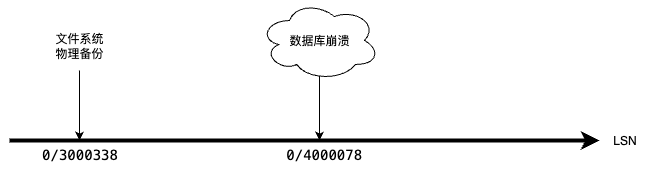
PostgreSQL 的时间点恢复基于一个文件系统级的物理备份(也可以叫做全量备份,下文称其为全量备份)和若干归档 WAL 日志来工作。当 PostgreSQL 崩溃,进行时间点恢复时,PostgreSQL 会先以全量备份作为起点进行启动,然后进入恢复模式,回放归档的 WAL 日志,以恢复到指定的某一时间点。所以,你可以恢复到【文件系统备份到数据库崩溃那一时刻】这一时间段的任意一个时间点。
这个全量备份可以是 pg_basebackup 工具自动做的全量备份,也可以是使用 pg_backup_start 和 pg_backup_stop 函数手动做的全量备份。甚至可以是直接对 PostgreSQL 数据目录文件使用 cp 命令或者其它方法做的文件拷贝。这个全量备份没必要具有一致性状态,因为我们有完整的归档 WAL 日志,任何不一致都可以通过回放 WAL 日志来纠正。
举个例子,你在LSN 0/3000338 处做了一次 pg_basebackup,在LSN 0/4000078 处数据库崩溃了,所以理论上来说你可以恢复数据库到 0/3000338, 0/4000078 之间的任意时刻。
要想进行时间点恢复,分三步走:
- 设置
PostgreSQL进入 WAL 归档模式。 - 进行全量备份。
PostgreSQL崩溃后,设置PostgreSQL进入restore模式,执行时间点恢复。
设置WAL归档模式
时间点恢复的关键是,你拥有一段完整的,连续的归档 WAL 日志,这段 WAL 日志的起点要小于等于你做文件系统物理备份的那一点。
PostgreSQL 生成的 WAL 日志以 segment 为单位,一个 WAL 日志文件就是一个 segment,他们是一对一的关系。一个 segment 默认为 16MB(initdb时可以指定 --wal-segsize 为其他大小),WAL 日志文件的命名方式是从 000000010000000000000001 开始递增。其中前八位表示 TimeLine,中间八位表示 LogID,最后八位表示 LogSeg。在不设置归档模式的情况下,WAL 日志文件是循环使用的,PostgreSQL 只会生成固定的几个 WAL 日志文件,然后通过将不再需要的 WAL 日志文件重命名为更高的编号来回收它们。
当设置了归档模式后,PostgreSQL 会在 WAL 日志文件被写满之后,被回收之前 ,将其保存到指定的位置。将 WAL 日志保存到何处完全由用户通过 archive_command 或者 archive_library 指定。要使用WAL归档模式,需要设置参数:
wal_level大于等于 replica级别。archive_mode设置为 on。- 在
archive_command参数中配置需要使用的 shell 命令,或者在archive_library参数中配置需要使用的动态库,告诉PostgreSQL如何归档 WAL 日志。
设置完上述参数后,需要重启 PostgreSQL ,然后 PostgreSQL 会启动一个 archiver 进程,持续进行 WAL 日志归档。
一个最简单的 archive_command 命令是:
shell
archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'%f 会被替换为实际的 WAL 日志文件名,%p 会被替换成时间的 WAL 日志文件路径。这个 shell 命令首先检测是否已经存在同名的 WAL 日志,如果不存在,才会拷贝 WAL 日志到目标位置。
如果 archive_command 返回非0,PostgreSQL 会认为归档失败,会定期重试。
另外,archive_command 的一个替代品是 archive_library,你需要自己编写 c 代码编译成动态库,完成实际的归档操作,可以参考 contrib/basic_archive 来编写你的代码。
注意: archiver 进程只会归档已经写满的 WAL 日志文件,因此事务提交到日志归档中间有一定的延时。你可以配置 archive_timeout 来每隔一段时间就切换一次 WAL 日志,或者手动调用 pg_switch_wal 函数,强制立即执行 WAL 日志的切换。
进行全量备份
使用 pg_basebackup 进行全量备份
可以使用 pg_basebackup 工具进行在线的全量备份,一个简单的例子是:
shell
pg_basebackup -D /target_dir -h 127.0.0.1 -p 5432 --checkpoint=fast --wal-method=stream --verbosepg_basebackup 需要最少保留 备份开始到备份结束 这一时间段产生的 WAL 日志来使备份达到一个一致性状态。
因此,在开启了归档模式的状态下,pg_basebackup 会在WAL归档目录下,创建一个备份历史文件(backup history file),比如 00000002000000000000000E.00000028.backup 就是一个备份历史文件,备份历史文件名包含三部分,第一部分是备份开始时的 WAL 日志文件名,第二部分是备份开始时的 LSN 在WAL 日志文件内的位置,第三部分是固定的 backup。备份历史文件内记录了备份时的一些信息:
!\[Clipboard_Screenshot_1752674533.png]
通过这个备份历史文件,你可以确定对于一个全量备份,需要从哪里开始进行恢复。
使用pg_backup_start函数进行全量备份
你还可以使用 pg_backup_start 和 pg_backup_stop 这一对函数来进行全量备份,这基本上是对 pg_basebackup 所做事情的手工模拟,基本使用方法是:
shell
0. 确保 PostgreSQL 处于归档模式
1. SELECT pg_backup_start(label => 'label', fast => false);
2. 使用文件系统备份工具,tar、cpio、cp等将数据目录进行备份
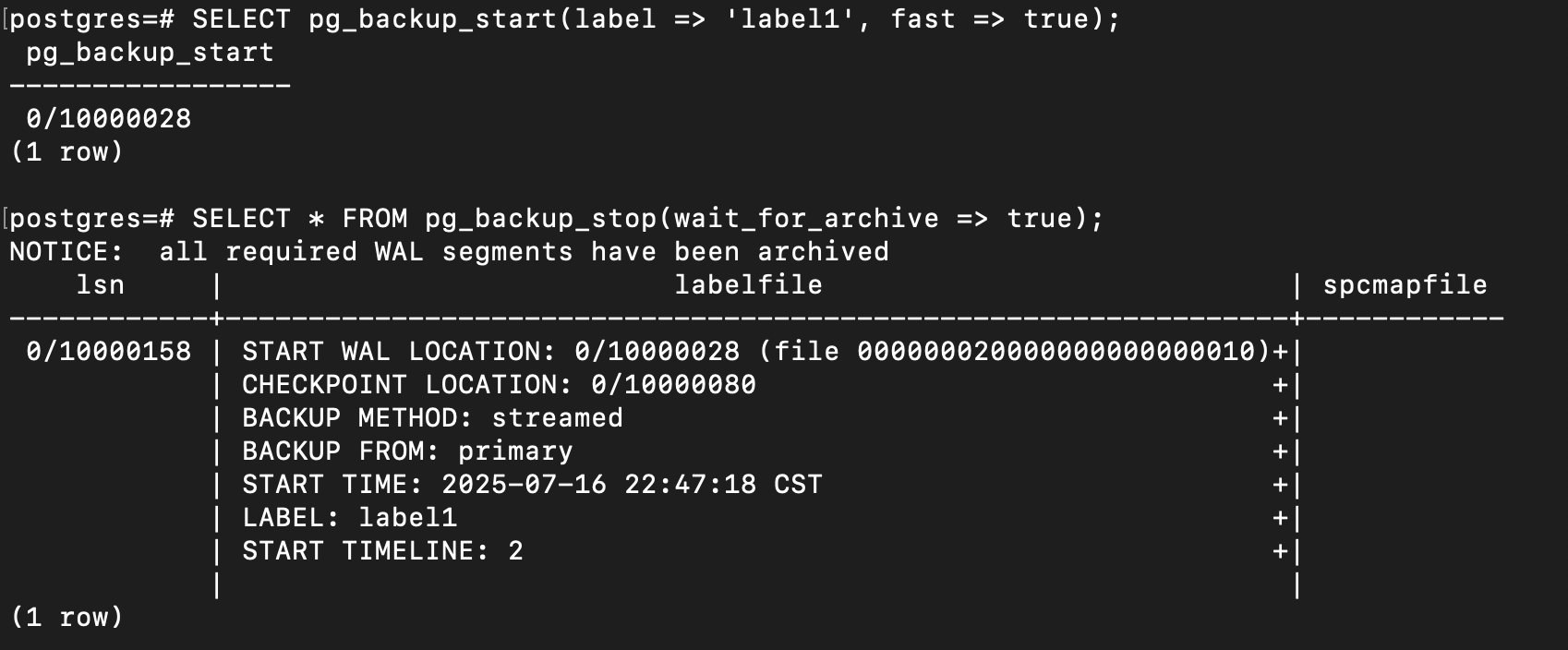
3. SELECT * FROM pg_backup_stop(wait_for_archive => true);- 和
pg_basebackup一样,默认情况下,pg_backup_start函数将等待PostgreSQL进行一次 checkpoint,你可以指定 fast 参数为 true,来请求立即执行一次 checkpoint,这相当于pg_basebackup的--checkpoint=fast参数。label 参数指定此次执行全量备份的标签,用于标识这次全量备份,和pg_basebackup的--label=label参数一样。 - 随便使用任何工具,对数据目录进行备份,备份期间没有必要停止服务器的运行。你也可以使用文件系统备份工具直接备份
PostgreSQL的数据目录。注意不要备份pg_wal/目录下的文件,postmaster.pid文件和postmaster.opts文件。pg_replslot目录下的文件也不要复制,因为如果你要用这个备份启动一个备库的话,复制槽会阻止未被客户端消费的WAL日志被删除,由于这些客户端实际上连接的是主库,新搭建备库的WAL日志无法被消费,会造成无限堆积;如果你要用这个备份启动一个新的主库,这些旧的复制槽也不会有太大作用,因为这些复制槽的内容太过落后了。pg_dynshmem/,pg_notify/,pg_serial/,pg_snapshots/,pg_stat_tmp/,pg_subtrans/目录下的内容可以不用备份,因为它们会在PostgreSQL启动时初始化,但是目录本身需要保留。 pg_backup_stop会立即进行一次 WAL 日志的切换,这样archiver进程能够有机会尽快归档全量备份期间产生的 WAL 日志,如果wait_for_archive为 true,还会等待archiver进程归档 WAL 日志完成。
如下图,pg_backup_start 会返回备份的起点 LSN,pg_backup_stop 会返回三个字段,lsn代表备份的结束 LSN,labelfile字段应该被原封不动的写入备份根目录的 backup_label 文件中,spcmapfile 字段应该被原封不动的写入 tablespace_map 备份根目录的文件中。pg_basebackup 做出的全量备份会自动生成这两个文件,这里需要你自己生成。
进行时间点恢复
首先拿到你之前做的全量备份。
确保备份中的 pg_wal 文件夹是空的,因为这些 WAL 日志都是过时的WAL日志,检查原节点,如果有 WAL 日志还没来得及归档,你需要拷贝它到备份节点的 pg_wal 下面。
在 postgresql.conf 配置文件中设置一些配置:
restore_command告诉PostgreSQL如何从归档目录中获取到所需要的 WAL 日志文件和 .history 文件:
shell
restore_command = 'cp /mnt/server/archivedir/%f %p'- 设置一个停止点,告诉
PostgreSQL何时停止恢复。如果不指定停止点,默认会回放完所有的 WAL 日志。可以指定下面任意一个配置:
shell
recovery_target = 'immediate' # 只能指定immediate,它会回放完所有的WAL日志
recovery_target_name = 'xxx' # 还原到指定的还原点,这个还原点 可以用 pg_create_restore_point 函数创建
recovery_target_time = 'timestamp with time zone' # 还原到一个指定的时间
recovery_target_xid = 'xxx' # 还原到指定的事务。它只能保证所有在 xid = xxx 之前提交的事务被还原,不保证所有 xid 小于 xxx 的事务都能被还原。因为事务 ID 虽然是顺序分配的,但是他们提交的时间不是顺序的,而 WAL 日志只能顺序回放
recovery_target_lsn = 'xxx' # 还原到指定的 LSN另外还有几个 GUC 和停止点相关:
- recovery_target_inclusive = 'on/off'。
和recovery_target_time,recovery_target_xid,recovery_target_lsn配合使用,如果为on,则还原时会包括你所指定的那一点,如果为off,则不包括。 - recovery_target_timeline = 'latest/current/0x11'
还原到指定的时间线。可以指定lateset还原到集群最近的一个时间线,也可以指定current还原到你做全量备份时的时间点,或者直接指定一个指定的时间线,比如 0x11。
%f、%p 的含义和 archive_command 一样。如果在归档目录中找不到所需要的 WAL 日志,会去 pg_log 中寻找。
然后创建一个空的 recovery.signal 文件。然后启动 PostgreSQL。