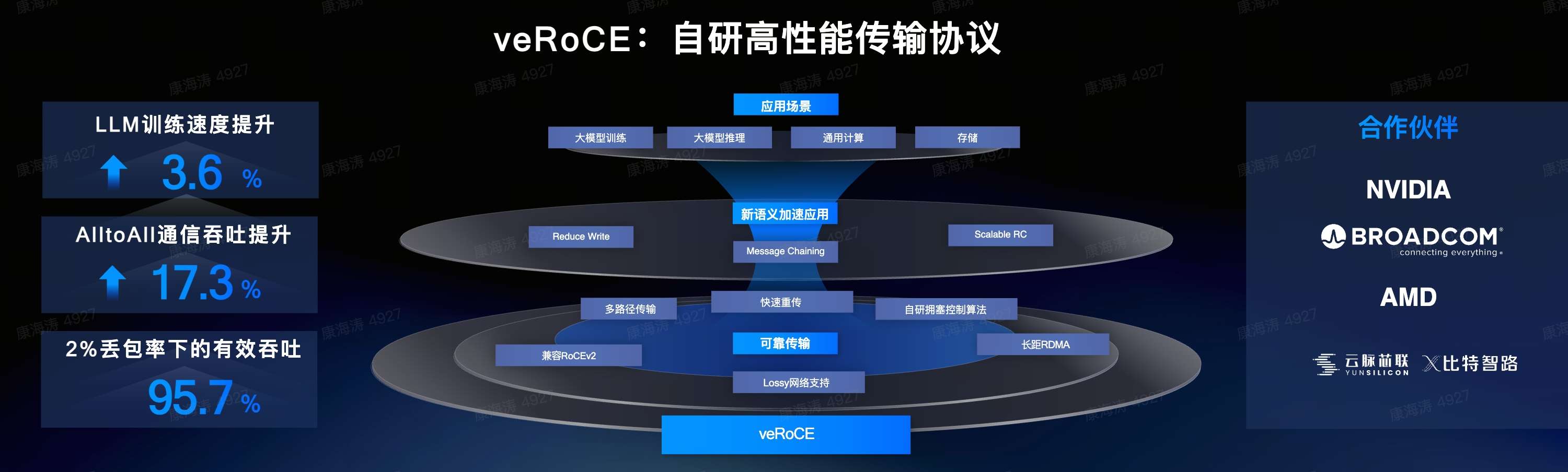
在12月18日的火山Force大会上,字节跳动正式发布veRoCE------字节跳动自研的高性能RDMA传输协议!
随着大语言模型(LLM, Large Language Model)的规模指数级扩张,构建万卡甚至更大规模的GPU集群已成为支撑大模型训练的刚需。这类大规模集群的节点间通信高度依赖RDMA网络,但传统RoCEv2在组网规模、带宽、时延上已经无法满足需求。同时,在云网络的发展下,通用计算、存储等业务也对RDMA组网提出了更高的要求。主流的RoCEv2高速网络存在两大关键局限------依赖PFC无损网络,而大规模组网中PFC极易引发网络稳定性问题,制约集群规模扩展;且不支持多路径传输,易导致ECMP冲突进而造成带宽浪费。
在此背景下,字节跳动推出自研高性能传输协议veRoCE,从源头解决RoCEv2的遗留问题,为大规模GPU集群通信提供更优解。
veRoCE针对RoCEv2的关键不足进行了创新:
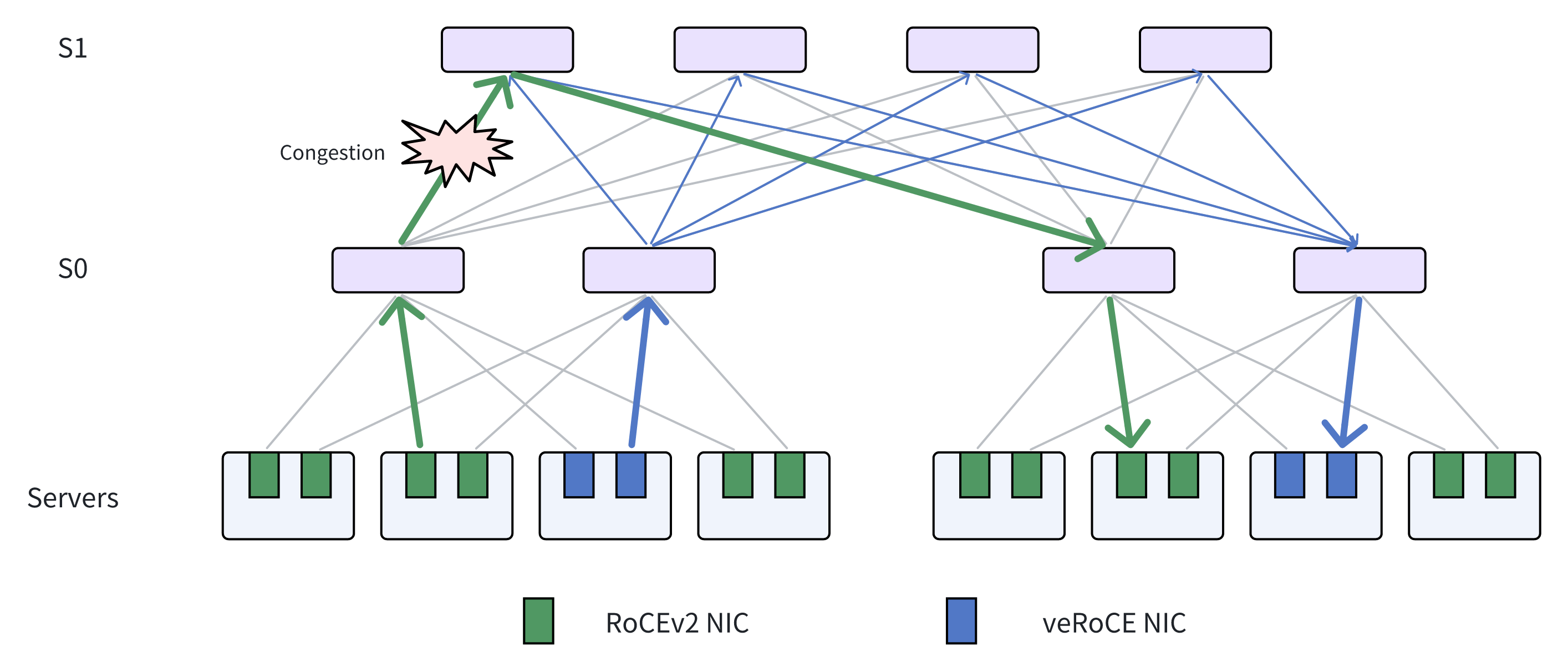
- 多路径与乱序优化:原生支持多路径传输(修改源端熵值、交换机报文喷洒两种模式);针对多路径导致的报文乱序,通过DDP (Direct Data Placement) 让数据无需等待保序即可直接交付应用,大幅减少网卡缓存开销。在veRoCE中,报文乱序接收和DDP对所有语义(RDMA Write, RDMA Read, Send/Recv, Atomics等)提供原生支持。
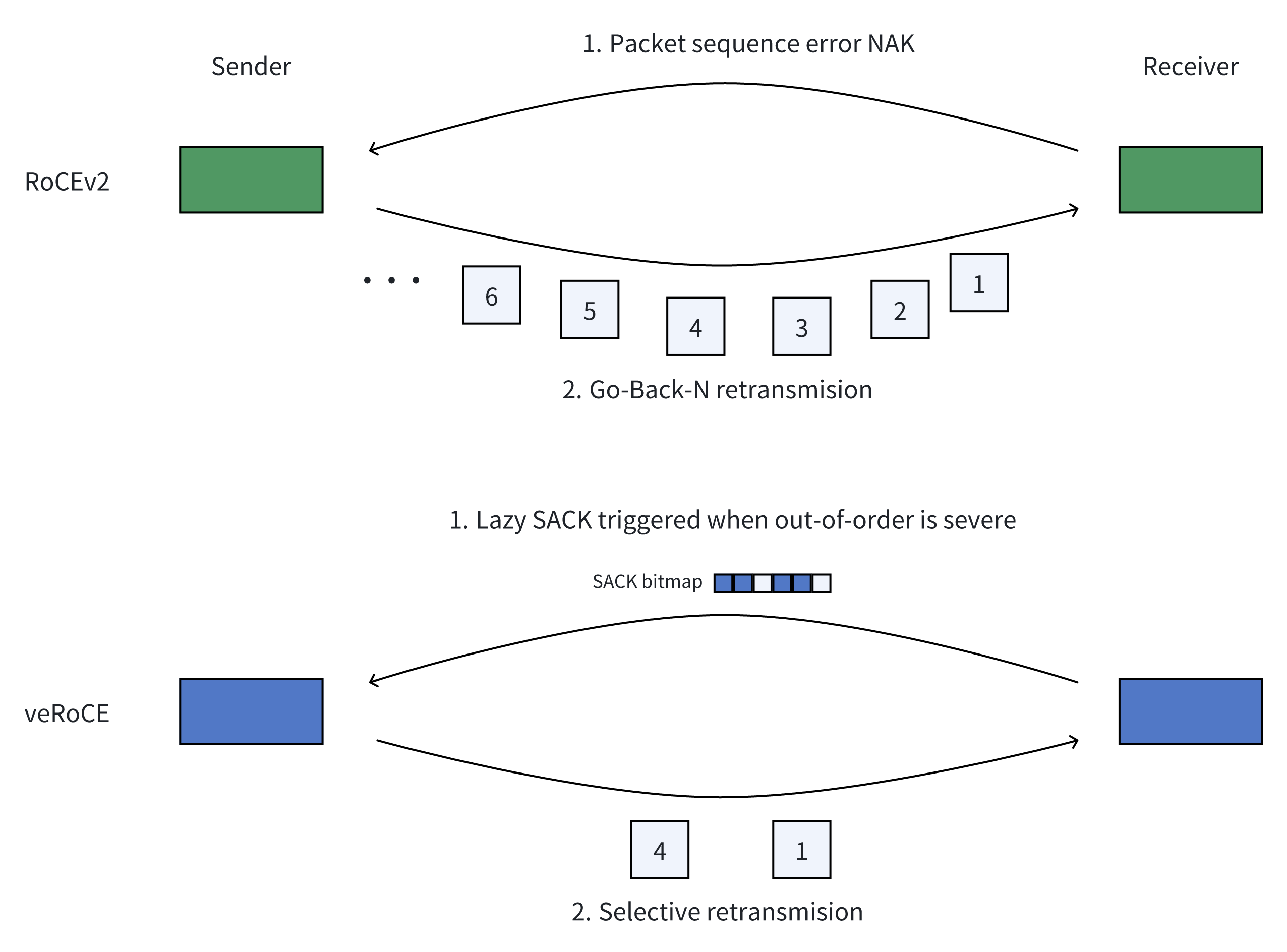
- 高效重传机制:采用基于选择性确认(SACK)的选择性重传策略,通过接收端位图精确确定丢包位置,支持单个报文的多次选择性重传;引入延迟选择性确认(lazy SACK)机制,根据报文乱序程度智能区分乱序报文和丢包报文,确保SACK在多路径场景下高效运行。
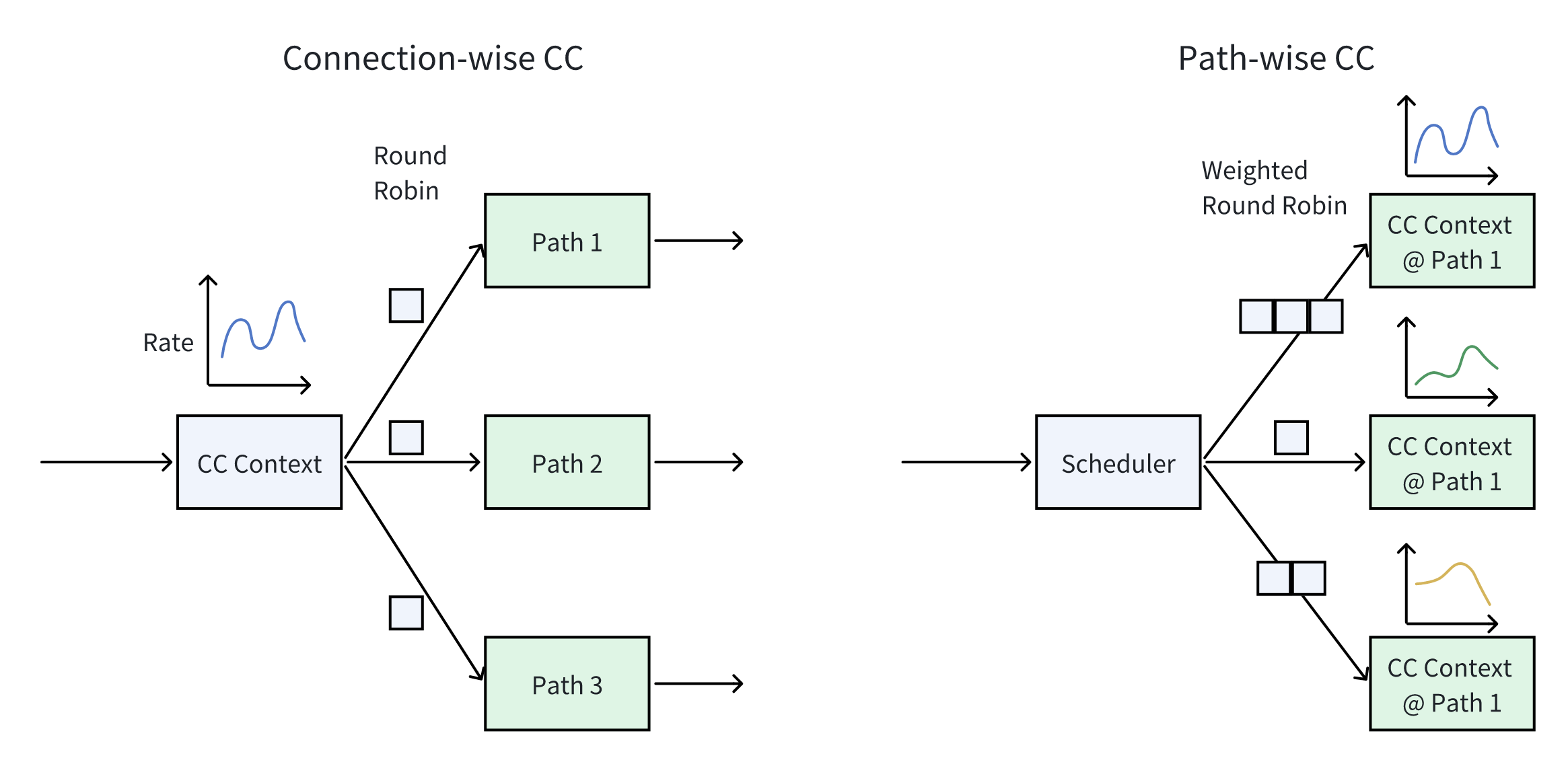
- 多路径拥塞控制:支持路径粒度和连接粒度两种拥塞控制模式,将拥塞信号与可靠传输完全解耦,避免数据传输干扰拥塞感知的准确性。针对路径拥塞不均衡问题,veRoCE提出了基于报文序列号的快速慢路径检测算法,以最小的开销快速定位并剔除慢路径。
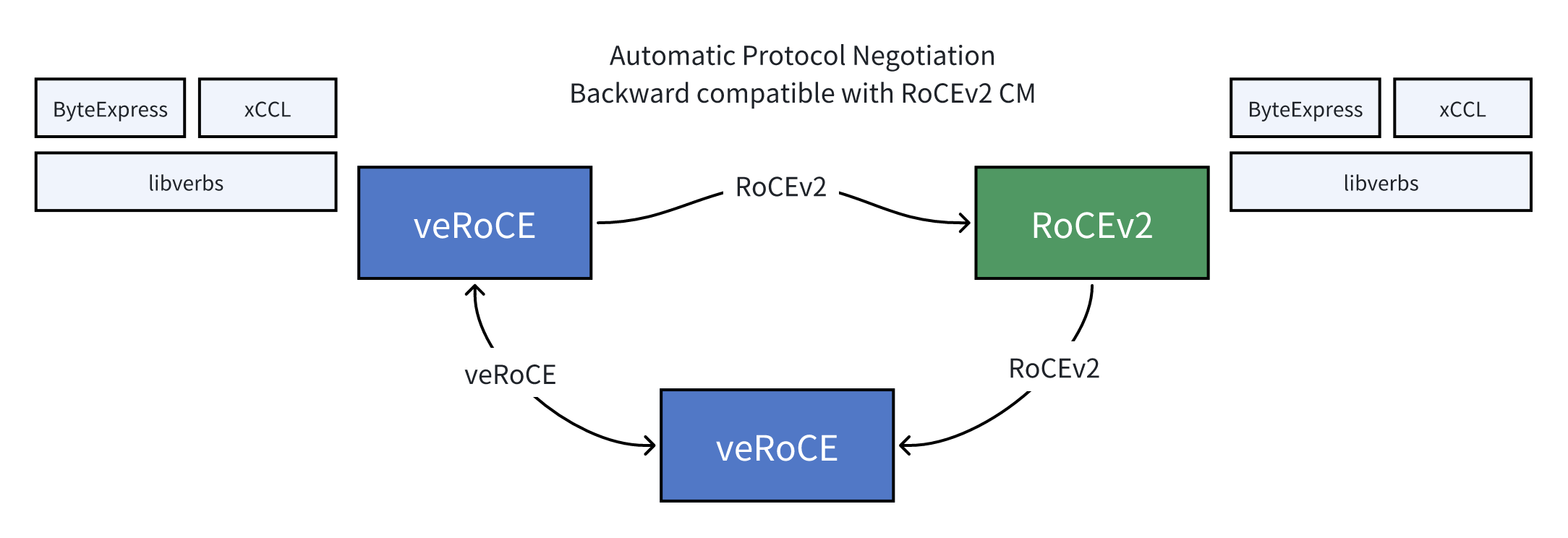
veRoCE注重兼容性和易用性,支持通用的verbs接口,消息语义与保序模型和RoCEv2一致,业务可以无缝切换。veRoCE的连接管理支持协议协商,与RoCEv2网卡互通时可自动回退到RoCEv2模式。该协议在与核心新功能无关的部分与RoCEv2保持完全一致,大大降低了迁移和部署的门槛。
在典型测试场景中,veRoCE为大模型训练带来显著收益:LLM训练速度相较于RoCEv2提升约11.2%;AlltoAll通信吞吐提升约48.4%;在2%丢包率下,veRoCE的有效吞吐仍能达到网卡带宽的约95.7%左右,而RoCEv2在这一场景下因为丢包过多而通信中断。 字节正在与Nvidia、AMD、Broadcom、云脉芯联、比特智路等厂商就veRoCE进行合作。veRoCE已在部分网卡上完成验证与小规模试用,更多400G、800G以及1.6T网卡正在逐步支持veRoCE。我们欢迎更多设备厂商与云厂商的参与,共同完善以太网高性能传输生态。
【下载链接】 https://developer.volcengine.com/resource/7584346532149723178