目录
[8. 命名约定](#8. 命名约定)
[10. 命令⾏定义](#10. 命令⾏定义)
[11. 条件编译](#11. 条件编译)
[12. 头⽂件的包含](#12. 头⽂件的包含)
[12.1 头⽂件被包含的⽅式:](#12.1 头⽂件被包含的⽅式:)
[12.1.1 本地⽂件包含](#12.1.1 本地⽂件包含)
[12.1.2 库⽂件包含](#12.1.2 库⽂件包含)
[12.2 嵌套⽂件包含](#12.2 嵌套⽂件包含)
[13. 其他预处理指令](#13. 其他预处理指令)
8. 命名约定
⼀般来讲函数的宏的使⽤语法很相似。所以语⾔本⾝没法帮我们区分⼆者。
那我们平时的⼀个习惯是:
- 把宏名全部⼤写
- 函数名不要全部⼤写
9. #undef
这条指令⽤于移除⼀个宏定义
cpp
#define MAX 100
int main()
{
printf("%d\n", MAX); //此时输出100
#undef MAX
printf("%d\n", MAX); //此时会报错误,因为宏定义被消除了
return 0;
}输出结果:
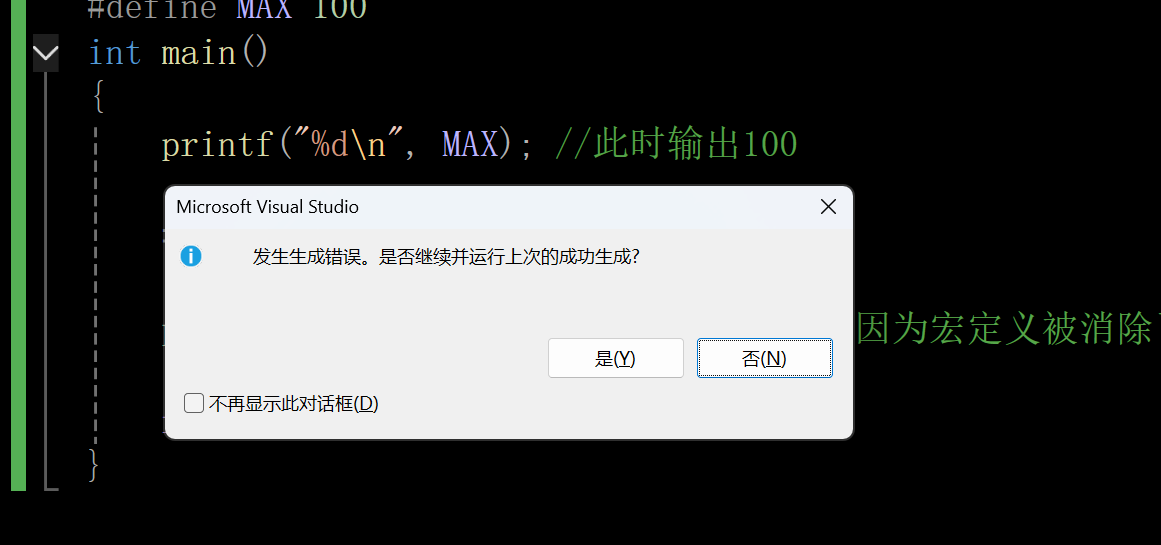
此时的我们会出先错误,这就是#undef的作用,可以取消宏定义
10. 命令⾏定义
许多C的编译器提供了⼀种能⼒,允许在命令⾏中定义符号。⽤于启动编译过程。 例如:当我们根据同⼀个源⽂件要编译出⼀个程序的不同版本的时候,这个特性有点⽤处。(假定某个程序中声明了⼀个某个⻓度的数组,如果机器内存有限,我们需要⼀个很⼩的数组,但是另外⼀个机器内存⼤些,我们需要⼀个数组能够⼤些。)
这个只能在gcc环境的情况才能看到,这里我们就不演示了
cpp
#include <stdio.h>
int main()
{
int array [ARRAY_SIZE];
int i = 0;
for(i = 0; i< ARRAY_SIZE; i ++)
{
array[i] = i;
}
for(i = 0; i< ARRAY_SIZE; i ++)
{
printf("%d " ,array[i]);
}
printf("\n" );
return 0;
}编译指令:
cpp
//linux 环境演⽰
gcc -D ARRAY_SIZE=10 programe.c11. 条件编译
在编译⼀个程序的时候我们如果要将⼀条语句(⼀组语句)编译或者放弃是很⽅便的
因为我们有条件编译指令。
⽐如说:
调试性的代码,删除可惜,保留⼜碍事,所以我们可以选择性的编译。
cpp
#include <stdio.h>
#define __DEBUG__
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<10; i++)
{
arr[i] = i;
#ifdef __DEBUG__
printf("%d\n", arr[i]);//为了观察数组是否赋值成功。
#endif //__DEBUG__
}
return 0;
}常⻅的条件编译指令:
cpp
1.
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__
//..
#endif
2.多个分⽀的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif#if #endif 的使用 (两个是一对的)
#if后面的常量表达式如果是0 的情况
cpp
//为假(0)的情况的
#define M 10
int main()
{
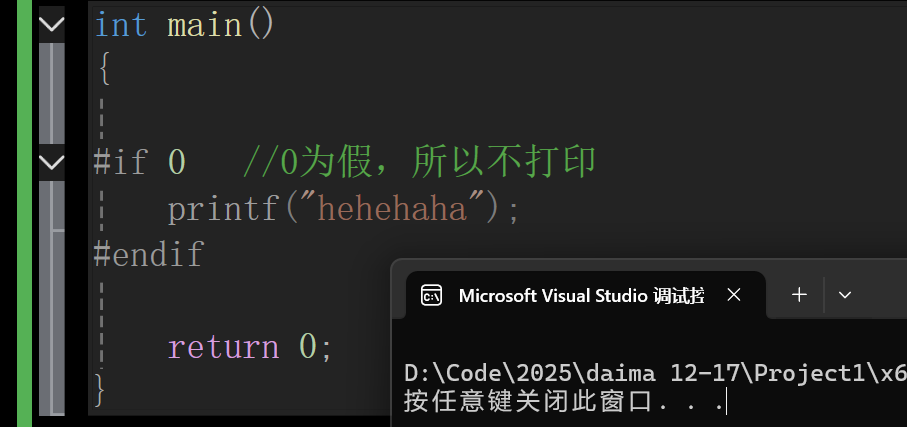
#if 0 //0为假,所以不打印
printf("hehehaha");
#endif
return 0;
}输出结果什么都没有,因为0为假,不打印
#if后面的常量表达式为真(非0)的情况
cpp
为真(非0)的情况的
#define M 10
int main()
{
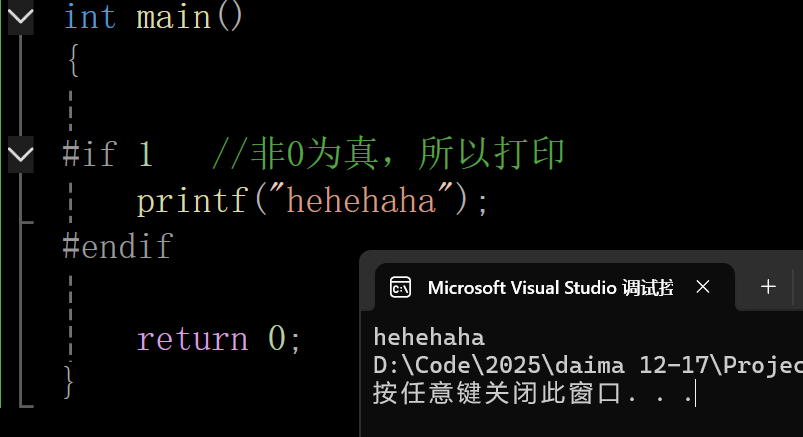
#if 1 //非0为真,所以打印
printf("hehehaha");
#endif
return 0;
}输出结果:
#if后面的表达式满足 M 的情况
cpp
满足 M 情况的
#define M 10
int main()
{
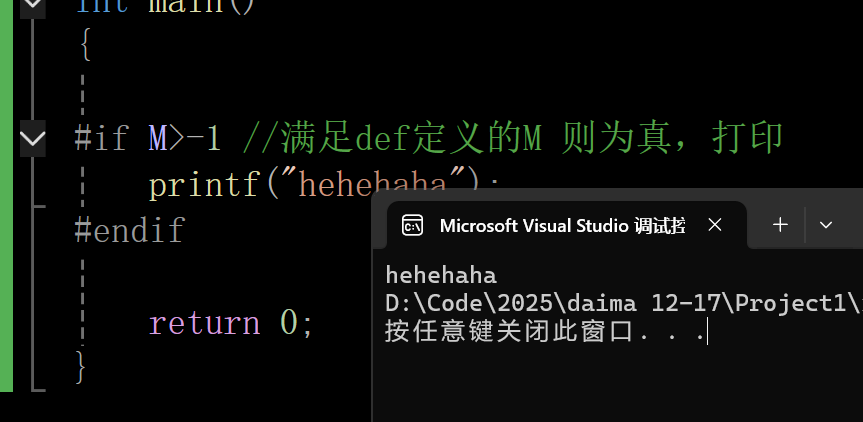
#if M>-1 //满足def定义的M 则为真,打印
printf("hehehaha");
#endif
return 0;
}输出结果:
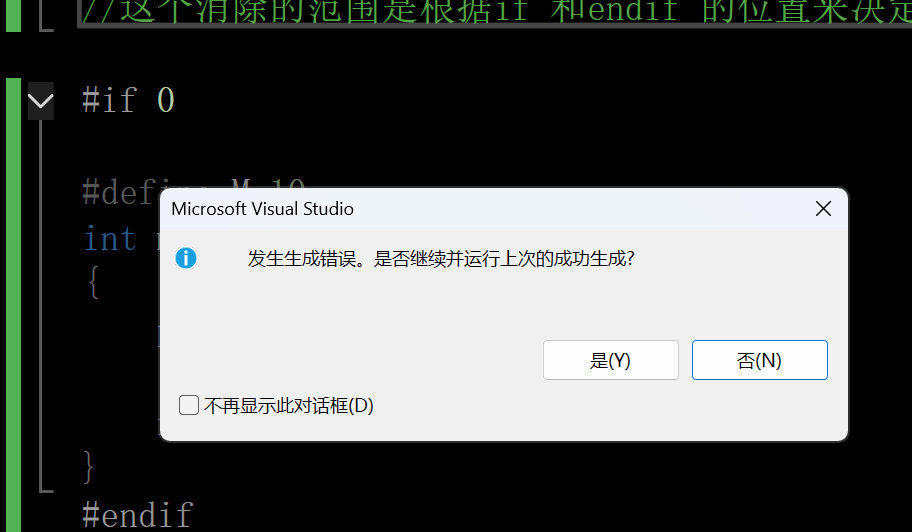
使用#if #endif 全部消除的使用
这个消除的范围是根据if 和endif 的位置来决定的,里面的都会被消除,为0则假,就消除,如果为真那就照常打印
cpp
这个消除的范围是根据if 和endif 的位置来决定的,里面的都会被消除,为0则假,就消除,如果为真那就照常打印
#if 0
#define M 10
int main()
{
printf("hehehaha");
return 0;
}
#endif此时的输出结果是会报错误的,因为全部被消除了
多个分支的条件编译
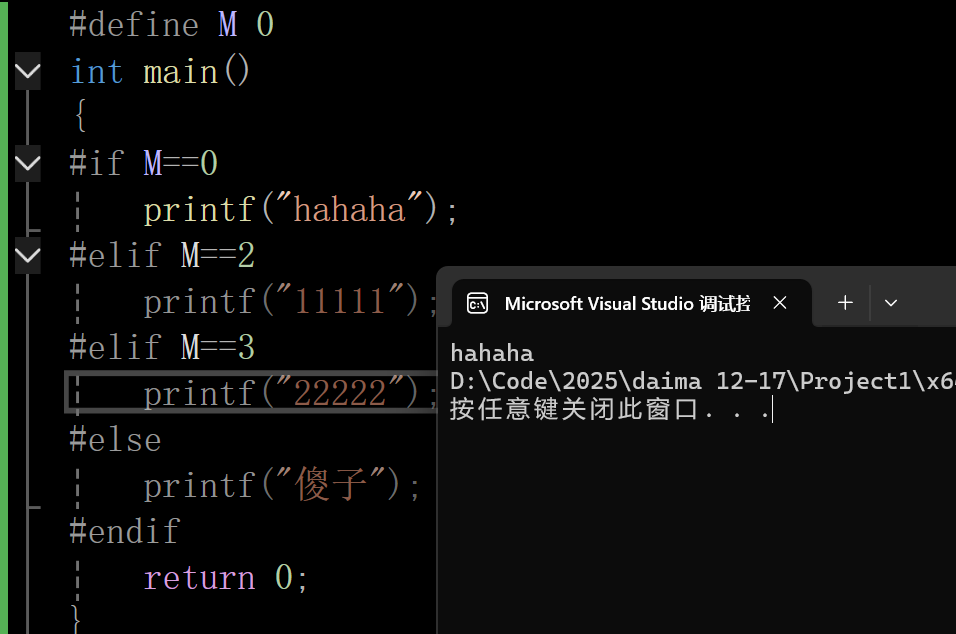
#elif #else 的使用
注意:当里面的式子满足多个的时候,它只会选择一个,即第一个执行的那个代码
cpp
#define M 0
int main()
{
#if M==0
printf("hahaha");
#elif M==2
printf("11111");
#elif M==3
printf("22222");
#else
printf("傻子");
#endif
return 0;
}输出结果:
这里的M==0,所以执行0的那行代码,后面就不会再执行了
判断是否被定义
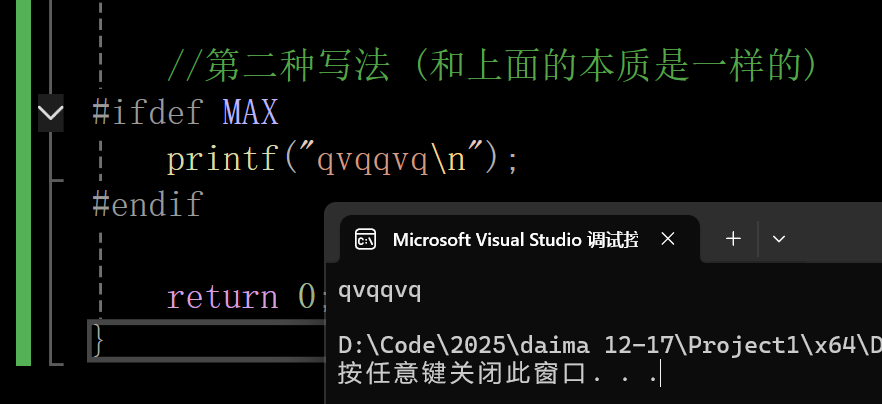
#if defined 的使用
cpp
#define MAX 1 //这里即使是0 ,也会打印,因为它只是判断你是否被定义,至于是多少,它不管
int main()
{
//第一种写法
#if defined (MAX) //判断是否被定义,如果我们定义了一个MAX则会执行打印,如果没有定义,则不会执行打印
printf("hehe\n");
#endif
//第二种写法 (和上面的本质是一样的)
#ifdef MAX
printf("qvqqvq\n");
#endif
return 0;
}输出结果:
还可以反过来判断,如果定义则不打印,不定义则打印
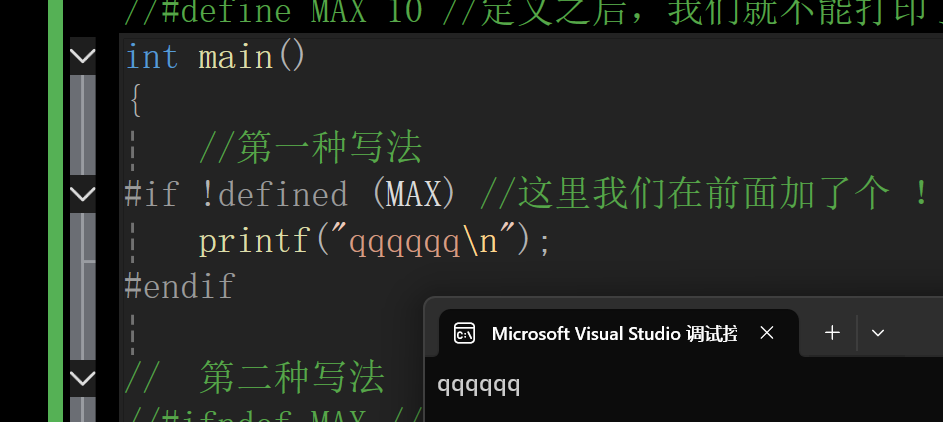
#if !defined 的使用
cpp
#define MAX 10 //定义之后,我们就不能打印了
int main()
{
//第一种写法
#if !defined (MAX) //这里我们在前面加了个 ! 于是就反过来了,此时我是没有定义MAX的,但是我们可以执行打印
printf("qqqqqq\n");
#endif
第二种写法
#ifndef MAX //这里加了个n ,注意区分,则是反过来写,不是加 !了
printf("11111\n");
#endif
return 0;
}#define MAX 10 定义之后,我们就不能打印了
#define MAX 10 没有定义的时候,我们就能打印了
输出结果:
12. 头⽂件的包含
12.1 头⽂件被包含的⽅式:
12.1.1 本地⽂件包含
cpp
#include "filename"使用的方式:
#include "add.h" 这就是我们的头文件,自己创建了一个add.h的文件,然后可以利用它
project.c文件的代码 (我开始写代码的文件名字)
cpp
#include "add.h" //这就是我们的头文件,自己创建了一个add.h的文件,然后可以利用它
int main()
{
int a = 1;
int b = 2;
int c= Add(a, b);
printf("%d\n", c);
return 0;
}add.h文件的代码 (自己后面又创建了一个头文件)
cpp
//函数的声明
int Add(int x, int y);add.c文件的代码 (后面又创建一个.c文件来完成我们的加法运算)
cpp
int Add(int x, int y)
{
return x + y;
}查找策略:
先在源⽂件所在⽬录下查找,如果该头⽂件未找到,编译器就像查找库函数头⽂件⼀样在标准位置查 找头⽂件。
如果找不到就提⽰编译错误
Linux环境的标准头⽂件的路径:
cpp
/usr/includeVS环境的标准头⽂件的路径:
cpp
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//这是VS2013的默认路径注意按照⾃⼰的安装路径去找。
12.1.2 库⽂件包含
cpp
#include <filename.h>查找头⽂件直接去标准路径下去查找,如果找不到就提⽰编译错误。
这样是不是可以说,对于库⽂件也可以使⽤ " " 的形式包含?
答案是肯定的,可以,但是这样做查找的效率就低些,当然这样也不容易区分是库⽂件还是本地⽂件 了。
cpp
如: #include <stdio.h>
注意:它也可以用 " " ,即"stdio.h" 虽然都可以,但是不推荐12.2 嵌套⽂件包含
我们已经知道,#include指令可以使另外⼀个⽂件被编译。就像它实际出现于 #include指令的地方一样
这种替换的⽅式很简单:预处理器先删除这条指令,并⽤包含⽂件的内容替换。
⼀个头⽂件被包含10次,那就实际被编译10次,如果重复包含,对编译的压⼒就⽐较⼤。
project.c文件
cpp
#include "add.h"
#include "add.h"
#include "add.h"
#include "add.h"
#include "add.h"
//这里我们如果输入五次这样的头文件,则代码运行的时候,add.h里面的代码会重复5次
//这里在gcc的环境下,可以观察到
int main()
{
return 0;
}add.h文件
cpp
int Add(int x, int y);
struct SS
{
int arr[5];
int n;
char c;
};如果直接这样写,project.c⽂件中将add.h包含5次,那么add.h⽂件的内容将会被拷⻉5份在project.c中。
如果add.h⽂件⽐较⼤,这样预处理后代码量会剧增。如果⼯程⽐较⼤,有公共使⽤的头⽂件,被⼤家 都能使⽤,⼜不做任何的处理,那么后果真的不堪设想。
如何解决头⽂件被重复引⼊的问题?答案:条件编译。
每个头⽂件的开头写:
cpp
#ifndef __ADD_H__
#define __ADD_H__
//
头⽂件的内容
#endif //__ADD_H_或者
cpp
#pragma once就可以避免头⽂件的重复引⼊。
代码如下:
add.h文件
第一种写法
cpp
#ifndef __ADD__H
#define __ADD__H
int Add(int x, int y);
struct SS
{
int arr[5];
int n;
char c;
};
#endifadd.h文件
第二种写法
cpp
#pragma once
int Add(int x, int y);
struct SS
{
int arr[5];
int n;
char c;
};此时我们即使包含了5次add.h的头文件,我们在运行代码的时候,它只会运行一次,这里的情况我们需要gcc的环境下才能观察的到,这里我们知道这个就行了
13. 其他预处理指令
cpp
#error
#pragma
#line
...
不做介绍,⾃⼰去了解。
#pragma pack() 在结构体部分介绍。参考《C语⾔深度解剖》学习
以上就是我们的全部内容了!!!!!!!