1 写在前面
在具身智能领域,强化学习 (RL) 正成为继有监督微调 (SFT) 之后提升视觉-语言-动作 (VLA) 模型表现的关键。最近 Physical Intelligence 发布的 π 0.6 ∗ \pi^*_{0.6} π0.6∗ 利用 RECAP 框架证明了这一路径的潜力。然而,构建高质量的奖励或价值模型通常代价高昂。
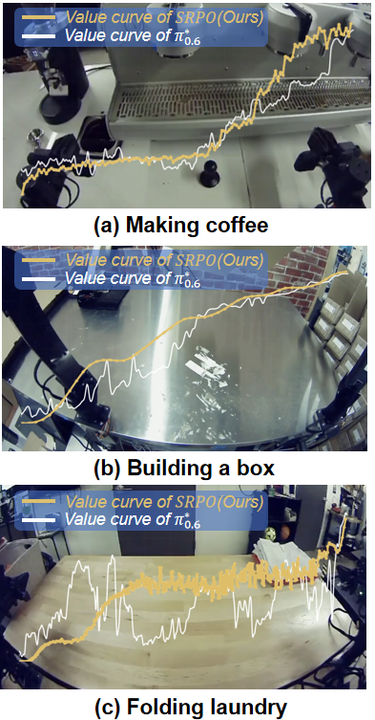
图 1: π 0.6 ∗ \pi^*{0.6} π0.6∗ 与 SRPO 价值函数曲线。图中三个场景取自 π 0.6 ∗ \pi^*{0.6} π0.6∗ 官方主页,白色曲线代表 π 0.6 ∗ \pi^*{0.6} π0.6∗ 的价值函数,而黄色曲线代表 SRPO 方法未经任务微调直接得到的价值函数。在 π 0.6 ∗ \pi^*{0.6} π0.6∗ 中,该价值函数预测的是完成任务所需的负向步骤数,当机器人取得进展时,预测值会上升,而当进展甚微时,预测值则保持平稳;在SRPO 中则直接预测任务的进展。
近期,OpenMOSS 团队与 SiiRL 团队联合带来最新工作 SRPO (Self-Referential Policy Optimization),提出了一种"自我参考"与"通用世界表征"结合的奖励构建机制。无需任何任务特定的奖励微调,SRPO 在 LIBERO 榜单上以 99.2% 的成功率刷新 SOTA,在 LIBERO-Plus 的泛化任务上性能较基线提升明显,并能大幅度提升 π 0 \pi_0 π0 等开源模型的真机表现。
论文标题:SRPO:Self-Referential Policy Optimization for Vision-Language-Action Models
论文链接:https://arxiv.org/pdf/2511.15605
文档:
【Pipeline】https://siirl.readthedocs.io/en/latest/code_explained/srpo_code_explained.html
【QuickStart】https://siirl.readthedocs.io/en/latest/examples/embodied_srpo_example.html
2 从 π 0.6 ∗ \pi^*_{0.6} π0.6∗ 说起:VLA-RL 的"奖励困境"
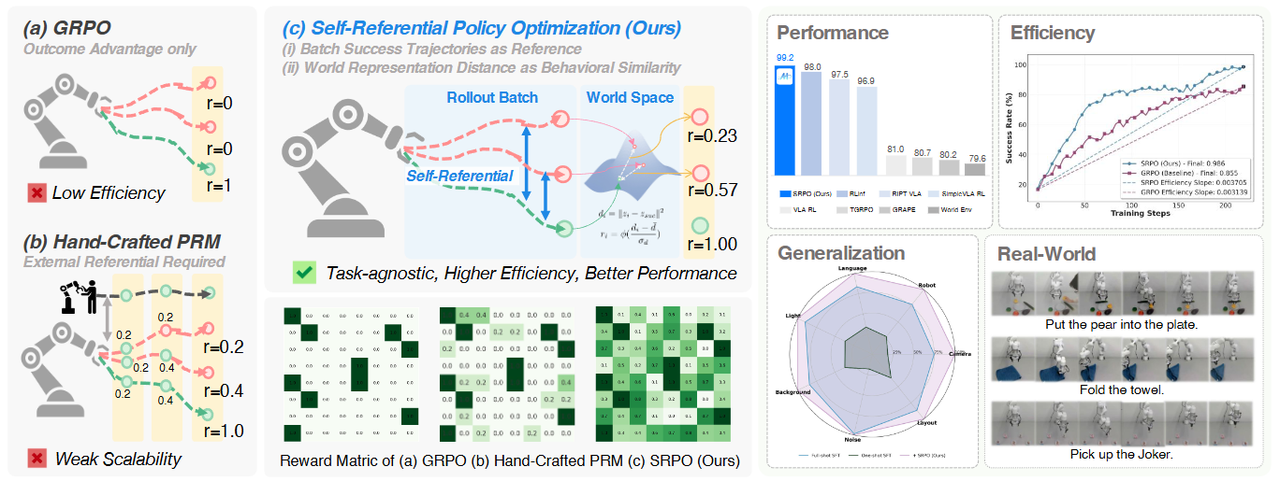
图 2:现有的 VLA 强化学习方法面临显著局限:(a)GRPO 等方法仅依赖稀疏的结果奖励,学习信号有限;(b)手动设计的过程奖励(PRM)需要成本高昂的外部示范或任务训练。而 SRPO 框架引入了自参考范式,利用批次内的成功轨迹和潜在世界表征来构建渐进式奖励,有效利用失败轨迹。实验表明,SRPO 实现了SOTA 的性能,卓越的训练效率,强大的泛化能力以及更好的真实世界表现。
最近,Physical Intelligence 的 π 0.6 ∗ \pi^*_{0.6} π0.6∗ 展示了通过 RL (RECAP) 带来的惊人能力提升。其核心在于利用高质量的 Value Function 来指导策略更新。但 RECAP 需要针对每个任务收集数据、微调价值模型,这在多任务、少样本场景下极具挑战。
思考一个问题:有没有一种"免费"的午餐?
能否不需要针对每个任务专门训练奖励模型,不需要人工设计稠密奖励,也能让机器人通过 RL "无师自通"?
答案是肯定的。 我们提出了 SRPO ------ 一种无需额外专家数据、无需任务特定操作的自我参考策略优化框架。
3 算法:任务无关的通用渐进式奖励构建
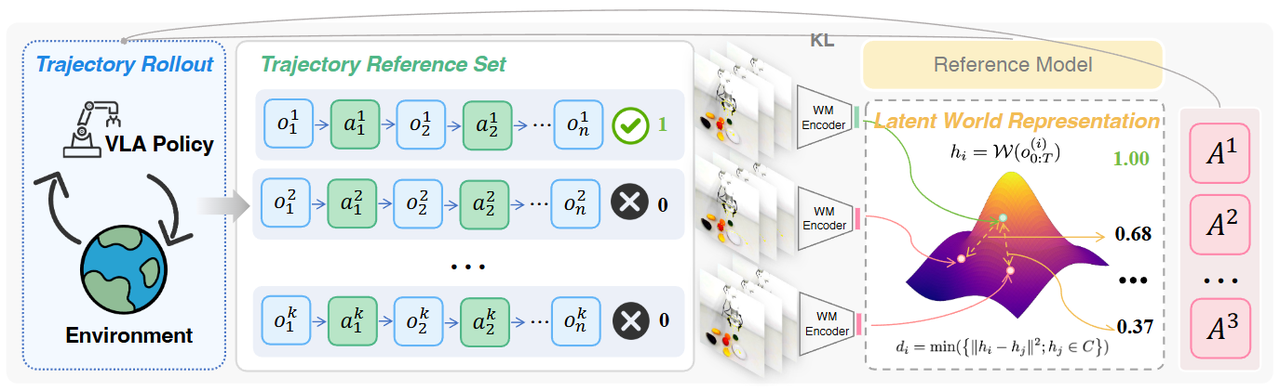
图 3: 策略部署过程产生的轨迹被收集到动态参考集中,采用在大规模机器人视频数据上预训练的世界模型作为编码器提取潜空间世界表征;行为相似性被建模为该空间中轨迹嵌入的 L2 距离,以此算出的渐进式奖励在 KL 正则化的约束下用于优势估计和策略优化。
3.1 核心思想
SRPO 的核心理念非常简单且优雅:我最好的表现,就是我的老师。
1. 自我参考:动态构建"参考系"
传统的 RL 往往只利用"成功/失败"的二元信号,浪费了大量失败轨迹中的有效信息;一些过程奖励构建方法依赖于专家轨迹先验或任务特定微调,代价昂贵。SRPO 直接利用当前推理批次中成功的轨迹构建动态参考集 S \mathcal{S} S,通过计算失败轨迹与这些"成功标尺"在行为层面的相似度,为每一次失败赋予渐进式奖励(Progress-wise Reward)
2. 潜空间世界表征:通用的奖励函数
如何衡量"失败"与"成功"的距离?这是 VLA-RL 的核心难题。像素级方法对光照、视角极度敏感,且无法理解物体遮挡,噪点极大。通用视觉编码器缺乏物理规律的理解,奖励曲线震荡,出现不合理的"伪进展示意" 。我们发现大规模视频预训练的世界模型(如 V-JEPA 2)的表征空间天然包含了对物理世界动态变化的理解。
3.2 算法流程
Step 1:世界模型编码
记当前轨迹的观测序列为 o 0 : T ( i ) o_{0:T}^{(i)} o0:T(i) ,世界模型编码器为 W ( ⋅ ) \mathcal{W}(\cdot) W(⋅),提取第 i i i条轨迹的语义表征 h i h_i hi如下:
h i = W ( o 0 : T ( i ) ) h_{i}=\mathcal{W}(o_{0:T}^{(i)}) hi=W(o0:T(i))
Step 2:成功轨迹聚类
考虑到每个任务会有不同的完成方式(例如将两个不同的物体移动到新的位置这一任务中,先移动哪个物体并不重要),我们对参考集 S \mathcal{S} S 中的成功轨迹进行聚类,找到代表性的策略中心 C \mathcal{C} C,避免单一轨迹的噪声干扰:
C = C l u s t e r ( S ) C=Cluster(\mathcal{S}) C=Cluster(S)
Step 3:潜空间距离计算
计算失败轨迹 h i h_i hi 与最近的成功策略中心 h j h_j hj 之间的 L2 距离。距离越小,代表行为模式越接近成功:
d i = min ( { ∣ ∣ h i − h j ∣ ∣ 2 ; h j ∈ C } ) d_{i}=\min(\{||h_{i}-h_{j}||^{2};h_{j}\in C\}) di=min({∣∣hi−hj∣∣2;hj∈C})
Step 4:奖励构造
最后,通过归一化和激活函数 ϕ \phi ϕ,将距离转化为 ( 0 , 1 ) (0, 1) (0,1) 区间的稠密奖励 g i g_i gi,实现渐进式奖励构造:
g i = { 1.0 for success trajectory ϕ ( d i − d σ d ) for failed trajectory g_{i}=\begin{cases}1.0 & \text{for success trajectory}\\ \phi(\frac{d_{i}-d}{\sigma_{d}}) & \text{for failed trajectory}\end{cases} gi={1.0ϕ(σddi−d)for success trajectoryfor failed trajectory
Step 5:策略更新
SRPO 沿用了 GRPO 的核心思想,利用当前 Group 内的统计数据 来计算优势。我们将一个 Batch 内采样的 M M M 条轨迹视为一个 Group。我们首先计算这组轨迹奖励的均值 μ g \mu_g μg 和标准差 σ g \sigma_g σg,作为"自指引"的基准:
μ g = 1 M ∑ j = 1 M g j , σ g = 1 M ∑ j = 1 M ( g j − μ g ) 2 + ϵ \mu_g = \frac{1}{M}\sum_{j=1}^M g_j, \quad \sigma_g = \sqrt{\frac{1}{M}\sum_{j=1}^M (g_j - \mu_g)^2 + \epsilon} μg=M1j=1∑Mgj,σg=M1j=1∑M(gj−μg)2+ϵ
其中 ϵ \epsilon ϵ是很小的常数。我们对每条轨迹的奖励 g i g_i gi 进行标准化,得到该轨迹的优势值
A ^ i = g i − μ g σ g \hat{A}_i = \frac{g_i - \mu_g}{\sigma_g} A^i=σggi−μg
通过这种组内归一化,模型不再关心绝对分值,而是关注"我是否比这一批次中的平均水平做得更好"。为了保证策略更新的步幅适中,我们采用 PPO 风格的 Clipped Surrogate Objective:
L t , i C L I P ( θ ) = min ( r i , t ( θ ) A ^ i , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i ) \mathcal{L}{t,i}^{CLIP}(\theta) = \min \left( r{i,t}(\theta)\hat{A}i, \text{clip}(r{i,t}(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_i \right) Lt,iCLIP(θ)=min(ri,t(θ)A^i,clip(ri,t(θ),1−ϵ,1+ϵ)A^i)
其中 r i , t ( θ ) = π θ ( a t ∣ o t , l ) π o l d ( a t ∣ o t , l ) r_{i,t}(\theta) = \frac{\pi_\theta(a_t|o_t, l)}{\pi_{old}(a_t|o_t, l)} ri,t(θ)=πold(at∣ot,l)πθ(at∣ot,l) 。
为了防止策略在强化学习过程中出现"灾难性遗忘"或偏离原始语言能力太远,我们在总目标函数中加入了 KL 散度正则化项:
max θ L S R P O ( θ ) = E t , i L t , i C L I P ( θ ) − β D K L ( π θ ∣ ∣ π r e f ) \max_{\theta} \mathcal{L}{SRPO}(\theta) = \mathbb{E}{t,i} \left \\mathcal{L}_{t,i}\^{CLIP}(\\theta) \\right - \beta D_{KL}(\pi_\theta || \pi_{ref}) θmaxLSRPO(θ)=Et,iLt,iCLIP(θ)−βDKL(πθ∣∣πref)
通过最大化这个目标函数,SRPO 能够在提升任务成功率的同时,保持 VLA 模型基础能力的稳定性。
一句话总结 : 我们提供了一个免费的、即插即用的稠密奖励生成器,无需任何额外训练即可迁移到新任务。这是一个完全 Zero-shot、Task-agnostic 的过程!
4 实验:仿真+真机性能暴涨
4.1 刷新 SOTA
在广泛使用的 LIBERO 基准测试中,SRPO 达到了 99.2% 的成功率。核心发现如下:(1)在线后训练的有效性:采用每个任务单条轨迹训练的 one-shot sft 模型效果不佳,SRPO 在其基础上实现了显著提升,这验证了我们的在线后训练范式通过环境交互来增强策略性能的有效性;(2)我们的方法超越了 SimpleVLA-RL、RLinf 等依赖稀疏结果奖励的基于强化学习的方法、以及 TGRPO 等使用人工设计过程奖励的方案,证明基于预训练世界模型的自参照奖励机制,相较于需要0/1奖励或启发式阶段划分方案能提供更有效的学习信号;(3)我们的方法仅使用第三视角观测和自然语言指令输入,超越了多个使用腕部视角或 3D 输入的基线方案。
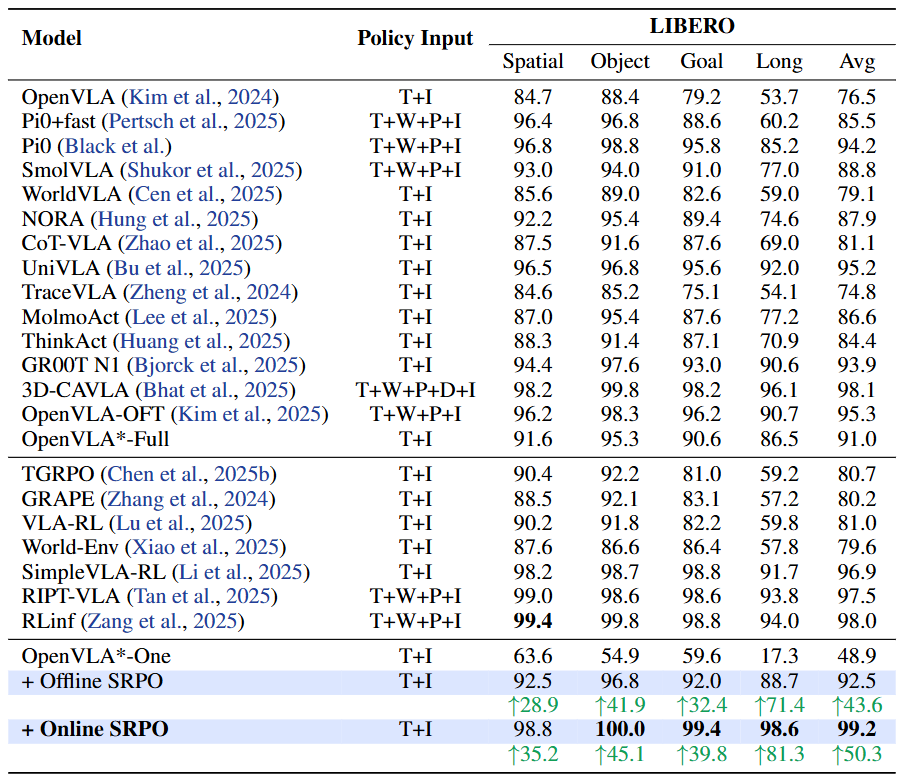
表 1: SRPO 仅通过第三视角观测,在 LIBERO 上取得了 SOTA 性能,超过了主流的 VLA 基础模型和基于强化学习的后训练方法。策略输入符号说明:T (第三视角),I (语言指令),P (本体数据),W (腕部视角),D (深度)。
4.2 更强的泛化性
我们在 LIBERO-Plus 上测试了模型的泛化性能,发现(1)在泛化场景中进行 SRPO 训练的模型相较 one-shot sft 基线性能提升高达 167%,同时超越了使用4000条轨迹训练150k步数的 full-shot sft 基线,证明了方法在泛化场景上的适用性;(2)对于未使用任何泛化场景数据训练的模型,SRPO 方法相较于 full-shot sft 也有提升,说明强化学习的探索能够帮助模型提升泛化性能。
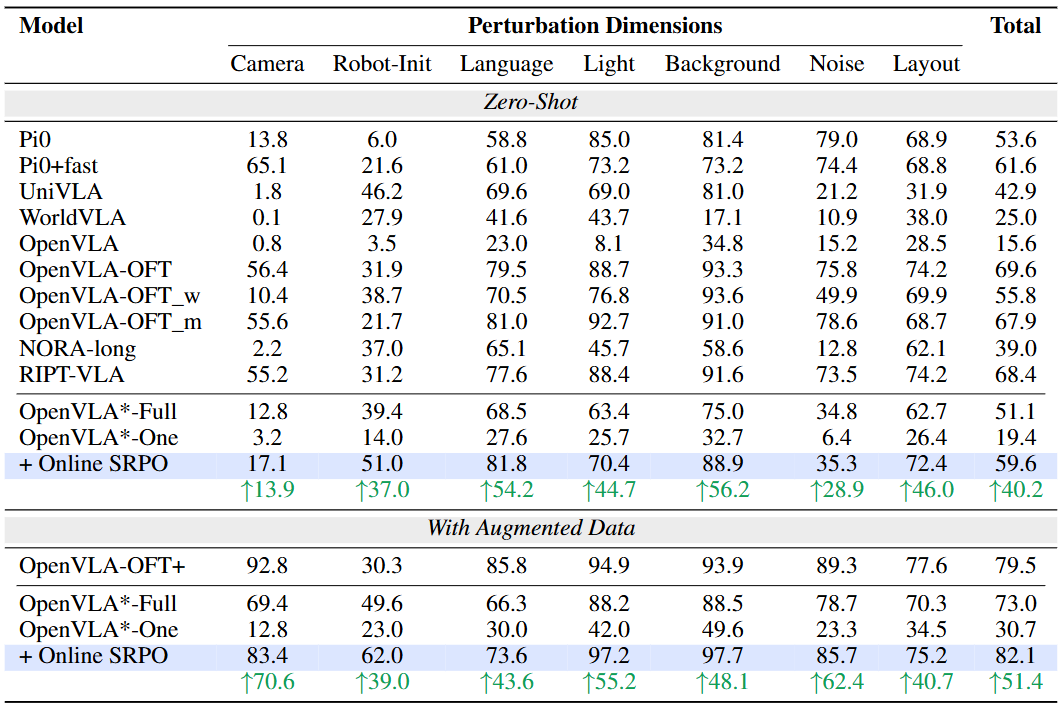
表 2: SRPO 在 LIBERO-Plus 泛化性测试基准上的表现显著优于其基线,还在全部 7 个维度上超过了全样本 SFT 基线,展现出卓越的泛化能力。
4.3 合理的奖励信号
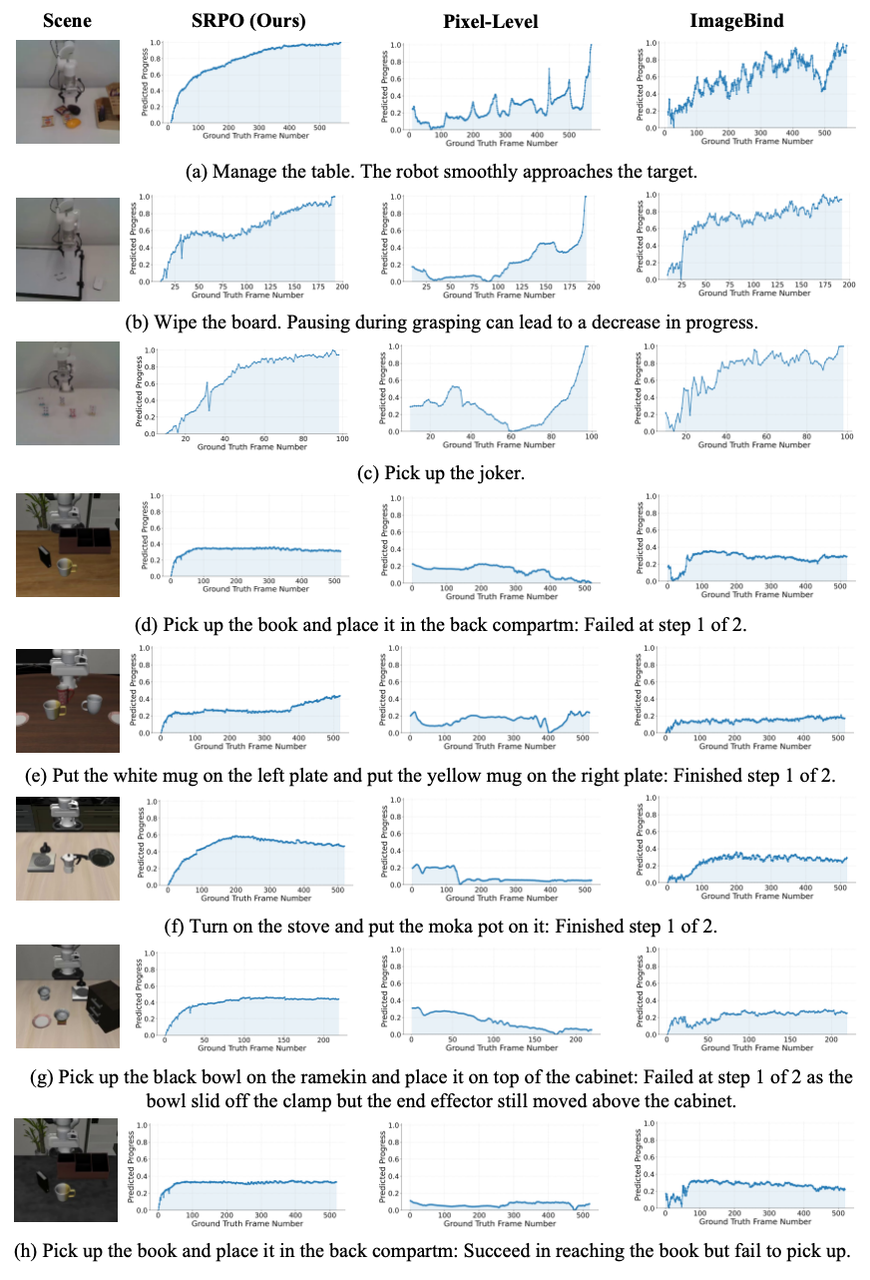
我们将渐进式奖励进行了可视化,分别选取了(1)仿真任务"将马克杯放进微波炉并关闭微波炉门",包含两个时序性的子步骤,与(2)真机任务"收拾桌面",包含五个重复性强的"pick and place"任务。可以看出,Pixel-level 的差异容易受干扰,通用视觉模型难以学习物理规律,但共享的世界模型表征空间天然包含了物理世界的进展示意,因此对于成功轨迹的进展估计与奖励构建更加平滑、合理。
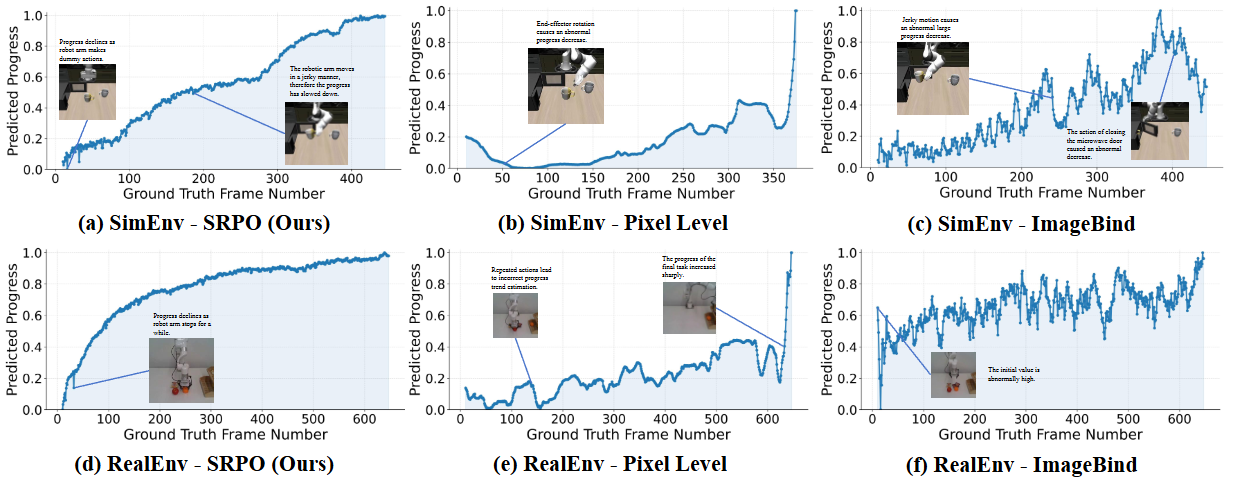
像素级方法基线对感知变化表现出敏感性,而通用视频编码器基线则会因机器人的微小动作呈现出不稳定的振荡。
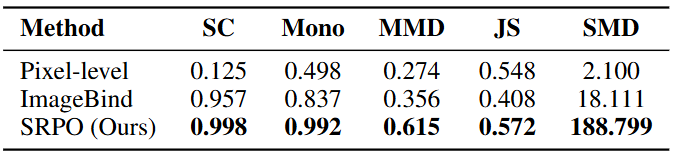
同时,我们构建了五个定量化指标来评估奖励信号,结果表明我们的奖励信号更加平滑,更能区分成功与失败轨迹。
4.4 效率提升
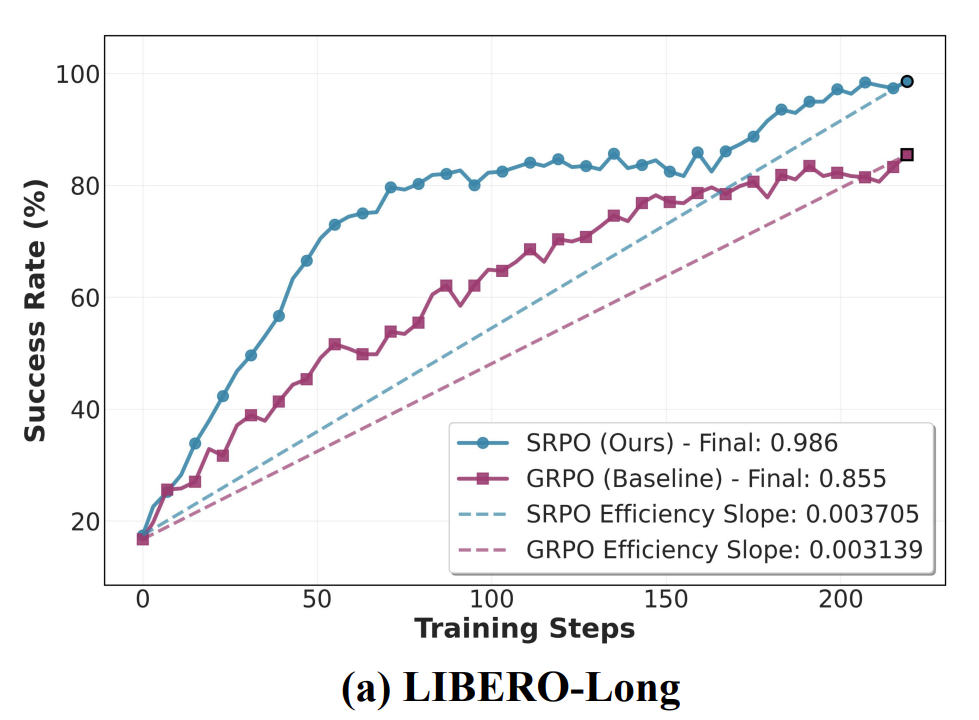
相较于使用 0/1 奖励的 GRPO 方法,我们的方法展现出了更好的效率。具体而言,初始模型仅使用 one-shot 数据进行微调,成功率仅 17.3%,而我们的方法仅需 219 步就能将表现提高到 98.6%,相较于同期的 GRPO 有 15.3% 的性能增长。特别是在训练初期失败轨迹较多的情况下,该效率优势尤为显著,说明充分利用失败轨迹可以带来可观的效能增益。
4.5 真机实测:提升显著
SRPO 不仅在仿真中有效,更是一套真机可迁移方案。我们在真机上针对开源模型 π 0 \pi_0 π0 和 π 0 \pi_0 π0-fast 进行了测试,成功率相对 SFT 分别提升 66.8% 和 86.7%。这意味着 SRPO 的奖励建模机制可以作为一个通用的插件,显著增强现有 VLA 模型的真机操作能力。
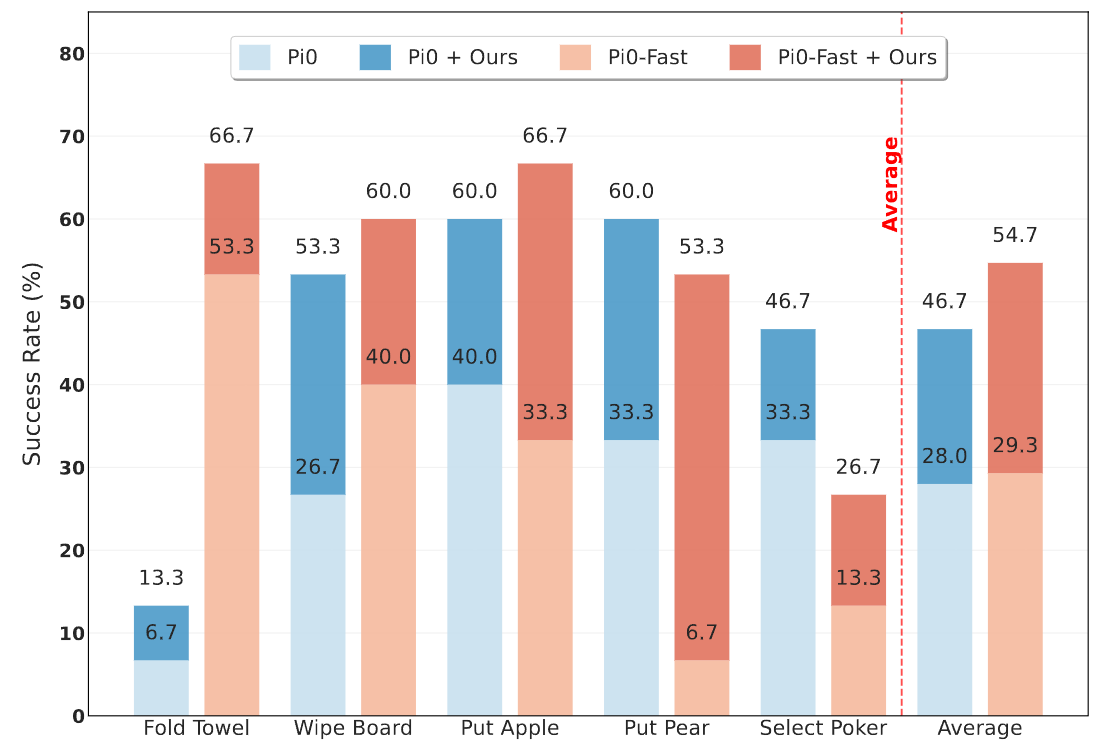
5 奖励信号可视化
为了直观展示不同奖励设计在任务中的表现,我们进行了一系列可视化对比分析。下图包含3个成功轨迹与5个失败轨迹,可以看出:(1)我们的方法生成的奖励信号在合理性与稳定性上均显著优于基线方法,特别是对于包含重复操作的较长程任务,我们的奖励较少受到重复视觉观测的干扰,(2)对于多步骤任务,我们的奖励可以根据大致的步骤完成情况给出相应的渐进式奖励。
6 结语
SRPO 为 VLA 的强化学习提供了一条高效、低成本的新路径。我们不需要昂贵的 Value Model 训练,只需要利用模型自身的成功经验和对物理世界的通用理解,就能实现性能与效率的飞升。无论你是想提升仿真跑分,还是想改善真机性能,SRPO 都是一个值得尝试的通用框架。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?