每 5 分钟一次",或者"从 2020 年 1 月 1 日开始每天一次"。
DAG 本身不关心任务内部正在发生什么;它只关心如何执行它们------它们的运行顺序、重试次数、是否有超时等。
声明DAG
使用with语句
python
import datetime
from airflow.sdk import DAG
from airflow.providers.standard.operators.empty import EmptyOperator
with DAG(
dag_id="my_dag_name",
start_date=datetime.datetime(2021, 1, 1),
schedule="@daily",
):
EmptyOperator(task_id="task")使用构造函数
python
import datetime
from airflow.sdk import DAG
from airflow.providers.standard.operators.empty import EmptyOperator
my_dag = DAG(
dag_id="my_dag_name",
start_date=datetime.datetime(2021, 1, 1),
schedule="@daily",
)
EmptyOperator(task_id="task", dag=my_dag)使用装饰器
python
import datetime
from airflow.sdk import dag
from airflow.providers.standard.operators.empty import EmptyOperator
@dag(start_date=datetime.datetime(2021, 1, 1), schedule="@daily")
def generate_dag():
EmptyOperator(task_id="task")
generate_dag()任务依赖
依赖于其他任务, 声明DAG的结构
推荐使用>>或者<<
python
first_task >> [second_task, third_task]
third_task << fourth_task更明确的set_upstream和set_downstream方法
python
first_task.set_downstream([second_task, third_task])
third_task.set_upstream(fourth_task)更复杂的依赖关系
python
from airflow.sdk import cross_downstream
# Replaces
# [op1, op2] >> op3
# [op1, op2] >> op4
cross_downstream([op1, op2], [op3, op4])链接关系chain
python
from airflow.sdk import chain
# Replaces op1 >> op2 >> op3 >> op4
chain(op1, op2, op3, op4)
# You can also do it dynamically
chain(*[EmptyOperator(task_id=f"op{i}") for i in range(1, 6)])加载DAG
Airflow会从DAG包中的Python源文件加载DAG, 会获取每个文件, 执行它, 然后从该文件中加载任何DAG对象 , 可以在Python中定义多个DAG, 甚至可以使用倒入功能将一个非常复杂的DAG分散到多个Python文件
Airflow加载DAG时只会拉取位于顶层 的DAG实例对象
python
# 会加载
dag_1 = DAG('this_dag_will_be_discovered')
def my_function():
dag_2 = DAG('but_this_dag_will_not')
# 不会加载
my_function()当在DAG包中搜索DAG时,Airflow只考虑包含字符串airflow和dag(不区分大小写)的Python文件
可以提供一个.airflowignore文件,该文件描述了加载器要忽略的文件模式。它涵盖了所在目录及其下的所有子文件夹。有关文件语法的详细信息
运行DAG
- 手动或者通过
API触法 - 按照
DAG定义去调度
DAG不要求必须定义调度, 可以通过schedule参数来定义
python
with DAG("my_daily_dag", schedule="@daily"):
...
with DAG("my_daily_dag", schedule="0 0 * * *"):
...
with DAG("my_one_time_dag", schedule="@once"):
...
with DAG("my_continuous_dag", schedule="@continuous"):
...每次运行DAG时都会创建一个新的实例, 称为DAG运行(DAG Run), 同一个DAG可以并行运行多个, 每个DAG运行都有一个定义的数据间隔, 用于标识应该处理的数据期间
DAG 运行有开始日期和结束日期。这个期间描述了 DAG 实际"运行"的时间。除了 DAG 运行的开始和结束日期外,还有一个称为逻辑日期 (logical date) (正式名称为执行日期 (execution date))的日期,它描述了 DAG 运行计划或触发的预期时间。之所以称为逻辑 ,是因为它具有抽象性,取决于 DAG 运行的上下文,可能具有多种含义
例如,如果 DAG 运行由用户手动触发,则其逻辑日期将是 DAG 运行触发的日期和时间,其值应等于 DAG 运行的开始日期。然而,当 DAG 根据设定的调度间隔自动调度时,逻辑日期将指示数据间隔开始的时间点,此时 DAG 运行的开始日期将是逻辑日期 + 调度间隔。
DAG分配
为了执行, 每个运算符和任务都必须分配给一个DAG, Airflow有几种方法可以在不显式传递DAG的情况下计算出
with DAG声明运算符- 在
@dag装饰器声明运算符 - 将运算符放在
DAG的上游或者下游
否则必须使用dag=传递给每个运算符
DAG装饰器
python
@dag(
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
)
def example_dag_decorator(url: str = "http://httpbin.org/get"):
"""
DAG to get IP address and echo it via BashOperator.
:param url: URL to get IP address from. Defaults to "http://httpbin.org/get".
"""
get_ip = GetRequestOperator(task_id="get_ip", url=url)
@task(multiple_outputs=True)
def prepare_command(raw_json: dict[str, Any]) -> dict[str, str]:
external_ip = raw_json["origin"]
return {
"command": f"echo 'Seems like today your server executing Airflow is connected from IP {external_ip}'",
}
command_info = prepare_command(get_ip.output)
BashOperator(task_id="echo_ip_info", bash_command=command_info["command"])
example_dag = example_dag_decorator()默认参数
DAG的许多运算符需要将一组相同的默认参数, 默认参数可以通过传递default_args, 将自动应用于与其关联的任何运算符
python
import pendulum
with DAG(
dag_id="my_dag",
start_date=pendulum.datetime(2016, 1, 1),
schedule="@daily",
default_args={"retries": 2},
):
op = BashOperator(task_id="hello_world", bash_command="Hello World!")
print(op.retries) # 2控制流
默认情况只有当一个任务所有依赖都成功时, DAG才会运行这个任务, 但是有几种方法可以修改这种行为
- 分支(Branching): 根据条件选择进入那个任务
- 触法规则(TriggerRules): 设置DAG运行任务的条件
- 设置和拆卸(SetupAndTeardown): 定义设置和拆卸关系
- 仅最新(LatestOnly): 特殊的分支形式, 旨在针对当前运行的DAGs运行
- 依赖过去(DependsOnPast): 任务可以依赖于他自身在之前的运行
分支
@task.branch装饰器非常像@task,但它期望被装饰的函数返回一个任务的 ID(或一个 ID 列表)。指定的任务将被执行,而所有其他路径将被跳过。它也可以返回None来跳过所有下游任务
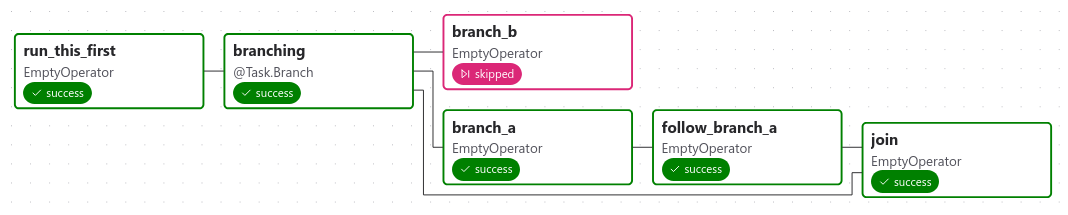
@task.branch也可以与XComs一起使用,允许分支上下文根据上游任务动态决定要遵循哪个分支。例如:
python
@task.branch(task_id="branch_task")
def branch_func(ti=None):
xcom_value = int(ti.xcom_pull(task_ids="start_task"))
if xcom_value >= 5:
return "continue_task"
elif xcom_value >= 3:
return "stop_task"
else:
return None
start_op = BashOperator(
task_id="start_task",
bash_command="echo 5",
do_xcom_push=True,
dag=dag,
)
branch_op = branch_func()
continue_op = EmptyOperator(task_id="continue_task", dag=dag)
stop_op = EmptyOperator(task_id="stop_task", dag=dag)
start_op >> branch_op >> [continue_op, stop_op]继承BaseBranchOperator可以四号线带有分支功能的自定义运算符, 实现choose_branch方法
python
class MyBranchOperator(BaseBranchOperator):
def choose_branch(self, context):
"""
Run an extra branch on the first day of the month
"""
if context['data_interval_start'].day == 1:
return ['daily_task_id', 'monthly_task_id']
elif context['data_interval_start'].day == 2:
return 'daily_task_id'
else:
return None仅最新
会在你不在"最新"的 DAG 运行时(如果当前真实时间在其执行时间 (execution_time) 和下一次计划执行时间之间,且不是外部触发的运行)跳过其下游的所有任务
python
import datetime
import pendulum
from airflow.providers.standard.operators.empty import EmptyOperator
from airflow.providers.standard.operators.latest_only import LatestOnlyOperator
from airflow.sdk import DAG
from airflow.utils.trigger_rule import TriggerRule
with DAG(
dag_id="latest_only_with_trigger",
schedule=datetime.timedelta(hours=4),
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example3"],
) as dag:
latest_only = LatestOnlyOperator(task_id="latest_only")
task1 = EmptyOperator(task_id="task1")
task2 = EmptyOperator(task_id="task2")
task3 = EmptyOperator(task_id="task3")
task4 = EmptyOperator(task_id="task4", trigger_rule=TriggerRule.ALL_DONE)
latest_only >> task1 >> [task3, task4]
task2 >> [task3, task4]在这个 DAG 的情况下:
- task1 是 latest_only 的直接下游,除了最新的运行外,所有运行都会跳过它。
- task2 完全独立于 latest_only,将在所有计划周期中运行。
- task3 是 task1 和 task2 的下游,由于默认的触发规则 (trigger rule) 是 all_success,它将收到来自 task1 的级联跳过。
- task4 是 task1 和 task2 的下游,但它不会被跳过,因为其 trigger_rule 设置为 all_done。
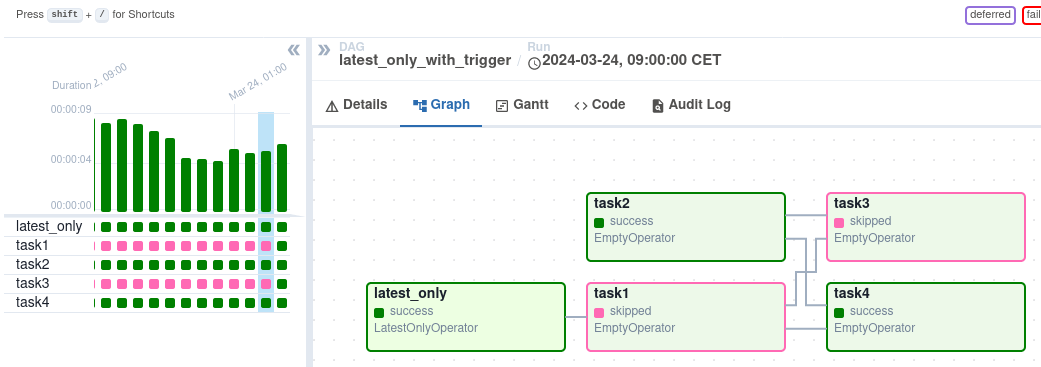
依赖于过去
你也可以说一个任务只有在其在先前 DAG 运行中的上一次 运行成功时才能运行。要使用此功能,你只需将任务的depends_on_past参数设置为True
第一次运行不受影响
触发规则
默认上游都完成执行下游, 但是可以通过触发规则trigger_rule来控制
- all_success (默认): 所有上游任务都已成功。
- all_failed: 所有上游任务都处于 failed 或 upstream_failed 状态。
- all_done: 所有上游任务都已完成执行。
- all_skipped: 所有上游任务都处于 skipped 状态。
- one_failed: 至少有一个上游任务失败(不等待所有上游任务完成)。
- one_success: 至少有一个上游任务成功(不等待所有上游任务完成)。
- one_done: 至少有一个上游任务成功或失败。
- none_failed: 所有上游任务都没有 failed 或 upstream_failed------也就是说,所有上游任务都已成功或被跳过。
- none_failed_min_one_success: 所有上游任务都没有 failed 或 upstream_failed,并且至少有一个上游任务成功。
- none_skipped: 没有上游任务处于 skipped 状态------也就是说,所有上游任务都处于 success、failed 或 upstream_failed 状态。
- always: 完全没有依赖关系,随时运行此任务。
DAG运行
DAG运行表示DAG的实例化对象, 可以同时运行一个DAG多个实例
运行状态
DAG运行状态是基于叶子结点来分配的, 叶子结点是没有子任务的任务, 运行有两种状态
- success(成功): 所有的叶子结点都为
success或者skipped, 为success - failed(失败): 如果叶子节点状态为
failed或者upstream_failed则为failed
数据区间
每个DAG运行都会分配一个数据区间, 代表操作时间范围, 例如@daily, 代表从每天00:00到24:00结束
DAG运行通畅在其关联的数据区间结束之后进行调度, 确保运行时可以手机到这个时间段内所有的数据
重新运行DAG
追赶执行
如果您在 DAG 中设置 catchup=True,调度器将为自上一个数据区间以来尚未运行(或已被清除)的任何数据区间启动一个 DAG 运行。这个概念被称为追赶执行 (Catchup)。
回填执行
您可能希望在指定的历史时期内运行 DAG。例如,创建了一个 start_date 为 2024-11-21 的 DAG,但另一个用户需要一个月前的数据输出,即 2024-10-21。这个过程称为回填执行 (Backfill)。
重新运行任务
在计划运行期间,某些任务可能会失败。在查阅日志并修复错误后,您可以通过清除计划日期的任务实例来重新运行任务。清除任务实例会创建该任务实例的记录。当前任务实例的 try_number 会递增,max_tries 设置为 0,状态设置为 None,这将导致任务重新运行。
在 Tree 或 Graph 视图中单击失败的任务,然后单击 Clear。Executor 将重新运行它。
您可以选择多个选项来重新运行 -
- Past (过去) - DAG 最近数据区间之前运行中的该任务的所有实例
- Future (将来) - DAG 最近数据区间之后运行中的该任务的所有实例
- Upstream (上游) - 当前 DAG 中的上游任务
- Downstream (下游) - 当前 DAG 中的下游任务
- Recursive (递归) - 子 DAG 和父 DAG 中的所有任务
- Failed (失败) - 仅限 DAG 最近一次运行中失败的任务
任务
最基本的执行单元, 通过设置上游和下游的依赖关系表达运行顺序, 有三种基本类型
- 操作符(Operators): 预定义的任务模板, 快速构建DAG的大部分
- 传感符(Sensors): 是
operator的子类, 完成用于等待外部事件的发生 - TaskFlow修饰
@task, 打包成任务自定义Python函数
关系
使用任务的关键在于依赖关系, 需要声明依赖关系
使用 >> 和 <<(位移)操作符
python
first_task >> second_task >> [third_task, fourth_task]
first_task.set_downstream(second_task)
third_task.set_upstream(second_task)任务实例
DAG下的任务会被实例化为任务实例, 具有生命周期阶段
- none: 尚未排队为执行(依赖尚未满足)
- scheduled: 调度器已经确定任务依赖满足并运行
- queued: 任务分配给执行器, 正在等待工作进程
- running: 任务正在工作进程上运行
- success: 任务运行完成无错误
- restarting: 任务在运行时被外部请求重新启动
- failed: 任务在执行完期间发生错误并运行失败
- skipped: 任务因分支, LatestOnly类似的原因被跳过
- upstream_failed: 上游任务失败, 切触发规则要求必须成功
- up_for_retry: 任务失败, 但是还有重试次数
- deferred: 任务已被延迟到触发器
- removed: 运行开始以来, 从DAG中消失

理想情况下,任务应从none依次流经scheduled、queued、running1,最终达到success`状态
超时
如果希望任务有最大超时可以设置execution_timeout, 设置为datetime.timedelta, 允许最大运行时间, 超出会抛出AirflowTaskTimeout异常
以下 SFTPSensor 示例对此进行了说明。该 sensor 处于 reschedule 模式,这意味着它会周期性地执行并重新调度,直到成功。
- 每次传感器探测 SFTP 服务器时,允许的最大时间为 execution_timeout 定义的 60 秒。
- 如果传感器探测 SFTP 服务器耗时超过 60 秒,AirflowTaskTimeout 将被抛出。发生这种情况时,传感器可以重试。最多可以重试 retries 定义的 2 次。
- 从第一次执行开始,直到最终成功(即文件 'root/test' 出现后),传感器允许的最大时间为 timeout 定义的 3600 秒。换句话说,如果文件在 3600 秒内没有出现在 SFTP 服务器上,传感器将抛出 AirflowSensorTimeout。抛出此错误时不会重试。
- 如果在 3600 秒间隔内,传感器由于网络中断等其他原因失败,最多可以重试 retries 定义的 2 次。重试不会重置 timeout。它总共有最多 3600 秒的时间来成功。
python
sensor = SFTPSensor(
task_id="sensor",
path="/root/test",
execution_timeout=timedelta(seconds=60),
timeout=3600,
retries=2,
mode="reschedule",
)操作符(Operator)
操作符在概念上是一个预定义的任务的模板, 可以在DAG中声明式的定义
python
with DAG("my-dag") as dag:
ping = HttpOperator(endpoint="http://example.com/update/")
email = EmailOperator(to="admin@example.com", subject="Update complete")
ping >> email系统操作符
- EmailOperator
- HttpOperator
- SQLExecuteQueryOperator
- DockerOperator
- HiveOperator
- S3FileTransformOperator
- PrestoToMySqlOperator
- SlackAPIOperator
Jinja模板
Airflow结合了Jinja模板, 例如使用BashOperator时将数据传递给Bash
python
# The start of the data interval as YYYY-MM-DD
date = "{{ ds }}"
t = BashOperator(
task_id="test_env",
bash_command="/tmp/test.sh ",
dag=dag,
env={"DATA_INTERVAL_START": date},
)context 和 jinja_env
python
def build_complex_command(context, jinja_env):
with open("file.csv") as f:
return do_complex_things(f)
t = BashOperator(
task_id="complex_templated_echo",
bash_command=build_complex_command,
dag=dag,
)因为模板字段值渲染一次, 所以可调用对象的返回值不会再次渲染可以调用render_template()来完成
python
def build_complex_command(context, jinja_env):
with open("file.csv") as f:
data = do_complex_things(f)
return context["task"].render_template(data, context, jinja_env)传感器(Sensor)
传感器是特殊的operator, 被设计出来做一件事发生, 可以是基于时间的等待, 等待事件成功, 然后执行
主要处于空闲状态, 传感器有两种不同的运行模式, 以便有效的使用
- poke(默认): 传感器在整个运行期间占用Worker插槽
- reschedule: 传感器仅在检查时占用Worker插槽, 并且两次检查之间休眠设定的时常
poke 和 reschedule 模式可以在实例化传感器时直接配置;通常,它们之间的权衡在于延迟。每秒检查一次的传感器应处于 poke 模式,而每分钟检查一次的传感器应处于 reschedule 模式。
TaskFlow
如果是纯Python开发, 而不是编写大量的Operator, 可以使用@task装饰器
TaskFlow会使用XCom在任务之间传递输入和输出, 并且自动计算依赖关系, 调用时候不会立即执行, 而是返回一个XCom(XComArg)对象, 然后将对象作用到Operator的输入
python
from airflow.sdk import task
from airflow.providers.smtp.operators.smtp import EmailOperator
@task
def get_ip():
return my_ip_service.get_main_ip()
@task(multiple_outputs=True)
def compose_email(external_ip):
return {
'subject':f'Server connected from {external_ip}',
'body': f'Your server executing Airflow is connected from the external IP {external_ip}<br>'
}
email_info = compose_email(get_ip())
EmailOperator(
task_id='send_email_notification',
to='example@example.com',
subject=email_info['subject'],
html_content=email_info['body']
)其中email_info的结果不会在调用时立即给出, 而是在调用时email_info['subject']给出
上下文(context)
定义关键字参数来自动注入访问
python
from airflow.models.taskinstance import TaskInstance
from airflow.models.dagrun import DagRun
@task
def print_ti_info(task_instance: TaskInstance, dag_run: DagRun):
print(f"Run ID: {task_instance.run_id}") # Run ID: scheduled__2023-08-09T00:00:00+00:00
print(f"Duration: {task_instance.duration}") # Duration: 0.972019
print(f"DAG Run queued at: {dag_run.queued_at}") # 2023-08-10 00:00:01+02:20添加**kwargs, 自动输入字典访问
python
from airflow.models.taskinstance import TaskInstance
from airflow.models.dagrun import DagRun
@task
def print_ti_info(**kwargs):
ti: TaskInstance = kwargs["task_instance"]
print(f"Run ID: {ti.run_id}") # Run ID: scheduled__2023-08-09T00:00:00+00:00
print(f"Duration: {ti.duration}") # Duration: 0.972019
dr: DagRun = kwargs["dag_run"]
print(f"DAG Run queued at: {dr.queued_at}") # 2023-08-10 00:00:01+02:20传递任意对象
TaskFlow使用XCom变量传递给到每个任务, 要求参数可以被序列化, 支持内置的int/str, 并且支持@dataclass, @attr.define装饰器
python
import json
import pendulum
import requests
from airflow import Asset
from airflow.sdk import dag, task
SRC = Asset(
"https://www.ncei.noaa.gov/access/monitoring/climate-at-a-glance/global/time-series/globe/land_ocean/ytd/12/1880-2022.json"
)
now = pendulum.now()
@dag(start_date=now, schedule="@daily", catchup=False)
def etl():
@task()
def retrieve(src: Asset) -> dict:
resp = requests.get(url=src.uri)
data = resp.json()
return data["data"]
@task()
def to_fahrenheit(temps: dict[int, dict[str, float]]) -> dict[int, float]:
ret: dict[int, float] = {}
for year, info in temps.items():
ret[year] = float(info["anomaly"]) * 1.8 + 32
return ret
@task()
def load(fahrenheit: dict[int, float]) -> Asset:
filename = "/tmp/fahrenheit.json"
s = json.dumps(fahrenheit)
f = open(filename, "w")
f.write(s)
f.close()
return Asset(f"file:///{filename}")
data = retrieve(SRC)
fahrenheit = to_fahrenheit(data)
load(fahrenheit)
etl()自定义对象
需要添加serialize()和deserialize
python
from typing import ClassVar
class MyCustom:
__version__: ClassVar[int] = 1
def __init__(self, x):
self.x = x
def serialize(self) -> dict:
return dict({"x": self.x})
@staticmethod
def deserialize(data: dict, version: int):
if version > 1:
raise TypeError(f"version > {MyCustom.version}")
return MyCustom(data["x"])日志记录
python
logger = logging.getLogger("airflow.task")通过这种方式创建的每一行日志都将记录在任务日志中。
自定义对象传递
自定义对象传递需要添加serialize()和deserialize(data: dict, version: int)
python
from typing import ClassVar
class MyCustom:
__version__: ClassVar[int] = 1
def __init__(self, x):
self.x = x
def serialize(self) -> dict:
return dict({"x": self.x})
@staticmethod
def deserialize(data: dict, version: int):
if version > 1:
raise TypeError(f"version > {MyCustom.version}")
return MyCustom(data["x"])Executor
Executor是运行任务实例的机制, 拥有一个通用API并且是可以插拔的, 意味着可以根据你的安装需求更换Executor, Executor由配置文件中[core]的executor部分设置
markdown
[core]
executor = KubernetesExecutor自定义或者第三方可以通过Python类来配置
markdown
[core]
executor = my.custom.executor.module.ExecutorClassExecutor类型
有本地运行的Executor和远程运行的Executor, 默认是本地的
本地Executor
在调度器进程内部运行
优点: 方便使用, 速度快, 延迟低, 配置少
缺点: 功能有限, 和调度器共享资源
远程Executor
队列/批处理Executor, 比如CeleryExecutor, BatchExecutor
Airflow的任务会发送到一个中心队列, 远程工作进程从队列中拉取任务执行, 通常是持久的, 可以同时运行多个任务
优点: 更健壮, 因为它将工作进程和调度器解耦, 工作进程可以是大型主机, 可以并行处理很多任务, 延迟低, 可以随时增加配置
缺点: 共享进程存在"吵闹邻居"问题, 任务会在共享主机竞争资源, 如果工作负载不是固定的, 可能会很麻烦, 需要管理伸缩
容器化Executor
任务在容器/Pod内执行, 每个任务都在自己的容器化环境中隔离. 该环境在Airflow任务排队时部署
优点: 每个Airflow任务都隔离到一个容器中, 没有资源竞争的问题
缺点: 启动存在延迟, 因为容器或者Pod需要在任务开始前部署, 如果你运行许多小的任务, 可能很昂贵
并行多个Executor
从2.10.0开始, Airflow允许采用多Executor运行, 通常是延迟/隔离/计算效率之间进行权衡, 运行多个Executor可以更好的利用所有的优势避免劣势
第一个executor都是作为默认的Executor
配置
markdown
[core]
executor = LocalExecutor
markdown
[core]
executor = LocalExecutor,CeleryExecutor
markdown
[core]
executor = KubernetesExecutor,my.custom.module.ExecutorClass别名
markdown
[core]
executor = LocalExecutor,ShortName:my.custom.module.ExecutorClass任务指定Executor
markdown
BashOperator(
task_id="hello_world",
executor="LocalExecutor",
bash_command="echo 'hello world!'",
)
markdown
@task(executor="LocalExecutor")
def hello_world():
print("hello world!")整个DAG默认使用的Executor
markdown
def hello_world():
print("hello world!")
def hello_world_again():
print("hello world again!")
with DAG(
dag_id="hello_worlds",
default_args={"executor": "LocalExecutor"}, # Applies to all tasks in the DAG
) as dag:
# All tasks will use the executor from default args automatically
hw = hello_world()
hw_again = hello_world_again()编写自己的Executor
所有的AirflowExecutor都实现了通用的接口, 使其可插拔, 并且任何Executor都可以访问Airflow中所有的能力和集成, 主要的Airflow的调度器使用此接口和Executor交互, 包括日志记录和CLI都是这样做的, 公共接口是BaseExecutor
什么情况需要编写
- 没有现有的Executor适合, 例如特定的计算工具和服务
- 想使用一个利用首选云提供商计算服务的Executor
- 有提供一个仅供你或者你的组织使用的专用工具
工作负载
在Executor中, 工作负载(workload)是Executor的执行单元, 代表了Executor再工作进程上运行的离散操作或作业, 例如它可以在工作进程上运行封装在Airflow任务的用户代码
markdown
ExecuteTask(
token="mock",
ti=TaskInstance(
id=UUID("4d828a62-a417-4936-a7a6-2b3fabacecab"),
task_id="mock",
dag_id="mock",
run_id="mock",
try_number=1,
map_index=-1,
pool_slots=1,
queue="default",
priority_weight=1,
executor_config=None,
parent_context_carrier=None,
context_carrier=None,
queued_dttm=None,
),
dag_rel_path=PurePosixPath("mock.py"),
bundle_info=BundleInfo(name="n/a", version="no matter"),
log_path="mock.log",
type="ExecuteTask",
)BaseExecutor方法
重要的方法
- heartbest: Airflow调度器Job循环会在定期Executor上调用heartbest. 这是airflow和Executor交互点,此方法会更新一些指标, 触发新排队的任务执行, 并更新正在运行/已完成任务状态
- queue_workload: 提供Executor运行的任务, 添加到Executor内部待运行的列表
- get_event_buffer: Airflow调度器会使用此方法来检索Executor正在执行的任务实例(TaskInstances)的当前状态
- has_task: 确定Executor是否已经将某个任务实例排队或者正在运行
- send_callback: 将任何回调发送到Executor配置的接收端(sink)
必须实现的方法
- sync: 这个方法会在
Executor的heartbest期间定期调用, 更新Executor知道的任务状态, 尝试执行从调度器接收到已排队的任务 - execute_async: 异步执行一个工作负载(workload), 在
heartbest被调用,heartbest是调度器定期执行的, 此方法通过只是将任务排入Executor的内部或外部任务队列中, 但是也可以直接执行, 看具体的Executor
可选实现的方法
- start: 调度器初始化
Executor后会调用此方法, 可以配置额外的内容 - end: 调度器关闭
Executor后会调用此方法 - terminate: 强制停止
Executor, 甚至kill正在运行的任务, 而不是同步完成, 时调用 - try_adopt_task_instances: 将以放弃的任务提供给
Executor来接管或者以其他方式处理 - get_cli_commands: 通过此方法实现向用户提供
CLI命令 - get_task_log: 通过此方法向Airflow任务日志提供日志消息
深度理解Scheduler
Airflow就是一个无限循环的Scheduler
Scheduler做的事情
- 开始任务的调度
- 检查任务之间的依赖
- 管理重试
- 确保任务仍然在运行
- 处理DST转换
- 保证可用性
- SLAs
- 触发成功/失败会掉
- 拷贝或者改变DAG结构体
- 加强并发限制
- 排放指标
- 支持触发规则(一个成功或者失败)包括自定义状态
- 可以选择不同的 start_data 进程
Scheduler的核心组件
- SchedulerJob: 管理任务状态和开始运行DAG
- Executor: 处理任务执行
- DagFileProcessor: 序列化DAG内部的文件到表
Scheduler状态管理
None -> Scheduled -> Queued -> Running -> Success\Failed\UpForRetry(->Scheduled)
None Scheduled Queued Running Success Failed UpForRetry
权限管理器
权限管理器是可插拔的, 可以根据安装需求更换权限管理器
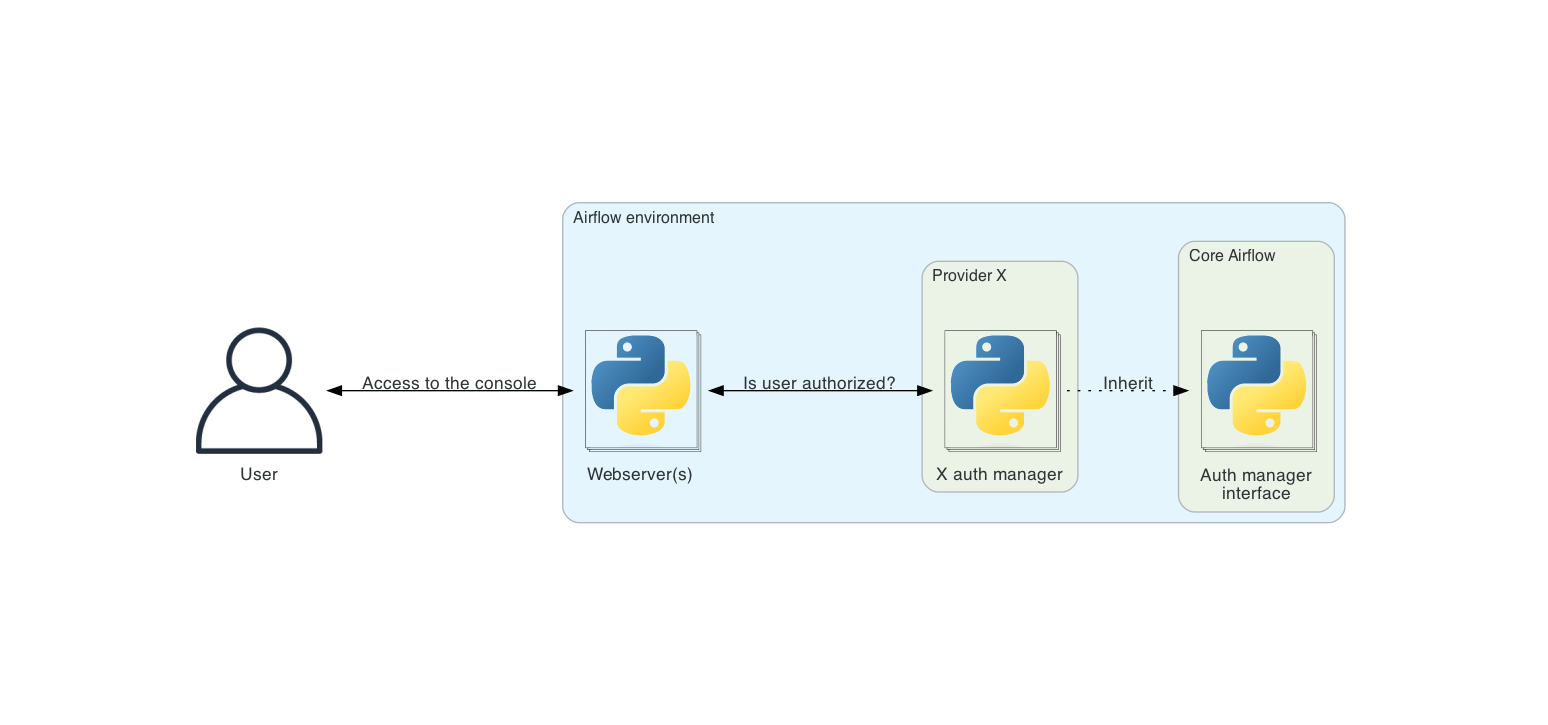
Airflow 一次只能配置一个权限管理器;这通过 配置文件 的 core 部分中的 auth_manager 选项来设置。
简单身份验证器
简单身份验证管理器仅用于开发和测试。如果您在生产环境中使用它,请确保通过其他方式控制访问。
管理用户
markdown
[core]
simple_auth_manager_users = "bob:admin,peter:viewer"用户列表用逗号分隔,每个用户是一个用户名/角色对,用冒号分隔。每个用户需要两部分信息:
- username: 用户的用户名
- role: 与用户关联的角色。有关这些角色的更多信息
管理角色和权限
简单身份验证管理器没有管理角色和权限的选项。它们作为简单身份验证管理器实现的一部分定义,无法修改。以下是简单身份验证管理器中定义的角色列表。这些角色可以与用户关联。
- viewe: 对 dags、assets 和 pools 具有只读权限
- user: 具有 viewer 权限以及对 dags 的所有权限(编辑、创建、删除)
- op: 具有 user 权限以及对 pools、assets、config、connections 和 variables 的所有权限
- admin: 所有权限
禁用身份验证并允许所有人作为管理员
markdown
[core]
simple_auth_manager_all_admins = "True"Scheduler原则
- 不要在长时间运行的程序中加载DAG代码
- 调度中只会读取序列化后的DAG而不会读取原始的DAG文件
Scheduler执行主要步骤
_do_scheduling(): 调度程序processor_agent.heartbeat(): 给处理器发送心跳heartbeat(): 给自己发送心跳, 不同的schedule相互通信timed_events.run(): 定期扫描超时, 定期操作
SchedulerJob._do_scheduling()
python
# 创建DAG任务从DAGs
self._create_dagruns_for_dags()
# 开始队列中的DAG任务
self._start_queued_dagruns()
# 获取所有运行中的dagruns, 并且调度
dag_runs = self._get_next_dagruns_to_examine(State.RUNNING)
for dag_run in dag_runs:
self._schedule_dag_run(dag_run)
num_queued_tis = self._critical_section_execute_task_instances()_create_dagruns_for_dags
判断DAG哪些一定要执行的(next_dagrun_create_after < NOW()
- 创建DAG运行从序列化仓库
- 更新下一次DagRun插入到DAG的表, 包含(next_dagrun, next_dagrun_create)
_start_queued_dagruns
获取DAG状态从(queued)
- 检查已经准备好运行的DagRuns, 不超过最大激活配置(dag.max_active_runs)
- 如果低于限制,则设置状态为运行
_get_next_dagruns_to_examine
拿回这些(n个)正在执行的DagRuns
_schedule_dag_run
- 检查DagRun没有超时
- DAG结构是否有没有改变
- 计算TaskInstances当前是否可以背调度, 如果可以就更新状态(DagRun.update_state)
- 将待决的回调传递给DagFileProcessorManager
_critical_section_execute_task_instants
检查concurrency的limits, 如果有足够的并发就开始执行
开始调度前任务的事情
一些必要的检查
- 池子有没有足够的空位
- DAG有没有超过最大的激活限制(max_active_tasks)
- (DAG, Task)concurrency的限制
- 执行器是否被激活
Executor
Executor就是任务真正被执行的地方
Executor interface
需要检查任务是否有做任务变更, 兼容Task的异常, 状态存储在kept的内存
DAG parsing
扫描指定的文件夹到数据库
DagFileProcessorManager
是一个单独存在的子进程, 在不停的循环, 主要做两件事情
- 解析DAG文件到dag的表
- 执行等待DAG的回调
DagFileProcessorManager._run_parsing_loop
_collect_results_from_processor start_new_processes Periodically: send heartbeat Periodically: _refresh_dag_dir Parsing process 'parse' dag file write DAGs to DB tables
High Availability(高可用)
不同于leader或者master模式, airflow使用metadataDB实现, 多个调度器配合
加入行锁
python
SQL1: SELECT * FROM task_instance LIMIT 2 FOR UPDATE SKIP LOCKED;
SQL2: SELECT * FROM task_instance LIMIT 2 FOR UPDATE SKIP LOCKED;
TaskInstance1: SQL1, SQL2(SKIP)
TaskInstance2: SQL1, SQL2(SKIP)
TaskInstance3: SQL2
TaskInstance4: SQL2FOR UPDATE SKIP LOCKED
加入行锁, 读取并且更新状态, 并且跳过锁, 不等待其他的锁保证效率
SchedulerJob._do_scheduling()
python
with prohibit_commit(session) as guard:
self._create_dagruns_for_dags(guard)
self._start_queued_dagruns(session)
guard.commit()
dag_runs = self.get_next_dagruns_to_examine(State.RUNNING, session)
for dag_run in dag_runs:
self._schedule_dag_run(dag_run)
guard.commit()
num_queued_tis = self._critical_section_execute_task_instances() _critical_section_execute_task_instances
Airflow中很多的任务都是需要排他性的, 需要保证执行的原子性, 比如下面的POOL会吧POOL全部都锁住, NOWAIT代表不等待, 里面去做其他的事情
sql
SELECT * FROM pool FOR UPDATE NOWAIT;Adopting tasks(认养/领养任务)
Active-active model, 双核心模式
当其中一个不管什么原因失败了, 另外一个就会快速顶上, 并且吧挂掉的调度器认领到自己下面