引言
在企业培训、技术文档、故障排查等场景中,PPT是一种极为常见的信息载体。然而,相比PDF、Word等文档格式,PPT具有独特的挑战:排版灵活跳跃、图文强相关、页间逻辑复杂。传统的RAG(检索增强生成)方案通常针对连续文本设计,直接套用在PPT上往往效果不佳。
在企业级知识库建设中,PPT更是一块"硬骨头"。相比线性叙事的Word或版式固定的PDF,PPT的信息分布是离散且高度视觉化的。如果直接套用传统的"文本分块+向量检索"方案,系统往往会因为丢失了图片上下文和页间逻辑,导致回答断章取义。
本文将深度拆解一套专门针对PPTx格式设计的RAG智能问答系统。我们将不再只是堆砌代码,而是从父子分块架构、跨页逻辑聚合、多模态图文对齐等核心技术维度,分析如何让大模型真正"看懂"幻灯片背后的深意。
原型系统界面展示
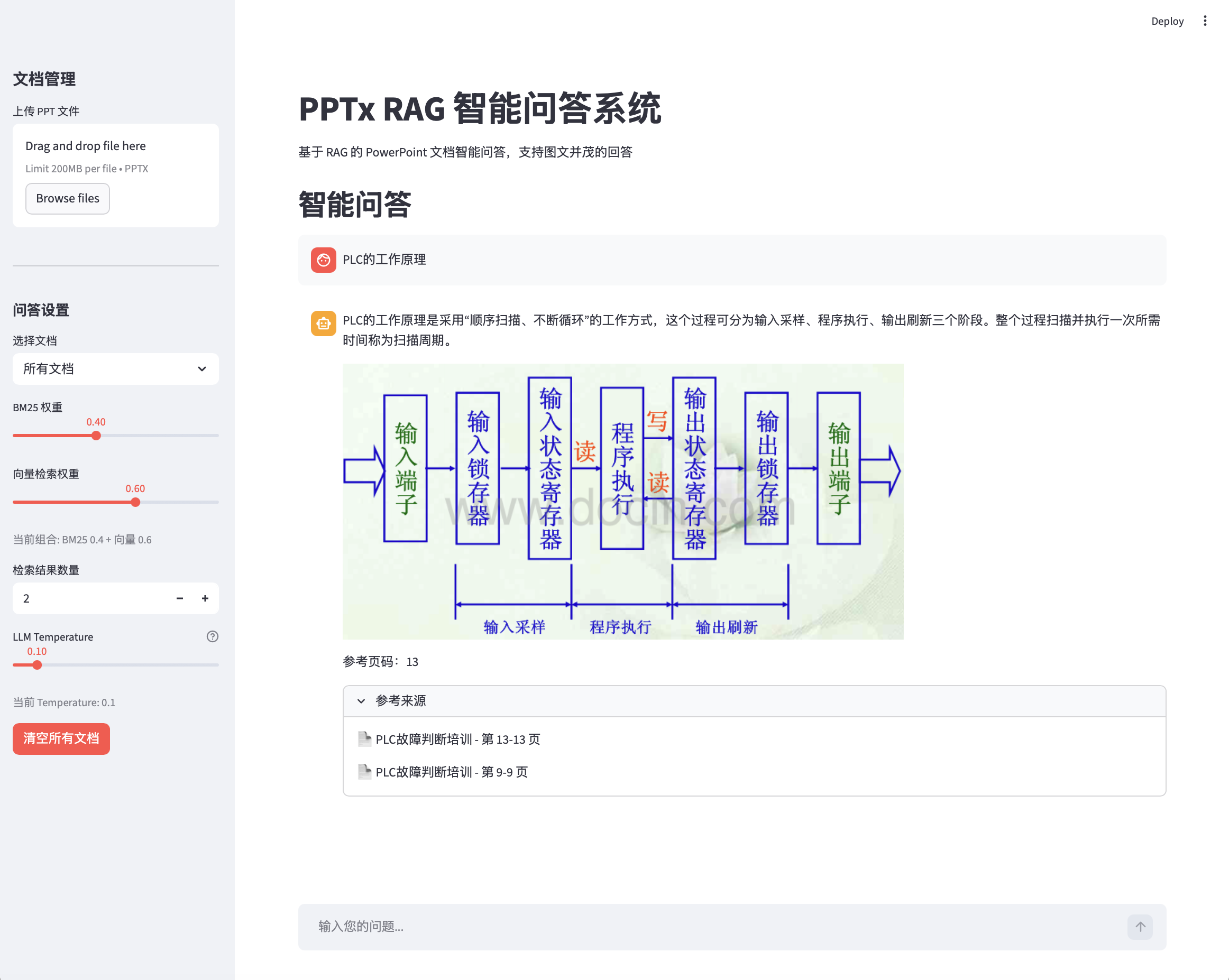
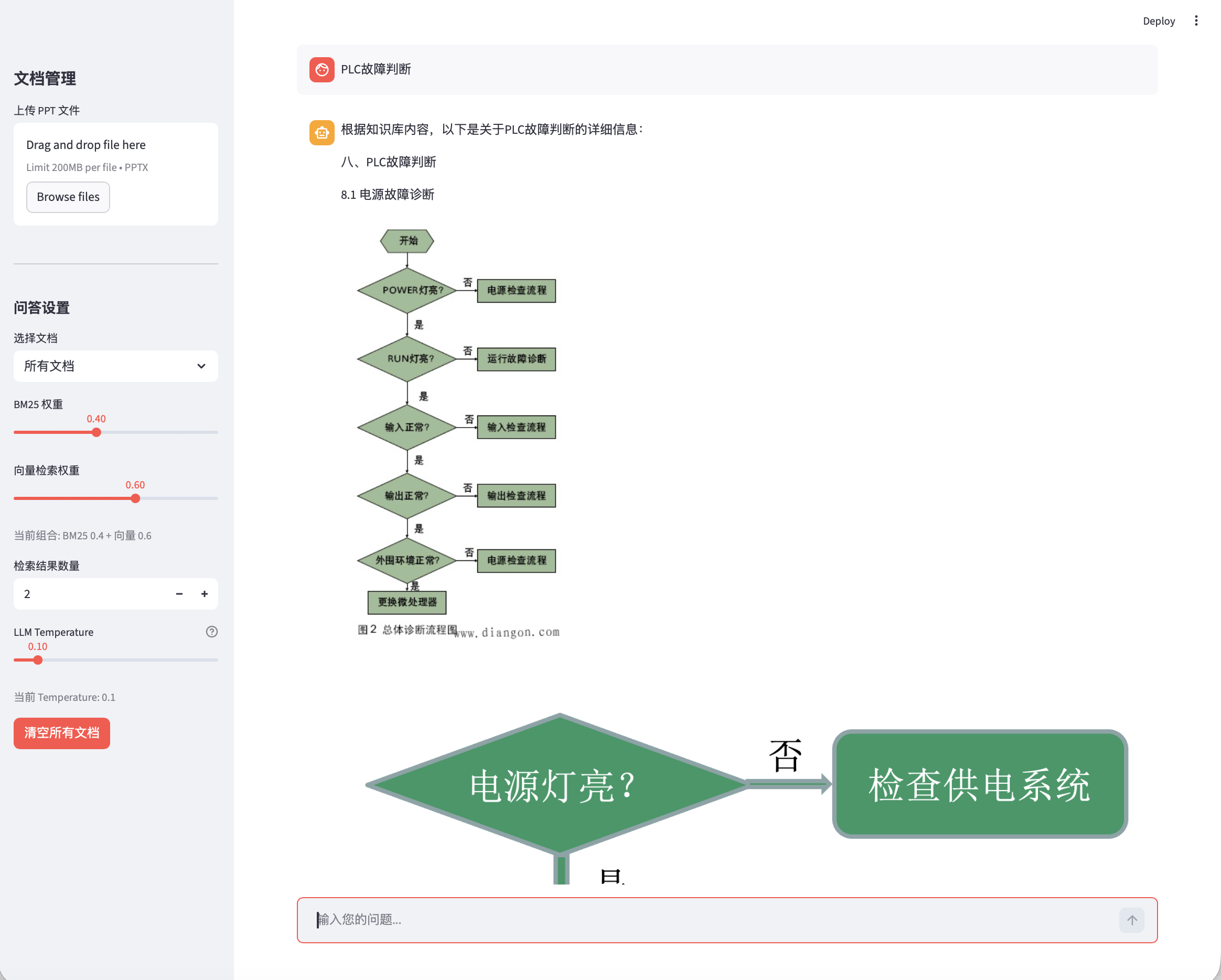
单页图文回答
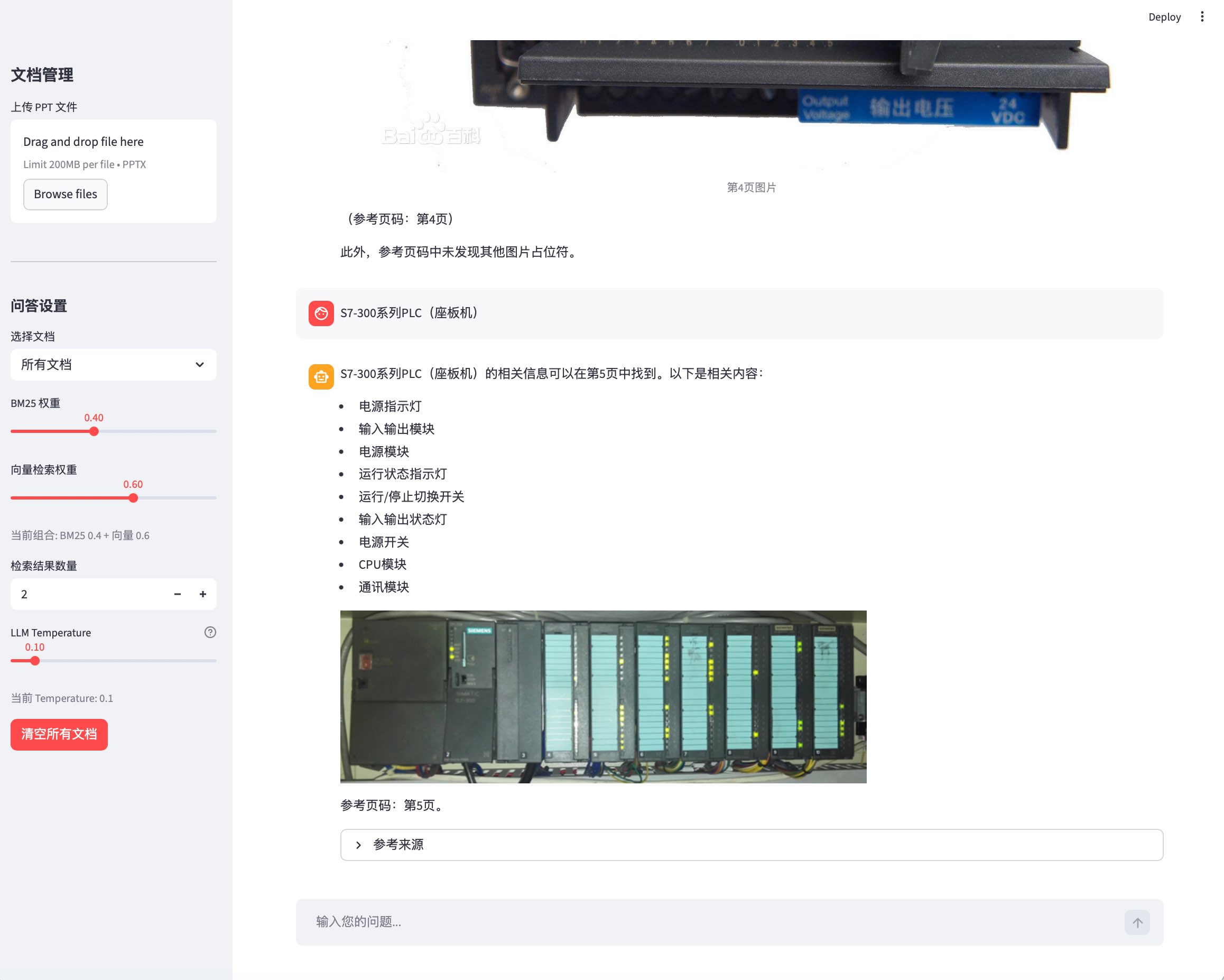
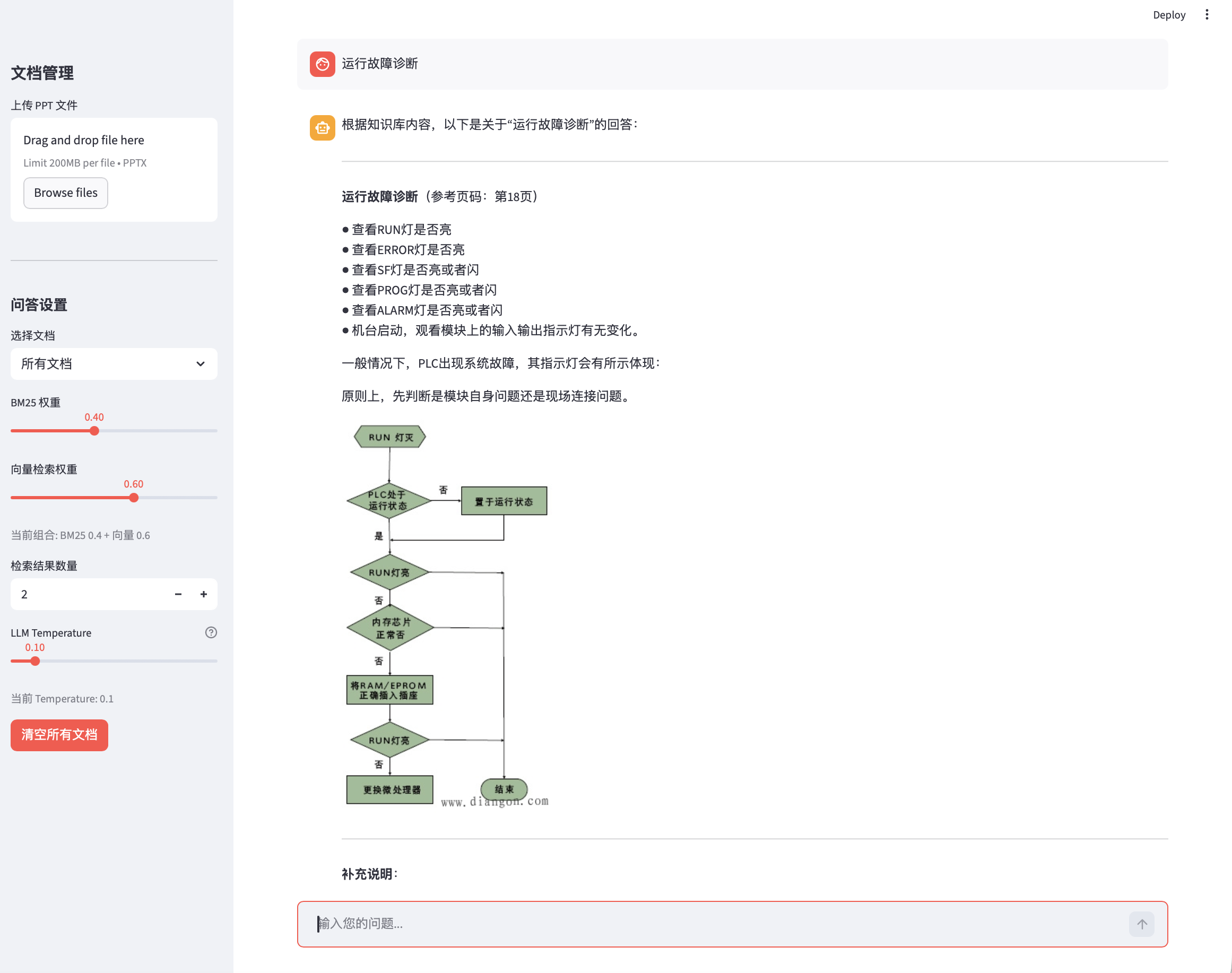
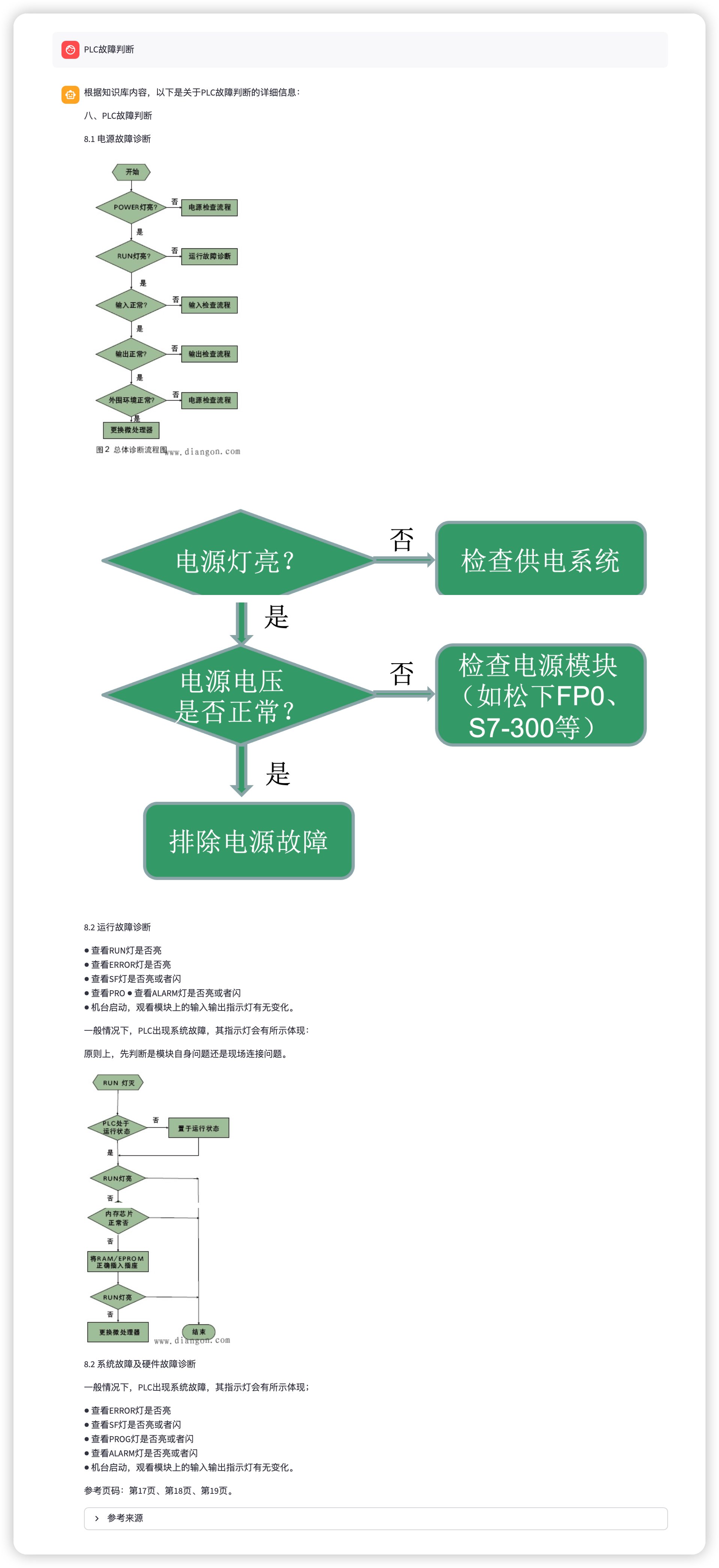
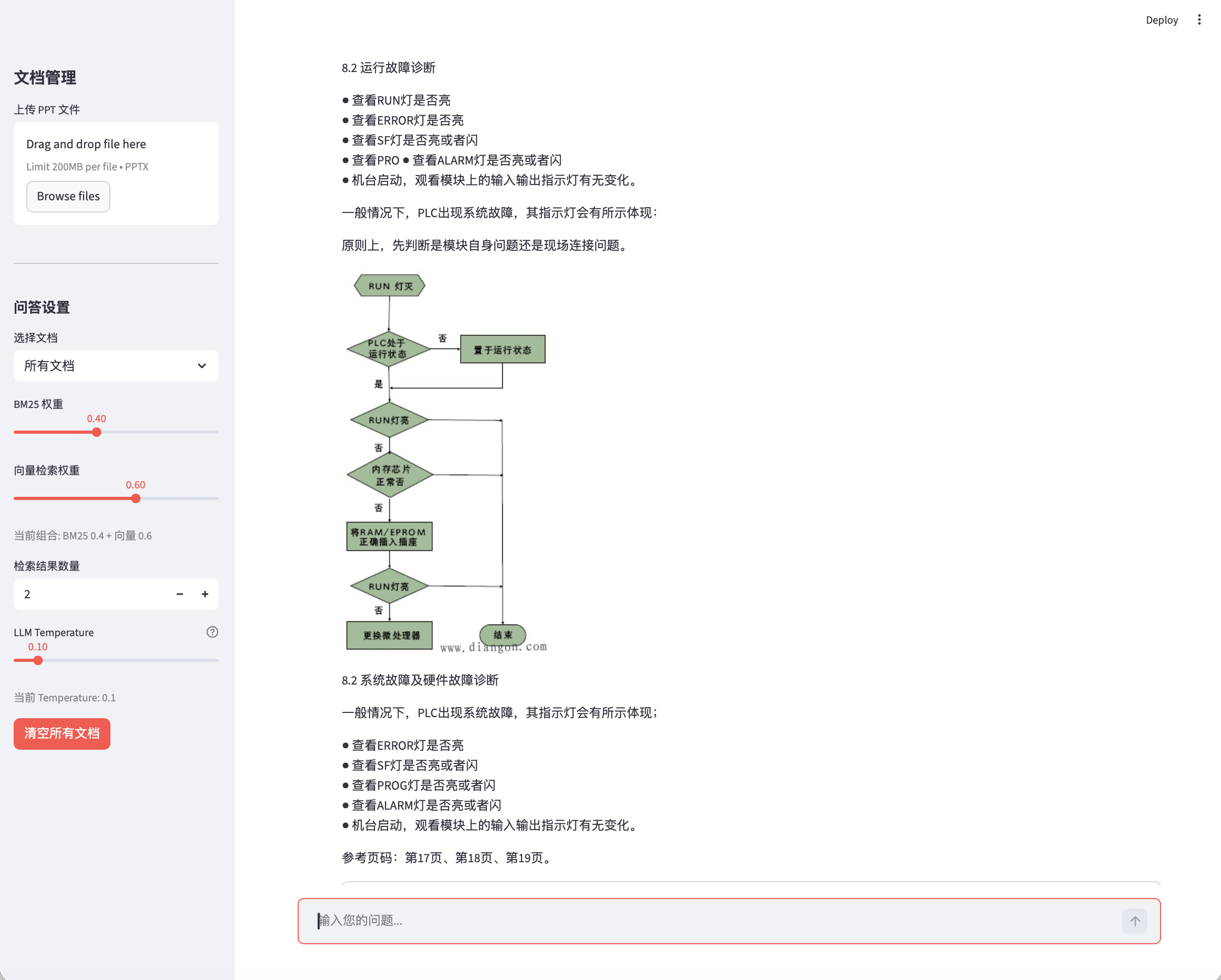
跨页图文回答
第一章:PPT做RAG面临的核心挑战
1.1 为什么传统RAG在PPT面前会"失明"?
在开发此系统前,我们必须理解PPT文档的三大异构特征:
1. 非线性的视觉布局
PPT不像PDF那样有固定的版式约束。一页PPT可能包含:
- 多级标题混杂
- 图片与文字交叉排列
- 表格、图表、SmartArt等多种元素
传统的"按段落切分"或"按字符数切分"策略在PPT面前完全失效。
2. 极高的信息密度窗口
以工业培训PPT为例:
- 传感器接线图
- 设备故障示意图
- 操作步骤流程图
一页PPT可能只有50字,却包含大量图片信息。这些图片承载的信息远超正文文字,但传统RAG系统很难处理图片。
3. 断裂的跨页逻辑
PPT的页面关系有三种模式:
- 单一主题页:一页一个完整知识点
- 连续步骤页:同一个操作分多页讲解(如"安装步骤1"、"安装步骤2")
- 独立主题页:与前后页无直接关联
传统RAG的分块策略(按字符数切分500-1000字符、按段落切分、按Markdown标题层级切分)在PPT面前都不适用,因为跨页的连续步骤被切分后,回答会不完整。
1.2 深度痛点分析
格式高度灵活,排版随意
PPT的排版完全打破了传统文档的线性思维。传统的"按段落切分"或"按字符数切分"策略在PPT面前完全失效。
图片信息密度往往高于文字
以工业培训PPT为例:传感器接线图、设备故障示意图、操作步骤流程图。这些图片承载的信息远超正文文字,但传统RAG系统很难处理图片。
页间逻辑跳跃且不固定
PPT的页面关系有三种模式,每种模式都需要不同的处理策略。
第二章:核心架构设计
2.1 为什么选择父子分块架构?
在传统的RAG中,检索单元就是生成单元。但这存在矛盾:短文本块有利于精确匹配,长文本块有利于LLM理解上下文。
为兼顾"检索精度"和"生成质量",本系统采用父子分块架构(Parent-Document Retrieval)。
子块(Child Chunks):以单页PPT为单位。我们将每一页的文本、标题和图片描述转换成向量。由于粒度小,它能更灵敏地响应用户的关键词搜索。
父块(Parent Chunks):通过"页面合并算法"将逻辑相关的连续页面聚合在一起。当子块被命中时,系统会回溯其所属的父块,并将整个父块的丰富内容投喂给LLM。
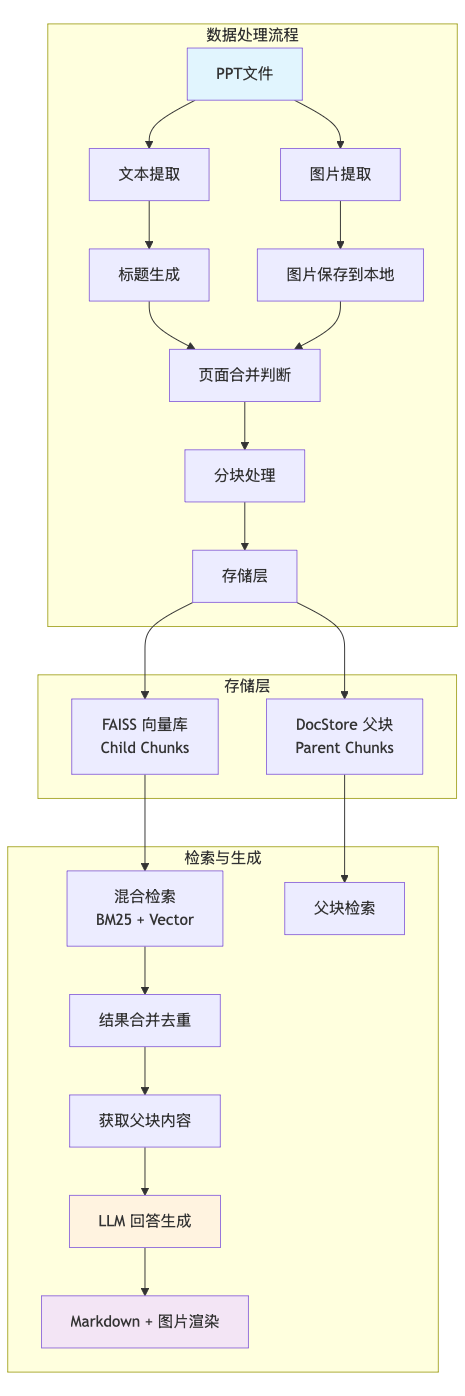
2.2 系统总体架构
2.3 技术栈选择
| 组件 | 选择 | 理由 |
|---|---|---|
| LLM 框架 | LangChain | 生态丰富,易于集成 |
| LLM 模型 | Qwen3:8b (Ollama) | 本地部署,多模态能力 |
| Embeddings | bge-m3:latest | 中英文效果好,支持多语言 |
| 向量库 | FAISS | 轻量级,本地部署简单 |
| DocStore | 本地 JSON 文件 | 简单够用,无需额外服务 |
| 前端 | Streamlit | 快速原型开发 |
| 图片存储 | 本地 HTTP 服务器 | 轻量级替代MinIO |
第三章:核心数据模型设计
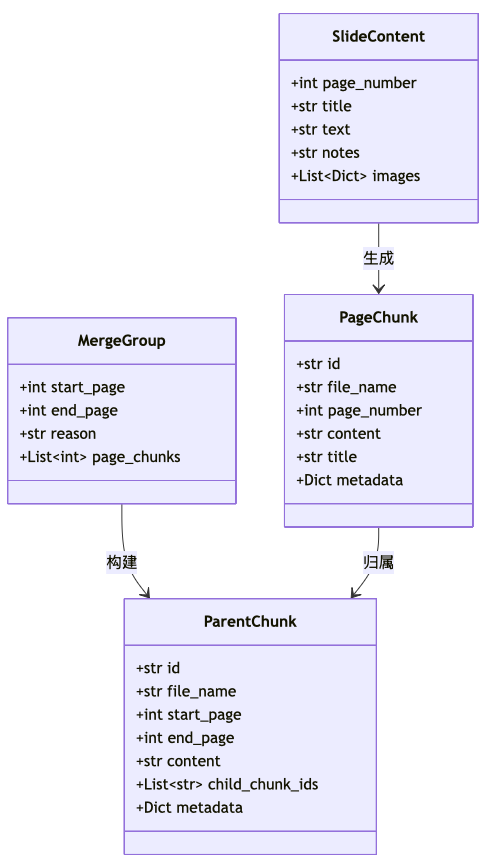
系统的数据模型是理解整个架构的关键。本系统定义了以下核心模型:
3.1 数据模型类图
3.2 核心模型代码实现
python
# src/models.py
class SlideContent(BaseModel):
"""单页PPT提取的内容"""
page_number: int # 页码
title: Optional[str] = None # 标题(可能为空)
text: str = "" # 提取的文本
notes: str = "" # 演讲者备注
images: List[Dict[str, Any]] = Field(default_factory=list)
class PageChunk(BaseModel):
"""子块:用于向量检索的最小单元(每页一个)"""
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
file_name: str # 源文件名
page_number: int # 页码
content: str # 块内容(含图片占位符)
title: Optional[str] = None # 标题
metadata: Dict[str, Any] = Field(default_factory=dict)
class ParentChunk(BaseModel):
"""父块:合并后的连续多页内容"""
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
file_name: str
start_page: int # 起始页
end_page: int # 结束页
content: str # 合并后的完整内容
child_chunk_ids: List[str] = Field(default_factory=list)
metadata: Dict[str, Any] = Field(default_factory=dict)
class MergeGroup(BaseModel):
"""需要合并的页面组"""
start_page: int
end_page: int
reason: str # 合并原因:标题相同/手动标记/单独页面
page_chunks: List[int] = Field(default_factory=list)设计要点:
PageChunk是向量检索的最小单元,一页对应一个ParentChunk包含多个PageChunk的内容,用于给LLM提供完整上下文child_chunk_ids建立父子关联,检索时通过子块找到父块
第四章:PPT解析与预处理
4.1 解析流程概览
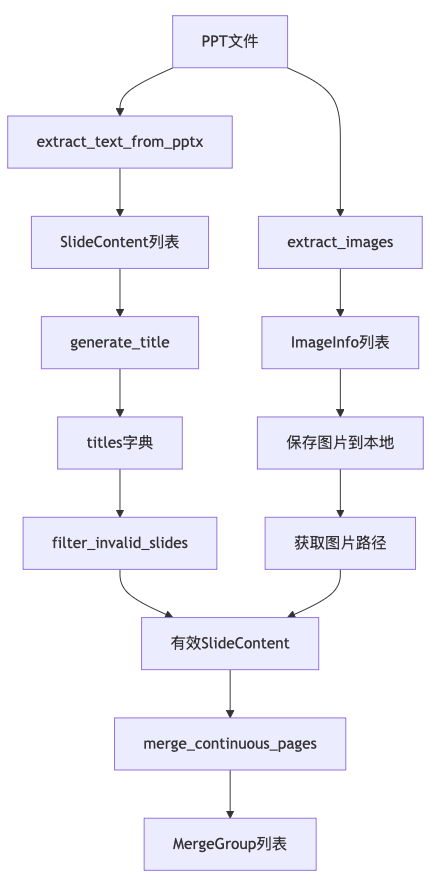
4.2 文本与图片提取实现
python
# src/parser/pptx_parser.py
def extract_text_from_pptx(pptx_path: str) -> List[SlideContent]:
"""从PPT中提取每页的文本内容"""
from pptx import Presentation
prs = Presentation(pptx_path)
slides_content = []
for i, slide in enumerate(prs.slides):
page_num = i + 1
# 提取标题
title = None
for shape in slide.shapes:
if shape.has_text_frame:
text = shape.text_frame.text
if shape == slide.shapes.title:
title = text
break
# 提取正文
text_parts = []
for shape in slide.shapes:
if hasattr(shape, "text_frame") and shape != slide.shapes.title:
for paragraph in shape.text_frame.paragraphs:
if paragraph.text.strip():
text_parts.append(paragraph.text)
# 提取备注
notes = slide.notes_slide.notes_text_frame.text if slide.notes_slide else ""
slides_content.append(SlideContent(
page_number=page_num,
title=title,
text="\n".join(text_parts),
notes=notes,
))
return slides_content4.3 图片提取与占位符生成
python
# src/parser/image_handler.py
def extract_images(pptx_path: str, images_dir: str, file_name: str) -> List[ImageInfo]:
"""提取PPT中的图片并保存到本地"""
import hashlib
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
from pathlib import Path
prs = Presentation(pptx_path)
images = []
# 创建文件专属目录
file_hash = hashlib.md5(file_name.encode("utf-8")).hexdigest()[:8]
save_dir = Path(images_dir) / file_hash
save_dir.mkdir(parents=True, exist_ok=True)
for i, slide in enumerate(prs.slides):
page_num = i + 1
img_idx = 0
for shape in slide.shapes:
if shape.shape_type == MSO_SHAPE_TYPE.PICTURE:
img_idx += 1
image = shape.image
# 保存图片
ext = image.ext or "png"
img_filename = f"{page_num}_{img_idx}.{ext}"
img_path = save_dir / img_filename
with open(img_path, "wb") as f:
f.write(image.blob)
images.append(ImageInfo(
page_number=page_num,
image_idx=img_idx,
path=str(img_path),
description=f"第{page_num}页图片{img_idx}",
))
return images第五章:技术突破:解决"逻辑断层"问题
5.1 语义补全:为"无名"页面赋予灵魂
很多PPT页面只有图表没有标题。如果直接索引,向量特征会非常模糊。
技术分析 :我们引入了TitleGenerator类。利用轻量化模型(如Qwen3:8b)对页面文字进行摘要,自动生成20字以内的概括性标题。这不仅增强了子块的语义特征,也为后续的标题相似度合并提供了依据。
python
# src/processor/title_generator.py
class TitleGenerator:
"""使用LLM为无标题页面生成标题"""
def __init__(self):
self.llm = ChatOllama(
model=config.ollama_model,
temperature=0.1,
num_predict=100, # 短输出,节省时间
)
def generate(self, text: str, existing_title: str = None) -> str:
"""根据页面内容生成标题"""
if existing_title and existing_title.strip():
return existing_title
prompt = f"""请根据以下PPT页面内容,生成一个简洁的标题(不超过20字):
{text[:500]}...
要求:
1. 标题要概括页面核心内容
2. 如果内容是步骤或操作,标题应包含动词
3. 直接输出标题,不要任何解释"""
try:
response = self.llm.invoke([HumanMessage(content=prompt)])
title = response.content.strip()
# 清理可能的引号
title = title.strip('"\'。')
return title if title else f"第X页内容"
except Exception as e:
log.warning(f"标题生成失败: {e}")
return f"第X页内容"5.2 动态合并算法:找回丢失的跨页逻辑
如何判断页面A和页面B是否属于同一个知识点?我们设计了双轨制:
1. 算法自动判定(标题相似度)
通过计算相邻页面标题的词汇重合度(Jaccard相似度)和包含关系。例如,"传感器安装(1)"与"传感器安装(2)"会被自动识别为连续逻辑。
2. 专家干预(手动标记)
我们在SlideContent解析逻辑中加入了对"演讲者备注"的监听。用户只需在PPT备注栏输入<START_BLOCK>和<END_BLOCK>,即可强制系统将特定范围的页面视为一个整体,完美解决算法无法识别的复杂业务逻辑。
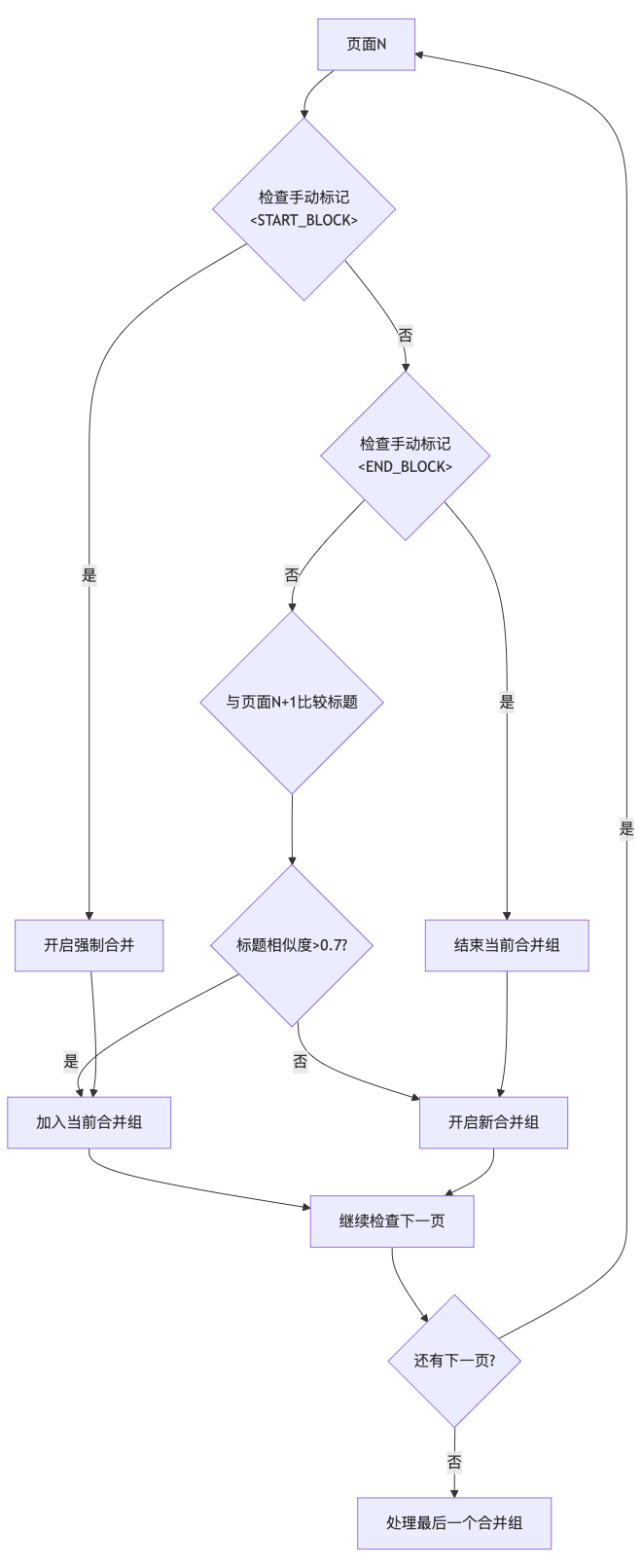
5.3 合并策略实现
python
# src/processor/merger.py
class Merger:
"""页面合并处理器"""
def check_title_similarity(self, title1: str, title2: str, threshold: float = 0.7) -> bool:
"""检查两个标题是否相似"""
if not title1 or not title2:
return False
# 完全相同
if title1 == title2:
return True
# 包含关系
if title1 in title2 or title2 in title1:
return True
# 词汇相似度
words1 = set(title1.lower().split())
words2 = set(title2.lower().split())
if not words1 or not words2:
return False
intersection = words1 & words2
union = words1 | words2
similarity = len(intersection) / len(union)
return similarity >= threshold
def parse_manual_marks(self, notes: str) -> Dict[str, bool]:
"""解析手动合并标记"""
return {
"start_block": "<START_BLOCK>" in notes.upper(),
"end_block": "<END_BLOCK>" in notes.upper(),
}
def merge_continuous_pages(
self,
slides_content: List[SlideContent],
titles: Dict[int, str] = None,
) -> List[MergeGroup]:
"""核心合并逻辑"""
merge_groups = []
current_group_start = slides_content[0].page_number
current_group_pages = [slides_content[0].page_number]
current_title = titles.get(slides_content[0].page_number)
for i in range(1, len(slides_content)):
slide = slides_content[i]
slide_title = titles.get(slide.page_number)
slide_notes = slide.notes
slide_marks = self.parse_manual_marks(slide_notes)
# 强制开启新组
if slide_marks.get("start_block"):
merge_groups.append(MergeGroup(
start_page=current_group_start,
end_page=slides_content[i - 1].page_number,
reason="手动标记开始",
page_chunks=list(range(current_group_start, slides_content[i - 1].page_number + 1)),
))
current_group_start = slide.page_number
current_group_pages = [slide.page_number]
current_title = slide_title
continue
# 检查标题相似度
if current_title and slide_title:
if self.check_title_similarity(current_title, slide_title):
current_group_pages.append(slide.page_number)
continue
# 不满足合并条件,结束当前组
merge_groups.append(MergeGroup(
start_page=current_group_start,
end_page=slides_content[i - 1].page_number,
reason="标题相同" if len(current_group_pages) > 1 else "单独页面",
page_chunks=list(range(current_group_start, slides_content[i - 1].page_number + 1)),
))
current_group_start = slide.page_number
current_group_pages = [slide.page_number]
current_title = slide_title
# 处理最后一个组
merge_groups.append(MergeGroup(
start_page=current_group_start,
end_page=slides_content[-1].page_number,
reason="最后页面",
page_chunks=list(range(current_group_start, slides_content[-1].page_number + 1)),
))
return merge_groups第六章:图文对齐技术
6.1 为什么需要图文对齐?
在PPT中,图片通常是文字的视觉化补充。传统RAG系统往往只处理文本,导致图片中的关键信息丢失。例如:
- 传感器接线图中的引脚标识
- 设备故障示意图中的异常现象
- 操作流程图中的决策节点
6.2 占位符技术实现
我们没有采用复杂的多模态大模型直接对图片进行推理(成本高且慢),而是采用了 **"文本锚点+本地渲染"**的轻量化方案:
- 在解析阶段,
image_handler将图片提取并存储。 - 在构建Chunk时,系统会在文本相应位置插入Markdown格式的图片占位符:
。 - 优势:LLM在处理上下文时,知道这里有一张图片及其含义;前端渲染时,能直接还原图文并茂的排版。
python
# src/processor/chunking.py
class ChunkingProcessor:
"""分块处理器"""
def create_chunk(
self,
slide_content: SlideContent,
images: List[ImageInfo] = None,
file_name: str = "",
title: Optional[str] = None,
image_server_url: str = "",
) -> PageChunk:
"""创建单个页面的分块"""
effective_title = title or slide_content.title
content_parts = []
# 添加标题
if effective_title:
content_parts.append(f"# {effective_title}")
# 添加正文
if slide_content.text:
content_parts.append(slide_content.text)
# 添加图片占位符
if images:
for img in images:
desc = img.description or f"第{slide_content.page_number}页图片"
if image_server_url:
img_rel_path = f"{img.path.parent.name}/{img.path.name}"
img_url = f"{image_server_url}/{quote(str(img_rel_path), safe='/')}"
else:
img_url = img.path
content_parts.append(f"")
# 添加备注
if slide_content.notes:
content_parts.append(f"【备注】{slide_content.notes}")
content = "\n\n".join(content_parts)
# 生成唯一ID
file_hash = hashlib.md5(file_name.encode("utf-8")).hexdigest()[:8]
chunk = PageChunk(
id=f"{file_hash}_{slide_content.page_number}",
file_name=file_name,
page_number=slide_content.page_number,
content=content,
title=effective_title,
metadata={"has_images": len(images) > 0 if images else False},
)
return chunk第七章:混合检索策略
7.1 为什么需要混合检索?
PPT文档包含两类信息:
- 专有名词:如"PLC"、"DAQ箱"、"CAN节点"等
- 语义概念:如"故障排查"、"参数配置"等
单一检索方式难以覆盖所有场景:
- 向量检索:对专有名词效果差(可能没有语义相似性)
- BM25:对新概念或短查询效果差
因此采用BM25 + Vector混合检索。
7.2 混合检索架构
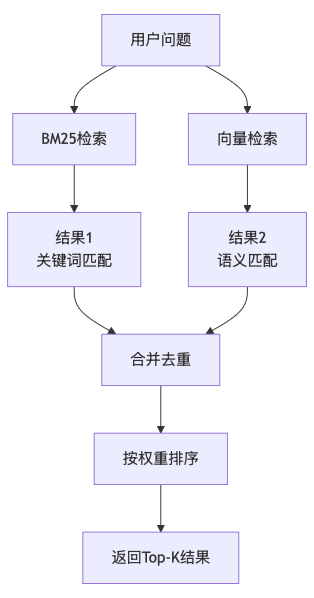
7.3 混合检索实现
python
# src/retriever/hybrid_retriever.py
class HybridRetriever:
"""混合检索器:BM25 + 向量"""
def __init__(self, vector_store: VectorStore = None):
self.vector_store = vector_store or VectorStore()
self.bm25_weight = config.bm25_weight # 默认0.4
self.vector_weight = config.vector_weight # 默认0.6
self._initialize_bm25()
def get_relevant_documents(
self,
query: str,
k: int = None,
file_name: str = None,
) -> List[PageChunk]:
"""混合检索核心逻辑"""
results = {"bm25": [], "vector": []}
# BM25 检索
if self.bm25_retriever:
bm25_results = self.bm25_retriever.invoke(query)
for doc in bm25_results:
if file_name is None or doc.metadata.get("file_name") == file_name:
results["bm25"].append(doc)
# 向量检索
vector_results = self.vector_store.search(query, k=k, file_name=file_name)
results["vector"] = vector_results
# 合并结果
merged = self._merge_results(results["bm25"], results["vector"], k)
return merged
def _merge_results(
self,
bm25_docs: List[Document],
vector_chunks: List[PageChunk],
k: int,
) -> List[PageChunk]:
"""合并 BM25 和向量检索结果"""
seen_pages = set()
merged = []
weighted_results = []
# 添加 BM25 结果
for doc in bm25_docs:
page_num = doc.metadata.get("page_number", 0)
if page_num not in seen_pages:
weighted_results.append({
"chunk": self._doc_to_chunk(doc),
"score": self.bm25_weight,
"source": "bm25",
})
# 添加向量结果
for chunk in vector_chunks:
if chunk.page_number not in seen_pages:
weighted_results.append({
"chunk": chunk,
"score": self.vector_weight,
"source": "vector",
})
# 按权重排序,返回 top-k
weighted_results.sort(key=lambda x: x["score"], reverse=True)
for item in weighted_results:
if len(merged) >= k:
break
if item["chunk"].page_number not in seen_pages:
seen_pages.add(item["chunk"].page_number)
merged.append(item["chunk"])
return merged7.4 权重调优
BM25的必要性 :工业PPT中充斥着大量的专有名词(如DAQ-900、PLC-X1)。这些词在向量空间中可能没有明显的语义倾向,但关键词匹配极其精准。
权重调优 :系统支持动态调整权重。对于术语密集的文档,我们可以调高bm25_weight;对于侧重方法论的文档,则调高vector_weight。
python
# streamlit 侧边栏配置
bm25_w = st.slider("BM25 权重", 0.0, 1.0, 0.4)
vector_w = st.slider("向量检索权重", 0.0, 1.0, 0.6)
st.session_state.rag_chain.hybrid_retriever.set_weights(bm25_w, vector_w)第八章:父子分块构建
8.1 分块策略概览
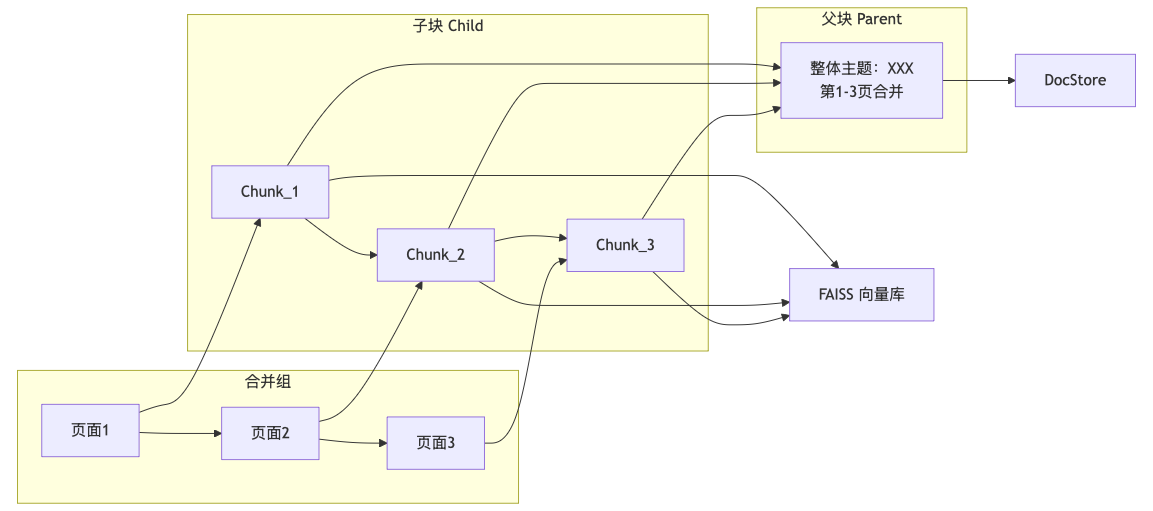
8.2 父块构建实现
python
# src/processor/parent_builder.py
class ParentBuilder:
"""父块构建器"""
def build(
self,
merge_group: MergeGroup,
page_chunks: Dict[int, PageChunk],
file_name: str,
) -> Tuple[ParentChunk, Dict[str, str]]:
"""构建父块(仅多页合并时需要)"""
# 单页不需要父块
if len(merge_group.page_chunks) == 1:
return None, {}
child_ids = []
contents = []
for page_num in merge_group.page_chunks:
if page_num in page_chunks:
chunk = page_chunks[page_num]
child_ids.append(chunk.id)
contents.append(chunk.content)
# 构建父块内容格式
first_chunk = page_chunks.get(merge_group.page_chunks[0])
main_title = first_chunk.title if first_chunk else ""
parts = [f"# 整体主题:{main_title}(第{merge_group.start_page}-{merge_group.end_page}页)\n"]
for page_num in merge_group.page_chunks:
if page_num in page_chunks:
chunk = page_chunks[page_num]
parts.append(f"---\n[第{page_num}页]\n{chunk.content}")
parent_content = "\n".join(parts)
file_hash = hashlib.md5(file_name.encode("utf-8")).hexdigest()[:8]
parent_id = f"{file_hash}_parent_{merge_group.start_page}_{merge_group.end_page}"
parent = ParentChunk(
id=parent_id,
file_name=file_name,
start_page=merge_group.start_page,
end_page=merge_group.end_page,
content=parent_content,
child_chunk_ids=child_ids,
metadata={
"merge_reason": merge_group.reason,
"page_count": len(child_ids),
},
)
# 建立子块到父块的映射
child_to_parent = {child_id: parent_id for child_id in child_ids}
return parent, child_to_parent8.3 父块内容格式示例
markdown
# 整体主题:传感器安装步骤(第5-9页)
---
[第5页]
# 传感器安装准备

准备安装前,请确认以下工具已准备就绪...
---
[第6页]
# 安装位置选择

选择安装位置时,应考虑以下因素...
---
[第7页]
# 固定传感器

使用M8螺栓将传感器固定在安装板上...第九章:问答生成与图文并茂展示
9.1 检索与生成流程
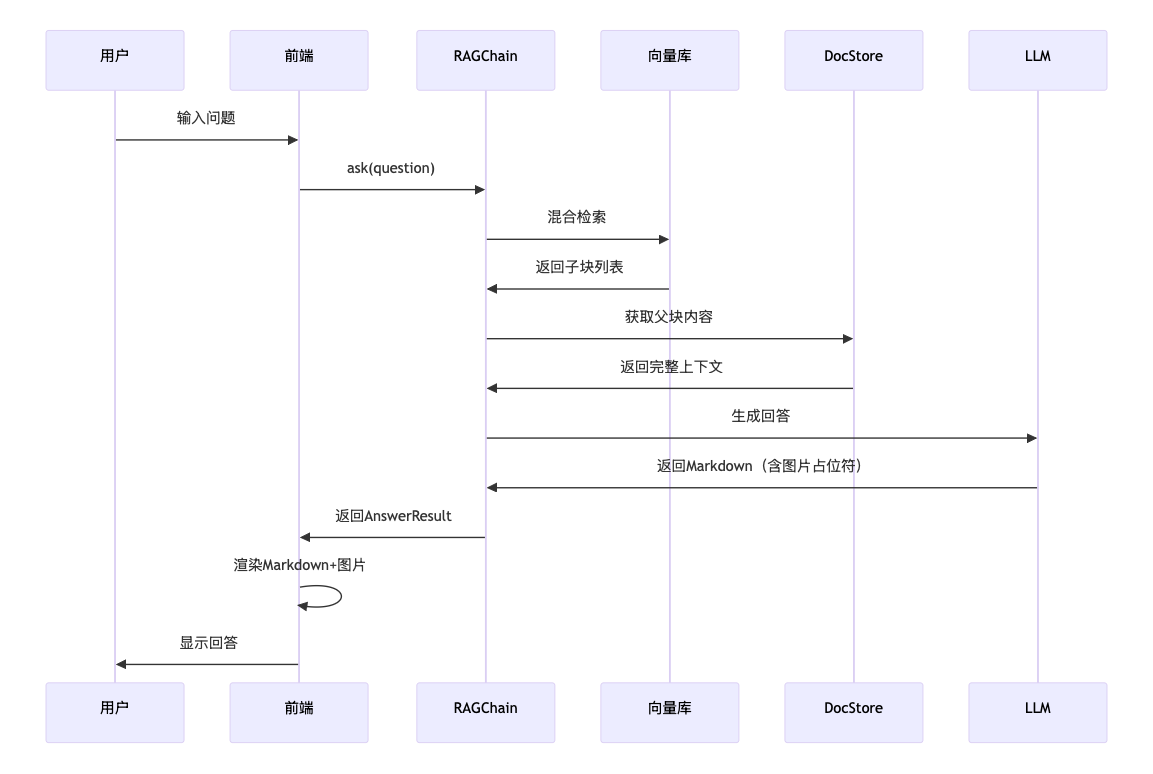
9.2 前端图片渲染
python
# app/streamlit_app.py
# 解析 Markdown 中的图片占位符
import re
img_pattern = r'!\[([^\]]*)\]\(([^)]+)\)'
for match in re.finditer(img_pattern, content):
desc = match.group(1) # 图片描述
url = match.group(2) # 图片URL
# 使用 Streamlit 显示图片
st.image(url, caption=desc)第十章:核心技术总结
10.1 核心设计总结
| 问题 | 解决方案 |
|---|---|
| PPT排版灵活 | 以"页"为最小单位,不做细粒度切分 |
| 图文相关展示 | 提取图片,生成URL占位符,合并到文本块 |
| 页面逻辑跳跃 | LLM判断标题相似度 + 手动标记控制 |
| 跨页内容不完整 | 父子分块架构,检索子块返回父块 |
10.2 关键代码位置
src/
├── models.py # 数据模型定义
├── parser/
│ ├── pptx_parser.py # PPT文本提取
│ └── image_handler.py # 图片提取处理
├── processor/
│ ├── title_generator.py # 标题生成
│ ├── chunking.py # 子块创建
│ ├── merger.py # 页面合并判断
│ └── parent_builder.py # 父块构建
├── storage/
│ ├── vector_store.py # FAISS向量库
│ └── doc_store.py # 父块存储
├── retriever/
│ └── hybrid_retriever.py # 混合检索
├── rag/
│ └── chain.py # RAG主流程
└── server/
└── image_server.py # 图片HTTP服务10.3 技术创新点
1. 智能标题生成
- 利用轻量级LLM为无标题页面生成概括性标题
- 增强子块语义特征,为页面合并提供依据
2. 双轨制页面合并
- 算法自动判定:基于标题相似度的智能合并
- 专家干预:手动标记控制复杂业务逻辑
3. 图文对齐轻量化方案
- 采用"文本锚点+本地渲染"替代多模态大模型
- 保持LLM上下文完整性,同时支持前端图文并茂展示
4. 混合检索优化
- BM25处理专有名词检索
- 向量检索处理语义概念
- 动态权重调优适应不同文档特性
第十一章:实施建议与优化方向
11.1 项目实施建议
性能优化
对于超大规模PPT,标题生成建议采用批处理(Batch Inference),显著提升处理效率。
交互增强
在Streamlit前端渲染时,建议不仅展示回答,还要在高亮处标注出引用了哪一页的图片,增强答案的可信度。
11.2 可扩展方向
- 图片存储升级:从本地文件系统升级为MinIO
- DocStore升级:从JSON文件升级为Redis/MongoDB
- 向量库升级:从FAISS升级为Chroma/Milvus
- 排序优化:增加Rerank模型进行精排
11.3 进阶优化方向
接入Rerank模型
在混合检索之后增加一步重排序,进一步过滤掉不相关的父块。
多模态增强
尝试使用GPT-4o或Qwen-VL对PPT中的复杂流程图进行文字描述化(Image-to-Text),将其注入到Chunk文本中。
结语:从"存文本"到"懂逻辑"
通过上述优化,本系统将PPT RAG的处理能力从简单的"文本提取"提升到了"语义理解"层面。
这个项目的核心价值不在于技术栈的复杂程度,而在于对业务场景的深刻理解和对用户需求的精准把握。每一项技术选择都源于对PPT文档特性的深度分析,每一个算法设计都为了解决实际业务中的痛点问题。
最终实现的效果是:让大模型真正"看懂"PPT的逻辑结构,理解图文之间的关系,感知跨页内容的完整性,从而给出准确、全面、有价值的回答。
项目源代码
完整的项目代码和更详细的实现,请访问我的知识星球( https://t.zsxq.com/CCi0k ),获取完整系统项目源代码。