文章目录
关系数据结构及形式化定义
数据模型三要素:数据结构、数据操作、数据的完整性约束条件
从集合论的角度讲,关系数据结构的形式化定义,涉及到几个术语:
- 域 :
是一组具有相同数据类型的值的集合。 - 笛卡尔积
给定⼀组域 D 1 , D 2 , ... , D n D_1,D_2,...,D_n D1,D2,...,Dn,允许其中某些域是相同的。 D 1 , D 2 , ... , D n D_1,D_2,...,D_n D1,D2,...,Dn的笛卡尔积为: D 1 × D 2 × ... × D n ={( d 1 , d 2 , ... , d n )| d i ∈ D i , i = 1 , 2 , ... , n } D_1×D_2×...×D_n={(d_1,d_2,...,d_n)|d_i \in D_i,i=1,2,...,n} D1×D2×...×Dn={(d1,d2,...,dn)|di∈Di,i=1,2,...,n}
假设 ∣ A ∣ = m , ∣ B ∣ = n , A × B = m ∗ n |A|=m,|B|=n,A\times B=m*n ∣A∣=m,∣B∣=n,A×B=m∗n
注意:结果就是所有域的所有取值的⼀个组合;且不能重复(特别注意)
- 元组(Tuple)(对应表中的一行)
笛卡尔积中每一个元素 ( d 1 , d 2 , ... , d n ) (d_1,d_2,...,d_n) (d1,d2,...,dn)叫作一个 n n n 元组(n-tuple)或简称元组。 - 分量(Component)(对应表中的一格)
笛卡尔积元素 ( d 1 , d 2 , ... , d n ) (d_1,d_2,...,d_n) (d1,d2,...,dn)中的每一个值 d i d_i di 叫作一个分量. - 基数(Cardinal number)
一个域中允许取值的个数。若 D i ( i = 1 , 2 , ... , n ) D_i(i=1,2,...,n) Di(i=1,2,...,n)为有限集,其基数为 m i ( i = 1 , 2 , ... , n ) m_i(i=1,2,...,n) mi(i=1,2,...,n),则 D 1 × D 2 × ... × D n D_1×D_2×...×D_n D1×D2×...×Dn的基数 M = ∏ m i M = \prod m_i M=∏mi。
- 关系(笛卡尔积的子集)
D 1 × D 2 × ... × D n D_1×D_2×...×D_n D1×D2×...×Dn的子集叫作在域 D 1 , D 2 , ... , D n D_1,D_2,...,D_n D1,D2,...,Dn上的关系,表示为 R ( D 1 , D 2 , ... , D n ) R(D1,D2,...,Dn) R(D1,D2,...,Dn)
R R R:关系名
n n n:关系的目或者度(Degree)
笛卡尔积是有序的
- 元组:关系中的每个元素是关系中的元组。
- 单元关系与二元关系
当n=1时,称该关系为单元关系(Unary relation)或一元关系
当n=2时,称该关系为二元关系(Binary relation) - 属性
关系中不同列可以对应相同的域
为了加以区分,必须对每列起一个名字,称为属性Attribute)(可解决笛卡尔积有序性问题)
n n n目关系必有 n n n 个属性 - 码
(1)候选码(Candidate key)
若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码;
简单的情况:候选码只包含一个属性(如学号)
(2)全码(All-key)
最极端的情况:关系模式的所有属性组是这个关系模式的候选码,称为全码(All-key)
(3)主码(Primary key)
若一个关系有多个候选码,则选定其中一个为主码
(4)主属性
候选码的诸属性称为主属性(Prime attribute)不包含在任何侯选码中的属性称为非主属性(Non-Prime attribute)或非码属性(Non-key attribute) - 关系的类型:三类
(1)基本关系(基本表或基表):实际存在的表,是实际存储数据的逻辑表示
(2)查询表:查询结果对应的表
(3)视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据的类型 - 基本关系的性质:
① 列是同质的(Homogeneous);
② 不同的列可出自同一个域;其中的每⼀列称为⼀个属性,不同的属性要给予不同的属性名
③ 列的顺序无所谓(次序可以任意交换);
④ 任意两个元组的候选码不能相同;
⑤ 行的顺序无所谓(次序可以任意交换)。
⑥ 分量必须取原子值(原子不可分)
规范化的关系简称范式
关系数据库
关系模式(Relation Schema) 是型 ,如:学生(学号,姓名,......)
关系 是值
关系模式是对关系的描述
关系数据库
在⼀个给定的应⽤领域中,所有关系的集合构成⼀个关系数据库
关系数据库的型与值
关系数据库的型: 关系数据库模式,是对关系数据库的描述。
关系数据库的值: 关系模式在某⼀时刻对应的关系的集合,通常称为关系数据库。
关系的操作
- 常用的关系操作:选择,投影,并,差,笛卡尔积。
- 数据更新:插入、删除、修改。
关系操作的特点:操作的对象和结果都是集合,一次一集和的方式。
关系的完整性
关系的完整性:
(1)实体完整性和参照完整性(由关系系统自动支持)
是关系模型必须满⾜的完整性约束条件称为关系的两个不变性。
(2)⽤户定义的完整性
应⽤领域需要遵循的约束条件,体现了具体领域中的语义约束.
- 实体完整性
(1)实体完整性规则是针对基本关系⽽⾔的。
⼀个基本表通常对应现实世界的⼀个实体集。
(2)现实世界中的实体是可区分的,即它们具有某种唯⼀性标识。
(3)关系模型中以主码作为唯⼀性标识。
(4)主属性不能取空值。
我们在讲参照完整性前先引入一个概念:
关系的引用
在关系模型中实体及实体间的联系都是用关系来描述的,自然存在着关系与关系间的引用。
学生、课程、学生与课程之间的多对多联系,例如:
学生(学号,姓名,性别,专业号,年龄)
课程(课程号,课程名,学分)
选修(学号,课程号,成绩)
选修关系引用了学生关系的主码学号和课程关系的主码课程号。这说明选修关系中某些属性取值要参照学生关系和课程关系属性的取值。
- 两个关系间可以存在引用关系;(如学生关系和专业关系)
- 两个以上的关系间可以存在引用关系; (如选修关系同时参照了学生关系和课程关系)
- 同一关系内部属性间也可以存在引用。(如"班长"属性)
外码:
设 F 是基本关系R的一个或一组属性,但不是关系 R 的码。如果 F 与基本关系 S 的主码 Ks 相对应,则称 F是 R 的外码(如学生关系中的"专业号" )
基本关系R 称为参照关系( ReferencingRelation)。
基本关系S称为被参照关系(ReferencedRelation) 或目标关系(Target Relation)。
- 参照完整性 :
若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不⼀
定是不同的关系),则对于R中每个元组在F上的值
必须为:
或者取空值(F的每个属性值均为空值)
或者等于S中某个元组的主码值
注意:外码是参照关系的主属性,则不能取空值;是非主属性则允许取空值

关系代数
关系代数是⼀种抽象的查询语⾔,它⽤关系的运算来表达查询
- 运算对象是关系
- 运算结果亦为关系
- 关系代数的运算符有两类:集合运算符和专门的关系运算符。
以下是关系的常见运算符号:
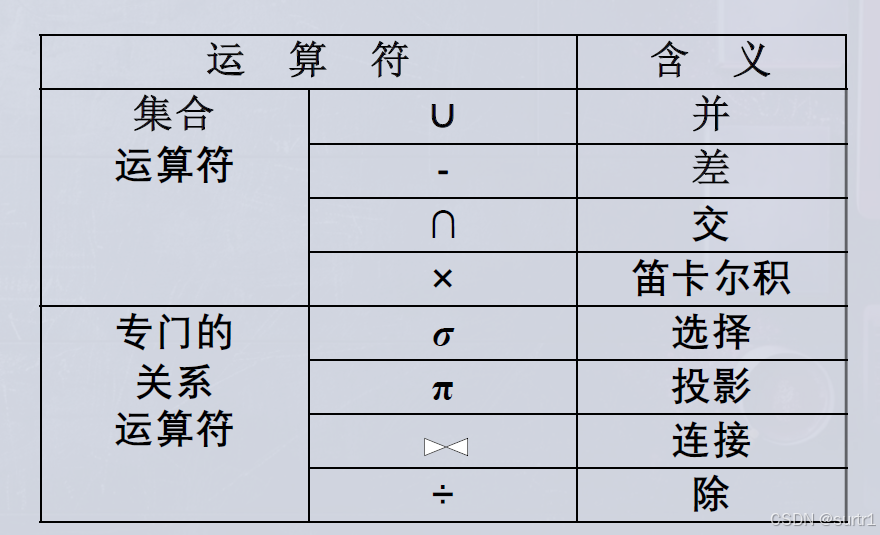
假设和前提:R和S具有相同的目 n n n(即两个关系都有 n n n个属性)且相应的属性取自同一个域
1.传统的集合运算
- R ∪ S R∪S R∪S 仍为 n n n ⽬关系,由属于R或属于S的元组组成 R ∪ S = { t ∣ t ∈ R ∨ t ∈ S } R∪S = \{ t|t \in R∨t \in S \} R∪S={t∣t∈R∨t∈S}
- R − S R - S R−S 仍为 n n n 目关系,由属于R而不属于S的所有元组组成 R − S = { t ∣ t ∈ R ∧ t ∈ S } R -S = \{ t|t\in R∧t \in S \} R−S={t∣t∈R∧t∈S}
- R ∩ S R∩S R∩S 仍为 n n n 目关系,由既属于R又属于S的元组组成 R ∩ S = { t ∣ t ∈ R ∧ t ∈ S } R∩S = \{ t|t \in R∧t \in S \} R∩S={t∣t∈R∧t∈S}
- R ∩ S = R --( R − S ) R∩S = R --(R-S) R∩S=R--(R−S)
- R × S R×S R×S
列: ( n + m ) (n+m) (n+m)列元组的集合
元组的前n列是关系R的⼀个元组,后m列是关系S的一个元组
行: k 1 × k 2 k_1×k_2 k1×k2 个元组( k 1 k_1 k1和 k 2 k_2 k2分别是S和R的行数)
R × S = { t r t s ∣ t r ∈ R ∧ t s ∈ S } R×S = \{ t_rt_s | t_r \in R ∧ t_s\in S \} R×S={trts∣tr∈R∧ts∈S}
2.专门的关系运算
先引入几个记号
- R , t ⊆ R , t A i R,t\subseteq R,tAi R,t⊆R,tAi
设关系模式为 R ( A 1 , A 2 , ... , A n ) R(A_1,A_2,...,A_n) R(A1,A2,...,An)
它的⼀个关系设为R
t ⊆ R t\subseteq R t⊆R表示 t 是 R 的⼀个元组
t A i tA_i tAi 则表示元组t中相应于属性 A i A_i Ai 的⼀个分量
设关系模式为 R ( A 1 , A 2 , ... , A n ) R(A_1, A_2, \dots, A_n) R(A1,A2,...,An),其一个具体关系实例也记为 R R R。
-
元组与分量 :
若 t ∈ R t \in R t∈R,则 t t t 是 R R R 的一个元组;
t A i tA_i tAi 表示元组 t t t 在属性 A i A_i Ai 上的分量。 -
属性组及其投影 :
设 A = { A i 1 , A i 2 , ... , A i k } ⊆ { A 1 , A 2 , ... , A n } A = \{A_{i_1}, A_{i_2}, \dots, A_{i_k}\} \subseteq \{A_1, A_2, \dots, A_n\} A={Ai1,Ai2,...,Aik}⊆{A1,A2,...,An} 为一个属性组,
则元组 t t t 在 A A A 上的投影定义为
t A = ( t A i 1 , t A i 2 , ... , t A i k ) . tA = (tA_{i_1}, tA_{i_2}, \dots, tA_{i_k}). tA=(tAi1,tAi2,...,tAik).记 A ‾ \overline{A} A 为 A A A 在全属性集中的补集,即
A ‾ = { A 1 , A 2 , ... , A n } ∖ A . \overline{A} = \{A_1, A_2, \dots, A_n\} \setminus A. A={A1,A2,...,An}∖A. -
元组的连接 :
设 R R R 为 n n n 目关系, S S S 为 m m m 目关系。
对任意 t r ∈ R t_r \in R tr∈R 和 t s ∈ S t_s \in S ts∈S,其连接元组 t r t s t_r t_s trts 是一个 ( n + m ) (n + m) (n+m) 元组,满足
t r t s = ( t r A 1 , ... , t r A n , t s B 1 , ... , t s B m ) , t_r t_s = (t_rA_1, \dots, t_rA_n, t_sB_1, \dots, t_sB_m), trts=(trA1,...,trAn,tsB1,...,tsBm),其中 B 1 , ... , B m B_1, \dots, B_m B1,...,Bm 为 S S S 的属性。该操作是笛卡尔积 R × S R \times S R×S 的基础。
-
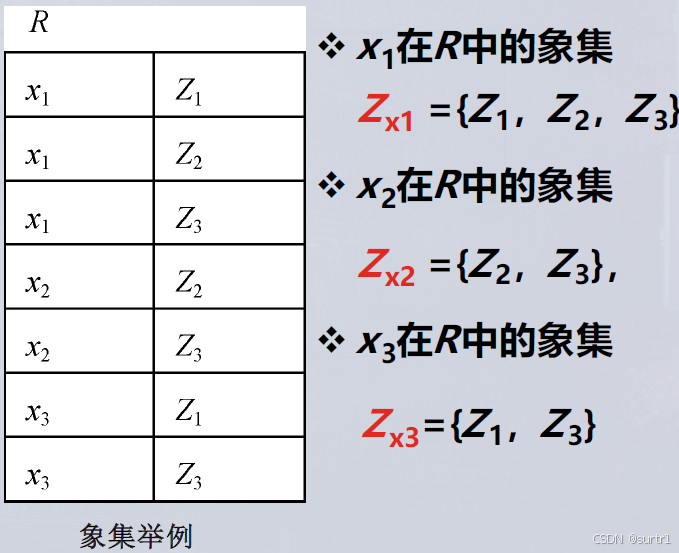
象集 (Images Set):
给定关系 R ( X , Z ) R(X, Z) R(X,Z),其中 X X X 和 Z Z Z 为不相交的属性组。
对任意 x x x,当存在元组 t ∈ R t \in R t∈R 使得 t X = x tX = x tX=x 时, x x x 在 R R R 中的象集 定义为
Z x = { t Z ∣ t ∈ R , t X = x } . Z_x = \{\, tZ \mid t \in R,\ tX = x \,\}. Zx={tZ∣t∈R, tX=x}.即 Z x Z_x Zx 是所有在 X X X 上取值为 x x x 的元组在 Z Z Z 上的分量集合。
在关系数据库理论中,专门的关系运算 是为处理关系(表)结构而设计的基本操作,主要包括 选择、投影、连接、除法 四种。
-
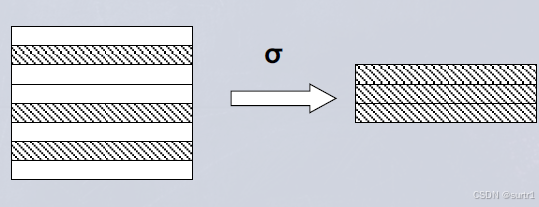
选择 (Selection):
从关系 R R R 中选出满足条件的元组。
记作 σ F ( R ) \sigma_{F}(R) σF(R),其中 F F F 是选择条件(如 A i = a A_i = a Ai=a 或 A i > A j A_i > A_j Ai>Aj)。
σ F ( R ) = { t ∣ t ∈ R , t 满足 F } . \sigma_{F}(R) = \{\, t \mid t \in R,\ t \text{ 满足 } F \,\}. σF(R)={t∣t∈R, t 满足 F}.该操作对关系进行水平分割 (减少行数),属性集不变。
-
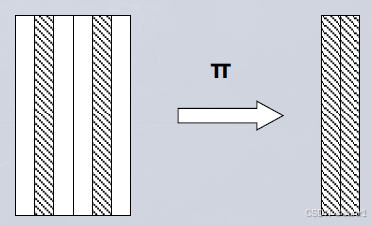
投影 (Projection):
从关系 R R R 中选取指定属性列,并自动去除重复元组。
记作 π A ( R ) \pi_{A}(R) πA(R),其中 A ⊆ { A 1 , ... , A n } A \subseteq \{A_1, \dots, A_n\} A⊆{A1,...,An} 为属性组。
π A ( R ) = { t A ∣ t ∈ R } . \pi_{A}(R) = \{\, tA \mid t \in R \,\}. πA(R)={tA∣t∈R}.该操作对关系进行垂直分割 (减少列数),结果仍为合法关系(无重复元组)。
-
连接 (Join):
将两个关系按某种条件组合。最常见的是 θ \theta θ-连接 和 自然连接。
- θ \theta θ-连接定义为:
R ⋈ A i θ B j S = { t r t s ∣ t r ∈ R , t s ∈ S , t r A i θ t s B j } , R \bowtie_{A_i\,\theta\,B_j} S = \{\, t_r t_s \mid t_r \in R,\ t_s \in S,\ t_rA_i\ \theta\ t_sB_j \,\}, R⋈AiθBjS={trts∣tr∈R, ts∈S, trAi θ tsBj},
其中 θ \theta θ 为比较运算符(如 = = =, < < <, ≥ \geq ≥ 等)。 - 自然连接 R ⋈ S R \bowtie S R⋈S 是一种特殊等值连接:
自动对 R R R 与 S S S 的同名属性 做等值匹配,并在结果中保留一份同名属性 (去除重复列 )。
假设有如下表:
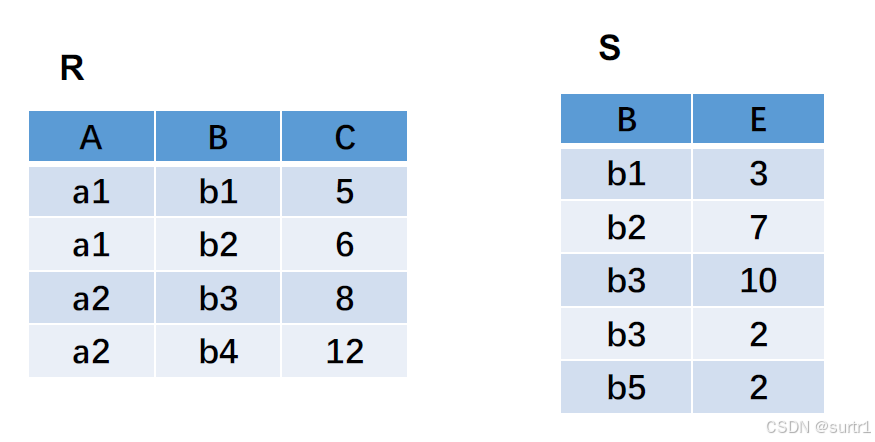
则 R ⋈ C < E S R \bowtie_{ C\lt E} S R⋈C<ES 如下:
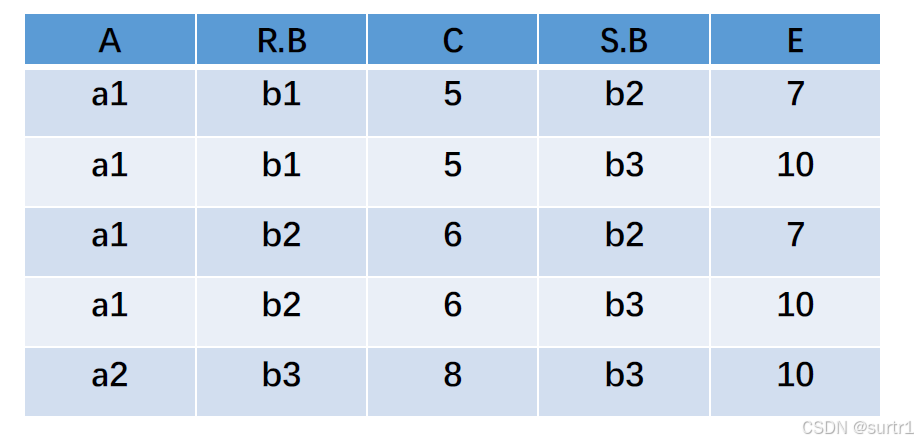
自然连接 R ⋈ S R \bowtie_{ } S R⋈S 如下:
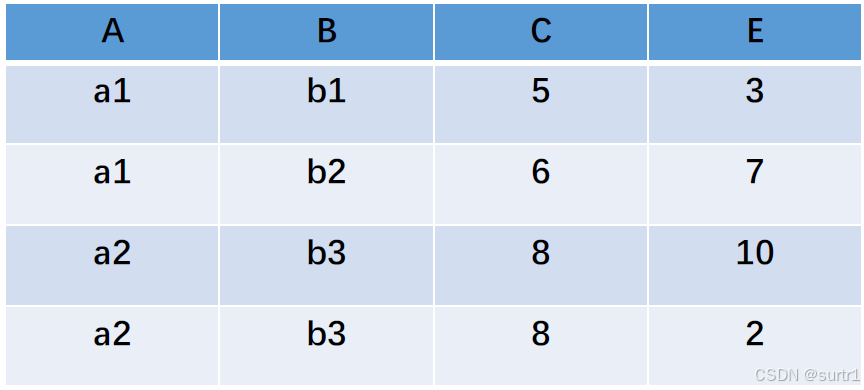
悬浮元组是自然连接舍去的那些元组。
外连接(Outer Join)
如果把悬浮元组也保存在结果关系中,而在其他属性上填空值(Null),就叫做外连接
左外连接(LEFT OUTER JOIN或LEFT JOIN):只保留左边关系R中的悬浮元组
右外连接(RIGHT OUTER JOIN或RIGHT JOIN) 只保留右边关系S中的悬浮元组
外连接:
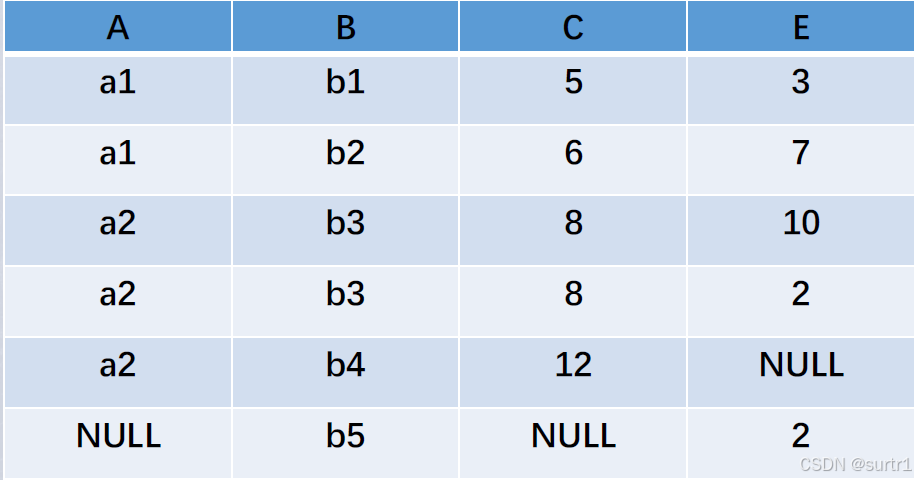
左右两图分别是左连接和右连接:
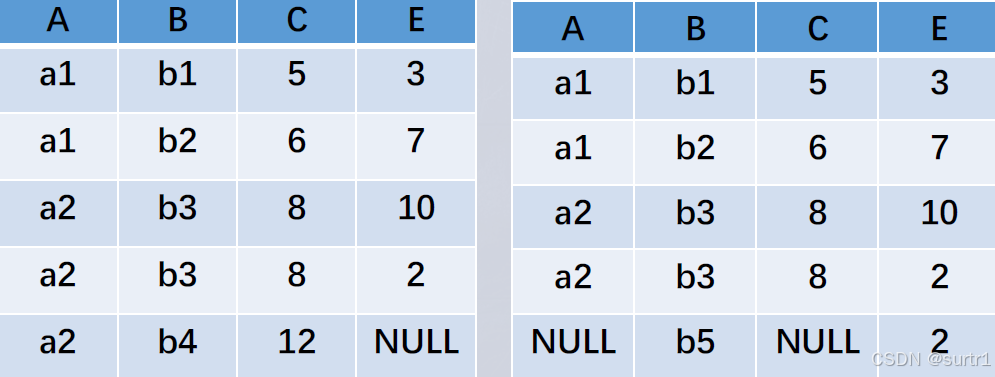
- θ \theta θ-连接定义为:
-
除法 (Division):
用于表达"对所有都成立"的查询(如"选修了所有课程的学生")。
设关系 R ( X , Y ) R(X, Y) R(X,Y) 与 S ( Y ) S(Y) S(Y),其中 Y Y Y 为公共属性组,则
R ÷ S = { t X ∣ t ∈ R , ∀ s ∈ S , ( t X , s Y ) ∈ R } . R \div S = \{\, tX \mid t \in R,\ \forall s \in S,\ (tX, sY) \in R \,\}. R÷S={tX∣t∈R, ∀s∈S, (tX,sY)∈R}.等价地, R ÷ S R \div S R÷S 是所有 x x x 的集合,使得其象集 Y x ⊇ S Y_x \supseteq S Yx⊇S。
用人话说就是:"谁满足了全部条件?" 或 "哪些主体覆盖了整个目标集合?"
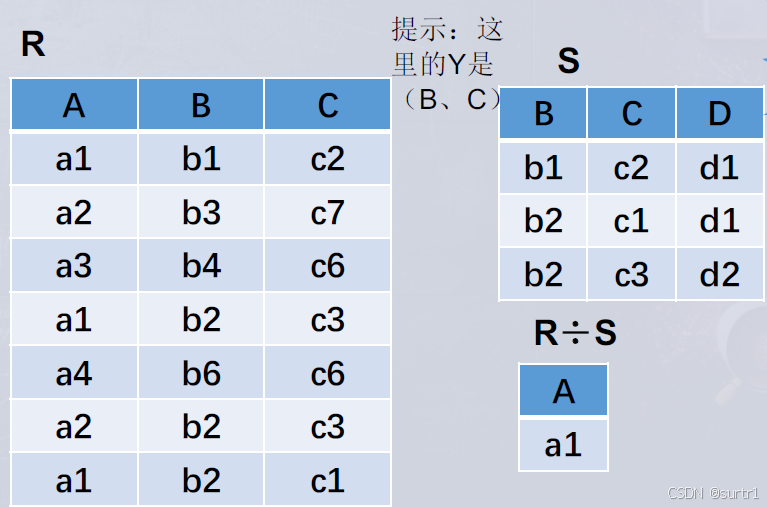
在关系R中,A可以取四个值 { a 1 , a 2 , a 3 , a 4 } \{a_1,a_2,a_3,a_4\} {a1,a2,a3,a4}
a 1 a_1 a1的象集为 { ( b 1 , c 2 ) , ( b 2 , c 3 ) , ( b 2 , c 1 ) } \{(b_1,c_2),(b_2,c_3),(b_2,c_1)\} {(b1,c2),(b2,c3),(b2,c1)}
a 2 a_2 a2的象集为 { ( b 3 , c 7 ) , ( b 2 , c 3 ) } \{(b_3,c_7),(b_2,c_3)\} {(b3,c7),(b2,c3)}
a 3 a_3 a3的象集为 { ( b 4 , c 6 ) } \{(b_4,c_6)\} {(b4,c6)}
a 4 a_4 a4的象集为 { ( b 6 , c 6 ) } \{(b_6,c_6)\} {(b6,c6)}S 在 ( B , C ) (B,C) (B,C) 上的投影为: { ( b 1 , c 2 ) , ( b 2 , c 1 ) , ( b 2 , c 3 ) } \{(b_1,c_2),(b_2,c_1),(b_2,c_3)\} {(b1,c2),(b2,c1),(b2,c3)}
只有 a 1 a_1 a1的象集包含了 S S S在 ( B , C ) (B,C) (B,C)属性组上的投影
所以 R ÷ S = { a 1 } R\div S =\{a_1\} R÷S={a1}
简单来说,除法的步骤为:
(1)求 R R R 的象集 Y x Y_x Yx;
(2)求 S S S 的投影 π A ( S ) \pi_{A}(S) πA(S);
(3)包含(2)结果的(1)中的象集对应的值。