【前瞻创想】Kurator·云原生实战派:打造下一代分布式云原生基础设施
- 【前瞻创想】Kurator·云原生实战派:打造下一代分布式云原生基础设施
-
- 摘要
- [1. Kurator框架全景解析](#1. Kurator框架全景解析)
-
- [1.1 什么是Kurator:分布式云原生平台的定义](#1.1 什么是Kurator:分布式云原生平台的定义)
- [1.2 核心架构设计理念](#1.2 核心架构设计理念)
- [1.3 与传统云原生平台的差异化优势](#1.3 与传统云原生平台的差异化优势)
- [2. 环境搭建与核心组件安装](#2. 环境搭建与核心组件安装)
-
- [2.1 前置条件与环境准备](#2.1 前置条件与环境准备)
- [2.2 从GitHub克隆Kurator源码详解](#2.2 从GitHub克隆Kurator源码详解)
- [2.3 安装流程与关键配置参数](#2.3 安装流程与关键配置参数)
- [2.4 验证安装与基础功能测试](#2.4 验证安装与基础功能测试)
- [3. Fleet舰队管理:统一多集群治理的艺术](#3. Fleet舰队管理:统一多集群治理的艺术)
-
- [3.1 Fleet概念与设计哲学](#3.1 Fleet概念与设计哲学)
- [3.2 集群注册与生命周期管理](#3.2 集群注册与生命周期管理)
- [3.3 Fleet队列中的命名空间相同性实现](#3.3 Fleet队列中的命名空间相同性实现)
- [3.4 跨集群服务发现与通信机制](#3.4 跨集群服务发现与通信机制)
- [4. Karmada集成实践:跨集群应用调度与弹性伸缩](#4. Karmada集成实践:跨集群应用调度与弹性伸缩)
-
- [4.1 Karmada核心架构与Kurator集成点](#4.1 Karmada核心架构与Kurator集成点)
- [4.2 应用跨集群分发策略配置](#4.2 应用跨集群分发策略配置)
- [4.3 基于负载的跨集群弹性伸缩实践](#4.3 基于负载的跨集群弹性伸缩实践)
- [4.4 故障转移与高可用性保障](#4.4 故障转移与高可用性保障)
- [5. KubeEdge边缘计算:云边协同新范式](#5. KubeEdge边缘计算:云边协同新范式)
-
- [5.1 KubeEdge架构解析与核心组件](#5.1 KubeEdge架构解析与核心组件)
- [5.2 云边资源统一纳管实践](#5.2 云边资源统一纳管实践)
- [5.3 边缘节点管理与应用部署](#5.3 边缘节点管理与应用部署)
- [5.4 边缘-云网络连通性与隧道机制](#5.4 边缘-云网络连通性与隧道机制)
- [6. GitOps实践:FluxCD驱动的持续交付](#6. GitOps实践:FluxCD驱动的持续交付)
-
- [6.1 Kurator中GitOps实现架构](#6.1 Kurator中GitOps实现架构)
- [6.2 FluxCD Helm应用部署示意图与实践](#6.2 FluxCD Helm应用部署示意图与实践)
- [6.3 Git仓库结构设计最佳实践](#6.3 Git仓库结构设计最佳实践)
- [6.4 自动化同步与安全策略配置](#6.4 自动化同步与安全策略配置)
- [7. 高级流量管理:Istio赋能的服务网格能力](#7. 高级流量管理:Istio赋能的服务网格能力)
-
- [7.1 Kurator中Istio集成架构](#7.1 Kurator中Istio集成架构)
- [7.2 金丝雀发布配置实战](#7.2 金丝雀发布配置实战)
- [7.3 蓝绿发布与A/B测试实现](#7.3 蓝绿发布与A/B测试实现)
- [8. Kurator未来发展方向:分布式云原生的演进之路](#8. Kurator未来发展方向:分布式云原生的演进之路)
-
- [8.1 当前技术挑战与突破点](#8.1 当前技术挑战与突破点)
- [8.2 边缘计算与5G融合趋势](#8.2 边缘计算与5G融合趋势)
- [8.3 AI驱动的智能资源调度](#8.3 AI驱动的智能资源调度)
- [8.4 开源社区共建与企业级应用场景展望](#8.4 开源社区共建与企业级应用场景展望)
【前瞻创想】Kurator·云原生实战派:打造下一代分布式云原生基础设施
摘要
在云原生技术蓬勃发展的今天,企业面临着多云、混合云、边缘计算等复杂场景下的基础设施管理挑战。Kurator作为一款开源的分布式云原生平台,通过集成Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀开源项目,为企业提供了统一的分布式云原生基础设施解决方案。本文将深入解析Kurator架构设计理念,从环境搭建到核心功能实践,结合Fleet集群管理、Karmada跨集群调度、KubeEdge边缘计算、GitOps持续交付等实战案例,展现Kurator在统一资源编排、统一调度、统一流量管理、统一遥测等方面的独特优势,并探讨分布式云原生技术的发展方向与企业数字化转型路径。
1. Kurator框架全景解析
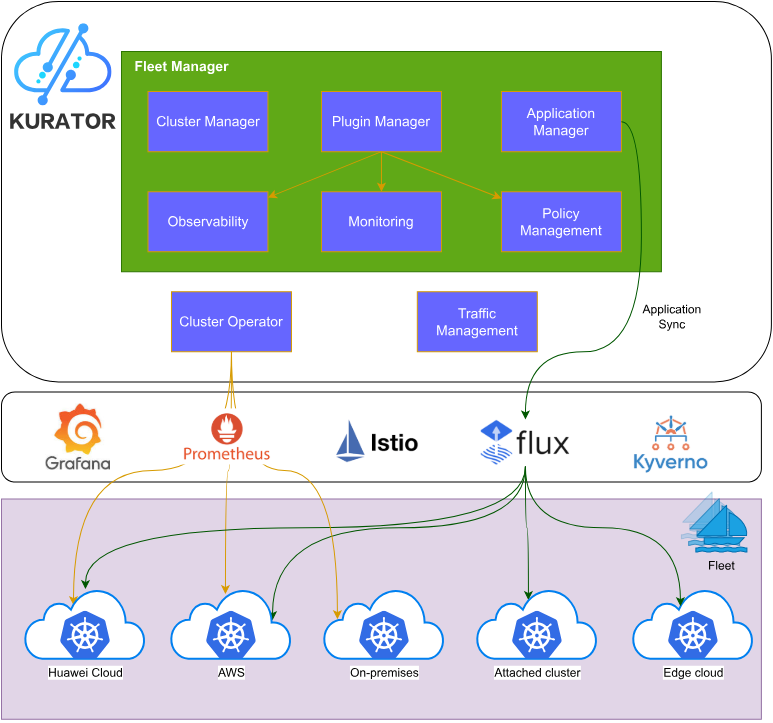
1.1 什么是Kurator:分布式云原生平台的定义
Kurator是一个开放源代码的分布式云原生平台,旨在帮助企业构建自己的分布式云原生基础设施,加速企业数字化转型进程。它不是简单的工具集合,而是一个有机整合的平台,站在众多优秀云原生项目的"肩膀"上,提供更高层次的抽象和统一管理能力。
Kurator的核心价值在于解决了分布式环境下的"碎片化"问题。在多云、混合云、边缘计算场景中,企业往往需要面对不同云服务商、不同Kubernetes发行版、不同网络环境带来的管理复杂性。Kurator通过统一的控制平面,实现了对这些异构环境的集中管控,让开发者和运维人员能够以一致的方式管理分布在各处的资源。
1.2 核心架构设计理念
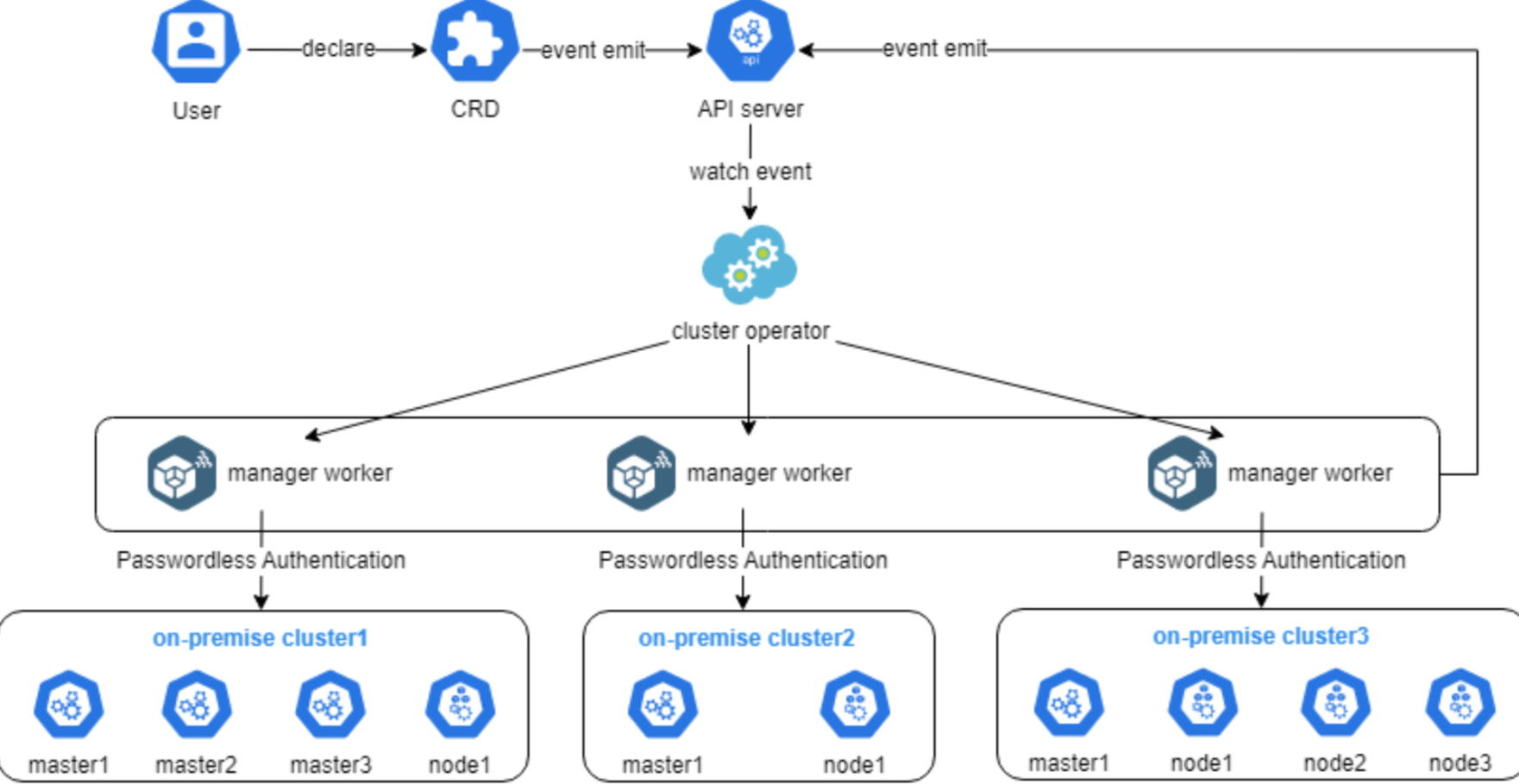
Kurator的架构设计遵循了"分层解耦、插件化扩展"的原则。底层是各种基础设施(公有云、私有云、边缘节点),中间层是Kubernetes集群,上层则是Kurator提供的统一控制平面。这种架构使得Kurator能够灵活适应不同的部署场景,同时保持系统的可扩展性。
Kurator的控制平面采用了微服务架构,各个功能模块(如集群管理、应用分发、策略引擎等)都是独立的服务,通过API进行通信。这种设计不仅提高了系统的可靠性,也便于社区贡献和功能扩展。同时,Kurator大量使用了Kubernetes CRD(Custom Resource Definition)机制,将复杂的分布式系统管理抽象为声明式的API,极大地降低了使用门槛。
1.3 与传统云原生平台的差异化优势
相比传统的云原生平台,Kurator具有几个显著的差异化优势:
统一性:Kurator提供了真正的统一管理体验,不是简单地将多个工具组合在一起,而是深度集成,确保各组件之间的协同工作。例如,Kurator的Fleet管理不仅能够注册集群,还能确保跨集群的命名空间、服务账号、服务的一致性,这是其他平台难以做到的。
原生集成:Kurator对集成的开源项目(如Istio、Karmada、KubeEdge等)进行了深度适配,不仅仅是安装部署,而是实现了功能层面的融合。例如,Kurator可以利用Karmada的跨集群调度能力,同时结合Istio的服务网格能力,实现跨集群的服务发现和流量管理。
声明式管理:Kurator全面采用"Infrastructure-as-Code"理念,所有资源(集群、节点、VPC等)都可以通过声明式配置进行管理。这种模式不仅提高了管理效率,也增强了系统的可审计性和可重复性。
2. 环境搭建与核心组件安装
2.1 前置条件与环境准备
在开始安装Kurator之前,需要准备以下环境:
- 至少一台Linux服务器(推荐Ubuntu 20.04 LTS或CentOS 7.9)
- Docker 20.10+
- Kubernetes 1.21+ 集群(可以是单节点或多节点)
- Helm 3.7+
- kubectl 1.21+
- 至少8GB内存和4核CPU
- 稳定的互联网连接
环境准备完成后,需要确保各组件版本兼容。Kurator对基础组件的版本有特定要求,建议参考官方文档获取最新的版本兼容性信息。同时,如果计划在生产环境中使用,建议提前规划网络拓扑,包括Pod CIDR、Service CIDR、节点IP分配等,避免后续配置冲突。
2.2 从GitHub克隆Kurator源码详解
Kurator的安装从获取源码开始,使用标准的git命令:
bash
git clone https://github.com/kurator-dev/kurator.git
cd kurator
克隆完成后,目录结构如下:
kurator/
├── charts/ # Helm图表
├── cmd/ # 命令行工具源码
├── config/ # 配置文件
├── deploy/ # 部署文件
├── docs/ # 文档
├── examples/ # 示例
├── hack/ # 脚本工具
├── pkg/ # 核心包
├── scripts/ # 安装脚本
└── README.md # 入门指南源码克隆后,建议先查看README.md和docs目录下的文档,了解最新的安装指南和版本要求。Kurator是活跃的开源项目,安装流程可能会随版本更新而变化,因此官方文档始终是最权威的参考。
2.3 安装流程与关键配置参数
Kurator提供了多种安装方式,推荐使用Helm Chart安装,步骤如下:
bash
# 添加Helm仓库
helm repo add kurator https://kurator-dev.github.io/kurator-charts
helm repo update
# 创建命名空间
kubectl create namespace kurator-system
# 安装Kurator
helm install kurator kurator/kurator -n kurator-system \
--set global.tag=v0.3.0 \
--set karmada.enabled=true \
--set kubeedge.enabled=true \
--set istio.enabled=true安装过程中有几个关键配置参数需要注意:
global.tag:指定Kurator版本,建议使用最新稳定版本karmada.enabled:是否启用Karmada多集群管理kubeedge.enabled:是否启用KubeEdge边缘计算istio.enabled:是否启用Istio服务网格volcano.enabled:是否启用Volcano批处理调度
这些参数可以根据实际需求调整,不必要一次性启用所有功能。对于初次体验,建议先启用核心功能,再逐步扩展。
2.4 验证安装与基础功能测试
安装完成后,需要验证各个组件是否正常运行:
bash
# 检查Kurator核心组件
kubectl get pods -n kurator-system
# 检查Karmada组件
kubectl get pods -n karmada-system
# 检查Istio组件
kubectl get pods -n istio-system
# 检查KubeEdge组件
kubectl get pods -n kubeedge所有Pod应该处于Running状态。如果发现某些Pod处于Pending或Error状态,需要根据日志进行排查:
bash
kubectl logs <pod-name> -n kurator-system基础功能测试可以通过创建一个简单的Fleet资源来验证:
yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: test-fleet
spec:
clusters:
- name: member1
kubeconfigSecretRef:
name: member1-kubeconfig应用这个配置后,可以通过以下命令验证Fleet状态:
bash
kubectl get fleet
kubectl describe fleet test-fleet如果一切正常,说明Kurator基础环境搭建成功,可以进行后续的深入实践。
3. Fleet舰队管理:统一多集群治理的艺术
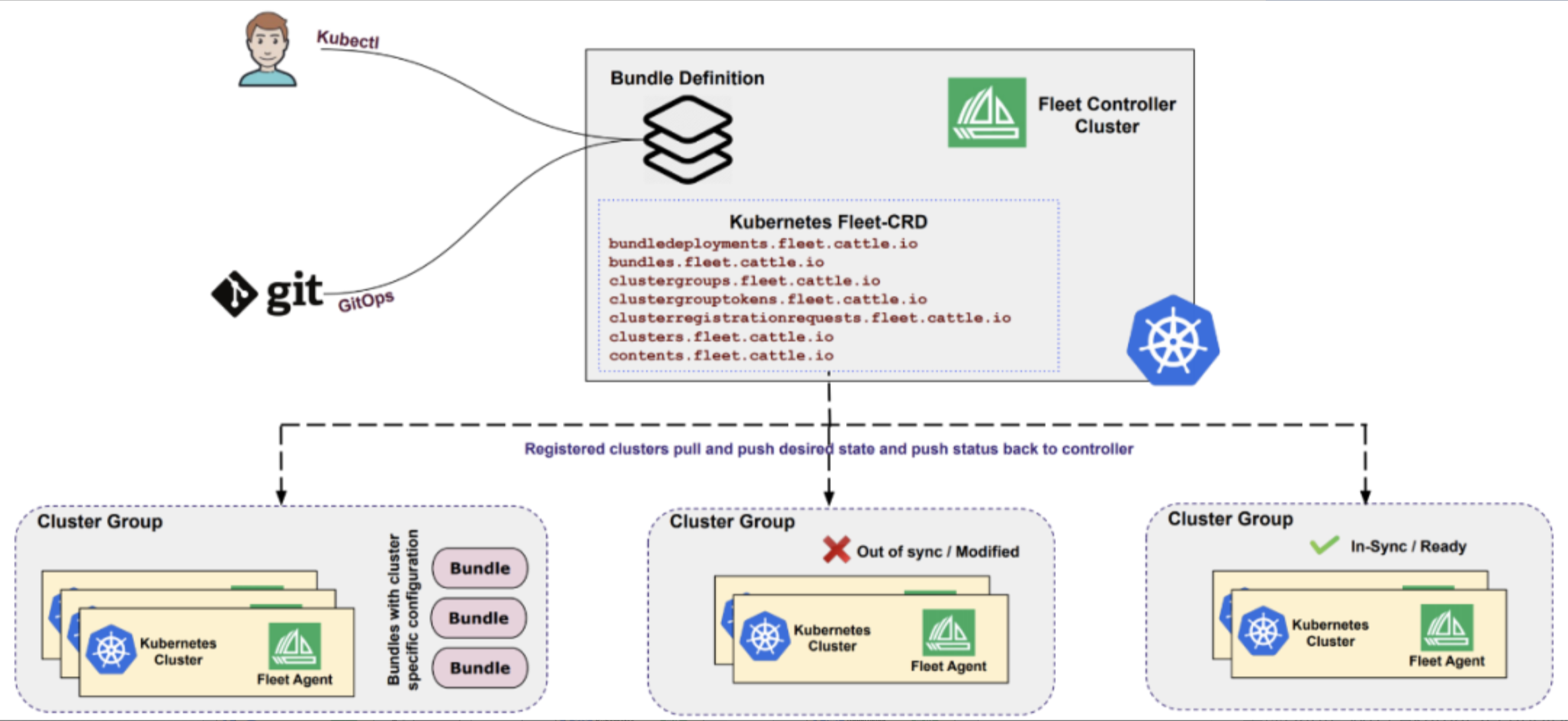
3.1 Fleet概念与设计哲学
Fleet是Kurator的核心概念,代表一组逻辑上相关的Kubernetes集群集合。Fleet的设计哲学是"逻辑统一,物理分散"------在逻辑层面,Fleet中的所有集群被视为一个统一的整体,可以进行统一的资源管理、策略应用和应用分发;在物理层面,每个集群仍然保持独立,可以根据实际需求部署在不同的地理位置、不同的云环境或不同的网络区域。
Fleet的设计解决了分布式云原生环境中的几个关键问题:
- 资源碎片化:将分散在不同环境的集群资源整合为一个逻辑池
- 管理复杂性:提供统一的API和工具链,降低多集群管理门槛
- 策略一致性:确保安全策略、网络策略、资源策略在所有集群中一致应用
- 应用可移植性:简化应用在不同集群间的迁移和分发
在Kurator中,Fleet不仅是集群的集合,更是一个具备完整生命周期管理能力的实体,包括集群注册、应用分发、策略同步、监控聚合等功能。
3.2 集群注册与生命周期管理
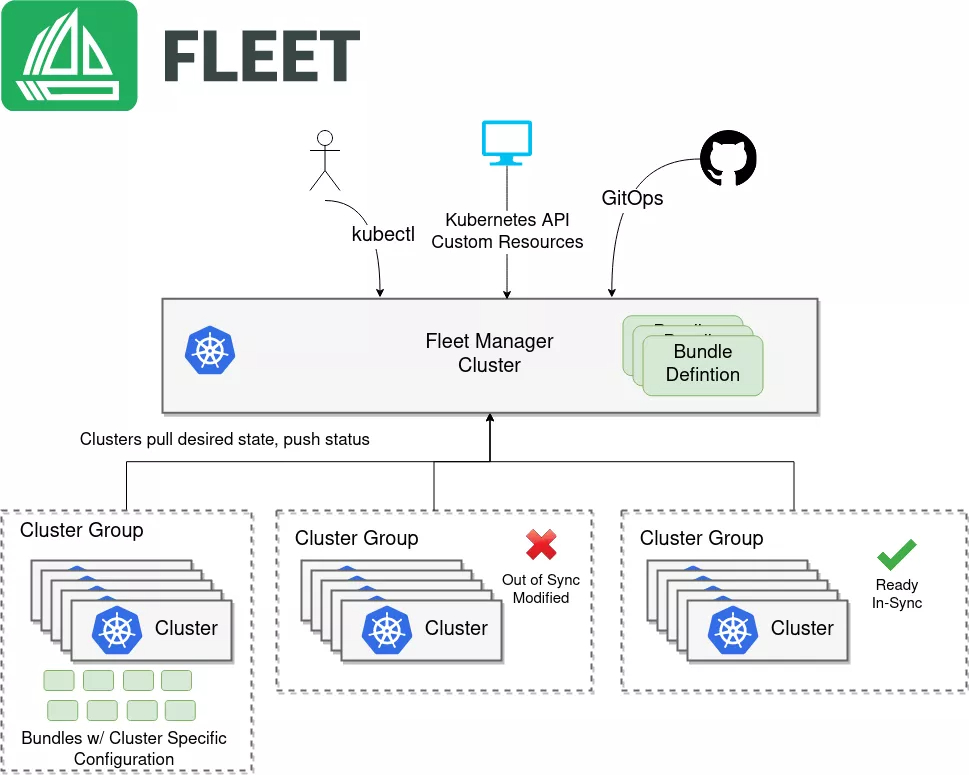
在Kurator中,集群注册是Fleet管理的第一步。注册过程包括:
- 准备集群Kubeconfig:获取目标集群的访问凭证
- 创建Secret:将Kubeconfig存储为Kubernetes Secret
- 创建Cluster资源:定义集群元数据和连接信息
- 加入Fleet:将Cluster资源关联到Fleet
示例代码:
yaml
# 1. 创建Kubeconfig Secret
apiVersion: v1
kind: Secret
meta
name: cluster1-kubeconfig
namespace: kurator-system
type: Opaque
kubeconfig: <base64-encoded-kubeconfig>
# 2. 创建Cluster资源
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
meta
name: cluster1
spec:
kubeconfigSecretRef:
name: cluster1-kubeconfig
clusterType: Kubernetes # 可以是Kubernetes、K3s、KubeEdge等
# 3. 创建Fleet并包含Cluster
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production-fleet
spec:
clusters:
- name: cluster1
kubeconfigSecretRef:
name: cluster1-kubeconfig集群生命周期管理包括注册、升级、维护和注销等操作。Kurator提供了丰富的API和CLI工具来简化这些操作。例如,集群升级可以通过更新Cluster资源的spec字段来触发,系统会自动协调升级过程,确保业务连续性。
3.3 Fleet队列中的命名空间相同性实现
Fleet 舰队中的命名空间相同性如图:
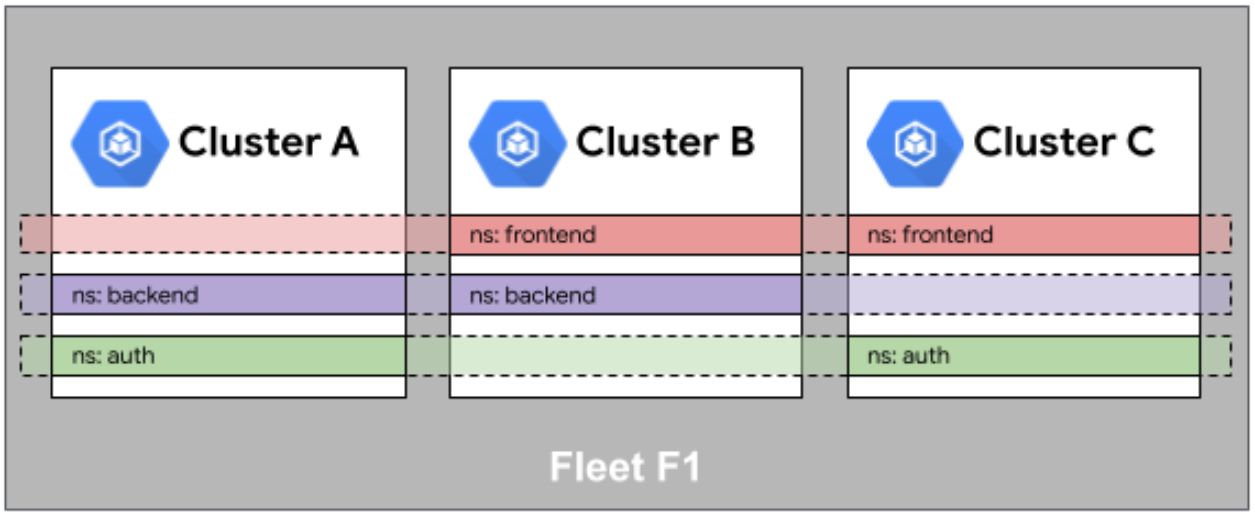
命名空间相同性(Namespace Sameness)是Fleet管理中的关键概念,指的是在Fleet的所有集群中,同一个命名空间具有相同的配置和资源状态。这解决了多集群环境中命名空间管理不一致的问题。
Kurator通过以下机制实现命名空间相同性:
- 声明式配置:通过FleetNamespace资源定义命名空间的期望状态
- 自动同步:控制器监控命名空间变化,并自动同步到所有集群
- 冲突解决:当不同集群中的命名空间配置冲突时,采用预定义的策略(如"主集群优先"或"合并策略")
示例配置:
yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: FleetNamespace
meta
name: production
spec:
fleetName: production-fleet
namespaceSpec:
metadata:
labels:
environment: production
tier: backend
resourceQuota:
hard:
requests.cpu: "10"
requests.memory: 20Gi
limits.cpu: "20"
limits.memory: 40Gi
syncPolicy:
strategy: Replace # 或Merge
dryRun: false这个配置会确保Fleet中所有集群都存在名为"production"的命名空间,并且具有相同的标签、注解和资源配额。当主配置发生变化时,所有集群中的对应命名空间会自动更新,保持一致性。
3.4 跨集群服务发现与通信机制
在分布式环境中,服务发现和跨集群通信是重大挑战。Kurator通过集成Istio和Karmada,提供了强大的跨集群服务发现能力。
实现原理:
- 服务注册:各集群中的服务自动注册到中央服务目录
- DNS解析:通过CoreDNS插件,实现跨集群的服务DNS解析
- 流量路由:利用Istio的VirtualService和DestinationRule,实现细粒度的跨集群流量控制
- 网络连通:通过隧道或Underlay网络,确保跨集群Pod间网络可达
示例配置(Istio跨集群服务):
yaml
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
meta
name: frontend-service
spec:
hosts:
- frontend.production.svc.cluster.local
location: MESH_INTERNAL
endpoints:
- address: cluster1-frontend.production.svc.cluster.local
ports:
http: 80
- address: cluster2-frontend.production.svc.cluster.local
ports:
http: 80
resolution: DNS
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
meta
name: frontend-route
spec:
hosts:
- frontend.production.svc.cluster.local
http:
- route:
- destination:
host: frontend.production.svc.cluster.local
subset: cluster1
weight: 70
- destination:
host: frontend.production.svc.cluster.local
subset: cluster2
weight: 30这个配置实现了跨两个集群的frontend服务流量分发,70%的流量导向cluster1,30%导向cluster2。Kurator简化了这类配置,通过Fleet级别的抽象,开发者无需关心底层集群细节,只需关注业务逻辑。
4. Karmada集成实践:跨集群应用调度与弹性伸缩
4.1 Karmada核心架构与Kurator集成点
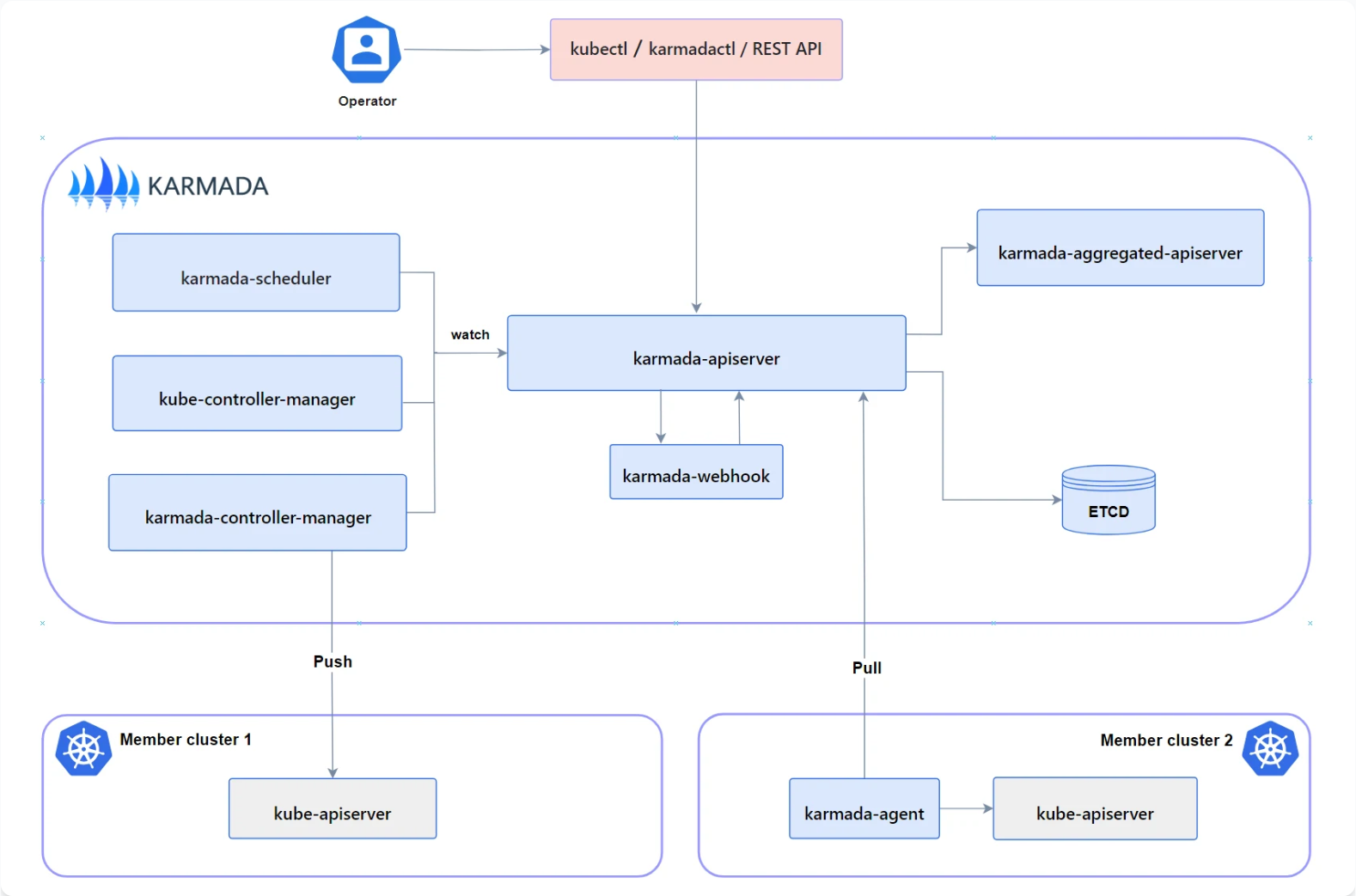
Karmada是Kurator集成的多集群管理核心组件,其架构设计围绕"中心控制平面+分布式执行"展开。Karmada的核心组件包括:
- karmada-apiserver:提供API服务,处理所有Karmada资源
- karmada-controller-manager:负责资源调度、状态聚合等核心逻辑
- karmada-scheduler:负责将工作负载调度到合适的成员集群
- karmada-agent:部署在成员集群中,负责与控制平面通信
Kurator与Karmada的集成点主要在以下几个方面:
- 资源抽象:Kurator扩展了Karmada的资源模型,添加了更多企业级功能
- 策略管理:Kurator提供了更友好的策略配置界面和工具
- 监控集成:将Karmada的监控指标集成到Kurator的统一监控体系
- 生命周期管理:简化Karmada组件的安装、升级和维护
在Kurator中,Karmada不再是独立的工具,而是成为Fleet管理能力的底层支撑,开发者通过Kurator的API即可使用Karmada的所有功能,无需深入了解Karmada的实现细节。
4.2 应用跨集群分发策略配置
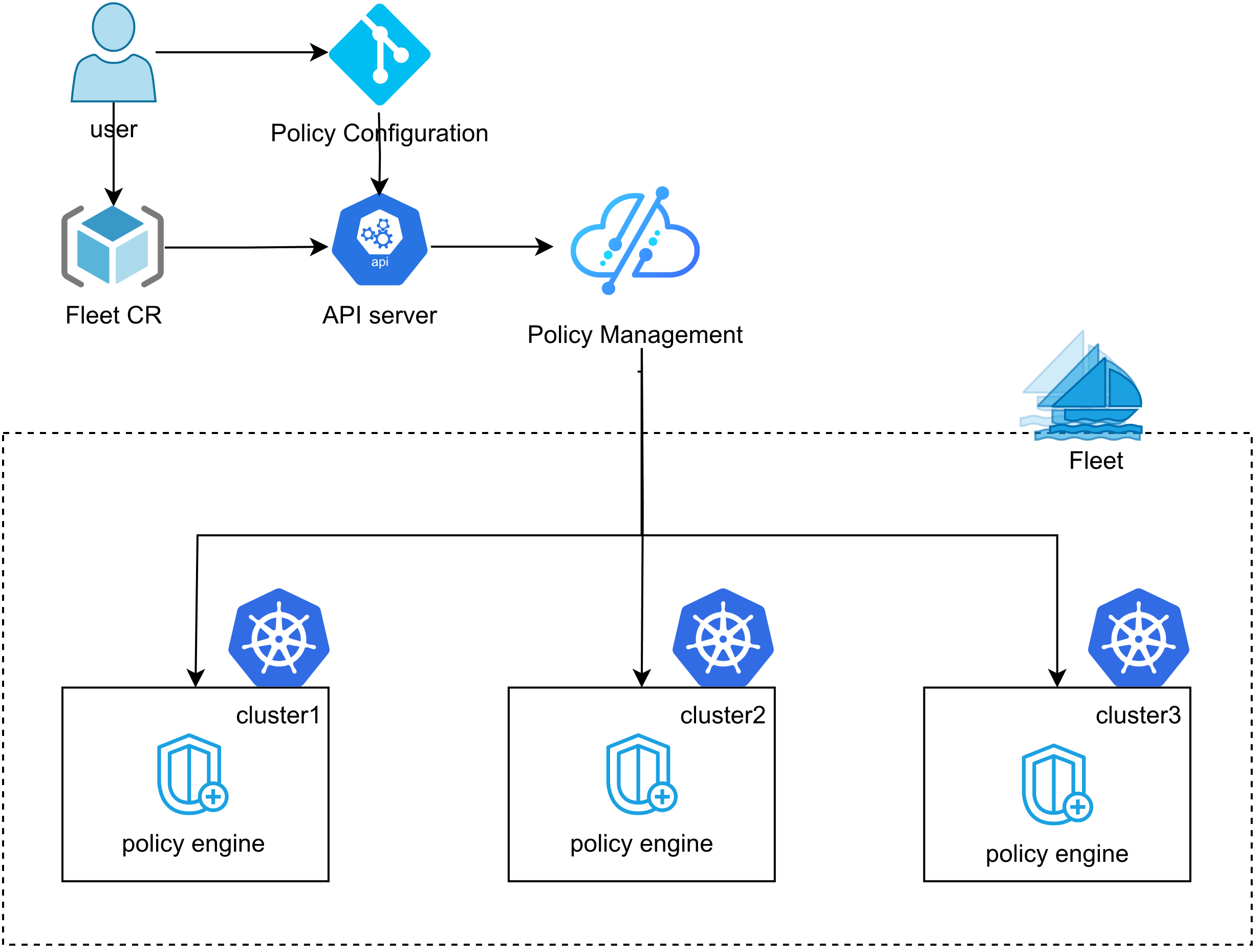
Karmada通过PropagationPolicy和ClusterPropagationPolicy资源实现应用的跨集群分发。在Kurator中,这些配置被进一步简化:
yaml
apiVersion: policy.kurator.dev/v1alpha1
kind: PropagationPolicy
meta
name: frontend-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: frontend
placement:
clusterAffinity:
clusterNames:
- cluster1
- cluster2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weights:
cluster1: 70
cluster2: 30这个策略配置了frontend部署的跨集群分发:
- 70%的副本部署在cluster1
- 30%的副本部署在cluster2
- 采用"按权重分配"的副本调度策略
更复杂的策略可以基于集群属性(如区域、可用区、集群容量)进行动态调度:
yaml
placement:
clusterAffinity:
labelSelector:
matchLabels:
topology.kubernetes.io/region: ap-southeast-1
replicaScheduling:
replicaDivisionPreference: Aggregated
replicaSchedulingType: Divided这个策略会将应用部署到所有标签为"topology.kubernetes.io/region=ap-southeast-1"的集群,并自动根据集群容量分配副本数量。
4.3 基于负载的跨集群弹性伸缩实践
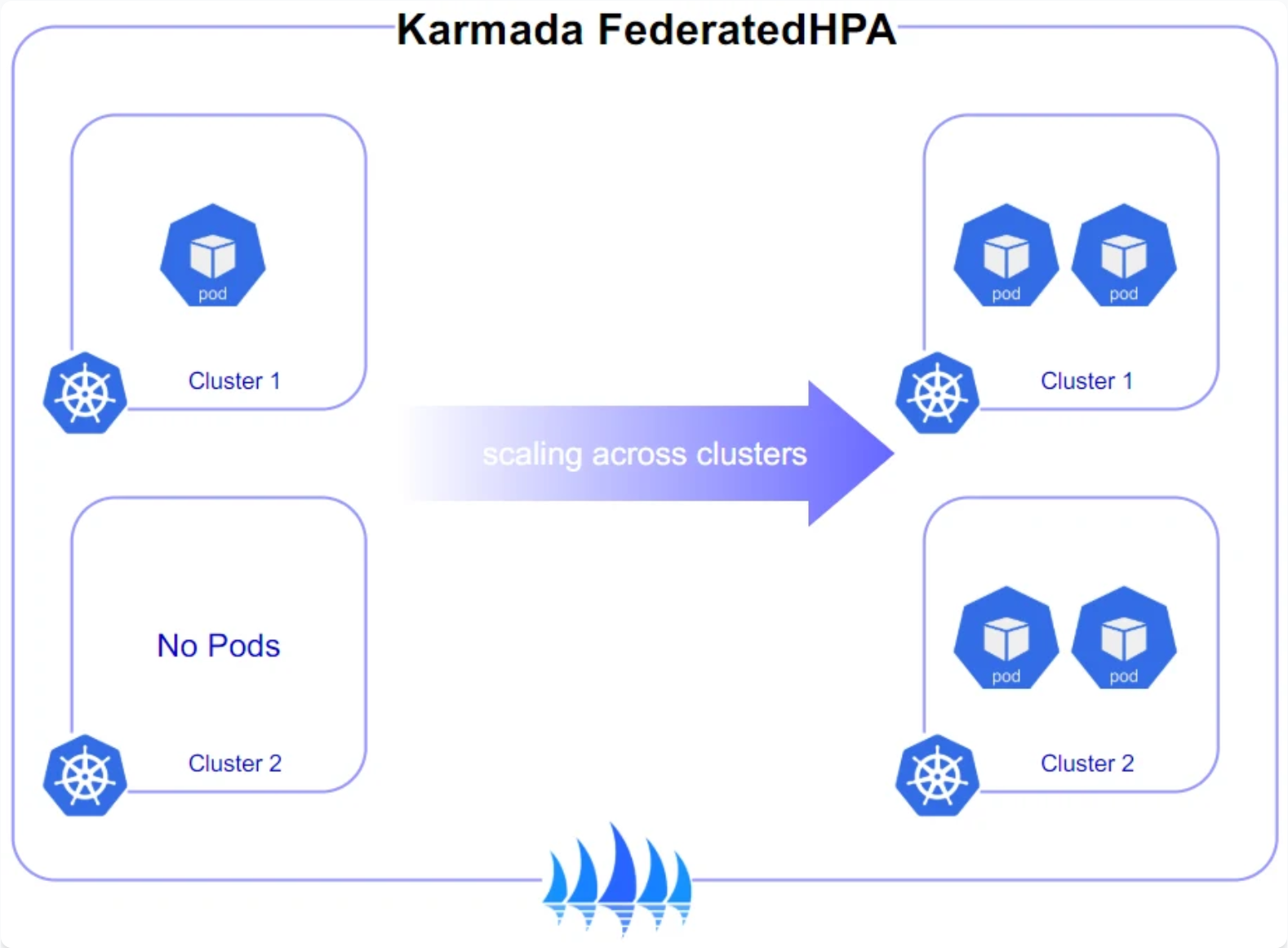
Kurator结合Karmada和HPA(Horizontal Pod Autoscaler),实现了跨集群的弹性伸缩能力。这不仅包括单集群内的Pod扩缩容,还包括跨集群的工作负载重分配。
实现原理:
- 监控采集:从各集群收集CPU、内存、自定义指标
- 负载分析:计算全局负载状态和各集群负载差异
- 决策引擎:基于预设策略决定是否需要跨集群调度
- 执行调度:调整PropagationPolicy中的权重,重新分配工作负载
示例代码(跨集群HPA):
yaml
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: FederatedHPA
meta
name: frontend-fhpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
policies:
- type: ClusterScaling
clusterScaling:
minReplicas: 3
maxReplicas: 20
scalingBehavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 20
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Pods
value: 4
periodSeconds: 15
- type: CrossClusterRebalance
crossClusterRebalance:
threshold: 20% # 当集群间负载差异超过20%时触发重平衡
cooldownSeconds: 300这个配置实现了:
- 当CPU利用率超过70%时触发扩缩容
- 总副本数在3-20之间
- 当集群间负载差异超过20%时,自动重新平衡工作负载
- 防止频繁的跨集群调度(cooldownSeconds=300)
4.4 故障转移与高可用性保障
在分布式环境中,单点故障是常态。Kurator通过Karmada实现了智能的故障转移机制:
- 健康检查:持续监控集群健康状态
- 故障检测:当集群不可用时,自动将工作负载迁移到健康集群
- 容量预留:在健康集群中预留一定容量,用于故障转移
- 渐进式迁移:避免所有工作负载同时迁移导致的雪崩效应
配置示例:
yaml
apiVersion: policy.kurator.dev/v1alpha1
kind: PropagationPolicy
meta
name: high-availability-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: critical-app
placement:
clusterAffinity:
clusterNames:
- primary-cluster
- backup-cluster1
- backup-cluster2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weights:
primary-cluster: 80
backup-cluster1: 10
backup-cluster2: 10
tolerations:
- key: "cluster.kurator.dev/unavailable"
operator: "Equal"
value: "true"
effect: "NoSchedule"
tolerationSeconds: 300
failoverStrategy:
enabled: true
failoverThreshold: 90% # 当主集群可用率低于90%时触发故障转移
migrationBatchSize: 20% # 每次迁移20%的工作负载这个配置实现了:
- 80%的工作负载在主集群,20%在备份集群(提供容量预留)
- 当主集群不可用时,自动将工作负载迁移到备份集群
- 采用渐进式迁移策略,避免雪崩
- 5分钟的容忍时间,防止短暂网络波动导致的误判
在实际生产环境中,这种配置能够显著提高系统的可用性和韧性,确保业务连续性。
5. KubeEdge边缘计算:云边协同新范式
5.1 KubeEdge架构解析与核心组件
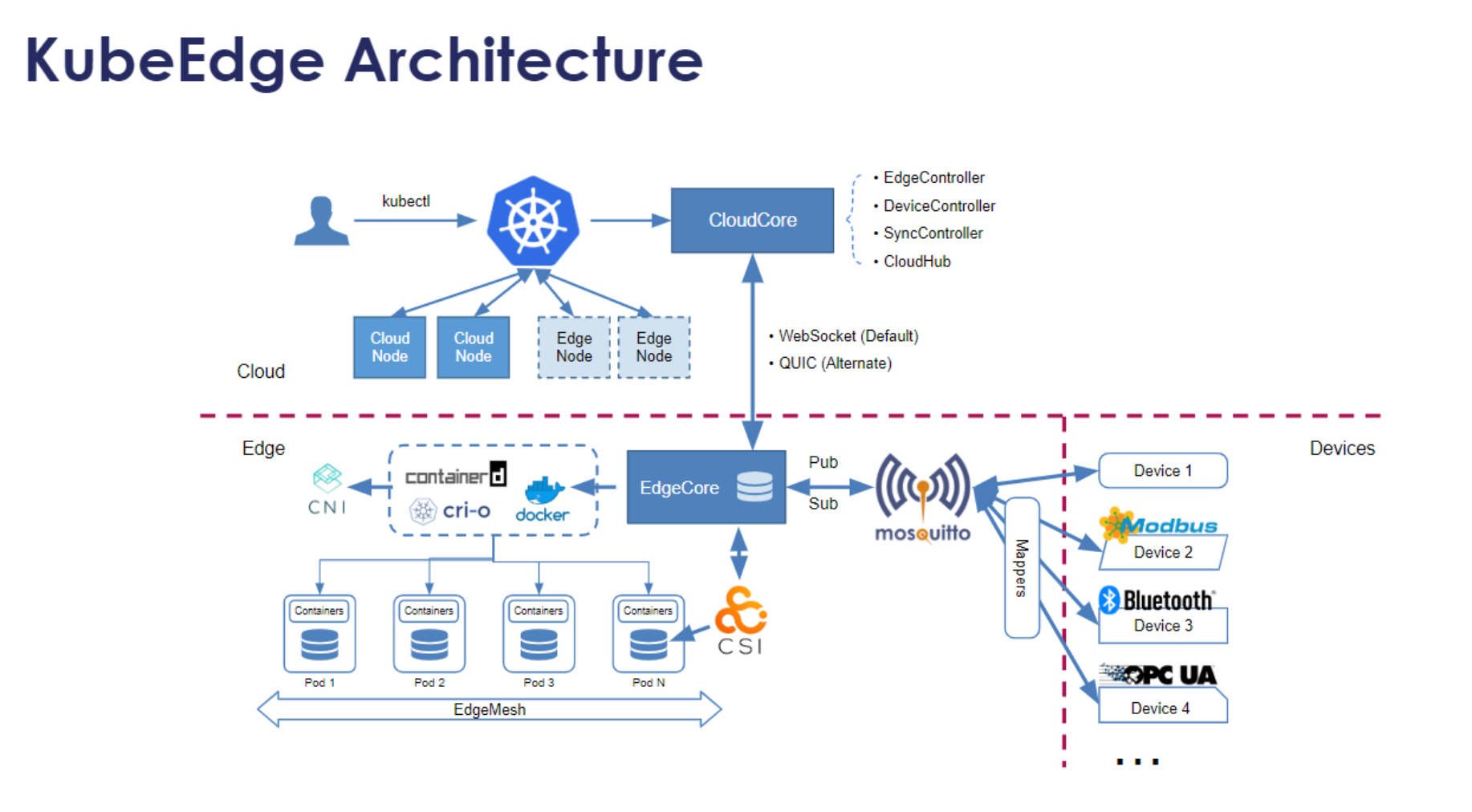
KubeEdge是Kurator集成的边缘计算核心组件,其架构设计解决了云边协同的关键挑战。KubeEdge架构分为云上部分(Cloud)和边缘部分(Edge):
云上组件:
- CloudCore :云上控制中心,包括:
- CloudHub:WebSocket/Quic服务器,负责与边缘节点通信
- EdgeController:管理边缘节点和Pod的状态同步
- DeviceController:管理边缘设备
边缘组件:
- EdgeCore :边缘节点核心,包括:
- EdgeHub:与CloudCore通信的客户端
- MetaManager:本地数据缓存和管理
- EventBus:MQTT客户端,处理设备通信
- ServiceBus:HTTP客户端,将云上请求转发到边缘服务
- DeviceTwin:管理设备状态同步
- Edged:轻量级Kubelet,管理容器生命周期
Kurator对KubeEdge的集成不仅仅是安装部署,更重要的是将边缘集群纳入Fleet管理体系,实现云边资源的统一调度、统一监控和统一策略管理。这种集成使得开发者可以用相同的工具和流程管理云端和边缘的应用,大大降低了边缘计算的采用门槛。
5.2 云边资源统一纳管实践
在Kurator中,边缘集群和云端集群可以统一管理。首先需要将边缘集群注册到Fleet:
yaml
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
meta
name: edge-cluster-1
spec:
clusterType: KubeEdge
kubeconfigSecretRef:
name: edge-cluster-1-kubeconfig
labels:
location: factory-a
edge-type: industrial
connectivity: intermittent注册完成后,可以通过FleetPolicy定义云边协同策略:
yaml
apiVersion: policy.kurator.dev/v1alpha1
kind: FleetPolicy
metadata:
name: edge-compute-policy
spec:
fleetName: hybrid-fleet
placement:
clusterSelector:
matchLabels:
edge-type: industrial
nodeSelector:
matchLabels:
node-role.kubernetes.io/edge: "true"
schedulingStrategy: PreferEdge # 优先在边缘执行
dataTransferPolicy:
mode: OnDemand # 按需同步
bandwidthLimit: 2Mbps # 带宽限制
compression: true # 启用压缩这个策略定义了:
- 仅将工作负载调度到标签为"edge-type=industrial"的集群
- 优先在边缘节点执行
- 限制数据同步带宽为2Mbps
- 启用数据压缩,适应边缘网络环境
5.3 边缘节点管理与应用部署
边缘节点管理是KubeEdge的核心能力。在Kurator中,可以通过NodePool资源统一管理边缘节点:
yaml
apiVersion: nodepool.kurator.dev/v1alpha1
kind: NodePool
meta
name: industrial-edge-pool
spec:
clusterName: edge-cluster-1
template:
metadata:
labels:
node-role.kubernetes.io/edge: "true"
environment: production
spec:
taints:
- key: "edge"
value: "true"
effect: "NoSchedule"
tolerations:
- key: "edge"
operator: "Equal"
value: "true"
effect: "NoSchedule"
autoScaling:
minNodes: 5
maxNodes: 50
targetCPUUtilizationPercentage: 70应用部署时,可以利用Kurator的抽象层,无需关心底层是云端还是边缘:
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
meta
name: iiot-data-processor
spec:
components:
- name: data-collector
workload:
deployment:
template:
spec:
nodeSelector:
node-role.kubernetes.io/edge: "true"
containers:
- name: collector
image: iiot/collector:v1.0
resources:
limits:
memory: 512Mi
cpu: 500m
volumeMounts:
- name: data-volume
mountPath: /data
volumes:
- name: data-volume
hostPath:
path: /var/lib/iiot/data
- name: data-aggregator
workload:
deployment:
template:
spec:
nodeSelector:
node-role.kubernetes.io/cloud: "true"
containers:
- name: aggregator
image: iiot/aggregator:v1.0这个应用配置定义了两个组件:
- data-collector:部署在边缘节点,负责数据采集
- data-aggregator:部署在云端,负责数据聚合分析
Kurator会自动处理云边之间的网络连接、数据同步和状态管理,开发者只需关注业务逻辑。
5.4 边缘-云网络连通性与隧道机制
网络连通性排查如图:
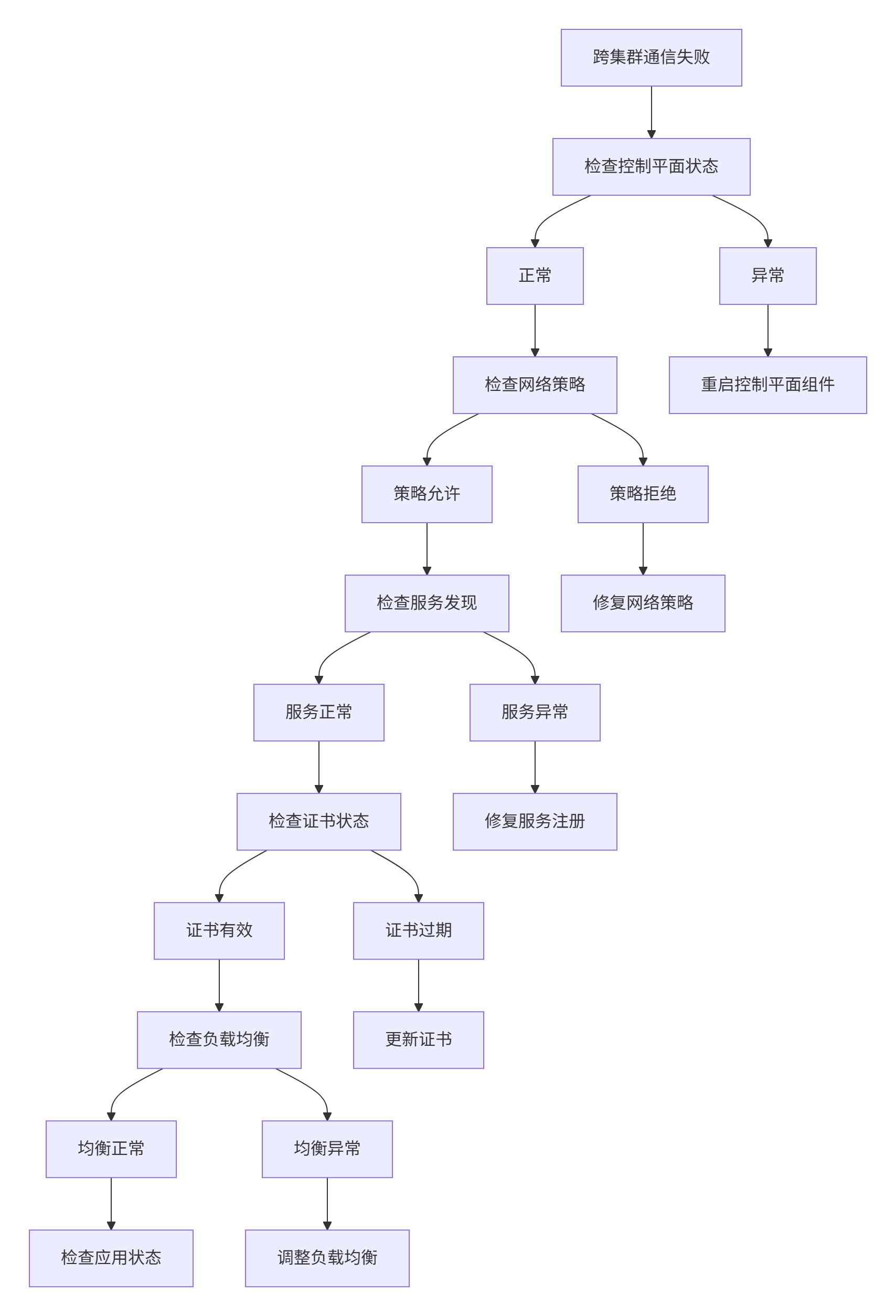
边缘环境通常面临网络不稳定、带宽有限、防火墙限制等挑战。Kurator通过KubeEdge提供了多种网络连接方案:
WebSocket隧道:
- 适用于大多数网络环境
- 穿透防火墙能力强
- 配置简单
- 性能中等
隧道如图:
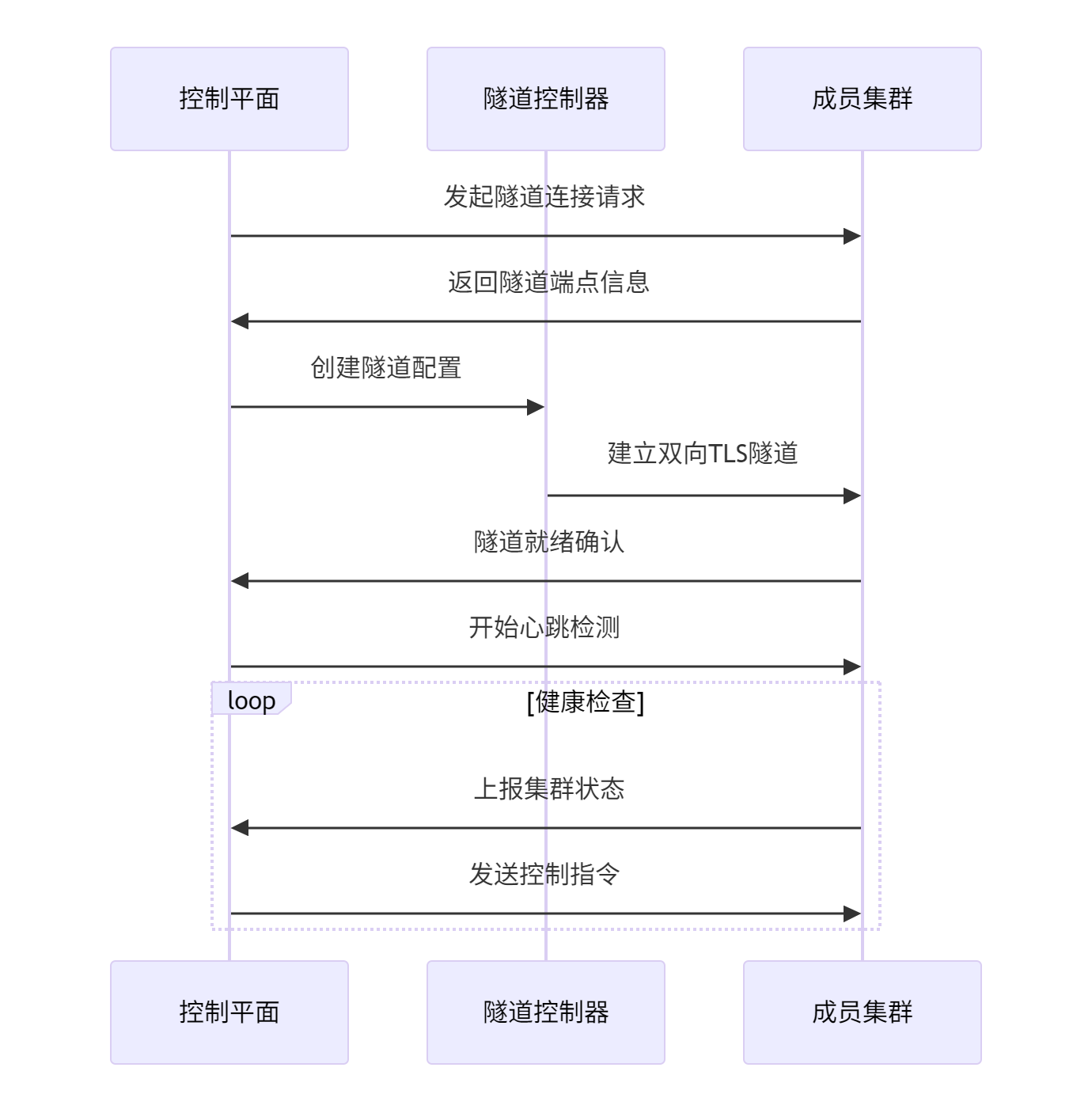
Quic隧道:
- 基于UDP,减少连接延迟
- 具有更好的丢包恢复能力
- 适用于高延迟、高丢包网络
- 性能优于WebSocket
EdgeMesh:
- P2P网络,边缘节点间直接通信
- 减少云端带宽消耗
- 适用于边缘节点间需要频繁通信的场景
网络配置示例:
yaml
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNetwork
meta
name: factory-a-network
spec:
clusterName: edge-cluster-1
tunnel:
type: Quic # 或WebSocket
quic:
port: 10001
maxStreams: 100
maxIdleTimeout: 30s
edgeMesh:
enabled: true
advertiseAddress:
- 192.168.1.0/24
bindAddress: 0.0.0.0
bindPort: 40000
qos:
enabled: true
policies:
- name: data-sync
priority: 1
bandwidthLimit: 1Mbps
- name: command-control
priority: 10
latencySensitive: true这个配置实现了:
- 使用Quic隧道连接云边
- 启用EdgeMesh实现边缘节点间P2P通信
- 配置QoS策略,确保控制命令优先传输
- 限制数据同步带宽,避免影响其他业务
在网络排查时,Kurator提供了丰富的诊断工具:
bash
# 检查边缘节点连接状态
kubectl get nodes -l node-role.kubernetes.io/edge=true
# 查看边缘组件日志
kubectl logs -n kubeedge edgecore-pod-name
# 诊断网络连通性
kubectl exec -it edge-node-pod -- edgecore network-diagnose这些工具帮助运维人员快速定位和解决边缘网络问题,确保云边协同的稳定性。
6. GitOps实践:FluxCD驱动的持续交付
6.1 Kurator中GitOps实现架构
GitOps是云原生时代的持续交付新范式,其核心理念是"将系统状态声明在Git中,并通过自动化工具确保运行状态与声明状态一致"。Kurator集成了FluxCD作为GitOps引擎,并在此基础上构建了企业级的持续交付能力。
Kurator的GitOps架构包括以下几个关键组件:
- Source Controller:监控Git仓库、Helm仓库、OCI镜像仓库的变化
- Kustomize Controller:处理Kustomize配置,生成最终的Kubernetes清单
- Helm Controller:管理Helm Chart的安装和升级
- Notification Controller:处理事件通知,支持Slack、Email、Webhook等
- Policy Controller:实施策略验证,确保配置符合安全和合规要求
Kurator对FluxCD的增强主要体现在:
- 多集群支持:将FluxCD的单集群能力扩展到多集群环境
- Fleet集成:与Fleet管理深度集成,实现跨集群的配置同步
- 增强可观测性:提供统一的GitOps状态监控和可视化
- 安全增强:支持更细粒度的访问控制和审计日志
这种架构使得GitOps不再局限于单个集群,而是成为企业级多集群、多环境的统一交付标准。
6.2 FluxCD Helm应用部署示意图与实践
FluxCD Helm 应用的示意图:
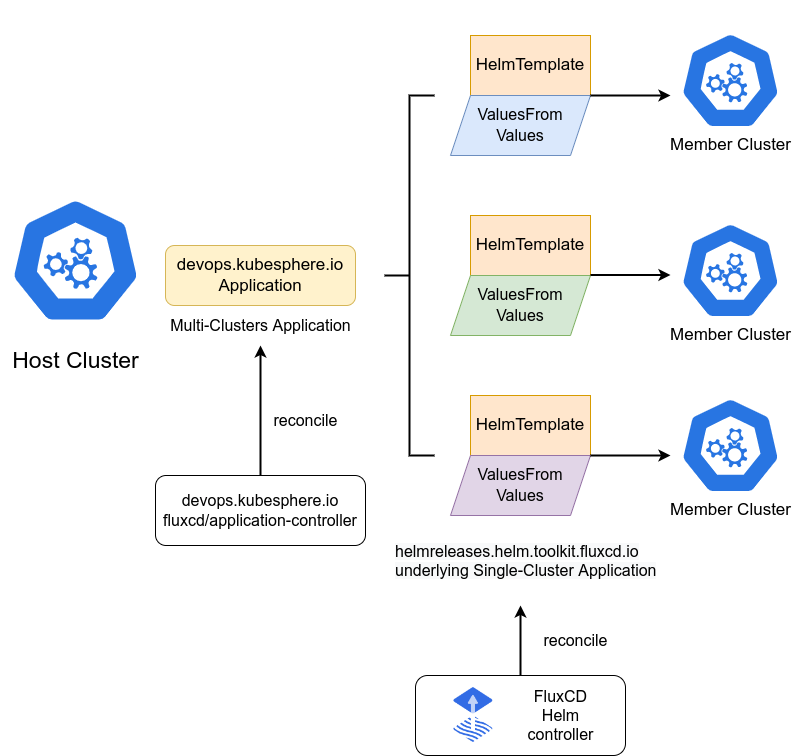
在Kurator中,Helm应用的部署流程如下:
Git Repository
│
├── Chart.yaml
├── values.yaml
├── templates/
│ ├── deployment.yaml
│ ├── service.yaml
│ └── ...
└── ...
│
Source Controller (监控仓库变化)
│
▼
Helm Repository (可选)
│
▼
Helm Controller (渲染Chart,生成Kubernetes资源)
│
▼
Kubernetes API Server (应用资源)
│
▼
Target Clusters (通过Fleet分发到多个集群)实际配置示例:
yaml
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
meta
name: my-app-repo
spec:
interval: 10m
url: https://charts.example.com
secretRef:
name: helm-repo-credentials
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: my-application
spec:
interval: 5m
chart:
spec:
chart: my-app
version: "1.2.3"
sourceRef:
kind: HelmRepository
name: my-app-repo
values:
replicaCount: 3
image:
repository: my-app
tag: v1.0.0
service:
type: ClusterIP
port: 80
valuesFrom:
- kind: ConfigMap
name: my-app-values
valuesKey: values.yaml
targetFleet:
name: production-fleet
placement:
clusterSelector:
matchLabels:
environment: production这个配置实现了:
- 从Helm仓库获取Chart
- 每5分钟检查一次更新
- 将应用部署到production-fleet中的所有生产环境集群
- 通过ConfigMap提供额外的values配置
- 自动处理多集群分发
6.3 Git仓库结构设计最佳实践
GitOps实现方式如图:

在Kurator的GitOps实践中,Git仓库的结构设计至关重要。推荐的仓库结构如下:
gitops-repo/
├── clusters/
│ ├── production/
│ │ ├── fleet.yaml
│ │ ├── namespaces/
│ │ │ ├── production.yaml
│ │ │ └── monitoring.yaml
│ │ └── applications/
│ │ ├── frontend.yaml
│ │ └── backend.yaml
│ └── staging/
│ ├── fleet.yaml
│ └── ...
├── base/
│ ├── nginx/
│ │ ├── kustomization.yaml
│ │ ├── deployment.yaml
│ │ └── service.yaml
│ └── redis/
│ ├── kustomization.yaml
│ └── statefulset.yaml
├── environments/
│ ├── production/
│ │ ├── kustomization.yaml
│ │ ├── frontend-patch.yaml
│ │ └── backend-patch.yaml
│ └── staging/
│ ├── kustomization.yaml
│ └── ...
├── policies/
│ ├── security/
│ │ ├── pod-security.yaml
│ │ └── network-policy.yaml
│ └── quotas/
│ └── resource-quota.yaml
└── scripts/
├── validate.sh
└── deploy.sh这种结构设计遵循以下原则:
- 环境隔离:不同环境(生产、预发、测试)使用独立的目录
- 配置复用:base目录存放通用配置,环境目录存放特定配置
- 职责分离:集群配置、应用配置、策略配置分离
- 版本控制:所有配置都在Git中,支持完整的审计历史
- 自动化友好:结构清晰,便于CI/CD工具处理
在Kurator中,可以通过FluxCD的Kustomization资源引用这些配置:
yaml
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
meta
name: production-apps
spec:
interval: 10m
path: "./environments/production"
prune: true
validation: client
sourceRef:
kind: GitRepository
name: gitops-repo
decryption:
provider: sops
secretRef:
name: sops-age-key
postBuild:
substitute:
APP_VERSION: v1.0.0
ENVIRONMENT: production6.4 自动化同步与安全策略配置
GitOps的核心是自动化同步,但在企业环境中,安全性和合规性同样重要。Kurator通过以下机制确保GitOps的安全性:
自动化同步机制:
- Pull模式:集群主动从Git仓库拉取配置,而非Git推送配置到集群
- 健康检查:每次同步后验证应用状态,确保配置生效
- 回滚机制:当新配置导致应用异常时,自动回滚到上一个稳定版本
- 渐进式交付:支持金丝雀发布、蓝绿发布等高级部署策略
安全策略配置:
- 最小权限原则:GitOps服务账户仅拥有必要的权限
- 配置验证:在应用前验证配置是否符合安全策略
- 敏感数据加密:使用SOPS或Sealed Secrets加密敏感数据
- 审计日志:记录所有配置变更和同步操作
安全策略示例(Kyverno策略):
yaml
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: prevent-privileged-containers
spec:
validationFailureAction: enforce
rules:
- name: validate-containers
match:
any:
- resources:
kinds:
- Pod
- Deployment
- StatefulSet
- DaemonSet
validate:
message: "Privileged containers are not allowed"
pattern:
spec:
=(initContainers):
- =(securityContext):
=(privileged): "false"
containers:
- =(securityContext):
=(privileged): "false"这个策略会阻止任何特权容器的创建,确保GitOps同步的安全性。在Kurator中,这些策略会自动应用到所有Fleet管理的集群,确保一致的安全基线。
7. 高级流量管理:Istio赋能的服务网格能力
7.1 Kurator中Istio集成架构
lstio架构如图:
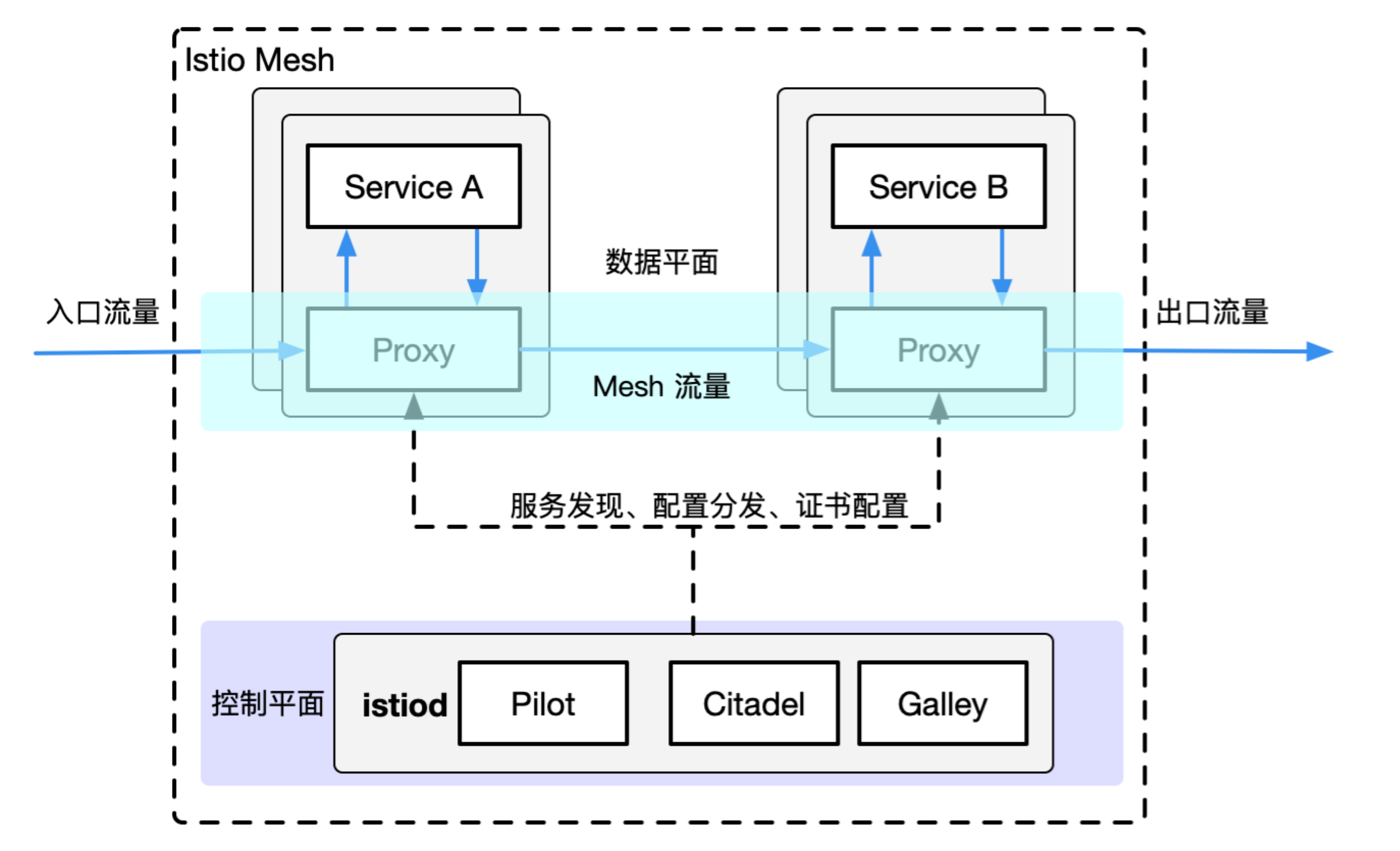
Istio是Kurator集成的核心服务网格组件,为分布式系统提供了细粒度的流量管理、安全、可观测性能力。Kurator对Istio的集成不仅仅是安装部署,更重要的是将其能力扩展到多集群、多环境场景。
Kurator的Istio集成架构包括:
控制平面:
- Central Istiod:中央控制平面,管理所有集群的配置
- Multi-cluster Mesh:跨集群服务网格,实现全局服务发现
- Fleet-aware Configuration:基于Fleet的配置分发,确保策略一致性
数据平面:
- Envoy Proxies:部署在每个Pod中,处理服务间通信
- Edge Gateways:处理入站和出站流量
- Egress Gateways:管理外部服务访问
集成层:
- Traffic Management API:统一的流量管理接口
- Policy Integration:与Kyverno等策略引擎集成
- Telemetry Integration:与Prometheus、Jaeger等可观测性工具集成
在Kurator中,Istio不再是单集群的服务网格,而是成为Fleet级别的流量管理基础设施。开发者可以通过Kurator的抽象API管理跨集群的流量,无需关心底层Istio的复杂性。
7.2 金丝雀发布配置实战
金丝雀发布是渐进式交付的核心模式,通过逐步将流量从旧版本切换到新版本,降低发布风险。在Kurator中,金丝雀发布配置如下:
yaml
apiVersion: traffic.kurator.dev/v1alpha1
kind: CanaryRelease
meta
name: frontend-canary
spec:
fleetName: production-fleet
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
strategy:
type: Progressive
steps:
- weight: 10
pause: 300s # 5分钟观察
- weight: 30
pause: 600s # 10分钟观察
- weight: 60
pause: 900s # 15分钟观察
- weight: 100
metrics:
- name: error-rate
type: Prometheus
query: |
sum(rate(http_requests_total{status=~"5.."}[5m]))
/ sum(rate(http_requests_total[5m]))
threshold: 0.01 # 1%错误率阈值
interval: 60s
- name: latency
type: Prometheus
query: |
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))
threshold: 0.5 # 500ms延迟阈值
interval: 60s
rollbackOnFailure: true
rollbackThreshold: 2 # 2个指标失败触发回滚这个配置实现了:
- 四步渐进式流量切换:10% → 30% → 60% → 100%
- 每步暂停观察,确保稳定性
- 基于Prometheus指标自动决策
- 当错误率超过1%或延迟超过500ms时,自动暂停或回滚
Kurator会自动将这个高级配置转换为底层的Istio VirtualService和DestinationRule配置,开发者无需手动管理复杂的Istio资源。
7.3 蓝绿发布与A/B测试实现
蓝绿发布和A/B测试是高级流量管理的两种重要模式。在Kurator中,这两种模式可以通过统一的API实现:
蓝绿发布配置:
yaml
apiVersion: traffic.kurator.dev/v1alpha1
kind: BlueGreenRelease
meta
name: payment-service-bg
spec:
fleetName: production-fleet
serviceRef:
name: payment-service
blueVersion:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: payment-service-v1
weight: 100
greenVersion:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: payment-service-v2
weight: 0
testEndpoints:
- path: /health
method: GET
expectedStatus: 200
- path: /api/test
method: POST
requestBody: '{"test": "data"}'
expectedStatus: 200
promotionStrategy:
type: Manual # 或Automatic
automatic:
metrics:
- name: success-rate
query: |
sum(rate(http_requests_total{status=~"2.."}[5m]))
/ sum(rate(http_requests_total[5m]))
threshold: 0.99
duration: 300sA/B测试配置:
yaml
apiVersion: traffic.kurator.dev/v1alpha1
kind: ABTest
meta
name: recommendation-abtest
spec:
fleetName: production-fleet
serviceRef:
name: recommendation-service
versions:
- name: v1
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: recommendation-v1
weight: 50
headers:
- name: x-user-type
value: premium
- name: v2
apiVersion: apps/v1
kind: Deployment
name: recommendation-v2
weight: 50
headers:
- name: x-user-type
value: standard
metrics:
- name: conversion-rate
query: |
sum(increase(conversion_events_total{version="v2"}[1h]))
/ sum(increase(conversion_events_total{version="v1"}[1h]))
improvementThreshold: 0.1 # 10%提升
- name: latency
query: |
histogram_quantile(0.95, sum(rate(request_duration_seconds_bucket{version="v2"}[5m])) by (le))
/ histogram_quantile(0.95, sum(rate(request_duration_seconds_bucket{version="v1"}[5m])) by (le))
degradationThreshold: 0.2 # 允许20%的性能下降
duration: 86400s # 24小时测试周期
decisionStrategy: StatisticalSignificance # 统计显著性决策这些配置展示了Kurator在高级流量管理方面的强大能力:
- 蓝绿发布:通过影子测试验证新版本,然后一键切换
- A/B测试:基于用户属性(如header)进行版本分流,通过业务指标评估效果
- 自动决策:基于预定义的指标阈值自动做出决策
- 多集群一致性:确保所有集群中的流量策略一致
8. Kurator未来发展方向:分布式云原生的演进之路

8.1 当前技术挑战与突破点
尽管Kurator在分布式云原生领域取得了显著进展,但仍面临诸多技术挑战:
跨集群状态一致性:在分布式环境中,保持全局状态一致性是根本性挑战。当前的解决方案(如最终一致性)在某些业务场景下无法满足需求。未来需要探索更高效的分布式共识算法,平衡一致性和性能。
边缘-云协同效率:边缘计算场景中,网络不稳定、带宽有限是常态。现有的数据同步机制(如定时同步)在高延迟、高丢包网络中表现不佳。需要研究更智能的同步策略,如基于网络状态的自适应同步、增量同步优化等。
安全与隔离:多租户、多集群环境中的安全隔离是关键挑战。现有的RBAC和网络策略在复杂拓扑中难以管理。需要更细粒度的权限控制、零信任架构的深度集成,以及跨集群的安全策略统一管理。
资源优化:在全局资源池中,如何最优分配计算、存储、网络资源是NP难问题。现有的调度算法(如基于权重的分配)无法处理复杂的业务约束和优化目标。需要引入运筹学、机器学习等技术,实现更智能的资源调度。
标准化与互操作性:云原生生态碎片化严重,不同项目、不同厂商的解决方案难以互通。Kurator需要在保持灵活性的同时,推动标准化进程,建立开放的接口规范,促进生态协同。
8.2 边缘计算与5G融合趋势
随着5G网络的普及和边缘计算的发展,Kurator将重点探索以下方向:
5G网络切片集成:将Kurator的资源调度能力与5G网络切片技术结合,为不同业务提供定制化的网络QoS。例如,工业物联网应用需要低延迟、高可靠性的网络切片,而视频分析应用需要高带宽切片。Kurator可以通过统一的API管理计算资源和网络资源,实现真正的云网融合。
边缘AI推理优化:在边缘设备上运行AI推理模型是重要趋势,但受限于边缘设备的计算能力。Kurator将探索模型分割、动态卸载等技术,将计算密集型部分卸载到云端,轻量级部分保留在边缘,优化整体性能和成本。
离线优先架构:边缘环境常常面临网络中断,传统的云中心架构无法适应。Kurator将增强离线优先能力,确保边缘节点在断网期间仍能正常运行,并在网络恢复时自动同步状态,提供无缝的用户体验。
边缘安全增强:边缘设备物理安全难以保障,容易遭受物理攻击。Kurator将集成可信执行环境(TEE)、远程认证等技术,确保边缘计算的安全性,防止数据泄露和代码篡改。
8.3 AI驱动的智能资源调度
AI和机器学习将成为Kurator未来发展的重要驱动力:
预测性扩缩容:基于历史负载模式和业务预测,提前进行资源扩缩容,避免传统反应式扩缩容的滞后性。例如,电商应用在促销前自动扩容,活动结束后自动缩容,优化资源利用率。
智能故障预测:通过分析系统指标、日志、追踪数据,使用机器学习模型预测潜在故障,在问题发生前自动修复或转移工作负载,提高系统可靠性。
成本优化引擎:在多云环境中,不同云服务商的价格策略复杂多变。Kurator将构建成本优化引擎,实时分析各云的定价,结合应用SLA要求,自动选择最优的部署位置和实例类型,降低总体拥有成本。
自愈系统:当系统出现异常时,不仅能够自动恢复,还能分析根本原因,自动生成修复建议,甚至自动调整配置参数,实现真正的自治系统。
AI驱动的调度策略配置示例:
yaml
apiVersion: scheduling.kurator.dev/v1alpha1
kind: AISchedulingPolicy
metadata:
name: predictive-scaling
spec:
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: ecommerce-backend
predictionModel:
type: LSTM
trainingData:
lookbackPeriod: 7d
samplingInterval: 5m
features:
- name: request_rate
source: prometheus
query: sum(rate(http_requests_total[5m]))
- name: cpu_utilization
source: prometheus
query: avg(node_cpu_usage_seconds_total)
- name: calendar_features
type: derived
expressions:
- hour_of_day
- day_of_week
- is_holiday
scalingStrategy:
predictive:
horizon: 60m # 预测1小时
confidenceThreshold: 0.85 # 85%置信度
bufferPercentage: 20 # 20%缓冲
reactive:
enabled: true # 同时启用反应式扩缩容作为备份
cpuThreshold: 70
costOptimization:
enabled: true
multiCloudPlacement:
providers:
- name: aws
regions: ["us-east-1", "ap-southeast-1"]
instanceTypes: ["c5.large", "c5.xlarge"]
- name: azure
regions: ["eastus", "southeastasia"]
instanceTypes: ["Standard_D2s_v3", "Standard_D4s_v3"]
optimizationObjective: cost_latency_tradeoff
latencyConstraint: 100ms这个配置定义了一个AI驱动的调度策略:
- 使用LSTM模型预测未来1小时的负载
- 基于85%置信度的预测结果进行资源预分配
- 保留20%的缓冲应对预测误差
- 同时启用传统反应式扩缩容作为备份
- 在多云环境中优化成本和延迟的权衡
8.4 开源社区共建与企业级应用场景展望
Kurator的成功离不开活跃的开源社区。未来将重点关注:
社区生态建设:
- 建立更开放的治理模式,让更多企业和个人参与决策
- 提供更完善的开发者体验,降低贡献门槛
- 举办定期的社区会议、黑客马拉松,促进知识分享
- 建立认证体系,培养Kurator专业人才
企业级功能增强:
- 多租户支持:支持企业内部多团队、多项目的资源隔离和配额管理
- 审计与合规:提供完整的操作审计日志,满足金融、医疗等行业的合规要求
- 灾难恢复:实现跨地域、跨云的灾难恢复能力,RTO<15分钟,RPO<5分钟
- 混合部署:支持从传统架构到云原生架构的平滑迁移,保护既有投资
垂直行业解决方案:
- 金融科技:低延迟交易、高可用支付、实时风控
- 智能制造:工业物联网、预测性维护、数字孪生
- 智慧医疗:远程医疗、医学影像分析、患者数据管理
- 零售电商:个性化推荐、实时库存、全渠道订单管理
全球化部署:
- 支持全球部署架构,满足数据主权要求
- 优化跨地域网络性能,减少延迟
- 支持多语言、多时区、多货币,适应全球化业务
Kurator的愿景是成为分布式云原生基础设施的事实标准,帮助企业构建"无处不在的计算"能力。在这个愿景下,计算不再局限于数据中心,而是延伸到边缘、到设备、到每一个需要智能的地方。Kurator将作为连接这些计算能力的桥梁,让开发者能够以统一的方式管理分散的资源,专注于业务创新而非基础设施复杂性。
通过开源社区的共同努力,Kurator将继续演进,解决分布式云原生领域的核心挑战,推动企业数字化转型进入新阶段。正如云原生计算基金会(CNCF)倡导的"让计算无处不在"愿景,Kurator正在这一道路上迈出坚实的步伐。