CASS
3.2. Spectral Object-Level Context Distillation
CLIP对象级定位能力弱, VFM(DINO)强
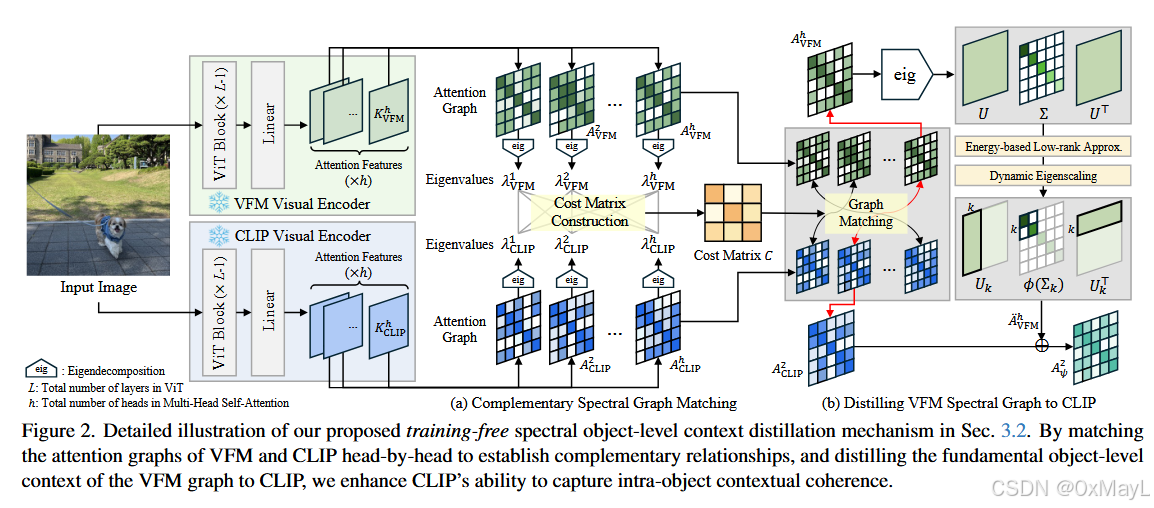
将VFM的注意力图蒸馏给CLIP
1.首先匹配合适的头,使用特征值+匈牙利匹配算法 。
2.对于VFM的注意力图,还需要使用特征值分解 的方式获得最重要的注意力矩阵(而不是完整的矩阵)
3.使用W距离函数进行互补 修正。距离远的权重大,距离近的权重小。
3.3. Object Presence-Driven Object-Level Context
同一对象的多个部分容易被分配到相似类别
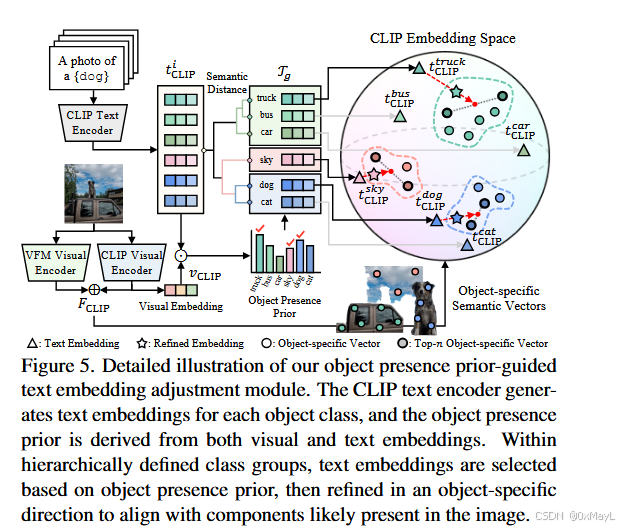
作者使用CLIP CLS token 和定义的类别集进行匹配和分组。
对分组中最有可能出现的文本嵌入进行修正
最后利用最有可能出现的CLIP分割掩膜进行类别分布修正。
下面是对论文 Distilling Spectral Graph for Object-Context Aware Open-Vocabulary Semantic Segmentation (CASS)的"方法部分深读式"解析,按你给的框架组织,并尽量把每一步 输入→处理→输出 讲清楚。
0. 摘要翻译(忠实直译+少量顺句)
开放词表语义分割(OVSS)随着近期视觉-语言模型(VLMs)的发展取得进展,使得模型能够通过多种学习范式对超出预定义类别的目标进行分割。尤其是免训练(training-free)方法,因其可扩展、易部署,能够处理未见数据(这正是 OVSS 的关键目标),而受到关注。然而,一个关键问题仍然存在:当基于任意查询提示词在具有挑战的 OVSS 环境中分割复杂物体时,现有方法缺乏对"物体级上下文(object-level context)"的考虑。这种忽视限制了模型将同一物体内部语义一致的元素聚合在一起,并精确映射到用户定义的任意类别的能力。
本文提出一种新方法,通过在图像中引入物体级上下文知识来克服该问题。具体而言,我们将由谱方法驱动的特征 从视觉基础模型(VFM)蒸馏到视觉编码器的注意力机制中,以增强物体内部一致性,使语义连贯的组件形成单一物体掩码。此外,我们利用零样本的物体存在概率来细化文本嵌入,从而更准确地与图像中出现的特定物体对齐。通过引入物体级上下文知识,我们的方法在多个数据集上实现了 SOTA 的免训练 OVSS 性能,并具有很强的泛化能力。
1. 方法动机
1a) 为什么提出这个方法(驱动力)
论文抓住一个非常具体但常被忽视的痛点:training-free OVSS 的分割结果往往"碎"------同一物体的不同组成部分(车轮/车身、羊腿/羊身等)不能稳定被聚合成一个统一的类别区域(Fig.1(b) 的 truck/sheep 例子)。作者认为这不是简单的后处理能解决的,而是"模型内部缺少物体级上下文建模"。
1b) 现有方法痛点/不足(更具体)
论文把 training-free OVSS 现有路线大致归为"改 CLIP 的 patch 相关性/注意力结构,但仍主要受限于 CLIP 的全局语义学习目标":
- CLIP 的视觉编码器训练时更强调 CLS 与文本对齐 ,对密集预测关键的 patch-to-patch 空间交互不足(所以很多工作会改最后一层 self-attention)。
- NACLIP / SCLIP 等主要做"局部平滑/相关性增强",ProxyCLIP 会引入 DINO 的 patch 特征,但作者认为:这些仍缺"显式的物体级结构",容易出现"一个物体被分到多个相近类别/局部区域被误分"。
1c) 研究假设/直觉(一句话版)
VFM 的注意力图经过谱分解能揭示物体级结构;把这种"低秩的物体结构"蒸馏进 CLIP 的注意力,同时用 CLIP 的零样本"物体存在先验"约束文本与相似度,就能让同一物体的组成部分更一致地聚合并正确对齐到用户提示词。
2. 方法设计(重点:非常细的 pipeline)
整体两大模块:
(A) 谱驱动的 VFM→CLIP 物体级上下文蒸馏(Sec.3.2) + (B) 物体存在先验驱动的文本/相似度修正(Sec.3.3)。
2a) 详细 Pipeline:输入→处理→输出
Step 0:输入与窗口推理(sliding window)
- 输入整图 (I)。为保证 ViT 能看到细节,作者用 sliding window:将 (I) 切成多个窗口 (\hat I),每个窗口大小 (224\times224),stride 112;短边 resize 到 336(Cityscapes 用 560)。
- 对每个窗口单独做后续计算,最后把窗口结果拼回整图的 segmentation map。
Step 1:CLIP patch 特征提取(并"改造最后一层"以适配分割)
-
CLIP ViT 的最后 block,作者去掉 residual/FFN/最后 self-attn(按 NACLIP/SCLIP 的做法),只保留类似:
- 先 LN,再 Self-Attention 得到 ({Z}^*)(Eq.(1))。
-
由最后一层 self-attn 的 key 得到每个 head 的注意力"邻接图":
A\^i_{\\text{CLIP}} = K^i_{\\text{CLIP}}(K^i_{\\text{CLIP}})\^\\top \\in \\mathbb{R}\^{N\\times N}
这里 (N) 是 patch 数(不含 CLS)。
-
patch token 通过投影矩阵 (P_{\text{CLIP}}) 到 CLIP 对齐空间得到 (F_{\text{CLIP}}\in\mathbb{R}^{N\times d}),与文本 embedding 做 patch-text 相似度(Eq.(4)):
\\hat S = F_{\\text{CLIP}}\\cdot \[t^i_{\\text{CLIP}}\]^\\top \\in\\mathbb{R}\^{N\\times C}
这就是"基础版"training-free OVSS 的 logit。
到这里为止,还是传统 CLIP-based training-free OVSS:CLIP patch 表征 + 文本对齐。
模块 A:谱蒸馏,把 VFM 的"物体级结构"灌进 CLIP 注意力
Step 2:构图:用 VFM 的注意力 key 得到 VFM 图
- 取 VFM(DINO ViT-B/8)某层的注意力 key:(K_{\text{VFM}})(按 head 存)。
- 每个 head 构造邻接图:
A\^i_{\\text{VFM}} = K^i_{\\text{VFM}}(K^i_{\\text{VFM}})\^\\top \\in \\mathbb{R}\^{N\\times N}
- 直觉:VFM attention graph 捕捉了更细粒度的 patch 语义关系,但要把它变成"物体级上下文",需要谱工具提炼结构。
Step 3:多头对齐(关键点):Complementary Spectral Graph Matching
问题:VFM 和 CLIP 都是 multi-head attention,不同 head 看不同区域;不能简单 i=j 对齐。
做法(Fig.2(a), Sec.3.2.1):
-
对每个 head 的图做特征:谱(eigenvalues)
- 对每个 (A^i_{\text{VFM}}) 和 (A^j_{\text{CLIP}}) 做 eigendecomposition,取 top-m eigenvalues,归一化得到 (\bar\lambda^i)。
-
用谱分布距离建代价矩阵
- 代价:
C_{ij} = 1 - D_W(\\bar\\lambda\^i_{\\text{VFM}}, \\bar\\lambda\^j_{\\text{CLIP}})
(D_W) 是 Wasserstein 距离(对排序后的特征逐项差的和)。
- 代价:
-
Hungarian 算法匹配 head
- 在 (h\times h) 的代价矩阵上做匈牙利匹配,得到 VFM-head 与 CLIP-head 的一一对应。
作者强调用"互补(complementary)"结构匹配:让 VFM 提供 CLIP 缺的物体结构(Fig.4)。
- 在 (h\times h) 的代价矩阵上做匈牙利匹配,得到 VFM-head 与 CLIP-head 的一一对应。
Step 4:VFM 图的低秩提炼 + 动态特征强化(Low-Rank + Dynamic Eigenscaling)
核心想法:直接把 (A_{\text{VFM}}) 加到 (A_{\text{CLIP}}) 会引入噪声;应该只蒸馏"物体级主结构",作者用 低秩谱分量表示。
-
低秩近似(能量阈值自适应选 k)
A\^i_{\\text{VFM}} = U\\Sigma U\^\\top,\\quad \\tilde A\^i_{\\text{VFM}} = U_k\\Sigma_k U_k\^\\top
(k) 不是固定的,而是用"累计能量占比 ≥ η"的方式按图像自适应选(补充材料 Algorithm 1)。
-
动态特征缩放(Dynamic Eigenscaling)
对 (\Sigma_k) 施加 (\phi):放大大特征值、压小小特征值,从而强调主结构、抑制噪声,得到:
\\ddot A\^i_{\\text{VFM}} = U_k\\phi(\\Sigma_k)U_k\^\\top
补充材料给了 (\phi) 的具体形式与超参((\epsilon=1.5))。
Fig.3 显示:不做 low-rank 时 attention 仍比较散;做了 low-rank+dynamic scaling 后,attention 更像"一个物体一团"。
Step 5:蒸馏到 CLIP:生成新的注意力 (A_\psi)
对匹配到的一对 head(VFM 的 i ↔ CLIP 的 j),用 Wasserstein 距离当"互补性权重"融合:
A\^j_{\\psi}=\\frac{w_{ij}\\ddot A\^i_{\\text{VFM}} + A\^j_{\\text{CLIP}}}{w_{ij}+1}
其中 (w_{ij}=D_W(\bar\lambdai_{\text{VFM}},\bar\lambdaj_{\text{CLIP}}))。直觉:谱差异越大越互补 → 给 VFM 分量更高权重;相似则少融合。
最后用 (A_\psi) 替换原来的 (A_{\text{CLIP}}) 去算 self-attn(替换 Eq.(2) 中 softmax 的注意力)。
模块 B:物体存在先验(Object Presence Prior)驱动文本与相似度修正
Step 6:计算"物体存在先验" (P(i))(CLIP 全图 CLS 做零样本分类)
- 取整图 (I) 的 CLIP 视觉全局向量(CLS token)(v_{\text{CLIP}}=Fv_{\text{CLIP}}(I)\in\mathbb{R}d)。
- 对每个类别文本 embedding (t^i_{\text{CLIP}})(由模板集平均得到,补充材料 Sec.9.1),算:
P(i)= t\^i_{\\text{CLIP}}\\cdot v_{\\text{CLIP}}
这就是"这张图里类 i 可能出现"的先验分数。
Step 7:OTA 文本嵌入调整(Object-Guided Text Embedding Adjustment)
目标:解决"同一物体部件被分到相近类别"的问题(如 motorbike vs bicycle)。
做法(Fig.5 + Sec.3.3):
- 先把所有类别文本 embedding 做层次聚类,以"语义相近的类"成组(补充材料 Algorithm 2:cosine distance + Ward linkage + 阈值)。
- 对每一组 (T_g),用先验选出最可能出现的类:
i\^\*=\\arg\\max_{i\\in I_g}P(i)
- 用 patch 视觉特征里"最像该类"的 top-n patch 向量平均得到方向 (\mu_n),把该类的文本 embedding 往 (\mu_n) 拉:
\\tilde t^{i^*}_{\\text{CLIP}}=(1-\\alpha)t^{i^* }_{\\text{CLIP}}+\\alpha\\mu_n
只替换组内最可能出现的那个文本向量,让它更"物体特定"。
Step 8:OPS 相似度修正(Object Perspective Patch-Text Similarity)
把 patch-text logit (\hat S) 与 "全图先验"融合成 (\hat S^*):
\\hat S\^* =(1-\\gamma)\\hat S+\\gamma,\[t\^i_{\\text{CLIP}}\]v_{\\text{CLIP}}
注意作者强调:这里先验来自 整图 I,而不是窗口 (\hat I),更符合"物体级上下文"。
Step 9:输出
- 对每个窗口得到 (\hat S^*)(N×C),reshape 回窗口空间 → 得到窗口分割。
- 多窗口拼回整图,得到最终 segmentation map。
2b) 模块结构与协同(你可以把它当"训练-free OVSS 的两条腿")
- 腿1(视觉侧):VFM 的谱结构 → 蒸馏进 CLIP 的注意力 → patch 之间更"像一个物体"地聚合(mask 更整)。
- 腿2(语言/决策侧):CLIP 全图先验 → 修正文本 embedding(OTA)与相似度(OPS)→ 减少"部件被分到相近类"的错配。
2c) 关键公式/算法的通俗解释(抓住角色)
- 谱分解(eigenvalues):把"图的结构指纹"提出来;不同 head 的注意力图结构不同,用谱指纹才能做 head 匹配。
- Wasserstein 距离:衡量两个谱分布"形状差异";差异大意味着 head 关注结构互补,融合更有价值。
- 低秩近似:只保留图里解释大部分能量的主结构(更像"物体轮廓/组织结构"),丢掉噪声。
- 匈牙利匹配:在所有 head 配对里找全局最优的一一匹配,避免随便对齐。
- Object presence prior:CLIP 最擅长的零样本分类能力,用来告诉分割"这一张图到底更像有哪些类"。
3. 与其他方法对比
3a) 本质不同点
- NACLIP / SCLIP:主要在 CLIP 内部做 attention/相关性改造以提升空间一致性,但仍在 CLIP 表征能力边界内。
- ProxyCLIP:引入 DINO 的 patch 特征增强一致性,但更偏"特征融合/代理注意力",并不显式把"物体级结构"作为图结构蒸馏进 CLIP 注意力。
- CASS :把 VFM attention 当 图 ,用 谱方法抽取"物体级结构低秩主成分",并且解决了多头对齐(head matching)这个细节,然后蒸馏回 CLIP attention(从机制上强化 intra-object coherence)。
3b) 创新点/贡献(明确列点)
- Complementary Spectral Graph Matching:用谱分布 + Hungarian 做 head 对齐,并强调"互补匹配"。
- Energy-based low-rank + Dynamic Eigenscaling:自适应选 k 的低秩提炼 + 动态特征缩放,提纯 VFM 图的物体结构再蒸馏。
- Object presence prior 驱动的 OTA+OPS:把 CLIP 的强项(零样本分类先验)用来修正文本 embedding 和 patch-text logits,减少部件到近义类的错配。
3c) 更适用的场景(适用范围)
- 更适合:物体由多个部件组成、需要"同一物体整体一致"的场景(车辆、人、动物等),尤其是 VOC 这种大物体类别更明显。论文也在讨论里说对大物体收益更大。
- 相对不占优:小物体密集的数据集(如 ADE、COCO)提升相对更有限,作者在限制里明确提到对小物体可能欠佳。
3d) 表格对比(优缺点/改进点)
| 方法 | 核心手段 | 优点 | 缺点/风险 | CASS 相比它的改进点 |
|---|---|---|---|---|
| NACLIP | CLIP attention 邻域平滑/一致性增强 | 简洁、免训练、稳 | 物体部件仍易碎裂、缺物体级结构 | 用 VFM 谱结构蒸馏让"一个物体更像一个整体" |
| SCLIP | 自注意力相关性重建以适配 dense | 改善 patch 相关性 | 仍受 CLIP 语义粒度限制 | 引入 VFM 图结构 + 先验修正文本/相似度 |
| ProxyCLIP | 引入 DINO 的 patch-level 一致特征 | 通常比纯 CLIP 更强 | 更偏特征层融合,不一定形成"物体级组织结构" | 把 attention graph 的低秩物体结构灌进 CLIP attention(机制更直接) |
| LaVG | 谱/图划分思路做 OVSS(同属谱系) | 谱方法有效 | 不一定能保持文本对齐的核心需求 | CASS 选择"蒸馏进 CLIP"而不是直接谱聚类输出,保持 VLM 对齐优势 |
4. 实验表现与优势
4a) 如何验证有效性(实验设置)
- Backbone:CLIP ViT-B/16;VFM 用 DINO ViT-B/8,均冻结。
- 推理:resize + sliding window(224/stride112),不使用 PAMR/DenseCRF 做后处理以保证公平。
- 指标:mIoU 为主,pAcc 辅助。
4b) 关键数据(代表性结论)
- 8 个数据集平均:CASS Avg mIoU = 44.4 ,相比 ProxyCLIP 的 41.4,提升 +3.0 mIoU(Table 1)。
- 在 V20(VOC 去背景)上,CASS 87.8,ProxyCLIP 78.2,提升 +9.6 mIoU;论文文字强调"相对第二名 +5.3 mIoU",对应其比较口径(Table 1 + 文本)。
- pAcc:CASS 平均 68.9 ,ProxyCLIP 66.7,提升 +2.2 pAcc(Table 2)。
4c) 哪些场景优势最明显(证据)
- 质化(Fig.6/7):车轮、人体四肢等细长/零碎部件更容易被统一进同一类 mask,而不是散到背景或相近类。
- 论文讨论明确:对大物体收益更强;在 VOC(大而清晰类)提升更显著。
4d) 局限性(论文承认/隐含)
- 算力/速度:eigendecomposition 仍重;Hungarian 在 CPU 上跑带来额外延迟;作者报告 5.6 FPS(RTX A6000)不足实时(Sec.11.1)。
- 小物体:强调物体级上下文对大物体更友好,小物体可能相对弱,导致在 ADE/COCO 这类小物体丰富数据集上整体提升更有限(Sec.11.1)。
5. 学习与应用(复现建议)
5a) 是否开源
论文首页写了 Project Page(含代码/材料线索):https://micv-yonsei.github.io/cass/(文中给出)。是否完整开源需你点项目页确认,但论文至少提供了项目入口。
5b) 复现关键步骤(按工程优先级)
-
搭好 baseline 推理框架:resize + sliding window + CLIP patch-text logits(Eq.4)。
-
实现 CLIP 最后一层改造:按文中移除 residual/FFN/最后 self-attn 的做法,确保拿到合适的 patch token 与 attention key。
-
构建 VFM/CLIP attention graph(建议先用 KK 组合):补充材料 Table 7 显示 KK 表现最好。
-
谱匹配与蒸馏:
- eigendecomposition → eigenvalues → Wasserstein cost → Hungarian matching → energy-based 选 k → dynamic eigenscaling → Eq.(7) 融合。
-
先验模块(OTA+OPS):
- CLS 先验 (P(i)) → 类别文本层次聚类 → OTA(Eq.8)→ OPS(Eq.9)。
5c) 超参数/细节提醒
-
(\alpha,\gamma) 是关键:论文按数据集给了表(补充材料 Table 11)。(\alpha) 控 OTA 拉近程度,(\gamma) 控先验融合强度。
-
低秩 rank k:建议复现作者的 energy-based 自适应(Algorithm 1),固定 k 的性能更差(Table 9)。
-
速度优化方向:
- eigendecomposition 可尝试更快的近似/低秩求解;Hungarian 的 CPU 瓶颈是作者明确的未来工作点。
5d) 能否迁移到其他任务
可以,且论文给了应用例子:用更"整"的 object mask 做 inpainting / object removal (Sec.10.1, Fig.9)。
更一般地,你可以把它当成一个"免训练的 object-level mask 生成器",可迁移到:
- 交互式编辑(先分割再编辑)
- 开放词表目标提取/检索
- 作为下游实例分割/检测的 proposal(但注意它是语义分割输出,未必天然区分同类多实例)
6. 总结
6a) 20字内核心思想
谱提纯物体结构,蒸馏进CLIP注意力。
6b) 速记版 pipeline(3--5步,尽量不用论文术语)
- 用两套模型各自算出"区域之间的关联图"。
- 找到两套关联图里最互补的对应关系。
- 从更强那套图里提取"最主要的结构",再融合进另一套图。
- 用整图判断"更可能有哪些类",据此修正类别表示与像素打分。
- 拼回整图得到最终分割。
如果你接下来想进一步"吃透方法",我建议你挑一个最小可运行的推导点:从 Eq.(7) 的蒸馏开始(先假设 head 已匹配、k 已给定),看它如何改变 CLIP 注意力,再接 OTA/OPS;这样最容易把"为什么能更像一个物体"建立直觉。