文章目录
-
- [一、Redis 语义缓存](#一、Redis 语义缓存)
-
- [1.1 传统缓存的问题](#1.1 传统缓存的问题)
- [1.2 语义缓存的定义](#1.2 语义缓存的定义)
- [二、Redis 发展史与为什么它能做语义缓存](#二、Redis 发展史与为什么它能做语义缓存)
-
- [2.1 Redis 版本演进(关键节点)](#2.1 Redis 版本演进(关键节点))
-
- [Redis 7.x + Redis Stack 支持语义检索(2022--至今)](#Redis 7.x + Redis Stack 支持语义检索(2022–至今))
- [什么是Redis Stack](#什么是Redis Stack)
-
- [Redis 内核(Redis OSS)](#Redis 内核(Redis OSS))
- [Redis Stack 包含哪些组件(核心)](#Redis Stack 包含哪些组件(核心))
-
- [1️⃣ RediSearch](#1️⃣ RediSearch)
- [2️⃣ RedisJSON](#2️⃣ RedisJSON)
- [3️⃣ RedisTimeSeries(可选)](#3️⃣ RedisTimeSeries(可选))
- [4️⃣ RedisBloom(可选)](#4️⃣ RedisBloom(可选))
- [三、Redis 底层数据结构](#三、Redis 底层数据结构)
-
- [3.1 Redis 对象模型](#3.1 Redis 对象模型)
- [3.2 向量在 Redis 中的存储](#3.2 向量在 Redis 中的存储)
- 四、Redis中向量检索算法
-
- 一、FLAT:暴力但准确的向量搜索
- 二、HNSW:分层可导航小世界图
-
- [HNSW 是什么](#HNSW 是什么)
- HNSW的基础
-
- 概率跳表
- [NSW: 可导航的小世界图](#NSW: 可导航的小世界图)
- HNSW:分层导航小世界图
- HNSW特点
- [HNSW算法 参数含义](#HNSW算法 参数含义)
- [五、Redis 语义缓存整体架构](#五、Redis 语义缓存整体架构)
- [七、Go 语言实现语义缓存(工程示例)](#七、Go 语言实现语义缓存(工程示例))
-
- [7.0 创建索引(Redis Stack)](#7.0 创建索引(Redis Stack))
- [7.1 数据结构设计](#7.1 数据结构设计)
- [7.2 向量写入 Redis](#7.2 向量写入 Redis)
- [7.3 向量检索(KNN)](#7.3 向量检索(KNN))
- [7.4 命中策略(工程关键)](#7.4 命中策略(工程关键))
- [八、语义缓存 vs 向量数据库](#八、语义缓存 vs 向量数据库)
- 九、常见工程坑
在传统缓存体系中,Redis 的核心价值是 Key 精确命中 。
但在 大模型 / RAG / 智能问答 场景下,问题的本质已经发生变化:
用户的问题不是"是否完全一样",而是"语义是否相近"。
这催生了一种新的缓存形态:语义缓存(Semantic Cache)。
一、Redis 语义缓存
1.1 传统缓存的问题
text
Q1: 更换轮胎需要多少钱?
Q2: 汽车换一个轮胎大概费用?在 Key-Value 缓存里:
text
key1 != key2 → cache miss但在语义上:
text
sim(Q1, Q2) ≈ 0.95 → 应该命中1.2 语义缓存的定义
语义缓存 = 向量化 + 相似度检索 + Redis 高速存储
基本流程:
Query
↓ embedding
Vector
↓ ANN search
TopK 相似问题
↓ 阈值判断
命中 → 直接返回
未命中 → LLM 推理 + 写入缓存二、Redis 发展史与为什么它能做语义缓存
2.1 Redis 版本演进(关键节点)
| 版本 | 时间 | 关键能力 |
|---|---|---|
| Redis 2.x | 2012 | 单线程 KV,引入基础数据结构 |
| Redis 3.x | 2015 | Cluster,分片与高可用 |
| Redis 4.x | 2017 | Modules API(模块化能力基石) |
| Redis 6.x | 2020 | IO 多线程,提升网络吞吐 |
| Redis 7.x | 2022 | 内存 / 协议 / Cluster 优化 |
| Redis 8.x | 2024+ | 核心性能与内存模型持续优化(未引入原生向量能力) |
| Redis Stack | 2023 | Search / JSON / Vector(语义检索实际落地形态) |
真正让 Redis 能做语义缓存的,是:
Redis Modules + Vector Similarity Search
Redis 从 RediSearch 2.4(2022)开始支持向量相似度检索(FLAT / HNSW),这才真正具备"语义检索"能力。
Redis 7.x + Redis Stack 支持语义检索(2022--至今)
-
Redis 核心版本:7.x
-
通过 Redis Stack 统一集成:
- RediSearch
- RedisJSON
- Vector Search
工程上我们通常说:
"Redis 7 + Redis Stack = 可用的语义检索 Redis"
什么是Redis Stack
Redis Stack 是 Redis 官方推出的"能力集合发行版",在不修改 Redis 内核的前提下,通过官方模块,把搜索、JSON、向量检索等高级能力标准化、产品化。
它不是一个新 Redis,也不是一个新版本。
Redis Stack 为什么出现?
过去 Redis 生态是这样的:
- 模块版本碎片化
- 编译复杂
- 线上环境难以维护
Redis Stack 的目标是:
把"可用于生产的模块组合"标准化
Redis 内核(Redis OSS)
| 分类 | 内容 |
|---|---|
| 负责 | - 内存管理 - 网络 IO - 数据结构(String / Hash / ZSet ...) |
| 目标 | - 极致性能 - 核心最小化 |
| 不直接做 | - 搜索 - 向量索引 - JSON 查询 |
Redis Stack 包含哪些组件(核心)
1️⃣ RediSearch
最重要的模块
- 全文检索
- 二级索引
- 聚合查询
- 向量相似度检索(FLAT / HNSW)
text
FT.CREATE
FT.SEARCH
FT.AGGREGATE语义检索能力 = 100% 来自 RediSearch
2️⃣ RedisJSON
-
原生 JSON 存储
-
支持:
- JSONPath
- 局部更新
-
解决 Hash 表达能力不足的问题
适合:
- RAG 元数据
- 结构化 Prompt
- 会话状态
3️⃣ RedisTimeSeries(可选)
-
高性能时序数据
-
常用于:
- 监控
- 指标
- 特征统计
4️⃣ RedisBloom(可选)
- Bloom / Cuckoo Filter
- HyperLogLog
- TopK
常用于:
- 去重
- 防缓存穿透
- 热点统计
三、Redis 底层数据结构
3.1 Redis 对象模型
text
redisObject
├── type (string / hash / zset / module)
├── encoding (int / embstr / ziplist / skiplist)
└── ptrVector 本质是:
text
module 类型对象3.2 向量在 Redis 中的存储
在 Redis Stack(Search 模块)中:
-
向量字段并非 String
-
而是 专用 Vector Index
-
支持:
- FLAT(暴力)
- HNSW(近似)
四、Redis中向量检索算法
一、FLAT:暴力但准确的向量搜索
对于Flat索引,我们引入查询向量 xq,并将其与索引中所有向量进行比较,即计算 xq 到每个向量的距离。
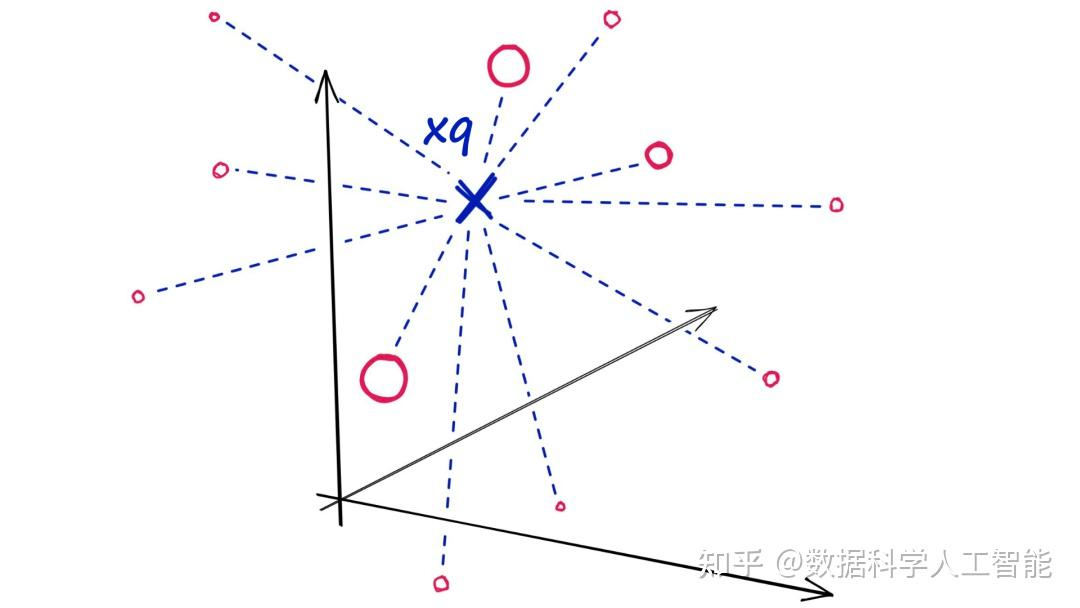
在计算完所有这些距离后,我们将返回其中最接近的 k 个作为我们最接近的匹配项。即进行一次k最近邻 (kNN) 搜索。
| 维度 | 说明 |
|---|---|
| 算法本质 | 对所有向量逐一计算距离,排序后取 TopK(Brute Force) |
| 时间复杂度 | O(N × D) N:向量数量 D:向量维度 |
| 距离计算 | L2(欧氏距离) IP(内积) COSINE(语义检索最常用) |
| 精度 | 100% 精确 |
| 构建成本 | 无需构建索引 |
| 参数调优 | 不需要 |
| 性能特点 | ❌ 性能差 ❌ 无法扩展 ❌ N 稍大就不可用 |
| 适用规模 | < 10k:可用 10k ~ 100k:勉强 > 100k:不现实 |
| Redis 支持 | VECTOR FLAT 768 |
| 典型场景 | 调试验证 小规模语义缓存 召回精度基准(Baseline) |
二、HNSW:分层可导航小世界图
HNSW 是什么
HNSW(Hierarchical Navigable Small World):
层次化可导航小世界(HNSW)图是向量相似性搜索中表现最佳的索引之一。HNSW 技术以其超级快速的搜索速度和出色的召回率,在近似最近邻(ANN)搜索中表现卓越。
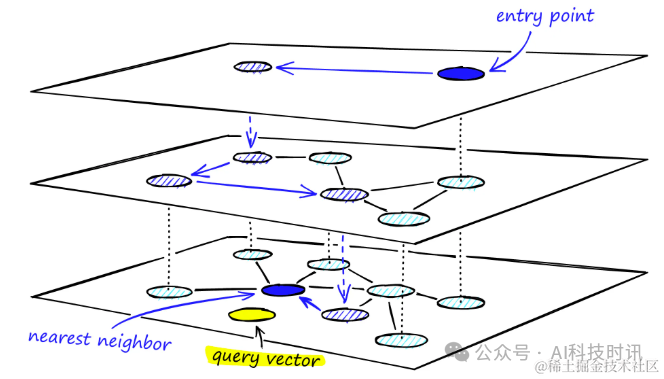
HNSW的基础
我们可以将ANN算法分为三个不同的类别;树、哈希和图。HNSW属于图类别。更具体地说,它是一个基于接近度的图,其中两个顶点根据它们的接近度(更接近的顶点被连接)连接------通常在欧几里得距离中定义。
从"接近度"图到"层次可导航的小世界"图的复杂度有显著的飞跃,将描述两种对HNSW贡献最大的基本技术:概率跳表和可导航的小世界图。
概率跳表
概率跳表由William Pugh在1990年引入,它结合了排序数组的快速搜索能力和链表的便捷插入操作。
跳表通过构建多个层的链表来工作。在最高层,链接能够跳过许多中间节点。在较低层,链接的"跳跃"数量逐渐减少。
要在跳表中进行搜索,从最高层开始,沿着边缘向右移动。如果发现当前节点的"键"大于目标键,表示已经超出目标,于是向下移动到下一层继续搜索。
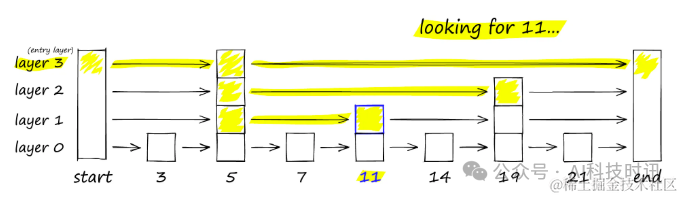
NSW: 可导航的小世界图
NSW: Navigable Small World Graphs
NSW是一种图结构,其中包含通过边连接到最近邻居的顶点。HNSW是对可导航小世界(NSW)图的进一步改进。
在NSW图中,每个节点(或称为顶点)都与若干其他节点相连,这些相连的节点被称为"朋友"。每个节点维护着一个朋友列表,共同构成了整个图的结构。
进行NSW图搜索时,搜索过程遵循以下步骤:
- 从预定义的起点出发:选择一个起点,该点与多个相邻节点相连。
- 局部邻近性识别:在这些相邻节点中,识别出与查询向量最为接近的一个节点。
- 逐步逼近目标:移动到该节点,并重复上述过程,逐步缩小搜索范围,直至找到最接近查询向量的节点。
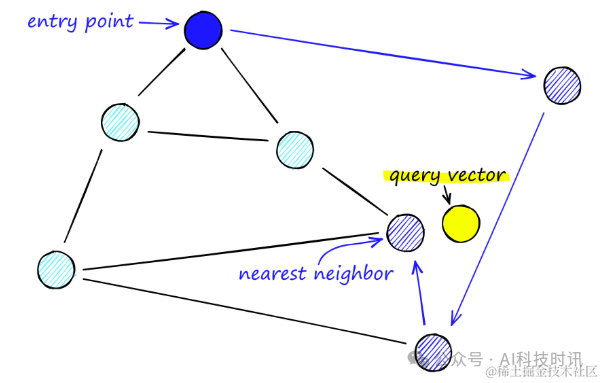
HNSW:分层导航小世界图
分层导航小世界图(Hierarchical Navigable Small World Graphs,简称HNSW)是可导航小世界图(NSW)的高级演变,它引入了概率跳表结构中的概率多层次概念。
HNSW通过向NSW添加层次化结构,创建一个在不同层级间具有不同链接长度的图。这种结构在最高层拥有最长的链接,在最低层则拥有最短的链接。
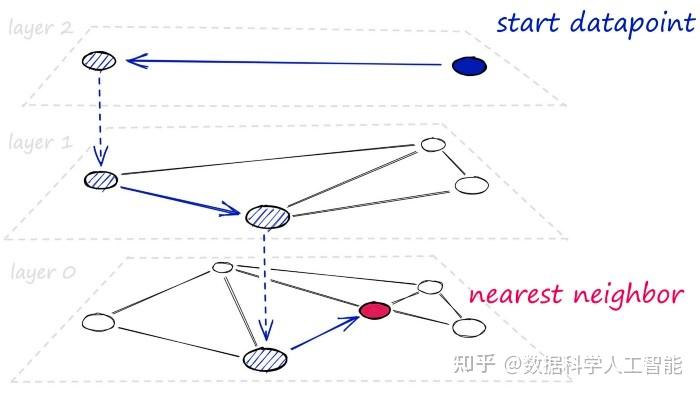
数据结构
- 多层图结构
- 每个节点连接有限邻居
- 高层稀疏,低层密集
从"接近度"图到"层次可导航的小世界"图的复杂度有显著的飞跃,将描述两种对HNSW贡献最大的基本技术:概率跳表和可导航的小世界图。
HNSW特点
| 维度 | 说明 |
|---|---|
| 算法全称 | HNSW(Hierarchical Navigable Small World) |
| 算法类型 | 近似最近邻搜索(ANN) |
| 核心思想 | 基于"小世界网络",通过多层图结构实现快速导航 |
| 图结构 | 分层图(Layered Graph) 高层稀疏、低层密集 |
| 节点连接 | 每个节点只连接有限数量的近邻(由 M 控制) |
| 索引结构特点 | 高层用于快速定位区域 底层用于精细搜索 |
| 搜索起点 | 最高层的入口节点 |
| 搜索策略 | 贪心搜索(Greedy Search)逐层下降 |
| 查询流程 | 高层快速收敛 → 逐层下探 → 底层精搜返回 TopK |
| 插入流程 | 新节点随机分配最高层级 → 自顶向下查找邻居 → 逐层建立连接 |
| 查询时间复杂度 | 近似 O(log N) |
| 插入时间复杂度 | 近似 O(log N) |
| 扩展能力 | 可支撑百万、千万级向量规模 |
| 精度特点 | 非 100% 精确,但可通过参数逼近精确结果 |
| 实时性 | 支持在线插入与查询 |
| 工程优势 | 查询稳定、延迟可控、适合在线系统 |
| 典型应用 | 语义缓存 向量数据库 RAG 粗排召回 |
| Redis 支持 | RediSearch Vector(HNSW) |
结构示意
Level 3: o────o
│
Level 2: o──o──o──o
│ │
Level 1: o─o─o─o─o─o3️⃣ 搜索流程
text
从最高层入口节点开始
↓
贪心搜索,快速接近目标区域
↓
逐层下降
↓
底层精搜,返回 TopKHNSW算法 参数含义
HNSW性能
在深入了解了HNSW(分层导航小世界图)的理论基础和Faiss库的实现细节后,现在转向评估不同参数对HNSW索引性能的具体影响。将重点分析召回率、搜索时间、构建时间以及内存使用情况。
将调整以下三个关键参数:M、efSearch和efConstruction,并在Sift1M数据集上测试它们的影响。
- M 控制每个节点的最大连接数量,影响图的密度和搜索精度。
- efSearch 控制查询过程中候选列表的大小,影响查询时间和精度。
- efConstruction 控制索引构建过程中候选列表的大小,影响索引构建时间和质量。
| 参数 | 含义 | 作用阶段 | 调大后的影响 | 常见取值 |
|---|---|---|---|---|
| M | 每个节点的最大邻居数 | 构建 | 精度 ↑,内存 ↑,构建变慢 | 8 / 16 / 32 |
| EF_CONSTRUCTION | 构建阶段候选集大小 | 构建 | 索引质量 ↑,构建时间 ↑ | 100 ~ 400 |
| EF_RUNTIME(EF_SEARCH) | 查询阶段候选集大小 | 查询 | 召回率 ↑,查询延迟 ↑ | 20 ~ 100 |
| K | 返回的最近邻数量 | 查询 | 结果更多,后处理成本 ↑ | 1 ~ 20 |
五、Redis 语义缓存整体架构
┌────────────┐
User Query → │ Embedding │
└─────┬──────┘
│
┌─────▼──────┐
│ Redis ANN │
│ HNSW │
└─────┬──────┘
hit? │ miss
│ ▼
┌────▼───┐ LLM
│ Answer │ ↓
└────────┘ 写入缓存七、Go 语言实现语义缓存(工程示例)
7.0 创建索引(Redis Stack)
bash
FT.CREATE semantic_cache
ON HASH
PREFIX 1 "qa:"
SCHEMA
question VECTOR HNSW 768 TYPE FLOAT32 DISTANCE_METRIC COSINE
answer TEXT7.1 数据结构设计
go
type CacheItem struct {
ID string
Vector []float32
Question string
Answer string
}7.2 向量写入 Redis
go
func Store(ctx context.Context, rdb *redis.Client, item CacheItem) error {
vecBytes := floatsToBytes(item.Vector)
key := "qa:" + item.ID
return rdb.HSet(ctx, key, map[string]interface{}{
"question": item.Question,
"answer": item.Answer,
"vector": vecBytes,
}).Err()
}
go
func floatsToBytes(vec []float32) []byte {
buf := new(bytes.Buffer)
for _, v := range vec {
_ = binary.Write(buf, binary.LittleEndian, v)
}
return buf.Bytes()
}7.3 向量检索(KNN)
go
func Search(ctx context.Context, rdb *redis.Client, vector []float32) (string, float64, error) {
vecBytes := floatsToBytes(vector)
cmd := []interface{}{
"FT.SEARCH", "semantic_cache",
"*=>[KNN 1 @question $vec AS score]",
"PARAMS", 2, "vec", vecBytes,
"SORTBY", "score",
"RETURN", 2, "answer", "score",
"DIALECT", 2,
}
res, err := rdb.Do(ctx, cmd...).Result()
if err != nil {
return "", 0, err
}
// 解析结果(略)
return answer, score, nil
}7.4 命中策略(工程关键)
go
const HitThreshold = 0.85
if score >= HitThreshold {
return cachedAnswer
}
// fallback to LLM实践经验:
- 技术问答:0.85~0.9
- 闲聊类:0.75~0.8
- 汽修 / 医疗:宁高勿低
八、语义缓存 vs 向量数据库
| 维度 | Redis 语义缓存 | 专用向量库 |
|---|---|---|
| 延迟 | 极低(<5ms) | 中 |
| 数据规模 | 百万级 | 千万~亿 |
| 事务 | 支持 | 弱 |
| 运维 | 简单 | 偏复杂 |
| 适合场景 | 热问题 | 冷知识 |
结论:
Redis 语义缓存 ≠ 向量数据库
它是 RAG 架构里的第一层"语义 L1 Cache"
九、常见工程坑
向量版本漂移:
embedding 模型升级 → 缓存需失效,或者维护embedding模型版本。
缓存污染:
低质量回答进入缓存
阈值静态:
不同业务应动态调整
并发写入:
建议异步写缓存
命中率忽高忽低/相同问题结果不稳定
原因 90% 是:
text
EF_RUNTIME 太小EF_RUNTIME 是 HNSW 算法的一个关键参数,它控制查询时的搜索精度与延迟之间的权衡。 查询阶段 EF 小,等于"搜索半途就停了"