前篇文章已经介绍了评判模型critic,引出了优势函数A(a,s)、价值函数V(s),并且我们知道一个好的critic模型给出的优势函数应该尽可能做到接近于reward的累计G'减去当前状态的价值函数V(s)。
但是上述例子成立的前提是actor每进行一个action,就可以立刻得到一个不为零的reward,但是在某些情况下,进行action以后是并不能立刻得到reward的,或者reward为0,该种情况称为sparse reward。例如围棋游戏,actor就是棋手,action就是落子,但是单独落一颗子未必能很快的对局势造成有利或者不利影响,所以就很难给出合适的reward,这种情况下reward往往为0;只有在游戏结束判定了胜负以后,才能够得到reward。
为了解决这种问题,提出了reward shaping的思想,即在原来的reward的基础上添加别的reward,引导actor做出action
训练AI进行FPS游戏是一个很好的说明reward shaping的概念。如果在不做reward shaping的情况下,对于actor来说只有击杀对手才能得分;但显然击杀对手的过程中要涉及到很多复杂的动作,并且耗时较长,仅仅依靠击杀对手作为reward,actor很难得到合适的训练;此时就可以引入reward shaping,例如:1.血量损失,reward=-0.05;2.弹药损失,reward=-0.04;3.agent总是待在原地,reward=-0.03(防止agent挂机摆烂)。reward shaping的设置规则往往是人类根据经验来进行设定的,得到合适的reward shaping规则要求人类对于如何完成任务有着深刻的理解
一种有趣的reward shaping的方法是curiosity base,该种reward shaping的核心方法是如果actor看到了新的画面,就得到正的reward。例如在训练AI玩超级马里奥时,该种方法就有较好的表现,因为超级马里奥是一个二维游戏,游戏通关的表现实际就是actor不断看到新的画面

除了sparse reward的情况外,还有一种更极端的情况,那就是甚至无法得到reward。例如我们让actor去马路上进行行走,马路上的路况十分复杂,所以reward的规则很难制定,这种情况下就几乎无法得到合适的reward。
有一种处理此种问题的方法叫做Imitation Learning(模仿学习)。通过引入expert(通常是人类)和环境的交互示范,来训练actor做出动作。
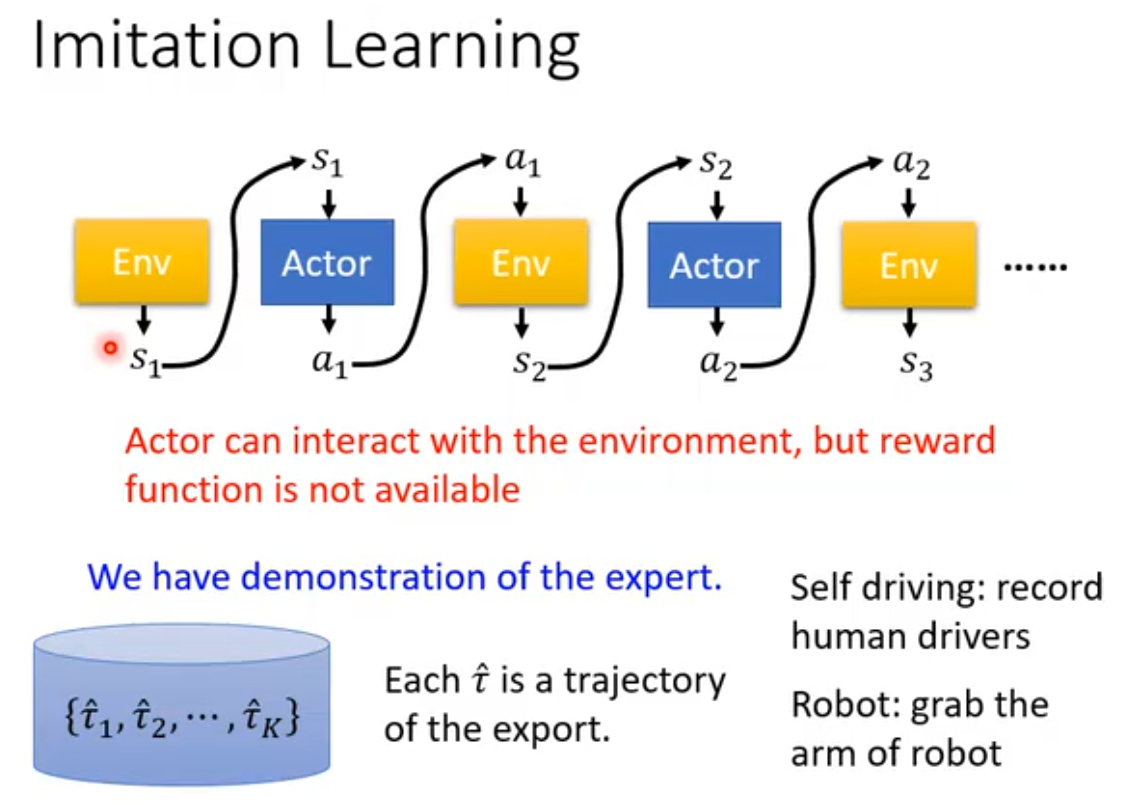
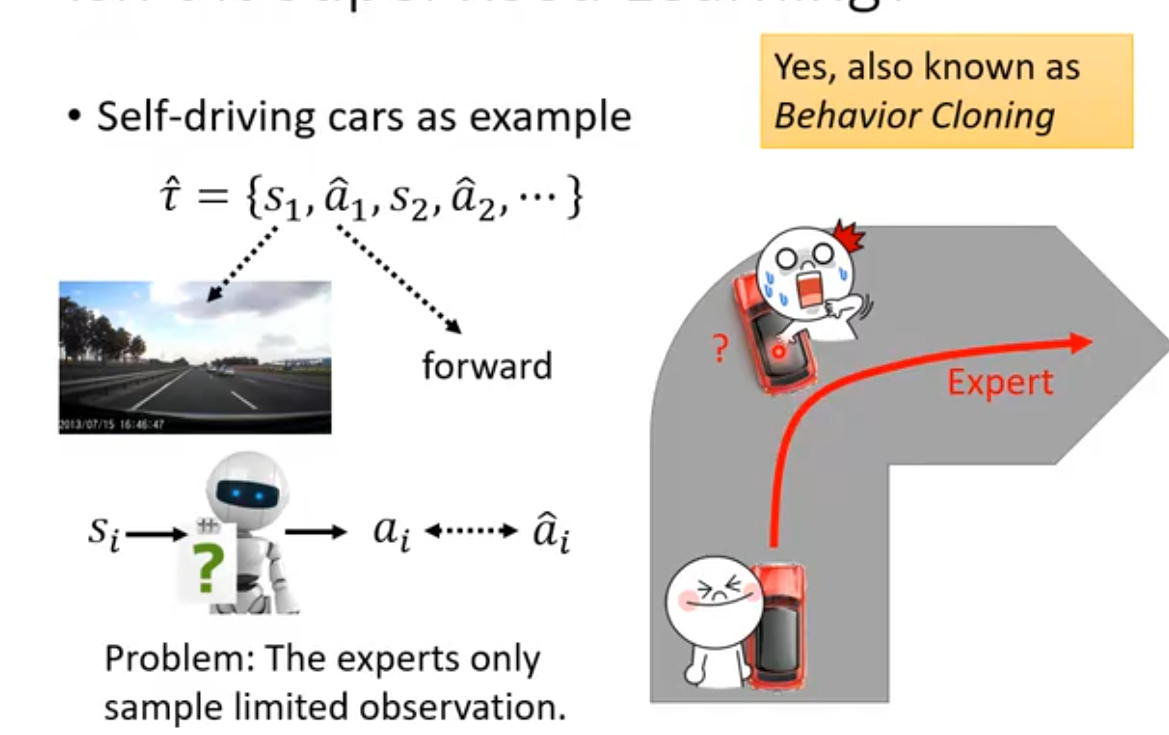
这种训练模式类似于supervised learning。输入状态s,将expert的动作作为标签,那么就构成了一对数据(s,
);以此来对actor进行训练,使其得到s输入后输出接近于expert的动作。但这样会产生一些问题:1.如果expert的所有动作都是正确的,如在自动驾驶场景下,面对转弯问题时作为expert的人类每次都可以顺利转向,那么机器就无法学习到转向失败时的数据,因此在面对复杂场景时,如果出现类似于转向失败的场景,actor将无法处理;2.完全复制模仿expert的行为,会产生一些多余的动作。例如人类expert在转弯时习惯抽烟(我们假设actor有抽烟的机动装置),那么这个动作也会被actor学到,但实际这个动作本身对转弯是没有任何好处的。3.expert具有非常多的行动特质,而actor的学习能力有限,只能学习其中的某些特质,而并非expert的所有特质都是有利的(例如转弯时抽烟);如果actor只学到了对处理问题无益的action,那么显然actor处理能力的问题并不会变强。
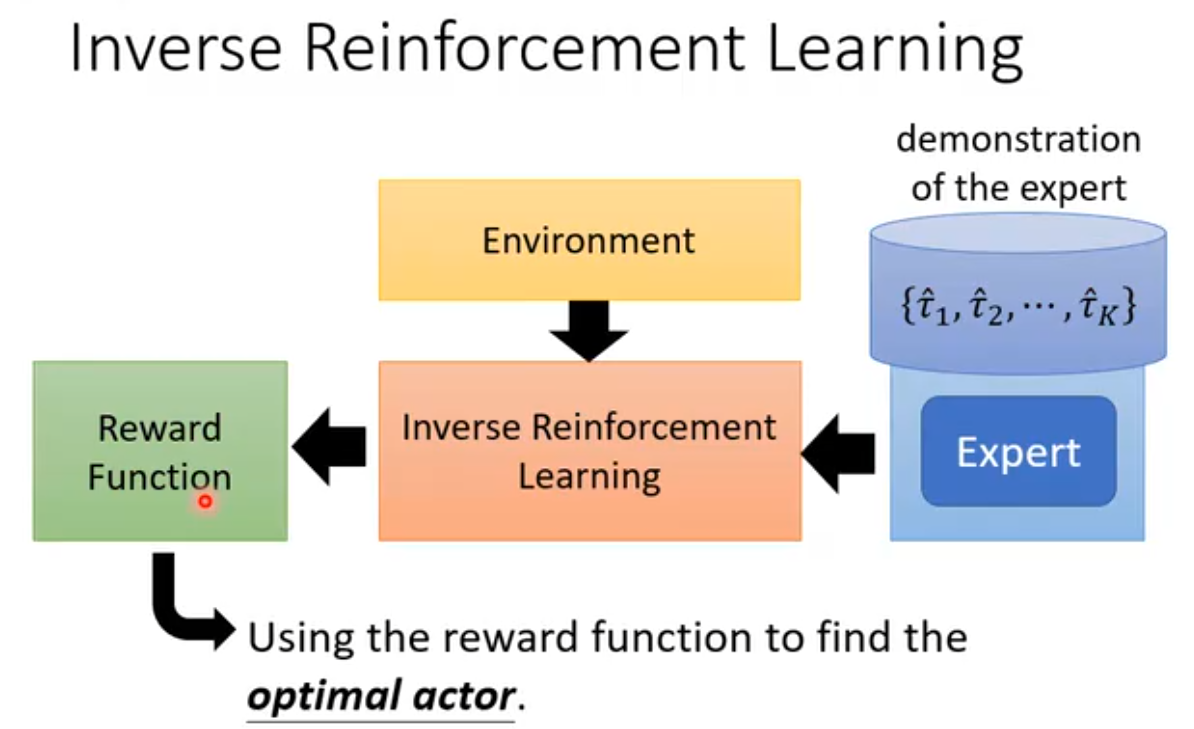
上述问题都是建立在人类无法给出合理的reward机制的前提上,我们自然而然的可以想出:是否可以让机器自己来学习如何设置合适的reward呢?
Inverse Reinforcement Learning就是一种让机器自己训练reward的方法。这种方法的逻辑模型如下,核心思路就是通过expert的行动、environment的反馈,来反推出reward函数,然后再用这个reward函数对actor进行训练。
通过expert训练reward函数的时候有一个基本原则,那就是要求expert的action所得到的reward必须要高于actor的分数(但这并不代表我们要求actor完全模仿expert的行为),训练的步骤如下:
1.初始化一个actor
2.actor和环境交互
3.定义一个初始的reward函数,(在下一次循环中要先更新reward函数)让其计算expert的action和actor的action的累计奖励,并且让expert的得分高于actor(这里expert的action已经作为开始的数据输入到了模型中)
4.actor在新的reward函数下继续和环境互动,最大化自己的累计reward
