DINO
自蒸馏学习(SSL)得到VIT
自监督学习的VIT比监督学习的VIT具有明显不同,密集特征中包含图像的定位和边界信息,这在监督VIT中是没有出现的。
DINOv1
教师和学生网络,共享相同架构 ,教师采用学生网络参数的指数平均 进行更新。
输入图像的大小不同 ,教师两张全图,学生多张局部。
训练目的是最小化二者输出的CLS特征的分布差异 ,使用CE进行优化 。
教师网络的输出特征经过中心化处理 。


DINOv2
注重数据规模化,极大的扩充了数据集,提高数据质量
引入了patch级损失,显示增强patch的区分能力

训练末期使用一段时间的高分辨率
使用正则化 ,用于高效划分特征空间 。
教师网络输出的中心化方法也得到了探讨。

| 维度 | DINOv1 | DINOv2 |
|---|---|---|
| 论文定位 | 发现现象 | 构建 foundation feature |
| 训练目标 | CLS-level DINO | DINO + iBOT(patch-level) |
| 数据 | ImageNet | Curated + 检索扩增 142M |
| 特征几何 | 无显式约束 | KoLeo |
| Dense 能力 | 偶然涌现 | 显式优化 |
| 工程 scale | 不考虑 | 核心贡献 |
| 是否"冻结即用" | 部分 | 是(设计目标) |
下面按你给的框架,对论文 "Emerging Properties in Self-Supervised Vision Transformers" (Caron et al., 2021; DINO) 的方法部分做"读懂+可复现"的深度拆解,并结合文中关键实验/消融给出对比与建议。
DINOv3
0. 翻译摘要原文
论文探讨:自监督学习是否会让 Vision Transformer(ViT)产生一些相比卷积网络(ConvNet)更独特/更显著的性质。作者观察到两点:
- 自监督训练的 ViT 特征显式包含语义分割相关信息 (场景布局、物体边界),这种性质在监督训练的 ViT 和ConvNet 中都不那么明显;并且这种信息可以从 ViT 最后一层 self-attention中直接读出来(图1)。
- 这些自监督 ViT 特征做 k-NN 分类非常强 :小 ViT 在 ImageNet 上能到 78.3% top-1。
论文进一步强调:动量教师(momentum encoder) 、multi-crop 、以及 小 patch(如 8×8) 对 ViT 的自监督特征质量很关键。基于这些发现,作者提出一个简单的自监督方法 DINO ,可理解为无标签自蒸馏(self-distillation with no labels) :学生网络预测教师网络输出,用交叉熵对齐;教师由学生的 EMA 得到,并通过centering+sharpening 避免塌陷。最终 DINO+ViT-B 在 ImageNet 线性评估达到 80.1% top-1。
1. 方法动机
1a) 为什么提出这个方法(驱动力)
核心驱动力是一个"反直觉"的问题:ViT 在监督预训练下并没有比 ConvNet 显著更强的独特优势 ,甚至更吃数据、更贵;那是不是"问题出在监督信号太弱/太粗"?
作者类比 NLP:Transformer 在 NLP 真正爆发依赖的是 自监督预训练 (BERT/GPT),因为自监督任务提供更丰富的学习信号,而图像监督往往把一张图压成"一个类别标签",信息量很低。于是他们想验证:ViT 在自监督下是否会涌现出新的性质(尤其是"结构化/布局感知"的能力)。
1b) 现有方法痛点/不足(具体局限)
从论文叙事里,痛点可以概括为三条:
- 监督预训练的视觉模型学习信号贫乏:图像级 label 让丰富场景信息被压扁。
- 已有自监督框架移植到 ViT 未必能把 ViT 的潜力"激发出来":需要搞清楚哪些组件对 ViT 特别关键(比如 momentum、multi-crop、patch size)。
- 避免塌陷(collapse)机制复杂:对比学习要大 batch / memory bank;BYOL 依赖 predictor / BN 等,工程负担大;作者希望找一个更"干净、架构无侵入"的机制。
1c) 研究假设/直觉(一句话版)
如果用自监督训练 ViT,让模型对齐不同视角下的"软目标分布",ViT 的自注意力会显式编码场景布局与对象边界,并且得到对 k-NN 特别友好的特征空间。
2. 方法设计(重点:非常细的 pipeline)
这篇的"方法"其实由两层组成:
- 训练目标:DINO(无标签自蒸馏)
- 输入视角构造:multi-crop + local-to-global 对齐
- 稳定训练:momentum teacher + centering + sharpening
- 网络形态:backbone + projection head(BN-free for ViT)
下面按"输入→处理→输出"走一遍完整前向/训练步骤。
2a) Pipeline:输入→处理→输出(逐步细化)
Step 0:准备网络
- 两个网络:student (g_{\theta_s}) 与 teacher (g_{\theta_t})
- 二者结构完全相同(这一点很关键:不是大老师教小学生;更像"自举式自蒸馏")。
网络 (g) = backbone (f) (ViT 或 ResNet) + projection head (h) :
g = h \\circ f
下游任务通常用 backbone 输出特征(尤其 ViT 的 CLS token 或其组合)。
Step 1:对每张图片做 multi-crop 生成多视角集合 V
对一张原图 (x),采样多种随机增强得到视角集合 (V):
- 2 个 global crops:分辨率 224×224,覆盖原图较大区域
- 多个 local crops:分辨率 96×96,覆盖较小区域
- student 吃所有 views ;teacher 只吃 global views(这是"local-to-global correspondences"的核心机制:用小局部去对齐全局语义)。
Step 2:前向计算 logits(未归一化输出)
- student 对每个 view 输出 logits:(s = g_{\theta_s}(x'))
- teacher 对 global views 输出 logits:(t = g_{\theta_t}(x^g))
这里 logits 维度是 (K)(论文常用很大的 K,如 65536,作为"原型维度/输出维度",但它不是分类 label)。
Step 3:把 logits 变成"概率分布"(关键:student / teacher 温度不同)
student 概率:
P_s(x)(i) = \\frac{\\exp(s_i / \\tau_s)}{\\sum_k \\exp(s_k / \\tau_s)}
teacher 概率类似,但会先做 centering 再用 teacher 温度 (\tau_t) 做 softmax。
- (\tau_s) 通常固定(文中给了常用值 0.1)
- (\tau_t) 更小(更"尖锐"),并且常用 warmup(例如从 0.04 到 0.07 的线性 warm-up)来保证稳定。
Step 4:teacher 输出做 centering(避免某一维占主导)
teacher 的 logits 先减去一个 center 向量 ©:
t' = t - C
其中 © 通过 EMA 更新(按 batch 的 teacher 输出均值更新):
C \\leftarrow mC + (1-m)\\cdot \\frac{1}{B}\\sum_{i=1}\^B g_{\\theta_t}(x_i)
这一步的直觉是:把 teacher 输出分布在 batch 维度上"拉回中心",避免单维度塌陷。
Step 5:计算自蒸馏损失(cross-entropy,对齐 teacher→student)
对每个 teacher global view (x \in {x^g_1, x^g_2}),以及 student 的每个 view (x' \in V, x'\neq x),做交叉熵:
\\mathcal{L}=\\sum_{x \\in {x^g_1,x^g_2}}\\ \\sum_{x'\\in V, x'\\neq x} H(P_t(x), P_s(x'))
其中 (H(a,b)=-a\log b)。
实现上 teacher 分支 stop-gradient:只更新 student。
这一步是 DINO 的"核心学习信号":
- teacher 用全局 view 给出"软语义目标"
- student 必须让局部/全局不同视角都对齐到这个目标
→ 促使模型学习到"跨尺度一致的语义结构",这也是后面 attention 出现"分割感"的重要原因之一。
Step 6:参数更新(student 用 SGD/AdamW;teacher 用 EMA)
- student:常规反向传播更新
- teacher:不反传梯度,而是用 EMA 从 student 更新:
\\theta_t \\leftarrow \\lambda \\theta_t + (1-\\lambda)\\theta_s
(\lambda) 往往采用 cosine schedule(从 0.996 到 1)。
作者强调:直接复制 student 给 teacher 会崩;"上一个 epoch 的 student 当 teacher"能跑但性能不如 EMA teacher。
Step 7:输出(训练后你真正用的特征)
训练完成后,下游任务用 backbone (f) 的输出特征:
- ViT:常用 CLS token(k-NN、线性评估等);线性评估中还尝试 concat 最后若干层的 CLS
- Dense 任务:会使用 patch tokens(论文在 DAVIS、attention mask probing 等用到了它们)
2b) 模型结构模块解释:各模块功能与协同
(1) Student/Teacher 双塔(同构)
- 目的:构造"自蒸馏目标",让学习信号来自模型自身的"时间集成版本",而不是 label 或负样本队列。
(2) Momentum teacher(EMA)
- 功能:提供更稳定、更强的目标分布。论文有个很关键的现象:teacher 在训练全过程中始终优于 student(k-NN 评估),从而形成良性"强者教弱者"的动态。
(3) Multi-crop + 只给 teacher 喂 global view
- 功能:迫使学生从局部视角也能对齐全局语义,学习到更强的 spatial/part-level 语义一致性。论文也指出 multi-crop 对 DINO 的提升非常明显。
(4) Centering + Sharpening
-
功能:这是 DINO 用来避免塌陷的关键组合。
- centering:防"单维主导"但会推向"均匀分布塌陷"
- sharpening(小 (\tau_t)):防"均匀塌陷"但可能推向"单峰极端"
- 两者组合平衡,配合 momentum teacher 即可稳定训练(作者甚至强调不需要 predictor、复杂 BN 等也能跑)。
(5) Projection head(带 l2 bottleneck + weight norm + 大 K)
- 功能:让训练目标空间更合适(类似很多 SSL 都需要 projection head 才能把"训练空间"和"可迁移空间"分开)。
- DINO 特别强调:l2-normalization bottleneck 对深 head 的稳定很重要 ;并且 ViT 情况下可以做到 BN-free。
2c) 公式/算法通俗解释(你需要记住的"意义")
- Eq.(3) multi-view CE loss:让不同 view(尤其 local)预测 global teacher 的软分布 → 强化跨尺度语义一致性。
- Eq.(4) center EMA:在 batch 统计上对 teacher logits 做"去偏置",抑制某些维度被长期占据。
- teacher EMA:把 teacher 变成 student 的"时间集成模型",相当于训练过程中的在线集成(类似 mean teacher/Polyak averaging 的作用)。
3. 与其他方法对比
3a) 本方法与主流方法的本质不同
从"避免塌陷 / 学习信号来源"角度:
- 对比学习(MoCo/SimCLR) :靠 正负样本对比 + 大 batch/queue/memory bank,核心约束来自"区分实例"。
- BYOL/SimSiam 类 :不用显式负样本,但常依赖 predictor + stop-grad 等机制。
- SwAV/DeepCluster 类 :用 聚类/分配约束(如 Sinkhorn-Knopp)来防塌陷。
DINO 的独特点:
- 学习信号是teacher 的软分布(不是 one-hot label,也不是负样本对比)。
- 防塌陷主要靠 momentum teacher + centering + sharpening(不要求 BN、predictor 也能稳定)。
- 对 ViT 的"attention 可解释布局/分割"涌现现象尤其突出(论文主打"emerging properties")。
3b) 创新点(贡献度明确)
我认为论文的贡献按"贡献强度"排序大致是:
- 发现性贡献:自监督 ViT 的 self-attention 显式携带对象边界/布局信息,且比监督 ViT 更明显(图1、图4、图10;并在 VOC 上用阈值 attention 做 Jaccard 定量)。
- 方法性贡献:提出 DINO:一种简单的"无标签自蒸馏"框架(同构 student/teacher,CE 对齐软分布,EMA teacher)。
- 工程/经验贡献 :系统性强调并验证 momentum、multi-crop、小 patch 对 ViT 自监督的关键性,并给出 ablation(表7、图5、表8等)。
3c) 更适用的场景(适用范围)
更适用:
- 你需要强表征且标签稀缺/没有标签(通用预训练)。
- 下游是检索/匹配/k-NN 友好的任务(论文显示 DINO+ViT 的 k-NN 非常强,且在检索/拷贝检测上表现突出)。
- 你关心 dense/布局相关能力(比如弱监督分割、视频目标分割里的跟踪式匹配),因为 patch tokens + attention 有明显空间信息保留。
不那么适用 / 成本点:
- 训练成本仍不低(尤其小 patch + 多 crop 会显著增加 token 数与显存/吞吐压力;表8直接量化了时间/显存 trade-off)。
3d) 表格总结方法对比(优点/缺点/改进点)
| 方法范式 | 代表方法 | 核心学习信号 | 防塌陷机制 | 优点 | 缺点/代价 | 可能的改进点 |
|---|---|---|---|---|---|---|
| 对比学习 | MoCo v2 / SimCLR | 正负样本对比(InfoNCE) | 大 batch / queue / memory bank | 稳健、理论直观 | 工程重;对 batch/队列敏感 | 更轻量的负样本替代;更适配 ViT 的 token 级对比 |
| 无负样本回归 | BYOL/SimSiam | student 回归 target 表征 | predictor、stop-grad、(常用)BN | 不需要负样本 | 组件耦合强;在一些设置下易不稳;multi-crop 组合可能不佳(论文也观察到) | 更强的 teacher 机制;更好的多视角策略 |
| 聚类/原型分配 | SwAV/DeepCluster | 对齐原型/聚类分配 | Sinkhorn-Knopp 等分配约束 | batch 内结构学习强 | 实现复杂;对超参敏感 | 更简单的分配近似;更稳定的 teacher |
| 无标签自蒸馏 | DINO | teacher 软分布 → student(CE) | momentum teacher + centering + sharpening | BN-free(ViT);k-NN 强;attention 涌现分割感 | multi-crop + 小 patch 成本高;对温度/中心更新敏感 | 研究更便宜的视角/teacher;更强的 dense 对齐损失 |
(表中结论均来自文中对比/消融的方向性证据,尤其表2、表7、表14/15、表8及相关讨论。)
4. 实验表现与优势
4a) 如何验证有效性(实验设计/设置)
作者的验证是"三段式":
-
ImageNet 标准 SSL 基准:线性评估 + k-NN 评估(表2)
-
性质验证(emerging properties):
- attention 直接阈值成 mask,与 VOC GT 做 Jaccard(图4)
- DAVIS 2017 视频实例分割:冻结特征,帧间 NN 匹配(表5)
-
迁移/检索类任务:
- revisited Oxford/Paris 检索 mAP(表3)
- Copydays 拷贝检测(表4)
- 多下游 finetune(表6)
4b) 超越对比方法的关键数据(代表性)
挑几个最"载重"的数据点(论文自己也最强调):
- ImageNet k-NN:ViT-S/8 + DINO = 78.3% top-1(表2 "Comparison across architectures")
- ImageNet 线性评估:ViT-B/8 + DINO = 80.1% top-1(表2)
- 同架构下 ViT-S:DINO 相比 BYOL/MoCov2/SwAV 线性更高、k-NN 提升更大(表2 上半部分,DINO ViT-S 线性 77.0 / k-NN 74.5,而 BYOL 等明显更低)
- attention mask 的 VOC Jaccard:DINO 显著高于监督与随机(图4给出 ViT-S/16:随机 22.0、监督 27.3、DINO 45.9;ViT-S/8 也类似)
4c) 哪些场景优势最明显(证据)
-
k-NN/检索型任务:作者反复强调这是 DINO+ViT 的突出点(表2、表3、表4)。
-
dense/布局相关:
- DAVIS:小 patch(/8)大幅提升(表5:ViT-S/8 从 61.8→69.9;ViT-B/8 到 71.4)
- attention 直接读出 object region(图1、图3、图8、图10)
4d) 局限性/不足(论文承认或隐含)
-
计算与显存成本:
- 小 patch 会导致 token 数暴涨、吞吐下降(表1 throughput,图5展示 patch size vs throughput 的 trade-off;表8展示 multi-crop 提升但显存更高)。
-
稳定性依赖特定组件组合:
- 没有 momentum 训练会直接崩(表7 row2 k-NN/linear=0.1)。
- centering 或 sharpening 单独使用会塌陷,必须配合(图7 的 entropy/KL 分析)。
-
方法本身不是为"显式分割"设计:attention mask 只是涌现属性,阈值法很粗糙,效果依然有限(论文也提示 attention map 并非为 mask 优化)。
5. 学习与应用(复现/实现建议)
5a) 是否开源?关键复现步骤
开源:论文首页明确给了代码仓库(github/facebookresearch/dino)。
复现关键步骤(按"最容易踩坑"排序):
-
Multi-crop 视角策略:2×224² global + 多个 96² local;teacher 只看 global。
-
Teacher EMA 更新:(\lambda) 需用 schedule(接近 1),不能直接 copy。
-
Centering + Sharpening:
- center 用 EMA 更新
- teacher 温度 (\tau_t) 要小,且建议 warmup
-
Projection head 结构:3-layer MLP + l2 bottleneck + weight norm FC;ViT 情况尽量 BN-free。
-
训练细节:AdamW、LR warmup + cosine、weight decay cosine(论文给了具体规则)。
5b) 超参数/预处理/训练细节(实现层建议)
结合文中经验,给你一组"优先级很高"的建议:
- 温度:(\tau_s) 固定(文中常用 0.1);(\tau_t) 小且 warmup(否则容易塌陷或不收敛)。
- center 动量 m:别设太大(文中指出 m=0.999 会塌陷,0.9/0.99/0 都能跑)。
- patch size:如果你要"分割/布局感更强",优先 /8;如果你资源有限,/16 更现实。图5展示了性能-吞吐权衡。
- multi-crop 数量:更多 local crops 提升会递减但显存涨很快(表8:2+6 vs 2+10 的收益很小但显存更大)。
- 评估:作者强调 k-NN 是一个"省调参、低方差"的好评估方式(实现上也更快验证你训练没崩)。
5c) 能否迁移到其他任务?如何迁移?
可以,迁移路径大概三类:
- 检索/匹配/聚类:直接用 CLS 或拼接 pooled patch tokens(论文在 copy detection 做了 CLS+GeM pooled patch tokens 的 descriptor)。
- Dense 任务(分割/跟踪):用 patch tokens,或用 attention map 做弱监督/提示(论文用 DAVIS 的 NN matching 验证了冻结特征仍保留空间信息)。
- 下游微调:按表6那样 finetune 到 CIFAR/Flowers/Cars/iNat 等,通常优于监督预训练。
6. 总结
6a) 一句话核心思想(≤20字)
用动量教师做无标签自蒸馏。
6b) 速记版 pipeline(3--5步,避免论文术语,尽量自明)
- 把一张图随机裁出"全图视角"和"局部视角"
- 用两个同结构网络分别看图:一个学、一个慢慢平均更新
- 让"学的网络"在所有视角上都匹配"平均网络"的输出分布
- 用输出去偏置与变尖锐来防止输出变成常数
- 训练完用模型特征做分类、检索或区域分析
如果你接下来想把它和你前面在做的 OVS / Ncut / DINO 特征分割范式串起来,我可以基于这篇论文里"attention 直接出 mask(图4)"的方式,进一步对比:
- "attention-threshold mask" vs "特征图构图 + Ncut" 的差异(信息来源、可控性、稳定性、复杂度)
并给你一个可推演的数值 toy example(patch token 相似度矩阵 → 图切分 → mask → 聚类/分类)。
下面我将按你给定的提纲,针对你提供的论文 DINOv2: Learning Robust Visual Features without Supervision(TMLR 01/2024) 做"方法部分"的深入拆解,并且所有公式都用 ......... 包围。引用均来自你上传的 PDF。
0. 翻译摘要原文(忠实意译)
自然语言处理中,基于大规模数据的预训练取得突破,推动了计算机视觉中类似"基础模型"的期待:一个模型输出的通用视觉特征能跨数据分布与任务"开箱即用"(无需微调)。本文表明:如果在足够多、来源多样且经过筛选的图像数据上训练,现有预训练方法(尤其自监督)也能产生这种通用特征。我们重新审视并组合多种技术,从数据规模和模型规模上扩展预训练,且多数技术贡献集中在大规模训练时的加速与稳定 。数据方面,我们提出自动化管线,构建一个专用的、多样且经过筛选的图像数据集(区别于常见的"直接用未筛选网络数据")。模型方面,我们训练了一个 10 亿参数的 ViT,并将其蒸馏到更小模型;这些小模型在多数图像级与像素级基准上超过了公开最强的通用特征(如 OpenCLIP)。
1. 方法动机
1a) 为什么提出这个方法(驱动力)
论文的目标是"真正通用"的视觉特征:
- 不仅能做图像级任务(分类、检索),也能做像素级任务(分割、深度)。
- 最好不需要微调,只靠冻结特征+简单头部就能强(foundation-style)。
作者认为:文本引导(CLIP类)虽然强,但caption 只能覆盖图像信息的一部分,很多像素级细节不会出现在文本监督里;而且需要对齐的图文数据。相对地,自监督"只看图像"更接近 NLP 的"只看原始数据",理论上更可能保留像素级信息。
1b) 现有方法的痛点/不足(具体局限)
论文明确指出了"扩展自监督"的关键困难:
-
数据问题:大规模未筛选网络图像会显著拉低特征质量
很多工作尝试把 SSL 从 ImageNet-1k 扩展到更大未筛选数据,但通常导致特征质量下降,原因是数据质量与多样性缺乏控制。
-
训练问题:判别式 SSL 在大模型/大数据上训练不稳定、成本高
作者强调他们的贡献主要是"加速与稳定大规模训练",并给出:相比类似判别式 SSL(如 iBOT 实现),他们做到 约 2× 更快、约 3× 更省显存,才使得更长训练、更大 batch 成为可能。
-
"通用特征"不仅要 ImageNet 好,还要跨域/跨任务
因此他们把评估扩展到分类鲁棒性、检索、分割、深度、视频等多类基准。
1c) 研究假设/直觉(简洁概括)
只要(1)用足够大且经过筛选/再平衡的多域数据,(2)用可扩展、稳定的判别式自监督训练 recipe,自监督也能训练出"冻结即用"的通用视觉特征,且在图像级与像素级任务都强。
2. 方法设计(重点:极细 pipeline)
DINOv2 方法可以分成两条主线:
- A. 数据:自动化构建"LVD-142M" curated 数据集(第3节)
- B. 训练:判别式 SSL 目标(DINO + iBOT + SwAV式居中)+ 正则 + 分辨率适配 + 大规模工程加速(第4-5节)
下面按"输入→处理→输出"的推理式 pipeline 讲清楚每一步怎么做。
2a) 清晰 pipeline:输入→处理→输出(逐步技术细节)
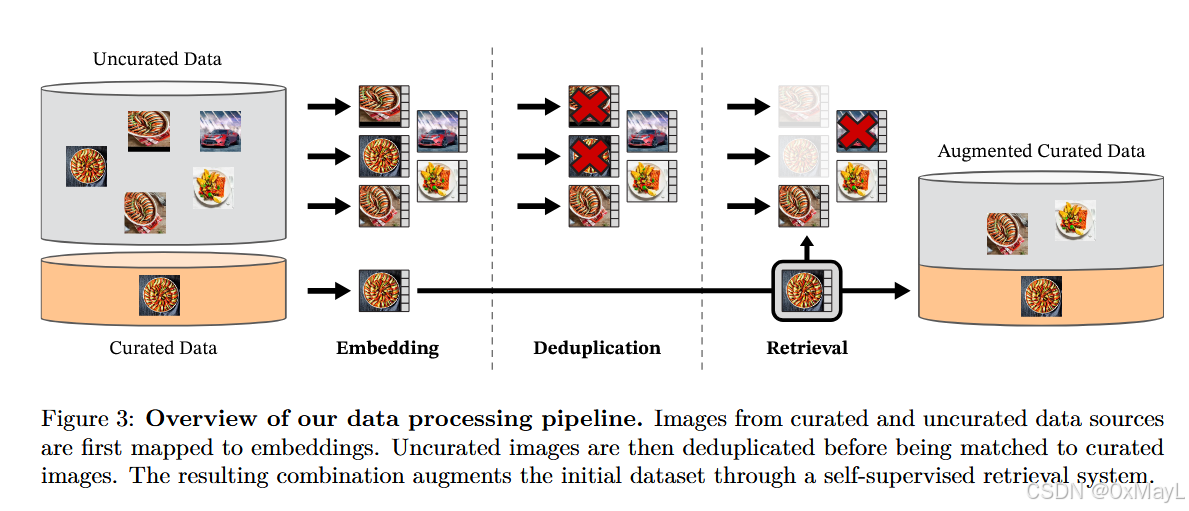
A. 数据构建 pipeline(Fig.3 + Sec.3)
输入:
- 多个"curated 数据源"(如 ImageNet-22k、ImageNet-1k train、Google Landmarks、若干细粒度/分割/深度相关数据集等,具体组成见 Table 15)。
- 一个巨大的"uncurated 网络图像源 ":抓取网页
<img>URL,过滤不安全/受限域名,做 NSFW 过滤与人脸模糊等后处理,得到 约 1.2B unique images(文中描述)。
Step A1:把图像映射到 embedding(用于去重与检索)
- 用一个自监督 ViT-H/16(先在 ImageNet-22k 预训练)提取图像 embedding;
- 用余弦相似度作为距离度量:
m(s,r)=cos(f(s),f(r))=f(s)⋅f(r)∣f(s)∣2∣f(r)∣2m(s,r)=\cos(f(s),f(r))=\frac{f(s)\cdot f(r)}{|f(s)|_2|f(r)|_2}m(s,r)=cos(f(s),f(r))=∣f(s)∣2∣f(r)∣2f(s)⋅f(r)
(见附录A.2)。
Step A2:对 uncurated 数据做去重(copy detection / 近重复消除)
- 用 copy detection 管线去除 near-duplicate,提升多样性;并且还会移除与任何评测 benchmark 的 val/test 近重复的图像,避免泄漏。
- 附录A.3给出更细实现:对每张图找 kNN(如 k=64),相似度阈值筛边,取连通分量,保留代表图。
Step A3:自监督检索做"curated 扩增"(核心思想:用视觉相似性而非文本/元数据)
-
从 uncurated pool 中检索与 curated 图像"近邻"的图片加入训练集(Fig.3)。
-
两种策略(附录A.4):
- sample-based:对大数据集(>1M)每张 query 取固定个数近邻(例如典型 N=4;但 ImageNet-22k 这条检索用了更大 k=32 让其成为核心部分)。
- cluster-based:对 uncurated 做 k-means(100k clusters),对每个 query 找到对应 cluster 后采样;并对每个数据集检索数量做上限(如 1M)保持平衡。
输出:
得到 LVD-142M(142M)多源、经过检索扩增、去重和再平衡的 curated 数据集(Table 15 汇总各数据来源与检索后数量)。
B. 训练目标与网络 pipeline(Sec.4)
作者说他们的方法可视为:DINO + iBOT 的组合,并引入 SwAV 的居中、加 KoLeo 正则、以及末期高分辨率训练。
输入:
- 一张训练图像 x,做多视角增强(global crops + local crops 是 DINO 系传统做法,文中在实现加速里也提到 DINO 需要大小 crop,例如 224 与 98)。
- Student / Teacher 两个 ViT(teacher 是 student 的 EMA)。
Step B1:Image-level 目标(DINO loss,用 class token)
- 从不同 crop 得到 student/teacher 的 class token(ViT 的 CLS)。
- 分别过 DINO head(MLP)得到"prototype scores",softmax 得到分布:student 为 psp_sps,teacher 为 ptp_tpt。
- teacher 的 ptp_tpt 需要做 centering(移动平均居中,或用 Sinkhorn-Knopp 居中)。
DINO loss 写成:
LDINO=−∑ptlogpsL_{\text{DINO}}=-\sum p_t \log p_sLDINO=−∑ptlogps
(论文在 Sec.4 用这行形式给出)。
直觉:teacher 给出"软目标分布",student 在不同视角上拟合它,促使表征跨增强一致。
Step B2:Patch-level 目标(iBOT loss,用 masked patch tokens)
- 只给 student 随机 mask 一部分输入 patch;teacher 不 mask。
- 对 student 的 mask tokens 过 iBOT head;对 teacher 中与这些 mask 位置对应的"可见 patch tokens"过 teacher iBOT head;softmax + centering 得到 teacher patch 分布 ptip_t^ipti 与 student patch 分布 psip_s^ipsi。
iBOT loss:
LiBOT=−∑iptilogpsiL_{\text{iBOT}}=-\sum_i p_t^i \log p_s^iLiBOT=−i∑ptilogpsi
其中 i 是被 mask 的 patch 索引。
直觉:这一步把"像素/局部信息"显式压进特征,使得下游 dense 任务(分割、深度)更线性可读。
Step B3:关键设计选择:DINO head 与 iBOT head 不共享(untie)
- iBOT 原文(Zhou et al.)报告共享 head 更好,但作者发现在大规模(data/model scale)下相反 ,因此 DINOv2 使用两套独立 head。
- 这是一个很"工程但关键"的差异:scale 上去后,image-level 与 patch-level 的 token 分布特性不同,共享参数会互相牵制。
Step B4:teacher 端的居中:Softmax-centering 或 Sinkhorn-Knopp(SK)
-
DINO/iBOT teacher 的归一化 + 居中可用两种:
- moving-average centering(DINO式)
- Sinkhorn-Knopp batch normalization(SwAV式),并运行 3 次迭代(文中明确"3 iterations")。
-
student 端仍用 softmax。
Step B5:KoLeo 正则(让特征"铺开",提升检索/最近邻)
KoLeo(Kozachenko--Leonenko 熵估计器相关)定义为:
Lkoleo=−1n∑i=1nlog(dn,i),dn,i=minj≠i∣xi−xj∣L_{\text{koleo}}=-\frac{1}{n}\sum_{i=1}^{n}\log(d_{n,i}),\quad d_{n,i}=\min_{j\neq i}|x_i-x_j|Lkoleo=−n1i=1∑nlog(dn,i),dn,i=j=imin∣xi−xj∣
并且在计算前对特征做 ℓ2\ell_2ℓ2 归一化。
直觉:鼓励 batch 内样本彼此拉开,避免表征拥挤在少数方向上;论文消融显示它对检索 mAP 提升巨大(后面实验部分详说)。
Step B6:末期高分辨率适配(resolution adaptation)
- 由于像素级任务需要高分辨率,但全程高分辨率太贵。
- 做法:预训练末期短阶段把输入分辨率提升到 518×518518\times 518518×518(文中写 518×518),只训一小段,逼近全程高分辨率效果。
- Fig.6 也用小实验说明"224→416 的短阶段训练"接近"全程 416",但计算量显著更低。
Step B7:teacher 更新(EMA)
teacher 是 student 的 EMA:
- teacher 初始与 student 相同;
- 动量在 0.994,1.00.994,1.00.994,1.0 之间用 cosine schedule;
- 每个 step 末更新一次(附录B.1明确写了这点)。
C. 大规模训练工程(Sec.5)------"能训起来"的关键
这些不改变数学目标,但决定"能否 scale":
- 自研 FlashAttention 版本:降低注意力显存/加速;并为硬件效率微调 ViT-g 的 head/维度(例如 embed dim 1536、24 heads,64 dim/head)。
- Sequence packing:把不同 crop 的 token 序列拼成一个长序列,注意力矩阵用 block-diagonal mask 防止跨序列相互 attention,从而一次 forward/backward 覆盖多 crop,显著提效。
- 更高效 stochastic depth:直接跳过被 drop 的残差计算而不是算完再 mask,节省 compute/memory。
- FSDP + 混精:把 student、teacher、AdamW 一二阶矩的参数/状态分片到多卡,且梯度通信用 float16(head 用 float32 防不稳定),降低通信与显存。
2b) 模型结构:模块功能与协同
- Backbone:ViT-S/B/L/g,patch size 多为 /14(Table 17);大模型(from scratch)用 SwiGLU FFN,小模型(distilled)用 MLP FFN。
- Heads:两套 head(DINO head + iBOT head)不共享,分别作用在 class token(图像级)与 patch/mask token(像素级)。
- Teacher:EMA 版 student,提供稳定软标签;配合 centering / SK 保持分布不塌陷。
- KoLeo:只对"特征空间几何"施加约束,帮助检索/最近邻。
整体协同:
- LDINOL_{\text{DINO}}LDINO 把"全局语义"对齐;
- LiBOTL_{\text{iBOT}}LiBOT 把"局部/像素信息"对齐;
- centering / SK 让 teacher 输出分布健康;
- KoLeo 让 embedding 更可检索;
- 末期高分辨率让 dense 特征更细。
2c) 公式/算法通俗解释(在方法中的角色)
- LDINO=−∑ptlogpsL_{\text{DINO}}=-\sum p_t \log p_sLDINO=−∑ptlogps:用 teacher 的软分布当"无标签监督",让不同视角的 class token 学到稳定的语义空间。
- LiBOT=−∑iptilogpsiL_{\text{iBOT}}=-\sum_i p_t^i \log p_s^iLiBOT=−i∑ptilogpsi:把"补全被 mask 的 patch 表征"变成分类式的对齐任务,使 patch token 线性包含更多像素/结构信息,直接提升分割/深度的线性可读性。
- Sinkhorn-Knopp:把 teacher 输出做一种 batch 内"近似均衡/归一化"的分配(SwAV式),缓解塌陷与模式偏置。
- LkoleoL_{\text{koleo}}Lkoleo:鼓励 batch 内样本最邻近距离变大,等价于"把特征铺开",对检索提升很明显(表3a给了证据)。
3. 与其他方法对比
3a) 本质不同点是什么?
DINOv2 属于判别式自监督(discriminative SSL),但它追求的是"跨任务通用冻结特征",因此在 iBOT/DINO 基础上组合了:
- 同时做图像级(class token)和像素级(patch token)目标(DINO + iBOT);
- **用更强的数据策略(curated + 检索扩增 + 去重 + 再平衡)**解决 scale 时的质量坍塌;
- 加入 KoLeo显式优化"特征空间几何"以服务检索/最近邻;
- 大量系统工程让 1B ViT 训练可行(flash attention、packing、FSDP)。
相比 MAE 这类 MIM 生成式方法:
- MAE 强在"微调后"性能(文中也提到 MAE 需要监督微调),而 DINOv2 强调"不开微调也强"。
相比 CLIP/OpenCLIP:
- CLIP是弱监督(文本引导),在像素级细节上可能不如纯视觉自监督;DINOv2 试图在多类基准上与 OpenCLIP 竞争甚至超过。
3b) 创新点与贡献度(明确指出)
我把贡献按"对结果影响/不可替代性"排序:
-
数据贡献:自动化构建 LVD-142M(curated + 去重 + 检索扩增 + 再平衡)
论文用 Table 2 明确显示:同规模训练下,curated 数据显著优于"随机采样未筛选数据"。
-
方法/目标贡献:DINO + iBOT + SwAV式居中 + KoLeo + 高分辨率末期训练 的组合 recipe
并通过 Table 1(从 iBOT baseline 逐步加组件)验证每一项如何提升。
-
系统工程贡献:2× 更快、3× 更省显存,让大模型大数据可训练
FlashAttention改造、sequence packing、FSDP、改 stochastic depth 等。
-
蒸馏策略:用 ViT-g 冻结 teacher 蒸馏小模型
蒸馏版在 12 个 benchmark 上全面优于从头训练(Fig.5)。
3c) 适用场景与适用范围
更适用:
- 你要一个"冻结即用"的 backbone,在分类/检索/分割/深度等多任务上都能用线性头快速起效果(Table 10, 11 等验证)。
- 你关心跨域鲁棒性(ImageNet-A/R/Sketch 等),DINOv2 提升非常显著(Table 6)。
- 你要做实例检索/最近邻检索,KoLeo 让优势更明显(Table 3a、Table 9)。
不太适用/成本点:
- 训练非常重:大模型需要大量 GPU 小时,并且论文还单独估计了复现 DINOv2-g 的能耗/碳排(Table 14)。
- 若你的目标是"特定任务 SOTA",完全微调+复杂解码头仍可能更强;DINOv2 的卖点是"简单头也强"。
3d) 表格:方法对比(优点/缺点/改进点)
| 方法 | 训练信号 | 是否依赖文本/标注 | "冻结即用"能力 | 像素级能力 | 主要优点 | 主要缺点 | 对 DINOv2 的启示/改进点 |
|---|---|---|---|---|---|---|---|
| CLIP / OpenCLIP | 图文对比 | 依赖图文对齐数据 | 强(图像级) | 相对弱(线性分割/深度有差距) | 开放词汇、零样本强 | caption 信息不完整,像素细节不充分 | 用纯视觉 SSL 补齐像素级信息(Table 10/11 对比) |
| MAE | 重建(MIM) | 不需要文本 | 冻结一般,微调强 | 微调后强 | 可扩展,训练稳定 | 需要监督微调才能强(文中强调这一点) | DINOv2 走"判别式 + 冻结即用"路线 |
| iBOT | 判别式 + patch MIM | 不需要文本 | 较强 | 强(patch级) | 对 dense 有帮助 | scale 上训练与 recipe 仍有空间 | DINOv2 在 iBOT 上叠加 KoLeo/SK/高分辨率/工程优化(Table 1) |
| DINO(v1) | teacher-student CE | 不需要文本 | 强(ImageNet 线性/kNN) | 有一定能力 | 简洁有效 | 数据/规模受限;像素级不如 iBOT 体系 | DINOv2 用 DINO+ iBOT 统一图像级与像素级目标 |
| DINOv2 | DINO + iBOT + centering/SK + KoLeo | 不需要文本 | 强:线性/kNN/跨域 | 强:线性分割/深度 | 通用、鲁棒、冻结即可强 | 训练成本高,依赖精心数据与工程 | 可探索更轻量数据构建/更省算力 recipe |
4. 实验表现与优势
4a) 作者如何验证有效性(实验设计/设置)
核心评估原则:冻结 backbone,只训练很浅的头(线性 probe / kNN / 简单解码),来证明"信息在特征里是线性可读的"。
- ImageNet-1k:kNN + linear(Table 4)
- 跨域鲁棒:ImageNet-A/R/C/Sketch(Table 6)
- 多分类基准:iNat/Places、视频动作(Table 7)
- 检索:Oxford/Paris/Met/AmsterTime(Table 9)
- Dense:分割(Table 10)、深度(Table 11)
- 消融:训练 recipe(Table 1)、数据源(Table 2)、KoLeo / MIM 作用(Table 3)
4b) 超越对比方法的代表性关键数据(列重点)
(1) ImageNet 冻结线性评估:大幅超 iBOT
Table 4 中,iBOT ViT-L/16(INet-22k)线性 val = 82.3;DINOv2 ViT-g/14(LVD-142M)线性 val = 86.5。
=> 提升约 +4.2%(论文正文也明确说 +4.2%)。
(2) 与弱监督(OpenCLIP / EVA-CLIP)在 ImageNet 线性上持平甚至略超
Table 4:DINOv2 ViT-g/14 线性 val 86.5;OpenCLIP ViT-G/14 86.2;EVA-CLIP ViT-g/14 86.4。
(3) 跨域鲁棒性提升非常显著(尤其对 iBOT)
Table 6:iBOT 在 Im-A/Im-R/Sketch 为 41.5/51.0/38.5;DINOv2 ViT-g/14 为 75.9/78.8/62.5。
(4) Dense 任务:冻结+线性分割 mIoU 明显更强
Table 10:ADE20k 线性(lin.)OpenCLIP 39.3;DINOv2 ViT-g/14 49.0;+ms 后 DINOv2 达 53.0。
(5) 深度:冻结特征+简单头,RMSE 更低(更好)
Table 11:NYUd 上 DINOv2 ViT-g/14(DPT)= 0.279,明显优于 OpenCLIP(0.414)与 iBOT(0.358)。
4c) 优势最明显的场景/数据集(证据)
- 实例检索:Table 9 的 Oxford/Paris Hard 上 DINOv2 明显领先(例如 Oxford-H mAP:DINOv2 ViT-L/14 = 54.0,ViT-g/14 = 52.3;而 iBOT ViT-L/16 = 12.7;OpenCLIP ViT-G/14 = 19.7)。
- 跨域鲁棒(Im-A/R/Sketch):Table 6 差距极大。
- 像素级任务(分割/深度):Table 10/11 线性可读性强;Fig.7/8 的定性图也显示 DINOv2 线性分割/深度更平滑、伪影更少。
4d) 局限性(论文承认或隐含)
- 训练与复现成本高:Table 14 给出复现 DINOv2-g 的 GPU-hours 与碳排估计;并且整个项目估计达到 0.5k--1k tCO2eq 量级(正文讨论)。
- 强依赖数据质量与平衡:Table 2 直接显示未筛选数据会显著拉低多项基准;"curation 是必要条件"。
- 公平性/偏差仍存在:Dollar Street 地域/收入差异仍明显(Table 12),作者也承认更彻底评估可能暴露更多偏差。
- 某些场景弱监督仍强:如 Places205 上 OpenCLIP 仍略高(Table 7 显示 DINOv2-g 67.5 vs OpenCLIP 69.8)。
5. 学习与应用(实现/复现建议)
5a) 是否开源?复现关键步骤
开源:论文明确写了代码与模型开源,并给出仓库(github/facebookresearch/dinov2)。
复现"方法正确性"的关键步骤(按重要性排序):
- Loss 组合 :同时实现 LDINOL_{\text{DINO}}LDINO(class token)与 LiBOTL_{\text{iBOT}}LiBOT(masked patch tokens),并保证 teacher/student 的 softmax/centering 流程正确。
- Head untying:DINO head 与 iBOT head 分开训练(scale 下很关键)。
- Teacher EMA + momentum schedule :teacher 动量 0.994,1.00.994,1.00.994,1.0 cosine schedule,每 step 更新(附录B.1)。
- KoLeo :按论文公式实现,并对特征先 ℓ2\ell_2ℓ2 normalize;权重在附录实现细节给了(附录B.1 也提 KoLeo 具体施加位置)。
- 末期高分辨率适配:按 Sec.4 的 518×518 短阶段训练,或按 Fig.6 的"224→416"思想在自己设置里做。
- 若要训练大模型:实现/调用 FSDP、packing、flash attention 等,否则成本会爆。
5b) 超参数/数据预处理/训练细节建议(实现层)
论文把关键训练超参汇总在 Table 16:
- 训练 625k iterations,AdamW;
- LR warmup 100k;
- weight decay cosine 0.04→0.2;
- teacher momentum cosine 0.994→1;
- stochastic depth 在 from scratch 大模型中用到 0.4;
- distilled 模型 drop-rate=0,LR=1e-3,batch=2048;from scratch ViT-L/g 用 LR=3.5e-4,batch=3072。
实现建议(结合文中消融与结论):
- 先用 kNN 作为训练健康指标:作者在 Table 1 的消融说明里说他们更"优化 kNN",因为经验上 linear probe 被 kNN 下界约束。
- KoLeo 对检索提升巨大:Table 3a 显示 Oxford-M mAP 从 55.6→63.9(+8.3),几乎不伤别的指标。
- iBOT 的 MIM 项对 dense 任务关键:Table 3b 显示 ADE-20k mIoU 从 44.2→47.1(+2.9)。
- 数据构建要做去重与"相对去重"(避免与测试集近重复):论文在 Sec.3 和附录A.3强调了这一点。
5c) 能否迁移到其他任务?如何迁移?
可以,而且论文已经展示"冻结特征 + 简单头"覆盖很多任务:
- 检索/匹配:直接用特征做余弦相似度检索(Table 9)。
- 分割:对 patch token 训练线性层输出低分辨率 logits,再上采样到全分辨率(Sec.7.4 的 linear 设置);增强版 +ms 会拼接最后4层 token、提高输入分辨率并做多尺度测试(Table 10)。
- 深度:拼接 CLS 到每个 patch token,上采样 token,再用线性层做分桶分类回归;或用 DPT decoder(Sec.7.4,Table 11)。
- 视频:抽多帧,特征平均(或拼接)后训练线性分类器(Table 7)。
6. 总结
6a) 20字内核心思想
筛选大数据上训练判别式自监督通用特征。
6b) 速记版 pipeline(3--5步,不用论文术语,直白自明)
- 从大规模网络图像里去重,并按视觉相似性补充到高质量训练集
- 同一张图裁出多种视角,让两个同结构网络分别提取全局与局部表示
- 让学习网络在全局与局部位置上都匹配平均网络的输出分布
- 额外拉开特征分布,并在训练末期短时间提升输入分辨率
- 训练后冻结特征,用线性层就能做分类、分割、深度、检索
如果你愿意,我可以进一步把 DINOv2 的"patch-level objective + 线性分割/深度" 和你之前关心的 OVS / Ncut(基于特征相似图的分割) 对齐:
- DINOv2 的 patch token 在"线性可读"意义下到底提供了什么结构;
- 为什么 KoLeo 会让图结构(kNN/检索/聚类)更稳定;
并用一个小型数值例子(4~6个 patch token 的相似矩阵)推演"线性分类 vs 图切分"的差异。