
目录
[一、函数:Python 代码的 "高效复用神器"](#一、函数:Python 代码的 “高效复用神器”)
[1.1 函数是什么?------ 可重复调用的代码片段](#1.1 函数是什么?—— 可重复调用的代码片段)
[1.2 函数的语法格式 ------ 先定义,再使用](#1.2 函数的语法格式 —— 先定义,再使用)
[1.2.1 函数定义语法](#1.2.1 函数定义语法)
[1.2.2 函数调用语法](#1.2.2 函数调用语法)
[1.3 函数参数 ------ 让函数更灵活](#1.3 函数参数 —— 让函数更灵活)
[1.3.1 形参和实参的对应关系](#1.3.1 形参和实参的对应关系)
[1.3.2 参数的灵活用法](#1.3.2 参数的灵活用法)
[1.4 函数返回值 ------ 函数的 "输出"](#1.4 函数返回值 —— 函数的 “输出”)
[1.4.1 返回值的基本用法](#1.4.1 返回值的基本用法)
[1.4.2 返回值的高级特性](#1.4.2 返回值的高级特性)
[1.5 变量作用域 ------ 变量的 "活动范围"](#1.5 变量作用域 —— 变量的 “活动范围”)
[1.5.1 局部变量与全局变量的区别](#1.5.1 局部变量与全局变量的区别)
[1.5.2 修改全局变量](#1.5.2 修改全局变量)
[1.6 函数的进阶用法 ------ 嵌套调用与递归](#1.6 函数的进阶用法 —— 嵌套调用与递归)
[1.6.1 嵌套调用](#1.6.1 嵌套调用)
[1.6.2 递归调用](#1.6.2 递归调用)
[1.7 函数小结](#1.7 函数小结)
[二、列表和元组:Python 中的 "数据容器"](#二、列表和元组:Python 中的 “数据容器”)
[2.1 列表和元组是什么?------ 生活化类比](#2.1 列表和元组是什么?—— 生活化类比)
[2.2 列表的基本操作](#2.2 列表的基本操作)
[2.2.1 创建列表](#2.2.1 创建列表)
[2.2.2 访问列表元素 ------ 下标(索引)操作](#2.2.2 访问列表元素 —— 下标(索引)操作)
[2.2.3 修改列表元素](#2.2.3 修改列表元素)
[2.2.4 列表的长度](#2.2.4 列表的长度)
[2.3 列表的进阶操作 ------ 切片、遍历、增删改查](#2.3 列表的进阶操作 —— 切片、遍历、增删改查)
[2.3.1 切片操作 ------ 批量获取元素](#2.3.1 切片操作 —— 批量获取元素)
[2.3.2 遍历列表 ------ 逐个访问元素](#2.3.2 遍历列表 —— 逐个访问元素)
[2.3.3 新增元素](#2.3.3 新增元素)
[2.3.4 删除元素](#2.3.4 删除元素)
[2.3.5 查找元素](#2.3.5 查找元素)
[2.3.6 连接列表](#2.3.6 连接列表)
[2.4 元组的基本操作](#2.4 元组的基本操作)
[2.4.1 创建元组](#2.4.1 创建元组)
[2.4.2 元组的支持操作](#2.4.2 元组的支持操作)
[2.4.3 元组的特殊场景](#2.4.3 元组的特殊场景)
[2.5 列表和元组的区别与选择](#2.5 列表和元组的区别与选择)
[2.6 列表和元组小结](#2.6 列表和元组小结)
[三、字典:Python 中的 "键值对映射神器"](#三、字典:Python 中的 “键值对映射神器”)
[3.1 字典是什么?------ 键值对的集合](#3.1 字典是什么?—— 键值对的集合)
[3.2 字典的基本操作](#3.2 字典的基本操作)
[3.2.1 创建字典](#3.2.1 创建字典)
[3.2.2 查找字典元素](#3.2.2 查找字典元素)
[3.2.3 新增 / 修改字典元素](#3.2.3 新增 / 修改字典元素)
[3.2.4 删除字典元素](#3.2.4 删除字典元素)
[3.2.5 遍历字典](#3.2.5 遍历字典)
[3.3 字典的键的合法类型](#3.3 字典的键的合法类型)
[3.4 字典的核心特性与应用场景](#3.4 字典的核心特性与应用场景)
[3.5 字典小结](#3.5 字典小结)
[四、文件操作:Python 中的 "数据持久化"](#四、文件操作:Python 中的 “数据持久化”)
[4.1 文件是什么?------ 数据的 "长期仓库"](#4.1 文件是什么?—— 数据的 “长期仓库”)
[4.2 文件路径 ------ 找到文件的 "地址"](#4.2 文件路径 —— 找到文件的 “地址”)
[4.2.1 绝对路径](#4.2.1 绝对路径)
[4.2.2 相对路径](#4.2.2 相对路径)
[4.3 文件操作的核心流程](#4.3 文件操作的核心流程)
[4.3.1 打开文件:open () 函数](#4.3.1 打开文件:open () 函数)
[4.3.2 关闭文件:close () 方法](#4.3.2 关闭文件:close () 方法)
[4.3.3 写文件:write () 方法](#4.3.3 写文件:write () 方法)
[4.3.4 读文件:read ()、readline ()、readlines ()](#4.3.4 读文件:read ()、readline ()、readlines ())
[4.4 中文编码问题 ------ 避坑指南](#4.4 中文编码问题 —— 避坑指南)
[4.4.1 常见中文编码](#4.4.1 常见中文编码)
[4.4.2 编码问题的解决方法](#4.4.2 编码问题的解决方法)
[4.4.3 如何查看文件编码?](#4.4.3 如何查看文件编码?)
[4.5 上下文管理器:自动关闭文件的神器](#4.5 上下文管理器:自动关闭文件的神器)
[4.5.1 语法格式](#4.5.1 语法格式)
[示例:用 with 语句读写文件](#示例:用 with 语句读写文件)
[4.6 文件操作的常见场景示例](#4.6 文件操作的常见场景示例)
[场景 1:读取多行文本并统计行数](#场景 1:读取多行文本并统计行数)
[场景 2:将列表数据写入文件(每行一个元素)](#场景 2:将列表数据写入文件(每行一个元素))
[场景 3:追加内容到文件](#场景 3:追加内容到文件)
[4.7 文件操作小结](#4.7 文件操作小结)
前言
作为编程界的 "全民语言",Python 凭借简洁优雅的语法、强大的生态兼容性,成为数据分析、人工智能、Web 开发、自动化运维等领域的 "香饽饽"。无论是零基础小白入门编程,还是资深开发者提升效率,扎实的 Python 语法基础都是不可或缺的核心能力。
很多新手学习 Python 时,常常陷入 "碎片化知识点堆砌" 的困境 ------ 单独看每个语法都懂,实际应用时却无从下手。本文基于系统的语法体系,从函数、列表元组、字典到文件操作,带你构建 Python 语法知识网。下面就让我们正式开始吧!
一、函数:Python 代码的 "高效复用神器"
在编程过程中,你是否遇到过这样的场景:同样的逻辑代码需要重复写几十遍,修改时还要逐个调整,费时又费力?这时候,函数就能帮你 "化繁为简",成为代码复用的 "利器"。
1.1 函数是什么?------ 可重复调用的代码片段
编程中的函数和数学中的函数有相似之处,但更具实用性。数学中的函数如y = sin x,输入不同的 x 会得到不同的 y;而 Python 中的函数,是一段封装好的、可重复调用的代码片段,能接收输入参数,完成特定逻辑后返回结果。
举个直观的例子:如果我们需要计算 1-100、300-400、1-1000 的和,不使用函数的写法是这样的:
python
# 1. 求 1 - 100 的和
sum = 0
for i in range(1, 101):
sum += i
print(sum)
# 2. 求 300 - 400 的和
sum = 0
for i in range(300, 401):
sum += i
print(sum)
# 3. 求 1 - 1000 的和
sum = 0
for i in range(1, 1001):
sum += i
print(sum)不难发现,这三组代码的核心逻辑完全一致,只是循环的起始和结束值不同。如果需要计算更多区间的和,就需要重复复制代码,不仅冗余,后续修改时还要逐个调整,维护成本极高。
而使用函数封装后,代码会变得简洁高效:
python
# 定义函数:封装求和逻辑
def calcSum(beg, end):
sum = 0
for i in range(beg, end + 1):
sum += i
print(sum)
# 调用函数:传入不同参数即可
calcSum(1, 100) # 计算1-100的和
calcSum(300, 400) # 计算300-400的和
calcSum(1, 1000) # 计算1-1000的和通过函数封装,重复的代码被提取成一个独立模块,调用时只需传入不同参数,大大减少了代码冗余,后续修改逻辑时也只需调整函数内部即可,维护效率翻倍。

1.2 函数的语法格式 ------ 先定义,再使用
函数的使用遵循**"先定义,再调用"** 的原则,就像动漫里释放技能前要先喊招式名字一样,必须先明确函数的功能,才能在需要时调用。
1.2.1 函数定义语法
python
def 函数名(形参列表):
函数体 # 函数要执行的逻辑
return 返回值 # 可选,用于返回函数执行结果
- def:Python 中定义函数的关键字,必须放在函数名前;
- 函数名 :遵循变量命名规则(字母、数字、下划线组成,不能以数字开头),建议见名知义(如
calcSum表示 "计算和");- 形参列表:函数接收的输入参数,多个参数用逗号分隔,可省略(无参数函数);
- 函数体:函数的核心逻辑,必须缩进(通常 4 个空格);
- return:用于返回函数执行结果,可返回单个值或多个值,执行到
return后函数会立即结束。
1.2.2 函数调用语法
python
# 不考虑返回值(仅执行函数逻辑)
函数名(实参列表)
# 考虑返回值(接收函数返回的结果)
返回值变量 = 函数名(实参列表)关键注意点:
- 函数定义后不会自动执行,必须调用才会触发函数体代码;
- 函数必须先定义后调用,否则会报错**
NameError**;- 调用时实参个数需与形参个数匹配,否则会抛出**
TypeError**。
举个反例:未定义就调用函数会报错:
python
# 错误示例:先调用后定义
test3()
def test3():
print('hello')
# 运行结果:NameError: name 'test3' is not defined1.3 函数参数 ------ 让函数更灵活
函数参数是函数的 "输入",通过参数可以让同一个函数处理不同的数据,大大提升函数的灵活性。Python 中的函数参数主要分为形参和实参,两者的关系就像 "签合同":
- 形参:函数定义时括号中的参数,相当于合同中的 "甲方""乙方"(占位符);
- 实参:函数调用时括号中的参数,相当于合同中具体的签约人(实际值)。
1.3.1 形参和实参的对应关系
以之前的求和函数为例:
python
def calcSum(beg, end): # beg、end 是形参(占位符)
sum = 0
for i in range(beg, end + 1):
sum += i
print(sum)
calcSum(1, 100) # 1、100 是实参(实际值)
calcSum(300, 400) # 300、400 是实参调用函数时,实参会赋值给对应的形参:calcSum(1, 100) 等价于 beg=1,end=100,函数内部就会基于这两个值执行计算。
再举个 "签合同" 的例子:
python
def 签合同(甲方, 乙方):
print(f"{甲方}与{乙方}签订房屋买卖合同")
# 调用函数:传入不同实参
签合同('汤老湿', '蔡徐坤')
签合同('汤老湿', '鹿晗')
签合同('汤老湿', '吴磊')这里的 "甲方""乙方" 是形参,而具体的人名是实参,通过更换实参,同一个函数可以处理不同的签约场景。
1.3.2 参数的灵活用法
Python 作为动态类型语言,函数参数有很多灵活特性,和 C++、Java 有明显区别:
(1)无需指定参数类型:同一个函数可以接收不同类型的参数,比如:
python
def printInfo(a):
print(a)
# 传入整数
printInfo(10) # 输出:10
# 传入字符串
printInfo('hello') # 输出:hello
# 传入布尔值
printInfo(True) # 输出:True(2)参数默认值:可以给形参指定默认值,调用时若未传该参数,则使用默认值。注意:带默认值的参数必须放在无默认值参数的后面。
python
# 计算两个数的和,默认不打印调试信息
def add(x, y, debug=False):
if debug:
print(f'调试信息: x={x}, y={y}')
return x + y
# 未传debug参数,使用默认值False
print(add(10, 20)) # 输出:30
# 传入debug=True,打印调试信息
print(add(10, 20, True)) # 输出:调试信息: x=10, y=20 → 30(3)关键字参数:调用函数时,可以通过 "参数名 = 值" 的方式指定实参,无需按照形参顺序传参:
python
def test(x, y):
print(f'x = {x}')
print(f'y = {y}')
# 按顺序传参
test(10, 20) # 输出:x=10, y=20
# 关键字传参(顺序可打乱)
test(y=100, x=200) # 输出:x=200, y=1001.4 函数返回值 ------ 函数的 "输出"
如果说参数是函数的 "输入",那么返回值就是函数的 "输出"。我们可以把函数想象成一个 "工厂":参数是原材料,函数体是加工流程,返回值是最终产品。
1.4.1 返回值的基本用法
之前的求和函数直接在内部打印结果,这种写法不够灵活(比如后续需要将结果保存到文件或网络传输时,无法复用)。更好的做法是用return返回结果,让调用者决定如何处理:
python
# 优化版:返回求和结果,不直接打印
def calcSum(beg, end):
sum = 0
for i in range(beg, end + 1):
sum += i
return sum # 返回计算结果
# 调用函数,接收返回值
result1 = calcSum(1, 100)
print(result1) # 打印结果:5050
# 把结果保存到变量,后续可复用
result2 = calcSum(300, 400)
print(f"300-400的和是:{result2}") # 输出:300-400的和是:35150这种 "逻辑与交互分离" 的写法是实际开发中的常用原则,函数只负责核心计算,调用者负责后续的展示、存储等操作,大大提升了代码的复用性。
1.4.2 返回值的高级特性
(1)多个返回值 :Python 函数支持一次返回多个值,用逗号分隔即可,接收时用多个变量对应:
python
# 返回坐标点的x、y值
def getPoint():
x = 10
y = 20
return x, y # 多个返回值用逗号分隔
# 接收多个返回值
a, b = getPoint()
print(f"x={a}, y={b}") # 输出:x=10, y=20
# 忽略不需要的返回值(用_表示)
_, b = getPoint()
print(f"只关注y值:{b}") # 输出:只关注y值:20(2)多个 return 语句 :函数中可以有多个return语句,执行到任意一个return后函数会立即结束:
python
# 判断一个数是否为奇数
def isOdd(num):
if num % 2 == 0:
return False # 偶数返回False,函数结束
return True # 奇数返回True
print(isOdd(10)) # 输出:False
print(isOdd(11)) # 输出:True1.5 变量作用域 ------ 变量的 "活动范围"
变量就像 "临时工",有自己的 "活动范围",超出范围就会 "失效"。Python 中变量的作用域主要分为两种:
- 局部变量:函数内部定义的变量,仅在函数内部生效,出了函数就无法访问;
- 全局变量:不在任何函数内部定义的变量,在整个程序中都能访问。
1.5.1 局部变量与全局变量的区别
python
# 全局变量:定义在函数外部
x = 20
def test():
# 局部变量:定义在函数内部
x = 10
print(f"函数内部 x = {x}") # 访问局部变量,输出:10
test()
print(f"函数外部 x = {x}") # 访问全局变量,输出:20可以看到,函数内部的x和外部的x是两个不同的变量,只是名字相同,互不影响。
如果函数内部没有定义局部变量,会自动查找全局变量:
python
x = 20
def test():
# 函数内部没有定义x,会查找全局变量x
print(f"x = {x}") # 输出:20
test()1.5.2 修改全局变量
如果想在函数内部修改全局变量的值,需要用global关键字声明,否则 Python 会把该变量当作局部变量:
python
x = 20
def test():
global x # 声明x是全局变量
x = 10 # 修改全局变量的值
print(f"函数内部 x = {x}") # 输出:10
test()
print(f"函数外部 x = {x}") # 输出:10(全局变量已被修改)注意点:
- if、while、for等语句块不会创建新的作用域,块内定义的变量在块外也能访问:
python
for i in range(1, 5):
num = i # 在for循环内定义变量
print(f"循环外部访问num:{num}") # 输出:4(变量有效)1.6 函数的进阶用法 ------ 嵌套调用与递归
1.6.1 嵌套调用
函数内部可以调用其他函数,这就是嵌套调用。嵌套调用的执行顺序是**"先执行内部函数,再回到外部函数继续执行"**。
python
def a():
print("函数a执行")
def b():
print("函数b开始执行")
a() # 嵌套调用函数a
print("函数b执行结束")
def c():
print("函数c开始执行")
b() # 嵌套调用函数b
print("函数c执行结束")
# 调用最外层函数
c()运行结果:
函数c开始执行
函数b开始执行
函数a执行
函数b执行结束
函数c执行结束嵌套调用的本质是 "函数调用栈":每次调用函数时,会在栈中新增一个 "栈帧"(存储函数的局部变量和执行状态),函数执行完毕后栈帧出栈,回到上一层函数继续执行。
1.6.2 递归调用
递归是嵌套调用的特殊情况 ------ 函数调用自身。递归的核心是 "明确初始条件 + 递推公式",就像数学归纳法一样,通过不断缩小问题规模,最终解决问题。
示例:递归计算 5 的阶乘(5! = 5×4×3×2×1)
python
def factor(n):
# 递归结束条件:n=1时返回1
if n == 1:
return 1
# 递推公式:n! = n × (n-1)!
return n * factor(n - 1)
result = factor(5)
print(result) # 输出:120递归的执行流程:
factor(5)→ 5 ×factor(4)factor(4)→ 4 ×factor(3)factor(3)→ 3 ×factor(2)factor(2)→ 2 ×factor(1)factor(1)→ 返回 1(结束递归)- 反向计算:2×1=2 → 3×2=6 → 4×6=24 → 5×24=120
递归的注意事项:
(1)必须有明确的结束条件,否则会导致 "无限递归",触发**RecursionError**:
python
# 错误示例:无结束条件的递归
def factor(n):
return n * factor(n - 1)
factor(5) # 运行结果:RecursionError: maximum recursion depth exceeded(2)递归深度有限制:Python 默认的递归深度约为 1000 层,超过会报错;
(3)递归代码简洁但可读性较差,且执行效率低于循环,实际开发中需谨慎使用(复杂场景建议用循环替代)。
1.7 函数小结
函数是 Python 代码组织的核心,掌握以下三点就能应对大部分场景:
- 函数的定义 :用def关键字,明确形参和返回值;
- 函数的调用 :遵循 "先定义后调用",实参与形参个数匹配;
- 参数传递:灵活运用默认值、关键字参数,提升代码灵活性。
实际开发中,函数的核心价值是 "代码复用" 和 "逻辑封装",合理使用函数能让代码更简洁、易维护。
二、列表和元组:Python 中的 "数据容器"
编程中经常需要批量处理数据,比如存储一个班级的学生姓名、一组商品的价格等。如果用单个变量存储,不仅繁琐,还难以统一处理。这时候,列表和元组就派上用场了 ------ 它们是 Python 中用于存储 "序列型数据" 的 "容器"。
2.1 列表和元组是什么?------ 生活化类比
列表和元组的核心作用是 "批量存储数据",两者的主要区别在于 "是否可修改",用生活化的例子就能轻松理解:
- 列表(list):像 "散装辣条"------ 买完后可以随时打开袋子加辣条、减辣条(数据可修改);
- 元组(tuple):像 "包装辣条"------ 出厂时就固定了数量,不能增减(数据不可修改)。

2.2 列表的基本操作
2.2.1 创建列表
Python 中创建列表有两种方式,推荐使用**[]**(更简洁):
python
# 方式1:使用[]创建列表(推荐)
alist = [] # 创建空列表
num_list = [1, 2, 3, 4, 5] # 创建包含整数的列表
mix_list = [1, 'hello', True, 3.14] # 列表支持不同类型的元素
# 方式2:使用list()函数创建列表
blist = list() # 创建空列表
str_list = list('python') # 从字符串创建列表:['p', 'y', 't', 'h', 'o', 'n']
# 打印列表和类型
print(num_list) # 输出:[1, 2, 3, 4, 5]
print(type(alist)) # 输出:<class 'list'>注意:列表的变量名不要用list(list是 Python 的内置函数,会覆盖原有功能)。
2.2.2 访问列表元素 ------ 下标(索引)操作
列表中的元素按顺序存储,每个元素都有一个唯一的 "下标" (索引),通过下标可以快速访问元素。下标从 0 开始计数,就像排队时的 "序号"(第 1 个人序号为 0,第 2 个人序号为 1,以此类推)。
python
alist = [10, 20, 30, 40, 50]
# 访问下标为0的元素(第一个元素)
print(alist[0]) # 输出:10
# 访问下标为2的元素(第三个元素)
print(alist[2]) # 输出:30
# 下标可以为负数,表示"倒数第n个元素"
print(alist[-1]) # 输出:50(倒数第一个元素)
print(alist[-2]) # 输出:40(倒数第二个元素)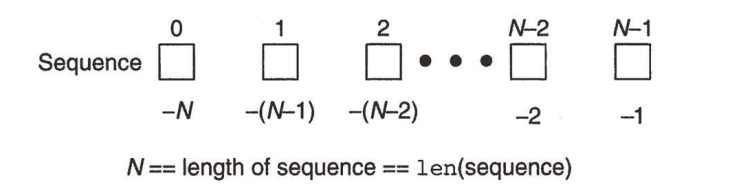
2.2.3 修改列表元素
通过 **"下标赋值"**可以修改列表中的元素:
python
alist = [10, 20, 30, 40, 50]
alist[2] = 300 # 修改下标为2的元素
print(alist) # 输出:[10, 20, 300, 40, 50]2.2.4 列表的长度
使用**len()**函数可以获取列表的元素个数(长度):
python
alist = [10, 20, 30, 40, 50]
print(len(alist)) # 输出:5(列表有5个元素)注意:下标越界会报错
列表的有效下标范围是**[0, len(alist)-1],如果下标超出这个范围,会抛出IndexError**:
python
alist = [10, 20, 30]
print(alist[5]) # 运行结果:IndexError: list index out of range2.3 列表的进阶操作 ------ 切片、遍历、增删改查
2.3.1 切片操作 ------ 批量获取元素
切片是列表的**"批量访问"** 功能,通过[起始下标:结束下标:步长]的格式,可以获取列表中连续或间隔的元素,返回一个新列表。
切片的核心规则:
- 起始下标:默认从 0 开始(可省略);
- 结束下标:默认到列表末尾(可省略);
- 步长:默认 1(表示连续取元素),步长为负数表示反向取元素;
- 切片范围是 "前闭后开" :**[start:end]**包含 start,不包含 end。
示例代码:
python
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 1. 基本切片:获取下标1到3的元素(不包含3)
print(alist[1:3]) # 输出:[2, 3]
# 2. 省略边界:从下标2取到末尾
print(alist[2:]) # 输出:[3, 4, 5, 6, 7, 8, 9, 10]
# 3. 省略起始:从开头取到下标5(不包含5)
print(alist[:5]) # 输出:[1, 2, 3, 4, 5]
# 4. 步长为2:每隔1个元素取1个
print(alist[::2]) # 输出:[1, 3, 5, 7, 9]
# 5. 步长为3:每隔2个元素取1个
print(alist[::3]) # 输出:[1, 4, 7, 10]
# 6. 反向切片:步长为-1(反转列表)
print(alist[::-1]) # 输出:[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
# 7. 反向步长为2:从后往前每隔1个取1个
print(alist[::-2]) # 输出:[10, 8, 6, 4, 2]
# 8. 下标越界不报错:仅返回有效元素
print(alist[100:200]) # 输出:[](空列表)切片操作不会修改原列表,而是返回一个新列表,这是列表切片的重要特性。
2.3.2 遍历列表 ------ 逐个访问元素
遍历是指**"逐个访问列表中的元素"**,Python 中常用三种遍历方式:
(1)for 循环直接遍历(推荐):
python
alist = [10, 20, 30, 40]
for elem in alist:
print(elem) # 输出:10 → 20 → 30 → 40(2)for 循环 + 下标遍历:
python
alist = [10, 20, 30, 40]
for i in range(len(alist)):
print(f"下标{i}:{alist[i]}")
# 输出:
# 下标0:10
# 下标1:20
# 下标2:30
# 下标3:40(3)while 循环遍历:
python
alist = [10, 20, 30, 40]
i = 0
while i < len(alist):
print(alist[i])
i += 1 # 手动更新下标
# 输出:10 → 20 → 30 → 402.3.3 新增元素
列表支持在任意位置新增元素,常用两种方法:
(1)append ():在列表末尾新增元素(尾插):
python
alist = [10, 20, 30]
alist.append(40) # 尾插40
alist.append('hello') # 尾插字符串
print(alist) # 输出:[10, 20, 30, 40, 'hello'](2)insert ():在指定下标位置插入元素:
python
alist = [10, 20, 30]
# 在下表1的位置插入25(原来的元素往后移)
alist.insert(1, 25)
print(alist) # 输出:[10, 25, 20, 30]2.3.4 删除元素
列表删除元素有三种常用方法,适用于不同场景:
(1)pop ():删除指定下标元素(默认删除最后一个):
python
alist = [10, 20, 30, 40]
alist.pop() # 删除最后一个元素
print(alist) # 输出:[10, 20, 30]
alist.pop(1) # 删除下标1的元素(20)
print(alist) # 输出:[10, 30](2)remove ():按值删除元素(删除第一个匹配的值):
python
alist = [10, 20, 30, 20]
alist.remove(20) # 删除第一个20
print(alist) # 输出:[10, 30, 20](3)del:按下标删除(或删除整个列表):
python
alist = [10, 20, 30]
del alist[1] # 删除下标1的元素
print(alist) # 输出:[10, 30]
del alist # 删除整个列表(后续无法访问alist)2.3.5 查找元素
判断元素是否在列表中,或查找元素的下标:
(1)in 操作符:判断元素是否存在(返回布尔值):
python
alist = [10, 20, 30, 40]
print(20 in alist) # 输出:True
print(50 in alist) # 输出:False(2)index ():查找元素的下标(元素不存在会报错):
python
alist = [10, 20, 30, 40]
print(alist.index(30)) # 输出:2(下标为2)
print(alist.index(50)) # 运行结果:ValueError: 50 is not in list2.3.6 连接列表
将两个列表合并成一个,有两种方法:
(1)+ 运算符:生成新列表(不修改原列表):
python
alist = [1, 2, 3]
blist = [4, 5, 6]
clist = alist + blist # 合并成新列表
print(clist) # 输出:[1, 2, 3, 4, 5, 6]
print(alist) # 输出:[1, 2, 3](原列表不变)(2)extend ():将一个列表拼接到另一个列表末尾(修改原列表):
python
alist = [1, 2, 3]
blist = [4, 5, 6]
alist.extend(blist) # 把blist拼接到alist末尾
print(alist) # 输出:[1, 2, 3, 4, 5, 6]
print(blist) # 输出:[4, 5, 6](blist不变)2.4 元组的基本操作
元组和列表功能类似,但元组的元素不可修改,创建后无法新增、删除或修改元素。
2.4.1 创建元组
元组用**()**创建,注意创建单个元素的元组时,需要在元素后加逗号(否则会被当作普通变量):
python
# 方式1:使用()创建元组
atuple = () # 空元组
num_tuple = (1, 2, 3, 4) # 包含多个元素的元组
single_tuple = (10,) # 单个元素的元组(必须加逗号)
# 方式2:使用tuple()函数创建
btuple = tuple() # 空元组
str_tuple = tuple('python') # 从字符串创建:('p', 'y', 't', 'h', 'o', 'n')
# 打印元组和类型
print(num_tuple) # 输出:(1, 2, 3, 4)
print(type(atuple)) # 输出:<class 'tuple'>2.4.2 元组的支持操作
元组支持**"读操作"** ,不支持 "写操作":
- 支持的操作:访问下标、切片、遍历、in 判断、index ()、+ 连接;
- 不支持的操作:append ()、insert ()、pop ()、remove ()、修改元素。
示例:元组的合法操作
python
atuple = (10, 20, 30, 40)
# 访问下标
print(atuple[2]) # 输出:30
# 切片
print(atuple[1:3]) # 输出:(20, 30)
# 遍历
for elem in atuple:
print(elem) # 输出:10 → 20 → 30 → 40
# 判断元素是否存在
print(20 in atuple) # 输出:True
# 连接元组
btuple = (50, 60)
print(atuple + btuple) # 输出:(10, 20, 30, 40, 50, 60)示例:元组的非法操作(会报错)
python
atuple = (10, 20, 30)
atuple[1] = 200 # 错误:修改元素
atuple.append(40) # 错误:新增元素
atuple.pop() # 错误:删除元素2.4.3 元组的特殊场景
(1)函数返回多个值时,默认是元组:
python
def getPoint():
return 10, 20 # 看似返回两个值,实际是元组
result = getPoint()
print(result) # 输出:(10, 20)
print(type(result)) # 输出:<class 'tuple'>(2)元组可以作为字典的键(列表不行) :字典的键要求是 "可哈希对象"(不可变类型),元组不可变所以可以作为键,而列表可变不能作为键:
python
# 元组作为字典键(合法)
dict1 = {(1, 2): 'a', (3, 4): 'b'}
print(dict1[(1, 2)]) # 输出:'a'
# 列表作为字典键(非法)
dict2 = {[1, 2]: 'a'} # 运行结果:TypeError: unhashable type: 'list'2.5 列表和元组的区别与选择
| 特性 | 列表(list) | 元组(tuple) |
|---|---|---|
| 定义符号 | ( ) | |
| 元素是否可变 | 可修改(增删改) | 不可修改 |
| 适用场景 | 数据需要动态调整 | 数据固定不变 |
| 能否作为字典键 | 不能 | 能(元素为不可变类型) |
| 执行效率 | 较低 | 较高(不可变类型更高效) |
选择原则:
- 如果数据需要动态调整 (比如添加、删除元素),用列表;
- 如果数据固定不变 (比如存储坐标、配置参数),用元组(更安全、效率更高)。
2.6 列表和元组小结
列表和元组是 Python 中最常用的序列型数据结构,核心操作是 "下标访问" 和 "切片"。记住 "可变用列表,不可变用元组" 的原则,就能在实际开发中灵活选择。
三、字典:Python 中的 "键值对映射神器"
在生活中,我们经常会遇到 "通过一个唯一标识查找对应信息" 的场景 ------ 比如通过学号查找学生信息、通过身份证号查找个人档案。Python 中的**字典(dict)**就是为这种 "键值对映射" 场景设计的数据结构,能实现高效的查找和修改。
3.1 字典是什么?------ 键值对的集合
字典是一种无序的 "键值对(key-value)" 集合,每个键(key)对应一个值(value),通过键可以快速找到对应的值,就像查字典一样:拼音(键)对应汉字(值),通过拼音能快速找到汉字。
生活案例:学校的学生信息管理,学号是唯一的 "键",学生的姓名、年龄等信息是 "值":
- 键(key):学号 101;值(value):{'name': ' 张三 ', 'age': 18}
- 键(key):学号 102;值(value):{'name': ' 李四 ', 'age': 19}
3.2 字典的基本操作
3.2.1 创建字典
Python 中创建字典有两种方式,推荐使用{}(更简洁):
python
# 方式1:使用{}创建字典(推荐)
dict1 = {} # 空字典
student = {
'id': 101,
'name': '张三',
'age': 18,
'score': 90
} # 包含多个键值对的字典
# 方式2:使用dict()函数创建
dict2 = dict() # 空字典
student2 = dict(id=102, name='李四', age=19) # 关键字参数创建
# 打印字典和类型
print(student) # 输出:{'id': 101, 'name': '张三', 'age': 18, 'score': 90}
print(type(dict1)) # 输出:<class 'dict'>字典的键值对格式:key: value,多个键值对用逗号分隔,冒号后面建议加一个空格(代码更规范)。
3.2.2 查找字典元素
字典的查找是通过 "键" 实现的,有两种常用方式:
(1) 访问:通过键获取值(键不存在会报错):
python
student = {'id': 101, 'name': '张三', 'age': 18}
print(student['name']) # 输出:'张三'
print(student['score']) # 运行结果:KeyError: 'score'(键不存在)(2)in 操作符:判断键是否存在(返回布尔值):
python
student = {'id': 101, 'name': '张三', 'age': 18}
print('name' in student) # 输出:True
print('score' in student) # 输出:False3.2.3 新增 / 修改字典元素
字典的新增和修改操作语法一致,核心是 "键是否存在":
- 键不存在:赋值操作是 "新增键值对";
- 键已存在:赋值操作是 "修改键对应的值"。
python
student = {'id': 101, 'name': '张三', 'age': 18}
# 1. 新增键值对(score不存在)
student['score'] = 90
print(student) # 输出:{'id': 101, 'name': '张三', 'age': 18, 'score': 90}
# 2. 修改值(age已存在)
student['age'] = 19
print(student) # 输出:{'id': 101, 'name': '张三', 'age': 19, 'score': 90}3.2.4 删除字典元素
通过**pop()**方法根据键删除键值对:
python
student = {'id': 101, 'name': '张三', 'age': 18, 'score': 90}
student.pop('score') # 删除键为'score'的键值对
print(student) # 输出:{'id': 101, 'name': '张三', 'age': 18}
# 删除不存在的键会报错
student.pop('gender') # 运行结果:KeyError: 'gender'3.2.5 遍历字典
字典是无序的,遍历的核心是 "遍历键""遍历值" 或 "遍历键值对":
(1)遍历键(默认遍历方式):
python
student = {'id': 101, 'name': '张三', 'age': 18}
for key in student:
print(f"键:{key},值:{student[key]}")
# 输出:
# 键:id,值:101
# 键:name,值:张三
# 键:age,值:18(2)遍历键值对(items () 方法):
python
student = {'id': 101, 'name': '张三', 'age': 18}
for key, value in student.items():
print(f"键:{key},值:{value}")
# 输出和上面一致(3)遍历值(values () 方法):
python
student = {'id': 101, 'name': '张三', 'age': 18}
for value in student.values():
print(value) # 输出:101 → 张三 → 18(4)遍历键(keys () 方法):
python
student = {'id': 101, 'name': '张三', 'age': 18}
for key in student.keys():
print(key) # 输出:id → name → age3.3 字典的键的合法类型
不是所有类型都能作为字典的键,字典的键必须是 "可哈希对象"(即不可变类型)。因为字典本质是哈希表,键的哈希值用于快速查找,若键是可变类型,哈希值会变化,导致查找失败。
合法的键类型(不可变类型):
- 整数(int) 、浮点数(float);
- 字符串(str);
- 布尔值(bool);
- 元组(tuple,元素需为不可变类型)。
python
# 合法示例:整数、字符串、元组作为键
dict1 = {
101: '张三',
'id': 102,
(1, 2): 'a'
}
print(dict1) # 输出:{101: '张三', 'id': 102, (1, 2): 'a'}非法的键类型(可变类型):
- 列表(list);
- 字典(dict);
- 集合(set)。
python
# 非法示例:列表作为键
dict2 = {[1, 2]: 'a'} # 运行结果:TypeError: unhashable type: 'list'
# 非法示例:字典作为键
dict3 = {{'id': 101}: '张三'} # 运行结果:TypeError: unhashable type: 'dict'3.4 字典的核心特性与应用场景
核心特性:
- 无序性:Python 3.7 之前字典是无序的,3.7 之后保证插入顺序,但遍历仍不依赖顺序;
- 唯一性:键是唯一的,若重复赋值,后面的值会覆盖前面的值;
- 高效查找:通过键查找值的时间复杂度是 O (1),比列表遍历(O (n))高效得多。
应用场景:
- 存储和管理具有唯一标识的数据(如用户信息、配置参数);
- 快速查找和修改数据(如缓存数据、映射关系)。
示例:用字典存储多个用户信息
python
# 字典嵌套:字典的值可以是字典
users = {
101: {'name': '张三', 'age': 18, 'score': 90},
102: {'name': '李四', 'age': 19, 'score': 85},
103: {'name': '王五', 'age': 18, 'score': 95}
}
# 查找学号102的用户姓名
print(users[102]['name']) # 输出:'李四'
# 修改学号103的分数
users[103]['score'] = 98
print(users[103]) # 输出:{'name': '王五', 'age': 18, 'score': 98}3.5 字典小结
字典是 Python 中用于 "键值对映射" 的核心数据结构,所有操作都围绕 "键" 展开。记住 "键必须是不可变类型" 和 "高效查找" 这两个核心点,就能在实际开发中灵活运用字典解决问题。
四、文件操作:Python 中的 "数据持久化"
变量存储的数据在程序重启或主机重启后会丢失,要想让数据长期保存,就需要将数据存储到文件中(持久化存储)。Python 提供了简洁的文件操作接口,支持读写文本文件、处理中文编码等常见需求。
4.1 文件是什么?------ 数据的 "长期仓库"
文件是存储在硬盘上的数据流,通过文件名和路径唯一标识。常见的文件类型包括:
- 文本文件(.txt、.py):存储字符数据,人类可读;
- 二进制文件(.jpg、.mp4、.exe):存储字节数据,需特定程序解析。
本文重点讲解文本文件的操作,这是 Python 开发中最常用的文件类型。
4.2 文件路径 ------ 找到文件的 "地址"
要操作文件,首先需要确定文件的位置,这就是文件路径。文件路径分为两种:
4.2.1 绝对路径
从盘符(Windows)或根目录(Linux/Mac)开始的完整路径,比如:
- Windows :
D:/test.txt(推荐用 /,避免 \ 转义问题);- Linux/Mac :
/home/user/test.txt。
绝对路径的优点是 "定位准确,不依赖当前目录",适合新手使用,不容易出错。
4.2.2 相对路径
相对于当前程序运行目录的路径,比如:
- test.txt:当前目录下的文件;
- ./data/test.txt:当前目录下的 data 文件夹中的文件;
- ../test.txt:上级目录下的文件。
相对路径的优点是 "路径简短",但依赖当前目录,容易出错,新手建议优先使用绝对路径。
路径分隔符
- Windows:支持
\和/(推荐用/,避免\需要转义成\\);- Linux/Mac:仅支持
/。
4.3 文件操作的核心流程
文件操作的核心流程是 "打开文件 → 读写文件 → 关闭文件",就像 "打开冰箱 → 取放食物 → 关闭冰箱" 一样,必须遵循这个顺序。
4.3.1 打开文件:open () 函数
使用 Python 内置的**open()**函数打开文件,语法如下:
python
file_object = open(file_path, mode, encoding=None)
- file_path:文件路径(绝对路径或相对路径);
- mode:打开模式(核心参数,见下表);
- encoding:文件编码(处理中文时需指定,如
utf-8、gbk);- 返回值:文件对象,后续的读写操作通过该对象实现。
常见打开模式:
| 模式 | 说明 |
|---|---|
| 'r' | 只读模式(默认),文件不存在则报错 |
| 'w' | 只写模式,文件不存在则创建,存在则清空原有内容 |
| 'a' | 追加模式,文件不存在则创建,存在则在末尾追加内容 |
| 'r+' | 读写模式,文件不存在则报错 |
| 'w+' | 读写模式,文件不存在则创建,存在则清空 |
| 'a+' | 读写模式,文件不存在则创建,存在则在末尾追加 |
示例:以只读模式打开文件
python
# 绝对路径打开文件(Windows)
f = open('D:/test.txt', 'r', encoding='utf-8')
# 绝对路径打开文件(Linux/Mac)
# f = open('/home/user/test.txt', 'r', encoding='utf-8')打开失败的常见原因:
- 文件路径错误(如拼写错误、盘符错误);
- 文件不存在('r' 模式下);
- 权限不足(如试图写入只读文件)。
打开失败会抛出**FileNotFoundError**等异常,需注意捕获。
4.3.2 关闭文件:close () 方法
文件使用完毕后必须关闭,否则会导致资源泄露(程序能同时打开的文件个数有限)。使用文件对象的**close()**方法关闭文件:
python
f = open('D:/test.txt', 'r', encoding='utf-8')
# 读写操作...
f.close() # 关闭文件为什么必须关闭文件?
- 系统资源有限:一个程序能同时打开的文件个数有上限,不关闭会导致无法打开新文件;
- 数据缓存问题:写入文件的数据可能存在缓存中,关闭文件时会强制刷新缓存,确保数据写入硬盘。
反例:不关闭文件导致报错
python
flist = []
count = 0
while True:
# 不断打开文件,不关闭
f = open('D:/test.txt', 'r', encoding='utf-8')
flist.append(f)
count += 1
print(f'已打开{count}个文件')
# 运行结果:OSError: [Errno 24] Too many open files4.3.3 写文件:write () 方法
写文件需使用**"写模式"('w'、'a'、'w+'、'a+'),通过文件对象的write()**方法写入内容。
示例 1:覆盖写文件('w' 模式)
python
# 以覆盖模式打开文件,不存在则创建
f = open('D:/test.txt', 'w', encoding='utf-8')
f.write('Hello Python!') # 写入字符串
f.write('\n这是第二行内容') # \n表示换行
f.close() # 关闭文件,确保数据写入运行后,文件内容为:
python
Hello Python!
这是第二行内容示例 2:追加写文件('a' 模式)
python
# 以追加模式打开文件
f = open('D:/test.txt', 'a', encoding='utf-8')
f.write('\n这是追加的内容')
f.close()运行后,文件内容为:
Hello Python!
这是第二行内容
这是追加的内容注意事项:
- **'w'**模式会清空原有内容,使用时需谨慎;
- 写入的内容必须是字符串,若为其他类型(如整数、列表),需先转换为字符串;
- 未关闭文件时,写入的数据可能在缓存中,关闭文件后才会写入硬盘。
4.3.4 读文件:read ()、readline ()、readlines ()
读文件需使用**"读模式"**('r'、'r+'、'w+'、'a+'),常用三种读取方法:
(1) read (size):读取指定长度的字符(默认读取全部):
python
f = open('D:/test.txt', 'r', encoding='utf-8')
# 读取前5个字符
content1 = f.read(5)
print(content1) # 输出:'Hello'
# 读取剩余所有字符
content2 = f.read()
print(content2) # 输出:' Python!\n这是第二行内容\n这是追加的内容'
f.close()(2) readline ():读取一行内容(包括换行符):
python
f = open('D:/test.txt', 'r', encoding='utf-8')
# 读取第一行
line1 = f.readline()
print(line1) # 输出:'Hello Python!\n'
# 读取第二行
line2 = f.readline()
print(line2) # 输出:'这是第二行内容\n'
f.close()(3) readlines ():读取所有行,返回列表(每行作为一个元素):
python
f = open('D:/test.txt', 'r', encoding='utf-8')
lines = f.readlines()
print(lines) # 输出:['Hello Python!\n', '这是第二行内容\n', '这是追加的内容']
f.close()
# 遍历列表,去除换行符
for line in lines:
print(line.strip()) # strip()去除首尾空白字符(包括\n)(4) for 循环遍历文件(推荐,内存高效) :对于大文件,**readlines()**会将所有内容加载到内存,效率较低。推荐使用 for 循环逐行读取,内存占用小:
python
f = open('D:/test.txt', 'r', encoding='utf-8')
for line in f:
print(line.strip()) # 逐行打印,去除换行符
f.close()4.4 中文编码问题 ------ 避坑指南
处理中文文件时,最容易遇到的问题是 "编码不匹配",导致读取乱码或写入失败。核心原则是 "文件编码与读取编码一致"。

4.4.1 常见中文编码
- UTF-8:国际通用编码,支持所有语言,推荐使用;
- GBK:中文专用编码,支持简体和繁体中文,Windows 系统默认的中文编码;
- GB2312:GBK 的子集,仅支持简体中文。
4.4.2 编码问题的解决方法
写入中文时,指定编码为 utf-8:
python
f = open('D:/test.txt', 'w', encoding='utf-8')
f.write('你好,Python!')
f.close()
- 读取中文文件时,明确文件的编码 :如果文件是用 UTF-8 编码保存的,读取时必须指定encoding='utf-8';如果是 GBK 编码,需指定encoding='gbk'。
示例:读取 UTF-8 编码的中文文件
python
f = open('D:/test.txt', 'r', encoding='utf-8')
content = f.read()
print(content) # 输出:'你好,Python!'
f.close()常见错误:编码不匹配
python
# 文件是UTF-8编码,读取时用GBK编码
f = open('D:/test.txt', 'r', encoding='gbk')
content = f.read() # 运行结果:UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 0: illegal multibyte sequence4.4.3 如何查看文件编码?
用记事本打开文件 → 点击 "文件"→"另存为"→ 查看 "编码" 选项(ANSI 对应 GBK,UTF-8 对应 UTF-8);
4.5 上下文管理器:自动关闭文件的神器
手动关闭文件容易忘记,Python 提供了 "上下文管理器"(with语句),能自动关闭文件,即使发生异常也能保证文件关闭,是实际开发中的推荐用法。
4.5.1 语法格式
python
with open(file_path, mode, encoding=None) as file_object:
# 读写操作(缩进块内)
# 代码执行完毕后,自动关闭文件示例:用 with 语句读写文件
python
# 写文件
with open('D:/test.txt', 'w', encoding='utf-8') as f:
f.write('你好,Python!')
# 代码块结束,自动关闭文件
# 读文件
with open('D:/test.txt', 'r', encoding='utf-8') as f:
content = f.read()
print(content) # 输出:'你好,Python!'
# 自动关闭文件 with语句的优势:
- 无需手动调用close(),简化代码;
- 异常安全:即使读写过程中发生异常,也会自动关闭文件;
- 代码更简洁、易维护。
4.6 文件操作的常见场景示例
场景 1:读取多行文本并统计行数
python
# 统计文件的行数
line_count = 0
with open('D:/test.txt', 'r', encoding='utf-8') as f:
for line in f:
line_count += 1
print(f"文件共有{line_count}行")场景 2:将列表数据写入文件(每行一个元素)
python
# 列表数据
fruits = ['苹果', '香蕉', '橙子', '葡萄']
# 写入文件
with open('D:/fruits.txt', 'w', encoding='utf-8') as f:
for fruit in fruits:
f.write(fruit + '\n') # 每行一个元素,加换行符场景 3:追加内容到文件
python
# 追加日志信息
import datetime # 导入时间模块
log_info = f"{datetime.datetime.now()} - 程序运行正常\n"
with open('D:/log.txt', 'a', encoding='utf-8') as f:
f.write(log_info)4.7 文件操作小结
文件操作是 Python 数据持久化的核心,掌握以下关键点就能应对大部分场景:
- 核心流程 :打开 → 读写 → 关闭(推荐用
with语句自动关闭);- 打开模式:'r' 只读、'w' 覆盖写、'a' 追加写;
- 中文编码 :写入时用
utf-8,读取时与文件编码一致;- 路径选择:新手优先使用绝对路径,避免路径错误。
总结
本文系统讲解了 Python 语法的四大核心模块 ------ 函数、列表元组、字典、文件操作,这些知识点是 Python 开发的 "基石",无论后续从事数据分析、Web 开发还是人工智能,都离不开这些基础。
Python 语法基础的学习就像盖房子,只有把地基打牢,后续才能搭建更复杂的系统。希望本文能帮助你轻松掌握 Python 语法基础,为后续进阶学习铺平道路!如果在学习过程中遇到问题,欢迎在评论区留言交流~