
Python 学习:文件的规范拆分和写法(零基础友好版)
先把今天的 4 个核心知识点拆成小步骤 ,用大白话 + 具体例子 + 代码 讲解,保证零基础也能看懂。先明确一个核心:今天的内容是为了让你学会找官方资料、看懂类的使用、理解绘图的底层逻辑,这些都是写规范 Python 代码的基础。
知识点 1:官方文档的检索方式(GitHub + 官网)
首先要明白:官方文档是最权威的学习资料 ,比网上随便找的教程靠谱 10 倍,因为它是开发这个库 / 语言的人写的。我们需要学两种检索方式:Python 本身的官网文档 和第三方库的 GitHub 文档。
1.1 先搞懂两个概念
- Python 官网 :管 Python 语言本身(比如
print、open、list这些内置功能)和官方标准库(比如os、sys、json)的文档。 - GitHub :管大部分第三方库(比如绘图的
matplotlib、数据分析的pandas)的源码和文档(因为这些库是开源的,存在 GitHub 上)。
1.2 方式 1:Python 官网文档的检索(步骤 + 例子)
步骤 1:进入 Python 官网文档入口
- 官网地址:https://www.python.org/
- 找到顶部导航栏的Documentation (文档),点击进入(比如选 "Python 3.x Documentation")。 小贴士:零基础选最新的稳定版(比如 3.11),不要选老版本(比如 2.7,已经淘汰了)。
步骤 2:检索你想查的内容
官网文档有两种检索方式:
- 方式 A:用搜索框(最直接) 比如你想查 "文件操作的
open函数怎么用",直接在文档页面的搜索框输入open,回车就能找到对应的说明。 - 方式 B:按模块分类找 比如想查
os模块(处理文件路径),可以在文档的 "Library Reference"(库参考)里找到os模块的入口。
例子:查open函数的官方文档
- 打开 Python 官网文档:https://docs.python.org/3/
- 在页面顶部的搜索框输入
open,点击搜索图标。 - 找到 "Built-in Functions: open (file, mode='r', buffering=-1, encoding=None, ...)" 这个条目,点进去就是
open函数的详细说明(参数、用法、示例)。
1.3 方式 2:GitHub 文档的检索(步骤 + 例子)
步骤 1:明白 GitHub 是什么
简单说:GitHub 是程序员的代码仓库 ,大部分 Python 第三方库(比如matplotlib)的源码、使用文档、示例代码都存在这里。
步骤 2:找第三方库的 GitHub 仓库
有两种方法:
- 方法 A:直接在 GitHub 搜索库名 GitHub 官网:https://github.com/在搜索框输入库名(比如
matplotlib),回车后第一个结果通常就是官方仓库(看头像 / 名称是否是官方,比如matplotlib/matplotlib)。 - 方法 B:从库的官网找 GitHub 链接 比如
matplotlib的官网:https://matplotlib.org/,页面底部 / 顶部会有 "GitHub" 的链接,直接点进去就行。
步骤 3:在 GitHub 仓库里找文档
每个 GitHub 仓库里有几个关键文件 / 文件夹,是学习的重点:
| 名称 | 作用 |
|---|---|
README.md |
项目的入门说明书(必看!包含安装方法、基本用法、核心功能) |
docs文件夹 |
详细的官方文档(比 README 更全面) |
examples文件夹 |
示例代码(直接跑就能看效果) |
例子:找matplotlib的 GitHub 文档
- 打开 GitHub,搜索
matplotlib,进入matplotlib/matplotlib仓库。 - 先看
README.md:里面会告诉你怎么安装matplotlib,还有最简单的绘图例子。 - 想找详细文档?点
docs文件夹,或者看 README 里的 "Documentation" 链接(会跳转到专门的文档网站)。
知识点 2:官方文档的阅读和使用 ------ 安装的包和文档为同一个版本
这是新手最容易踩的坑 !比如你装了matplotlib 3.7,但看的是matplotlib 3.9的文档,里面的某个函数在 3.7 里没有,运行代码就会报错。
核心逻辑:版本一致 = 避免报错
我们分 3 步走,保证包和文档版本一致:
步骤 1:查看本地已安装包的版本
有两种方法(推荐用代码,更直观):
方法 A:用pip命令(在电脑的命令行 / 终端里输)
方法 B:在 Python 代码里查看(更推荐,不用记命令)
python
# 导入要查的库
import matplotlib
import pandas
# 打印版本号(__version__是库的内置属性,大部分库都有)
print("matplotlib版本:", matplotlib.__version__)
print("pandas版本:", pandas.__version__)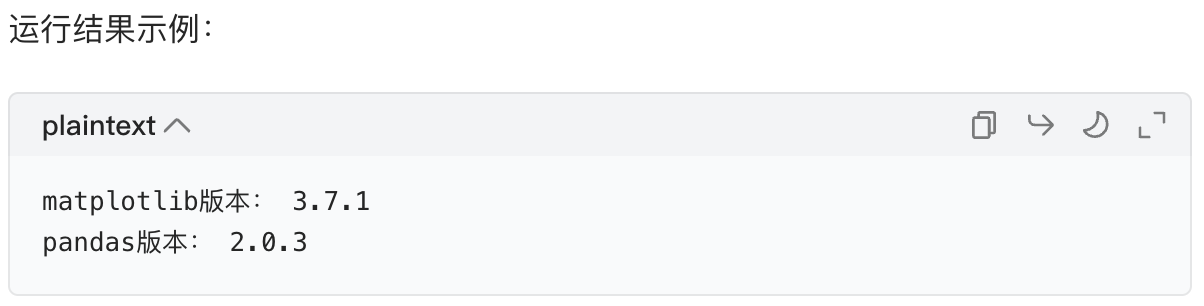
步骤 2:找到对应版本的官方文档
情况 1:Python 官网文档
在 Python 文档页面的顶部,有版本选择下拉框(比如 "3.11"),选你本地的 Python 版本即可(比如你装的是 Python 3.10,就选 3.10)。
情况 2:第三方库文档
- 方法 A:库的文档官网选版本 比如
matplotlib的文档官网:https://matplotlib.org/,页面顶部有版本选择(比如 3.7.1)。 - **方法 B:GitHub 仓库选版本(tag)**在 GitHub 仓库的页面,找到 "Releases" 或 "Tags"(通常在页面右侧),点击后选你本地的版本号,就能看到对应版本的文档和代码。
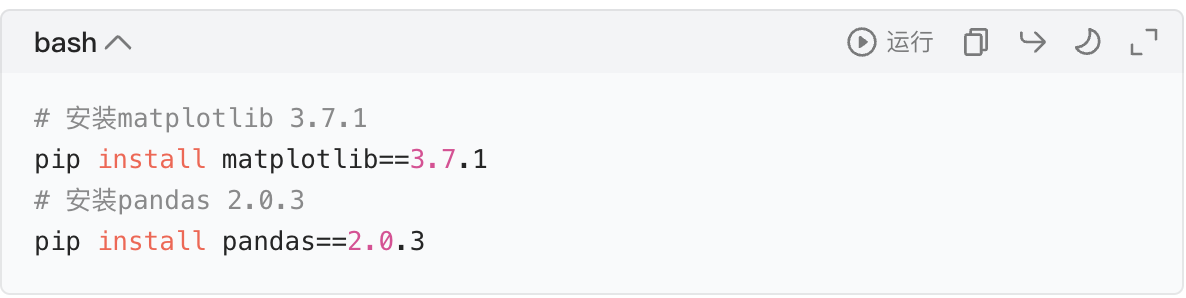
步骤 3:安装指定版本的包(如果版本不一致)
如果你的本地包版本和文档版本不一样,用pip install 包名==版本号安装指定版本:
小贴士:如果安装失败,先输
pip uninstall 包名卸载旧版本,再装新版本。
知识点 3:类的关注点 ------ 实例化参数、方法参数、方法返回值
首先用大白话解释类 :类是一个模板 ,比如 "狗" 这个类,定义了狗有 "名字、颜色" 这些属性,还有 "叫、跑" 这些行为;实例是根据模板创建的具体对象,比如 "大黄" 这个具体的狗。
我们重点关注类的 3 个核心点,用一个完整的例子讲明白。
3.1 关注点 1:实例化所需要的参数
实例化 :用类创建具体对象的过程(比如dog1 = Dog("大黄", "黄色"))。这些参数是在类的__init__方法里定义的(__init__是类的初始化方法,用来给对象设置属性)。
关键知识点:
__init__方法的第一个参数必须是self(代表实例本身,不用传参,Python 会自动传)。- 后面的参数是实例化时需要传的参数(可以设默认值,变成可选参数)。
3.2 关注点 2:普通方法所需要的参数
普通方法:类里定义的函数,用来实现对象的行为(比如狗叫)。
关键知识点:
- 普通方法的第一个参数必须是
self(代表实例本身)。 - 后面的参数是调用方法时需要传的参数。
3.3 关注点 3:普通方法的返回值
返回值 :方法执行后返回的结果(用return语句实现),可以是数字、字符串、列表等。
3.4 完整例子(代码 + 解释)
python
# 定义一个"狗"类(模板)
class Dog:
# __init__方法:初始化对象的属性,这里是实例化的参数
# 参数说明:self(必选,代表实例)、name(必选,狗的名字)、color(可选,默认白色)
def __init__(self, name, color="白色"):
# 给实例设置属性(self.属性名 = 参数)
self.name = name # 名字属性
self.color = color # 颜色属性
# 普通方法1:狗叫(有参数)
# 参数:self、sound(叫的声音,必选)
def bark(self, sound):
# 打印狗叫的声音
print(f"{self.name}发出了{sound}的声音!")
# 普通方法2:获取狗的信息(有返回值)
# 参数:只有self(不需要传其他参数)
def get_info(self):
# 返回值:字符串(包含名字和颜色)
return f"狗的名字是{self.name},颜色是{self.color}"
# ---------------------- 实例化和调用方法 ----------------------
# 实例化1:传2个参数(name="大黄",color="黄色")
dog1 = Dog("大黄", "黄色")
# 实例化2:只传name参数(color用默认值"白色")
dog2 = Dog("小白")
# 调用普通方法1:bark(需要传sound参数)
dog1.bark("汪汪汪") # 输出:大黄发出了汪汪汪的声音!
dog2.bark("嗷嗷嗷") # 输出:小白发出了嗷嗷嗷的声音!
# 调用普通方法2:get_info(不需要传参,获取返回值)
info1 = dog1.get_info()
info2 = dog2.get_info()
print(info1) # 输出:狗的名字是大黄,颜色是黄色
print(info2) # 输出:狗的名字是小白,颜色是白色逐行解释重点:
class Dog::定义一个名为 Dog 的类。def __init__(self, name, color="白色"):self:代表创建的实例本身(比如 dog1、dog2)。name:实例化时必须传的参数(比如 "大黄")。color="白色":默认参数,实例化时可以不传(比如 dog2)。
self.name = name:把传入的 name 参数赋值给实例的 name 属性(这样 dog1 就有了 name 属性,值是 "大黄")。def bark(self, sound):普通方法,第一个参数是 self,第二个是 sound(调用时要传,比如 "汪汪汪")。def get_info(self):普通方法,没有其他参数,用return返回了一个字符串。
知识点 4:绘图的理解 ------ 对底层库的调用
4.1 先搞懂核心逻辑(大白话)
Python 里的绘图库(比如matplotlib)就像手机的拍照功能:
- 你拍照时,只需要点快门,不用懂相机的光学原理、传感器技术(这是底层的东西)。
- 绘图库就是把复杂的底层绘图逻辑 封装成了简单的函数(比如
plt.plot()),你只用调用这些函数,就能画出图来。
底层库 :比如matplotlib的底层会调用 C 语言的绘图库(如Agg)、Python 的numpy(处理数值计算),这些都是你不用关心的,绘图库已经帮你处理好了。
4.2 绘图的基本流程(5 步走)
以最常用的matplotlib为例,绘图的核心步骤是:
- 导入绘图库(调用库的入口)。
- 准备数据(x 轴、y 轴的数值)。
- 调用绘图方法(画折线、柱状图等)。
- 设置图形属性(标题、坐标轴标签等)。
- 显示 / 保存图形(最终输出)。
4.3 完整例子(画一个简单的折线图)
python
# 步骤1:导入绘图库(plt是约定俗成的别名,方便调用)
import matplotlib.pyplot as plt
import numpy as np # 底层数值计算库,matplotlib会调用它
# 步骤2:准备数据(x轴是0到4的整数,y轴是x的平方)
x = np.array([0, 1, 2, 3, 4]) # x轴数据
y = x ** 2 # y轴数据(0²=0,1²=1,2²=4,3²=9,4²=16)
# 步骤3:调用绘图方法(plt.plot()是画折线的方法,底层调用了numpy和Agg库)
plt.plot(x, y, color="red", linewidth=2) # 画折线,设置颜色和线宽
# 步骤4:设置图形属性(标题、坐标轴标签)
plt.title("简单的折线图(x的平方)") # 标题
plt.xlabel("x轴") # x轴标签
plt.ylabel("y轴(x²)") # y轴标签
# 步骤5:显示图形(plt.show()会调用底层的显示库,比如TkAgg)
plt.show()解释底层调用逻辑:
- 当你写
plt.plot(x, y)时,matplotlib会先调用numpy处理 x 和 y 的数值(比如把列表转成高效的数组)。 - 然后调用底层的渲染库(比如
Agg)把折线画在内存里。 - 最后
plt.show()调用电脑的图形界面库(比如 Windows 的 GDI、Linux 的 X11)把图形显示在屏幕上。
4.4 扩展:上层库对底层库的调用
比如seaborn(更美观的绘图库)是基于 matplotlib 封装的 ,它的底层还是调用matplotlib的方法:
python
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn的绘图方法,底层调用了matplotlib的plt.plot()
sns.lineplot(x=[0,1,2,3], y=[0,1,4,9])
plt.show()简单说:上层库调用底层库,底层库处理具体的绘图逻辑,你只用调用上层库的简单函数就行。
总结(零基础友好版)
- 官方文档:Python 官网查内置功能,GitHub 查第三方库,一定要看对应版本。
- 类的使用:重点看实例化参数(__init__里的)、方法参数(第一个是 self)、方法返回值(return)。
- 绘图:绘图库封装了底层逻辑,你只用按 "导入库→准备数据→画图→设置属性→显示" 的步骤来就行。
如何选择适合的数据集和模型?(零基础友好版)
作为零基础学习者,选择数据集和模型的核心原则是:匹配任务目标 + 适配工具特性(比如 PDPbox) + 新手友好。简单说就是 "挑简单的、能直接用的、和你要做的事匹配的"。
我会把这个问题拆成 **「数据集选择」和「模型选择」** 两部分,结合你之前用 PDPbox 绘图的场景,给出具体的选择方法、原则和例子,保证你一看就懂、一用就会。
一、先选数据集:新手优先 "躺平式选择"(不用自己造数据、洗数据)
数据集是分析的基础,新手最容易踩的坑是选了 "脏数据"(有大量缺失值、复杂文本特征)或 "超大数据"(跑起来慢)。我们按 **「任务类型」+「新手原则」** 来选。
1. 第一步:先定「任务类型」(数据集要和任务匹配)
不同的任务对应不同的数据集,先明确你想做什么,再选数据集:
| 任务类型 | 目标(简单说) | 例子 | 对应数据集特点 |
|---|---|---|---|
| 回归任务 | 预测数值(比如房价、销量、温度) | 预测房价、预测商品销量 | 目标列是数字(如 100 万、500 件) |
| 分类任务 | 预测类别(比如是否患病、花的种类) | 识别鸢尾花种类、判断邮件是否是垃圾邮件 | 目标列是类别(如 "山鸢尾""垃圾邮件") |
| 聚类任务 | 给数据分群(不用提前知道类别) | 给客户分群、给商品分群 | 没有目标列,只有特征列 |
小贴士:结合PDPbox 作业(模型可解释性), 优先选回归或二分类任务的数据集,PDP 图的结果更直观。
2. 第二步:新手选数据集的 4 个黄金原则(避坑关键)
原则 1:优先选内置数据集(不用洗数据,直接用)
新手别自己爬数据、别找网上的 "原始数据"(比如电商评论、医疗数据),这些数据有缺失值、异常值,清洗起来超麻烦。优先选以下地方的内置数据集:
- sklearn 内置数据集 (最推荐):https://scikit-learn.org/stable/datasets.html特点:已经清洗好,样本量适中(几百到几千条),特征类型简单(数值为主)。代表:
- 回归:加州房价(
fetch_california_housing)、波士顿房价(注意:部分版本 sklearn 已移除,用加州房价替代) - 分类:鸢尾花(
load_iris)、红酒分类(load_wine)、乳腺癌分类(load_breast_cancer)
- 回归:加州房价(
- seaborn 内置数据集 :https://seaborn.pydata.org/generated/seaborn.load_dataset.html特点:表格形式,更贴近实际业务,比如小费数据(tips)、航班数据(flights)。
原则 2:数据量适中(几千条样本就够了)
- 太少:比如只有几十条样本,模型学不到规律,结果没意义。
- 太多:比如几十万条,新手的电脑跑起来慢,甚至卡死。
- 推荐:500~5000 条样本,既够模型学习,又跑得飞快。
原则 3:特征类型以数值为主(避免复杂的文本 / 类别特征)
新手别碰:文本特征(比如用户评论)、高基数类别特征(比如省份、职业,有几十种类别),这些需要做 "编码""分词" 等额外处理,容易出错。优先选:数值特征(比如收入、年龄、房间数),直接导入就能用。
原则 4:匹配工具特性(比如 PDPbox)
PDPbox 是用于机器学习模型可解释性的工具,所以数据集要满足:
- 必须是结构化数据(表格形式,行是样本,列是特征),不能是图像、音频、文本(PDPbox 不支持)。
- 特征和目标之间有明显的关联(比如收入和房价正相关),这样画出来的 PDP 图才有意义,不会是一条平线。
3. 新手数据集推荐清单(直接抄作业)
| 任务类型 | 推荐数据集 | 特点 | 适用场景 |
|---|---|---|---|
| 回归 | sklearn - 加州房价 | 8 个数值特征,2 万条样本,目标是房价中位数 | PDPbox 单特征 / 双特征图 |
| 分类 | sklearn - 鸢尾花 | 4 个数值特征,150 条样本,目标是 3 种花的种类 | PDPbox 看特征对分类的影响 |
| 分类 | sklearn - 乳腺癌分类 | 30 个数值特征,569 条样本,目标是良性 / 恶性 | PDPbox 二分类场景 |
| 回归 | seaborn-tips | 7 个特征(数值 + 少量简单类别),244 条样本,目标是小费金额 | PDPbox 看消费金额对小费的影响 |
二、再选模型:新手优先 "开箱即用" 的模型(不用调参,直接跑)
模型是用来学习数据规律的工具,选择的核心是「匹配任务类型」+「适配数据集」+「新手友好」。尤其结合 PDPbox 的使用,模型选择还要考虑工具的支持度。
1. 第一步:先匹配「任务类型」(模型类型不能错)
不同任务对应不同的模型,选反了会直接报错:
| 任务类型 | 新手推荐模型 | 模型作用 |
|---|---|---|
| 回归 | 线性回归(LinearRegression)、随机森林回归(RandomForestRegressor) | 预测数值 |
| 分类 | 逻辑回归(LogisticRegression)、随机森林分类(RandomForestClassifier) | 预测类别 |
小贴士:随机森林是新手的 "万能模型",不管回归还是分类都能用,而且对数据的非线性关系适应力强,画出来的 PDP 图也更有意义。
2. 第二步:新手选模型的 4 个黄金原则
原则 1:优先选 "开箱即用" 的模型 (默认参数就能跑)
新手别碰复杂模型(比如 XGBoost、LightGBM、神经网络),这些模型需要调参(比如学习率、树的数量),调不好反而效果差。优先选:
- 线性模型(线性回归、逻辑回归):原理简单,结果易解释,适合特征和目标有线性关系的场景。
- 树模型(决策树、随机森林):不用对数据做预处理(比如标准化),对非线性关系友好,是 PDPbox 的 "最佳搭档"。
原则 2:适配数据集特性
| 数据集特点 | 推荐模型 | 原因 |
|---|---|---|
| 特征和目标是线性关系(比如温度越高,销量越高) | 线性回归 / 逻辑回归 | 模型简单,计算快,解释性强 |
| 特征和目标是非线性关系(比如收入到一定值后,房价增长变慢) | 随机森林 | 能捕捉复杂的非线性规律 |
| 数据集小(几百条样本) | 决策树 / 逻辑回归 | 不容易过拟合(模型学歪) |
| 数据集大(几千条样本) | 随机森林 | 泛化能力强(预测更准) |
原则 3:匹配工具特性(比如 PDPbox)
PDPbox 对不同模型的支持度不同,新手优先选树模型(随机森林、决策树),原因:
- 计算速度快:树模型计算 PDP 值的效率比线性模型高,尤其数据量稍大时。
- 结果更直观:树模型能捕捉非线性关系,PDP 图会有明显的趋势(比如上升、下降、平缓),而线性模型的 PDP 图通常是一条直线,虽然也能用,但趣味性和分析价值稍低。
- 兼容性好:PDPbox 对树模型的支持最完善,几乎不会报错。
原则 4:先简单后复杂(逐步进阶)
新手学习的顺序应该是:线性回归/逻辑回归 → 决策树 → 随机森林 → XGBoost/LightGBM先把简单模型用熟,理解模型的基本逻辑,再尝试复杂模型,不要一步到位。
3. 新手模型推荐清单(结合 PDPbox)
| 任务类型 | 首选模型 | 次选模型 | 不推荐(新手) |
|---|---|---|---|
| 回归 | 随机森林回归(RandomForestRegressor) | 线性回归(LinearRegression) | XGBRegressor、神经网络 |
| 分类 | 随机森林分类(RandomForestClassifier) | 逻辑回归(LogisticRegression) | XGBClassifier、SVM(支持向量机) |
三、实战搭配:数据集 + 模型的最佳组合(直接用)
结合你之前的 PDPbox 作业,我给你整理了 3 个 "开箱即用" 的组合,抄代码就行:
组合 1:回归任务(最推荐)
- 数据集 :sklearn 加州房价(
fetch_california_housing) - 模型 :随机森林回归(
RandomForestRegressor) - 优势:特征和目标关联明显,PDP 图趋势清晰,新手易理解。
组合 2:分类任务
- 数据集 :sklearn 鸢尾花(
load_iris) - 模型 :随机森林分类(
RandomForestClassifier) - 优势:样本量小,运行快,能看特征对花种类分类的影响。
组合 3:二分类任务
- 数据集 :sklearn 乳腺癌分类(
load_breast_cancer) - 模型 :随机森林分类(
RandomForestClassifier) - 优势:实际业务场景(医疗),PDP 图有实际分析价值。
四、新手避坑小贴士
- 别追求 "完美数据":新手的目标是跑通代码、理解逻辑,不是做精准的数据分析,所以用内置数据集就够了。
- 别死磕复杂模型 :随机森林的默认参数对新手来说足够用,不用调参(比如
n_estimators=100是默认值,直接用)。 - 别选不匹配的工具:比如用 PDPbox 分析图像数据,这是不可能的,工具和数据 / 模型要匹配。
- 验证是否合适的简单方法:跑通代码后,看 PDP 图有没有明显趋势(不是平线),模型预测准确率 / 得分不用太高(新手不用追求 99%)。
五、总结:选择的核心流程(一步一步来)
- 定任务:先确定是回归还是分类(新手优先回归)。
- 选数据:选 sklearn/seaborn 的内置数据集,数值特征为主,样本量适中。
- 选模型:优先随机森林(回归 / 分类),其次线性模型。
- 验效果:跑通代码,看 PDP 图是否有意义,不用追求高精度。
这样的选择逻辑,既符合零基础的学习节奏,又能和你之前学的类的调用、PDPbox 绘图结合起来,形成完整的知识链~
作业:参考 pdpbox 官方文档中的其他类,绘制相应的图,任选即可
作业实现:使用 PDPbox 绘制部分依赖图(PDP)
作为零基础学习者,我会选PDPbox 中最常用、最易理解的PDPIsolate类 (单特征部分依赖图)来完成绘图作业。整个过程会从环境准备→文档检索→代码实现→结果解释一步步拆解,保证你能跟着做、看得懂。
一、先搞懂:PDPbox 是什么?
PDPbox 是 Python 中用于机器学习模型可解释性 的库,核心功能是绘制部分依赖图(Partial Dependence Plot, PDP) :它能展示单个特征 或两个特征的交互对模型预测结果的影响,简单说就是 "看某个特征变了,模型预测结果会怎么变"。
二、步骤 1:环境准备(安装 + 版本核对)
1. 安装 PDPbox 及相关依赖
PDPbox 依赖pandas、numpy、scikit-learn(机器学习库)、matplotlib(绘图底层库),先在命令行 / 终端安装:

2. 核对版本(保证文档和包版本一致)
安装后,用代码查看版本,确保后续文档和版本匹配:
python
# 导入库
import pdpbox
import sklearn
import pandas as pd
# 打印版本号
print("PDPbox版本:", pdpbox.__version__)
print("Scikit-learn版本:", sklearn.__version__)预期结果 :PDPbox 版本为0.2.1(这是比较稳定的版本,文档也齐全)。
三、步骤 2:检索 PDPbox 的官方文档(找PDPIsolate类的用法)
1. 找 PDPbox 的官方文档
- GitHub 仓库 (核心):https://github.com/SauceCat/PDPbox(官方源码 + 文档)
- 官方文档地址 :https://pdpbox.readthedocs.io/en/latest/(详细的 API 说明)
2. 定位PDPIsolate类的关键信息
在文档中找到PDPIsolate类,重点看 3 个核心点(对应之前学的类的关注点):
| 关注点 | 文档中的关键信息 |
|---|---|
| 实例化参数 | model(训练好的机器学习模型)、dataset(数据集)、model_features(模型的特征列表)、feature(要分析的单个特征名) |
| 普通方法 | pdp_isolate.fit()(计算部分依赖值)、pdp_isolate.plot()(绘制图形) |
| 方法返回值 | fit()无显式返回值(内部计算数据),plot()返回绘图的轴对象(可用于后续调整) |
四、步骤 3:代码实现(绘制单特征部分依赖图)
我们用加州房价数据集 (sklearn 内置的回归数据集),训练一个随机森林回归模型,然后用PDPIsolate绘制 "平均收入" 这个特征对房价预测的影响。
完整代码(带详细注释)
python
# ---------------------- 步骤1:导入所需库 ----------------------
# PDPbox的核心模块
from pdpbox import pdp
# sklearn的数据集和模型
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import pandas as pd
# ---------------------- 步骤2:加载并预处理数据 ----------------------
# 加载加州房价数据集(返回的是字典格式)
housing = fetch_california_housing()
# 把数据转换成DataFrame(方便后续处理)
housing_df = pd.DataFrame(housing.data, columns=housing.feature_names)
# 添加目标变量(房价中位数)
housing_df['MedHouseVal'] = housing.target
# 划分训练集和测试集(模型训练用)
X = housing_df.drop('MedHouseVal', axis=1) # 特征数据
y = housing_df['MedHouseVal'] # 目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ---------------------- 步骤3:训练机器学习模型 ----------------------
# 初始化随机森林回归模型(简单易上手,不用调参)
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 用训练集训练模型
rf_model.fit(X_train, y_train)
# ---------------------- 步骤4:实例化PDPIsolate类(核心) ----------------------
# 选择要分析的特征:"MedInc"(居民平均收入,这个特征对房价影响大,结果直观)
feature_name = 'MedInc'
# 实例化PDPIsolate对象(对应文档中的实例化参数)
pdp_isolate = pdp.pdp_isolate(
model=rf_model, # 训练好的模型
dataset=X_test, # 用于计算的数据集(测试集即可)
model_features=X.columns.tolist(), # 模型的所有特征名列表
feature=feature_name # 要分析的单个特征
)
# ---------------------- 步骤5:计算部分依赖值并绘图 ----------------------
# 计算部分依赖值(调用fit方法,文档中是pdp_isolate.fit(),这里pdp_isolate已经包含了fit的结果)
# 绘制部分依赖图(调用plot方法)
fig, axes = pdp_isolate.plot(
figsize=(10, 6), # 图形大小
title=f'部分依赖图:{feature_name}对房价的影响', # 图形标题
plot_lines=True, # 显示每个样本的ICE曲线(个体条件期望,可选)
frac_to_plot=0.5 # 随机显示50%的样本ICE曲线,避免图形太乱
)五、代码解释(零基础友好版)
1. 数据加载部分
fetch_california_housing():从 sklearn 获取加州房价数据集,包含房屋的 8 个特征(比如平均收入、房屋年龄、房间数等)和目标变量(房价中位数)。- 转换成 DataFrame:是为了用表格形式处理数据,更直观。
2. 模型训练部分
RandomForestRegressor:随机森林模型,是一种常用的机器学习模型,不需要复杂的参数调整,适合新手。fit():训练模型,让模型学习 "特征和房价的关系"。
3. PDPIsolate 核心部分
pdp.pdp_isolate():其实是PDPIsolate类的便捷调用方法(文档里也推荐这么用),参数里:model:告诉 PDPbox 用哪个模型来计算依赖关系。dataset:用哪个数据集来计算(测试集即可,因为训练集已经用来训练模型了)。model_features:模型的所有特征名,保证特征对应正确。feature:要分析的特征(这里选 "平均收入",因为收入对房价影响最明显)。
4. 绘图部分
pdp_isolate.plot():调用绘图方法,参数里:plot_lines=True:除了显示平均的部分依赖曲线(蓝色粗线),还显示每个样本的 ICE 曲线(灰色细线),能看到个体的差异。frac_to_plot=0.5:只显示 50% 的样本曲线,避免图形太拥挤。
六、运行结果及解读
1. 图形样子
你会看到一个折线图:
- x 轴 :居民平均收入(
MedInc)的取值。 - y 轴:模型预测的房价中位数。
- 蓝色粗线 :部分依赖曲线(所有样本的平均情况)。
- 灰色细线 :ICE 曲线(每个样本的个体情况)。
2. 结果解读
- 随着居民平均收入的增加,房价的预测值明显上升,这符合常识(收入越高,房价越高)。
- 当收入达到一定值后,房价的增长速度变慢(曲线变平缓),说明收入对房价的影响有上限。
七、拓展:如果想画双特征交互图(PDPInteract类)
如果你想尝试更进阶的,可使用PDPInteract类绘制两个特征的交互影响(比如 "平均收入" 和 "房屋年龄" 的交互),核心代码只需替换第四步和第五步:
python
# 选择两个要分析的特征
feature_names = ['MedInc', 'HouseAge']
# 实例化PDPInteract对象
pdp_interact = pdp.pdp_interact(
model=rf_model,
dataset=X_test,
model_features=X.columns.tolist(),
features=feature_names
)
# 绘制交互图
fig, axes = pdp_interact.plot(
figsize=(12, 8),
title='部分依赖交互图:收入和房屋年龄对房价的影响'
)这个图会是一个热力图,能看到两个特征共同对房价的影响。
八、新手避坑小贴士
- 数据格式:PDPbox 要求数据集是 DataFrame 或数组,且特征名必须和模型训练时的一致。
- 模型类型:PDPbox 支持大部分机器学习模型(树模型、线性模型等),但不支持深度学习模型(如神经网络)。
- 版本问题 :如果报错,优先检查 PDPbox 版本是否为
0.2.1,sklearn 版本是否兼容(推荐1.2.2左右)。
这样一步步下来,不仅完成了作业,还能理解 PDPbox 的核心用法,以及类的实例化、方法调用的逻辑~