BOSS直聘Nanbeige大语言模型实验室,开源了它们的Nanbeige4-3B模型。
一款仅有30亿参数的小模型,在数学和推理能力上超越了320亿参数的大模型。
BOSS直聘Nanbeige大语言模型实验室,开源了它们的Nanbeige4-3B模型。

23万亿Token重塑小模型潜能
对于一个3B级别的模型,通常的训练量可能在几万亿token,但Nanbeige4-3B直接将这一数字拉升到了23T(23万亿),为了通过重复和强化,将知识压实在有限的参数空间里。
数据的筛选是这一切的基石,单纯的数据堆砌只会带来噪声,为了从海量数据中提炼出这23T的高质量语料,团队设计了一套混合数据过滤机制,这套机制包含两个核心维度:基于标签的评分和基于检索的召回。
多维标签系统不再满足于简单的格式分类,而是深入到内容层面。
团队定义了超过60个维度,最终精选出20个关键维度进行人工标注,包括知识密度、推理密度和文本流畅度等。
实验发现,内容相关的标签比格式标签更能预测数据质量,且0到9的精细打分比简单的0/1二分类要准确得多,配合数千亿条目的检索数据库,团队得以在保证数据来源权威性的同时,剔除了数十万亿的低质token,最终保留下的23T数据,构成了模型强大的知识底座。
为了让模型更好地消化这些数据,训练调度器也进行了革新。
传统的WSD(预热-稳定-衰减)调度器虽然有效,但在数据利用上仍显粗糙,Nanbeige4-3B引入了FG-WSD(细粒度预热-稳定-衰减)调度器,其核心在于渐进式优化。
在漫长的稳定训练阶段,数据配比并非一成不变,而是被切分为多个更细的阶段,随着训练的进行,高质量数据的比例逐步提升,这种策略确保了模型在这一阶段能够持续获得新的高质量信息刺激,而不是在低质数据的重复中停滞不前。
实验数据佐证了这一策略的有效性,在1B参数模型的对比测试中,使用FG-WSD的模型在GSM8k(数学推理)上的得分从27.1提升到了34.3,在MMLU(多任务语言理解)上从49.2提升到了50.6,这种提升并非来自参数的增加,纯粹源于数据喂养节奏的优化。

这种调度器还将最后的衰减阶段加以利用,采用ABF(调整基频)方法将上下文长度扩展到了64K,这让模型在预训练结束前,能够完整消化长思维链、学术论文和大规模代码库,确保长文本处理能力不出现截断损失。
千万级指令微调构建推理基座
进入后训练阶段,Nanbeige4-3B打破了另一个行业迷思,即高质量微调数据只需少量即可。
虽然对于简单的指令遵循任务,少量数据或许足够,但对于旨在突破推理极限的模型而言,数据的广度和深度依然缺一不可。
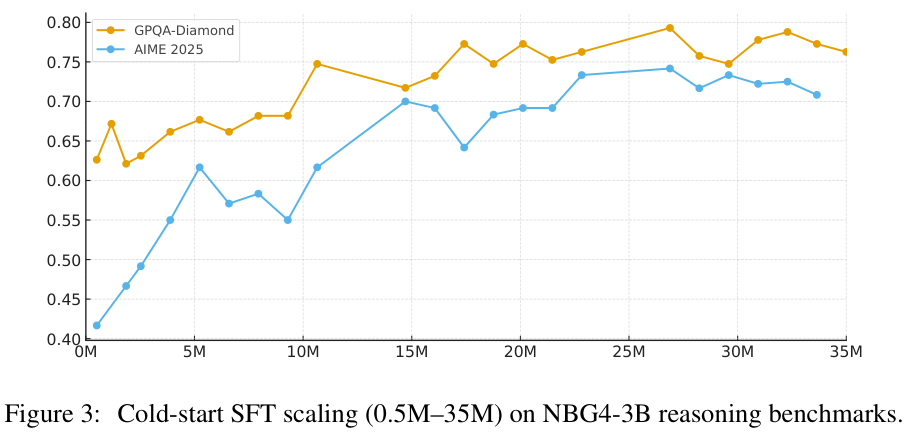
在冷启动SFT(监督微调)阶段,团队并未通过几千条数据浅尝辄止,而是清洗并构建了约3000万条高质量问答样本。
这3000万样本涵盖了数学、代码和学科推理,其中数学推理占比50%,科学推理占30%,代码占20%。
为了让模型学会思考,所有训练数据的上下文长度都被拉到了32K,这种大规模的冷启动训练,实际上是为模型注入了强大的推理先验,使其思维链(CoT)的生成策略更加稳定。
有了扎实的冷启动基础,全面SFT阶段进一步引入了更加复杂的任务,包括通用对话、Agent(智能体)交互、高难推理和代码任务。
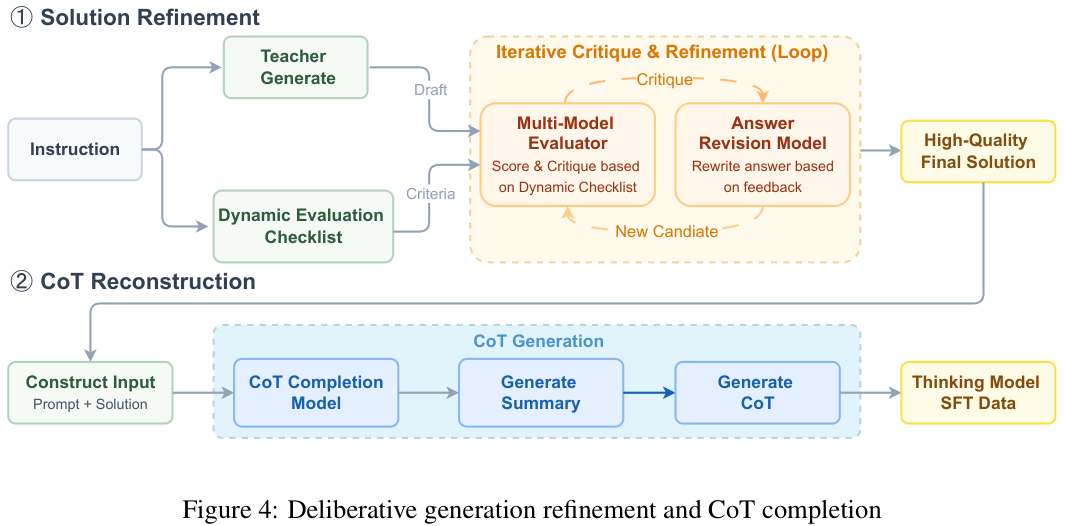
在这个阶段,团队设计了一套解决方案精炼与CoT重构的联合机制,专门解决复杂任务中答案质量与推理过程不匹配的问题。
针对每一个指令,系统首先构建一个多维评估清单,根据具体问题动态生成的检查点,涵盖正确性、完整性、可执行性等。
随后,系统会调用多个教师模型生成候选答案,并利用评估模型进行交叉打分和批判,选出最佳答案,或者基于反馈让模型进行多轮自我修正,直到得到一个高质量的最终解。
这还不够,团队训练了一个专门的思维链补全模型,它接收原始问题和最终的高质量答案作为输入,反向推导出一条逻辑严密、条理清晰的思维链。
这种先有果后有因的重构方式,确保了SFT数据既有正确的终点,又有清晰的路径,极大地提升了训练效率。
这种精细的数据工程让Nanbeige4-3B在SFT阶段就积累了深厚的内功,不仅保留了冷启动阶段的强推理能力,还在通用对话和任务执行上变得更加圆融。
双重蒸馏与多阶段强化学习
微调之后,模型的能力已经成型,但为了进一步逼近大模型的表现,蒸馏(Distillation)和强化学习(RL)成为了关键的助推器。
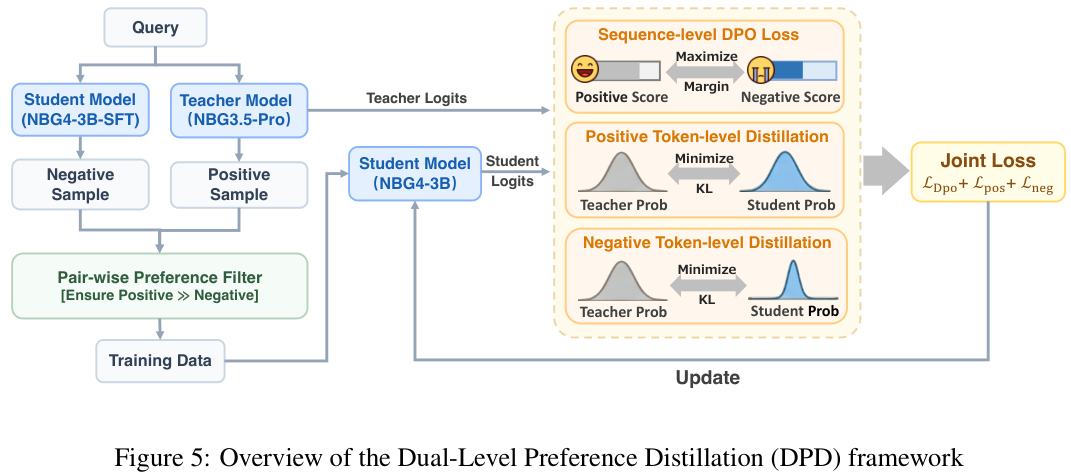
Nanbeige4-3B采用了一种DPD(双重偏好蒸馏)的新方法,它不仅仅是让小模型模仿大模型的输出概率,而是引入了偏好优化的思想。
在DPD框架中,教师模型Nanbeige3.5-Pro会生成多个回复,经过筛选得到正样本,而正在训练的学生模型则生成负样本。
训练目标包含两部分:在正样本上,学生模型要尽可能拟合教师模型的概率分布,学习怎么说是对的;在负样本上,学生模型同样参考教师的分布,目的是降低那些模型盲目自信的错误token的概率,学习怎么说是不对的以及如何纠正错误。
同时,配合序列级别的DPO(直接偏好优化)损失函数,拉大正负样本之间的得分差距,这种双管齐下的策略,让小模型在逻辑推理和人类偏好对齐上同时取得了进步。
强化学习阶段则被划分为三个明确的阶段,分别针对STEM(科学、技术、工程、数学)、代码和人类偏好,避免了混合训练导致的领域能力互斥。
在STEM阶段,为了解决数学答案形式多样(如分数、小数、表达式)导致的评估难题,团队引入了工具增强的验证器,调用Python解释器进行精确计算,不再依赖脆弱的字符串匹配。
代码强化学习阶段则更加硬核,采用了合成测试函数的策略。
系统逆向操作,先生成代码解决方案和测试用例,再生成对应的自然语言问题描述,所有数据都经过沙盒执行验证,确保在RL训练时,奖励信号是绝对客观真实的------代码跑通就是1,跑不通就是0。
最后的人类偏好对齐阶段,为了避免一般奖励模型存在的耗时和被Hack(攻击)风险,团队训练了一个成对奖励模型,它不需要生成长篇大论的评价,只需对两个回复的优劣做出快速判断。
这种高效的信号反馈机制,让模型在创意写作和角色扮演等开放任务上的表现更加符合人类直觉。这让它在写作综合基准WritingBench上脱颖而出,与众多闭源、开源大模型比较排到了第11位。
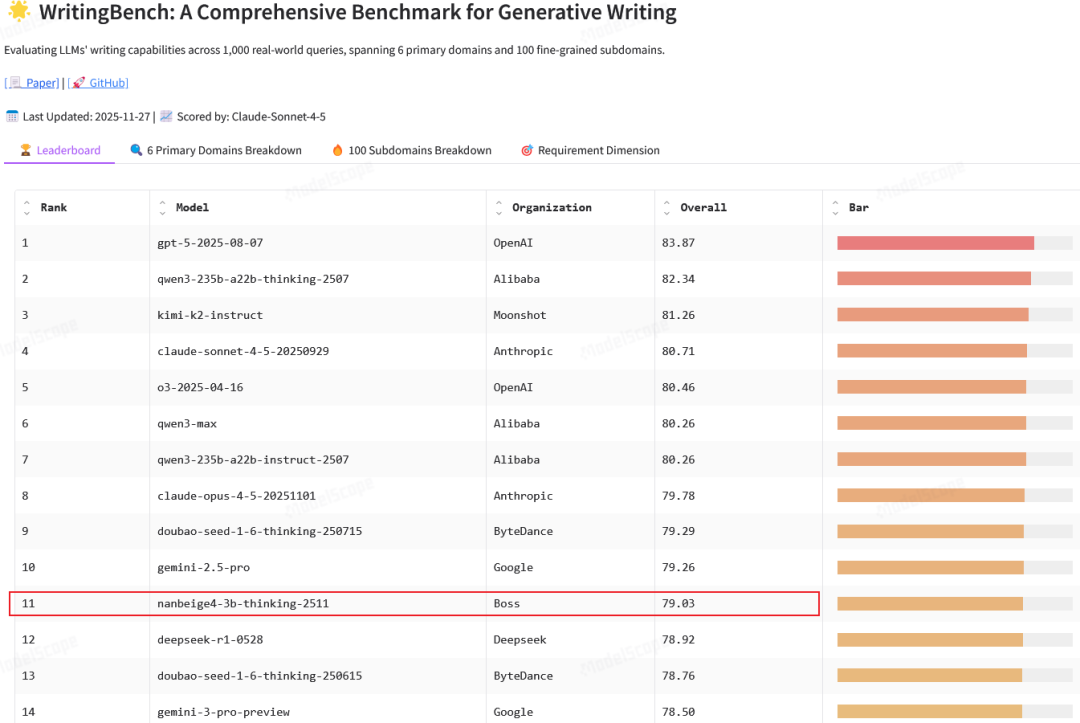
在每个RL阶段开始前,团队都会进行On-Policy(策略内)的数据过滤,使用当前模型对所有训练问题进行测试,只保留通过率在10%到90%之间的样本,剔除那些对当前模型来说太简单或太难的问题,确保每一次训练更新都用在刀刃上。
性能越级挑战与小模型新范式
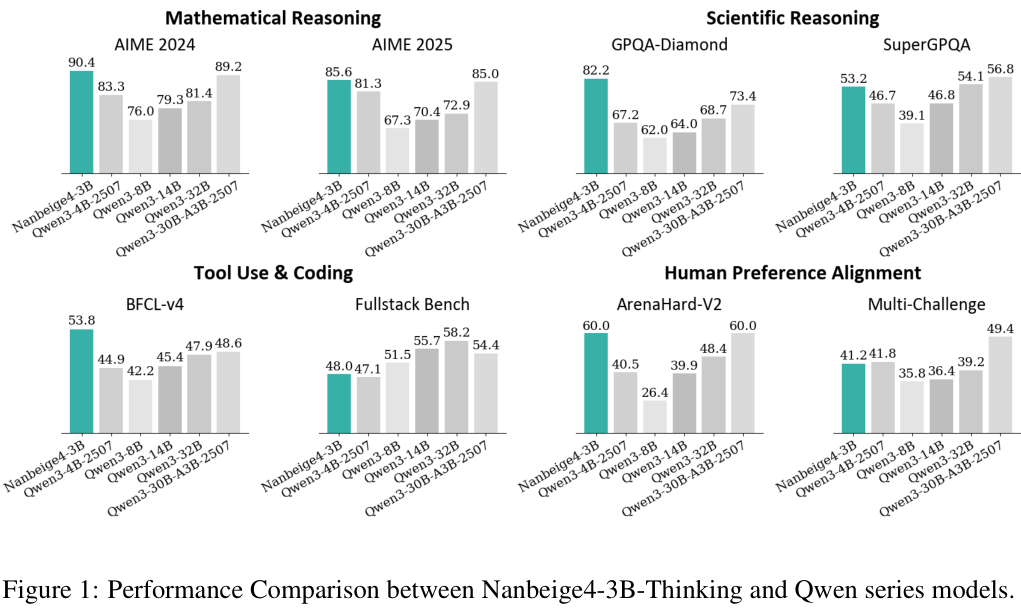
经过这一系列复杂而精密的训练流程,Nanbeige4-3B交出的答卷令人印象深刻,在与Qwen(通义千问)系列模型的对比中,它展现出了惊人的越级打击能力。
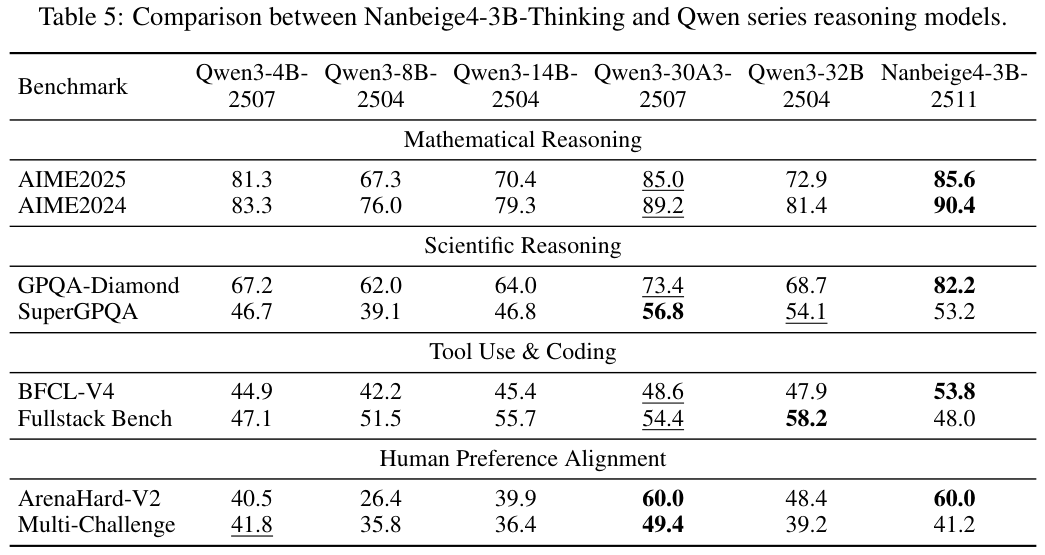
在数学推理领域,AIME 2024基准测试中,Nanbeige4-3B取得了90.4的高分,不仅远超同级别的Qwen3-4B(81.3)和8B(76.0),甚至击败了参数量十倍于己的Qwen3-32B(81.4)和Qwen3-30B-A3B(89.2)。
在AIME 2025上,它同样以85.6的成绩傲视群雄,超越了32B模型的72.9分。
科学推理方面,GPQA-Diamond测试集上,Nanbeige4-3B拿下了82.2分,远超Qwen3-32B的68.7分,也优于Qwen3-30B-A3B的73.4分,这一成绩证明了其在处理专家级科学问题时的可靠性。
在代码和工具使用上,Nanbeige4-3B同样表现不俗,在BFCL-V4(伯克利函数调用排行榜)中,它获得了53.8分,比Qwen3-30B-A3B高出5.2分,这得益于其对Function Call(函数调用)的原生支持和专门的Agent数据训练。
即使在主观的人类偏好对齐上,Nanbeige4-3B也没有偏科,在Arena-Hard V2榜单上,它取得了60.0的分数,与Qwen3-30A3-2507持平,远高于Qwen3-32B的48.4分,这表明它不仅是一个做题家,也是一个能够流畅对话、理解人类意图的好助手。
Nanbeige4-3B重新定义了3B这个参数量级的意义。
它证明了在有限的计算预算和存储空间下,通过极致的数据工程、精细的训练调度和先进的算法设计,完全可以获得媲美甚至超越大模型的智能体验。
对于那些受限于显存、追求端侧部署或希望降低推理成本的开发者而言,是非常好的选择。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量