数据挖掘06
1.卷积神经网络
卷积神经网络(Convolutional Neural Network,简称 CNN)是一种专门用于处理具有网格结构数据的深度学习模型,
2.传统神经网络不具备不变性。
(1)什么是"不变性"?
在模式识别中,不变性指的是:当输入数据发生某种变换(如平移、旋转、缩放、光照变化等)时,模型的输出(如分类结果)保持不变。
例如:
一张猫的图片向左移动几个像素,模型仍应识别为"猫" → 平移不变性
(2)传统全连接神经网络为什么缺乏不变性?
1)全连接结构:每个输入像素(如图像中的每个像素点)都与下一层的神经元单独连接,权重独立。
2)没有空间结构感知:它把图像当作一维向量处理,完全忽略了像素之间的空间局部关系。
3)对位置敏感:如果目标物体在图像中移动了,输入向量就完全不同,网络可能无法识别。
3.卷积神经网络的组成
(1)卷积层(Convolutional Layer)
(2)池化层(Pooling Layer)
(3)激活函数(Activation Function)
(4)关键要素
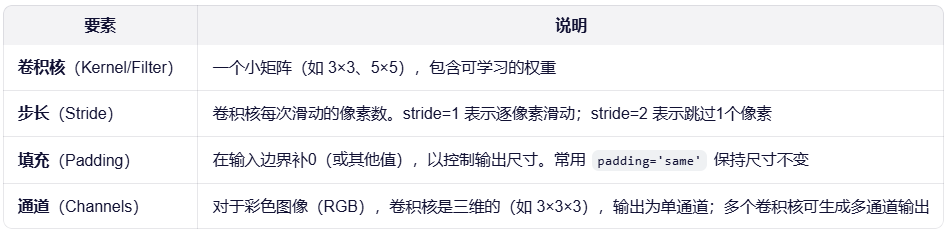
(5)卷积操作
对应点乘再求和,得到一个新值。
有单通道和双通道。
先 举个单通道的例子:
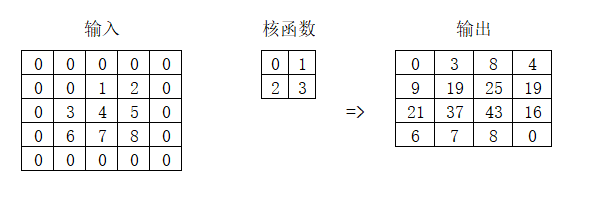
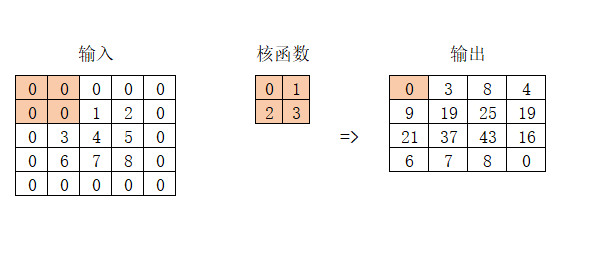
输出矩阵左上角的元素 0 = 0×0+ 0×1 + 0×2 + 0×3
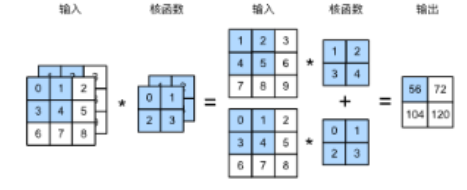
算法是一样的,多通道就是要对每个通道点乘求和,只不过多了一步把各个通道的结果相加。
再举个双通道的例子:
(4)卷积输出尺寸计算公式:

如果卷积核不是正方形,可分别对高和宽计算。
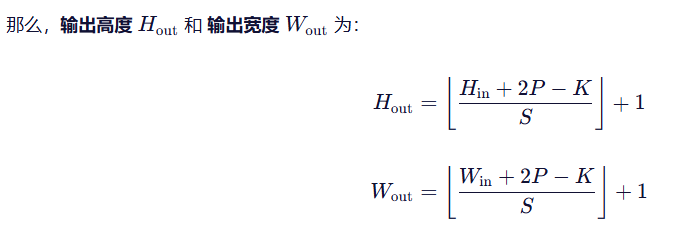
(备注:如果结果不是整数,通常向下取整(floor),表示无法完整滑动时丢弃边缘)
总结:
(输入 + 2×padding − 卷积核) ÷ 步长,向下取整再加1
(5)怎么理解卷积输出尺寸?
1)举个例子

2)为什么是 "−K"?
因为卷积核必须完全落在有效区域内。
比如有 5 个位置,但一个 3 单位宽的窗口只能从位置 0、1、2 开始,否则会"伸出边界"。
4.通过例题加深理解
(1)例题1单选
题目:在卷积神经网络(CNN)中,下列关于卷积操作的描述,错误的是哪一项?
A. 卷积操作可有效提取图像的局部特征
B. 卷积核的权重在网络训练过程中保持不变
C. 通过调整步长(stride)可影响输出特征图的尺寸
D. 填充(padding)操作可避免特征图尺寸过快减小
答案:B
理由:
在训练过程中,卷积核的权重是可学习参数,会通过反向传播和优化算法(如SGD、Adam)不断更新。如果权重"保持不变",模型就无法学习任何特征,完全失去意义。
(2)例题2单选
题目:在卷积神经网络(CNN)中,下列哪一项因素不会直接影响卷积层输出特征图的尺寸?
A. 卷积核大小(Kernel size)
B. 步长(Stride)
C. 激活函数的类型(Activation function)
D. 填充的大小(Padding)
答案:C
理由:
因为它不改变特征图的空间尺寸,只是对每个像素值做非线性变换。
(3)例题3多选

答案:ABCE
理由:偏差是由损失函数来衡量的,优化器是根据这个偏差进行参数调整的工具。优化器并不估计偏差,所以D错误。
(4)例题4多选

答案:ABC
理由:
单层神经网络可以表示非线性,只要使用非线性激活函数(如Sigmoid、ReLU)。
(5)例题5单选
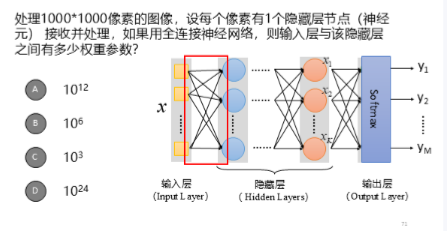
答案:A
理由:
每个像素对应一个输入神经元 → 输入层有 10⁶ 个神经元
每个像素有 1 个隐藏层节点接收并处理 → 隐藏层有 10⁶ 个神经元
全连接结构:每个输入神经元都连接到每个隐藏层神经元
那么就有:
权重数=输入层神经元数×隐藏层神经元数
所以选A
(6)例题6多选

答案:AC
理由:
想象你有一张大信封(代表输入图像),你要在上面贴很多小邮票(代表卷积核)来"盖章认证"每一个区域。
每张贴上的邮票必须完全落在信封上(这是标准卷积,不越界);
你从左到右、从上到下移动邮票,每次移动一小步(比如1格);
信封中间的区域会被很多邮票覆盖(比如某个中心点,可能出现在几十张贴纸的中间);
但信封最边缘的一圈(比如最左边一列、最上一行)
只有当邮票刚好靠边时才能盖到,
所以只被盖1次或2次,甚至某些角落只被盖1次!
结果:边缘信息"认证不足",容易被忽略!
A. 对图像边缘进行扩充(比如用白色填充)
相当于:把信封四周加一圈白纸边(像相框一样)!
原来的边缘像素现在变成了"新信封"的内圈,有效,A对
B. 使用更大的邮票(更大的卷积核)
相当于 邮票变大了(比如从3×3变成7×7)!
问题更严重了!因为大邮票更难贴到角落;所以B错
C. 使用更小的邮票(比如1×1或3×3)
小邮票更容易贴到边缘,确实能多盖几次边缘。
所以C对
D. 每次移动邮票的步子更大(比如跳2格)
相当于 邮票跳着走!
很多地方直接跳过,边缘更可能被漏掉;D错
(7)例题7单选

答案:A
(8)例题8多选

答案:ABCD
5.池化
(1)定义
池化(Pooling)是卷积神经网络(CNN)中一种重要的下采样(downsampling)操作。
(2)目的
1)降维:减小特征图尺寸,节省计算资源。
2)防止过拟合:通过丢弃部分细节信息,提升泛化能力。
3)增强平移不变性:即使目标在图像中轻微移动,池化后的结果变化不大。
4)突出主要特征:保留最显著的响应(如最大值),抑制噪声。
(3)常见池化类型
1)最大池化(Max Pooling)
在每个局部窗口中取最大值作为输出。
2)平均池化(Average Pooling)
在窗口内取平均值。
(4)池化的参数
和卷积类似,池化也有:
1)池化窗口大小(pool size):如 2×2
2)步长(stride):通常等于窗口大小(如 stride=2 表示不重叠滑动)
3)填充(padding):较少使用,但某些框架支持
不同的是:
池化没有可学习参数!它是一个固定的、确定性的操作。