AlexNet:点燃深度学习革命的那把火
作者:Weisian | AI探索者 · 软件工程师 · 写给每一个想看懂AI如何"觉醒"的你
引言:一场比赛,一个模型,改写AI的命运
2012年,加拿大多伦多大学的一间实验室里,三个年轻人提交了一个名叫 AlexNet 的神经网络模型,参加了一场看似普通的图像识别竞赛。
没人想到,这个模型会以压倒性优势横扫全场 ------
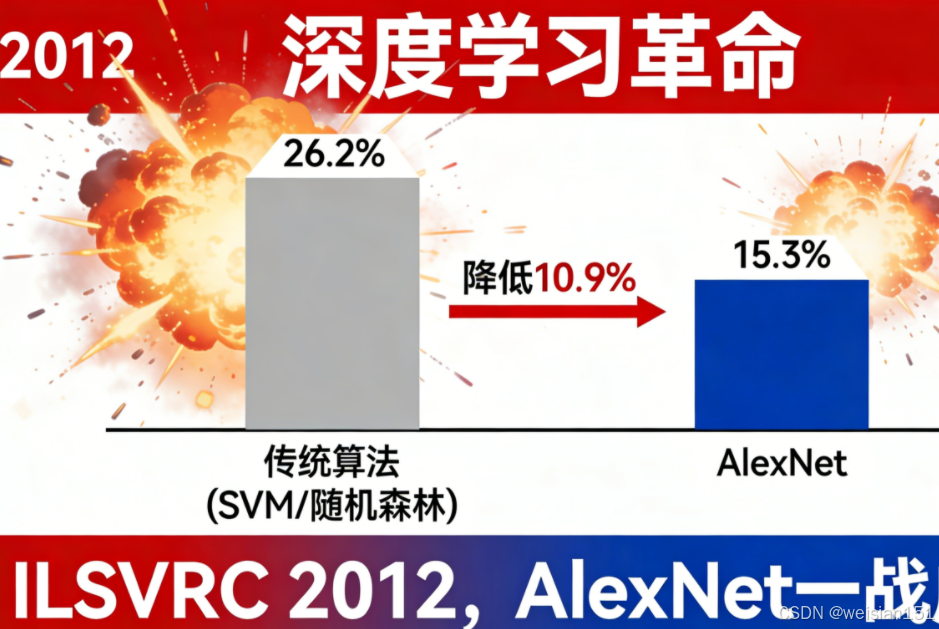
它把图像分类错误率从 26% 一举砍到 15% ,领先第二名整整 10个百分点。
更没人想到,这场胜利会成为深度学习时代的起点 。
从此,AI不再只是学术圈的玩具,而是真正开始"看见"世界。
今天,当你用手机拍照识物、刷短视频被精准推荐,甚至和AI聊天时背后调用的视觉能力,都或多或少流淌着 AlexNet 的基因。
那么------
AlexNet 到底是什么?它凭什么引爆AI革命?它的设计思想对今天的我们还有意义吗?
别担心,这篇文章不堆公式、不炫术语,只用清晰的逻辑和人性化的语言,带你完整读懂这个"改变AI历史的里程碑模型"。
一、AlexNet诞生的时代土壤
任何伟大的技术突破,都不是凭空而来。AlexNet 的出现,是 数据、算力、算法 三大要素在恰当时机交汇的必然结果。
1.1 AI的"寒冬余温":传统方法走到尽头
20世纪末至21世纪初,AI经历了两次"寒冬",核心原因在于:
- 主流方法依赖 手工设计特征 + 简单分类器(如SVM、随机森林);
- 面对真实世界的复杂图像(不同光照、角度、遮挡),这些方法表现极差;
- 虽然神经网络理论早已存在(如1986年反向传播、1998年LeNet-5),但受限于两大瓶颈:
- 数据不足:没有大规模标注图像,深层网络无法有效学习;
- 算力不够:CPU训练速度慢,训练一个深层模型需数周,几乎不可行。
1.2 两大"神助攻"铺平道路
就在AI陷入僵局时,两个关键事件悄然发生:
- 2009年:ImageNet发布
李飞飞团队构建了包含 1400万张标注图像、1000个类别 的数据集,首次为深层网络提供了充足的"学习教材"。 - 2006年:CUDA框架推出
NVIDIA 让 GPU 从"游戏显卡"变身"并行计算引擎",训练速度提升数十倍。
有了数据和算力,就差一个能驾驭它们的模型------而 AlexNet,正是那个"天选之人"。
1.3 历史契机:2012年 ImageNet 挑战赛
AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 团队研发,目标直指 ILSVRC 2012 。
任务很简单:给一张图,从1000类中选出最可能的5个(Top-5准确率)。
结果震撼全场:
- 传统方法错误率:26.2%
- AlexNet 错误率:15.3%
这一胜,不仅赢了比赛,更点燃了深度学习的燎原之火,让所有人看到了深度学习的巨大潜力,直接引爆了全球深度学习的研发热潮。
二、AlexNet 是什么?不只是"一个神经网络"
很多人一听"深层网络"就望而生畏,但 AlexNet 的架构其实逻辑清晰、层次分明。
2.1 基本定义
- 输入:227×227 的彩色图像
- 输出:1000个类别的预测概率(如"金毛犬""笔记本电脑")
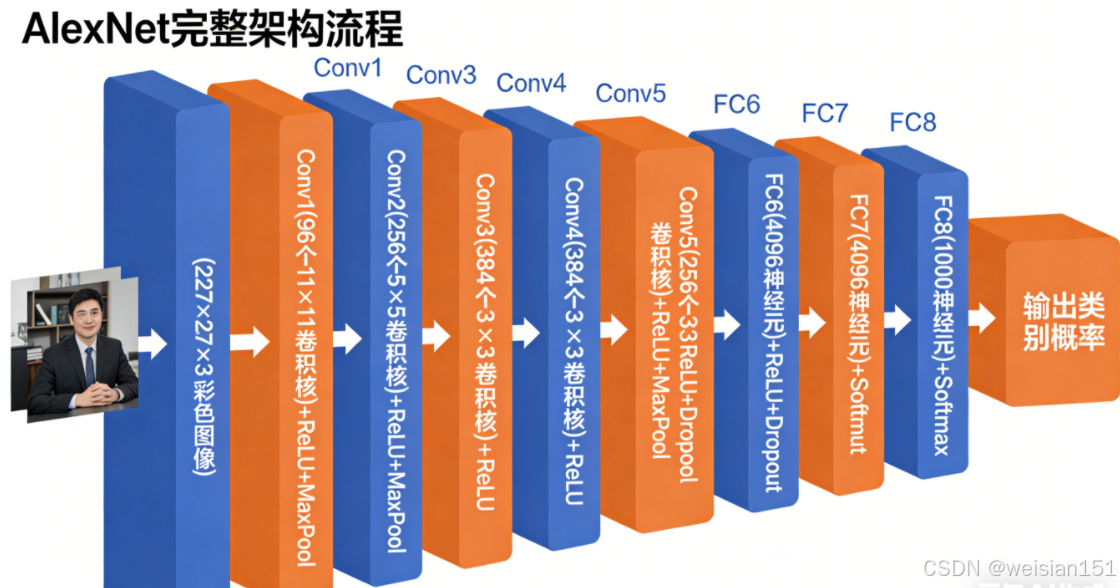
- 结构:8层(5卷积 + 3全连接)
- 参数量 :约 6000万
- 背景:专为 ImageNet 挑战赛设计,是当时最大、最深的 CNN。
💡 在2012年,这已是"巨无霸"级别的模型。
2.2 架构流程:像工厂一样"加工"图像
我们可以把 AlexNet 想象成一条智能流水线:
原始图像 → 卷积层(提取边缘/纹理)→ ReLU(激活有用信号)→ 池化层(压缩+筛选)
→ 多轮深度加工(提取部件/整体)→ 全连接层(综合判断)→ Dropout(防死记硬背)→ 输出类别具体结构如下:
输入 (227×227×3)
│
├─ Conv1 → ReLU → MaxPool → LRN
├─ Conv2 → ReLU → MaxPool → LRN
├─ Conv3 → ReLU
├─ Conv4 → ReLU
├─ Conv5 → ReLU → MaxPool
│
├─ FC6 → ReLU → Dropout
├─ FC7 → ReLU → Dropout
└─ FC8 → Softmax → 输出(1000类)2.3 关键组件大白话解释
- 卷积层(Conv):用"探测器"扫描图像,提取局部特征(如边缘、角点、纹理);
- ReLU 激活函数:把负值归零,正数保留------简单高效,解决梯度消失问题;
- 池化层(MaxPool):取局部最大值,压缩数据、保留关键信息;
- 全连接层(FC):整合所有特征,做最终分类决策;
- Dropout:训练时随机"关掉"一半神经元,防止模型死记硬背;
- LRN(局部响应归一化):早期尝试模拟生物神经抑制,后被 BatchNorm 取代。
🔍 有趣细节:
论文中写道:"我们不确定 LRN 是否真的有用,但比赛要紧,先加上再说。"
------科研的真实,往往藏在这些"临时决策"里。
2.4 它曾不被看好
投稿 NIPS 时,审稿人甚至怀疑:"是不是代码写错了?"
因为没人相信,一个纯靠数据驱动的深层网络,能打败精心调优的传统算法。
但结果证明:它不仅没错,反而开启了一个新时代。
三、五大关键技术突破:为什么 AlexNet 能碾压对手?
AlexNet 的成功,不是靠单一黑科技,而是系统性工程创新的集中体现。
3.1 ReLU 激活函数:让深层网络"活"起来
- 替代 Sigmoid/Tanh,避免梯度消失;举个直观的对比:用Sigmoid函数训练10层以上的网络,梯度会衰减到几乎为0;而用ReLU函数,梯度能有效传递到浅层,让10层、20层的深层网络都能正常训练。直到今天,ReLU依然是深度学习中最常用的激活函数之一。
- 训练速度提升数倍,使8层网络首次可有效收敛。
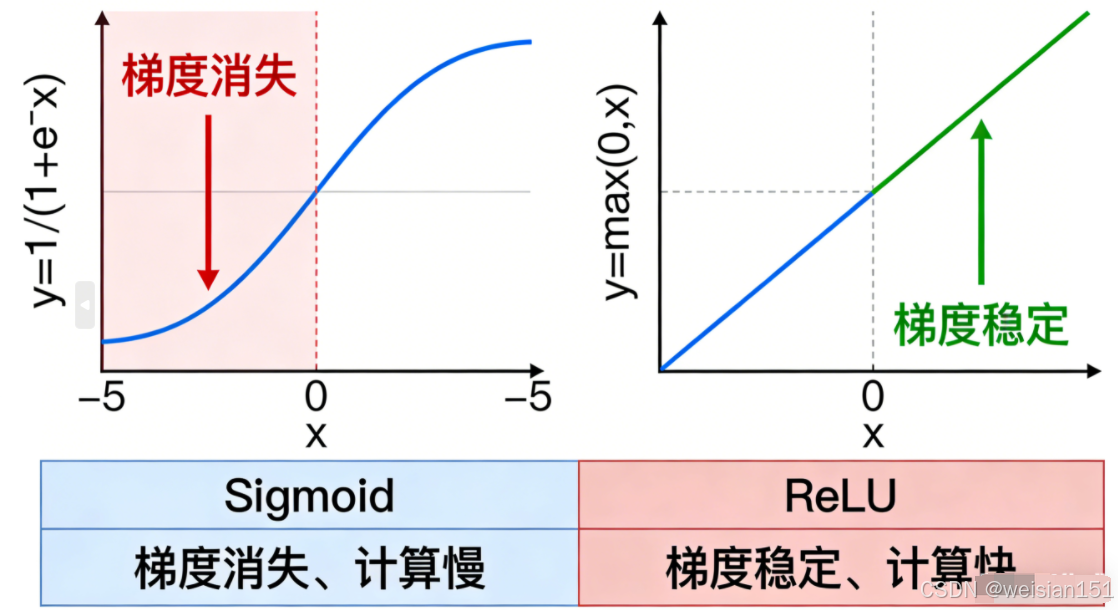
💡 类比:给神经元装了个"单向开关"------有信号就通,没信号就关。
3.2 GPU 并行训练:算力的第一次"破壁"
- 使用 两块 GTX 580 GPU ,将训练时间从几周缩短到 5--6天; 用当时的CPU训练需要几周时间;
- 直接推动 GPU 成为 AI 训练的标准硬件。
🌟 启示:算法 + 数据 + 算力 = 技术革命的铁三角。
3.3 Dropout:对抗过拟合的"神来之笔"
- 训练时随机屏蔽50%神经元,强制模型学习通用特征;
- 测试时全部启用,并缩放输出,实现"隐式集成"。
- 成为后续所有深层网络的标配正则化手段。
3.4 重叠池化(Overlapping Pooling)
- 采用 3×3 池化窗口,步长=2,形成重叠区域;
- 减少信息损失,略微提升准确率。
3.5 数据增强(Data Augmentation)
- 随机裁剪:把256×256的图像随机裁剪成227×227,增加图像的角度和位置多样性;
- 水平翻转:把图像左右翻转,比如"猫"的图像翻转后依然是猫,让模型不受左右方向的影响;
- 颜色抖动 :随机调整图像的亮度、对比度、饱和度,让模型适应不同光照条件。
→ 用有限数据"生成"更多样本,显著提升泛化能力。让AlexNet能学习到更通用的特征,在真实场景中的识别准确率大幅提升。
✅ 总结:
AlexNet 不是靠奇迹,而是系统性工程创新------从激活函数到硬件部署,每一步都踩在时代痛点上 。
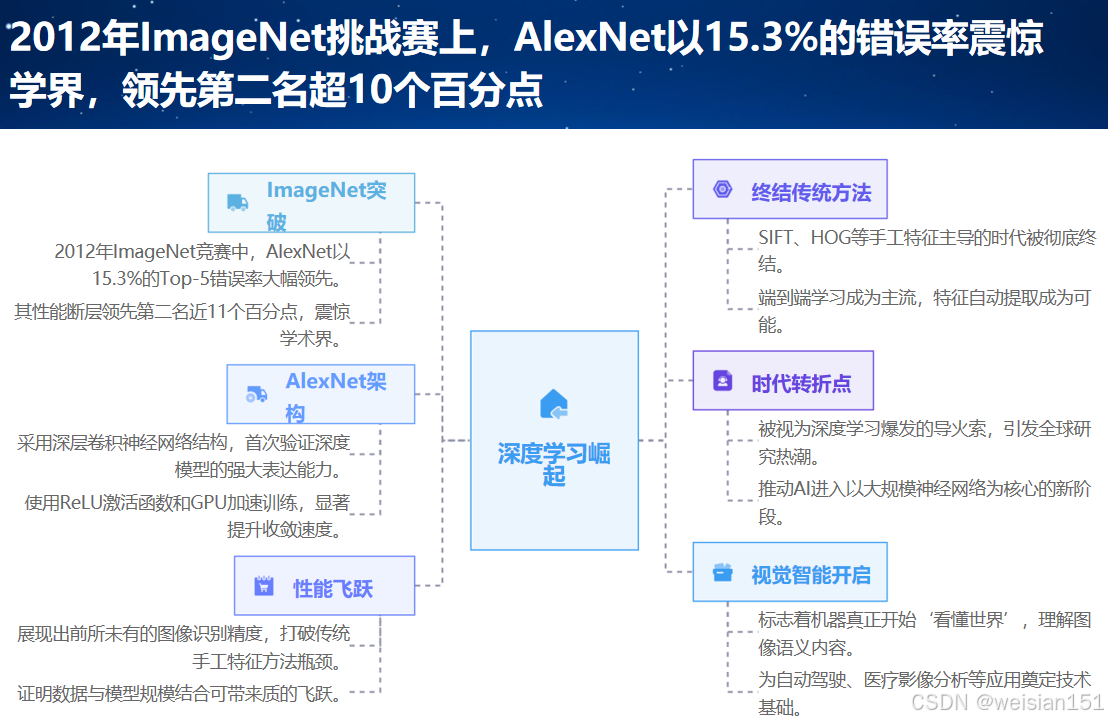
四、AlexNet 的历史地位:它如何改写AI轨迹?
AlexNet 的意义,远超一场竞赛的胜利。它奠定了现代AI的四大基石。
4.1 第一次证明深度学习的有效性
在AlexNet之前,很多学界大佬都质疑"深层网络是不是噱头"。而AlexNet用 15.3% vs 26.2% 的碾压性优势,终结了"深层网络是否可行"的争论,用无可辩驳的成绩证明:只要有足够的数据和算力,深层网络在复杂任务上的表现远超传统算法。
这一结论直接点燃了全球学界和工业界对深度学习的热情,科研经费、人才纷纷涌入AI领域,AI正式走出"寒冬",进入爆发式增长期。
4.2 奠定 CNN 的经典范式
"卷积 + ReLU + 池化 + 全连接 + Dropout" 成为后续所有视觉模型的标准模板:
- VGG:小卷积核 + 深层堆叠
- ResNet:残差连接解决退化
- GoogLeNet:多尺度并行结构
可以说,没有AlexNet的架构范式,就没有后续计算机视觉的快速发展。
4.3 推动 GPU 成为 AI 基础设施
从"游戏显卡"到"AI芯片",NVIDIA 的崛起始于 AlexNet 的示范效应。
AlexNet用GPU并行训练的做法,让所有人看到了GPU在AI领域的潜力。今天的大模型训练集群,依然延续这一路径。此后,NVIDIA开始重点布局AI芯片,推出了一系列针对深度学习的GPU(比如Tesla系列),并完善了CUDA生态。
4.4 开启"数据驱动"的AI新时代
AlexNet的成功,让整个行业意识到"数据的重要性"。在此之前,大家更关注"如何设计更好的算法";而AlexNet之后,大家开始疯狂构建大规模标注数据集。
比如后续的COCO数据集(用于目标检测、语义分割)、KITTI数据集(用于自动驾驶)、ChestX-ray数据集(用于医学影像识别)等,都是在ImageNet的基础上发展的。"数据+算法+算力"的铁三角,也从这时开始成为AI发展的核心驱动力。
"数据即燃料" 的理念由此深入人心。
| 技术 | AlexNet 的贡献 | 今日应用 |
|---|---|---|
| ReLU | 首次大规模验证有效性 | 几乎所有现代网络标配 |
| Dropout | 提出实用正则化方法 | 广泛用于全连接层 |
| GPU训练 | 证明并行计算可行性 | AI训练基础设施 |
| 端到端学习 | 无需手工特征 | CV/NLP/语音通用范式 |
| 数据增强 | 系统化使用 | 训练流程标配 |
甚至 Transformer、Diffusion 模型,也继承了"大数据+深层结构+端到端优化"的核心哲学。
五、普通人如何学习和体验 AlexNet?
5.1 动手复现(强烈推荐!)
PyTorch / TensorFlow 均内置 AlexNet,你也可以用 CIFAR-10 微调简化版:
python
import torchvision.models as models
alexnet = models.alexnet(pretrained=True) # 加载预训练权重完整简化版代码(适配 CIFAR-10):
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 1. 定义简化版AlexNet模型
class AlexNet(nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
# 特征提取部分:卷积+ReLU+池化
self.features = nn.Sequential(
# Conv1 + ReLU + MaxPool
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Conv2 + ReLU + MaxPool
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Conv3 + ReLU
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv4 + ReLU
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# Conv5 + ReLU + MaxPool
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 分类部分:全连接+Dropout
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096), # 输入维度:256通道×6×6特征图
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes), # 输出10个类别
)
def forward(self, x):
x = self.features(x) # 特征提取
x = torch.flatten(x, 1) # 展平特征图,输入全连接层
x = self.classifier(x) # 分类
return x
# 2. 数据预处理与加载(适配CIFAR-10)
transform = transforms.Compose([
transforms.Resize((227, 227)), # 调整图像尺寸到AlexNet要求的227×227
transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 加载CIFAR-10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
# 3. 模型初始化与训练配置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 优先用GPU
model = AlexNet(num_classes=10).to(device)
criterion = nn.CrossEntropyLoss() # 分类损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4) # 优化器
# 4. 训练函数
def train(epoch):
model.train()
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader, 0):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
if i % 100 == 99: # 每100个批次打印一次损失
print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
# 5. 测试函数
def test():
model.eval()
correct = 0
total = 0
with torch.no_grad(): # 测试时不计算梯度
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) # 获取预测类别
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'测试集准确率: {100 * correct / total} %')
# 6. 启动训练(10个epoch)
for epoch in range(10):
train(epoch)
test()
print('训练完成!')✅ 效果 :10个 epoch 后,CIFAR-10 准确率可达 80%+,远超传统方法。
代码说明:
- 模型定义:严格遵循AlexNet的"卷积+ReLU+池化+全连接+Dropout"架构,只是调整了输出类别(从1000类改为10类,适配CIFAR-10);
- 数据预处理:把CIFAR-10的32×32图像调整到227×227(AlexNet的输入尺寸),加入随机水平翻转做数据增强;
- 训练配置:用SGD优化器(带动量,加速收敛),权重衰减防止过拟合;
- 效果:训练10个epoch后,在CIFAR-10测试集上的准确率能达到80%以上,远超传统算法。
5.2 学习建议
- 先掌握 CNN 基础(卷积、池化、激活);
- 对比 LeNet-5(1998) 与 AlexNet,体会"深度"的价值;
- 尝试 关闭 ReLU 或 Dropout,观察性能变化------亲手验证,印象最深。
5.3 思维启发
- 工程思维至关重要:AlexNet 是理论与工程的完美结合;
- 敢于挑战主流:在 SVM 统治时代坚持神经网络,需要极大勇气;
- 技术是累积的:它站在 LeNet 的肩膀上,又为 ResNet 铺路。
六、反思与局限:为何 AlexNet 后来被超越?
尽管是里程碑,AlexNet 仍有明显短板,这也正是后续模型的改进方向:
| 局限 | 后续解决方案 |
|---|---|
| 网络深度有限:只有8层,无法提取更复杂的特征(比如ResNet有152层,能学习到更精细的语义特征) | ResNet 引入残差连接,支持百层以上 |
| 超参数手动设计:卷积核尺寸(11×11、5×5)、数量(96、256)等都是人工调整的,缺乏通用性,换个数据集可能就需要重新调参 | 自动架构搜索(NAS)、通用设计原则 |
| 全连接层参数过多:FC6和FC7有8000多万个参数,占整个模型参数的90%以上,计算量大,容易过拟合 | 全局平均池化(GoogLeNet)、轻量化设计 |
| 没有解决梯度消失的终极问题:虽然ReLU缓解了梯度消失,但当网络层数超过10层时,梯度消失问题会再次出现(直到ResNet的残差连接才彻底解决) | BatchNorm、残差结构 |
更重要的是,它的成功高度依赖 ImageNet 和 GPU ------
若缺其一,奇迹或许不会发生。
🤔 启示 :
伟大创新,需要 天时(数据)、地利(算力)、人和(团队) 的完美共振。
结语:火种不灭,照亮前路
- AlexNet不是第一个卷积神经网络(第一个是1998年的LeNet-5),也不是最复杂的模型(现在的大模型有上千层),但它却是深度学习的"引爆点"。
- 它用无可辩驳的成绩,证明了深度学习的巨大潜力;它奠定的CNN范式,影响了后续十年的计算机视觉发展;它推动的GPU算力革命,为今天的大模型时代埋下了伏笔。
- 对于新手来说,理解AlexNet的核心逻辑------用卷积提取特征、用ReLU解决梯度消失、用Dropout防止过拟合、用GPU提升效率------是入门计算机视觉的必经之路。

时至今日,AlexNet 早已不是最先进的模型,
但它点燃的那把火,至今仍在照亮 AI 的前路。
它告诉我们:
伟大的突破,往往始于一个"不被看好"的想法,
加上一群"不信邪"的人,
在一个"恰到好处"的时机。
今天,我们或许在训练百亿参数的大模型,
但回望2012年那个用两块游戏显卡跑出奇迹的夜晚 ,
依然能感受到------
技术革命的起点,常常朴素而坚定。
记住 :
不是 AlexNet 多完美,而是它敢迈出那一步 。
而你,也可以。
互动时间 :
你第一次听说 AlexNet 是什么时候?有没有尝试复现过它?欢迎在评论区聊聊你的故事!
我是 Weisian,持续为你拆解 AI 背后的逻辑与温度。