**
数据挖掘08------基于统计模型的序列数据挖掘
**
1.序列数据挖掘方法分类
(1)模式匹配
把未知量伸长或者缩短到参考模式的长度。
然后使用动态规划方法把被比较的数据扭曲或者弯折,时期特征与模型特征对齐。
比如:DTW
(2)统计学习方法
对时间序列结构建立统计模型
比如:HMM 、CRF
(3)神经网络
模拟大脑在处理时间序列信息和工作记忆时所依赖的核心原理
比如:RNN、 LSTM 、 Transformer
2.隐马尔可夫模型
(1)定义
**隐马尔可夫模型(Hidden Markov Model, HMM)**是一种经典的概率图模型,用于建模含有隐藏状态的时序随机过程。
(2)核心思想:看得见的输出,看不见的状态
(3)HMM 的关键假设是:
系统的真实状态(隐藏状态)无法直接观测,但每个状态会以一定概率生成一个可观测的输出(观测值)。
下一状态只依赖于当前状态。
(4)举个例子:"天气与冰淇淋"
隐藏状态(真实天气):晴天(Sunny)、雨天(Rainy)------你不知道每天具体是什么天气。
观测值(你能看到的):每天朋友吃 1、2 或 3 个冰淇淋。
问题:根据过去一周他吃的冰淇淋数量,推断最可能的天气序列。
这就是HMM模型要做的事。
(5)单选题
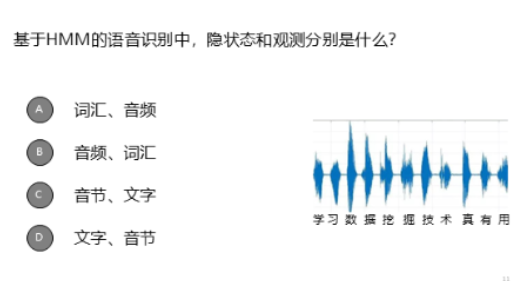
答案:A
3.知识抽取中的分词任务
将连续的字符序列切分成有意义的词语单元(tokens)
方法:
基于词典、基于统计模型、工具库( Jieba、THULAC、HanLP、LTP、PKU分词器)、深度学习

答案:AB
解释:
A很容易理解。
B里指的是词典中存在重叠词,比如:
"直" 是副词(AD)
"直达" 是动词(VV)
当遇到"直达"时,系统可能在"直"和"直达"之间产生歧义:
切成 "直", "达" 还是 "直达"?
这就是典型的切分歧义(ambiguity in segmentation),尤其是在最大匹配法中容易出现。
D错误。
分词结果高度依赖词典规模:
词典越大,覆盖的词汇越多,越不容易漏掉词语;
词典小 → 容易将真实词切错(如"中国银行"变成"中国"+"银行"没问题,但如果词典没有"中国银行",可能切错);
词典过大 → 可能引入噪声或歧义(如上面提到的"直" vs "直达")。
所以,分词结果与词典规模密切相关。
4.基于HMM的分词方法
(1)两个核心部分:
1)观测序列(Observation):输入的汉字序列(如 "我爱自然语言处理")
2)隐状态序列(Hidden States):每个字对应的分词标签(通常采用 BIES 标注体系)
BIES 标签说明:
B : Begin,词的开始
I :Inside,词的中间
E : End,词的结束
S : Single,单字成词
例子:
句子:"我爱自然语言处理"
正确标签:S S B E B E B E
(2)通过以下概率进行推断:
1)初始状态概率 :句子开头是 B/I/E/S 的概率
2)状态转移概率 :标签之间的转移概率,如 P(E → B)、P(B → I) 等
3)观测发射概率:某个标签下生成某个字的概率,如 P("自" | B),由隐状态B生成汉字 自 的概率。
多选题,加深理解:
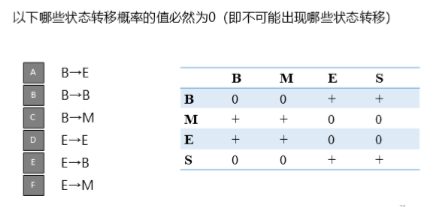
答案:BDF
解释:
B错误:
在 BIES 中,B 只能接 M 或 E,不能接另一个 B。
因为一旦一个词开始(B),它必须继续为 M 或结束为 E。
E错误:
因为 E 表示一个词的结尾,下一个字必须是新词的开始(B)或单字(S),不能是另一个词的结尾(E)。
F错误:
因为 M 是词的中间,只能出现在一个多字词的中间。
但 M 前面必须是 B 或 M,后面是 M 或 E。
不能直接从 E → M,因为 E 是词的结尾,下一个字要么是 B(新词开始),要么是 S(单字词)。
所以 E → M 是非法的。