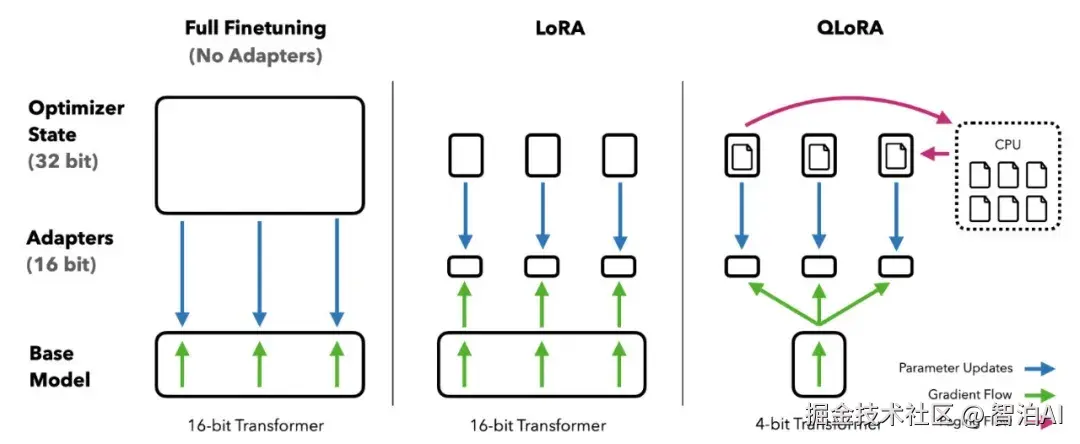
LoRA(Low-Rank Adaptation)是一种用于微调大型语言模型(LLM)的高效方法,能够在不大幅增加计算资源的情况下,让模型快速适应新任务或新领域。
1.背景: 为什么需要 LoRA?
想象一下,大型语言模型(比如 GPT-3、LLaMA)就像一辆超级跑车,里面有几十亿甚至上千亿个零件(参数)。
这些模型在通用任务上很强,但如果你想让它专门处理某个新任务(比如医疗问答、金融分析),传统方法是把整个型的参数重新调整一遍。
这就像为了让跑车跑得更快,把发动机、轮胎、底盘全拆了重装一遍,费时费力还费钱。
但现实中,我们往往没有那么多资源--训练一个大模型需要超级计算机和海量时间。
于是,LORA 出现了。它的核心思路是: 不用动整个模型,只调整一小部分参数,就能让模型适应新任务。
这就像在跑车上加个小涡轮增压器,既省钱又省力,效果还不错。
2.LoRA 的原理: 低秩适配是什么?
翻译成中文就是"低秩适配"。这个名LORA 的全称是 Low-Rank Adaptation,字听起来有点学术,但其实原理很简单。
模型的参数是大矩阵
大型语言模型的参数很多是以矩阵形式存在的,比如自注意力层里的权重矩阵。这些矩阵很大,包含了模型的核心知识。
低秩分解: 精简更新
LORA 的聪明之处在于,它认为你不需要更新整个大矩阵,而是可以用一个"精简版"来代替。这个精简版叫"低秩矩阵",它捕捉了大矩阵里最核心的变化信息,但参数量小得多。
具体操作是这样的:
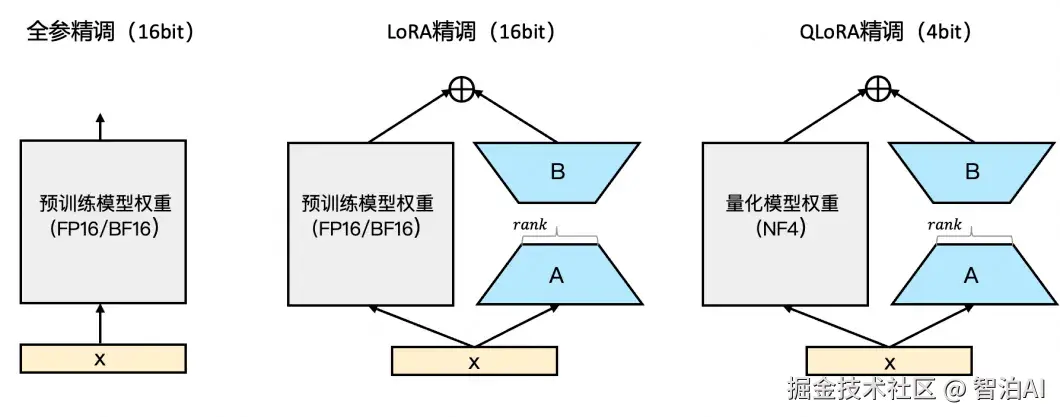
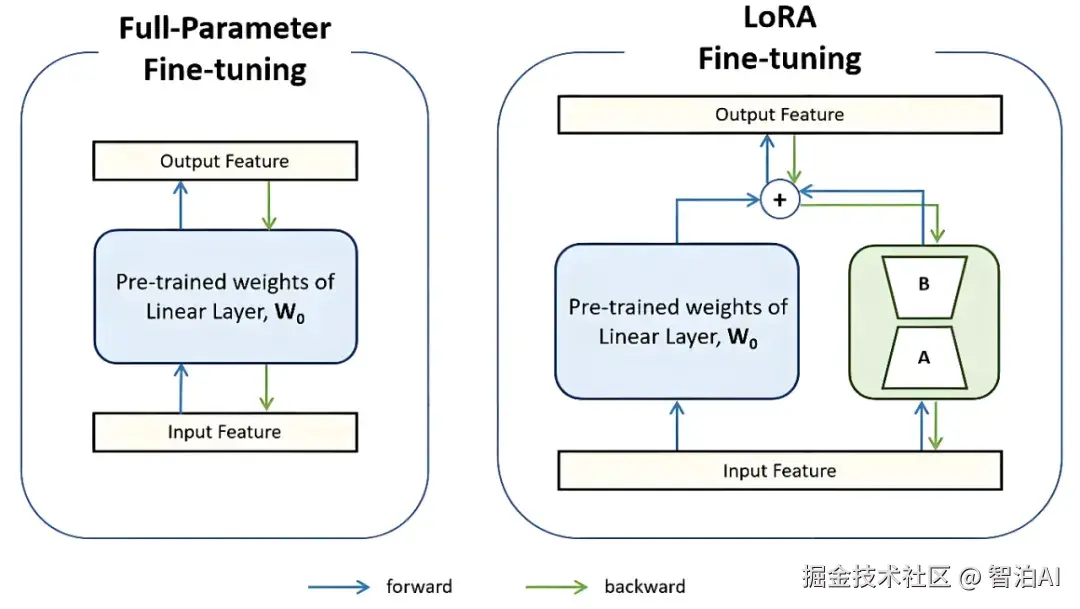
在原始的权重矩阵(记为(W))旁边,加两个小矩阵(A)和(B); (A)和(B)的"秩"(rank)很低(比如8或16),参数量远小于(W); 微调时,原始矩阵(W)不动,只更新(A)和(B)。
最后,模型的输出变成 w+AxB,这里的 AxB就像一个小助手,帮原始模型适应新任务。
通俗比喻
想象你有个大公司(原始模型),要接手一个新业务。传统方法是把所有部门都改组,太麻烦。
LORA则是派一个小团队((A)和(B)),专门负责新业务,既高效又不影响公司核心运作。
3.LoRA 的优势: 为什么这么受欢迎?
LoRA 能火起来,是因为它有几个特别牛的优势
参数超少: 传统微调要更新全部参数(比如几十亿个)LORA 只更新一小部分(通常是原始模型的 0.01%到1%)存储和计算成本大幅降低。
训练超快: 参数少,训练自然快,普通 GPU就能跑,不用超算。
部署超方便: LoRA 模块像"插件"一样,可以随时插拔。比如一个基础模型,可以加载不同的 LoRA 模块来处理不同任务。
效果还不错: 虽然参数少,但在很多任务上,LORA的表现和全参数微调差不多,甚至更好。
通俗比喻
LORA 就像给手机装个小应用。不用换新手机,只需下载个插件,就能让手机多会几招,既省钱又方便。
4. LoRA 的应用场景: 能干啥?
LoRA 在实际中用途很广,尤其是在自然语言处理(NLP)领域。以下是几个典型场景:
领域适配:让通用模型变成"专家"。比如拿医疗数据微调一个 LoRA 模块,模型就能回答医学问题。
多任务学习:一个基础模型,通过不同 LoRA 模块处理不同任务,比如翻译、对话、文本生成。
个性化定制:为特定用户或场景定制模型,比如让聊天机器人模仿你的语言风格。
实际例子
假设你有个通用聊天机器人,想让它在金融领域表现更好。传统方法是用金融数据重训整个模型,费时费力。
LORA 则是训练一个金融领域的 LoRA 模块,插到原始模型上,机器人立马变成"金融专家"。
5.LoRA 的工作流程: 怎么用?
LoRA 的使用过程很简单,步骤如下
1.选个基础模型: 比如一个预训练好的大模型(LLaMA、GPT等)
2.加 LoRA 模块: 在模型的某些层(比如自注意力层)旁边加两个小矩阵(A)和(B)。
冻结原始参数: 训练时,原始模型的参数不动,只更新(A)和(B)。
微调: 用新任务的数据训练(A)和(B),让它们学会A.新技能。
推理: 用的时候,把 LoRA 模块加到原始模型上,模型就能干新活了。
通俗比喻
你有个智能音箱,想让它会讲笑话。不用把音箱拆了重装,只需下载个"笑话插件"(LORA 模块),插上就能讲笑话。
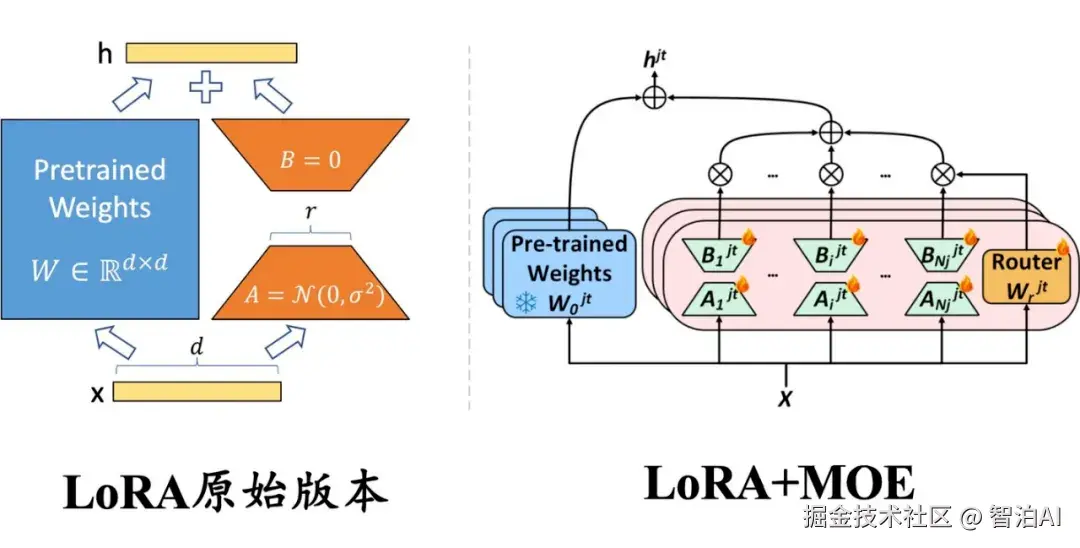
6.LoRA 的数学细节: 想深入了解?
如果你对数学感兴趣,可以看看 LoRA 的简单原理(不感兴趣可以跳过)
原始权重矩阵(W)是dxd的,参数量是 d^2(比如,d=1000 参数量就是 100 万)。
LORA加了Delta(w)=AxB,其中(A)是d x r(B)是rxd,(r)很小(比如8)。参数量变成 2xdxr(比如)2x1000 x8=16000 ,远小于 d^2
简单说,LoRA 用很少的参数(比如1.6万个)代替了更新全部参数(100 万个),但效果依然很好。
7.LoRA 的局限性: 有啥不足?
LORA 虽然好用,但也不是万能的:
效果有限: 某些复杂任务上,LORA 可能不如全参数微调。
超参数麻烦: 比如秩(r)的选择,太小效果不好,太大参数又多,需要试错。
位置选择: LORA 加在哪些层效果最好,靠经验或实验。
为了改进这些问题,出现了 LORA+、DORA 等升级版性能更强,适应性更好。
8.总结: LORA 到底是啥?
LoRA 是一种高效微调大型语言模型的方法,通过在原始模型旁边加两个小矩阵(低秩矩阵),让模型快速适应新任务。
它的优势是参数少、训练快、部署方便,特别适合资源有限或需要快速适应的场景。
简单来说,LoRA 就像给模型装了个"外挂",不用大动干戈,就能让模型学会新技能。
通俗总结
LORA 是模型的"涡轮增压器",小投入大回报,让微调变得像装插件一样简单。