Any 和 AnyObject 有什么区别?
Any 和 AnyObject 是 Swift 中用于表示"任意类型"的两个关键字,核心区别集中在适用类型范围、类型转换规则和使用场景上,理解二者差异是避免类型安全问题的关键,也是面试高频考点。
首先从适用类型范围来看,Any 是真正意义上的"任意类型",支持所有 Swift 类型,包括值类型(如 Int、String、结构体、枚举)、引用类型(如类实例)、函数类型(() -> Void)甚至 Optional 类型;而 AnyObject 仅支持引用类型,即类的实例、类类型本身,不支持值类型和函数类型,若强制将值类型赋值给 AnyObject,Swift 会自动将其包装为对应的包装类(如 Int 包装为 NSNumber,String 包装为 NSString),这一隐式转换可能带来潜在风险。
其次是类型转换的差异,Any 类型转换需通过"as?"(可选绑定)或"as!"(强制解包),且转换后需明确指定目标类型,因为其可能存储任何类型;AnyObject 由于仅存储引用类型,可使用"as?"转换为具体类类型,也支持通过"as!"进行强制转换,同时在与 Objective-C 交互时,AnyObject 可隐式转换为 id 类型,这是其与 OC 兼容的重要特性。
使用场景上,Any 更适合 Swift 纯原生开发中需要兼容多种类型的场景,例如存储不同类型的集合(如 Any = 1, "hello", { print("func") })、函数参数需要接收任意类型输入等;AnyObject 主要用于与 Objective-C 交互的场景,因为 OC 中没有值类型概念,所有对象都是 id 类型(对应 Swift 的 AnyObject),例如 UIKit 框架中的 API 经常使用 AnyObject 作为参数或返回值(如 view.subviews 返回 AnyObject),此外也可用于纯 Swift 中仅处理类实例的场景(如存储不同类的实例集合 AnyObject)。
为了更清晰对比,可参考以下表格:
| 特性 | Any | AnyObject |
|---|---|---|
| 适用类型范围 | 值类型、引用类型、函数类型、Optional | 仅引用类型(类实例、类类型) |
| 与 Objective-C 兼容 | 不直接兼容,需显式转换 | 直接兼容,对应 OC 中的 id 类型 |
| 隐式包装行为 | 无隐式包装 | 值类型赋值时自动包装为包装类 |
| 典型使用场景 | Swift 原生多类型兼容场景 | 与 OC 交互、仅处理类实例的场景 |
面试加分点:能指出 AnyObject 对值类型的隐式包装可能导致的问题(如 Int 包装为 NSNumber 后,比较相等时需注意类型匹配),或举例说明 Optional 类型存储在 Any 中时的解包细节(如 let value: Any = Optional(1),需先解包 Optional 再转换为 Int)。
记忆法:"Any 全包,AnyObject 只包类"------ 用"全包"记忆 Any 支持所有类型,"只包类"记忆 AnyObject 仅支持引用类型(类);结合场景记忆:"Swift 原生用 Any,OC 交互用 AnyObject",快速对应核心使用场景。
逃逸闭包与非逃逸闭包的区别是什么?
逃逸闭包(@escaping)和非逃逸闭包(默认,@noescape 已在 Swift 3 中废弃)的核心区别的是闭包是否在函数返回后才被执行,这一差异直接影响内存管理、生命周期和使用规则,是 Swift 并发编程和内存优化的基础考点。
首先明确定义:非逃逸闭包是指闭包在函数体内被执行完毕,函数返回前闭包的生命周期就已结束,闭包不会"逃离"函数的作用域;逃逸闭包则是闭包在函数返回后才被执行,闭包的生命周期超出了原函数的作用域,可能在函数返回后通过异步回调、存储在外部变量等方式被调用。
从生命周期与内存管理来看,非逃逸闭包由于在函数返回前执行完毕,编译器可进行明确的生命周期管理:若闭包捕获了外部变量(如 self),编译器会自动确保变量在闭包执行期间有效,且无需担心循环引用(因为闭包执行完后会立即释放,不会长期持有捕获的变量);而逃逸闭包由于在函数返回后才执行,需要长期持有捕获的变量,若捕获了 self 且未处理,极易导致循环引用(例如将逃逸闭包存储在 self 的属性中,self 持有闭包,闭包又持有 self,形成循环),因此逃逸闭包捕获 self 时必须显式使用 self(Swift 强制要求),提醒开发者处理内存问题(如使用 weak self、unowned self 避免循环引用)。
使用场景上,非逃逸闭包常见于同步执行的场景,例如数组的遍历方法(map、filter、forEach)、函数内部同步处理逻辑(如计算回调),示例代码:
// 非逃逸闭包:函数体内同步执行闭包,函数返回前闭包已执行完毕
func processData(data: [Int], handler: (Int) -> Void) {
for num in data {
handler(num * 2) // 闭包同步执行
}
}
// 调用:闭包在 processData 返回前执行
processData(data: [1,2,3]) { print($0) }逃逸闭包常见于异步操作、延迟执行或闭包被存储的场景,例如网络请求回调、定时器回调、闭包被存储在外部变量/属性中,示例代码:
// 逃逸闭包:用 @escaping 标记,闭包被存储在属性中,函数返回后才执行
class NetworkManager {
var completionHandler: (() -> Void)? // 存储闭包的属性
func requestData(completion: @escaping () -> Void) {
self.completionHandler = completion // 闭包被存储,逃离函数作用域
// 模拟异步网络请求,1秒后执行闭包
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
completion() // 函数返回后才执行闭包
}
}
}
// 调用:requestData 返回后,闭包仍可能被执行
let manager = NetworkManager()
manager.requestData {
print("请求完成")
}语法规则上,非逃逸闭包无需显式标记(默认行为),且不能被存储在函数外部的变量/属性中,也不能用于异步执行的上下文(如 DispatchQueue.async);逃逸闭包必须用 @escaping 显式标记,允许被存储或用于异步场景,且捕获 self 时必须显式写 self(即使在当前作用域可省略的情况下),示例:
class Test {
func testEscaping() {
// 逃逸闭包捕获 self 必须显式写 self
let closure: @escaping () -> Void = {
print(self) // 必须显式 self
}
}
func testNoEscaping(handler: () -> Void) {
// 非逃逸闭包捕获 self 可省略(也可显式写)
handler() {
print(self) // 可省略 self,编译器自动处理
}
}
}面试加分点:能说明逃逸闭包的底层实现(如闭包被包装为堆上的对象,以支持长期存在),或对比 Swift 3 前后 @noescape 的变化(Swift 3 后非逃逸闭包成为默认,@escaping 仅用于逃逸场景,简化语法并提升安全性);能结合循环引用案例,分析逃逸闭包中 weak self 和 unowned self 的使用场景差异。
记忆法:"逃逸=跑出去,非逃逸=在里面"------ 用"跑出去"记忆逃逸闭包会在函数返回后(外部)执行,"在里面"记忆非逃逸闭包在函数体内(内部)执行完毕;
CoreData 是什么?具体该如何使用?
CoreData 是 Apple 提供的一套面向对象的数据持久化框架,并非数据库本身,其核心作用是将内存中的对象模型(NSManagedObject)与持久化存储(支持 SQLite、XML、Binary、In-Memory 等存储方式,默认 SQLite)进行映射,简化数据的增删改查、缓存管理和数据迁移操作,广泛用于 iOS/macOS 应用中存储结构化数据(如用户信息、列表数据、离线缓存等)。其底层基于对象关系映射(ORM)思想,允许开发者用面向对象的方式操作数据,无需直接编写 SQL 语句,大幅降低持久化开发成本。
核心组件与工作原理
CoreData 的核心组件构成"数据处理流水线",各组件职责明确:
| 组件 | 作用 |
|---|---|
| NSManagedObjectModel | 数据模型描述:定义实体(Entity)、属性(Attribute)、实体间关系(Relationship),通常通过 .xcdatamodeld 文件可视化配置 |
| NSPersistentStoreCoordinator | 存储协调器:管理持久化存储(如 SQLite 文件),负责将对象模型与存储介质关联,处理数据读写的底层逻辑 |
| NSManagedObjectContext | 上下文:数据操作的"工作台",所有增删改查都通过上下文执行,维护对象的状态(新增、修改、删除),最终通过协调器同步到存储介质 |
| NSManagedObject | 数据模型实例:对应 Entity 的具体对象,存储实际数据,可通过子类(如 User、Article)自定义属性和方法 |
| NSPersistentContainer | iOS 10+ 新增的容器类,封装了 Model、Coordinator、Context 的创建和关联,简化 CoreData 初始化流程 |
工作流程核心:通过 Context 操作 ManagedObject(增删改查)→ Context 跟踪对象状态变化 → 调用 Context 的 save() 方法 → Coordinator 将变更同步到持久化存储(如 SQLite 数据库文件)。
具体使用步骤(以 iOS 10+ 为例,基于 NSPersistentContainer)
-
创建数据模型(.xcdatamodeld) 新建 Core Data Model 文件,添加 Entity(如"User"),设置属性(如
id:Integer 64(主键)、name:String、age:Integer 16),若需实体间关系(如 User 与 Order 为一对多),可在 Relationship 中配置。可选:为 Entity 生成自定义 NSManagedObject 子类(Xcode → Editor → Create NSManagedObject Subclass),便于通过属性直接操作数据,而非通过value(forKey:)间接访问。 -
初始化 CoreData 核心组件利用 NSPersistentContainer 快速初始化,通常在 AppDelegate 或单独的 CoreData 管理类中实现:
import CoreData class CoreDataManager { // 单例模式,全局共享 CoreData 实例 static let shared = CoreDataManager() // 持久化容器 private let persistentContainer: NSPersistentContainer private init() { // 容器名称需与 .xcdatamodeld 文件名一致 persistentContainer = NSPersistentContainer(name: "DataModel") // 加载持久化存储 persistentContainer.loadPersistentStores { description, error in if let error = error as NSError? { fatalError("CoreData 初始化失败:\(error.localizedDescription)") } } } // 提供上下文供外部操作(主队列上下文,用于 UI 相关操作) var context: NSManagedObjectContext { return persistentContainer.viewContext } // 保存上下文变更(同步到存储介质) func saveContext() { let context = persistentContainer.viewContext if context.hasChanges { do { try context.save() print("CoreData 保存成功") } catch { let nserror = error as NSError fatalError("CoreData 保存失败:\(nserror.localizedDescription)") } } } } -
数据操作(增删改查)
-
新增数据 :通过上下文创建 ManagedObject 实例,设置属性后保存上下文:
// 创建 User 实例(需先生成自定义子类) let newUser = User(context: CoreDataManager.shared.context) newUser.id = 1 newUser.name = "张三" newUser.age = 25 // 保存变更 CoreDataManager.shared.saveContext() -
查询数据 :通过 NSFetchRequest 构建查询请求,可设置条件、排序、分页等:
func fetchUsers(age: Int) -> [User] { let request: NSFetchRequest<User> = User.fetchRequest() // 设置查询条件:age == 传入的参数(NSPredicate 用于过滤) request.predicate = NSPredicate(format: "age == %d", age) // 设置排序:按 id 升序 request.sortDescriptors = [NSSortDescriptor(keyPath: \User.id, ascending: true)] // 执行查询 do { let users = try CoreDataManager.shared.context.fetch(request) return users } catch { print("查询失败:\(error.localizedDescription)") return [] } } -
修改数据 :查询到目标对象后,直接修改属性并保存上下文:
let users = fetchUsers(age: 25) if let targetUser = users.first { targetUser.name = "李四" // 修改属性 CoreDataManager.shared.saveContext() // 保存变更 } -
删除数据 :查询到目标对象后,通过上下文删除并保存:
let users = fetchUsers(age: 25) if let targetUser = users.first { CoreDataManager.shared.context.delete(targetUser) // 删除对象 CoreDataManager.shared.saveContext() // 保存变更(实际删除存储中的数据) }
-
-
进阶操作(可选)
- 数据迁移:当数据模型变更(如新增属性、修改实体关系)时,需配置迁移策略(轻量级迁移可通过设置
persistentContainer.viewContext.automaticallyMergesChangesFromParent = true自动处理,复杂迁移需自定义 NSMigrationManager)。 - 后台操作:若需处理大量数据(如批量导入),避免阻塞 UI 线程,可使用后台上下文(
persistentContainer.newBackgroundContext()),操作完成后合并到主上下文。
- 数据迁移:当数据模型变更(如新增属性、修改实体关系)时,需配置迁移策略(轻量级迁移可通过设置
面试关键点与加分点
- 关键点:明确 CoreData 是 ORM 框架而非数据库,核心组件的职责,上下文的作用(状态管理、数据同步入口)。
- 加分点:能说明 CoreData 支持的存储类型差异(SQLite 适合大量结构化数据,In-Memory 适合临时数据);能解释上下文的并发类型(主队列上下文用于 UI,私有队列上下文用于后台操作);能举例说明数据迁移的场景和处理方式;能指出 CoreData 的性能优化手段(如批量操作使用
NSBatchUpdateRequest、避免频繁 save()、使用fetchLimit分页查询)。
记忆法
- 组件记忆:"Model 定结构,Container 装全家,Context 做操作,Coordinator 连存储"------ 对应 Model(数据结构)、PersistentContainer(封装核心组件)、Context(操作入口)、Coordinator(关联存储)的核心职责。
- 使用步骤记忆:"建模型 → 初始化 → 增删改查 → 保存",按"定义-初始化-操作-持久化"的逻辑链记忆,符合开发流程的自然顺序。
SQLite 是什么?它的优缺点有哪些?
SQLite 是一款轻量级的嵌入式关系型数据库,由 C 语言编写,无需独立的数据库服务器进程(进程内数据库),数据以单一文件形式存储(.db 或 .sqlite 文件),支持标准 SQL 语法和 ACID 事务特性,广泛用于移动应用、嵌入式设备和小型桌面应用中,是 iOS 开发中最基础的结构化数据持久化方案之一(CoreData 的默认存储引擎就是 SQLite)。其核心特点是"嵌入式、零配置、跨平台、轻量级",无需安装、启动服务,直接通过 API 操作数据库文件。
核心特性(基础认知)
- 嵌入式架构:无独立服务器,数据库操作与应用程序在同一进程中执行,无需网络通信,性能开销低。
- 单一文件存储:整个数据库(表、索引、数据)封装在一个文件中,便于备份、迁移(直接复制文件即可)。
- 支持标准 SQL:兼容 SQL-92 标准,支持 SELECT、INSERT、UPDATE、DELETE 等常规操作,以及 JOIN、GROUP BY、事务(BEGIN/COMMIT/ROLLBACK)、索引、触发器等高级特性。
- 跨平台:支持 iOS、Android、Windows、Linux 等几乎所有主流平台,数据库文件可在不同平台间共享。
- 零配置:无需安装、配置用户权限,开箱即用,仅需通过 API 加载数据库文件即可操作。
- 轻量级:库文件体积小(仅几百 KB),内存占用低,适合资源受限的移动设备和嵌入式环境。
优点(适用场景的核心支撑)
- 轻量高效,资源占用低:无服务器进程,避免了进程间通信的开销,数据库操作速度快;库体积小、内存占用少,不会给移动应用带来过多性能负担,即使在低端设备上也能流畅运行。
- 零配置与易用的部署:无需安装数据库服务、配置端口或用户权限,开发时仅需引入 SQLite 库(iOS 已内置 libsqlite3.tbd 库,无需额外导入),直接操作 .db 文件,部署时只需将数据库文件打包到应用或在运行时创建,迁移时复制文件即可,大幅降低开发和部署成本。
- 强兼容性与标准化:支持标准 SQL 语法和 ACID 事务(原子性、一致性、隔离性、持久性),开发者无需学习新的查询语言,熟悉 SQL 即可快速上手;跨平台特性确保数据库文件可在不同系统间复用(如 iOS 生成的 .db 文件可直接在 Android 或桌面应用中读取)。
- 灵活的存储与扩展:支持多种数据类型( INTEGER、TEXT、REAL、BLOB、NULL ),BLOB 类型可存储图片、音频等二进制数据;支持自定义函数、触发器和索引,可根据需求优化查询性能(如为常用查询字段创建索引)。
- 稳定性与可靠性:经过长期验证,是成熟稳定的数据库方案,支持事务回滚(ROLLBACK),可避免异常情况下的数据损坏;支持数据库文件加密(需通过 SQLCipher 等扩展实现),保障数据安全性。
缺点(局限与适用边界)
- 并发访问支持有限:SQLite 采用"写独占、读共享"的锁机制,同一时间只能有一个写操作执行,多个写操作会排队等待;虽然支持多线程读,但高并发写场景(如多个线程同时插入/修改数据)下会出现性能瓶颈,甚至导致死锁(需开发者手动处理线程同步),不适合高并发写入的场景(如社交应用的实时消息存储)。
- 缺乏高级数据库特性:相比 MySQL、PostgreSQL 等服务器型数据库,SQLite 不支持存储过程、复杂的用户权限管理、分区表、外键约束(默认关闭,需手动开启且支持有限)等高级特性,对于复杂业务逻辑的支撑不足。
- 单文件存储的局限性:虽然单文件便于迁移,但文件大小受限于文件系统(通常最大支持 2TB,但移动设备上实际使用时不宜过大);若数据库文件损坏,数据恢复难度较大(需依赖备份或第三方工具);且单文件无法实现分布式存储,不适合大规模数据存储场景。
- iOS 开发中需手动管理 SQL 与模型映射:相比 CoreData 的 ORM 机制,直接使用 SQLite 需手动编写 SQL 语句,且需自行处理"数据库表结构与 Swift/OC 对象模型"的映射(如将查询结果的字段值逐一赋值给对象属性),开发效率低,且容易因 SQL 语法错误或字段不匹配导致 Bug;同时需手动管理数据库版本升级(如新增表、修改字段时,需编写 ALTER TABLE 语句处理旧版本数据库)。
- 线程安全需手动保障:SQLite 本身是线程安全的,但 iOS 中使用的 libsqlite3 库默认不开启线程模式,若多线程直接操作同一数据库连接,会导致数据错乱或崩溃;需开发者手动实现线程同步(如使用串行队列包裹所有数据库操作)或为每个线程创建独立连接,增加了开发复杂度。
面试关键点与加分点
- 关键点:明确 SQLite 是嵌入式关系型数据库,核心特性(嵌入式、单文件、零配置),与服务器型数据库的本质区别(无独立进程)。
- 加分点:能结合 iOS 开发场景举例说明 SQLite 的适用场景(如离线数据缓存、本地配置存储、低并发的结构化数据存储)和不适用场景(如高并发写、大规模分布式数据);能解释 SQLite 的锁机制(写独占、读共享)对并发的影响;能对比说明 iOS 中操作 SQLite 的常用框架(如 FMDB、GRDB.swift)的作用(封装原生 C API,简化 SQL 操作和线程安全管理);能指出 SQLite 性能优化的手段(如创建合适的索引、避免 SELECT *、批量操作使用事务、关闭不必要的日志)。
记忆法
- 优点记忆:"轻、零、标、灵、稳"------ 对应轻量高效、零配置、标准化(SQL/ACID)、灵活扩展、稳定可靠。
- 缺点记忆:"并、高、单、映、线"------ 对应并发支持有限、缺乏高级特性、单文件局限、模型映射手动管、线程安全需手动保障;结合场景记忆:"小而简单用 SQLite,大而复杂选服务型数据库",明确其适用边界。
动态库和静态库分别如何影响 App 的启动速度?
动态库(Dynamic Library)和静态库(Static Library)对 App 启动速度的影响,核心源于链接时机、文件体积、内存加载方式的差异,最终体现在启动流程中的 "加载 - 链接 - 初始化" 三个关键阶段,是 iOS 性能优化和包体积优化的重要考点。
首先明确二者的核心链接机制差异,这是影响启动速度的根本:静态库在编译期(链接阶段) 会被完整复制到目标 App 的可执行文件(Mach-O)中,App 运行时无需额外加载库文件,直接从自身可执行文件中读取代码;动态库则在运行时(App 启动或库首次被调用时) 才被加载到内存并完成链接,App 的可执行文件中仅存储动态库的引用(路径或 UUID),而非完整代码。
静态库对 App 启动速度的影响
静态库对启动速度的核心影响是 "编译期增重,运行期提速":
- 启动阶段无额外加载开销:由于静态库代码已整合到 App 可执行文件中,App 启动时无需单独加载静态库文件,减少了 "查找库文件→加载到内存→验证签名→链接符号" 的流程,缩短了启动时间中的 "动态库加载阶段"。这一点在启动时需要调用大量库代码的场景下优势明显,例如 App 核心功能依赖多个静态库时,启动时无需等待库的异步加载,可直接执行代码。
- 可执行文件体积增大,可能间接影响启动:静态库的完整代码被复制到可执行文件中,会导致 Mach-O 文件体积变大。一方面,更大的可执行文件会增加 "磁盘读取时间"(启动时需将可执行文件从磁盘加载到内存),尤其是在机械硬盘设备(如旧款 iOS 设备)或 App 可执行文件极大(如集成多个大型静态库)的情况下,磁盘 IO 开销可能抵消部分运行期优势;另一方面,更大的可执行文件可能导致 "代码签名验证时间" 延长(系统需验证整个可执行文件的签名完整性),进一步影响启动速度。
- 符号解析效率高:静态库的符号(函数、变量名)在编译期已完成解析和绑定,运行时无需额外进行符号查找和重定位,减少了启动时的 CPU 开销。例如静态库中的函数调用,编译后直接对应内存中的绝对地址,而动态库的函数调用需要通过 "间接跳转表" 查找实际地址,存在轻微的运行时开销。
动态库对 App 启动速度的影响
动态库对启动速度的核心影响是 "编译期减重,运行期增负",但需区分 "启动时加载" 和 "懒加载" 两种场景:
- 启动时加载的动态库直接增加启动耗时 :默认情况下,动态库会在 App 启动的 "动态库加载阶段" 被加载(通过 dyld 动态链接器),这个过程包含多个耗时步骤:dyld 会遍历 App 依赖的所有动态库,根据引用路径查找库文件(优先查找系统库目录,再查找 App 沙盒内的嵌入式动态库);将库文件加载到内存并分配虚拟地址空间;验证库的签名(确保未被篡改);解析库的符号表,将 App 可执行文件中的符号引用与动态库中的实际符号绑定;处理库的初始化代码(如
+load方法、构造函数)。每增加一个动态库,都会增加上述流程的开销,尤其是嵌入式动态库(非系统库),查找和加载的耗时更明显。Apple 官方数据显示,App 依赖的动态库数量越多,启动时间越长,建议非系统动态库数量控制在 60 个以内。 - 懒加载动态库可降低启动开销 :动态库支持 "懒加载"(默认部分系统库为懒加载,自定义动态库可通过 Xcode 配置
Mach-O Type为Dynamic Library并开启懒加载),即库在首次被调用时才会被加载和链接,而非启动时。这种方式可减少启动时的动态库加载数量,缩短启动时间,适合 "非启动必需" 的功能模块(如设置页面、次要功能入口)。例如,将分享功能封装为动态库,仅在用户点击 "分享" 按钮时才加载该库,避免启动时额外开销。 - 可执行文件体积小,优化磁盘 IO:动态库不进入 App 可执行文件,仅需存储引用,因此能显著减小 Mach-O 文件体积,减少启动时的磁盘读取时间和签名验证时间。这一点在 App 集成多个大型库(如地图、视频播放库)时优势明显,例如将地图 SDK 封装为动态库,可使 App 安装包体积减小几十 MB,启动时磁盘读取可执行文件的时间大幅缩短。
- 存在符号绑定和重定位开销:动态库的符号在运行时才完成绑定,App 调用动态库中的函数时,需通过 "全局偏移表(GOT)" 和 "过程链接表(PLT)" 查找实际内存地址,首次调用时存在轻微的延迟(后续调用会缓存地址,开销可忽略)。此外,动态库加载时需进行代码重定位(将库中的相对地址转换为内存中的绝对地址),若动态库未开启 "位置无关代码(PIC)",重定位开销会更大,进一步影响启动速度(iOS 动态库默认强制开启 PIC,可缓解该问题)。
关键影响因素与面试加分点
- 关键影响因素:动态库数量(数量越多,启动耗时越长)、库体积(越大的动态库加载时间越长)、加载时机(启动时加载 vs 懒加载)、静态库整合程度(多个小型静态库合并为一个,可减少可执行文件碎片化,优化磁盘 IO)。
- 面试加分点:能结合 iOS 启动流程(dyld 加载→可执行文件加载→动态库加载→初始化)说明影响机制;能提到 "动态库共享缓存(dyld Shared Cache)"(系统动态库被预加载到共享缓存中,App 启动时无需重新加载,仅需链接,开销远低于嵌入式动态库);能给出优化建议(如将非核心功能动态库改为懒加载、合并小型静态库减少可执行文件碎片化、控制嵌入式动态库数量);能区分 "冷启动" 和 "热启动" 的差异(冷启动时动态库加载开销更明显,热启动时库已缓存,开销较小)。
记忆法
- 核心逻辑记忆:"静态 = 编译期整合,启动无加载开销但文件大;动态 = 运行期加载,文件小但启动多一步"------ 提炼核心差异,快速对应启动速度的影响方向。
- 场景记忆:"启动必需用静态,非必需用动态懒加载"------ 结合使用场景记忆,明确哪种库类型更利于启动速度优化,符合实际开发中的选择逻辑。
iOS 应用的组件化该如何实现?
iOS 应用的组件化是一种 "按业务功能拆分模块,实现模块解耦、独立开发、灵活集成 " 的架构设计方案,核心目标是解决大型 App 中 "模块依赖混乱、编译缓慢、团队协作效率低、功能复用难" 的问题。实现组件化的关键是 "解耦(消除模块间直接依赖) " 和 "通信(模块间间接交互) ",具体实现需从 "架构设计、模块拆分、通信方案、集成方式" 四个维度落地。
一、组件化的核心原则(设计前提)
- 单一职责原则:每个组件仅负责一个核心业务领域(如 "首页组件""购物车组件""用户中心组件""支付组件"),不包含无关功能,确保组件的独立性和复用性。
- 依赖倒置原则:组件间不直接依赖具体实现,而是依赖抽象协议(如 "支付组件" 定义支付协议,"购物车组件" 依赖协议而非支付组件的具体类),避免 "上层模块依赖下层模块" 导致的耦合。
- 接口暴露原则:组件仅暴露必要的接口(API)供外部调用,内部实现(私有类、方法、属性)隐藏,减少模块间的耦合面,便于后续修改内部实现而不影响外部调用者。
- 可独立编译运行:核心组件应支持单独编译(如通过 Pod 工程或独立 Xcode 工程),可单独进行单元测试或 UI 调试,避免必须依赖整个 App 才能开发测试。
二、模块拆分方案(组件划分方法)
模块拆分需结合业务和技术维度,避免过度拆分或拆分不足,常见拆分方式:
- 业务组件(核心功能模块):按业务线拆分,是组件化的核心,例如 "首页组件(HomeModule)""商品列表组件(ProductListModule)""订单组件(OrderModule)""用户中心组件(UserModule)""支付组件(PaymentModule)"。每个业务组件包含自身的 UI 页面、业务逻辑、数据模型(私有)和对外接口(公有)。
- 基础组件(通用工具模块):提供全局通用的工具类、基础能力,不依赖其他组件,例如 "网络请求组件(NetworkModule)""存储组件(StorageModule)""日志组件(LogModule)""UI 基础组件(BaseUIModule,如通用按钮、列表控件)""工具类组件(UtilModule,如字符串处理、日期工具)"。
- 中间件组件(通信与依赖管理模块):负责组件间通信、服务注册与发现,是解耦的核心,例如 "路由组件(RouterModule)""服务注册中心(ServiceRegistryModule)",不包含业务逻辑,仅提供通信能力。
拆分示例(大型电商 App):
- 业务组件:Home、Product、Cart、Order、User、Payment、Search、Message
- 基础组件:Network、Storage、Log、BaseUI、Util、ImageLoader
- 中间件组件:Router、ServiceRegistry
三、核心实现:组件间通信方案(解耦关键)
组件间通信是组件化的核心难题,需避免直接导入其他组件的头文件(硬依赖),常见方案有三种,各有适用场景:
| 通信方案 | 实现原理 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 路由(Router)方案 | 基于 URL 或协议映射,通过 "路由中心" 匹配目标组件的接口,实现间接调用(如 URL 路由:scheme://module/path?param=xxx) |
解耦彻底,组件无需知道对方存在;支持跨组件页面跳转、方法调用;便于统一拦截(如登录校验) | 需维护路由表,配置成本高;参数传递需序列化(如 JSON),性能略低 | 页面跳转、跨组件方法调用(无强类型校验) |
| 服务注册与发现方案 | 组件通过 "服务中心" 注册协议实现类,其他组件从服务中心获取协议实例,调用协议方法(基于依赖倒置) | 强类型校验(编译期报错);性能好(直接调用协议方法);支持组件替换(如 mock 服务) | 需定义统一协议;服务注册需在启动时完成,影响启动速度 | 组件间业务逻辑调用(如支付、登录验证) |
| 通知(Notification)方案 | 基于系统 NSNotificationCenter 或自定义通知中心,组件发送通知,其他组件监听通知 |
实现简单,无需额外配置;支持一对多通信 | 弱类型(参数类型无校验);依赖通知名称,易冲突;调试困难(难以追踪通知发送者) | 跨组件状态同步(如用户登录状态变更、订单支付成功通知) |
四、具体落地步骤(结合 CocoaPods 实现)
以 "路由 + 服务注册" 混合方案为例,落地步骤如下:
-
创建组件工程结构:
-
每个组件单独创建 Xcode 工程(或 Pod 工程),包含 "公有接口" 和 "私有实现":
- 公有目录(Public):暴露的接口文件(如路由 URL 定义、服务协议、对外模型),例如
HomeModulePublic.h、PaymentServiceProtocol.h。 - 私有目录(Private):组件内部实现(UI 页面、业务逻辑、私有模型),不对外暴露。
- 公有目录(Public):暴露的接口文件(如路由 URL 定义、服务协议、对外模型),例如
-
通过 CocoaPods 管理组件依赖:每个组件的 Podspec 文件中仅声明依赖的 "基础组件" 或 "中间件组件",不依赖其他业务组件。例如购物车组件的 Podspec: ruby
Pod::Spec.new do |s| s.name = "CartModule" s.version = "1.0.0" s.source = { :git => "xxx.git", :tag => s.version.to_s } # 依赖基础组件和中间件 s.dependency "NetworkModule" s.dependency "RouterModule" s.dependency "ServiceRegistryModule" # 暴露公有接口 s.public_header_files = "CartModule/Public/*.h" # 私有实现 s.source_files = "CartModule/Private/**/*.{h,m,swift}" end
-
-
实现路由组件(页面跳转):采用 URL 路由方案,通过 "路由中心" 统一管理组件间页面跳转,示例代码(Swift):
// 路由中心(中间件组件) class RouterManager { static let shared = RouterManager() // 存储 URL 与页面控制器的映射关系 private var urlMap: [String: () -> UIViewController] = [:] // 注册 URL(组件启动时调用) func registerURL(_ url: String, handler: @escaping () -> UIViewController) { urlMap[url] = handler } // 跳转页面(外部组件调用) func pushURL(_ url: String, params: [String: Any]? = nil, from vc: UIViewController) { guard let handler = urlMap[url] else { print("未注册的 URL:\(url)") return } let targetVC = handler() // 传递参数(通过模型或 KVC 赋值) if let params = params { targetVC.setValuesForKeys(params) } vc.navigationController?.pushViewController(targetVC, animated: true) } } // 首页组件注册页面 URL class HomeModule { static func setup() { // 注册首页页面 URL:"app://home/main" RouterManager.shared.registerURL("app://home/main") { return HomeViewController() } } } // 其他组件调用首页页面(无需导入 HomeModule) RouterManager.shared.pushURL("app://home/main", params: ["title": "首页"], from: currentVC) -
实现服务注册与发现(业务逻辑调用):基于协议的服务注册方案,实现组件间业务逻辑调用,示例代码(Swift):
// 服务注册中心(中间件组件) class ServiceRegistry { static let shared = ServiceRegistry() private var serviceMap: [String: Any] = [:] // 注册服务(组件实现协议后注册) func registerService<T>(_ serviceProtocol: T.Type, implementation: T) { let key = String(describing: serviceProtocol) serviceMap[key] = implementation } // 获取服务(外部组件调用) func getService<T>(_ serviceProtocol: T.Type) -> T? { let key = String(describing: serviceProtocol) return serviceMap[key] as? T } } // 定义支付服务协议(公有接口,可放在基础组件或单独的协议组件中) protocol PaymentServiceProtocol { func pay(amount: Double, completion: @escaping (Bool) -> Void) } // 支付组件实现协议并注册服务 class PaymentServiceImpl: PaymentServiceProtocol { func pay(amount: Double, completion: @escaping (Bool) -> Void) { // 调用支付 SDK 完成支付逻辑 print("支付 \(amount) 元") completion(true) } } // 支付组件启动时注册服务 class PaymentModule { static func setup() { let service = PaymentServiceImpl() ServiceRegistry.shared.registerService(PaymentServiceProtocol.self, implementation: service) } } // 购物车组件调用支付服务(无需导入 PaymentModule,仅依赖协议) if let paymentService = ServiceRegistry.shared.getService(PaymentServiceProtocol.self) { paymentService.pay(amount: 99.0) { success in if success { print("支付成功,更新购物车") } } } -
组件集成与启动流程:
- 主工程(App 壳工程)仅依赖所有业务组件、基础组件和中间件组件,不包含具体业务逻辑,负责组件的初始化和全局配置。
- 启动流程:App 启动后,主工程调用各组件的
setup()方法(如HomeModule.setup()、PaymentModule.setup()),完成路由注册、服务注册等初始化操作;之后通过路由或服务调用各组件功能。 - 独立开发与调试:每个组件可通过 "Demo 工程"(单独的 Xcode 工程)依赖自身和必要的基础组件,实现独立编译、运行和调试,无需启动整个 App。
面试关键点与加分点
- 关键点:组件化的核心目标(解耦、独立开发、复用);模块拆分原则(单一职责、依赖倒置);核心通信方案(路由、服务注册、通知)的差异与适用场景。
- 加分点:能提到组件化的常见问题及解决方案(如组件间资源共享:通过 bundle 管理组件资源、统一资源命名;组件版本管理:语义化版本控制、Pod 私有库;编译优化:组件按需编译、增量编译);能结合实际项目经验说明拆分粒度(如避免拆分过细导致通信成本过高,或拆分过粗导致解耦不彻底);能对比不同通信方案的性能差异(服务注册 > 路由 > 通知)。
记忆法
- 核心逻辑记忆:"拆分(按业务 / 基础 / 中间件)→ 解耦(依赖抽象不依赖实现)→ 通信(路由跳页面,服务调逻辑,通知传状态)→ 集成(Pod 管理,壳工程整合)"------ 按 "拆分 - 解耦 - 通信 - 集成" 的流程记忆,符合实现逻辑。
- 通信方案记忆:"页面用路由,逻辑用服务,状态用通知"------ 对应三种通信方案的核心适用场景,快速区分使用场景。
CocoaPods 的 install 与 update 有什么区别?
CocoaPods 的 install 和 update 是管理第三方依赖的核心命令,二者的核心区别在于 "是否遵循 Podfile.lock 中的版本约束",直接影响依赖版本的稳定性、项目构建一致性和依赖更新逻辑,是 iOS 开发中团队协作和依赖管理的基础考点。
首先明确两个关键文件的作用,这是理解二者差异的前提:
- Podfile :开发者编写的依赖配置文件,声明项目需要的第三方库、版本约束(如
pod 'AFNetworking', '~> 4.0')、源地址等,定义 "允许使用的版本范围"。 - Podfile.lock :CocoaPods 自动生成的 "版本锁定文件",记录当前项目实际依赖的每个库的具体版本号 (如
AFNetworking: 4.0.1)、依赖树(库的子依赖版本)、校验哈希值。其核心作用是 "锁定版本,确保团队所有成员、不同环境下构建项目时使用完全一致的依赖版本",避免因版本差异导致的兼容性问题。
pod install 命令的核心逻辑与行为
pod install 的核心原则是 "优先遵循 Podfile.lock,无则按 Podfile 安装",具体行为如下:
-
首次安装依赖(无 Podfile.lock 时) :若项目是首次集成 CocoaPods,或 Podfile.lock 不存在,
install会根据 Podfile 中的版本约束,查找符合条件的 "最新可用版本"(如~> 4.0约束下,最新的 4.x 版本),下载并安装该版本及所有子依赖,同时生成 Podfile.lock 文件,记录所有依赖的具体版本。例如 Podfile 中声明pod 'AFNetworking', '~> 4.0',当前最新 4.x 版本是 4.0.1,则安装 4.0.1 并在 Podfile.lock 中记录AFNetworking: 4.0.1。 -
已有 Podfile.lock 时(非首次安装) :这是
install最常用的场景(如团队成员拉取代码后、切换分支后),核心行为是 "严格遵循 Podfile.lock 中的版本,不主动更新依赖":- 对于 Podfile 中已存在且在 Podfile.lock 中记录的依赖,
install会直接安装 Podfile.lock 中指定的具体版本,忽略该库是否有更新的版本(即使 Podfile 允许更高版本)。例如 Podfile.lock 中记录 AFNetworking 4.0.1,即使此时 AFNetworking 已更新到 4.1.0,install仍会安装 4.0.1,确保版本一致性。 - 若 Podfile 中新增了依赖(如新增
pod 'Masonry'),install会为新增依赖查找符合 Podfile 版本约束的最新可用版本,安装后更新 Podfile.lock,将新增依赖的具体版本记录进去,同时不影响已存在的依赖版本。 - 若 Podfile 中修改了已有依赖的 "版本约束"(如从
~> 4.0改为~> 5.0),install会认为该依赖的版本规则已变更,会忽略 Podfile.lock 中的旧版本,查找符合新约束的最新可用版本,安装后更新 Podfile.lock 中的对应版本。
- 对于 Podfile 中已存在且在 Podfile.lock 中记录的依赖,
-
其他关键行为:
- 生成 / 更新
Pods目录(存储依赖库的源代码、资源文件)和xxx.xcworkspace文件(整合项目工程和 Pods 工程)。 - 不删除已安装但 Podfile 中已移除的依赖(需手动执行
pod deintegrate或删除Pods目录后重新install)。
- 生成 / 更新
pod update [PodName] 命令的核心逻辑与行为
pod update 的核心原则是 "忽略 Podfile.lock,按 Podfile 约束更新依赖到最新版本",具体行为如下:
-
无指定 PodName 时(
pod update) :忽略整个 Podfile.lock 文件,对 Podfile 中所有依赖进行 "全面更新":为每个依赖查找符合其版本约束的 "最新可用版本"(包括主依赖和子依赖),下载并安装后,重新生成 Podfile.lock 文件,覆盖旧版本记录。例如 Podfile 中pod 'AFNetworking', '~> 4.0',当前最新 4.x 版本是 4.1.0,即使 Podfile.lock 中之前记录的是 4.0.1,update也会安装 4.1.0 并更新 Podfile.lock。这种方式的风险是 "批量更新可能引入兼容性问题",例如多个依赖更新后,彼此版本不兼容,或与项目代码不兼容,因此不建议频繁执行全局pod update。 -
指定 PodName 时(
pod update AFNetworking):仅针对指定的依赖进行更新,其他依赖仍遵循 Podfile.lock 中的版本,是更安全的更新方式:- 忽略 Podfile.lock 中该指定依赖的旧版本,查找符合其 Podfile 版本约束的最新可用版本,安装后更新 Podfile.lock 中该依赖的版本。
- 若该指定依赖有子依赖,会同时更新子依赖到符合约束的最新版本(但不影响其他主依赖及其子依赖)。例如更新 AFNetworking 时,会同时更新其依赖的
SDWebImage(若有)到最新兼容版本,但不会更新 Podfile 中其他依赖(如 Masonry)的版本。
-
其他关键行为:
- 若 Podfile 中某个依赖的版本约束是 "固定版本"(如
pod 'AFNetworking', '4.0.1'),则update不会更新该依赖(因为已锁定具体版本,无更新空间)。 - 同样会更新
Pods目录和xcworkspace文件,但不会删除未指定的依赖。
- 若 Podfile 中某个依赖的版本约束是 "固定版本"(如
核心区别对比表
| 对比维度 | pod install | pod update PodName |
|---|---|---|
| 核心原则 | 遵循 Podfile.lock,确保版本一致 | 忽略 Podfile.lock(指定依赖),追求最新版本 |
| 版本来源 | 已有依赖取 Podfile.lock 具体版本,新增依赖取最新符合约束版本 | 指定依赖取最新符合约束版本,其他依赖取 Podfile.lock 版本 |
| 适用场景 | 首次集成依赖、新增依赖、团队协作拉取代码后、切换分支后 | 单独更新某个依赖到最新版本、修复特定依赖的 Bug(需新版本) |
| 对 Podfile.lock 的影响 | 首次安装生成,新增 / 修改依赖时更新对应部分 | 重新生成(全局更新)或更新指定依赖部分(指定 PodName) |
| 兼容性风险 | 低(版本固定,与之前构建一致) | 中(仅更新指定依赖,风险可控)/ 高(全局更新,批量变更) |
面试关键点与加分点
- 关键点:明确 Podfile 和 Podfile.lock 的作用;
install遵循 lock 文件、update忽略 lock 文件的核心差异;适用场景的区分(团队协作用install,更新依赖用update)。 - 面试加分点:能提到
pod install --repo-update命令(在install时强制更新本地 CocoaPods 仓库索引,确保能找到最新版本的依赖,默认install不更新索引);能解释 "子依赖版本管理"(install遵循 lock 中的子依赖版本,update会更新子依赖到最新兼容版本);能给出最佳实践(如团队协作时,Podfile.lock 必须提交到 Git 仓库;更新依赖时优先使用pod update 具体库名,避免全局更新;更新前备份 Podfile.lock,出现问题可回滚);能说明版本约束符号的含义(~> 4.0表示 4.x 最新版本,>= 4.0表示 4.0 及以上所有版本,== 4.0.1表示固定版本)。
记忆法
- 核心逻辑记忆:"install 保一致,update 追最新"------ 提炼核心差异,
install核心是保证团队成员、环境间的版本一致,update核心是更新到符合约束的最新版本。 - 适用场景记忆:"新环境 / 加依赖用 install,更版本用 update"------ 对应实际开发中的使用场景,快速判断该用哪个命令。
Git 的 rebase 与 merge 有什么区别?该如何选择使用?
Git 的 rebase(变基)和 merge(合并)是两种整合分支代码的核心命令,二者的核心区别在于 "分支提交历史的处理方式 "------ merge 保留分支原有提交历史,通过创建新的合并提交整合代码;rebase 改写提交历史,将当前分支的提交 "嫁接" 到目标分支的最新提交上,最终形成线性的提交历史。这一差异直接影响代码仓库的可读性、协作效率和冲突处理方式,是 Git 协作开发的核心考点。
一、核心原理与操作流程差异
merge 的原理与流程
merge 的核心是 "保留分支痕迹,创建合并节点",操作流程如下:
-
假设存在两个分支:
main(主分支)和feature(功能分支,基于main分支创建)。 -
开发过程中,
main分支有新的提交(C3),feature分支也有自己的提交(C4、C5),此时分支历史为:main: C1 → C2 → C3 feature: C1 → C2 → C4 → C5 -
执行
git checkout feature && git merge main(将main分支合并到feature分支),Git 会:-
查找两个分支的 "共同祖先提交"(此处为 C2)。
-
对比
main分支从 C2 到 C3 的变更,以及feature分支从 C2 到 C5 的变更。 -
若无冲突,直接创建一个新的 "合并提交"(C6),该提交的父提交是 C5(
feature最后一个提交)和 C3(main最后一个提交),最终分支历史为:main: C1 → C2 → C3 feature: C1 → C2 → C4 → C5 → C6(C6 是合并提交,父提交为 C5 和 C3) -
若有冲突,Git 会暂停合并,提示开发者解决冲突后,通过
git add+git commit完成合并提交(无需额外写提交信息,Git 会自动生成合并提交说明)。
-
merge 的核心特点是 "不破坏原有分支的提交历史",所有提交(包括合并提交)都被保留,分支历史呈现 "非线性" 结构(有分叉和合并节点)。
rebase 的原理与流程
rebase 的核心是 "改写提交历史,形成线性结构",操作流程如下:
-
基于上述同样的分支状态(
main有 C3,feature有 C4、C5)。 -
执行
git checkout feature && git rebase main(将feature分支的提交变基到main分支),Git 会:-
查找两个分支的共同祖先(C2),将
feature分支从 C2 开始的所有提交(C4、C5)暂时 "摘下来",存储为临时补丁。 -
将
feature分支指针移动到目标分支(main)的最新提交(C3)上,此时feature分支的历史暂时与main一致(C1→C2→C3)。 -
依次将之前 "摘下来" 的提交(C4、C5)重新应用到
feature分支上,形成新的提交(C4'、C5',与原 C4、C5 内容相同,但提交哈希值不同,因为父提交变为 C3)。 -
最终分支历史为:
main: C1 → C2 → C3 feature: C1 → C2 → C3 → C4' → C5'(线性历史,无合并提交)
-
-
若应用某个临时补丁时出现冲突,Git 会暂停 rebase 过程,提示开发者解决冲突后:
- 执行
git add标记冲突已解决(无需git commit)。 - 执行
git rebase --continue继续应用后续提交;若需放弃 rebase,执行git rebase --abort回滚到 rebase 前的状态。
- 执行
rebase 的核心特点是 "改写提交历史",消除分支分叉,使提交历史呈现 "线性" 结构,但原有的提交(C4、C5)会被替换为新的提交(C4'、C5'),若该分支已推送到远程仓库并被其他开发者使用,改写历史会导致协作冲突。
二、核心区别对比表
| 对比维度 | rebase(变基) | merge(合并) |
|---|---|---|
| 提交历史结构 | 线性结构,无合并提交,历史干净 | 非线性结构,有合并提交,保留分支分叉痕迹 |
| 提交历史改写 | 改写当前分支的提交(生成新的提交哈希) | 不改写原有提交,仅新增合并提交 |
| 冲突处理方式 | 按提交顺序逐个解决冲突(每应用一个提交可能冲突) | 一次性解决所有分支差异的冲突 |
| 分支痕迹保留 | 不保留分支创建、开发的痕迹(线性历史) | 保留完整的分支痕迹(合并提交记录分支来源) |
| 远程分支兼容性 | 已推送的分支不建议使用(改写历史导致冲突) | 可安全用于已推送的分支(不改写历史) |
| 代码整合逻辑 | 把当前分支 "嫁接" 到目标分支最新提交之后 | 基于共同祖先,合并两个分支的所有变更 |
三、如何选择使用?(最佳实践)
选择的核心原则是 "本地分支用 rebase,公共分支用 merge",结合具体场景细化如下:
- 使用 rebase 的场景 :
- 本地开发分支(如
feature、bugfix分支)整合主分支(main、develop)的最新代码时:例如在feature分支开发时,main分支有他人提交的重要修复,需将这些修复整合到自己的feature分支,此时用rebase main可保持feature分支的提交历史干净线性,便于后续代码审查和问题追溯。 - 优化本地提交历史时:例如本地开发过程中有多个临时提交(如 "测试""修改"),可通过
git rebase -i HEAD...
- 本地开发分支(如
iOS 中的事件是如何响应的?其响应链机制是怎样的?
iOS 中的事件是用户与应用交互的核心(如触摸、手势、摇晃、远程控制等),其中最常用的是触摸事件(UITouch) ,其响应流程遵循"事件分发→命中测试→响应链传递"的核心逻辑,响应链机制则是确保事件能被正确视图接收并处理的关键,是 iOS 视图体系的核心知识点。
一、iOS 事件的分类与基本概念
首先明确 iOS 支持的核心事件类型,其中触摸事件是面试重点:
| 事件类型 | 描述 |
|---|---|
| 触摸事件(UITouch) | 用户通过屏幕操作触发(单点触摸、多点触摸、长按、滑动等),最常用场景 |
| 手势事件(UIGestureRecognizer) | 基于触摸事件封装的高级事件(如点击、捏合、旋转、滑动),本质是对触摸事件的解析 |
| 运动事件(UIEventSubtypeMotion) | 设备运动触发(如摇晃、加速计、陀螺仪数据),需开启运动权限 |
| 远程控制事件(UIEventSubtypeRemoteControl) | 外部设备控制(如耳机线控、蓝牙设备控制音乐播放) |
核心概念:
- UIEvent:事件对象,存储事件类型、触发时间、触摸点信息等,每次用户交互都会生成一个 UIEvent 实例。
- UITouch:触摸对象,每个触摸点对应一个 UITouch,存储触摸位置(相对于不同视图的坐标)、触摸阶段(开始、移动、结束、取消)、触摸次数等。
- 响应者对象(UIResponder) :能接收并处理事件的对象,所有继承自 UIResponder 的类(如 UIView、UIViewController、UIApplication、UIWindow)都具备响应能力,核心方法包括
touchesBegan(_:with:)、touchesMoved(_:with:)、touchesEnded(_:with:)、touchesCancelled(_:with:)(处理触摸事件)和canBecomeFirstResponder()(是否能成为第一响应者)。
二、事件响应的完整流程(以触摸事件为例)
事件响应分为三个核心阶段:事件分发→命中测试→响应链传递,流程不可逆且环环相扣:
-
事件分发:系统将事件传递给应用
- 用户触摸屏幕时,iOS 系统会捕获触摸信号,生成 UIEvent 和对应的 UITouch 对象,通过 IPC(进程间通信)将事件传递给当前活跃的应用(前台应用)。
- 应用的 UIApplication 接收事件后,将事件传递给应用的主窗口(UIWindow,因为 UIWindow 是 UIApplication 的下一级响应者)。
-
命中测试(Hit-Testing):找到事件的初始响应视图 主窗口接收事件后,通过"命中测试"遍历视图层级,找到最上层、能接收事件且包含触摸点的视图(即"命中视图"),这是事件响应的关键步骤,具体流程:
- 从主窗口的根视图(rootViewController 的 view)开始,递归遍历子视图,遵循"从父视图到子视图、从后往前(subviews 数组顺序,索引越大越靠上)"的顺序。
- 对每个视图执行命中测试逻辑:
- 检查视图是否"可交互":
userInteractionEnabled为 true(默认 true)、hidden为 false、alpha> 0.01(alpha ≤ 0.01 时无法接收事件),若不满足则直接跳过该视图及其子视图。 - 检查触摸点是否在视图的 bounds 范围内(注意:是 bounds 而非 frame,因为 bounds 是视图自身坐标体系,frame 是父视图坐标体系,触摸点坐标会先转换为当前视图的 bounds 坐标)。
- 若满足以上条件,继续递归遍历该视图的子视图,重复上述步骤,直到找到"没有子视图命中"或"子视图不可交互"的视图,该视图即为"命中视图(hitTestView)"。
- 检查视图是否"可交互":
- 示例:若界面层级为 Window → ViewA → ViewB → ViewC(ViewC 在最上层),触摸点在 ViewC 内且 ViewC 可交互,则命中视图为 ViewC;若 ViewC 隐藏,则继续查找其父视图 ViewB,以此类推。
-
响应链传递:事件在响应者之间传递命中视图是事件的"初始响应者",但不一定是最终处理者,事件会沿"响应链"向上传递,直到被某个响应者处理或传递至终点(UIApplication),具体规则:
-
响应链的默认顺序:命中视图 → 父视图 → 视图控制器(若视图是控制器的 view,则传递给控制器)→ 父控制器 → 窗口 → UIApplication → UIApplicationDelegate(若代理是 UIResponder 子类)。
-
事件传递逻辑:
- 初始响应者(命中视图)优先尝试处理事件:若该视图实现了
touchesBegan(_:with:)等触摸方法且未调用super方法,则事件被该视图消费,传递终止;若调用了super方法,则事件继续向上传递给父视图。 - 若所有响应者都未处理事件(即都调用了
super方法),则事件最终传递到 UIApplication,若 UIApplication 也未处理,则事件被系统丢弃。
- 初始响应者(命中视图)优先尝试处理事件:若该视图实现了
-
示例代码(视图处理触摸事件):
class CustomView: UIView { override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) { print("CustomView 接收到触摸事件") // 若不调用 super,事件不会向上传递给父视图 // super.touchesBegan(touches, with: event) } } // 父视图 class ParentView: UIView { override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) { print("ParentView 接收到触摸事件") super.touchesBegan(touches, with: event) // 继续向上传递 } } // 若 CustomView 未调用 super,则仅打印 "CustomView 接收到触摸事件";若调用,则依次打印 CustomView → ParentView → ...
-
三、响应链与手势识别的关系
UIGestureRecognizer(手势识别器)是对触摸事件的封装,其与响应链的关系是"手势识别优先于视图的触摸事件处理":
- 当视图添加了手势识别器后,触摸事件会先传递给手势识别器,手势识别器会解析触摸序列(如判断是否是点击、长按)。
- 若手势识别成功(如识别为点击),则系统会发送
touchesCancelled(_:with:)给该视图及其父视图,终止原有的触摸事件响应链,转而执行手势的回调方法(如tapGestureRecognizer.addTarget(self, action: #selector(tapAction)))。 - 若手势识别失败(如触摸序列不符合手势规则),则事件会退回给视图,继续沿响应链传递,视图的
touchesBegan(_:with:)等方法会正常执行。 - 可通过
gestureRecognizer.cancelsTouchesInView = false禁用"手势识别成功后取消视图触摸事件"的行为,使视图和手势能同时响应。
面试关键点与加分点
-
关键点:事件响应的三阶段(分发→命中测试→响应链传递);命中测试的核心条件(可交互、触摸点在 bounds 内、子视图优先);响应链的传递顺序(命中视图→父视图→控制器→窗口→应用)。
-
加分点:能区分 frame 和 bounds 在命中测试中的作用(触摸点坐标转换为视图 bounds 坐标进行判断);能解释
userInteractionEnabled、hidden、alpha对事件接收的影响;能说明手势识别与响应链的优先级关系;能自定义命中测试逻辑(重写hitTest(_:with:)方法,例如让父视图"穿透"子视图,使下层视图接收事件),示例代码:// 自定义视图,重写 hitTest 实现"穿透",让子视图下方的视图接收事件 class TransparentView: UIView { override func hitTest(_ point: CGPoint, with event: UIEvent?) -> UIView? { let hitView = super.hitTest(point, with: event) // 若命中的是自身(而非子视图),则返回 nil,让事件继续向下传递 return hitView === self ? nil : hitView } }
记忆法
- 流程记忆:"分发找应用,测试找视图,传递沿链条"------ 对应"事件分发(给应用)→ 命中测试(找初始视图)→ 响应链传递(沿响应者向上)"的核心流程。
- 响应链顺序记忆:"子→父→控制器→窗口→应用"------ 按从下到上的传递顺序记忆,结合示例场景(如 CustomView → ParentView → ViewController → Window → UIApplication)强化记忆。
iOS 应用是否存在事件循环?具体是什么?
iOS 应用存在事件循环,其核心是 RunLoop(运行循环) ------ 一个贯穿应用生命周期的"无限循环机制",负责管理事件处理、任务调度、线程休眠与唤醒,是 iOS 应用能够"持续运行并响应交互"的核心底层机制,没有 RunLoop,应用启动后会立即退出,无法接收触摸、网络回调等任何事件。
一、RunLoop 的核心定义与本质
RunLoop 的本质是"一个基于事件驱动的无限循环",其核心逻辑可简化为伪代码:
func runLoop() {
while true {
// 1. 休眠:等待事件(如触摸、网络回调、定时器)
let event = waitForEvent()
// 2. 唤醒:接收到事件后,从休眠中唤醒
// 3. 处理事件:分发并处理事件(如传递给响应链、执行回调)
processEvent(event)
// 4. 处理完事件后,再次进入休眠,节省 CPU 资源
}
}- 其核心作用是"让线程在有事件时工作,无事件时休眠",避免线程无意义地空转(浪费 CPU 资源),同时确保线程能及时响应各类事件。
- 每个线程(包括主线程和子线程)都对应一个 RunLoop 实例,但 RunLoop 并非线程创建时自动启动:主线程的 RunLoop 由系统自动创建并启动(应用启动时,UIApplicationMain 函数会初始化并启动主线程 RunLoop);子线程的 RunLoop 需手动创建并启动(若不启动,子线程执行完任务后会立即退出)。
二、RunLoop 的核心组件与工作原理
RunLoop 的工作依赖四个核心组件,它们共同构成"事件收集→分发→处理"的闭环:
| 组件 | 作用 |
|---|---|
| 模式(RunLoopMode) | 限定 RunLoop 处理的事件类型,不同模式下 RunLoop 只响应对应类型的事件,避免不同场景的事件干扰 |
| 源(Source) | 事件源,产生 RunLoop 所需处理的事件(如触摸事件、网络回调、定时器事件),分为 Source0(用户态事件,如触摸)和 Source1(内核态事件,如端口通信) |
| 观察者(Observer) | 监听 RunLoop 的状态变化(如进入休眠、唤醒、处理事件、退出),可在状态变化时执行自定义逻辑(如 UI 刷新、自动释放池释放) |
| 定时器(Timer) | 定时事件源,按指定时间间隔触发事件(如 NSTimer),需添加到 RunLoop 中才会生效 |
1. 关键组件详解
-
RunLoopMode(模式):模式是 RunLoop 的"过滤规则",每个模式都包含一组 Source、Observer、Timer,RunLoop 同一时间只能运行在一个模式下,切换模式会导致 RunLoop 重新筛选可处理的事件。iOS 中常用的模式:
kCFRunLoopDefaultMode(默认模式):主线程默认运行的模式,处理大多数事件(如触摸事件、定时器、网络回调),应用空闲时处于该模式。UITrackingRunLoopMode(跟踪模式):滚动视图(UIScrollView、UITableView、UICollectionView)滚动时,主线程会自动切换到该模式,仅处理与滚动相关的事件(如触摸移动、滚动动画),避免其他事件(如定时器)干扰滚动流畅性。UIInitializationRunLoopMode(初始化模式):应用启动初始化时的临时模式,初始化完成后自动切换到默认模式。GSEventReceiveRunLoopMode(系统事件模式):接收系统级事件(如屏幕旋转、键盘弹出)的模式,开发者无需手动处理。- 自定义模式:通过
CFRunLoopCreateMode创建,用于隔离特定场景的事件(如视频播放时的事件处理)。
-
Source(事件源):分为两类,对应不同的事件来源:
- Source0:用户态事件,需手动触发,无内核通知机制,如触摸事件(UITouch)、UI 控件的动作事件(如按钮点击)、自定义的回调事件。Source0 触发后,RunLoop 需被唤醒(通过
CFRunLoopWakeUp)才能处理。 - Source1:内核态事件,由内核自动通知,基于 Mach Port(端口通信)实现,如网络回调(NSURLSession 的回调、CFNetwork 的回调)、系统消息(如键盘弹出通知)。Source1 触发时,内核会主动唤醒 RunLoop 处理事件。
- Source0:用户态事件,需手动触发,无内核通知机制,如触摸事件(UITouch)、UI 控件的动作事件(如按钮点击)、自定义的回调事件。Source0 触发后,RunLoop 需被唤醒(通过
-
Observer(观察者):监听 RunLoop 的 6 种状态变化,常用状态包括:
kCFRunLoopEntry:RunLoop 进入循环。kCFRunLoopBeforeTimers:RunLoop 即将处理定时器事件。kCFRunLoopBeforeSources:RunLoop 即将处理 Source 事件。kCFRunLoopBeforeWaiting:RunLoop 即将进入休眠。kCFRunLoopAfterWaiting:RunLoop 从休眠中唤醒。kCFRunLoopExit:RunLoop 退出循环。典型应用:主线程的自动释放池(Autorelease Pool)会通过 Observer 实现"进入休眠前释放池释放"和"退出循环时释放池释放",避免内存泄漏。
-
Timer(定时器):定时触发的事件源,依赖 RunLoop 运行:
- Timer 被添加到 RunLoop 后,RunLoop 会在指定时间间隔触发 Timer 的回调方法。
- 若 RunLoop 处于 Timer 未关联的模式(如 Timer 添加到默认模式,而 RunLoop 切换到跟踪模式),则 Timer 会暂时失效,直到 RunLoop 切换回关联模式。
- 示例:若想让 Timer 在滚动视图时仍生效,需将 Timer 同时添加到默认模式和跟踪模式(通过
NSRunLoopCommonModes,这是一个模式集合,包含默认模式和跟踪模式)。
2. RunLoop 的工作流程(简化版)
- RunLoop 进入指定模式(如默认模式),触发
kCFRunLoopEntry观察者回调。 - 触发
kCFRunLoopBeforeTimers观察者回调,检查并处理所有到期的 Timer。 - 触发
kCFRunLoopBeforeSources观察者回调,处理所有就绪的 Source(先处理 Source0,再处理 Source1)。 - 若有未处理完的事件(如 Source 仍有数据),重复步骤 2-3;若无事件,触发
kCFRunLoopBeforeWaiting观察者回调(此时自动释放池会释放)。 - RunLoop 进入休眠状态,等待事件触发(如触摸、网络回调、Timer 到期)。
- 当有事件触发(如用户触摸屏幕),内核唤醒 RunLoop,触发
kCFRunLoopAfterWaiting观察者回调。 - 根据唤醒原因处理对应事件(如 Timer 到期则处理 Timer,Source1 触发则处理 Source1,触摸事件则分发到响应链)。
- 事件处理完成后,若 RunLoop 未被停止,切换回指定模式(或保持当前模式),重复步骤 2-7;若被停止,则触发
kCFRunLoopExit观察者回调,RunLoop 退出。
三、RunLoop 在 iOS 应用中的核心应用场景
RunLoop 是 iOS 应用运行的基础,所有交互和后台任务都依赖其机制,典型场景:
-
UI 事件处理:触摸事件、手势事件、UI 控件动作事件(如按钮点击)通过 Source0 进入 RunLoop,RunLoop 唤醒后将事件分发到响应链,确保 UI 能及时响应。
-
定时器触发 :NSTimer、CADisplayLink(屏幕刷新定时器)需添加到 RunLoop 中才能生效,例如 CADisplayLink 依赖 RunLoop 的
kCFRunLoopCommonModes,确保屏幕刷新(60fps)不受滚动影响。 -
网络回调处理:NSURLSession、AFNetworking 等网络框架的回调通过 Source1(Mach Port)触发,内核接收网络数据后唤醒 RunLoop,执行回调方法(如请求成功/失败处理)。
-
自动释放池管理:主线程的自动释放池通过 Observer 实现"休眠前释放"和"退出时释放",避免临时对象累积导致内存泄漏。
-
线程保活 :子线程若需长期运行(如后台下载、实时数据同步),需手动创建并启动 RunLoop,通过添加 Source 或 Timer 让 RunLoop 持续运行,避免线程执行完任务后退出。示例代码(子线程保活):
func keepThreadAlive() { let thread = Thread { // 1. 获取当前线程的 RunLoop let runLoop = RunLoop.current // 2. 添加一个空的 Source0,让 RunLoop 有事件可处理(避免立即退出) runLoop.add(NSMachPort(), forMode: .default) // 3. 启动 RunLoop,运行在默认模式下 runLoop.run(mode: .default, before: .distantFuture) } thread.name = "KeepAliveThread" thread.start() } -
滚动视图流畅性优化 :滚动视图滚动时,主线程 RunLoop 切换到
UITrackingRunLoopMode,仅处理滚动相关事件,暂停其他事件(如默认模式下的 Timer),确保滚动动画流畅。
面试关键点与加分点
-
关键点:RunLoop 是 iOS 事件循环的核心,本质是"无限循环+事件驱动";主线程 RunLoop 自动启动,子线程需手动启动;核心组件(模式、Source、Observer、Timer)的作用;RunLoop 的基本工作流程。
-
加分点:能区分 Source0 和 Source1 的差异;能解释
NSRunLoopCommonModes的作用(模式集合,避免 Timer 在滚动时失效);能说明 RunLoop 与自动释放池的关系;能通过自定义 Observer 监听 RunLoop 状态(示例代码如下);能分析 RunLoop 相关的性能问题(如 RunLoop 卡顿:事件处理耗时过长导致无法及时休眠,需通过 Instrument 的 RunLoop 工具分析)。// 自定义 Observer 监听 RunLoop 状态变化 func addRunLoopObserver() { let runLoop = RunLoop.current // 创建 Observer,监听 RunLoop 进入休眠和唤醒状态 let observer = CFRunLoopObserverCreateWithHandler(kCFAllocatorDefault, CFRunLoopActivity.allActivities.rawValue, true, 0) { observer, activity in switch activity { case .beforeWaiting: print("RunLoop 即将进入休眠") case .afterWaiting: print("RunLoop 从休眠中唤醒") default: break } } // 添加 Observer 到 RunLoop 的默认模式 CFRunLoopAddObserver(runLoop.getCFRunLoop(), observer, .defaultMode) }
记忆法
- 本质记忆:"有活干就醒,没活干就睡"------ 简化 RunLoop 的核心逻辑,记住其"事件驱动、休眠-唤醒"的循环特性。
- 组件记忆:"模式定范围,源生事件,观察者监听,定时器定时"------ 对应四个核心组件的作用,快速区分各组件功能。
- 应用场景记忆:"UI 响应、定时、网络、保活、释池、滚动优化"------ 罗列核心应用场景,结合实际开发经验强化记忆。
设计一个支持上传功能的图片控件,对应的缓存清除策略有哪些?
支持上传功能的图片控件,核心是"图片选择→本地缓存→上传管理→上传状态展示→缓存清理"的全流程设计,其中缓存清除策略需兼顾"用户体验(避免重复上传)"和"设备存储(避免缓存过多占用空间)",需根据业务场景设计灵活、高效的清理方案。首先明确控件的核心设计要点,再详细拆解缓存清除策略。
一、支持上传功能的图片控件核心设计要点
控件需具备"选择-缓存-上传-展示-清理"的闭环能力,核心模块如下:
- 图片选择模块 :支持从相册选择、相机拍摄获取图片,通过
UIImagePickerController实现,选择/拍摄后返回UIImage实例。 - 本地缓存模块 :将选择的图片(原始图片、压缩后图片)、上传相关元数据(如图片唯一标识、上传状态、上传进度、服务器返回的图片 URL)存储到本地,避免重复选择后重新上传,核心存储内容:
- 图片数据:压缩后的图片文件(存储路径或数据库 Blob 字段)。
- 元数据:图片 ID(UUID 生成)、文件名、文件大小、上传状态(未上传/上传中/上传成功/上传失败)、上传进度(0-1)、服务器 URL、上传时间戳、过期时间(可选)。
- 上传管理模块:集成上传逻辑(如基于 AFNetworking 的 multipart/form-data 上传),支持单张/批量上传、暂停/继续上传、断点续传(需服务器支持),上传状态实时回调给控件更新 UI。
- UI 展示模块:展示已选择的图片缩略图、上传进度条、上传状态图标(成功/失败/暂停)、删除按钮、重新上传按钮,支持点击原图。
- 缓存管理模块:提供缓存清除接口,实现自动/手动清除策略,核心是"保留有用缓存,清理无效/过期缓存"。
二、核心缓存清除策略(按"自动+手动"分类)
缓存清除的核心目标是"在不影响用户体验的前提下,最小化缓存占用空间",需结合业务场景(如是否需要保留历史上传记录、图片是否有有效期)选择合适策略,以下是常用且实用的清除方案:
1. 手动清除策略(用户主动触发)
手动清除是用户可控的清除方式,需在控件或应用设置中提供入口,核心场景是"用户感知到存储占用过多,主动清理",具体实现:
- 单张图片缓存清除 :控件中每张图片的缩略图旁添加"删除"按钮,用户点击后:
- 移除 UI 上的图片展示。
- 删除本地缓存的图片文件(如沙盒中的图片路径)。
- 删除数据库中对应的元数据记录(图片 ID、上传状态等)。
- 若该图片处于"上传中"状态,先取消上传任务(调用上传框架的取消接口,如
AFHTTPSessionManager.task.cancel())。
- 批量缓存清除 :提供"清空所有缓存"按钮(如在控件的更多选项中),用户点击后:
- 弹出确认弹窗(避免误操作),确认后执行批量删除。
- 遍历本地缓存目录,删除所有图片文件。
- 清空数据库中所有图片元数据记录。
- 取消所有未完成的上传任务,释放资源。
- 按状态筛选清除 :提供筛选选项(如"清除未上传图片""清除上传失败图片"),用户可针对性清理:
- 清除未上传图片:删除所有"上传状态=未上传"的图片缓存和元数据,适合用户选择后未上传,后续不再需要的场景。
- 清除上传失败图片:删除所有"上传状态=上传失败"且未重试的图片缓存,适合用户已放弃重试的场景。
2. 自动清除策略(系统/控件自动触发)
自动清除无需用户操作,由控件或应用在特定时机执行,核心是"智能化清理,减少用户干预",具体方案:
-
过期时间清除策略(TTL 策略)
- 核心逻辑:为每张图片缓存设置"过期时间(TTL,Time To Live)",超过有效期后自动清除,适用于"图片有时效性(如临时头像、活动图片)"的场景。
- 实现步骤:
- 图片缓存时,在元数据中记录"缓存创建时间戳"和"过期时间"(如默认 7 天过期,可通过控件参数配置)。
- 触发时机:控件初始化时、每次添加新图片时、应用启动时、后台切换到前台时。
- 清理逻辑:遍历所有缓存的元数据,筛选出"当前时间 > 过期时间"的记录,删除对应的图片文件和元数据。
- 优势:避免过期缓存占用空间,适合临时场景;劣势:若图片需长期保留(如用户头像),需手动设置"永不过期"。
-
缓存容量阈值清除策略
- 核心逻辑:设置本地缓存的最大容量(如 100MB),当总缓存容量超过阈值时,自动清理部分缓存,适用于"缓存容量需严格控制"的场景。
- 实现步骤:
- 控件初始化时,配置最大缓存容量(如
maxCacheSize = 100 * 1024 * 1024,支持业务方自定义)。 - 触发时机:每次添加新图片缓存后,计算当前总缓存容量(遍历缓存目录下所有文件大小求和)。
- 清理逻辑:
- 若总容量 ≤ 阈值:不清理。
- 若总容量 > 阈值:按"最近最少使用(LRU)"或"最早创建"规则删除缓存,直到总容量 ≤ 阈值的 80%(预留空间,避免频繁清理)。
- 优先保留"上传成功"的图片缓存(避免重复上传),优先清理"未上传""上传失败"的图片缓存。
- 控件初始化时,配置最大缓存容量(如
- 优势:严格控制缓存占用,避免超出设备存储上限;劣势:需定期计算缓存容量,存在轻微性能开销(可异步计算)。
-
上传成功后自动清理原始图片策略
- 核心逻辑:图片上传成功后,服务器返回图片 URL,本地仅保留"缩略图缓存"(用于 UI 展示),删除"原始图片/压缩后的高清图片"缓存,适用于"仅需展示缩略图,高清图可从服务器下载"的场景。
- 实现步骤:
- 图片上传成功后,上传管理模块回调"上传成功"状态,携带服务器 URL。
- 控件收到回调后,保留缩略图文件(如 200x200 尺寸),删除原始图片文件(如 2000x2000 尺寸)。
- 元数据中更新"是否保留原始图"字段为 false,后续时通过服务器 URL 下载高清图。
- 优势:大幅减少缓存占用(原始图片体积通常是缩略图的 10 倍以上);劣势:高清图时需网络请求,依赖网络状态。
-
应用退出/后台时自动清理策略
- 核心逻辑:利用
UIApplication的生命周期回调,在应用退出或切换到后台时,自动清理"无效缓存"(未上传、上传失败、已过期的缓存),适用于"无需长期保留临时缓存"的场景。 - 实现步骤:
- 注册应用生命周期通知:
UIApplicationDidEnterBackgroundNotification(进入后台)、UIApplicationWillTerminateNotification(即将退出)。 - 收到通知后,在后台线程执行清理逻辑:删除"上传状态=未上传/上传失败"且"创建时间超过 24 小时"的缓存,或直接删除所有未上传的缓存。
- 注意:清理操作需在后台线程执行,避免阻塞主线程;应用退出时清理需快速执行(系统给应用退出的时间有限,可通过
beginBackgroundTask(expirationHandler:)申请额外后台时间)。
- 注册应用生命周期通知:
- 优势:利用空闲时机清理,不影响用户使用;劣势:若用户频繁切换后台,可能导致未上传的缓存被误删(需提示用户"有未上传图片,切换后台可能丢失")。
- 核心逻辑:利用
-
LRU(最近最少使用)清除策略
- 核心逻辑:优先清理"最近最少被访问"的缓存,保留"经常访问"的缓存,适用于"用户可能重复使用历史图片"的场景(如常用头像、常用配图)。
- 实现步骤:
- 元数据中新增"最后访问时间戳"字段,每次、重新上传图片时,更新该时间戳。
- 触发时机:缓存容量达到阈值时、定期(如每天凌晨)执行。
- 清理逻辑:按"最后访问时间戳"升序排序(最早未访问的在前),优先删除排序靠前的缓存,直到满足容量要求;优先保留"上传成功"且"最近访问"的缓存。
- 优势:智能化保留用户常用缓存,提升用户体验;劣势:需维护"最后访问时间",增加元数据存储成本,清理时排序存在轻微性能开销。
三、缓存存储位置与清除的关联(补充说明)
缓存清除策略需结合存储位置设计,iOS 中图片缓存的常用存储位置:
- 沙盒 Documents 目录:适合存储"需长期保留"的缓存(如上传成功的图片),iTunes 同步时会备份,清理时需谨慎(避免误删用户重要数据)。
- 沙盒 Library/Caches 目录:适合存储"可清理"的缓存(如未上传、临时图片),iTunes 同步时不备份,系统低存储空间时可能自动清理,是图片缓存的首选位置。
- 沙盒 tmp 目录:适合存储"临时文件"(如拍摄后的原始图片、压缩过程中的临时文件),应用退出后系统可能自动清理,无需手动清理。
- 设计建议:将图片文件存储在
Library/Caches/ImageUploader目录,元数据存储在UserDefaults或 SQLite 数据库中,清除时同步删除文件和元数据。
面试关键点与加分点
-
关键点:图片上传控件的核心模块(选择-缓存-上传-展示-清理);缓存清除策略的分类(手动+自动);各策略的适用场景和实现逻辑;缓存存储位置与清除的关联。
-
加分点:能结合业务场景设计混合策略(如"TTL+容量阈值+LRU"组合,过期的直接清,容量超了按 LRU 清);能考虑清除时的性能优化(如异步清理、批量删除、避免主线程阻塞);能处理边缘场景(如清理时图片正在上传,需先取消任务;清理前提示用户确认;误删后支持恢复最近删除的缓存);能提供缓存清除的接口设计示例:
class ImageUploadControl { // 手动清除单张图片缓存 func clearCache(for imageID: String) { // 1. 取消该图片的上传任务 uploadManager.cancelTask(with: imageID) // 2. 删除图片文件 let imagePath = cacheManager.imagePath(for: imageID) try? FileManager.default.removeItem(atPath: imagePath) // 3. 删除元数据 cacheManager.deleteMetadata(for: imageID) // 4. 更新 UI updateUIAfterCacheCleared(imageID: imageID) } // 自动清除过期缓存 func autoClearExpiredCache() { DispatchQueue.global().async { let expiredMetadata = self.cacheManager.getExpiredMetadata() for metadata in expiredMetadata { self.clearCache(for: metadata.imageID) } } } // 按容量阈值清除缓存(LRU 规则) func autoClearCacheBySizeThreshold() { DispatchQueue.global().async { let currentSize = self.cacheManager.calculateTotalCacheSize() if currentSize > self.maxCacheSize { let cacheToClear = self.cacheManager.getLRUCacheToClear(targetSize: currentSize - self.reservedCacheSize) for imageID in cacheToClear { self.clearCache(for: imageID) } } } } }
记忆法
- 策略分类记忆:"手动分单批,自动有五类"------ 手动策略分"单张、批量、按状态",自动策略有"过期时间、容量阈值、上传后清原图、后台/退出清、LRU"五类。
- 适用场景记忆:"临时图片用 TTL,容量有限用阈值,常用图片用 LRU,上传成功清原图"------ 对应各自动策略的核心适用场景,快速匹配业务需求。
什么是离屏渲染?其常见场景及优化方案是什么?
离屏渲染(Off-Screen Rendering)是指 GPU 不在当前屏幕帧缓冲区(On-Screen Framebuffer)直接绘制内容,而是先在临时的离屏缓冲区(Off-Screen Buffer)中完成绘制,再将离屏缓冲区的内容合并(Compositing)到屏幕帧缓冲区的渲染过程。其核心问题是"多缓冲区切换与数据拷贝",会增加 GPU 开销、占用额外内存,严重时导致 UI 卡顿(如列表滑动掉帧),是 iOS 性能优化的核心考点。
一、离屏渲染的核心原理与影响
正常的"屏上渲染"流程是:GPU 直接将视图内容绘制到屏幕帧缓冲区,绘制完成后由显示器读取并显示,流程简单、开销低。而离屏渲染需要额外的"创建离屏缓冲区→绘制→拷贝到屏幕缓冲区→释放离屏缓冲区"步骤:
- GPU 为离屏渲染创建独立的临时缓冲区(通常是 FBO,帧缓冲对象)。
- 将目标视图的内容(如带圆角、阴影的视图)绘制到该临时缓冲区。
- 完成后,将临时缓冲区的像素数据拷贝到屏幕帧缓冲区。
- 释放临时缓冲区(或复用,若开启缓冲区复用)。
离屏渲染的核心负面影响:
- GPU 开销增加:多缓冲区的创建、切换、拷贝操作会消耗 GPU 算力,尤其当大量视图同时触发离屏渲染时,GPU 会成为性能瓶颈。
- 内存占用增加:每个离屏缓冲区都需要占用显存(大小 = 缓冲区分辨率 × 像素格式字节数,如 1080p 屏幕的缓冲区约占用 4MB),多个离屏缓冲区可能导致显存不足,触发内存警告。
- 卡顿风险:若离屏渲染的耗时超过屏幕刷新周期(60fps 下约 16.67ms),会导致帧间隔延长,出现掉帧、滑动不流畅等问题。
二、离屏渲染的常见场景
iOS 中触发离屏渲染的场景可分为"系统自动触发"和"开发者手动触发"两类,需重点关注系统自动触发的场景:
-
系统自动触发的离屏渲染场景
-
视图设置圆角+裁剪+非 opaque 背景 :这是最常见的场景。当同时设置
layer.cornerRadius(圆角)、layer.masksToBounds = true(裁剪超出圆角的内容),且视图的backgroundColor为透明(或layer.opacity < 1)时,GPU 无法直接在屏幕缓冲区完成圆角裁剪,需通过离屏渲染实现。例如:let view = UIView(frame: CGRect(x: 50, y: 50, width: 100, height: 100)) view.backgroundColor = .clear // 透明背景 view.layer.cornerRadius = 50 // 圆角 view.layer.masksToBounds = true // 裁剪 // 触发离屏渲染 -
设置阴影(layer.shadow 相关属性) *:阴影需要基于视图的轮廓(alpha 通道)计算,而视图的轮廓可能包含透明区域或复杂形状,GPU 需先在离屏缓冲区绘制视图的轮廓,再基于轮廓渲染阴影,最后合并到屏幕缓冲区。例如
layer.shadowColor、layer.shadowOffset、layer.shadowOpacity > 0时,默认触发离屏渲染。 -
设置遮罩(layer.mask):遮罩层(mask)是一个透明的图层,GPU 需先将视图内容与遮罩层的 alpha 通道进行混合计算(决定哪些区域显示、哪些隐藏),该混合过程需在离屏缓冲区完成,再将结果拷贝到屏幕缓冲区。
-
视图透明度动画(layer.opacity 动画) :当对视图的
layer.opacity进行动画时,若视图包含子视图或复杂内容,GPU 需先将视图及其子视图的内容绘制到离屏缓冲区,再对整个缓冲区的像素进行透明度调整,最后合并到屏幕缓冲区(静态透明度opacity = 0.5不一定触发,动画时触发概率更高)。 -
使用光栅化(layer.shouldRasterize = true):光栅化是将图层内容渲染为位图(bitmap)并缓存,后续复用该位图以避免重复绘制。开启后,GPU 会先将图层绘制到离屏缓冲区(生成位图)并缓存,属于主动触发的离屏渲染,若使用不当(如频繁修改图层内容)会适得其反。
-
-
开发者手动触发的离屏渲染场景
- 使用 Core Graphics 绘制(draw(_:) 方法) :当重写 UIView 的
draw(_:)方法并使用 Core Graphics 绘制内容时,系统会为该视图创建离屏缓冲区,GPU 先在该缓冲区完成绘制,再合并到屏幕缓冲区。 - 自定义图层(CALayer 子类重写 drawInContext:) :与
draw(_:)类似,自定义 CALayer 并重写绘制方法时,会触发离屏渲染。 - 使用 UIKit 高级效果(如 UIVisualEffectView 毛玻璃):毛玻璃效果需要对下层视图的内容进行模糊处理,该处理过程需在离屏缓冲区完成,属于系统级的离屏渲染,但优化空间较小。
- 使用 Core Graphics 绘制(draw(_:) 方法) :当重写 UIView 的
三、离屏渲染的优化方案
优化的核心思路是"避免不必要的离屏渲染,或通过更高效的方式替代",针对不同场景有明确的优化方向:
-
优化圆角+裁剪场景
-
方案一:使用不透明背景+圆角,避免
masksToBounds。若视图背景是纯色且不透明,可直接设置cornerRadius且不开启masksToBounds(此时仅背景会显示圆角,若视图内有图片或子视图,需确保子视图也设置圆角);若必须裁剪,可通过图片预处理实现:将图片本身处理为圆角(如使用 UIGraphicsImageRenderer 绘制圆角图片),视图直接显示该图片,无需设置cornerRadius和masksToBounds。示例代码:// 预处理圆角图片,避免视图设置圆角触发离屏渲染 func createRoundedImage(image: UIImage, cornerRadius: CGFloat) -> UIImage? { let renderer = UIGraphicsImageRenderer(size: image.size) return renderer.image { context in let rect = CGRect(origin: .zero, size: image.size) // 绘制圆角路径 context.cgContext.addPath(UIBezierPath(roundedRect: rect, cornerRadius: cornerRadius).cgPath) context.cgContext.clip() // 裁剪 image.draw(in: rect) // 绘制图片 } } // 视图直接显示圆角图片,无需设置 cornerRadius 和 masksToBounds let imageView = UIImageView(image: createRoundedImage(image: originalImage, cornerRadius: 50)) -
方案二:使用
CALayer的cornerRadius结合contentsScale,确保圆角绘制效率。对于纯色视图,可设置layer.backgroundColor为目标颜色,cornerRadius为圆角值,masksToBounds = true,同时设置layer.contentsScale = UIScreen.main.scale(匹配屏幕分辨率),减少 GPU 绘制压力。
-
-
优化阴影场景
-
方案一:设置
layer.shadowPath,明确阴影轮廓。默认情况下,GPU 需通过视图的 alpha 通道计算阴影轮廓,耗时较高;若手动设置shadowPath(明确的路径,如矩形、圆形),GPU 可直接基于路径渲染阴影,无需计算轮廓,避免离屏渲染。示例代码:let view = UIView(frame: CGRect(x: 50, y: 50, width: 100, height: 100)) view.layer.shadowColor = UIColor.black.cgColor view.layer.shadowOffset = CGSize(width: 2, height: 2) view.layer.shadowOpacity = 0.5 // 设置阴影路径为视图的 bounds 路径,避免离屏渲染 view.layer.shadowPath = UIBezierPath(roundedRect: view.bounds, cornerRadius: 0).cgPath -
方案二:使用背景视图承载阴影。创建一个独立的背景视图,仅用于显示阴影(设置
shadow*属性),目标视图作为子视图添加到背景视图上,且目标视图不设置阴影相关属性,避免目标视图触发离屏渲染。
-
-
优化遮罩(mask)场景
- 方案一:使用图片替代遮罩。若遮罩是简单的形状(如圆形、不规则图标),可直接使用带透明通道的图片作为视图的背景图或内容图,替代
layer.mask,避免遮罩触发的离屏渲染。 - 方案二:减少遮罩层的复杂度。若必须使用遮罩,尽量简化遮罩层的内容(如使用纯色遮罩、简单路径遮罩),避免遮罩层包含复杂的子视图或渐变效果,降低 GPU 混合计算的开销。
- 方案一:使用图片替代遮罩。若遮罩是简单的形状(如圆形、不规则图标),可直接使用带透明通道的图片作为视图的背景图或内容图,替代
-
优化光栅化(shouldRasterize)场景
- 方案一:合理开启光栅化,仅用于"静态且频繁复用"的图层。例如列表中固定不变的单元格(cell)、静态的图标视图,开启
shouldRasterize = true后,GPU 会缓存图层的位图,后续复用无需重新绘制;但对于频繁修改的图层(如动态更新内容的标签),开启后会导致频繁的离屏渲染和缓存失效,反而降低性能。 - 方案二:设置合理的缓存过期时间。通过
layer.rasterizationScale = UIScreen.main.scale确保缓存的位图匹配屏幕分辨率,避免模糊;同时避免长期缓存未使用的图层,可通过定期重置shouldRasterize为 false 再设为 true,清除旧缓存。
- 方案一:合理开启光栅化,仅用于"静态且频繁复用"的图层。例如列表中固定不变的单元格(cell)、静态的图标视图,开启
-
避免不必要的离屏渲染场景
- 移除无用的
masksToBounds和cornerRadius:若视图无需圆角或裁剪,直接移除相关设置,避免误触发离屏渲染。 - 避免过度使用透明效果:尽量使用不透明的背景色(
opaque = true),减少 GPU 的混合计算,降低离屏渲染的概率。 - 替换 Core Graphics 绘制:若使用
draw(_:)方法绘制简单内容(如纯色矩形、文字),可直接通过layer.backgroundColor、UILabel等 UIKit 组件替代,避免手动绘制触发的离屏渲染。
- 移除无用的
面试关键点与加分点
- 关键点:离屏渲染的定义(多缓冲区绘制与拷贝);核心负面影响(GPU 开销、内存占用、卡顿);常见触发场景(圆角+裁剪、阴影、遮罩、光栅化等);针对性优化方案(图片预处理、设置 shadowPath、合理使用光栅化等)。
- 加分点:能通过 Instrument 工具(如 Core Animation 工具)检测离屏渲染(开启"Color Off-Screen Rendered"选项,红色标记的区域即为离屏渲染区域);能区分"强制离屏渲染"和"自愿离屏渲染"(系统自动触发为强制,开发者手动触发为自愿);能解释离屏渲染与屏幕刷新周期的关系(离屏渲染耗时超过 16.67ms 会导致掉帧);能结合实际项目案例说明优化效果(如列表滑动帧率从 40fps 提升到 60fps)。
记忆法
- 场景记忆:"圆角裁剪阴影罩,光栅化加绘制调"------ 提炼常见触发场景(圆角+裁剪、阴影、遮罩、光栅化、手动绘制),快速记忆。
- 优化思路记忆:"避免替代提效率,工具检测定问题"------ 核心优化方向是"避免不必要的离屏渲染""用更高效的方式替代",结合 Instrument 工具检测问题,形成完整优化闭环。
有 ABCD 四个任务,要求 ABC 异步执行,且全部完成后才能执行 D,有几种实现方法?
在 iOS 开发中,满足"ABC 异步执行、全部完成后执行 D"的需求,本质是"并发执行多个异步任务,等待所有任务完成后触发回调",核心依赖 iOS 的异步任务调度机制(GCD、OperationQueue、Combine 等)。常见实现方法有 5 种,每种方法各有适用场景,需结合业务复杂度、是否需要取消任务、是否需要获取任务结果等需求选择。
一、方法一:GCD 调度组(DispatchGroup)
DispatchGroup 是 GCD 提供的专门用于"等待多个异步任务完成"的机制,核心逻辑是"将异步任务加入组→监听组内所有任务完成→触发回调",是最常用、最灵活的实现方式,支持任意类型的异步任务(网络请求、文件读写、耗时计算等)。
实现步骤与代码示例
- 创建调度组(
DispatchGroup())。 - 为每个异步任务(A、B、C)调用
group.enter()(标记任务开始)。 - 在每个任务的完成回调中调用
group.leave()(标记任务结束),enter()和leave()必须成对出现。 - 通过
group.notify(queue:)监听所有任务完成,在回调中执行 D 任务(notify不会阻塞当前线程);或通过group.wait()阻塞当前线程等待所有任务完成(不推荐在主线程使用,会导致 UI 卡顿)。
示例代码(Swift):
// 1. 创建调度组
let group = DispatchGroup()
// 2. 异步执行任务 A(全局并发队列)
DispatchQueue.global().async(group: group) {
print("任务 A 开始执行")
// 模拟任务 A 耗时操作(如网络请求、文件读写)
Thread.sleep(forTimeInterval: 2)
print("任务 A 执行完成")
}
// 异步执行任务 B
DispatchQueue.global().async(group: group) {
print("任务 B 开始执行")
Thread.sleep(forTimeInterval: 1)
print("任务 B 执行完成")
}
// 异步执行任务 C
DispatchQueue.global().async(group: group) {
print("任务 C 开始执行")
Thread.sleep(forTimeInterval: 3)
print("任务 C 执行完成")
}
// 3. 所有任务完成后,在主线程执行任务 D
group.notify(queue: DispatchQueue.main) {
print("任务 A、B、C 全部完成,执行任务 D")
// 执行 D 任务(如更新 UI、整合结果)
}特点与适用场景
- 优点:使用简单,支持任意异步任务(无需修改任务本身),
notify回调不阻塞线程,支持在指定队列(如主线程)执行 D 任务;可通过group.wait(timeout:)设置超时时间,处理任务超时场景。 - 缺点:不支持任务取消(若需取消任务,需手动管理任务标识);无法直接获取单个任务的执行结果(需通过全局变量或闭包捕获)。
- 适用场景:大多数异步任务协同场景(如多个网络请求并行、多文件并行读写),无需取消任务,仅需等待所有任务完成。
二、方法二:GCD 屏障(DispatchBarrier)
DispatchBarrier 是 GCD 用于"控制并发队列中任务执行顺序"的机制 ,核心逻辑是"并发队列中,屏障任务会等待之前的所有并发任务完成后执行,且之后的任务需等待屏障任务完成"。需注意:必须使用自定义并发队列(DispatchQueue(label:attributes: .concurrent)),系统全局并发队列(global())中的屏障任务无效。
实现步骤与代码示例
- 创建自定义并发队列。
- 在队列中异步执行任务 A、B、C(并发执行)。
- 在 A、B、C 之后添加屏障任务(
async(flags: .barrier)),屏障任务中执行 D 任务,确保 D 在 A、B、C 全部完成后执行。
示例代码(Swift):
// 1. 创建自定义并发队列
let concurrentQueue = DispatchQueue(label: "com.example.concurrentQueue", attributes: .concurrent)
// 2. 并发执行任务 A、B、C
concurrentQueue.async {
print("任务 A 开始执行")
Thread.sleep(forTimeInterval: 2)
print("任务 A 执行完成")
}
concurrentQueue.async {
print("任务 B 开始执行")
Thread.sleep(forTimeInterval: 1)
print("任务 B 执行完成")
}
concurrentQueue.async {
print("任务 C 开始执行")
Thread.sleep(forTimeInterval: 3)
print("任务 C 执行完成")
}
// 3. 添加屏障任务,执行 D(等待 A、B、C 全部完成)
concurrentQueue.async(flags: .barrier) {
print("任务 A、B、C 全部完成,执行任务 D")
// 执行 D 任务
}特点与适用场景
- 优点:无需额外调度组,通过队列本身的特性控制顺序,实现简单;适合与队列绑定的任务(如操作同一资源的多个异步任务,屏障任务可确保资源操作的原子性)。
- 缺点:仅支持自定义并发队列,系统全局队列无效;不支持任务取消和超时处理;D 任务必须在同一队列执行,灵活性低于 DispatchGroup。
- 适用场景:任务 A、B、C 需操作同一资源(如读写同一文件、修改同一全局变量),D 任务依赖该资源的最终状态,需确保 A、B、C 对资源的操作完成后再执行 D。
三、方法三:NSOperationQueue + 依赖关系
NSOperationQueue(操作队列)通过"任务依赖"机制控制执行顺序,核心逻辑是"将 A、B、C 封装为 NSOperation 子类,设置 D 任务依赖于 A、B、C 任务,确保 D 仅在 A、B、C 全部完成后执行"。支持任务取消、优先级设置、获取任务结果等高级功能。
实现步骤与代码示例
- 封装任务 A、B、C、D 为 NSOperation 子类(或使用 BlockOperation 简化)。
- 设置 D 任务的依赖:
dTask.addDependency(aTask)、dTask.addDependency(bTask)、dTask.addDependency(cTask)。 - 将所有任务添加到 NSOperationQueue 中,队列会自动调度 A、B、C 并发执行,待其全部完成后执行 D。
示例代码(Swift):
// 1. 封装任务 A、B、C、D 为 BlockOperation(简化版,无需自定义子类)
let aTask = BlockOperation {
print("任务 A 开始执行")
Thread.sleep(forTimeInterval: 2)
print("任务 A 执行完成")
}
let bTask = BlockOperation {
print("任务 B 开始执行")
Thread.sleep(forTimeInterval: 1)
print("任务 B 执行完成")
}
let cTask = BlockOperation {
print("任务 C 开始执行")
Thread.sleep(forTimeInterval: 3)
print("任务 C 执行完成")
}
let dTask = BlockOperation {
print("任务 A、B、C 全部完成,执行任务 D")
// 执行 D 任务
}
// 2. 设置 D 任务依赖于 A、B、C
dTask.addDependency(aTask)
dTask.addDependency(bTask)
dTask.addDependency(cTask)
// 3. 创建操作队列,添加所有任务(A、B、C 并发执行,D 等待依赖完成)
let operationQueue = OperationQueue()
operationQueue.addOperations([aTask, bTask, cTask, dTask], waitUntilFinished: false)特点与适用场景
- 优点:支持任务取消(
aTask.cancel())、优先级设置(aTask.queuePriority)、获取任务结果(通过自定义 NSOperation 子类的属性传递);支持复杂依赖关系(如 D 依赖 A、B、C,E 依赖 D);队列可设置最大并发数(operationQueue.maxConcurrentOperationCount)。 - 缺点:相比 GCD 略显繁琐,需封装任务为 Operation;依赖关系不可循环(如 A 依赖 B,B 依赖 A 会导致死锁)。
- 适用场景:需要灵活控制任务(取消、优先级)、获取任务结果、复杂依赖关系的场景(如多步骤异步流程,每个步骤有明确的依赖)。
四、方法四:Combine 框架(iOS 13+)
Combine 是 Apple 推出的响应式编程框架 ,通过"发布者(Publisher)+ 订阅者(Subscriber)"模式处理异步任务,可通过 Publishers.Zip3 合并三个任务的发布者,等待所有发布者完成后执行 D 任务。仅适用于 iOS 13 及以上版本。
实现步骤与代码示例
- 将任务 A、B、C 封装为发布者(如
Future发布者,代表单个异步任务的结果)。 - 使用
Publishers.Zip3合并三个发布者,等待所有发布者发送完成信号。 - 订阅合并后的发布者,在
sink回调中执行 D 任务。
示例代码(Swift):
import Combine
// 存储订阅对象,避免被释放(Combine 订阅需持有 cancellable)
var cancellables = Set<AnyCancellable>()
// 1. 封装任务 A 为 Future 发布者(Future 仅发送一次结果或失败)
func taskA() -> Future<Void, Error> {
return Future { promise in
DispatchQueue.global().async {
print("任务 A 开始执行")
Thread.sleep(forTimeInterval: 2)
print("任务 A 执行完成")
promise(.success(())) // 任务完成,发送成功信号
}
}
}
// 封装任务 B、C
func taskB() -> Future<Void, Error> {
return Future { promise in
DispatchQueue.global().async {
print("任务 B 开始执行")
Thread.sleep(forTimeInterval: 1)
print("任务 B 执行完成")
promise(.success(()))
}
}
}
func taskC() -> Future<Void, Error> {
return Future { promise in
DispatchQueue.global().async {
print("任务 C 开始执行")
Thread.sleep(forTimeInterval: 3)
print("任务 C 执行完成")
promise(.success(()))
}
}
}
// 2. 合并三个发布者,等待全部完成
Publishers.Zip3(taskA(), taskB(), taskC())
.receive(on: DispatchQueue.main) // 在主线程执行回调
.sink(receiveCompletion: { completion in
// 处理完成或失败(如任意任务失败,会触发 completion)
if case .failure(let error) = completion {
print("任务执行失败:\(error)")
}
}, receiveValue: { _, _, _ in
// 所有任务成功完成,执行任务 D
print("任务 A、B、C 全部完成,执行任务 D")
})
.store(in: &cancellables) // 持有订阅特点与适用场景
- 优点:响应式编程风格,支持任务结果传递、错误处理(任意任务失败可快速捕获);可与 SwiftUI 无缝集成(适合跨平台开发);支持取消订阅(
cancellables.removeAll())。 - 缺点:仅支持 iOS 13+,兼容性有限;学习成本较高,需熟悉 Combine 框架的发布者、订阅者、运算符等概念。
- 适用场景:iOS 13+ 版本的应用,采用响应式编程架构(如 SwiftUI 项目),需要统一处理任务结果和错误的场景。
五、方法五:手动计数(不推荐,仅作理解)
手动计数是最原始的实现方式,核心逻辑是"维护一个计数器,记录已完成的任务数,每个任务完成后计数器加 1,当计数器等于任务总数时执行 D 任务"。需手动处理线程安全(避免多线程同时修改计数器)。
实现步骤与代码示例
- 定义线程安全的计数器(如使用
Atomic类型,或通过 GCD 串行队列保证原子操作)。 - 异步执行 A、B、C 任务,每个任务完成后在串行队列中更新计数器。
- 计数器等于 3 时,执行 D 任务。
示例代码(Swift):
// 1. 定义线程安全的计数器(通过串行队列保证原子操作)
let countQueue = DispatchQueue(label: "com.example.countQueue")
var completedCount = 0
// 2. 定义任务完成后的统一回调(更新计数器并检查是否执行 D)
func taskCompleted() {
countQueue.async {
completedCount += 1
if completedCount == 3 {
// 所有任务完成,在主线程执行 D
DispatchQueue.main.async {
print("任务 A、B、C 全部完成,执行任务 D")
}
}
}
}
// 3. 异步执行 A、B、C 任务
DispatchQueue.global().async {
print("任务 A 开始执行")
Thread.sleep(forTimeInterval: 2)
print("任务 A 执行完成")
taskCompleted()
}
DispatchQueue.global().async {
print("任务 B 开始执行")
Thread.sleep(forTimeInterval: 1)
print("任务 B 执行完成")
taskCompleted()
}
DispatchQueue.global().async {
print("任务 C 开始执行")
Thread.sleep(forTimeInterval: 3)
print("任务 C 执行完成")
taskCompleted()
}特点与适用场景
- 优点:无需依赖任何框架,仅使用基础多线程知识,理解简单。
- 缺点:手动处理线程安全,容易出现竞态条件(如未使用串行队列导致计数器更新错误);不支持任务取消、超时处理、错误处理,扩展性差;代码冗余,维护成本高。
- 适用场景:仅用于理解"等待多个异步任务完成"的核心逻辑,实际开发中不推荐使用(优先选择 DispatchGroup 或 OperationQueue)。
面试关键点与加分点
- 关键点:5 种实现方法的核心原理(调度组、屏障、依赖、Combine 合并、手动计数);每种方法的适用场景、优缺点;线程安全问题(如手动计数需保证原子操作);任务取消、错误处理的支持情况。
- 加分点:能对比不同方法的性能差异(如 DispatchGroup 比 OperationQueue 更轻量,性能略优);能处理边缘场景(如任务超时、任务失败后的降级策略);能结合实际项目选择合适的方法(如简单场景用 DispatchGroup,复杂场景用 OperationQueue,响应式项目用 Combine);能写出线程安全的手动计数实现(如使用
OSAtomicIncrement32或串行队列)。
记忆法
- 方法分类记忆:"GCD 两组(调度组、屏障),Operation 依赖,Combine 合并,手动计数"------ 提炼 5 种方法的核心标识,快速区分。
- 适用场景记忆:"简单用组,复杂用依赖,响应式用 Combine,避免手动计数"------ 按业务复杂度选择,优先推荐 DispatchGroup 和 OperationQueue,减少手动实现的风险。
C++ 中闭包的概念是什么?
在 C++ 中,闭包(Closure)是一个能够捕获其定义所在作用域中变量(自由变量)的可调用对象 ,核心特征是"函数代码 + 捕获的变量上下文"的组合------它不仅包含可执行的代码逻辑,还持有对外部变量的引用或副本,即使这些变量的定义作用域已经结束,闭包仍能访问和操作这些变量。C++ 中的闭包主要通过"函数对象(Functor)"和"C++11 及以后的 Lambda 表达式"实现,其中 Lambda 是最常用、最简洁的闭包形式。
一、闭包的核心构成与本质
闭包的本质是"带状态的可调用对象",与普通函数的核心区别在于"是否持有外部变量的上下文":
- 普通函数:仅包含代码逻辑,不依赖外部作用域的变量(除全局变量、静态变量外),调用时的行为仅由输入参数决定,无"状态"可言。
- 闭包:包含代码逻辑 + 捕获的外部变量上下文(状态),调用时的行为不仅取决于输入参数,还取决于捕获变量的当前值。即使捕获变量的原始作用域被销毁(如函数返回后),闭包仍能通过捕获的副本或引用访问该变量(需注意生命周期问题)。
闭包的核心构成:
- 可调用接口 :能像函数一样被调用(重载
operator()或 Lambda 自带的调用逻辑),支持传入参数并返回结果。 - 捕获列表 :明确捕获外部作用域的变量,捕获方式分为"值捕获"(拷贝变量副本)和"引用捕获"(持有变量引用),还可指定捕获权限(如
mutable允许修改值捕获的变量)。 - 变量上下文:存储捕获的变量(值捕获存储副本,引用捕获存储指针/引用),构成闭包的"状态",每次调用闭包时可能读取或修改该状态。
二、C++ 中闭包的实现方式
C++ 中闭包的实现依赖"可调用对象",主要有两种形式,其中 Lambda 是 C++11 后推荐的方式:
-
传统实现:函数对象(Functor) 函数对象是重载了
operator()的类实例,通过类的成员变量存储"捕获的外部变量",从而实现闭包的"状态持有"特性。例如,实现一个捕获外部变量并累加的闭包:#include
using namespace std;// 函数对象(闭包的传统实现)
class Adder {
private:
// 捕获的外部变量(状态):存储累加的初始值
int base_;
public:
// 构造函数:传入外部变量,初始化状态
Adder(int base) : base_(base) {}// 重载 operator():可调用接口,实现累加逻辑 int operator()(int num) { base_ += num; // 操作捕获的变量(状态更新) return base_; }};
int main() {
int init = 10;
// 创建函数对象(闭包实例),捕获 init 的值(通过构造函数传入)
Adder adder(init);// 调用闭包,行为依赖捕获的状态(base_) cout << adder(5) << endl; // base_ = 10+5=15,输出 15 cout << adder(3) << endl; // base_ = 15+3=18,输出 18 cout << init << endl; // init 未被修改(值捕获),输出 10 return 0;}
- 该函数对象
Adder是典型的闭包:通过成员变量base_捕获外部变量init,每次调用operator()时都会修改base_(状态更新),且即使init的作用域在main函数内,adder实例仍能访问和操作base_(init的副本)。
- 现代实现:Lambda 表达式(C++11+) Lambda 是 C++11 引入的匿名函数对象,编译器会自动将 Lambda 转换为一个匿名的函数对象类,其成员变量对应捕获的外部变量,
operator()对应 Lambda 的代码逻辑------因此 Lambda 本质上是编译器自动生成的闭包,使用更简洁、灵活。
Lambda 实现闭包的核心语法:
[capture-list](parameters) mutable -> return-type {
// 代码逻辑(可访问捕获的变量)
}capture-list:捕获列表,指定捕获的外部变量及捕获方式(如[=]按值捕获所有外部变量,[&]按引用捕获所有外部变量,[x, &y]按值捕获 x、按引用捕获 y)。mutable:可选,允许修改值捕获的变量(默认值捕获的变量是const类型,不可修改)。return-type:可选,返回值类型,编译器可自动推导(复杂场景需显式指定)。
示例:用 Lambda 实现上述累加闭包:
#include <iostream>
using namespace std;
int main() {
int init = 10;
// Lambda 闭包:按值捕获 init,mutable 允许修改捕获的副本
auto adder = [=](int num) mutable -> int {
init += num; // 操作捕获的副本(因 mutable 可修改)
return init;
};
cout << adder(5) << endl; // init 副本 = 10+5=15,输出 15
cout << adder(3) << endl; // init 副本 = 15+3=18,输出 18
cout << init << endl; // 原始 init 未被修改,输出 10
// 按引用捕获的 Lambda 闭包(修改原始变量)
auto adderRef = [&](int num) -> int {
init += num; // 操作原始 init 的引用
return init;
};
cout << adderRef(2) << endl; // 原始 init = 10+2=12,输出 12
cout << init << endl; // 原始 init 被修改,输出 12
return 0;
}- 该 Lambda 表达式
adder是标准闭包:通过捕获列表[=]捕获外部变量init(值捕获),mutable允许修改捕获的副本,每次调用时状态(副本init)被更新;adderRef则通过引用捕获init,直接修改原始变量,同样体现了闭包"持有外部变量上下文"的特征。
三、闭包的关键特性与注意事项
- 捕获变量的生命周期与安全性
-
值捕获:捕获的是变量的副本,闭包持有副本的所有权,即使原始变量被销毁(如函数返回后),闭包仍能安全访问副本,无悬垂引用风险。
-
引用捕获:捕获的是变量的引用(本质是指针),若原始变量的生命周期短于闭包(如闭包被保存到函数外部,而捕获的局部变量已销毁),则闭包访问该引用时会触发未定义行为(悬垂引用)。例如:
#include <functional> using namespace std; // 错误示例:返回的闭包引用了局部变量 x function<int()> createAdder() { int x = 5; // 局部变量,函数返回后销毁 return [&]() { return x + 10; }; // 引用捕获 x,悬垂引用 } int main() { auto adder = createAdder(); cout << adder()
-
C++ 面向对象的设计原理有哪些?
C++ 面向对象的设计原理核心围绕 "高内聚、低耦合、可复用、可扩展" 四大目标,是指导类设计、继承关系、模块划分的核心准则,常用的核心设计原理包括五大类,每类原理都对应具体的设计场景和问题解决方案。
一、封装(Encapsulation):隐藏细节,暴露接口
封装是面向对象的基础,核心是 "将数据(属性)和操作数据的方法(成员函数)绑定为一个整体,并隐藏对象的内部实现细节,仅通过公开接口与外部交互"。
-
核心思想:"数据私有化,接口公有化"------ 对象的状态(成员变量)仅能通过自身提供的公有方法修改,外部无法直接访问,避免外部操作破坏对象的完整性和一致性。
-
实现方式:通过访问控制符(
private、protected、public)控制成员的访问权限:private:私有成员,仅类内部和友元可访问,外部及派生类不可直接访问(核心隐藏的细节)。protected:保护成员,类内部、友元和派生类可访问,外部不可访问(支持继承复用的同时隐藏细节)。public:公有成员,类内部、友元、派生类、外部均能访问(暴露给外部的交互接口)。
-
代码示例:
#include <string> using namespace std; class Person { private: // 私有属性:隐藏内部状态,外部无法直接修改 string name; int age; public: // 公有接口:外部通过接口与对象交互,内部保证逻辑合法 void setName(const string& n) { if (!n.empty()) name = n; // 内部校验,避免空名字 } void setAge(int a) { if (a >= 0 && a <= 120) age = a; // 校验年龄合法性 } string getName() const { return name; } int getAge() const { return age; } }; int main() { Person p; p.setName("Alice"); p.setAge(25); // p.name = "Bob"; // 编译错误:私有属性不可直接访问 return 0; } -
核心优势:降低外部与对象的耦合度,对象内部实现修改时(如年龄校验规则调整),外部代码无需改动;提高代码安全性,避免非法操作。
二、继承(Inheritance):复用已有代码,建立层级关系
继承是 "从已有类(基类 / 父类)派生出新类(派生类 / 子类),子类自动拥有父类的非私有成员,同时可扩展新功能或重写父类方法",核心是实现代码复用和建立类的层级关系。
-
核心思想:"共性抽取,个性扩展"------ 将多个类的共同属性和方法抽取到父类,子类继承后仅需实现自身特有的功能,减少代码冗余。
-
实现方式:通过
class 子类 : 继承方式 父类声明,继承方式包括public(公有继承)、protected(保护继承)、private(私有继承),默认私有继承。 -
代码示例:
// 父类:抽取共性(姓名、年龄、吃饭) class Person { protected: string name; int age; public: void eat() { cout << name << " is eating." << endl; } }; // 子类:继承父类,扩展特有功能(学生的学号、学习方法) class Student : public Person { private: string studentID; public: void setStudentInfo(const string& n, int a, const string& id) { name = n; // 访问父类保护属性 age = a; studentID = id; } void study() { cout << studentID << " " << name << " is studying." << endl; } }; int main() { Student s; s.setStudentInfo("Bob", 20, "2023001"); s.eat(); // 继承父类的方法 s.study(); // 子类特有方法 return 0; } -
核心优势:代码复用,减少重复开发;建立类的层级关系(如
Person→Student→GraduateStudent),符合现实世界的逻辑结构。 -
注意事项:避免多重继承(可能导致菱形继承问题),优先使用单继承 + 组合;避免继承过深(超过 3 层),导致代码复杂度升高。
三、多态(Polymorphism):一个接口,多种实现
多态是 "同一操作作用于不同对象,产生不同的执行结果" ,核心是通过 "虚函数(virtual)" 实现,分为静态多态(编译时多态)和动态多态(运行时多态)。
-
- 动态多态(核心):
-
实现条件:父类声明虚函数(
virtual修饰),子类重写(override)该虚函数,通过父类指针或引用指向子类对象调用虚函数。 -
核心原理:父类含有虚函数时,编译器会为类生成虚函数表(vtable),存储虚函数地址;对象会包含一个虚表指针(vptr),指向自身类的虚函数表;调用时通过 vptr 查找对应子类的虚函数实现,实现运行时动态绑定。
-
代码示例:
class Shape { public: // 虚函数:父类声明接口 virtual double getArea() const = 0; // 纯虚函数,强制子类实现 }; class Circle : public Shape { private: double radius; public: Circle(double r) : radius(r) {} // 重写虚函数 double getArea() const override { return 3.14 * radius * radius; } }; class Rectangle : public Shape { private: double width, height; public: Rectangle(double w, double h) : width(w), height(h) {} double getArea() const override { return width * height; } }; int main() { Shape* shape1 = new Circle(5); Shape* shape2 = new Rectangle(4, 6); // 同一接口(getArea),不同实现 cout << "Circle Area: " << shape1->getArea() << endl; // 78.5 cout << "Rectangle Area: " << shape2->getArea() << endl; // 24 delete shape1; delete shape2; return 0; }
-
- 静态多态:通过函数重载、模板实现,编译时确定调用的函数版本(如
add(int, int)和add(double, double)),不属于面向对象核心多态,是语法层面的多态。
- 静态多态:通过函数重载、模板实现,编译时确定调用的函数版本(如
-
核心优势:提高代码灵活性和扩展性,新增子类(如
Triangle)时,无需修改父类和调用代码,仅需实现子类的虚函数,符合 "开闭原则"。
四、抽象(Abstraction):提取核心特征,忽略无关细节
抽象是 "忽略对象的非本质细节,仅提取与目标相关的核心特征和行为,形成抽象类或接口",核心是 "聚焦有用信息,简化复杂系统"。
- 实现方式:
- 抽象类:包含纯虚函数(
virtual 返回类型 函数名() = 0)的类,无法实例化,仅作为父类供子类继承,强制子类实现纯虚函数(定义接口规范)。 - 接口:C++ 中无专门的
interface关键字,通过 "仅包含纯虚函数和静态常量的抽象类" 模拟接口(如上述Shape类)。
- 抽象类:包含纯虚函数(
- 核心思想:抽象类定义 "做什么"(接口),子类定义 "怎么做"(实现),屏蔽不同子类的实现差异,仅暴露统一接口。
- 核心优势:降低系统复杂度,使用者无需关注子类的具体实现,仅需通过抽象接口交互;便于团队协作,明确模块间的接口约定。
五、组合(Composition)/ 聚合(Aggregation):优先组合,而非继承
组合和聚合是 "has-a" 关系(A 包含 B),核心是通过将其他类的对象作为成员变量,实现功能复用,比继承更灵活、耦合度更低,是 "合成复用原则" 的核心体现。
-
- 组合(强依赖):
-
关系:部分(成员对象)与整体(当前类)生命周期一致,整体创建时部分创建,整体销毁时部分销毁(部分不能脱离整体独立存在)。
-
代码示例:
Car包含Engine,Car创建时Engine被初始化,Car销毁时Engine也被销毁。class Engine { public: void start() { cout << "Engine started." << endl; } }; class Car { private: Engine engine; // 组合:Engine 是 Car 的一部分 public: void startCar() { engine.start(); } }; int main() { Car car; car.startCar(); // 间接调用 Engine 的方法 return 0; }
-
- 聚合(弱依赖):
- 关系:部分(成员对象)与整体生命周期独立,部分可被多个整体共享(如
Company包含Employee,Employee可脱离Company存在)。 - 实现方式:通常通过指针或引用持有成员对象,成员对象由外部创建,整体仅使用其接口。
-
核心优势:比继承灵活,可动态替换成员对象(如
Car可更换不同类型的Engine);降低耦合度,成员对象的修改不会直接影响整体;避免继承带来的菱形继承、继承过深等问题,符合 "优先组合,而非继承" 的设计原则。
面试关键点与加分点
- 关键点:五大核心原理(封装、继承、多态、抽象、组合 / 聚合)的定义、实现方式、核心优势;动态多态的实现条件和原理(虚函数表、虚表指针);组合与继承的区别及选择原则。
- 加分点:能结合设计模式说明原理的应用(如工厂模式利用多态、策略模式利用组合);能解释 "合成复用原则"(优先组合而非继承)的原因;能区分静态多态与动态多态的差异;能分析菱形继承问题及解决方案(虚继承
virtual public)。
记忆法
- 核心原理记忆:"封继多抽组,面向对象五虎"------ 提炼五大核心原理的关键字,快速关联;
- 核心思想记忆:"封装藏细节,继承复代码,多态扩功能,抽象定接口,组合解耦合"------ 对应每类原理的核心目标,强化理解。
C++ 中保护继承和公有继承的差异是什么?
C++ 中保护继承(protected inheritance)和公有继承(public inheritance)的核心差异,在于基类成员在派生类中的访问权限,以及派生类对象 / 外部代码对基类成员的访问权限------ 本质是 "继承时的访问权限过滤规则" 不同,直接影响代码的封装性和复用性。
一、核心概念与继承规则
继承的核心是 "基类成员的访问权限在派生类中被重新限定",访问权限的传递遵循 "派生类的访问权限不能高于继承方式,也不能高于基类成员本身的访问权限"(即 "就低不就高" 原则)。
首先明确基类成员的三种原始访问权限:
public:基类外部、基类内部、派生类均可访问(公开接口);protected:基类内部、派生类可访问,基类外部不可访问(继承复用的内部细节);private:仅基类内部可访问,派生类、基类外部均不可访问(完全隐藏的细节)。
以下通过表格对比公有继承和保护继承对基类成员权限的影响(核心差异):
| 基类成员原始权限 | 公有继承(public)后,在派生类中的权限 | 保护继承(protected)后,在派生类中的权限 |
|---|---|---|
| public | 保持 public(派生类外部可访问) | 变为 protected(派生类外部不可访问) |
| protected | 保持 protected(派生类外部不可访问) | 保持 protected(派生类外部不可访问) |
| private | 不可访问(派生类、外部均不可访问) | 不可访问(派生类、外部均不可访问) |
二、详细差异拆解(结合代码示例)
为了更直观理解,通过同一基类分别演示公有继承和保护继承的行为:
1. 公有继承(public inheritance):"接口复用" 的首选
公有继承的核心特征是 "基类的 public 成员成为派生类的 public 成员,基类的 protected 成员成为派生类的 protected 成员",派生类对象可直接访问基类的 public 成员,外部代码也可通过派生类对象访问基类的 public 成员 ------ 本质是 "is-a" 关系(派生类是基类的一种),保留基类的公开接口。
代码示例:
#include <iostream>
using namespace std;
// 基类
class Base {
public:
void publicFunc() { cout << "Base::publicFunc" << endl; }
protected:
void protectedFunc() { cout << "Base::protectedFunc" << endl; }
private:
void privateFunc() { cout << "Base::privateFunc" << endl; }
};
// 公有继承
class PublicDerived : public Base {
public:
void derivedFunc() {
publicFunc(); // 可访问:基类 public → 派生类 public
protectedFunc(); // 可访问:基类 protected → 派生类 protected
// privateFunc(); // 编译错误:基类 private 成员不可访问
}
};
int main() {
PublicDerived pd;
pd.publicFunc(); // 可访问:派生类 public 成员(继承自基类 public)
pd.derivedFunc(); // 可访问:派生类自身 public 成员
// pd.protectedFunc(); // 编译错误:派生类 protected 成员,外部不可访问
// pd.privateFunc(); // 编译错误:基类 private 成员,外部不可访问
return 0;
}- 核心结论:公有继承保留基类的接口(public 成员),派生类对象和外部代码可通过派生类访问基类的 public 成员,符合 "is-a" 关系(如
Student is a Person),是最常用的继承方式。
2. 保护继承(protected inheritance):"实现复用" 的隐藏接口
保护继承的核心特征是 "基类的 public 成员和 protected 成员,均成为派生类的 protected 成员",派生类对象和外部代码均无法访问基类的任何成员(包括原 public 成员)------ 本质是 "has-a" 的一种特殊形式,仅复用基类的实现细节,不暴露基类的接口,基类的接口仅对派生类的子类可见。
代码示例:
#include <iostream>
using namespace std;
// 基类(同上文)
class Base {
public:
void publicFunc() { cout << "Base::publicFunc" << endl; }
protected:
void protectedFunc() { cout << "Base::protectedFunc" << endl; }
private:
void privateFunc() { cout << "Base::privateFunc" << endl; }
};
// 保护继承
class ProtectedDerived : protected Base {
public:
void derivedFunc() {
publicFunc(); // 可访问:基类 public → 派生类 protected
protectedFunc(); // 可访问:基类 protected → 派生类 protected
// privateFunc(); // 编译错误:基类 private 成员不可访问
}
};
// 保护继承的子类(二级派生类)
class SubDerived : public ProtectedDerived {
public:
void subDerivedFunc() {
publicFunc(); // 可访问:Base::public → ProtectedDerived::protected → SubDerived::protected
protectedFunc(); // 可访问:传递下来的 protected 成员
}
};
int main() {
ProtectedDerived pd;
// pd.publicFunc(); // 编译错误:基类 public 成员 → 派生类 protected,外部不可访问
pd.derivedFunc(); // 可访问:派生类自身 public 成员(内部可调用基类成员)
SubDerived sd;
sd.subDerivedFunc(); // 可访问:二级派生类可访问基类传递的 protected 成员
// sd.publicFunc(); // 编译错误:二级派生类中仍是 protected,外部不可访问
return 0;
}- 核心结论:保护继承隐藏了基类的所有接口,外部无法通过派生类访问基类成员;但基类的成员(原 public 和 protected)在派生类中为 protected,可被派生类的子类(二级派生类)访问,适合 "仅需复用基类实现,且希望该实现能被自身子类复用,但不暴露给外部" 的场景。
三、关键差异总结(核心对比)
| 对比维度 | 公有继承(public) | 保护继承(protected) |
|---|---|---|
| 基类 public 成员的权限 | 派生类中为 public(外部可访问) | 派生类中为 protected(外部不可访问) |
| 基类 protected 成员权限 | 派生类中为 protected(外部不可访问) | 派生类中为 protected(外部不可访问) |
| 派生类对象的访问权限 | 可访问基类的 public 成员 | 不可访问基类的任何成员(仅能访问自身成员) |
| 外部代码的访问权限 | 可通过派生类对象访问基类的 public 成员 | 不可访问基类的任何成员 |
| 二级派生类的访问权限 | 可访问基类的 public 和 protected 成员 | 可访问基类的 public 和 protected 成员 |
| 核心关系 | is-a(派生类是基类的一种,暴露基类接口) | has-a(复用基类实现,隐藏基类接口) |
| 适用场景 | 接口复用(如 Student 继承 Person) | 实现复用(仅内部复用基类功能,不暴露接口) |
四、补充:private 继承的对比(避免混淆)
为了更清晰区分,补充私有继承(private inheritance)的规则:基类的 public 和 protected 成员均变为派生类的 private 成员,派生类的子类(二级派生类)无法访问基类成员 ------ 与保护继承的核心差异是 "二级派生类是否可访问基类成员",保护继承支持,私有继承不支持。
面试关键点与加分点
- 关键点:两种继承方式对基类成员权限的影响(核心表格);"就低不就高" 的权限传递原则;公有继承的 is-a 关系和保护继承的 has-a 关系;适用场景的差异。
- 加分点:能结合实际场景选择继承方式(如需要暴露基类接口用公有继承,仅需复用实现且隐藏接口用保护继承);能解释 "为什么保护继承的基类 public 成员会变为 protected"(核心是隐藏基类接口,仅允许派生类内部及子类复用);能区分三种继承方式(public/protected/private)的核心差异(重点是基类成员在派生类中的权限及外部访问性)。
记忆法
- 权限传递记忆:"继承方式是上限,基类权限是下限,就低不就高"------ 例如基类 public 成员,公有继承后仍是 public(上限高),保护继承后变为 protected(上限低);
- 核心差异记忆:"公有留接口,保护藏接口,都是为复用,场景各不同"------ 公有继承保留基类接口供外部访问,保护继承隐藏基类接口仅内部复用,核心都是实现代码复用,但接口暴露策略不同。
C++ 中保护继承下来的属性,在派生类中如何访问和使用?
C++ 中保护继承(protected inheritance)的核心规则是:基类的 public 和 protected 属性(成员变量 / 成员函数),在派生类中均被限定为 protected 权限;基类的 private 属性,无论何种继承方式,派生类均无法访问 。因此,保护继承下来的属性(本质是基类的 public 和 protected 属性),其访问和使用需遵循 protected 权限的约束,核心场景包括 "派生类内部访问""派生类的成员函数访问""二级派生类访问",外部代码和派生类对象均无法直接访问。
一、核心前提:明确保护继承的属性权限
首先重申保护继承的权限传递规则(避免混淆):
| 基类属性原始权限 | 保护继承后在派生类中的权限 | 能否被派生类访问 | 能否被外部 / 派生类对象访问 |
|---|---|---|---|
| public | protected | 能 | 不能 |
| protected | protected | 能 | 不能 |
| private | 不可访问 | 不能 | 不能 |
关键结论:保护继承下来的属性,在派生类中是 protected 级别的 "内部属性"------ 仅能在派生类自身、派生类的成员函数、派生类的友元、派生类的子类(二级派生类)中访问,外部代码和派生类对象无法直接访问(编译报错)。
二、派生类中访问保护继承属性的具体场景与代码示例
以下通过 "基类→保护继承的派生类→二级派生类" 的层级结构,详细演示各场景下的访问方式:
1. 场景一:派生类的成员函数中直接访问
这是最常用的场景:保护继承下来的属性,可在派生类的成员函数(public/protected/private 成员函数均可)中直接访问,无需额外语法,如同访问派生类自身的 protected 属性。
代码示例:
#include <iostream>
#include <string>
using namespace std;
// 基类
class Base {
public:
// 基类 public 属性:保护继承后变为派生类的 protected 属性
string publicAttr = "Base_public";
protected:
// 基类 protected 属性:保护继承后仍为派生类的 protected 属性
int protectedAttr = 100;
private:
// 基类 private 属性:派生类无法访问
double privateAttr = 3.14;
};
// 保护继承 Base
class ProtectedDerived : protected Base {
public:
// 派生类的 public 成员函数:可直接访问保护继承的属性
void accessBaseAttr() {
// 访问基类 public 继承来的属性(现为派生类 protected)
cout << "访问基类 public 继承的属性:" << publicAttr << endl;
// 访问基类 protected 继承来的属性(现为派生类 protected)
cout << "访问基类 protected 继承的属性:" << protectedAttr << endl;
// 修改继承来的属性(允许,因为是派生类内部)
publicAttr = "Modified_by_ProtectedDerived";
protectedAttr = 200;
cout << "修改后:" << publicAttr << ", " << protectedAttr << endl;
// cout << privateAttr; // 编译错误:基类 private 属性,派生类无法访问
}
private:
// 派生类的 private 成员函数:同样可访问继承来的属性
void privateAccessFunc() {
cout << "私有成员函数访问:" << publicAttr << ", " << protectedAttr << endl;
}
public:
void callPrivateAccessFunc() {
privateAccessFunc(); // 派生类内部可调用自身私有函数,间接访问继承属性
}
};
int main() {
ProtectedDerived pd;
// 调用派生类成员函数,间接访问和修改继承属性
pd.accessBaseAttr();
pd.callPrivateAccessFunc();
// 以下代码编译错误:外部无法直接访问派生类的 protected 属性(继承来的属性)
// cout << pd.publicAttr;
// cout << pd.protectedAttr;
return 0;
}-
输出结果:
访问基类 public 继承的属性:Base_public 访问基类 protected 继承的属性:100 修改后:Modified_by_ProtectedDerived, 200 私有成员函数访问:Modified_by_ProtectedDerived, 200 -
核心结论:派生类的任意成员函数(无论访问权限),均可直接访问保护继承下来的属性(基类原
public和protected),包括读取和修改;外部代码无法直接访问,需通过派生类提供的公有接口间接操作。
2. 场景二:派生类的友元函数中访问
友元函数(friend)的核心特权是 "突破访问权限限制",可访问类的 private 和 protected 成员。因此,保护继承下来的属性(派生类的 protected 属性),可在派生类的友元函数中直接访问。
代码示例(基于上文 Base 和 ProtectedDerived 类扩展):
// 友元函数声明(需在派生类前声明,或使用类内声明)
void friendFunc(ProtectedDerived& pd);
class ProtectedDerived : protected Base {
// 声明友元函数:允许其访问自身的 protected/private 成员(包括继承来的属性)
friend void friendFunc(ProtectedDerived& pd);
public:
string publicAttr = "Derived_public"; // 派生类自身的 public 属性
protected:
int derivedProtectedAttr = 50; // 派生类自身的 protected 属性
};
// 友元函数实现:访问保护继承的属性
void friendFunc(ProtectedDerived& pd) {
// 访问保护继承来的属性(基类原 public)
cout << "友元访问继承属性(Base::publicAttr):" << pd.publicAttr << endl;
// 访问保护继承来的属性(基类原 protected)
cout << "友元访问继承属性(Base::protectedAttr):" << pd.protectedAttr << endl;
// 访问派生类自身的 protected 属性
cout << "友元访问派生类自身 protected 属性:" << pd.derivedProtectedAttr << endl;
}
int main() {
ProtectedDerived pd;
friendFunc(pd); // 调用友元函数,间接访问继承属性
return 0;
}-
输出结果:
友元访问继承属性(Base::publicAttr):Base_public 友元访问继承属性(Base::protectedAttr):100 友元访问派生类自身 protected 属性:50 -
核心结论:派生类的友元函数可直接访问保护继承下来的属性,无需通过派生类的成员函数中转;但友元函数破坏了封装性,需谨慎使用(仅在必要时使用)。
3. 场景三:二级派生类中访问(派生类的子类)
保护继承的核心特点之一是 "继承下来的属性可被派生类的子类(二级派生类)访问"------ 因为保护继承下来的属性在派生类中是 protected 权限,二级派生类作为 "子类",可访问父类(一级派生类)的 protected 成员(包括继承来的属性)。
代码示例(基于上文 Base 和 ProtectedDerived 类扩展):
// 二级派生类:公有继承 ProtectedDerived(一级派生类)
class SubDerived : public ProtectedDerived {
public:
void accessInheritedAttr() {
// 访问一级派生类从 Base 保护继承来的属性(基类原 public)
cout << "二级派生类访问 Base::publicAttr:" << publicAttr << endl;
// 访问一级派生类从 Base 保护继承来的属性(基类原 protected)
cout << "二级派生类访问 Base::protectedAttr:" << protectedAttr << endl;
// 访问一级派生类自身的 protected 属性
cout << "二级派生类访问 ProtectedDerived::derivedProtectedAttr:" << derivedProtectedAttr << endl;
// 修改这些属性(允许)
publicAttr = "Modified_by_SubDerived";
protectedAttr = 300;
}
};
int main() {
SubDerived sd;
sd.accessInheritedAttr(); // 二级派生类成员函数访问继承属性
// 以下代码编译错误:二级派生类中,这些属性仍是 protected,外部无法访问
// cout << sd.publicAttr;
// cout << sd.protectedAttr;
return 0;
}-
输出结果:
二级派生类访问 Base::publicAttr:Base_public 二级派生类访问 Base::protectedAttr:100 二级派生类访问 ProtectedDerived::derivedProtectedAttr:50 -
核心结论:二级派生类可通过自身的成员函数,直接访问一级派生类从基类保护继承来的属性;若二级派生类是 "保护继承" 或 "私有继承" 一级派生类,访问规则同样遵循 "就低不就高" 原则,但只要一级派生类中的属性是
protected,二级派生类即可访问。
三、关键注意事项(避免踩坑)
- 禁止派生类对象直接访问 :保护继承下来的属性是派生类的
protected属性,派生类对象无法直接访问(如pd.publicAttr编译报错),必须通过派生类的公有成员函数或友元函数间接访问 ------ 这是protected权限的核心约束。 - 基类 private 属性不可访问 :无论何种继承方式,基类的
private属性都无法被派生类访问(包括保护继承的派生类),若需让派生类访问,需将基类属性声明为protected,或通过基类的公有 / 保护成员函数间接访问。 - 继承方式不影响访问权限上限 :即使二级派生类采用公有继承一级派生类,保护继承下来的属性在二级派生类中仍是
protected权限,外部代码仍无法直接访问 ------ 仅能在二级派生类内部或其友元、三级派生类中访问。 - 避免滥用保护继承:保护继承的核心场景是 "复用基类实现但不暴露基类接口",若需暴露基类接口,应使用公有继承;若无需让二级派生类访问基类属性,可使用私有继承。
面试关键点与加分点
- 关键点:保护继承下来的属性在派生类中的权限(
protected);三大访问场景(派生类成员函数、友元函数、二级派生类);外部代码和派生类对象无法直接访问的约束;基类private属性不可访问的规则。 - 加分点:能区分 "保护继承" 和 "私有继承" 在二级派生类访问场景的差异(保护继承支持,私有继承不支持);能结合实际场景设计访问逻辑(如通过派生类公有接口封装继承属性的访问,兼顾复用和封装);能解释 "为什么保护继承的属性可被二级派生类访问"(
protected权限的传递性,子类可访问父类的protected成员)。
记忆法
- 访问场景记忆:"内部函数直接用,友元函数破封装,子类继承接着用,外部对象不能碰"------ 对应派生类成员函数、友元函数、二级派生类、外部对象四种场景的访问规则;
- 权限核心记忆:"保护继承变保护,仅限内部和子类,外部直接访问错,接口封装才合规"------ 强调保护继承后属性的权限级别,及通过公有接口间接访问的合规方式。
计算 C++ 类的对象大小时,需要考虑哪些因素?
C++ 类的对象大小并非简单的 "所有成员变量大小之和",而是受成员变量、虚函数、继承关系、内存对齐、空类优化等多重因素影响 ------ 核心原则是 "对象大小 = 所有非静态成员变量占用空间 + 虚表指针(若有) + 继承带来的额外空间(如虚基类指针) - 内存对齐优化的重叠部分"(实际为各成员按对齐规则分配后的总空间)。
一、核心因素拆解(结合代码示例)
1. 非静态成员变量(核心组成部分)
类的对象大小首先由 "非静态成员变量" 决定 ------静态成员变量(static)不占用对象空间(存储在全局数据区,所有对象共享),仅非静态成员变量(包括普通成员变量、引用、指针)会占用对象空间。
-
关键规则:
- 普通成员变量:占用空间为其数据类型大小(如
int4 字节、double8 字节、char1 字节)。 - 引用(
&):本质是指针的封装,占用空间与指针相同(32 位系统 4 字节,64 位系统 8 字节),而非所引用对象的大小。 - 指针(
*):无论指向何种类型,占用空间均为指针大小(32 位 4 字节,64 位 8 字节)。
- 普通成员变量:占用空间为其数据类型大小(如
-
代码示例:
#include <iostream> using namespace std; class Test { private: int a; // 4字节(非静态) double b; // 8字节(非静态) char c; // 1字节(非静态) static int d; // 静态成员变量,不占用对象空间 int& ref; // 引用,8字节(64位系统) int* ptr; // 指针,8字节(64位系统) public: Test(int& r) : ref(r) {} }; int Test::d = 0; // 静态成员变量初始化(全局数据区) int main() { int x = 10; Test t(x); cout << "Test 对象大小:" << sizeof(t) << endl; // 64位系统下计算:4(int) + 8(double) + 1(char) + 8(ref) + 8(ptr) = 29字节? // 实际输出:32字节(受内存对齐影响) return 0; } -
结论:非静态成员变量是对象大小的基础,但最终大小需结合内存对齐调整。
2. 内存对齐(影响最终大小的关键因素)
内存对齐是编译器为了 "提高 CPU 访问内存的效率" 而采用的优化策略 ------CPU 访问内存时,倾向于按 "对齐单位"(通常是 4 字节或 8 字节,取决于系统和编译器)读取数据,而非单字节读取。因此,编译器会自动调整成员变量的存储位置,使每个成员的起始地址是其自身大小的整数倍(或对齐单位的整数倍,取两者较大者),最终对象大小是最大对齐单位的整数倍。
如何将函数参数放入寄存器中?
在 C++ 等编译型语言中,函数参数的传递方式由编译器、调用约定(Calling Convention)和目标架构(如 x86、ARM)共同决定,"将函数参数放入寄存器"是编译器优化参数传递效率的核心方式------相比栈传递(参数入栈/出栈需内存读写),寄存器访问速度更快(CPU 内部操作),能显著提升函数调用性能。实现这一目标的核心是"遵循调用约定+编译器优化",开发者可通过语法指令引导编译器,最终由编译器结合架构限制完成寄存器分配。
一、核心前提:调用约定与寄存器传递的底层逻辑
函数调用约定是"编译器与 CPU 之间的约定",明确了参数传递顺序、参数存储位置(寄存器/栈)、栈清理责任(调用者/被调用者)等规则。支持寄存器传递参数的常见调用约定包括:
- x86-64 架构:System V AMD64 ABI(Linux/macOS/iOS 常用)、Microsoft x64 ABI(Windows 常用);
- ARM 架构:ARM AAPCS(ARM 架构过程调用标准,iOS 设备核心架构)。
这些约定的核心设计:优先将前 N 个参数放入指定寄存器,超出数量的参数存入栈------寄存器数量有限(如 x86-64 最多 6 个通用寄存器用于参数传递,ARM 最多 4 个),无法容纳所有参数时,剩余参数退化为栈传递。
底层逻辑:CPU 寄存器是高速临时存储单元(如 x86-64 的 RDI、RSI、RDX 等,ARM 的 R0-R3 等),函数调用时,编译器先将参数值写入约定的寄存器,被调用函数直接从寄存器读取参数,无需访问内存栈,减少 I/O 开销。
二、开发者层面:引导编译器将参数放入寄存器的方法
开发者无法直接"手动将参数写入寄存器"(寄存器操作是底层指令,由编译器生成汇编代码),但可通过以下方式引导编译器优先使用寄存器传递参数,核心是"遵循调用约定+消除编译器顾虑+显式优化指令"。
1. 遵循目标架构的默认调用约定(最基础方式)
主流架构的默认调用约定已优先支持寄存器传递参数,开发者无需额外操作,编译器会自动优化:
- x86-64(System V AMD64 ABI) :前 6 个整数/指针类型参数依次放入
RDI、RSI、RDX、RCX、R8、R9寄存器;浮点数/双精度参数放入XMM0-XMM7寄存器;第 7 个及以后参数入栈。 - ARM AAPCS(iOS ARM64) :前 4 个整数/指针/浮点数参数依次放入
R0-R3寄存器;超出 4 个的参数入栈;返回值存入R0寄存器。
代码示例(iOS ARM64 环境,默认调用约定):
#include <iostream>
using namespace std;
// 4 个参数,ARM64 下全部通过 R0-R3 寄存器传递
int add(int a, int b, int c, int d) {
return a + b + c + d; // 直接从 R0-R3 读取参数
}
// 5 个参数,前 4 个通过 R0-R3 传递,第 5 个入栈
int add_more(int a, int b, int c, int d, int e) {
return a + b + c + d + e; // e 从栈中读取
}
int main() {
cout << add(1, 2, 3, 4) << endl; // 输出 10,全寄存器传递
cout << add_more(1, 2, 3, 4, 5) << endl; // 输出 15,前 4 寄存器+第 5 栈
return 0;
}- 编译验证:使用
clang -S -O2 test.cpp(iOS clang 编译器)生成汇编代码,可看到add函数从R0-R3读取参数,add_more从R0-R3读取前 4 个参数,第 5 个参数从栈指针SP偏移处读取。
2. 使用编译器特定的属性/关键字(显式引导)
部分编译器支持通过扩展属性(如 GCC/clang 的 __attribute__((regparm(n)))、__attribute__((fastcall)))强制指定参数通过寄存器传递,进一步优化性能(需注意编译器兼容性)。
-
__attribute__((regparm(n)))(GCC/clang) :指定最多n个整数/指针参数通过寄存器传递(n 取值 0-3,x86 架构常用,x86-64/ARM 架构效果有限,因默认已用寄存器传递)。代码示例(x86 32 位环境):// 指定前 2 个参数通过寄存器传递(x86 32 位的 EAX、EDX 寄存器) int __attribute__((regparm(2))) multiply(int x, int y) { return x * y; } int main() { multiply(3, 4); // x 入 EAX,y 入 EDX,无栈操作 return 0; } -
__fastcall调用约定 :强制将前 2 个整数/指针参数放入寄存器(x86 架构的 ECX、EDX),剩余参数入栈(Visual Studio 编译器支持,GCC/clang 可通过__attribute__((fastcall))兼容)。注意:x86-64/ARM 架构已淘汰__fastcall,因默认调用约定已覆盖其优化效果,过度使用可能导致兼容性问题。
3. 开启编译器优化(关键保障)
编译器默认可能为了调试方便(如 -O0 优化级别),将参数放入栈而非寄存器,需开启优化级别(如 -O1、-O2、-O3),编译器才会主动遵循调用约定,优先使用寄存器传递参数。
-
优化级别影响:
-O0(无优化):所有参数入栈,便于调试(参数在栈中可直接查看);-O1/-O2/-O3(优化级别):编译器自动应用寄存器传递、代码内联等优化,参数优先入寄存器。
-
编译命令示例(iOS clang):
# 开启 O2 优化,编译器优先用寄存器传递参数 clang -O2 -target arm64-apple-ios14.0 test.cpp -o test
4. 避免影响寄存器分配的场景(消除编译器顾虑)
编译器若判断参数无法安全放入寄存器,会退化为栈传递,需避免以下场景:
-
参数是大型结构体/类对象(按值传递) :大型对象占用空间超过寄存器容量(如 16 字节以上),编译器会自动将其入栈(或通过指针间接传递),需改为按引用(
&)或指针传递(仅传递地址,占 8 字节,可放入寄存器)。反例(不推荐):// 大型结构体按值传递,无法放入寄存器,编译器退化为栈传递 struct BigStruct { int a[100]; }; int process(BigStruct s) { return s.a[0]; }正例(推荐):
// 按 const 引用传递,仅传递地址(8 字节),可放入寄存器 int process(const BigStruct& s) { return s.a[0]; } -
参数被取地址(
¶m):若函数内部对参数取地址,编译器需确保参数有固定内存地址(寄存器无固定地址),会强制将参数入栈,无法放入寄存器。反例:// 对参数取地址,编译器强制入栈 int getAddr(int x) { return (int)&x; } -
可变参数函数(如
printf) :可变参数(...)的数量和类型在编译时未知,编译器无法提前分配寄存器,所有参数均入栈。
三、底层实现:编译器如何分配寄存器
编译器的寄存器分配是复杂的"资源调度"过程,核心步骤:
-
参数分类:区分整数/指针、浮点数/双精度等类型,按调用约定分配对应类型的寄存器(如 x86-64 整数用通用寄存器,浮点数用 XMM 寄存器)。
-
寄存器可用性检查:若约定的寄存器已被其他变量占用(如函数内部已有大量局部变量),编译器会将参数入栈,或通过"寄存器溢出"(spill)将占用寄存器的变量暂存到栈,释放寄存器用于参数传递。
-
生成汇编指令 :将参数值写入分配的寄存器(如 ARM64 的
MOV R0, #1把 1 放入 R0 寄存器),被调用函数通过寄存器名读取参数(如ADD R0, R0, R1计算 R0 和 R1 的和)。; main 函数中调用 add(1,2,3,4)
MOV R0, #1 ; 第一个参数 a=1 放入 R0
MOV R1, #2 ; 第二个参数 b=2 放入 R1
MOV R2, #3 ; 第三个参数 c=3 放入 R2
MOV R3, #4 ; 第四个参数 d=4 放入 R3
BL _add ; 调用 add 函数(BL 是分支并链接指令); add 函数实现(从寄存器读取参数)
_add:
ADD R0, R0, R1 ; R0 = a + b(1+2=3)
ADD R0, R0, R2 ; R0 = 3 + c(3+3=6)
ADD R0, R0, R3 ; R0 = 6 + d(6+4=10)
RET ; 返回 R0 中的结果(10)
面试关键点与加分点
- 关键点:调用约定是核心(不同架构约定不同寄存器数量);编译器优化级别(
-O2及以上)是必要条件;避免取参数地址、大型对象按值传递等破坏寄存器分配的场景;引用/指针传递可减少参数体积,便于寄存器存储。 - 加分点:能说出具体架构的调用约定细节(如 ARM64 前 4 个参数用 R0-R3);能解释"为什么大型对象按值传递无法入寄存器"(超出寄存器容量);能通过汇编代码验证参数传递方式;了解编译器寄存器分配的"溢出处理"(寄存器不足时退化为栈传递)。
记忆法
- 核心逻辑记忆:"约定定规则,优化促执行,避坑保分配"------调用约定定义寄存器传递的规则,优化级别触发编译器执行,避免取地址、大对象按值传递等坑点保障寄存器分配成功;
- 架构约定记忆:"ARM 4 个 R0-R3,x86-64 六个通用+八个浮点"------提炼主流架构的寄存器数量,快速关联参数传递上限。
C++ 中智能指针 weak_ptr 内部是如何使用 shared_ptr 的?
C++11 引入的 weak_ptr 是为解决 shared_ptr 循环引用问题设计的"弱引用智能指针",其核心依赖 shared_ptr 的内部机制------weak_ptr 本身不直接管理资源,而是通过指向 shared_ptr 维护的"控制块(Control Block)",间接关联资源,实现对 shared_ptr 管理资源的弱引用 。内部使用 shared_ptr 的核心逻辑是"复用控制块的计数机制",而非直接持有 shared_ptr 对象。
一、核心前提:shared_ptr 的控制块结构
要理解 weak_ptr 与 shared_ptr 的关系,需先明确 shared_ptr 的底层实现:shared_ptr 由两部分组成:
- 资源指针(raw pointer) :指向实际管理的堆内存资源(如
new分配的对象); - 控制块指针(control block pointer) :指向一个堆上的控制块,控制块包含三个核心成员:
- 引用计数(
use_count):记录当前持有资源的shared_ptr数量,use_count为 0 时销毁资源; - 弱引用计数(
weak_count):记录当前指向该控制块的weak_ptr数量,weak_count为 0 时销毁控制块; - 资源销毁器(deleter):
shared_ptr构造时指定的自定义销毁逻辑(默认delete)。
- 引用计数(
关键结论:shared_ptr 的核心是控制块,所有 shared_ptr 和 weak_ptr 对同一资源的操作,本质都是通过修改控制块的 use_count 和 weak_count 实现的。
二、weak_ptr 内部使用 shared_ptr 的核心机制
weak_ptr 本身不持有资源(不影响 use_count),其内部仅存储"控制块指针"------该指针来自 shared_ptr 的控制块,即 weak_ptr 是通过 shared_ptr 间接关联控制块,进而"观察"资源状态。具体使用方式分为以下场景:
1. 构造/赋值:从 shared_ptr 获取控制块指针
weak_ptr 无法直接构造(无 weak_ptr<T> wp(new T) 语法),必须通过 shared_ptr 或已存在的 weak_ptr 构造/赋值,核心是"复用 shared_ptr 的控制块":
- 构造:
weak_ptr<T> wp(sp)(sp是shared_ptr<T>),wp的控制块指针指向sp的控制块,同时控制块的weak_count加 1; - 赋值:
wp = sp,先断开当前wp与原控制块的关联(weak_count减 1,若weak_count变为 0 且use_count为 0,销毁控制块),再指向sp的控制块,weak_count加 1。
代码示例:
#include <memory>
using namespace std;
int main() {
shared_ptr<int> sp = make_shared<int>(10);
// 1. 从 shared_ptr 构造 weak_ptr:复用 sp 的控制块
weak_ptr<int> wp1(sp);
// 此时控制块:use_count=1(sp),weak_count=1(wp1)
// 2. 从 weak_ptr 构造 weak_ptr:复用同一控制块
weak_ptr<int> wp2 = wp1;
// 此时控制块:use_count=1,weak_count=2(wp1+wp2)
// 3. 赋值操作:wp2 重新指向 sp(无变化,仅 weak_count 不变)
wp2 = sp;
// 控制块:use_count=1,weak_count=2(wp1+wp2)
return 0;
}底层逻辑:shared_ptr 提供了访问控制块的接口(内部接口,不对外暴露),weak_ptr 构造/赋值时,通过该接口获取 shared_ptr 的控制块指针,并修改 weak_count------这是 weak_ptr 依赖 shared_ptr 的核心:weak_ptr 无法独立创建控制块,必须依附于 shared_ptr 已创建的控制块。
2. 锁操作(lock()):通过控制块转换为 shared_ptr
weak_ptr 无法直接访问资源(无 operator* 和 operator-> 重载),必须通过 lock() 方法转换为 shared_ptr 才能访问资源------该过程本质是"通过控制块检查资源是否存活,若存活则创建新的 shared_ptr 持有资源"。
lock() 方法的内部流程(依赖 shared_ptr 的控制块):
- 检查控制块的
use_count:若use_count > 0(资源存活),则创建一个新的shared_ptr,指向该控制块的资源,同时use_count加 1; - 若
use_count == 0(资源已销毁),则返回一个空的shared_ptr(operator bool()为 false); - 整个过程是线程安全的(控制块的
use_count和weak_count操作是原子的)。
代码示例:
#include <memory>
#include <iostream>
using namespace std;
int main() {
shared_ptr<int> sp = make_shared<int>(10);
weak_ptr<int> wp(sp);
// 1. 资源存活时,lock() 返回有效 shared_ptr
if (shared_ptr<int> locked_sp = wp.lock()) {
cout << "资源存活:" << *locked_sp << endl; // 输出 10
cout << "use_count:" << locked_sp.use_count() << endl; // 输出 2(sp + locked_sp)
}
// 2. 销毁所有 shared_ptr,资源释放
sp.reset();
cout << "sp 已重置,use_count:" << wp.use_count() << endl; // 输出 0
// 3. 资源已销毁,lock() 返回空 shared_ptr
if (shared_ptr<int> locked_sp = wp.lock()) {
cout << "资源存活" << endl;
} else {
cout << "资源已销毁" << endl; // 输出该语句
}
return 0;
}底层逻辑:lock() 方法本质是"基于控制块的 use_count 状态,创建新的 shared_ptr"------weak_ptr 本身不参与资源管理,仅通过控制块"观察"资源,而 shared_ptr 是资源管理的核心,lock() 是两者协同的关键接口。
3. 计数管理:与 shared_ptr 协同维护控制块生命周期
控制块的销毁条件是"use_count == 0 且 weak_count == 0"------shared_ptr 负责维护 use_count(资源生命周期),weak_ptr 负责维护 weak_count(控制块生命周期),两者协同确保控制块不泄露、资源及时释放:
- 当所有
shared_ptr销毁(use_count == 0):资源被销毁(调用 deleter),但控制块仍存在(若weak_count > 0),供weak_ptr检查资源状态; - 当所有
weak_ptr也销毁(weak_count == 0):控制块被销毁,彻底释放堆内存。
示例流程(展示 shared_ptr 与 weak_ptr 对计数的影响):
| 操作步骤 | use_count(shared_ptr 计数) | weak_count(weak_ptr 计数) | 资源状态 | 控制块状态 |
|---|---|---|---|---|
| shared_ptr<int> sp = make_shared<int>(10) | 1 | 0 | 存活 | 存在 |
| weak_ptr<int> wp = sp | 1 | 1 | 存活 | 存在 |
| sp.reset() | 0 | 1 | 销毁 | 存在(weak_count > 0) |
| wp.reset() | 0 | 0 | 销毁 | 销毁 |
关键:weak_ptr 对 weak_count 的修改,必须基于 shared_ptr 创建的控制块------若没有 shared_ptr 先创建控制块,weak_ptr 无法独立存在,这是 weak_ptr 依赖 shared_ptr 的根本原因。
4. 辅助接口:use_count() 和 expired() 依赖控制块
weak_ptr 提供的 use_count()(获取当前 use_count)和 expired()(判断资源是否已销毁,等价于 use_count() == 0),其内部实现均是通过控制块指针访问控制块的 use_count 成员------而控制块是 shared_ptr 创建和维护的。
代码示例:
shared_ptr<int> sp = make_shared<int>(10);
weak_ptr<int> wp(sp);
cout << wp.use_count() << endl; // 输出 1(访问控制块的 use_count)
cout << wp.expired() << endl; // 输出 false(use_count > 0)
sp.reset();
cout << wp.use_count() << endl; // 输出 0
cout << wp.expired() << endl; // 输出 true底层逻辑:weak_ptr 本身不存储 use_count,所有计数查询都委托给 shared_ptr 的控制块,进一步体现了其"依赖 shared_ptr 管理状态"的设计。
三、weak_ptr 不直接持有 shared_ptr 的原因
weak_ptr 内部仅存储"控制块指针",而非 shared_ptr 对象,核心原因:
- 避免循环引用:若
weak_ptr持有shared_ptr,会导致use_count无法归零(如A的shared_ptr指向B,B的weak_ptr指向A,若weak_ptr持有shared_ptr,则A的use_count始终为 1),违背weak_ptr解决循环引用的设计目标; - 轻量化设计:
weak_ptr的核心是"观察"而非"持有",仅存储控制块指针(8 字节,64 位系统),比存储shared_ptr(16 字节,资源指针+控制块指针)更节省内存。
面试关键点与加分点
- 关键点:
weak_ptr依赖shared_ptr的控制块(复用计数机制);通过shared_ptr构造/赋值获取控制块指针;lock()方法转换为shared_ptr访问资源;协同维护控制块生命周期(use_count管资源,weak_count管控制块)。 - 加分点:能详细描述控制块的结构(
use_count/weak_count/deleter);能解释lock()的线程安全性(原子操作计数);能说明weak_ptr解决循环引用的原理(不增加use_count);能区分weak_ptr与shared_ptr的内存占用差异(8 字节 vs 16 字节)。
记忆法
- 核心关系记忆:"shared 管资源,weak 观状态,控制块为桥,lock 为通道"------
shared_ptr管理资源生命周期,weak_ptr观察资源状态,控制块是两者的桥梁,lock()是weak_ptr访问资源的唯一通道; - 计数逻辑记忆:"use_count 判存活,weak_count 保控制块,两者为零才销毁"------
use_count决定资源是否存活,weak_count决定控制块是否销毁,只有两者都为 0 时,控制块才被释放。
进程、线程、协程的概念及核心区别是什么?
进程、线程、协程是操作系统和程序设计中用于"并发执行任务"的核心概念,三者的本质是"任务执行的载体",但在资源占用、调度方式、并发粒度等方面存在根本差异------核心区别可概括为"进程是资源分配的最小单位,线程是 CPU 调度的最小单位,协程是用户态调度的最小单位"。
一、核心概念拆解
1. 进程(Process)
进程是操作系统为程序分配资源(内存、CPU、文件句柄等)的最小单位,是程序的"执行实例"------当一个程序被启动时,操作系统会为其创建一个进程,分配独立的地址空间、内存资源、文件描述符等,进程内的所有任务共享这些资源。
-
核心特征:
- 资源独立:进程拥有独立的虚拟地址空间(代码段、数据段、堆栈段),不同进程的资源相互隔离(如进程 A 无法直接访问进程 B 的内存,需通过进程间通信 IPC 机制);
- 开销较大:创建/销毁进程需操作系统分配/回收资源,切换进程需保存/恢复进程的上下文(如寄存器状态、内存映射表),耗时较长(毫秒级);
- 独立性强:进程是操作系统调度的基本单位(早期操作系统无线程,直接调度进程),一个进程崩溃通常不会影响其他进程(如浏览器进程崩溃不影响桌面进程)。
-
示例:打开一个 iOS 应用(如微信),操作系统会为微信创建一个或多个进程,每个进程拥有独立的内存空间,存储微信的代码、数据和运行状态。
2. 线程(Thread)
线程是CPU 调度和执行的最小单位,隶属于进程,是进程内的"执行流"------一个进程可以包含多个线程,所有线程共享进程的资源(地址空间、内存、文件句柄等),但拥有独立的堆栈和寄存器状态。
-
核心特征:
- 资源共享:线程共享所属进程的所有资源,无需额外分配(如线程 A 和线程 B 可直接访问进程的全局变量、堆内存);
- 开销较小:创建/销毁线程仅需分配独立的堆栈(通常几 MB)和寄存器状态,切换线程仅需保存/恢复线程的上下文(无需切换地址空间),耗时较短(微秒级);
- 调度由 OS 负责:线程的调度由操作系统内核完成(抢占式调度),内核根据线程优先级分配 CPU 时间片,线程无需主动放弃 CPU。
-
示例:微信进程内,"接收消息""刷新朋友圈""播放语音"等任务分别由不同线程执行,这些线程共享微信的内存资源(如用户数据、缓存文件),但各自拥有独立的执行流程。
3. 协程(Coroutine)
协程是用户态下的轻量级"执行单元",由程序(用户)自行调度,而非操作系统内核------协程隶属于线程,多个协程共享一个线程的资源,协程切换完全在用户态完成,无需内核参与。
-
核心特征:
- 极致轻量化:协程的创建/销毁和切换开销极小(纳秒级),一个线程可承载成千上万个协程(而一个进程通常最多承载数百个线程);
- 用户态调度:协程的调度由用户程序控制(非抢占式调度),需通过"主动让出 CPU"(如
yield操作)切换到其他协程,若无主动让出,一个协程会一直占用线程; - 资源共享:同一线程内的协程共享线程的堆栈和资源,协程间通信无需复杂的同步机制(如无锁队列),直接通过内存共享即可。
-
示例:iOS 中使用
Swift Concurrency的async/await实现的异步任务,本质是协程------多个网络请求协程共享一个线程,当一个协程等待网络响应时,主动让出 CPU 给其他协程执行,避免线程阻塞。
二、核心区别对比(表格汇总)
| 对比维度 | 进程(Process) | 线程(Thread) | 协程(Coroutine) |
|---|---|---|---|
| 核心定位 | 资源分配的最小单位 | CPU 调度的最小单位 | 用户态调度的最小单位 |
| 资源占用 | 大(独立地址空间、内存、文件句柄) | 中(共享进程资源,独立堆栈/寄存器) | 极小(共享线程资源,无独立资源) |
| 调度主体 | 操作系统内核(抢占式调度) | 操作系统内核(抢占式调度) | 用户程序(非抢占式调度,主动让出) |
| 切换开销 | 大(毫秒级,需切换地址空间、保存上下文) | 中(微秒级,仅保存线程上下文) | 极小(纳秒级,用户态直接切换,无内核参与) |
| 并发粒度 | 粗(进程间隔离,适合独立任务) | 中(线程间共享资源,适合进程内并行任务) | 细(协程间极致轻量,适合高并发 IO 任务) |
| 通信方式 | 进程间通信(IPC):管道、消息队列、共享内存等 | 线程间通信:全局变量、互斥锁、条件变量等 | 协程间通信:直接内存共享(同一线程内)、通道(Channel)等 |
| 崩溃影响 | 独立崩溃,不影响其他进程 | 线程崩溃导致整个进程崩溃 | 协程崩溃可能导致所属线程崩溃(进而影响同线程其他协程) |
| 适用场景 | 独立程序实例(如多个 App 进程)、资源隔离需求高的任务 | 进程内并行执行的任务(如 IO 操作、计算任务) | 高并发 IO 密集型任务(如网络请求、文件读写)、轻量级异步任务 |
三、关键区别深度解析
1. 资源分配:进程独立,线程/协程共享
- 进程:操作系统为每个进程分配独立的虚拟地址空间,进程间无法直接访问内存(如 iOS 中 App 进程的沙盒目录相互隔离),需通过 IPC 机制(如 Mach 端口、通知中心)通信,资源隔离性强,但开销大。
- 线程:同一进程的线程共享进程的地址空间、堆内存、文件句柄等资源(如微信的所有线程可访问用户的聊天记录缓存),线程间通信简单,但需通过互斥锁(
mutex)避免资源竞争(如同时修改同一变量)。 - 协程:同一线程的协程共享线程的堆栈和资源(如一个线程内的多个网络请求协程共享线程的 IO 资源),协程间无资源竞争(因非抢占式调度,同一时间仅一个协程执行),无需复杂同步机制。
2. 调度机制:内核调度 vs 用户调度
- 进程/线程调度:由操作系统内核完成(抢占式调度)------内核维护进程/线程的就绪队列,根据优先级分配 CPU 时间片(如 iOS 的
GCD线程调度),当时间片用完或有更高优先级任务就绪时,内核会强制切换进程/线程,保存当前上下文(寄存器、程序计数器等),恢复目标上下文,该过程需从用户态切换到内核态,开销较大。 - 协程调度:由用户程序控制(非抢占式调度)------协程的切换无需内核参与,完全在用户态完成:当一个协程执行到 IO 操作(如网络请求)或主动调用
yield时,会将自身状态(程序计数器、局部变量)保存到用户态的栈中,然后切换到其他就绪协程,恢复其状态继续执行,无需内核态切换,开销极低。
3. 并发能力:协程 > 线程 > 进程
- 进程:创建/切换开销最大,一个操作系统通常只能同时运行数百个进程(如 iOS 后台进程数量有限制),并发能力最弱。
- 线程:创建/切换开销中等,一个进程通常可创建数百个线程(如 iOS 中
GCD的全局并发队列默认线程数与 CPU 核心数相关),并发能力中等------线程过多会导致频繁的上下文切换,反而降低性能(线程颠簸)。 - 协程:创建/切换开销极小,一个线程可承载成千上万个协程(如
Swift Concurrency可轻松支持数千个异步协程),并发能力极强------尤其适合 IO 密集型任务(如同时发起数千个网络请求),因 IO 操作时协程主动让出 CPU,不会浪费线程资源。
4. 崩溃影响:进程独立,线程/协程依赖
- 进程:进程是资源隔离的最小单位,一个进程崩溃(如内存访问错误)不会影响其他进程(如 Safari 标签页进程崩溃,其他标签页可正常使用),稳定性强。
- 线程:线程隶属于进程,一个线程崩溃(如空指针访问)会导致整个进程崩溃(如微信的"接收消息"线程崩溃,整个微信 App 闪退),稳定性中等。
- 协程:协程隶属于线程,一个协程崩溃(如未捕获的异常)会导致所属线程崩溃,进而影响同线程内的所有协程(如一个网络请求协程崩溃,导致整个线程内的其他协程停止执行),稳定性较弱------需通过异常捕获机制保障协程安全。
面试关键点与加分点
- 关键点:三者的核心定位(资源分配/CPU 调度/用户态调度);资源占用和切换开销的差异;调度主体(内核/用户);适用场景(进程:资源隔离,线程:并行计算,协程:高并发 IO)。
- 加分点:能结合 iOS 实际场景举例(如 App 进程、GCD 线程、Swift Concurrency 协程);能解释"协程为何适合 IO 密集型任务"(避免线程阻塞,提高线程利用率);能说明"线程颠簸"的原因(线程过多导致频繁上下文切换);能区分"抢占式调度"(内核强制切换)和"非抢占式调度"(用户主动让出)。
记忆法
- 核心定位记忆:"进程分资源,线程抢 CPU,协程用户调,轻量高并发"------提炼三者的核心职责,快速区分定位;
- 开销对比记忆:"进程毫秒级,线程微秒级,协程纳秒级,粒度越细开销越低"------通过时间量级记忆切换开销,关联并发粒度。
进程和线程的具体区别有哪些?
进程和线程是操作系统中并发执行任务的核心载体,两者的关系是"线程隶属于进程,进程包含线程",但在资源分配、调度机制、生命周期等 10 个核心维度存在具体差异------这些差异直接决定了两者的使用场景(进程适合资源隔离,线程适合进程内并行任务),是 iOS 开发中理解多线程编程(如 GCD、NSOperation)和进程间通信(如通知、共享内存)的基础。
一、核心区别拆解(结合 iOS 场景)
1. 资源分配:进程独立,线程共享
这是进程和线程最根本的区别:
-
进程:操作系统为每个进程分配独立的资源集合,包括:
- 独立的虚拟地址空间(代码段、数据段、堆、栈):如 iOS 中每个 App 进程有独立的沙盒目录(Documents、Library 等),其他 App 进程无法直接访问;
- 系统资源:独立的文件句柄、网络端口、进程 ID(PID)、内存配额等。进程间的资源完全隔离,一个进程的资源修改(如修改堆内存数据)不会影响其他进程。
-
线程:线程不拥有独立资源,共享所属进程的所有资源,包括:
- 进程的地址空间:线程可直接访问进程的全局变量、堆内存、代码段(如 iOS 中 GCD 线程可直接读写 App 进程的缓存数据);
- 系统资源:共享进程的文件句柄、网络端口(如一个 App 进程的多个线程可共用同一个网络连接)。线程仅拥有独立的"执行相关资源":独立的栈空间(存储局部变量、函数调用栈)、独立的寄存器状态(程序计数器、指令指针)。
2. 调度机制:进程调度vs线程调度
调度是操作系统分配 CPU 时间片的过程,两者的调度主体、开销、策略差异显著:
-
进程调度:
- 调度主体:操作系统内核(内核态调度);
- 调度单位:以进程为单位分配 CPU 时间片;
- 切换开销:大(毫秒级)------切换进程时,内核需完成"保存当前进程的上下文(地址空间、寄存器、内存映射表)→ 加载目标进程的上下文 → 切换地址空间"等操作,涉及用户态与内核态的切换,耗时较长;
- 调度策略:抢占式调度(内核可强制暂停当前进程,切换到更高优先级进程),如 iOS 的进程优先级调度(前台 App 进程优先级高于后台进程)。
-
线程调度:
- 调度主体:操作系统内核(内核态调度);
- 调度单位:以线程为单位分配 CPU 时间片;
- 切换开销:中(微秒级)------切换线程时,内核仅需保存/恢复线程的独立资源(栈指针、寄存器状态),无需切换地址空间(因线程共享进程地址空间),开销远低于进程切换;
- 调度策略:同样是抢占式调度,内核根据线程优先级分配时间片(如 iOS 中
NSThread可设置threadPriority,高优先级线程优先执行)。
3. 生命周期:进程生命周期vs线程生命周期
生命周期是"创建→就绪→运行→阻塞→终止"的过程,两者的生命周期依赖关系、管理开销不同:
- 进程生命周期:
- 独立性强:进程的生命周期独立于其他进程,由操作系统直接管理(创建:
fork()/exec()系统调用;终止:正常退出、异常崩溃、被内核终止)
- 独立性强:进程的生命周期独立于其他进程,由操作系统直接管理(创建:
什么情况下会产生死锁?如何避免死锁?
死锁是多线程并发编程中最典型的问题之一,指两个或多个线程互相持有对方所需的资源,且都无法释放自己的资源,导致所有线程永久阻塞,无法继续执行的状态。死锁的产生需满足特定条件,避免死锁的核心是破坏这些条件,或通过合理的资源管理策略减少冲突。
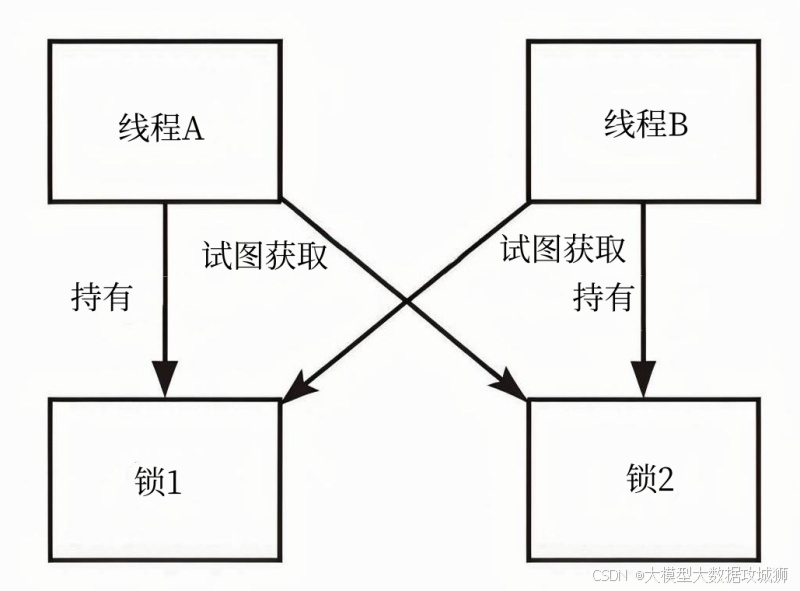
一、死锁产生的必要条件(缺一不可)
死锁的发生必须同时满足以下四个条件,只要破坏其中任意一个,死锁就不会产生:
- 互斥条件:资源具有排他性,同一时间只能被一个线程占用(如锁、文件句柄等,无法同时被多个线程访问)。这是资源本身的属性,无法改变(如锁的核心作用就是互斥)。
- 持有并等待条件:线程持有至少一个资源,同时又在等待其他线程持有的资源,且在等待期间不释放自己已持有的资源。例如:线程 A 持有锁 1,等待锁 2;线程 B 持有锁 2,等待锁 1,两者均不释放已有资源。
- 不可剥夺条件:线程已持有的资源不能被其他线程强制剥夺,只能由持有线程主动释放(如锁只能由加锁线程解锁,其他线程无法强制解锁)。
- 循环等待条件:多个线程形成环形等待链,每个线程都在等待链中下一个线程持有的资源。例如:线程 A → 等待锁 2(线程 B 持有),线程 B → 等待锁 1(线程 A 持有),形成 A→B→A 的循环。
二、死锁产生的典型场景(结合 iOS 示例)
1. 多锁顺序不一致(最常见场景)
多个线程在获取多个锁时,顺序不同,导致循环等待。这是 iOS 多线程开发(如 GCD、NSThread)中最易出现的死锁场景。
代码示例(iOS 中 GCD 线程死锁):
#import <Foundation/Foundation.h>
// 定义两个锁
NSLock *lock1 = [[NSLock alloc] init];
NSLock *lock2 = [[NSLock alloc] init];
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 线程 1:先加锁1,再加锁2
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock1 lock];
NSLog(@"线程1:持有锁1,等待锁2");
// 模拟耗时操作,让线程2有时间获取锁2
[NSThread sleepForTimeInterval:1];
[lock2 lock]; // 等待线程2释放锁2
NSLog(@"线程1:获取锁2,执行完成");
[lock2 unlock];
[lock1 unlock];
});
// 线程 2:先加锁2,再加锁1
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock2 lock];
NSLog(@"线程2:持有锁2,等待锁1");
// 模拟耗时操作,让线程1有时间获取锁1
[NSThread sleepForTimeInterval:1];
[lock1 lock]; // 等待线程1释放锁1
NSLog(@"线程2:获取锁1,执行完成");
[lock1 unlock];
[lock2 unlock];
});
}
return 0;
}- 运行结果:线程1持有锁1等待锁2,线程2持有锁2等待锁1,形成循环等待,程序永久阻塞,无后续输出。
2. 嵌套锁与线程阻塞
线程在持有锁的情况下,等待其他可能持有该锁的线程完成任务,导致自我阻塞或循环等待。例如:主线程持有锁,子线程等待主线程的任务,而主线程又在等待子线程释放锁。
代码示例(主线程与子线程死锁):
NSLock *lock = [[NSLock alloc] init];
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 主线程:加锁后,等待子线程完成任务
[lock lock];
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"子线程:等待锁");
[lock lock]; // 等待主线程释放锁
NSLog(@"子线程:获取锁,执行完成");
[lock unlock];
});
// 主线程等待子线程完成(但子线程在等待主线程的锁)
dispatch_sync(dispatch_get_global_queue(0, 0), ^{
NSLog(@"主线程等待子线程任务");
});
[lock unlock];
}
return 0;
}- 运行结果:主线程持有锁,等待子线程的
dispatch_sync任务完成;子线程等待主线程释放锁,无法执行,形成死锁。
3. 资源不足导致的循环等待
多个线程竞争有限的资源(如数据库连接、网络端口),且资源分配顺序不合理,导致循环等待。例如:线程 A 持有资源 1,等待资源 2;线程 B 持有资源 2,等待资源 3;线程 C 持有资源 3,等待资源 1,形成环形等待链。
三、避免死锁的核心策略(破坏死锁条件)
避免死锁的本质是破坏死锁的四个必要条件(互斥条件无法破坏,重点破坏后三个),结合 iOS 开发场景,常用策略如下:
1. 统一资源获取顺序(破坏循环等待条件)
这是最常用、最有效的策略:多个线程在获取多个资源(锁、数据库连接等)时,严格遵循相同的顺序,避免形成循环等待。
修改上述多锁顺序不一致的示例(统一获取顺序):
// 线程 1 和线程 2 均遵循"先锁1,后锁2"的顺序
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock1 lock];
NSLog(@"线程1:持有锁1,等待锁2");
[NSThread sleepForTimeInterval:1];
[lock2 lock];
NSLog(@"线程1:获取锁2,执行完成");
[lock2 unlock];
[lock1 unlock];
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock1 lock]; // 统一先获取锁1
NSLog(@"线程2:持有锁1,等待锁2");
[NSThread sleepForTimeInterval:1];
[lock2 lock];
NSLog(@"线程2:获取锁2,执行完成");
[lock2 unlock];
[lock1 unlock];
});- 运行结果:线程1先获取锁1,线程2等待锁1;线程1获取锁2执行完成后释放锁1和锁2,线程2再获取锁1和锁2,无死锁。
2. 一次性获取所有资源(破坏持有并等待条件)
线程在执行任务前,一次性获取所需的所有资源,获取失败则放弃已获取的资源(若有),重新等待,避免"持有部分资源等待其他资源"的情况。
iOS 中可通过 NSLock 的 tryLock 方法(尝试加锁,失败返回 NO)实现:
// 线程尝试一次性获取锁1和锁2,获取失败则重试
dispatch_async(dispatch_get_global_queue(0, 0), ^{
BOOL success = NO;
while (!success) {
// 尝试获取锁1
if ([lock1 tryLock]) {
// 尝试获取锁2
if ([lock2 tryLock]) {
NSLog(@"线程1:成功获取所有锁,执行完成");
[lock2 unlock];
[lock1 unlock];
success = YES;
} else {
// 获取锁2失败,释放锁1,避免持有资源
[lock1 unlock];
[NSThread sleepForTimeInterval:0.1]; // 短暂等待后重试
}
} else {
[NSThread sleepForTimeInterval:0.1]; // 获取锁1失败,重试
}
}
});- 核心逻辑:若无法一次性获取所有资源,立即释放已获取的资源,避免持有部分资源等待,破坏"持有并等待"条件。
3. 超时释放资源(破坏不可剥夺条件)
线程获取资源(如锁)后,设置超时时间,若超时未获取到所需的其他资源,则主动释放已持有的资源,避免永久等待。
iOS 中 NSLock 支持 lockBeforeDate: 方法(指定时间前未获取锁则返回 NO),可实现超时释放:
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock1 lock];
NSLog(@"线程1:持有锁1,等待锁2(超时1秒)");
// 尝试在1秒内获取锁2,超时返回NO
BOOL lock2Success = [lock2 lockBeforeDate:[NSDate dateWithTimeIntervalSinceNow:1]];
if (lock2Success) {
NSLog(@"线程1:获取锁2,执行完成");
[lock2 unlock];
} else {
NSLog(@"线程1:获取锁2超时,释放锁1");
[lock1 unlock]; // 超时释放已持有资源
}
});- 核心逻辑:通过超时机制,让线程在等待超时后主动释放资源,破坏"不可剥夺"条件(相当于资源被"自我剥夺")。
4. 减少锁的嵌套和持有时间(降低死锁概率)
- 避免锁嵌套:尽量不使用"锁中锁"(如在持有锁1的情况下加锁2),减少资源竞争的复杂度;
- 缩短锁持有时间:仅在操作共享资源的关键代码段加锁,执行完成后立即解锁,避免长时间持有锁导致其他线程等待。
iOS 中 GCD 的 dispatch_semaphore_t 可用于简化锁的使用,缩短持有时间:
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);
dispatch_async(dispatch_get_global_queue(0, 0), ^{
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
// 仅关键代码段加锁,执行完成立即解锁
NSLog(@"线程1:操作共享资源");
dispatch_semaphore_signal(semaphore);
});5. 使用无锁编程或原子操作(避免互斥条件)
对于简单的共享数据操作(如计数器增减),可使用原子操作(如 iOS 中的 OSAtomic 系列函数、Swift 中的 Atomic 类型)或无锁数据结构(如无锁队列),避免使用锁,从根源上消除死锁可能。
代码示例(iOS 原子操作实现计数器):
#import <libkern/OSAtomic.h>
int32_t counter = 0;
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 1000; i++) {
// 原子自增操作,无需加锁
OSAtomicIncrement32(&counter);
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int i = 0; i < 1000; i++) {
OSAtomicIncrement32(&counter);
}
});面试关键点与加分点
- 关键点:死锁的四个必要条件(互斥、持有并等待、不可剥夺、循环等待);典型场景(多锁顺序不一致、嵌套锁阻塞);核心避免策略(统一资源顺序、一次性获取资源、超时释放、减少锁嵌套)。
- 加分点:能结合 iOS 具体 API (如
NSLock的lockBeforeDate:、GCD 信号量)说明避免死锁的实现;能区分"避免死锁"和"解除死锁"(如通过监控线程状态强制终止阻塞线程);能解释原子操作为何能避免死锁(无需互斥锁,破坏互斥条件)。
记忆法
- 死锁条件记忆:"互斥持有等,循环不可夺"------提炼四个必要条件的关键字,快速关联;
- 避免策略记忆:"顺序要统一,资源一次性,超时就释放,少锁短持有"------对应四大核心策略,强化理解。
请讲解优先级反转的概念及对应的解决方案?
优先级反转是多线程调度中常见的问题,指高优先级线程因等待低优先级线程持有的资源(如锁),导致高优先级线程被阻塞,而低优先级线程又被中优先级线程抢占 CPU,最终高优先级线程的执行优先级低于中优先级线程的现象。该问题会破坏"高优先级线程优先执行"的调度原则,导致系统响应延迟,在实时系统(如 iOS 实时任务、嵌入式设备)中危害尤为严重。
一、优先级反转的核心概念与发生流程
要理解优先级反转,需先明确三个核心角色:
- 高优先级线程(H):本应优先执行的线程(如 iOS 中处理用户交互的主线程,优先级高于后台线程);
- 中优先级线程(M):优先级介于 H 和 L 之间;
- 低优先级线程(L):优先级最低,但持有 H 线程所需的资源(如锁)。
优先级反转的典型发生流程(结合 iOS 场景):
- 低优先级线程 L 先获取锁,开始执行临界区代码;
- 高优先级线程 H 启动,因需要 L 持有的锁,被阻塞(等待 L 释放锁);
- 中优先级线程 M 启动,其优先级高于 L,抢占 CPU 执行(操作系统的抢占式调度);
- L 线程因优先级低于 M,无法获得 CPU 时间片,无法继续执行,也就无法释放锁;
- H 线程因等待 L 释放锁,持续阻塞,导致 H 的实际执行优先级低于 M,形成优先级反转。
示例场景(iOS 中 GCD 线程优先级反转):
- 线程 L(低优先级全局队列):持有数据锁,执行文件写入(耗时操作);
- 线程 H(主队列,高优先级):需要读取该数据,等待 L 释放锁;
- 线程 M(默认优先级全局队列):启动后抢占 CPU,执行计算任务,L 无法获得 CPU 继续执行,H 持续阻塞,导致用户交互延迟(主线程阻塞)。
二、优先级反转的危害
- 破坏实时性:高优先级线程(如处理用户点击、传感器数据的线程)本应快速响应,却因阻塞导致系统响应延迟(如 iOS 应用卡顿、掉帧);
- 资源浪费:高优先级线程的 CPU 资源被中优先级线程占用,系统整体吞吐量下降;
- 潜在死锁风险:若低优先级线程长期被抢占,高优先级线程可能永久阻塞(极端情况下)。
三、优先级反转的解决方案(结合 iOS 实现)
解决优先级反转的核心思路是"确保持有高优先级线程所需资源的低优先级线程,能优先获得 CPU 执行,尽快释放资源",常用方案包括优先级继承、优先级天花板、禁止抢占等,iOS 中主要通过系统调度机制和 API 支持前两种方案。
1. 优先级继承(Priority Inheritance):最常用方案
优先级继承是指当低优先级线程 L 持有高优先级线程 H 所需的资源时,L 的优先级被临时提升至 H 的优先级,直到 L 释放资源------这样 L 不会被中优先级线程 M 抢占,能快速执行并释放资源,H 可及时获取资源执行。
- 核心逻辑:"谁等待,就继承谁的优先级",临时提升持有资源的低优先级线程优先级,避免其被抢占。
- iOS 中的支持:iOS 系统内核(XNU 内核)和 GCD 调度机制已内置优先级继承支持,尤其是在使用系统提供的锁(如
pthread_mutex_t、NSLock)时,会自动触发优先级继承。
代码示例(iOS 中利用系统锁触发优先级继承):
#import <Foundation/Foundation.h>
#import <pthread.h>
pthread_mutex_t lock;
// 初始化锁,默认支持优先级继承(iOS 中 pthread_mutex_t 的默认属性包含优先级继承)
pthread_mutex_init(&lock, NULL);
// 低优先级线程 L
void *lowPriorityThread(void *arg) {
pthread_mutex_lock(&lock);
NSLog(@"低优先级线程 L:持有锁,开始执行(优先级临时提升)");
// 模拟耗时操作(若不提升优先级,会被中优先级线程抢占)
[NSThread sleepForTimeInterval:2];
pthread_mutex_unlock(&lock);
NSLog(@"低优先级线程 L:释放锁,优先级恢复");
return NULL;
}
// 中优先级线程 M
void *midPriorityThread(void *arg) {
NSLog(@"中优先级线程 M:启动,尝试抢占 CPU");
// 模拟耗时计算,若 L 未提升优先级,会抢占 L 的 CPU
for (int i = 0; i < 1000000000; i++);
NSLog(@"中优先级线程 M:执行完成");
return NULL;
}
// 高优先级线程 H(主线程,优先级最高)
void highPriorityThread() {
NSLog(@"高优先级线程 H:启动,等待锁");
pthread_mutex_lock(&lock);
NSLog(@"高优先级线程 H:获取锁,执行完成");
pthread_mutex_unlock(&lock);
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
pthread_t t1, t2;
// 设置线程 L 为低优先级
struct sched_param paramLow = {.sched_priority = 10};
pthread_attr_setschedparam(&t1, ¶mLow);
pthread_create(&t1, NULL, lowPriorityThread, NULL);
// 设置线程 M 为中优先级
struct sched_param paramMid = {.sched_priority = 50};
pthread_attr_setschedparam(&t2, ¶mMid);
pthread_create(&t2, NULL, midPriorityThread, NULL);
// 延迟 0.5 秒,确保 L 已持有锁
[NSThread sleepForTimeInterval:0.5];
// 主线程(H)执行,等待锁
highPriorityThread();
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_mutex_destroy(&lock);
}
return 0;
}-
运行结果:
低优先级线程 L:持有锁,开始执行(优先级临时提升) 中优先级线程 M:启动,尝试抢占 CPU(失败,因 L 优先级已提升至 H 的级别) 高优先级线程 H:启动,等待锁 低优先级线程 L:释放锁,优先级恢复 高优先级线程 H:获取锁,执行完成 中优先级线程 M:执行完成 -
核心:
pthread_mutex_t在 iOS 中默认支持优先级继承,L 持有锁后被提升至 H 的优先级,M 无法抢占,L 快速释放锁,H 正常执行,避免优先级反转。
2. 优先级天花板(Priority Ceiling):预先提升优先级
优先级天花板是指将持有资源(如锁)的所有线程的优先级,预先提升至"可能访问该资源的最高优先级线程的优先级"------即资源本身有一个"优先级天花板",任何线程持有该资源时,优先级都会被提升至该天花板,无需等待高优先级线程触发。
- 核心逻辑:"资源有天花板,持有即提升",预先设定资源的最高优先级,避免临时调整的开销。
- iOS 中的支持:可通过
pthread_mutexattr_setprioceiling函数设置锁的优先级天花板,适用于已知访问资源的最高优先级线程的场景。
代码示例(iOS 中设置锁的优先级天花板):
pthread_mutex_t lock;
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
// 设置锁的优先级天花板为高优先级(如 100,对应主线程优先级)
pthread_mutexattr_setprioceiling(&attr, 100);
// 初始化锁,应用优先级天花板属性
pthread_mutex_init(&lock, &attr);
// 低优先级线程 L 持有锁时,优先级自动提升至 100(天花板级别)
void *lowPriorityThread(void *arg) {
pthread_mutex_lock(&lock);
NSLog(@"低优先级线程 L:持有锁,优先级提升至天花板(100)");
[NSThread sleepForTimeInterval:2];
pthread_mutex_unlock(&lock);
return NULL;
}- 核心:锁的优先级天花板预先设定为最高优先级,L 持有锁后立即提升优先级,无需等待 H 线程启动,更主动地避免抢占。
3. 禁止抢占:简化调度(适用于简单场景)
禁止抢占是指在低优先级线程执行临界区代码(持有资源)期间,禁止其他线程抢占 CPU------即 L 持有资源时,CPU 完全分配给 L,直到其释放资源,适用于临界区代码执行时间短的场景。
- iOS 中的支持:可通过
pthread_setschedparam设置线程的调度策略为SCHED_FIFO(先进先出),低优先级线程执行时不会被中优先级线程抢占(仅高优先级线程可抢占),但需谨慎使用(可能导致低优先级线程长期占用 CPU)。
4. 避免使用共享资源:从根源消除
对于简单的任务,可通过无锁编程(如原子操作、无锁队列)避免使用锁,从根源上消除优先级反转的可能------因为优先级反转的核心是"资源竞争+优先级差异",无锁则无竞争。
iOS 中原子操作示例(无锁计数器):
#import <libkern/OSAtomic.h>
int32_t counter = 0;
// 低优先级线程 L 执行原子自增
void *lowPriorityThread(void *arg) {
for (int i = 0; i < 1000; i++) {
OSAtomicIncrement32(&counter);
}
return NULL;
}
// 高优先级线程 H 执行原子自增
void highPriorityThread() {
for (int i = 0; i < 1000; i++) {
OSAtomicIncrement32(&counter);
}
}- 核心:原子操作无需加锁,高优先级线程不会因等待锁被阻塞,无优先级反转风险。
四、iOS 开发中的注意事项
- 优先使用系统原生锁:
NSLock、pthread_mutex_t等系统锁已内置优先级继承支持,避免使用自定义锁(如基于信号量的简单锁),可能不支持优先级继承; - 合理设置线程优先级:避免滥用高优先级线程,仅对实时性要求高的任务(如用户交互、音频播放)设置高优先级;
- 缩短临界区时间:无论使用哪种方案,都应尽量缩短持有锁的时间,减少线程阻塞的可能性;
- 避免嵌套锁:嵌套锁会增加优先级继承的复杂度,可能导致优先级反转难以解决。
面试关键点与加分点
- 关键点:优先级反转的定义(高优先级线程等待低优先级线程的资源,被中优先级线程抢占);发生流程(L 持有锁→H 等待→M 抢占 L→H 阻塞);核心解决方案(优先级继承、优先级天花板);iOS 中的实现(系统锁支持优先级继承、
pthread_mutexattr_setprioceiling设置天花板)。 - 加分点:能区分优先级继承和优先级天花板的差异(继承是临时提升,天花板是预先设定);能结合 iOS 具体 API (如
pthread_mutex_t初始化、OSAtomic原子操作)说明实现;能解释为何自定义锁可能导致优先级反转(不支持系统调度的优先级继承)。
记忆法
- 概念记忆:"高等低,低被中抢,高变低"------简化优先级反转的核心逻辑:高优先级等低优先级的资源,低优先级被中优先级抢占,高优先级实际优先级变低;
- 解决方案记忆:"继承临时提,天花板预先提,无锁根上移"------优先级继承是临时提升,天花板是预先提升,无锁编程从根源消除问题。
多线程操作非原子数据时,如何保障数据的安全性?
多线程操作非原子数据(如普通变量、数组、自定义对象等)时,因 CPU 调度的并行性,可能出现"数据竞争"(多个线程同时读写同一数据),导致数据不一致、脏读、死锁等问题。保障数据安全性的核心是"通过同步机制,确保同一时间只有一个线程能修改数据,或读写操作的原子性、有序性",常用方案包括锁机制、原子操作、无锁编程、串行队列等,需根据场景选择合适的方案。
一、核心问题:为何非原子数据需要保障安全?
非原子数据的读写操作不是"不可分割的"(原子操作),可能被 CPU 调度打断。例如:
- 32 位系统中读写 64 位数据(如
double、long long),需分两次 32 位操作; - 自定义对象的属性赋值(如
obj->count = 10),可能包含"读取旧值→修改→写入新值"的步骤。
代码示例(多线程操作非原子数据导致数据不一致):
#import <Foundation/Foundation.h>
// 非原子变量(默认情况下,iOS 中全局变量、局部静态变量均为非原子)
int nonAtomicCount = 0;
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 10 个线程同时自增 1000 次
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int j = 0; j < 1000; j++) {
nonAtomicCount++; // 非原子操作,可能被打断
}
});
}
// 等待所有线程完成
dispatch_barrier_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"最终结果:%d(预期:10000)", nonAtomicCount);
});
}
return 0;
}- 运行结果:最终结果可能为 9876、9950 等(小于 10000),原因是
nonAtomicCount++被拆分为"读取 count→count+1→写入 count",多个线程同时读取旧值,导致多次自增仅生效一次。
二、保障数据安全性的常用方案(结合 iOS 实现)
1. 锁机制:最通用的同步方案
锁的核心是"互斥访问",确保同一时间只有一个线程能进入临界区(操作共享数据的代码段),iOS 提供了多种锁 API,适用于不同场景。
(1)互斥锁:独占式访问(适合读写混合场景)
互斥锁是"当一个线程持有锁时,其他线程需等待锁释放"的锁,分为自旋锁和阻塞锁(挂起锁),iOS 中常用的互斥锁包括:
NSLock:封装后的阻塞锁,简单易用,支持超时设置;pthread_mutex_t:底层 POSIX 锁,支持多种属性(如优先级继承、递归锁);@synchronized:Objective-C 语法级锁,底层基于pthread_mutex_t,使用简单但性能略差。
代码示例(使用 NSLock 保护非原子数据):
#import <Foundation/Foundation.h>
int nonAtomicCount = 0;
NSLock *lock = [[NSLock alloc] init];
int main(int argc, const char * argv[]) {
@autoreleasepool {
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int j = 0; j < 1000; j++) {
[lock lock]; // 加锁,进入临界区
nonAtomicCount++; // 安全操作非原子数据
[lock unlock]; // 解锁,释放临界区
}
});
}
dispatch_barrier_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"最终结果:%d(预期:10000)", nonAtomicCount); // 输出 10000
});
}
return 0;
}- 核心逻辑:
lock和unlock之间的代码段为临界区,同一时间只有一个线程能执行,确保nonAtomicCount++是原子的。
(2)读写锁:优化读多写少场景
读写锁(pthread_rwlock_t)是"读共享、写独占"的锁,适合读操作远多于写操作的场景(如缓存数据读取),能提高并发效率(多个线程可同时读,仅写线程需互斥)。
代码示例(iOS 中使用读写锁):
#import <Foundation/Foundation.h>
#import <pthread.h>
NSMutableDictionary *cache = [NSMutableDictionary dictionary];
pthread_rwlock_t rwlock;
// 初始化读写锁
pthread_rwlock_init(&rwlock, NULL);
// 读操作(共享,多个线程可同时执行)
void readCache(NSString *key) {
pthread_rwlock_rdlock(&rwlock); // 加读锁
id value = cache[key];
NSLog(@"读取 key:%@,value:%@", key, value);
pthread_rwlock_unlock(&rwlock); // 解锁
}
// 写操作(独占,同一时间仅一个线程执行)
void writeCache(NSString *key, id value) {
pthread_rwlock_wrlock(&rwlock); // 加写锁
cache[key] = value;
NSLog(@"写入 key:%@,value:%@", key, value);
pthread_rwlock_unlock(&rwlock); // 解锁
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 10 个读线程
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
readCache(@"name");
});
}
// 1 个写线程
dispatch_async(dispatch_get_global_queue(0, 0), ^{
writeCache(@"name", @"Alice");
});
// 等待所有线程完成
dispatch_barrier_async(dispatch_get_global_queue(0, 0), ^{
pthread_rwlock_destroy(&rwlock);
});
}
return 0;
}- 核心优势:读操作不互斥,提高并发效率;写操作互斥,保障数据一致性,适合缓存、配置文件等读多写少场景。
2. 原子操作:轻量级数据同步(适合简单数据类型)
原子操作是"不可分割的操作"(CPU 层面无法打断),适用于简单数据类型(如 int、long、指针等)的增减、赋值等操作,无需锁,性能远高于锁机制。
iOS 中的原子操作 API:
OSAtomic系列函数(32 位/64 位数据操作,如OSAtomicIncrement32、OSAtomicCompareAndSwap64);- Swift 中的
Atomic类型(Swift 5.5+ 支持,如Atomic<Int>); std::atomic(C++ 标准库,跨平台支持)。
代码示例(使用 OSAtomic 实现原子自增):
#import <Foundation/Foundation.h>
#import <libkern/OSAtomic.h>
// 非原子变量,但通过原子操作保障安全
int32_t nonAtomicCount = 0;
int main(int argc, const char * argv[]) {
@autoreleasepool {
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int j = 0; j < 1000; j++) {
// 原子自增操作,不可分割
OSAtomicIncrement32(&nonAtomicCount);
}
});
}
dispatch_barrier_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"最终结果:%d(预期:10000)", nonAtomicCount); // 输出 10000
});
}
return 0;
}- 核心适用场景:简单数据类型的加减、赋值、比较交换(CAS)操作,如计数器、标志位等,避免因锁带来的性能开销。
3. 串行队列:通过队列串行化执行任务
GCD 的串行队列(dispatch_queue_create("com.example.serial", DISPATCH_QUEUE_SERIAL))可将所有操作串行化执行(同一时间仅一个任务执行),本质是"队列层面的同步",无需手动加锁,适合 Objective-C/Swift 开发中的数据同步。
代码示例(使用 GCD 串行队列保护非原子数据):
#import <Foundation/Foundation.h>
int nonAtomicCount = 0;
// 创建串行队列
dispatch_queue_t serialQueue = dispatch_queue_create("com.example.serial", DISPATCH_QUEUE_SERIAL);
int main(int argc, const char * argv[]) {
@autoreleasepool {
for (int i = 0; i < 10; i++) {
dispatch_async(serialQueue, ^{ // 所有任务提交到串行队列
for (int j = 0; j < 1000; j++) {
nonAtomicCount++; // 串行执行,无需加锁
}
});
}
dispatch_barrier_async(serialQueue, ^{
NSLog(@"最终结果:%d(预期:10000)", nonAtomicCount); // 输出 10000
});
}
return 0;
}- 核心优势:使用简单,无需关注锁的加解锁和死锁问题;GCD 队列由系统优化,性能稳定,是 iOS 开发中推荐的方案之一(如替代
@synchronized)。
4. 无锁编程:基于 CAS 机制(高并发场景)
无锁编程是指不使用锁,通过"比较并交换(CAS)"机制实现数据同步,核心是"乐观锁"思想(假设无冲突,冲突则重试),适用于高并发、低冲突场景,性能远高于锁机制。
- CAS 机制原理:通过原子操作比较内存中的值与预期值,若相等则更新为新值,否则重试(或返回失败),整个过程原子化,无需锁。
- iOS 中的支持:
OSAtomicCompareAndSwap32、std::atomic的compare_exchange_weak等 API。
代码示例(使用 CAS 实现无锁计数器):
#import <Foundation/Foundation.h>
#import <libkern/OSAtomic.h>
int32_t nonAtomicCount = 0;
// 无锁自增函数
void atomicIncrement() {
int32_t oldValue;
do {
oldValue = nonAtomicCount; // 读取当前值
// CAS 操作:若当前值仍为 oldValue,则更新为 oldValue + 1
} while (!OSAtomicCompareAndSwap32(oldValue, oldValue + 1, &nonAtomicCount));
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
for (int j = 0; j < 1000; j++) {
atomicIncrement();
}
});
}
dispatch_barrier_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"最终结果:%d(预期:10000)", nonAtomicCount); // 输出 10000
});
}
return 0;
}- 核心适用场景:高并发、低冲突的场景(如秒杀系统计数器),冲突率高时会导致频繁重试,性能下降,需谨慎使用。
5. 线程局部存储(TLS):避免共享数据
线程局部存储(Thread-Local Storage,TLS)是指为每个线程分配独立的存储空间,线程仅访问自己的局部数据,无需共享,从根源上消除数据竞争。
iOS 中的 TLS 实现:
__thread关键字(C++11+):用于全局变量或静态变量,每个线程有独立副本;pthread_setspecific/pthread_getspecific:POSIX 接口,支持任意类型的线程局部数据;NSThread的threadDictionary:Objective-C 层面的线程局部存储,以字典形式存储数据。
代码示例(使用 __thread 避免共享数据):
#import <Foundation/Foundation.h>
// 线程局部变量:每个线程有独立副本
__thread int threadLocalCount = 0;
int main(int argc, const char * argv[]) {
@autoreleasepool {
for (int i = 0; i < 10; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
threadLocalCount = 0; // 初始化当前线程的局部变量
for (int j = 0; j < 1000; j++) {
threadLocalCount++; // 操作线程局部数据,无竞争
}
NSLog(@"线程 %@:局部计数 %d", [NSThread自旋锁和互斥锁的区别是什么?各自的应用场景有哪些?
自旋锁和互斥锁是多线程同步中最基础的两种锁机制,核心共性是 "保证临界区互斥访问",但在等待锁的策略、性能开销、资源占用等方面存在本质差异 ------ 自旋锁 "忙等" 不放弃 CPU,互斥锁 "阻塞" 放弃 CPU,两者的选择需结合临界区执行时间、线程竞争强度等场景判断。
一、核心区别对比(表格汇总)
| 对比维度 | 自旋锁(Spin Lock) | 互斥锁(Mutex Lock) |
|---|---|---|
| 等待策略 | 忙等(Busy Waiting):线程在锁被占用时,持续循环检查锁状态,不放弃 CPU 执行权 | 阻塞等待(Block Waiting):线程在锁被占用时,主动放弃 CPU,进入休眠状态,等待锁释放后被内核唤醒 |
| CPU 资源占用 | 高:等待期间持续占用 CPU,循环检查锁状态,导致 CPU 利用率飙升 | 低:等待期间线程休眠,CPU 可调度给其他线程,资源利用率高 |
| 上下文切换开销 | 无:线程始终处于运行状态,无需内核切换上下文(用户态操作) | 有:线程阻塞 / 唤醒需切换内核态,保存 / 恢复线程上下文(栈、寄存器等),开销较大(微秒级) |
| 响应速度 | 快:锁释放时,等待线程可立即获取锁(无唤醒延迟) | 慢:锁释放后,需内核唤醒线程,存在唤醒延迟 |
| 死锁风险 | 高:若持有锁的线程被抢占(如优先级反转)或阻塞(如 IO 操作),等待线程会永久自旋 | 低:线程阻塞时不占用 CPU,即使持有锁的线程阻塞,也不会导致 CPU 浪费 |
| 适用临界区类型 | 短临界区(执行时间极短,如几纳秒 / 微秒) | 长临界区(执行时间较长,如毫秒级、IO 操作) |
| 线程竞争强度 | 低竞争(等待锁的线程少,锁释放快) | 高竞争(等待锁的线程多,锁释放慢) |
| iOS 中的典型实现 | OSSpinLock(已废弃,存在优先级反转问题)、pthread_spinlock_t |
NSLock、pthread_mutex_t、@synchronized、GCD 信号量(间接实现) |
二、关键区别深度解析
1. 等待策略:忙等 vs 阻塞(核心差异)
-
自旋锁的 "忙等" 机制 :当线程尝试获取自旋锁但失败时,不会放弃 CPU 执行权,而是进入一个无限循环(如
while(!tryLock()){}),持续检查锁是否被释放。期间线程始终处于 "运行态",CPU 完全被该线程占用,直到获取到锁。- 底层逻辑:自旋锁是用户态锁,操作完全在用户态完成,无需内核介入,因此无上下文切换开销。
- 示例:iOS 中
pthread_spinlock_t的获取逻辑,本质是通过原子操作(如 CAS)循环尝试修改锁的状态标志位。
-
互斥锁的 "阻塞" 机制 :当线程尝试获取互斥锁但失败时,会主动调用系统调用(如
pthread_mutex_lock),将线程状态从 "运行态" 切换为 "阻塞态",并加入锁的等待队列。此时 CPU 会调度其他就绪线程执行,直到持有锁的线程释放锁,内核才会从等待队列中唤醒一个线程,使其恢复为 "运行态" 并获取锁。- 底层逻辑:互斥锁依赖内核态调度,阻塞 / 唤醒过程涉及用户态与内核态的切换,需保存线程上下文(栈指针、寄存器、程序计数器等),开销远大于自旋锁的循环检查。
- 示例:iOS 的
NSLock底层封装了pthread_mutex_t,调用lock方法时,若锁被占用,线程会进入休眠,直到unlock被调用后被内核唤醒。
2. 性能开销:无切换 vs 有切换
- 自旋锁:无上下文切换开销,但等待期间 CPU 资源被浪费("空转")。若临界区执行时间极短(如修改一个全局变量、原子操作封装),自旋等待的总开销(循环检查时间)远小于互斥锁的上下文切换开销,此时自旋锁性能更优。
- 互斥锁:上下文切换开销较大(一次切换约几微秒),但等待期间 CPU 可被其他线程利用。若临界区执行时间较长(如文件读写、网络请求、复杂计算),互斥锁的阻塞等待开销远小于自旋锁的 CPU 空转开销,此时互斥锁更高效。
3. 死锁与优先级反转风险
- 自旋锁:死锁风险更高。例如:持有自旋锁的线程执行 IO 操作(如读取文件),导致线程阻塞,而等待锁的线程会持续自旋,永久占用 CPU,形成 "死锁"(持有锁的线程无法执行,等待线程无法获取锁);此外,自旋锁易引发优先级反转(低优先级线程持有锁,高优先级线程自旋等待,中优先级线程抢占 CPU)。
- 互斥锁 :死锁风险较低。持有锁的线程若阻塞,等待线程会进入休眠,不会浪费 CPU;且 iOS 中的
pthread_mutex_t支持优先级继承(默认开启),可缓解优先级反转问题。
三、各自的应用场景
1. 自旋锁的应用场景
自旋锁的核心优势是 "响应快、无切换开销",仅适用于以下场景:
- 临界区执行时间极短 :如简单的变量赋值、计数器增减、指针操作等(执行时间在纳秒 / 微秒级),此时自旋等待的时间远小于互斥锁的上下文切换时间。
- 示例:内核态代码(如 iOS 的 XNU 内核)中,临界区操作简单(如修改内核全局变量),自旋锁可避免内核态与用户态切换的开销;用户态中,无锁编程的 CAS 操作封装、简单的原子操作同步等。
- 线程竞争强度低 :等待锁的线程数量少(如 1-2 个线程),锁释放快,自旋等待的 CPU 浪费可忽略。
- 示例:单 CPU 核心场景下,线程竞争不激烈,自旋锁可避免互斥锁的上下文切换;多 CPU 核心场景下,持有锁的线程在一个核心执行,等待线程在另一个核心自旋,无需抢占,效率较高。
- 不允许线程阻塞的场景:如中断处理程序、内核原子操作等,线程无法进入休眠状态,只能通过自旋等待锁释放。
注意:iOS 开发中,
OSSpinLock已被苹果废弃(iOS 10+),因存在严重的优先级反转问题(高优先级线程自旋等待低优先级线程的锁,低优先级线程被中优先级线程抢占,导致高优先级线程永久自旋),推荐使用pthread_spinlock_t或os_unfair_lock(苹果替代OSSpinLock的轻量级锁,结合自旋和阻塞特性)。
2. 互斥锁的应用场景
互斥锁的核心优势是 "低 CPU 占用、支持长临界区",是 iOS 开发中最常用的锁,适用于以下场景:
- 临界区执行时间较长 :如文件读写、网络请求、数据库操作、复杂计算等(执行时间在毫秒级及以上),此时互斥锁的阻塞开销远小于自旋锁的 CPU 空转开销。
- 示例:iOS 中通过
NSLock保护数据库操作(如 SQLite 写入)、@synchronized保护自定义对象的属性读写、GCD 信号量保护文件下载任务等。
- 示例:iOS 中通过
- 线程竞争强度高 :多个线程(如 10 + 个)同时竞争锁,互斥锁的阻塞机制可避免 CPU 资源被浪费,保证系统整体吞吐量。
- 示例:App 的全局缓存读写、多线程并发处理网络响应数据等场景,多个线程频繁竞争锁,互斥锁的资源利用率更高。
- 线程可能阻塞的场景 :临界区中包含 IO 操作(如读取沙盒文件、网络请求)、睡眠操作(如
[NSThread sleepForTimeInterval:])等,此时若使用自旋锁,会导致等待线程永久自旋,而互斥锁可让线程休眠,避免 CPU 浪费。- 示例:iOS 中多线程下载文件,每个下载线程需要获取 "下载队列锁",临界区包含网络请求(可能阻塞),使用
NSLock可避免 CPU 空转。
- 示例:iOS 中多线程下载文件,每个下载线程需要获取 "下载队列锁",临界区包含网络请求(可能阻塞),使用
面试关键点与加分点
- 关键点:核心区别是等待策略(自旋 "忙等" vs 互斥 "阻塞");自旋锁无上下文切换、响应快但 CPU 占用高,互斥锁有切换、响应慢但 CPU 占用低;自旋锁适用于短临界区、低竞争,互斥锁适用于长临界区、高竞争。
- 加分点:能结合 iOS 实际 API(如
pthread_spinlock_t、NSLock、os_unfair_lock)说明差异;能解释OSSpinLock被废弃的原因(优先级反转);能区分多 CPU 和单 CPU 场景下两种锁的性能差异(多 CPU 自旋锁可利用多核,单 CPU 自旋锁浪费资源)。
记忆法
- 核心区别记忆:"自旋忙等不放手,互斥阻塞让 CPU"------ 提炼等待策略的核心差异,快速关联资源占用和开销特点;
- 应用场景记忆:"短临界、低竞争用自旋,长临界、高竞争用互斥"------ 简化场景选择逻辑,强化记忆。