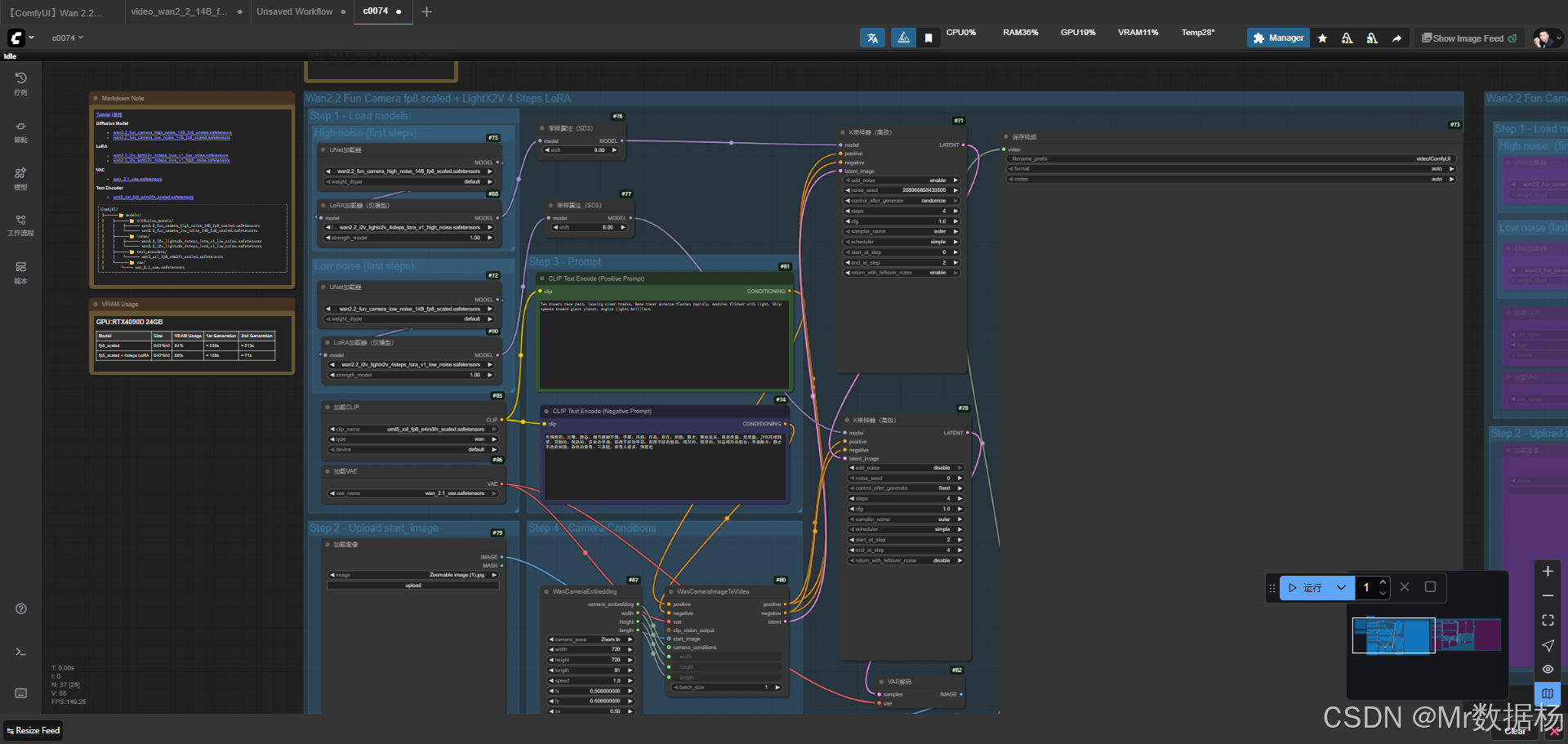
今天展示的案例是一个基于 Wan2.2 相机模型的 ComfyUI 图生视频工作流,它能够将静态图像转换为具有镜头感的视频片段。整个流程通过加载高噪声与低噪声的扩散模型、结合 LoRA 插件进行轻量化推理,再配合 CLIP 文本编码、相机条件控制与多阶段采样,生成具有强烈动态表现的短视频。通过对比不同噪声水平与推理路径,读者能直观感受到 ComfyUI 在视频生成方面的表现力与灵活性。
文章目录
- 工作流介绍
- 工作流程
- 大模型应用
-
- [CLIPTextEncode(Positive Prompt) 场景与镜头语义驱动编码](#CLIPTextEncode(Positive Prompt) 场景与镜头语义驱动编码)
- [CLIPTextEncode(Negative Prompt) 杂质抑制与质量控制编码](#CLIPTextEncode(Negative Prompt) 杂质抑制与质量控制编码)
- [WanCameraImageToVideo 镜头运动 + 图像到视频的多维生成控制](#WanCameraImageToVideo 镜头运动 + 图像到视频的多维生成控制)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
该工作流的目标是利用 Wan2.2 系列扩散模型 配合 相机嵌入条件控制,实现从单张图像扩展到动态视频的生成效果。模型加载部分涵盖高噪声与低噪声的两种版本,并在推理时可灵活调用 LoRA 插件以缩短生成时间。配合 CLIP 文本编码对提示词的正负面约束,以及 VAE 负责潜变量的编码解码,最终生成的视频通过 CreateVideo 与 SaveVideo 节点完成拼接与输出,整体流程层次清晰,便于理解与扩展。
核心模型
工作流中涉及的核心模型包含扩散模型、LoRA、VAE 与文本编码器。扩散模型分为高噪声和低噪声两个版本,分别适用于不同阶段的采样,保证视频既有细节表现也具备动态流畅度。LoRA 模型提供了轻量化的快速生成方案,在牺牲部分动态性的同时显著缩短计算时间。VAE 用于潜变量与图像间的转换,保持生成结果的稳定性,而文本编码器则负责解析提示词,保证正负面约束在视频生成过程中有效传递。
| 模型名称 | 说明 |
|---|---|
| wan2.2_fun_camera_high_noise_14B_fp8_scaled.safetensors | 高噪声扩散模型,用于前期推理,强调细节与动态感 |
| wan2.2_fun_camera_low_noise_14B_fp8_scaled.safetensors | 低噪声扩散模型,用于后期收敛,保证清晰度与稳定性 |
| wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors | 低噪声 LoRA 模型,减少动态表现但提升生成速度 |
| wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors | 高噪声 LoRA 模型,结合前期采样优化推理效率 |
| wan_2.1_vae.safetensors | VAE 模型,负责潜变量与图像间的双向转换 |
| umt5_xxl_fp8_e4m3fn_scaled.safetensors | 文本编码器,解析正负提示词并传递至扩散模型 |
Node节点
在节点设计上,工作流覆盖了从输入到输出的完整链路。LoadImage 节点导入初始图像,WanCameraEmbedding 节点注入镜头运动条件,使生成过程具备类似真实摄影机的动态效果。CLIPTextEncode 节点负责正负面提示的文本向量化,并与扩散模型进行条件融合。多阶段的 KSamplerAdvanced 节点用于采样迭代,结合高噪声与低噪声模型逐步收敛结果。VAELoader 与 VAEDecode 节点实现潜变量与图像的往返映射,保证生成内容的还原度。最后,通过 CreateVideo 与 SaveVideo 节点完成帧序列的合成与导出。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入图像作为视频生成的起点 |
| WanCameraEmbedding | 设置相机运动条件,实现缩放、移动等动态效果 |
| CLIPTextEncode | 将正负面提示词转化为条件向量 |
| UNETLoader | 加载高噪声与低噪声扩散模型 |
| LoraLoaderModelOnly | 挂载 LoRA 模型,实现快速推理 |
| KSamplerAdvanced | 多阶段采样器,逐步收敛潜变量 |
| VAELoader / VAEDecode | 潜变量与图像的相互转换 |
| CreateVideo | 将图像帧序列合成为视频 |
| SaveVideo | 保存生成的视频文件 |
工作流程
该工作流的运行逻辑以"加载---采样---合成---保存"为主线,从模型与输入图像的准备,到条件控制的注入,再到潜变量的迭代采样与视频输出,形成了完整的生成链路。前期通过高噪声扩散模型与正负面提示词的融合,保证了画面具有充足的动态张力;中期利用低噪声模型逐步收敛结果,使细节更清晰;在此过程中,相机嵌入节点发挥了关键作用,为生成过程提供了类似真实摄影的运动感。最终,潜变量被解码为图像帧,通过视频拼接节点合成为连贯的视频片段,并在保存节点完成导出。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型与输入加载 | 导入高噪声与低噪声扩散模型,挂载 VAE 与文本编码器,同时载入初始图像 | UNETLoader, VAELoader, CLIPLoader, LoadImage |
| 2 | 相机条件注入 | 设置镜头参数,控制视频生成的缩放与运动效果 | WanCameraEmbedding |
| 3 | 提示词解析 | 将正负提示词向量化,传递给扩散模型作为生成约束 | CLIPTextEncode |
| 4 | 高噪声阶段采样 | 使用高噪声扩散模型进行初步推理,生成动态潜变量 | KSamplerAdvanced, ModelSamplingSD3 |
| 5 | 低噪声阶段收敛 | 切换至低噪声模型,细化与稳定画面细节 | KSamplerAdvanced, ModelSamplingSD3 |
| 6 | 潜变量解码 | 将潜变量转化为图像帧序列,保证图像稳定性与还原度 | VAEDecode |
| 7 | 视频合成与保存 | 将帧序列拼接为视频文件并完成输出 | CreateVideo, SaveVideo |
大模型应用
CLIPTextEncode(Positive Prompt) 场景与镜头语义驱动编码
该节点负责将用户输入的正向 Prompt 进行语义编码,为视频生成提供「场景描述、镜头动作、光线变化、物体行为等」语义控制核心。模型根据 Prompt 决定视频整体风格、动作趋势与镜头节奏。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode(Positive Prompt) | Two rovers race past, leaving clear tracks. Base tower antenna flashes rapidly, modules flicker with light. Ship speeds toward giant planet, engine lights brilliant. | 将正向文本转化为语义向量,用于决定视频的画面内容、动作趋势、镜头动势与光影变化。Prompt 是控制最终生成画面最关键的因素。 |
CLIPTextEncode(Negative Prompt) 杂质抑制与质量控制编码
用于在视频生成过程中抑制不希望出现的缺陷,如形变、噪点、伪影、曝光问题等。负向 Prompt 影响生成质量的稳定性,使视频画面更干净连贯。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CLIPTextEncode(Negative Prompt) | 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走 | 负向 Prompt 编码模型的「禁止项」,用于强力压制画面劣化细节,增强形体稳定性,提高视频在多帧连续下的视觉一致性。 |
WanCameraImageToVideo 镜头运动 + 图像到视频的多维生成控制
这是本工作流的核心大模型节点,负责从图片生成连续视频,融合 Prompt、相机轨迹、起始图像与模型推理能力。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| WanCameraImageToVideo | (正向与负向 Prompt 共同作用) | 综合处理 CLIP 文本语义、初始图片、相机轨迹嵌入,输出可进一步采样的初始 latent,用于驱动图像→视频的时间序列生成。Prompt 决定画面叙事,而镜头条件决定运动方式。 |
使用方法
该工作流可根据一张起始图像自动生成带有镜头运动的视频。用户加载模型、设置 LoRA、输入 Prompt、上传起始图像,再选择相机运动模式(如 Zoom in / Static),最终由多段采样器和 VAE 解码输出完整视频。
只需更换原图或 Prompt,系统就会根据设定的镜头模式与语义内容自动生成完整动态视频。起始图像负责视觉主体,Prompt 控制叙事方向,相机嵌入控制镜头运动,而模型链路负责视频的连续性与清晰度。
| 注意点 | 说明 |
|---|---|
| Prompt 控制最核心 | 明确描述动作、镜头、光线、主体细节,可显著提升视频一致性与语义准确度 |
| 负向 Prompt 必填 | 强烈建议加入形体控制与质量类负向词,避免多帧中的错位、畸变 |
| 起始图像质量越高越好 | 直接影响生成主体的细节与稳定性 |
| 镜头模式影响视频风格 | Zoom in / Static 等直接决定镜头运动方式与整体观看体验 |
| LoRA 可提升光照或动作表现 | 但可能降低动态连续性,按需要选择启用 |
| 高噪声 → 低噪声两阶段采样 | 生成更顺滑、帧间稳定的结果 |
| 分辨率与长度需合理 | 832×480 / 81 帧为默认稳定配置,过大可能导致显存不足 |
应用场景
该工作流的设计既适用于创意类短视频生成,也能在科研与实验场景中作为动态图像生成的参考。对于数字艺术创作者来说,可以将静态插画快速转换为具有镜头感的动态视频,提升作品的表现力。影视与游戏行业能够利用这一流程快速验证分镜与镜头运动效果,在前期概念设计阶段降低制作成本。教育与科研领域则可借助此类工作流研究扩散模型在视频合成中的动态表现力,为后续的 AI 视频生成研究提供实验范式。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 数字艺术创作 | 将静态画面转化为动态短片 | 插画师、独立艺术家 | 单帧插画生成镜头感视频 | 增强作品的表现力与沉浸感 |
| 影视预演设计 | 快速验证镜头语言与分镜节奏 | 导演、动画设计师 | 概念分镜或场景草图 | 节省前期验证成本 |
| 游戏原画与CG | 演示角色与场景的动态效果 | 游戏设计师、CG 艺术家 | 游戏原画或 CG 场景图像 | 模拟镜头运动与场景氛围 |
| 教育与科研 | 探索视频生成算法的表现力 | 教师、研究人员 | 实验数据与图像素材 | 用于研究 AI 视频生成技术 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用