每天早上醒来,手机推送的新闻恰好是你关注的领域;打开购物软件,首页推荐的商品总能戳中你的喜好;用语音助手发消息,它能精准识别你的口音和语义;开车时,自动驾驶系统会平稳避开障碍物......这些我们习以为常的智能场景,背后都藏着同一个核心技术------机器学习。
对于人工智能初学者来说,"机器学习"可能听起来高深莫测,但其实它的核心逻辑和我们人类学习的过程很相似。就像我们通过观察、练习学会骑自行车、识别动物,机器也能通过"观察"数据、"练习"模型,学会完成特定任务。今天,我们就用最通俗的语言,带大家走进机器学习的世界,搞清楚它是什么、怎么工作、能做什么、不能做什么。
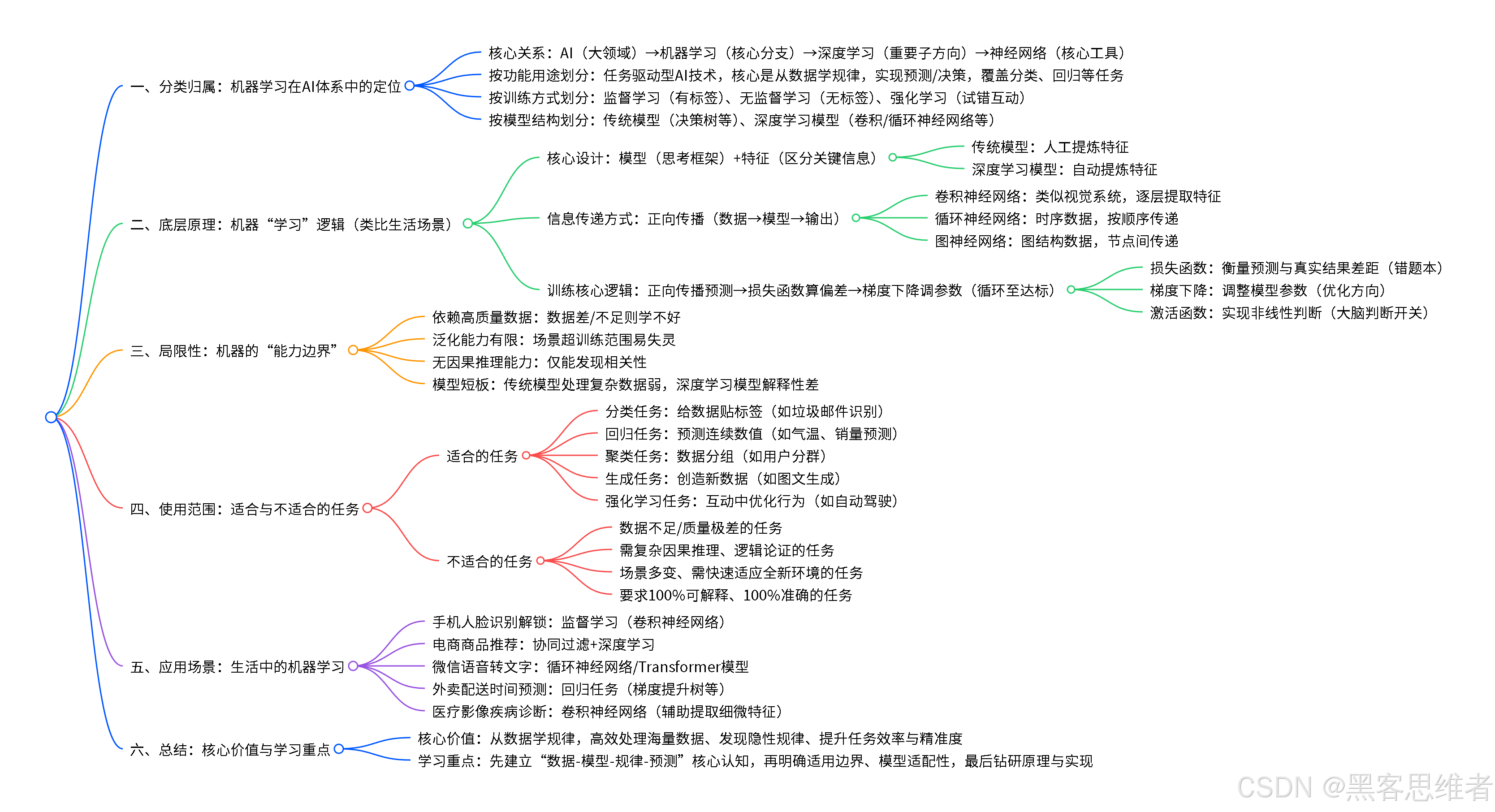
一、分类归属:机器学习在AI体系中的定位
在正式拆解原理前,我们先明确机器学习在主流人工智能分类体系中的位置。首先要区分一个常见误区:机器学习≠神经网络,而是人工智能的核心分支 ,而神经网络是机器学习中"深度学习"方向的核心实现载体。简单来说,人工智能是"大领域",机器学习是"大领域下的核心分支",深度学习是"机器学习的重要子方向",神经网络是"深度学习的核心工具"。
从不同维度划分,机器学习的分类归属清晰明确:
-
按"功能用途 "划分:机器学习属于"任务驱动型"AI技术,核心目标是解决"从数据中学习规律,并用规律预测或决策 "的问题,覆盖分类、回归、聚类、生成等多个核心任务,是实现"数据智能"的核心手段。
-
按"训练方式 "划分:这是机器学习最核心的分类维度,主要分为三大类------监督学习、无监督学习、强化学习。就像老师教学生的不同方式:监督学习是"有老师指导"(数据有明确标签,比如"这张图是猫""这个邮件是垃圾邮件");无监督学习是"自学探索"(数据无标签,让机器自己找规律,比如把相似的用户分成不同群体);强化学习是"试错中学习"(机器通过和环境互动,根据"奖励"或"惩罚"调整行为,比如AlphaGo学下棋)。
-
按"模型结构/神经元特性 "划分:机器学习包含传统模型 (如决策树、支持向量机,无复杂神经网络结构)和深度学习模型(基于神经网络,神经元按特定拓扑结构连接,如卷积神经网络、循环神经网络)。其中,深度学习是当前机器学习的主流方向,也是实现复杂智能任务(如图像识别、语音合成)的核心力量。
简单总结:机器学习是人工智能的"核心技能库",按训练方式可分为监督、无监督、强化学习三类,既包含简单的传统模型,也包含复杂的深度学习模型,能适配不同难度的智能任务。
二、底层原理:用生活类比看懂机器如何"学习"
机器学习的核心原理可以概括为一句话:让机器从数据中找到"规律",并用这个规律解决新问题。就像我们小时候学认水果,妈妈会指着苹果说"这是苹果,圆形、红色、吃起来甜",指着香蕉说"这是香蕉,长条形、黄色、吃起来软"------妈妈给的"苹果、香蕉的特征"就是"数据",我们大脑里形成的"认水果的标准"就是"模型",这个过程就是"学习"。机器学习的过程,和这个逻辑完全一致。
下面我们用"教机器认猫"的例子,拆解机器学习的核心环节,同时解释清楚关键概念。
1. 核心设计:机器的"大脑结构"------模型与特征
要让机器认猫,首先要给它一个"思考框架",这个框架就是"模型"。不同的模型,就像不同的"学习方法":比如传统模型中的"决策树",就像我们查字典的"分类目录"(先看"有没有毛"→再看"是不是四条腿"→再看"有没有尾巴");而深度学习中的"卷积神经网络",就像我们的视觉系统(先看整体轮廓→再看细节特征,比如耳朵形状、眼睛位置)。
这里要先解释一个关键概念:特征。特征就是数据中"能帮我们区分不同事物的关键信息"。比如认猫的特征可能是"有两只三角形的耳朵""有一条长尾巴""全身有毛""会喵喵叫"------这些特征就像我们学习时记的"重点笔记",机器就是通过这些"笔记"找规律。
不同类型的机器学习模型,对"特征"的处理方式不同:传统模型需要我们人工提炼特征(比如我们先告诉机器"要关注耳朵、尾巴");而深度学习模型能自己从数据中提炼特征(机器自己学会"看耳朵、尾巴这些重点"),这也是深度学习为什么能处理复杂任务的核心原因------它不用人工"划重点",能自己发现关键信息。
2. 信息传递方式:机器的"思考流程"------正向传播
当机器有了"模型"这个思考框架后,就会按照固定的流程处理数据,这个流程就是"信息传递"。我们以"卷积神经网络认猫"为例,用"逐行看书找重点"的类比来理解:
你拿到一本关于"猫"的书,会逐行阅读,找出和"猫"相关的重点句子;机器处理猫的图片时,也会用类似的方式------通过"卷积核"(相当于我们的"重点标记笔")逐行扫描图片,先提取简单的特征(比如线条、颜色块),再把这些简单特征组合成复杂特征(比如"线条组成的耳朵""颜色块组成的身体"),这个过程就是"正向传播"------信息从"原始数据"(图片)一步步传递到"模型输出"(判断"是猫"或"不是猫")。
不同模型的信息传递方式不同:比如循环神经网络(处理文字、语音等时序数据)是"单向/双向传递",就像我们读句子要按顺序从左到右读;而图神经网络(处理社交网络、分子结构等数据)是"图结构传递",就像我们在社交网络中,通过朋友认识新朋友,信息在节点之间相互传递。
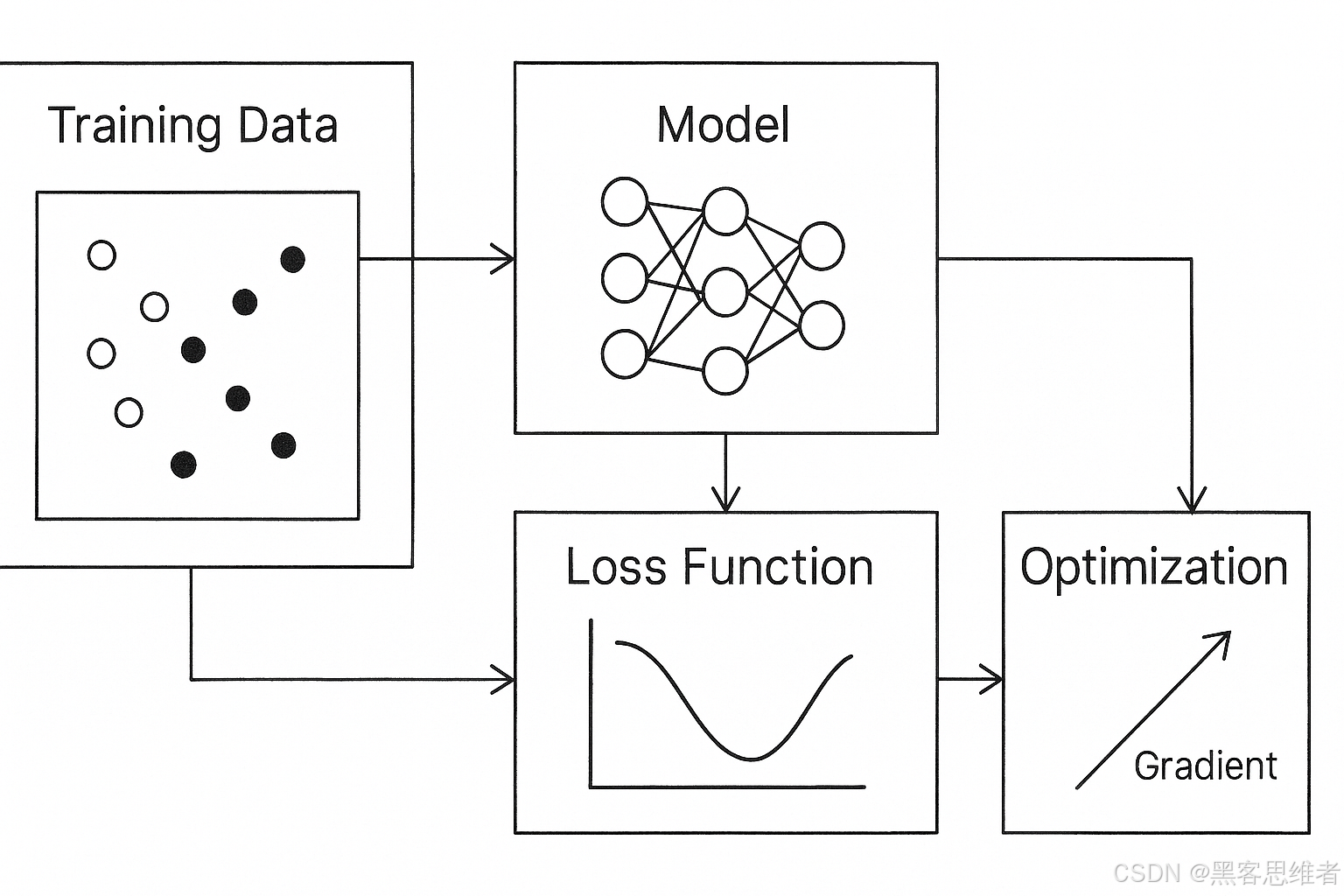
3. 训练的核心逻辑:机器的"纠错改进"------损失函数与梯度下降
机器第一次认猫时,很可能出错(比如把狗当成猫),这时候就需要"纠错改进",这个过程就是"训练"。训练的核心逻辑是"发现错误→调整方向→减少错误",就像我们考试做错了题,要分析错题原因,调整学习方法,下次争取考得更好。
这里需要解释两个关键概念,我们用"投篮练习"来类比:
第一个概念:损失函数。它相当于"投篮的偏差值"------用来衡量机器预测结果和真实结果的差距。比如机器把狗当成了猫,损失函数就会算出一个"大偏差值"(说明错得离谱);如果机器正确认出了猫,损失函数就会算出一个"小偏差值"(说明做得好)。简单说,损失函数就是机器的"错题本",帮它明确"错了多少"。
第二个概念:梯度下降。它相当于"调整投篮的力度和角度"------机器根据损失函数算出的"偏差值",调整模型中的参数(相当于我们调整投篮的力度、角度),让下次预测的偏差值更小。比如机器第一次因为"把'四条腿'当成了猫的唯一特征"认错了狗,通过梯度下降调整参数后,会学会"除了四条腿,还要看耳朵形状",下次就不会再错了。
训练的过程,就是"正向传播预测→损失函数算偏差→梯度下降调参数"的循环,直到机器的预测准确率达到我们的要求,训练就完成了。这时候,机器就相当于"学会了认猫的规律",可以用来识别新的猫图片了。
补充一个关键概念:激活函数。如果说模型是机器的"大脑",激活函数就是"大脑的判断开关"。它的作用是让机器学会"非线性判断",就像我们判断"一个人是不是好人",不能只看"有没有做好事"这一个线性标准(做一件好事就是好人,做两件就是更好的人),还要综合多个因素做非线性判断(比如虽然做了一件好事,但动机不好,也不能算好人)。激活函数让机器能处理更复杂的问题,而不是简单的"非黑即白"。
三、局限性:机器不是"万能的",这些问题它解决不了
虽然机器学习能实现很多智能功能,但它并不是"万能的",有明确的适用边界和不足。我们用"学生考试"来类比:再优秀的学生,也有不擅长的科目;机器再智能,也有解决不了的问题。下面我们客观说明机器学习的核心局限性,同时解释清楚"为什么会有这些局限"。
1. 依赖高质量数据,"数据差"就会"学不好"
机器学习的核心是"从数据中学习",如果数据质量差(比如数据不完整、有错误,或者数据分布不均),机器就会学到错误的规律。这就像我们学习时,如果看的是错误的教材、记的是错误的笔记,肯定学不会正确的知识。
比如用"大多是白色猫"的数据训练机器认猫,机器就会误以为"白色是猫的关键特征",遇到黑色的猫就会认错;如果数据中混有"狗的图片"且没有标注,机器就会混淆猫和狗的特征。更重要的是,机器无法"凭空学习"------如果没有足够的数据,它就像学生没有足够的练习题,无法形成稳定的"解题能力",也就无法完成复杂任务。
2. 泛化能力有限,"换个场景就失灵"
泛化能力指的是机器"把学到的规律用到新场景、新数据上的能力"。机器学习的泛化能力很有限,一旦场景变化超出训练数据的范围,就容易出错。这就像我们学会了在平地上骑自行车,到了崎岖的山路就可能摔倒------因为训练(练习)的场景和新场景差异太大。
比如用"白天的猫图片"训练的机器,到了夜晚光线昏暗的场景,就可能认不出猫;用"正常口音的语音"训练的语音识别系统,遇到方言或特殊口音,识别准确率就会大幅下降。为什么会这样?因为机器学到的是"训练数据中的规律",而不是"事物的本质规律"------它不知道"猫的本质特征是耳朵形状、身体结构,而不是颜色或光线",所以场景一变就会失灵。
3. 无法理解"因果关系",只能找"相关性"
这是机器学习最核心的局限性之一:机器只能发现数据中的"相关性",而无法理解"因果关系"。简单说,它知道"两个事物同时出现",但不知道"为什么会同时出现"。这就像我们发现"夏天冰淇淋销量上升,溺水事故也上升",机器会认为"冰淇淋销量和溺水事故有关",但它不知道背后的原因是"夏天天气热,大家都去游泳"。
比如推荐系统知道"用户买了A商品后,大概率会买B商品",但它不知道"用户为什么买A后会买B"(是A和B互补,还是A是B的前置需求);医疗诊断模型知道"某种症状和某种疾病同时出现",但它无法判断"是症状导致了疾病,还是疾病导致了症状"。这种局限性让机器学习无法完成需要"逻辑推理"和"因果判断"的任务,比如复杂的科学研究、法律判断等。
4. 传统模型处理复杂数据能力弱,深度学习模型"解释性差"
传统机器学习模型(如决策树、支持向量机)虽然简单易懂,但处理复杂数据(如图像、语音、长文本)的能力很弱------它们无法自己提炼复杂数据中的特征,需要人工做大量的"特征工程",效率很低。
而深度学习模型虽然能处理复杂数据,但存在"解释性差"的问题------它就像一个"黑盒子",我们知道它能做出正确的预测,但不知道它是"怎么想到的"。比如卷积神经网络能正确认出猫,但我们无法说清"它是通过哪个具体特征判断的";AlphaGo能赢下棋局,但我们无法复刻它的思考过程。这种"黑盒子"特性,让深度学习在需要"可解释性"的场景(如医疗诊断、金融决策)中受到限制------医生需要知道"为什么模型判断患者患病",才能做出最终诊断;法官需要知道"为什么模型判断风险高",才能做出公正判决。
四、使用范围:有些问题适合用机器学习,有些不适合
结合上面的局限性,我们可以明确机器学习的适用范围。简单来说:机器学习适合处理"有大量高质量数据、可通过规律预测/分类、不需要复杂因果推理"的问题;不适合处理"数据不足、场景多变、需要理解因果关系、要求完全可解释"的问题。
下面我们按"任务类型"具体说明:
1. 适合的任务类型
(1)分类任务:核心是"给数据贴标签",判断"是什么"。比如"判断邮件是不是垃圾邮件""判断图片是猫还是狗""判断用户是不是潜在客户"------这类任务有明确的"类别标签",只要有足够的标注数据,用监督学习模型就能很好地完成。
(2)回归任务:核心是"预测连续数值",判断"有多少"。比如"预测明天的气温""预测商品的销量""预测用户的消费金额"------这类任务的输出是连续的数值,只要数据有明显的趋势规律,用线性回归、梯度提升树等模型就能实现。
(3)聚类任务:核心是"给数据分组",找"相似的群体"。比如"把用户按消费习惯分成不同群体""把新闻按主题分成不同类别""把产品按特征分成不同系列"------这类任务没有标签,需要机器自己找规律,用无监督学习模型(如K-means)就能完成。
(4)生成任务:核心是"创造新数据",生成"和原有数据相似的内容"。比如"生成逼真的图片""生成通顺的文字""合成自然的语音"------这类任务需要处理复杂的高维数据,用深度学习模型(如GAN、Transformer)能实现很好的效果。
(5)强化学习任务:核心是"在互动中优化行为",比如"自动驾驶""机器人导航""游戏AI"------这类任务有明确的"奖励/惩罚"机制,机器能通过不断试错调整行为,适合需要实时决策的场景。
2. 不适合的任务类型
(1)数据不足或数据质量极差的任务:比如"预测一款全新未上市产品的销量"(没有历史数据)、"用错误百出的病历数据做疾病预测"(数据质量差)------没有足够的"学习素材",机器无法形成规律,自然无法完成。
(2)需要复杂因果推理和逻辑论证的任务:比如"证明一个数学定理""判断一个法律案件的是非曲直""分析一个复杂社会问题的根源"------这些任务需要理解"为什么",而不仅仅是"是什么",机器学习的"相关性分析"无法满足需求。
(3)场景多变、需要快速适应全新环境的任务:比如"让机器人在完全未知的外星环境中自主生存"(场景从未见过,没有训练数据)、"用针对城市道路训练的自动驾驶模型在崎岖的山区道路行驶"(场景差异太大)------机器的泛化能力有限,无法快速适应全新环境。
(4)要求100%可解释、100%准确的任务:比如"用机器学习模型做心脏手术的决策"(需要医生完全理解模型的判断依据,且不允许任何错误)、"用模型判断一个人是否犯罪"(要求100%准确,否则会造成冤假错案)------机器学习的"黑盒子"特性和概率性预测(无法保证100%准确)无法满足这类任务的要求。
五、应用场景:生活中那些藏着机器学习的"智能瞬间"
了解了机器学习的原理和适用范围后,我们再看生活中的具体应用。其实机器学习已经渗透到我们生活的方方面面,下面列举5个最贴近生活的案例,说明机器学习在其中的作用。
1. 手机人脸识别解锁------监督学习的分类任务应用
现在很多人的手机都支持人脸识别解锁,这个功能的核心就是机器学习中的"卷积神经网络"(监督学习模型)。具体过程是:首先,我们第一次设置解锁时,手机会采集我们多张不同角度的人脸图片(这是"训练数据"),并标注"这是机主"(这是"标签");然后,卷积神经网络会从这些图片中提取人脸的关键特征,比如"眼角到嘴角的距离""鼻梁的高度""颧骨的轮廓"等,训练出一个"认机主"的模型;最后,我们解锁时,手机会实时采集人脸图片,让模型判断"这张脸的特征和机主的特征是否匹配",如果匹配,就解锁手机。
这里机器学习的作用是"提取人脸特征并做分类判断"------快速区分"机主"和"非机主",保证解锁的安全性和便捷性。
2. 电商平台商品推荐------协同过滤与深度学习的混合应用
打开淘宝、京东等电商平台,首页的"为你推荐"栏目总能精准命中我们的喜好,这背后是机器学习的"推荐系统"在工作。推荐系统通常结合了"协同过滤"(传统机器学习模型)和"深度学习模型":协同过滤的逻辑是"找相似的人或相似的商品",比如"和你有相似购物习惯的人都买了这款商品,所以推荐给你";深度学习模型则会分析更复杂的特征,比如"你浏览商品的时长""你是否加入购物车""你对商品的评价内容"等,进一步提升推荐的精准度。
这里机器学习的作用是"挖掘用户的购物偏好规律"------通过分析用户的历史行为数据,找到用户可能喜欢的商品,既提升了用户的购物体验,也帮助商家提高了销量。
- 微信语音转文字------循环神经网络的时序任务应用
微信的语音转文字功能,让我们不用听语音就能知道内容,这个功能依赖于机器学习中的"循环神经网络"(RNN)或"Transformer模型"(处理时序数据的深度学习模型)。语音是典型的"时序数据"(有时间顺序,比如"你好"的发音有先后顺序,不能颠倒),循环神经网络能按时间顺序处理语音信号,提取其中的语义特征,再将其转换为对应的文字。对于不同口音的语音,模型还会通过"迁移学习"(把在大量标准语音上学到的规律,迁移到口音语音上)提升识别准确率。
这里机器学习的作用是"解析语音的时序特征和语义信息"------实现语音到文字的精准转换,解决了"不方便听语音"的痛点。
- 外卖平台配送时间预测------回归任务的实际应用
我们在美团、饿了么点外卖时,平台会显示"预计送达时间",这个时间的预测就是机器学习的"回归任务"。平台会收集大量数据,比如"商家出餐速度""骑手当前位置""距离用户的距离""实时交通状况""天气情况"等,然后用"梯度提升树"(传统机器学习模型)或"深度学习模型"分析这些数据和"实际送达时间"的关系,训练出预测模型。当我们下单后,模型会输入当前的相关数据,预测出最可能的送达时间。
这里机器学习的作用是"挖掘多因素与送达时间的规律"------精准预测配送时间,让用户和骑手都能合理安排时间,提升外卖配送的效率。
- 医疗影像疾病诊断------卷积神经网络的特征提取应用
在医疗领域,机器学习已经成为医生的"好帮手",比如用卷积神经网络辅助诊断肺癌、乳腺癌等疾病。以肺癌诊断为例,医生需要看大量的肺部CT影像,找出微小的结节(早期肺癌的特征),但人工诊断容易遗漏。卷积神经网络能从CT影像中提取出医生可能忽略的微小特征,比如"直径几毫米的结节""结节的边缘形状"等,然后判断"是否存在肺癌风险",并把可疑区域标记给医生。
这里机器学习的作用是"精准提取医疗影像的细微特征"------辅助医生诊断,提高早期疾病的检出率,减少漏诊和误诊。需要注意的是,目前机器学习还只是"辅助工具",最终的诊断结论还是需要医生做出。
六、总结:机器学习的核心价值与学习重点
最后,我们用一句话总结机器学习的核心价值:机器学习是让机器从数据中学习规律、解决实际问题的核心AI技术,它的价值在于"高效处理海量数据、发现人类难以察觉的规律、提升任务效率和精准度"。
对于人工智能初学者来说,学习机器学习的重点的不是一开始就钻研复杂的公式和模型,而是先建立"数据-模型-规律-预测"的核心认知:先明白"机器学习能做什么、不能做什么",再理解"不同模型适合什么任务",最后再逐步学习具体的模型原理和实现方法。就像我们学习数学,先明白"数学能解决什么问题",再学具体的公式和解题方法,才能真正掌握。