图片转 ppt,实现可编辑
效果演示
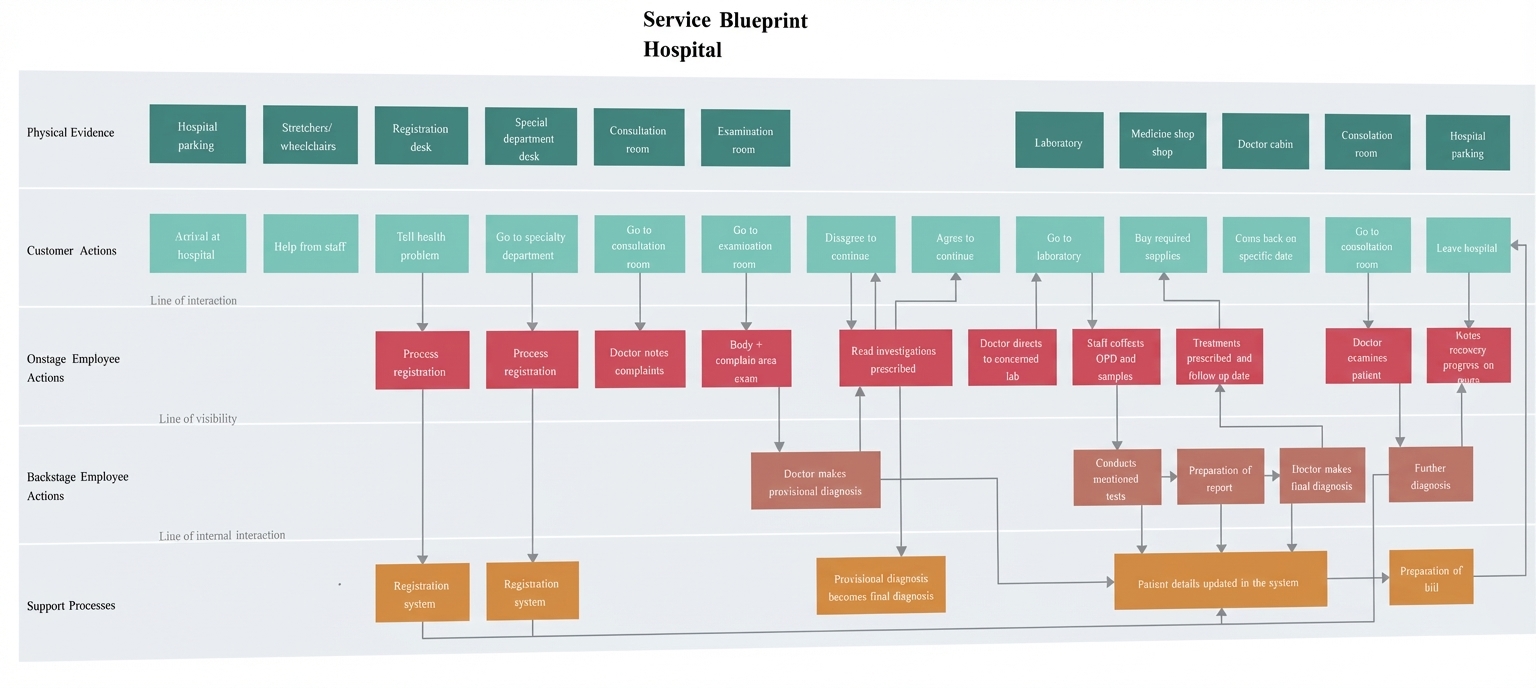
输出后:
只需要手动修订一下箭头了,工作量减少了,不用自己纯手打(2小时)
完整代码
大模型只能选用 gemini-3-pro-preview,qwen 是不行的
python
#!/usr/bin/env python3
"""
图片转PPTX v3 - 增强精确版
改进点:
1. 两步法:先OCR提取文字,再生成布局
2. 强制安全边距约束
3. 支持切换模型
使用方法:
python image_to_pptx_v3.py input_image.png -o output.pptx
python image_to_pptx_v3.py input_image.png -o output.pptx --model gemini-3-pro-preview-thinking
"""
import os
import sys
import base64
import argparse
import tempfile
import subprocess
import requests
import json
import re
from pathlib import Path
# ============================================================
# 配置
# ============================================================
# 默认API配置
DEFAULT_BASE_URL = "https://api.vectorengine.ai/v1"
DEFAULT_API_KEY = "sk-m"
# 固定使用的模型
DEFAULT_MODEL = "gemini-3-pro-preview"
# 幻灯片安全边距配置(英寸)
SLIDE_WIDTH = 13.333
SLIDE_HEIGHT = 7.5
SAFE_MARGIN_LEFT = 0.3
SAFE_MARGIN_RIGHT = 0.3
SAFE_MARGIN_TOP = 0.3
SAFE_MARGIN_BOTTOM = 0.3
SAFE_WIDTH = SLIDE_WIDTH - SAFE_MARGIN_LEFT - SAFE_MARGIN_RIGHT # 12.733
SAFE_HEIGHT = SLIDE_HEIGHT - SAFE_MARGIN_TOP - SAFE_MARGIN_BOTTOM # 6.9
# ============================================================
# PPTX 模板代码
# ============================================================
PPTX_TEMPLATE = '''
from pptx import Presentation
from pptx.util import Inches, Pt, Emu
from pptx.dml.color import RGBColor
from pptx.enum.text import PP_ALIGN, MSO_ANCHOR
from pptx.enum.shapes import MSO_SHAPE
from pptx.enum.dml import MSO_LINE_DASH_STYLE
# 幻灯片尺寸
SLIDE_WIDTH = 13.333
SLIDE_HEIGHT = 7.5
# 安全边距
SAFE_LEFT = 0.3
SAFE_RIGHT = 13.033 # 13.333 - 0.3
SAFE_TOP = 0.3
SAFE_BOTTOM = 7.2 # 7.5 - 0.3
# 创建演示文稿 (16:9)
prs = Presentation()
prs.slide_width = Inches(SLIDE_WIDTH)
prs.slide_height = Inches(SLIDE_HEIGHT)
# 添加空白幻灯片
slide = prs.slides.add_slide(prs.slide_layouts[6])
def clamp_x(x, width=0):
"""确保X坐标在安全范围内"""
x = max(SAFE_LEFT, x)
if x + width > SAFE_RIGHT:
x = SAFE_RIGHT - width
return max(SAFE_LEFT, x)
def clamp_y(y, height=0):
"""确保Y坐标在安全范围内"""
y = max(SAFE_TOP, y)
if y + height > SAFE_BOTTOM:
y = SAFE_BOTTOM - height
return max(SAFE_TOP, y)
def parse_color(color):
"""解析颜色值,支持带#和不带#的格式"""
if not color:
return RGBColor(0, 0, 0)
color = str(color).strip().lstrip('#')
if len(color) == 6:
return RGBColor(int(color[0:2], 16), int(color[2:4], 16), int(color[4:6], 16))
return RGBColor(0, 0, 0)
def add_text_box(slide, text, left, top, width, height, font_size=12, bold=False, color="000000", align="center", font_name="Arial"):
"""添加文本框(带边界检查)"""
left = clamp_x(left, width)
top = clamp_y(top, height)
textbox = slide.shapes.add_textbox(Inches(left), Inches(top), Inches(width), Inches(height))
tf = textbox.text_frame
tf.word_wrap = True
p = tf.paragraphs[0]
p.text = text
p.font.size = Pt(font_size)
p.font.bold = bold
p.font.name = font_name
p.font.color.rgb = parse_color(color)
if align == "center":
p.alignment = PP_ALIGN.CENTER
elif align == "left":
p.alignment = PP_ALIGN.LEFT
elif align == "right":
p.alignment = PP_ALIGN.RIGHT
return textbox
def add_rect(slide, left, top, width, height, fill_color=None, border_color=None, border_width=1, text=None, text_color="FFFFFF", font_size=10, corner_radius=0, bold=False, font_name="Arial"):
"""添加矩形(带边界检查)"""
left = clamp_x(left, width)
top = clamp_y(top, height)
if corner_radius > 0:
shape = slide.shapes.add_shape(MSO_SHAPE.ROUNDED_RECTANGLE, Inches(left), Inches(top), Inches(width), Inches(height))
else:
shape = slide.shapes.add_shape(MSO_SHAPE.RECTANGLE, Inches(left), Inches(top), Inches(width), Inches(height))
if fill_color:
shape.fill.solid()
shape.fill.fore_color.rgb = parse_color(fill_color)
else:
shape.fill.background()
if border_color:
shape.line.color.rgb = parse_color(border_color)
shape.line.width = Pt(border_width)
else:
shape.line.fill.background()
if text:
tf = shape.text_frame
tf.word_wrap = True
p = tf.paragraphs[0]
p.text = text
p.font.size = Pt(font_size)
p.font.bold = bold
p.font.name = font_name
p.font.color.rgb = parse_color(text_color)
p.alignment = PP_ALIGN.CENTER
tf.anchor = MSO_ANCHOR.MIDDLE
return shape
def add_line(slide, start_x, start_y, end_x, end_y, color="000000", width=1, dashed=False):
"""添加直线(带边界检查)"""
start_x = clamp_x(start_x)
end_x = clamp_x(end_x)
start_y = clamp_y(start_y)
end_y = clamp_y(end_y)
connector = slide.shapes.add_connector(
1,
Inches(start_x), Inches(start_y),
Inches(end_x), Inches(end_y)
)
connector.line.color.rgb = parse_color(color)
connector.line.width = Pt(width)
if dashed:
connector.line.dash_style = MSO_LINE_DASH_STYLE.DASH
return connector
def add_arrow(slide, start_x, start_y, end_x, end_y, color="000000", width=1.5):
"""添加箭头(带边界检查)- 使用带箭头端点的线条"""
start_x = clamp_x(start_x)
end_x = clamp_x(end_x)
start_y = clamp_y(start_y)
end_y = clamp_y(end_y)
line = slide.shapes.add_connector(
1,
Inches(start_x), Inches(start_y),
Inches(end_x), Inches(end_y)
)
line.line.color.rgb = parse_color(color)
line.line.width = Pt(width)
# 尝试添加箭头头部
try:
from pptx.oxml.ns import qn
from lxml import etree
spPr = line._element.find(qn('p:spPr'))
if spPr is not None:
ln = spPr.find(qn('a:ln'))
if ln is not None:
tailEnd = etree.SubElement(ln, qn('a:tailEnd'))
tailEnd.set('type', 'triangle')
tailEnd.set('w', 'med')
tailEnd.set('len', 'med')
except:
pass
return line
# ========== 以下是AI生成的绘图代码 ==========
'''
def encode_image_to_base64(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def get_image_mime_type(image_path: str) -> str:
ext = Path(image_path).suffix.lower()
mime_map = {".png": "image/png", ".jpg": "image/jpeg", ".jpeg": "image/jpeg", ".gif": "image/gif", ".webp": "image/webp"}
return mime_map.get(ext, "image/png")
def call_api(base_url: str, api_key: str, model: str, messages: list, max_tokens: int = 8000) -> str:
"""调用API"""
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": model,
"messages": messages,
"temperature": 0.1,
"max_tokens": max_tokens
}
response = requests.post(
f"{base_url}/chat/completions",
headers=headers,
json=payload,
timeout=600
)
if response.status_code != 200:
print(f"❌ API调用失败: {response.status_code}")
print(response.text)
sys.exit(1)
result = response.json()
return result["choices"][0]["message"]["content"]
def step1_extract_content(base_url: str, api_key: str, model: str, image_path: str) -> dict:
"""
Step 1: 精确提取图片中的所有文字内容和结构
"""
base64_image = encode_image_to_base64(image_path)
mime_type = get_image_mime_type(image_path)
system_prompt = """你是一个专业的OCR和图表分析专家。仔细分析用户提供的图片,精确提取所有内容。
## 任务
分析这张图片(可能是流程图、服务蓝图、PPT等),提取:
1. 所有文字内容(一字不差)
2. 元素的相对位置关系
3. 颜色信息
4. 连接线/箭头的逻辑关系
## 输出格式(JSON)
```json
{
"title": "图片标题",
"type": "service_blueprint / flowchart / presentation / other",
"structure": {
"rows": [
{
"row_name": "行名称(如 Physical Evidence)",
"row_index": 0,
"color": "主要颜色十六进制",
"items": [
{"text": "完整文字", "column": 0},
{"text": "完整文字", "column": 1}
]
}
],
"total_columns": 13,
"divider_lines": ["Line of interaction", "Line of visibility"]
},
"connections": [
{"from": "元素A", "to": "元素B", "type": "arrow/line"}
]
}
\```
## 关键规则
1. **文字必须100%准确**:不要猜测、简化或遗漏任何文字
2. **保留换行**:多行文字用\\n分隔
3. **颜色准确**:用十六进制表示(如 #5DADE2)
4. **结构清晰**:标注每个元素所在的行号和列号
只输出JSON,不要其他内容。"""
user_content = [
{"type": "text", "text": "请精确分析这张图片,提取所有文字内容和结构信息。文字必须100%准确,不要遗漏任何内容。"},
{"type": "image_url", "image_url": {"url": f"data:{mime_type};base64,{base64_image}"}}
]
print("📖 Step 1: 正在精确提取图片内容...")
content = call_api(base_url, api_key, model, [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content}
], max_tokens=8000)
# 清理JSON
if "```json" in content:
content = content.split("```json")[1].split("```")[0]
elif "```" in content:
content = content.split("```")[1].split("```")[0]
try:
return json.loads(content.strip())
except json.JSONDecodeError:
print("⚠️ JSON解析失败,返回原始内容")
return {"raw_content": content}
def step2_generate_code(base_url: str, api_key: str, model: str, image_path: str, extracted_content: dict) -> str:
"""
Step 2: 基于提取的内容生成PPTX代码
"""
base64_image = encode_image_to_base64(image_path)
mime_type = get_image_mime_type(image_path)
system_prompt = f"""你是一个专业的PPT开发工程师。根据提取的内容信息和原图,生成python-pptx代码来1:1还原图片。
## 幻灯片安全区域(必须遵守!)
- 幻灯片尺寸: {SLIDE_WIDTH} x {SLIDE_HEIGHT} 英寸
- 左边距: {SAFE_MARGIN_LEFT} 英寸(内容不能小于此值)
- 右边距: 内容X坐标+宽度 不能超过 {SLIDE_WIDTH - SAFE_MARGIN_RIGHT} 英寸
- 上边距: {SAFE_MARGIN_TOP} 英寸
- 下边距: 内容Y坐标+高度 不能超过 {SLIDE_HEIGHT - SAFE_MARGIN_BOTTOM} 英寸
## 可用区域计算
- 有效宽度: {SAFE_WIDTH:.2f} 英寸
- 有效高度: {SAFE_HEIGHT:.2f} 英寸
- 如果有13列元素,每列宽度约: {SAFE_WIDTH/13:.3f} 英寸
## 可用的辅助函数(只能使用这4个!已在模板中定义好,不要重新定义!)
1. add_text_box(slide, text, left, top, width, height, font_size=12, bold=False, color="000000", align="center")
2. add_rect(slide, left, top, width, height, fill_color=None, border_color=None, text=None, text_color="FFFFFF", font_size=10)
3. add_line(slide, start_x, start_y, end_x, end_y, color="000000", width=1, dashed=False)
4. add_arrow(slide, start_x, start_y, end_x, end_y, color="000000", width=1.5)
## 禁止事项(非常重要!)
- **禁止定义任何函数**(def xxx:)
- **禁止导入任何模块**(import xxx)
- **禁止使用pptx库的其他API**
- 只能直接调用上面4个函数和使用变量 slide, prs
## 关键规则(必须遵守!)
### 规则1:边界安全
- 所有内容必须在安全区域内,不能超出边界
### 规则2:文字准确
- 文字必须与提取的内容完全一致
### 规则3:连线和箭头(非常重要!)
- **必须绘制所有的连接线和箭头**
- 观察原图中方框之间的连线,用 add_line() 或 add_arrow() 绘制
- 垂直连线:连接上下方框
- 水平连线:连接左右方框
- 虚线分隔线:用 add_line(..., dashed=True) 绘制泳道分隔线
- 箭头方向:注意箭头指向(从哪到哪)
### 规则4:绘制顺序
1. 先画背景
2. 再画所有矩形方框
3. 再画虚线分隔线(Line of interaction等)
4. 最后画所有连接线和箭头
## 已提取的内容
{json.dumps(extracted_content, ensure_ascii=False, indent=2)}
## 输出格式
只输出Python代码。
重要:代码末尾必须使用这一行保存文件(不要改变):
prs.save(OUTPUT_PATH)
不要使用任何未定义的函数。只能使用: add_text_box, add_rect, add_line, add_arrow"""
user_content = [
{"type": "text", "text": "根据上面提取的内容和这张原图,生成python-pptx代码。确保所有内容都在安全边距内,不要超出边界。"},
{"type": "image_url", "image_url": {"url": f"data:{mime_type};base64,{base64_image}"}}
]
print("🔨 Step 2: 正在生成PPTX代码...")
code = call_api(base_url, api_key, model, [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content}
], max_tokens=16000)
# 清理markdown代码块
if "```python" in code:
code = code.split("```python")[1].split("```")[0]
elif "```" in code:
code = code.split("```")[1].split("```")[0]
return code.strip()
def main():
parser = argparse.ArgumentParser(
description="图片转PPTX v3 - 增强精确版(使用 gemini-3-pro-preview 模型)",
formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument("input", help="输入图片文件")
parser.add_argument("-o", "--output", default="output.pptx", help="输出PPTX文件")
parser.add_argument("--api-key", help="API Key")
parser.add_argument("--show-content", action="store_true", help="显示提取的内容")
parser.add_argument("--show-code", action="store_true", help="显示生成的代码")
args = parser.parse_args()
api_key = args.api_key or DEFAULT_API_KEY
base_url = DEFAULT_BASE_URL
model = DEFAULT_MODEL
if not Path(args.input).exists():
print(f"❌ 文件不存在: {args.input}")
sys.exit(1)
print(f"\n📊 图片转PPTX v3 - 增强精确版")
print(f"{'='*50}")
print(f"输入: {args.input}")
print(f"输出: {args.output}")
print(f"模型: {model}")
print(f"安全区域: {SAFE_MARGIN_LEFT}~{SLIDE_WIDTH-SAFE_MARGIN_RIGHT} x {SAFE_MARGIN_TOP}~{SLIDE_HEIGHT-SAFE_MARGIN_BOTTOM}")
print(f"{'='*50}\n")
# Step 1: 提取内容
extracted_content = step1_extract_content(base_url, api_key, model, args.input)
if args.show_content:
print("\n📋 提取的内容:")
print("-" * 50)
print(json.dumps(extracted_content, ensure_ascii=False, indent=2))
print("-" * 50)
# Step 2: 生成代码
generated_code = step2_generate_code(base_url, api_key, model, args.input, extracted_content)
if args.show_code:
print("\n📝 生成的代码:")
print("-" * 50)
print(generated_code)
print("-" * 50)
# 组合完整代码
full_code = PPTX_TEMPLATE + generated_code
# 修复 OUTPUT_PATH 问题
# 替换各种可能的写法
full_code = full_code.replace('prs.save(OUTPUT_PATH)', f'prs.save("{args.output}")')
full_code = full_code.replace("prs.save(OUTPUT_PATH)", f'prs.save("{args.output}")')
# 如果AI直接写了具体文件名,也替换掉
full_code = re.sub(r'prs\.save\(["\'][^"\']+["\']\)', f'prs.save("{args.output}")', full_code)
# 确保末尾有保存语句
if 'prs.save(' not in full_code:
full_code += f'\nprs.save("{args.output}")'
# 写入临时文件并执行
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False, encoding='utf-8') as f:
f.write(full_code)
temp_file = f.name
print("\n🔨 正在生成PPTX...")
try:
result = subprocess.run(
[sys.executable, temp_file],
capture_output=True,
text=True,
cwd=str(Path(args.output).parent.absolute()) if Path(args.output).parent.exists() else "."
)
if result.returncode == 0:
print(f"\n✅ 成功!PPTX已保存: {args.output}")
else:
print(f"\n❌ 生成失败:")
print(result.stderr)
debug_file = "debug_pptx_code.py"
with open(debug_file, 'w', encoding='utf-8') as f:
f.write(full_code)
print(f"\n💡 代码已保存到 {debug_file} 供调试")
finally:
os.unlink(temp_file)
if __name__ == "__main__":
main()更复杂的图形icon
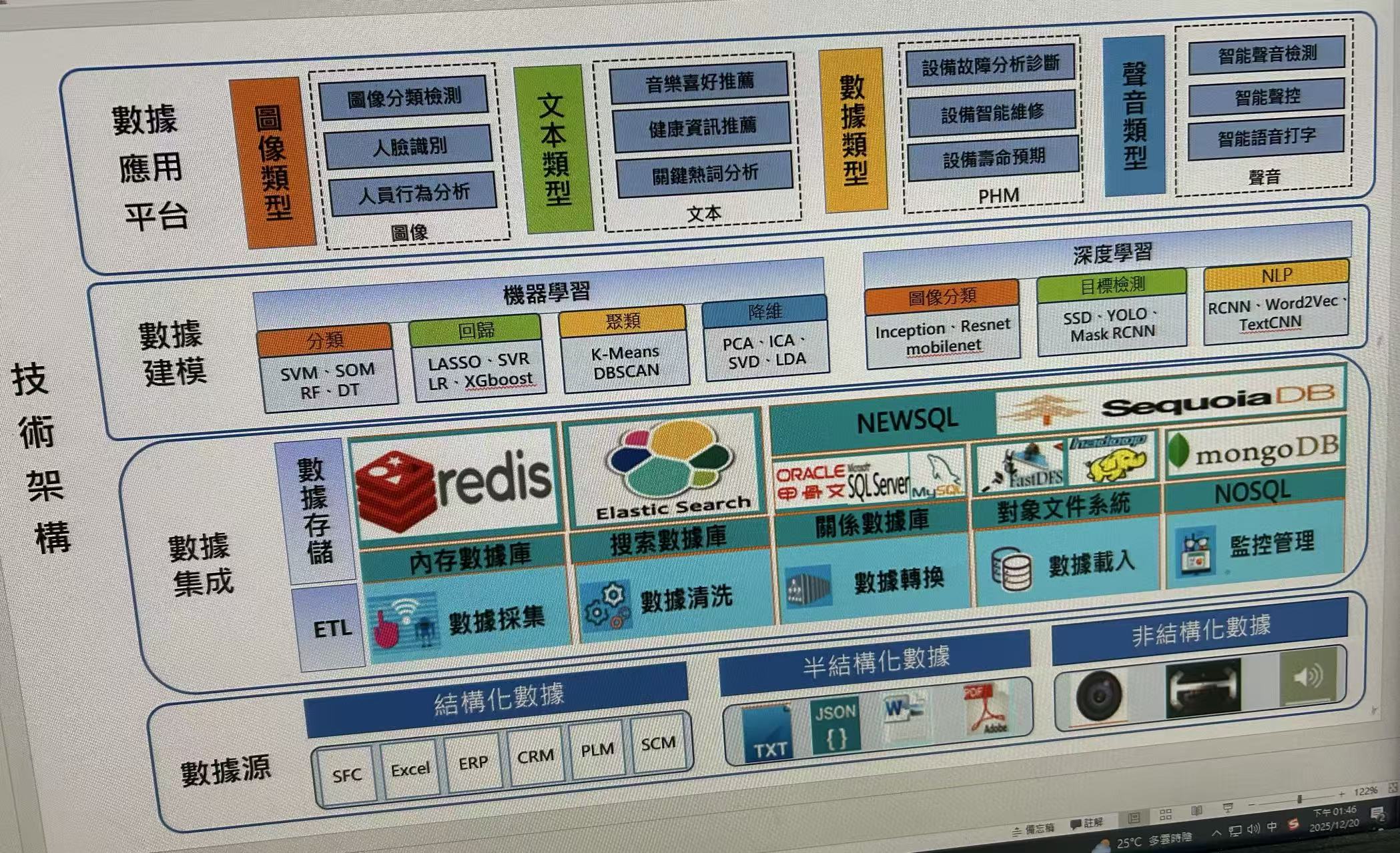
上面代码的输出:
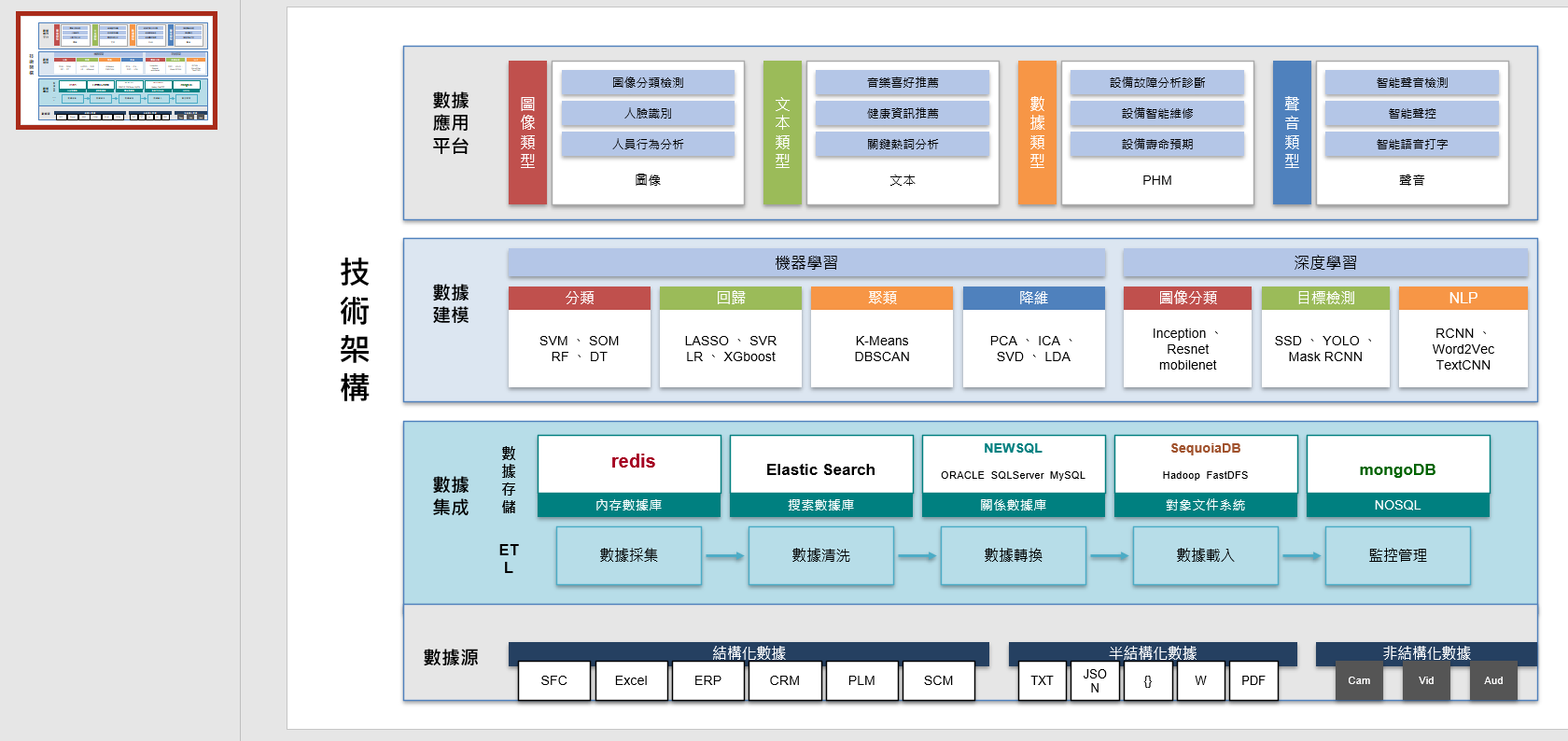
针对图标的新版本
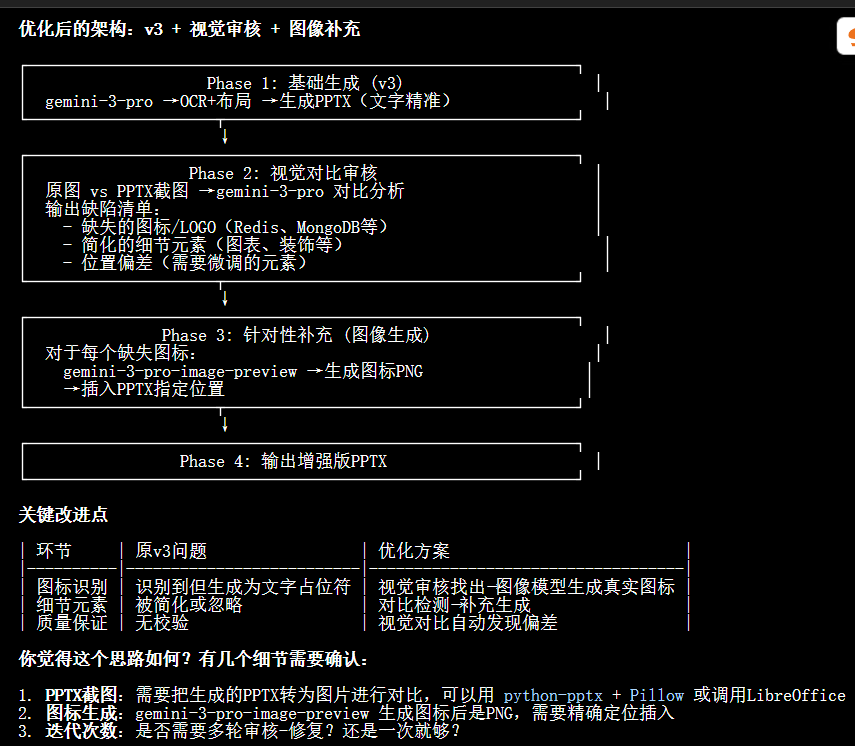
新版本输出:
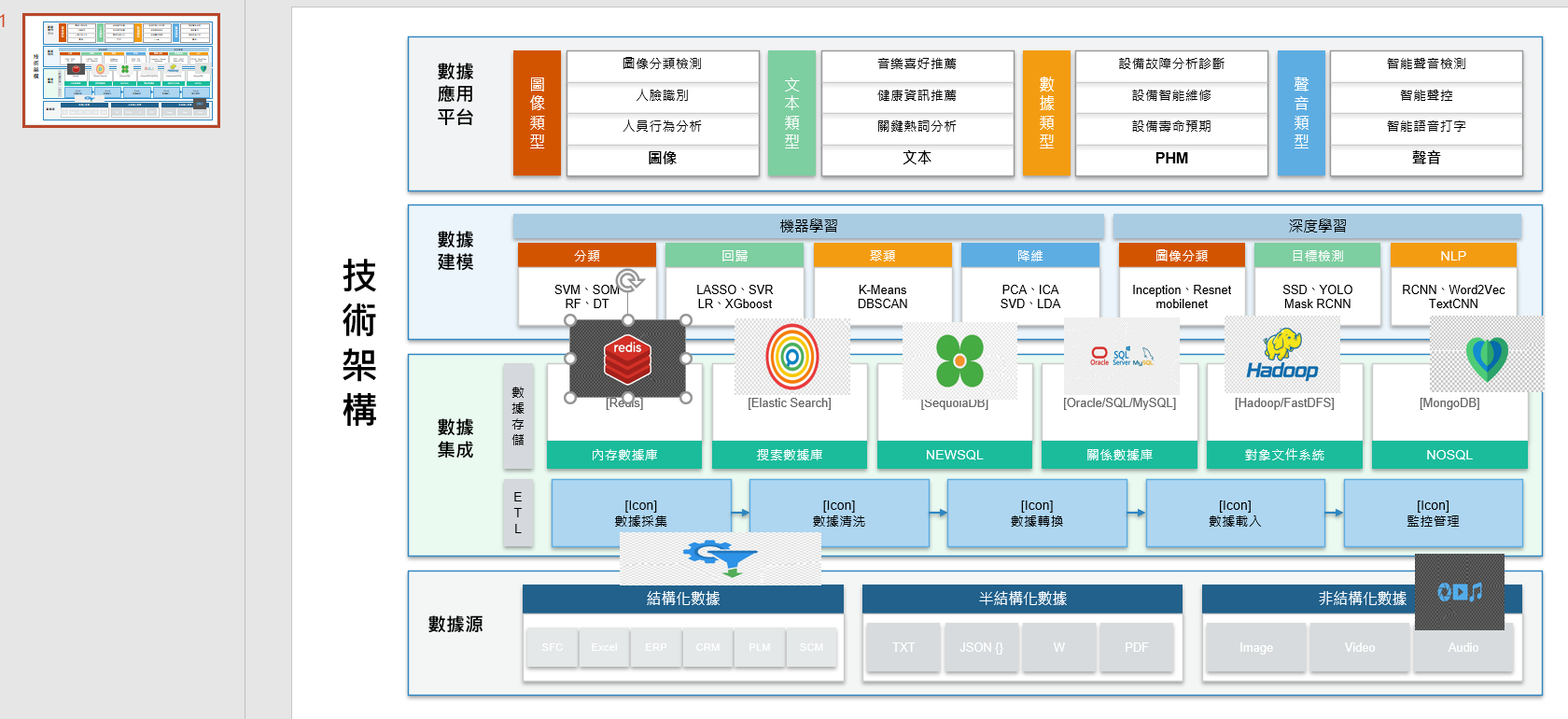
文字和结构生成是: gemini-3-pro-preview
图标生成是:gemini-3-pro-image-preview
但这个图的生成结果,感觉和原图还是有差距。