一、重点:Redis Cluster(集群)模式
1. 什么是Cluster模式
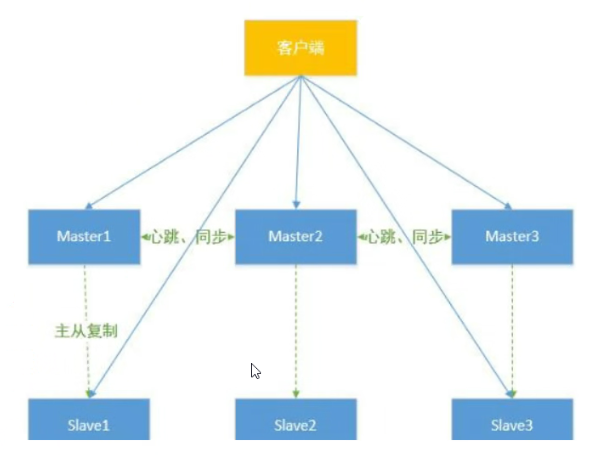
Redis Cluster模式是Redis为解决数据量大、水平扩展需求 设计的分布式解决方案,核心功能是结合数据分片 与高可用保障 ------既通过哈希槽划分数据实现节点间的负载均衡,又支持节点故障后的自动切换,避免单点故障,适用于需要横向扩展存储能力的场景。
2. 运行条件
服务器数量:至少需要6台服务器(推荐配置:3个Master节点 + 每个Master对应1个Slave节点)
Master节点要求 :需为奇数个Master(保障投票选举的有效性,避免平票)
主从复制:每个Master节点至少关联1个Slave节点,用于主节点故障时的角色承接
特殊规则:挂掉的Master节点仍会参与投票过程,确保选举机制的完整性
3. 核心工作原理
(1)数据分片:基于哈希槽的分布式存储
哈希槽划分 :将Redis数据空间划分为16384个哈希槽(Slots),所有数据通过哈希算法映射到对应槽位
槽位分配:每个Master节点负责一部分槽位(可手动配置或自动分配),Slave节点不直接存储槽位数据,仅作为对应Master的副本同步数据
数据路由:客户端访问数据时,先通过哈希计算确定目标槽位,再定位到负责该槽位的Master节点,实现分布式存储与负载均衡
(2)节点通信:基于Gossip协议的状态同步
集群中所有节点通过Gossip协议定期交换信息,内容包括:各节点的存活状态、槽位分配情况、主从关系等
该协议确保集群内节点状态一致,当槽位分配或节点角色变化时,能快速同步到所有节点,避免信息偏差
(3)故障处理:主从切换与槽位接管
① 故障检测:节点通过心跳检测感知其他节点状态,若Master节点故障,其关联的Slave节点会优先检测到故障
② 新主选举:故障Master的Slave节点会参与选举,最终选出1个Slave升级为新Master
③ 槽位接管:新Master自动接管原Master负责的所有哈希槽,继续提供数据服务
④ 集群降级:若故障Master无关联Slave节点,集群会降级为"部分可用"(仅其他Master的槽位可正常访问)或"不可用"(视配置而定)
二、Cluster模式与Sentinel(哨兵)模式的区别
| 对比维度 | Cluster模式 | Sentinel模式 |
|---|---|---|
| 核心功能 | 数据分片(水平扩展)+ 高可用(故障切换) | 仅高可用(主从故障自动转移),无数据分片 |
| 数据分布 | 16384个哈希槽,节点仅存对应槽位数据 | 主从节点存储全量数据,从节点是主节点副本 |
| 适用场景 | 数据量大、需横向扩展(如海量用户数据存储) | 数据量小、读多写少(如高频读缓存场景) |
| 节点通信 | 基于Gossip协议交换槽位与节点状态 | 基于"hello频道"相互监听,同步故障信息 |
| 故障处理 | 主节点故障时,Slave升级并接管哈希槽 | 选举Leader哨兵,从所有Slave中选新主节点 |
三、Redis持久化机制(AOF + RDB)
持久化是Redis保障数据不丢失的核心手段,通过将内存数据持久化到磁盘,避免重启后数据清空。
1. RDB持久化(数据快照)
触发方式(至少2种)
手动触发:
save命令:同步执行,阻塞Redis进程直到RDB文件生成(生产环境不推荐,易影响服务)
bgsave命令:异步执行,Redis fork子进程生成RDB文件,主进程正常处理请求(生产常用)
自动触发:
配置save规则(如save 900 1:900秒内有1次写操作即触发bgsave)
主从复制时,主节点向从节点同步数据前,自动执行bgsave生成快照
2. AOF持久化(日志追加)
触发方式
实时写入触发 (由appendfsync配置控制)
always:每个写命令立即刷盘(最安全,性能最差)
everysec:每秒刷盘1次(默认配置,平衡安全与性能)
no:由操作系统决定刷盘时机(性能最好,丢数据风险高)
AOF重写触发(优化日志文件大小):
手动:执行bgrewriteaof命令,子进程合并冗余命令重写AOF文件;
自动:通过auto-aof-rewrite-percentage(文件增长比例)+ auto-aof-rewrite-min-size(最小文件大小)配置,满足条件自动重写
四、Redis常见故障及解决方案
1. 缓存雪崩
定义:大量缓存数据同时过期失效,或Redis服务宕机,导致所有请求直接冲击数据库,造成数据库过载不可用;
解决/预防:
给缓存过期时间加随机值,避免大量Key同时失效
搭建Redis集群(如Cluster模式),避免单点故障
增加服务降级、限流措施,限制数据库请求量
数据库配置读写分离,分散查询压力
2. 缓存穿透
定义:请求不存在的数据(既不在缓存也不在数据库),如恶意请求无效ID,持续绕过缓存访问数库,消耗数据库资源。
解决/预防:
缓存空值(对不存在的数据缓存空结果,设置短过期时间)
用布隆过滤器过滤不存在的请求
接口层增加参数校验,拦截非法请求
3. 缓存击穿
定义:热点Key过期时,大量请求同时访问该Key,直接冲击数据库;
解决/预防:
热点Key设置为"永不过期"
加互斥锁(如SETNX命令),仅允许1个线程更新缓存,其他线程等待
五、Redis优化方案
1. 内存碎片优化
内存碎片是Redis频繁增删改后产生的零散空闲内存,优化方式:
开启自动碎片整理(Redis 4.0+ 配置activedefrag yes)
避免频繁操作大Key,将大Key拆分为多个小Key(如将大哈希表拆分为多个小哈希表)
必要时重启Redis(需先完成持久化,避免数据丢失)
2. 淘汰与命中机制调整
淘汰机制(内存满时的清理策略):
优先选择allkeys-lru(淘汰最少访问的Key),适配热点数据场景;
按需选择volatile-lru(仅淘汰带过期时间的最少访问Key)
命中机制(提升缓存命中率):
合理设置过期时间,避免热点数据过早失效
缓存全量热点数据,优化Key设计(避免大Key、冗余Key)
六、Redis Cluster 模式搭建步骤(3主3从)
1. 环境准备
服务器:同一台机器模拟6个节点(端口6001-6006,3主3从)。
目录创建:
Bash
cd /etc/redis/
mkdir -p redis-cluster/redis600{1..6}2. 配置文件修改(以6001为例,其他节点同理)
编辑/etc/redis/redis-cluster/redis6001/redis.conf:
Plain
# 注释bind,监听所有网卡
# bind 127.0.0.1
protected-mode no # 关闭保护模式
port 6001 # 节点端口(6001-6006依次修改)
daemonize yes # 后台运行
cluster-enabled yes # 开启集群功能
cluster-config-file nodes-6001.conf # 集群配置文件
cluster-node-timeout 15000 # 集群超时时间(15秒)
appendonly yes # 开启AOF持久化3. 启动所有节点
Bash
for d in {1..6}; do
cd /etc/redis/redis-cluster/redis600$d
redis-server redis.conf
done
# 验证启动:ps -ef | grep redis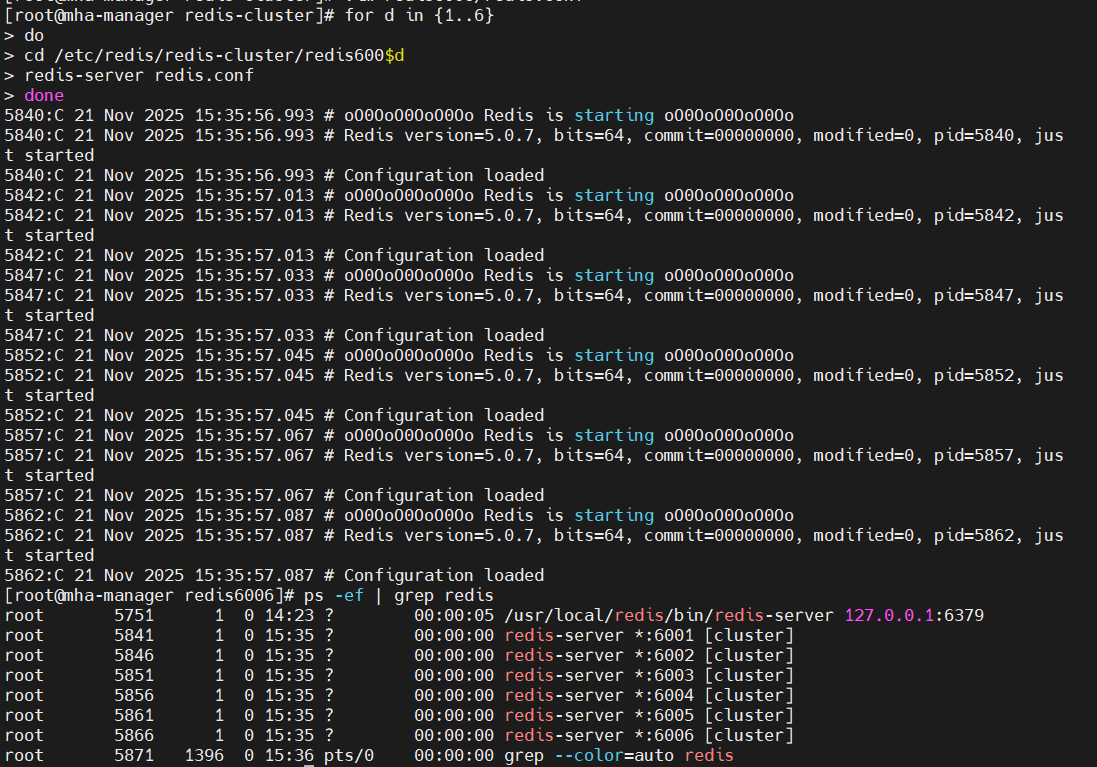
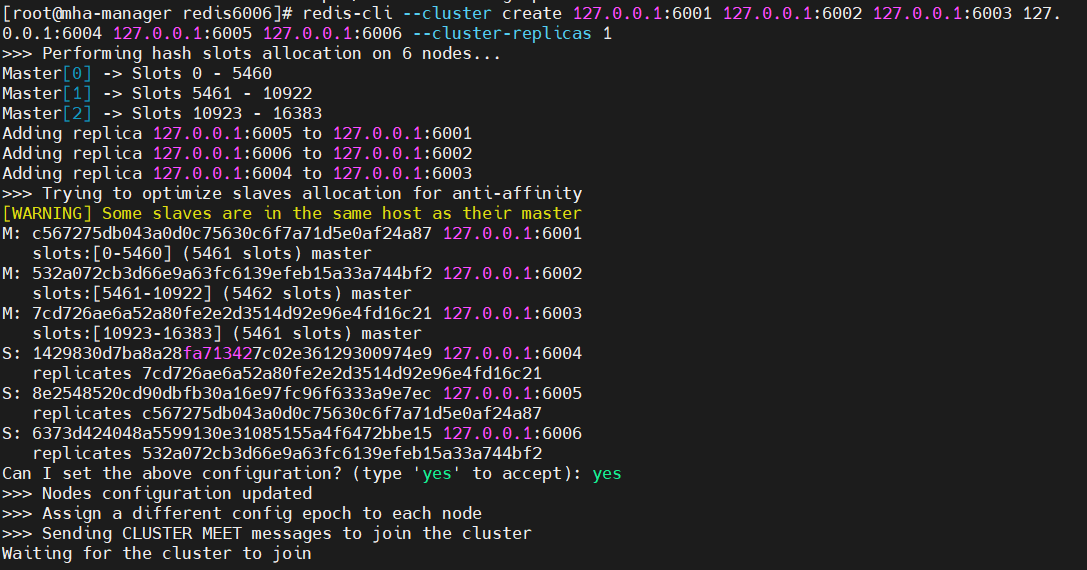
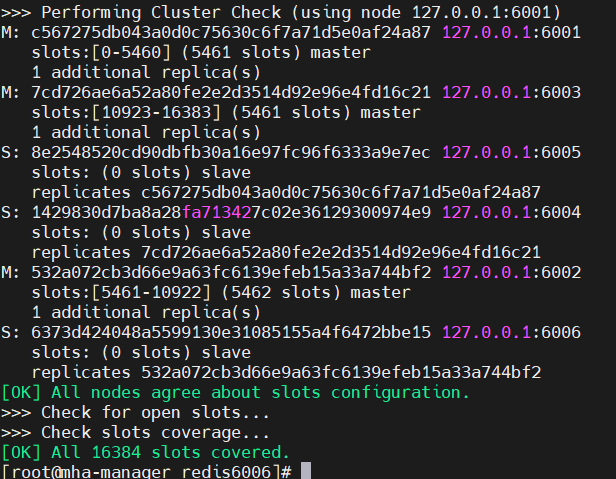
4. 创建集群
Bash
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1--cluster-replicas 1:每个主节点分配1个从节点。
交互时输入yes确认哈希槽分配。
5. 测试集群
Bash
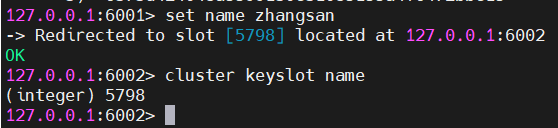
# 连接集群(-c开启节点跳转)
redis-cli -p 6001 -c
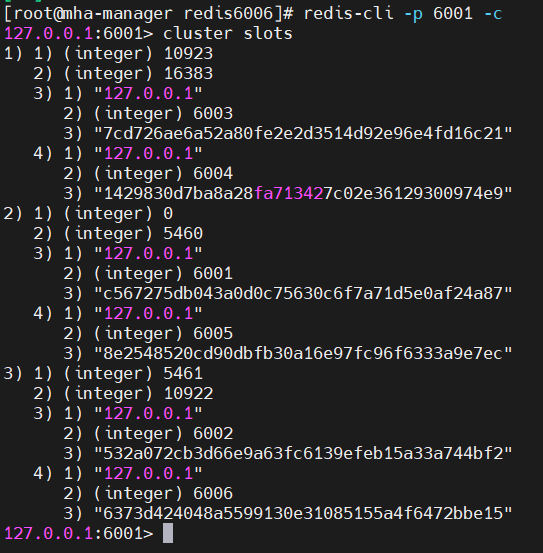
# 查看哈希槽分布
127.0.0.1:6001> cluster slots
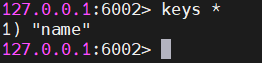
# 测试数据写入(自动路由到对应槽节点)
127.0.0.1:6001> set name zhangsan