文章目录
- 一、前期准备
- 二、多表查询
-
- [2-1 内连接](#2-1 内连接)
- [2-2 左连接](#2-2 左连接)
- [2-3 右连接](#2-3 右连接)
- 三、自查询
- 四、子查询
-
- [4-1 标量子查询](#4-1 标量子查询)
- [4-2 列子查询](#4-2 列子查询)
- [4-3 表子查询](#4-3 表子查询)
一、前期准备
我们将通过一个模拟公司场景来学习。包含两个核心表:depts,emps,请打开你的终端,跟随以下步骤操作
sql
-- 创建并使用数据库
CREATE DATABASE IF NOT EXISTS learn_sql;
USE learn_sql;
-- 1. 创建部门表
CREATE TABLE depts (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL
);
-- 2. 创建员工表
CREATE TABLE emps (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
job VARCHAR(50),
salary DECIMAL(10, 2),
manager_id INT, -- 上级领导的ID (用于自连接)
dept_id INT, -- 所属部门ID (用于多表连接)
FOREIGN KEY (dept_id) REFERENCES depts(id)
);
-- 3. 插入数据
-- 插入部门
INSERT INTO depts (id, name) VALUES (1, '研发部'), (2, '市场部'), (3, '财务部'), (4, '运维部');
-- 插入员工 (注意:有些员工没有部门,有些部门没有员工,用于测试外连接)
-- 老板 (没有上级)
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (1, '宋江', 'CEO', 20000, NULL, 1);
-- 经理
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (2, '吴用', '研发经理', 15000, 1, 1);
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (3, '卢俊义', '市场经理', 14000, 1, 2);
-- 普通员工
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (4, '林冲', '程序员', 10000, 2, 1);
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (5, '鲁智深', '程序员', 10000, 2, 1);
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (6, '武松', '销售', 8000, 3, 2);
-- 实习生 (还没有分配部门)
INSERT INTO emps (id, name, job, salary, manager_id, dept_id) VALUES (7, '白胜', '实习生', 3000, 3, NULL);二、多表查询
多表查询指的是两个或两个以上的表,同时查询数据并显示一起显示出来,分别有:左连接,内连接,右连接,理解这三种连接的区别,最好的办法就是观察谁被留下了,谁被扔掉了,哪里出现了 NULL
为了让你看得更清楚,我先简要回顾一下我们在上一条中准备的特殊数据:
- 左边的表 (
emps员工表):有一个特殊员工 "白胜",他的dept_id是NULL(也就是他没有部门) - 右边的表 (
depts部门表):有两个特殊部门 "财务部"和"运维部",它们在员工表里找不到对应的dept_id(也就是这两个部门没人)
我们现在的目标是:把员工表和部门表拼起来
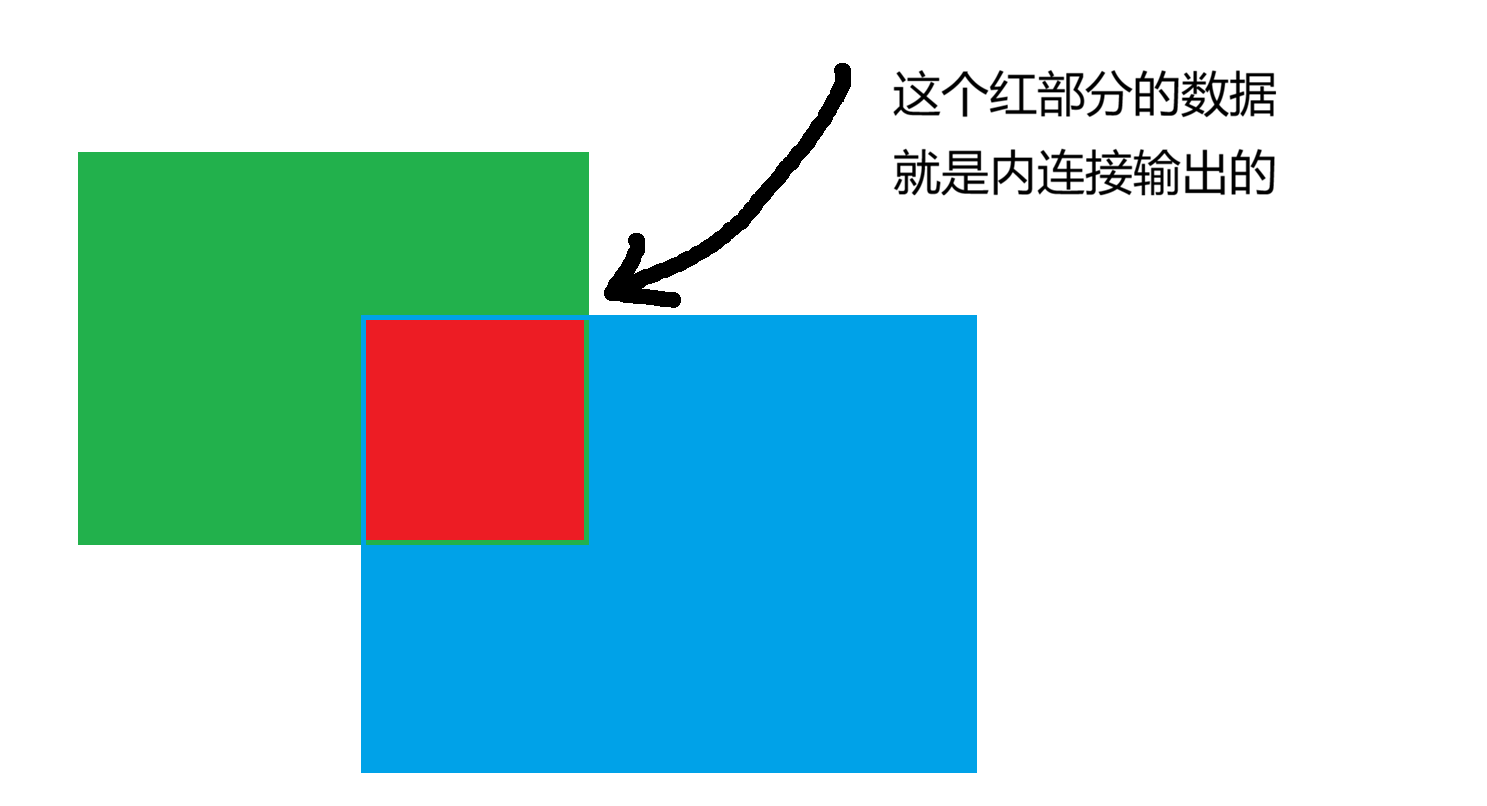
2-1 内连接
两边都有才保留,一边没有全扔掉,内连接是最严格的。它只取出两个表中完全匹配的数据。这就像是找交集
sql
SELECT
e.name AS 员工,
d.name AS 部门
FROM emps e
INNER JOIN depts d ON e.dept_id = d.id;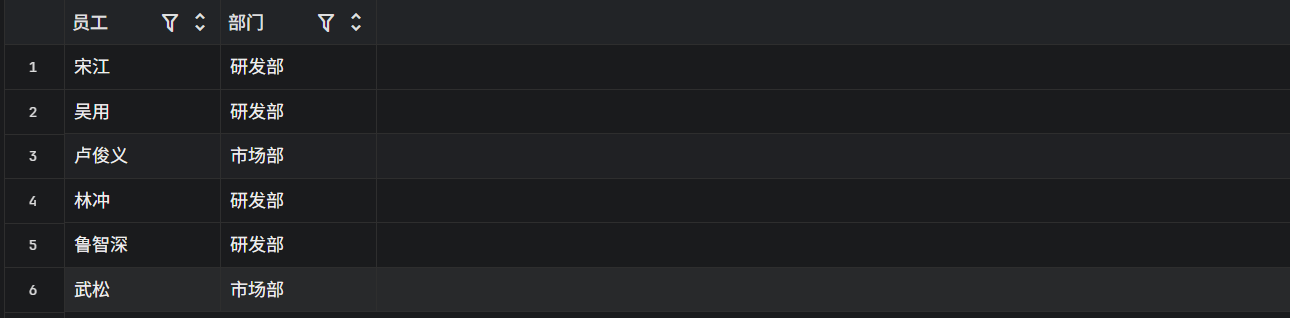
这里我们使用部门的id和员工的dept_id相比较,如果有相同的则输出,如果没用则不输出
白胜不见了,因为他的 dept_id 是 NULL,在部门表里找不到对应的 ID,财务部和运维部不见了,因为员工表里没有人的 dept_id 是 3 或 4。所以如果你只想看已经在部门就职的员工,用内连接
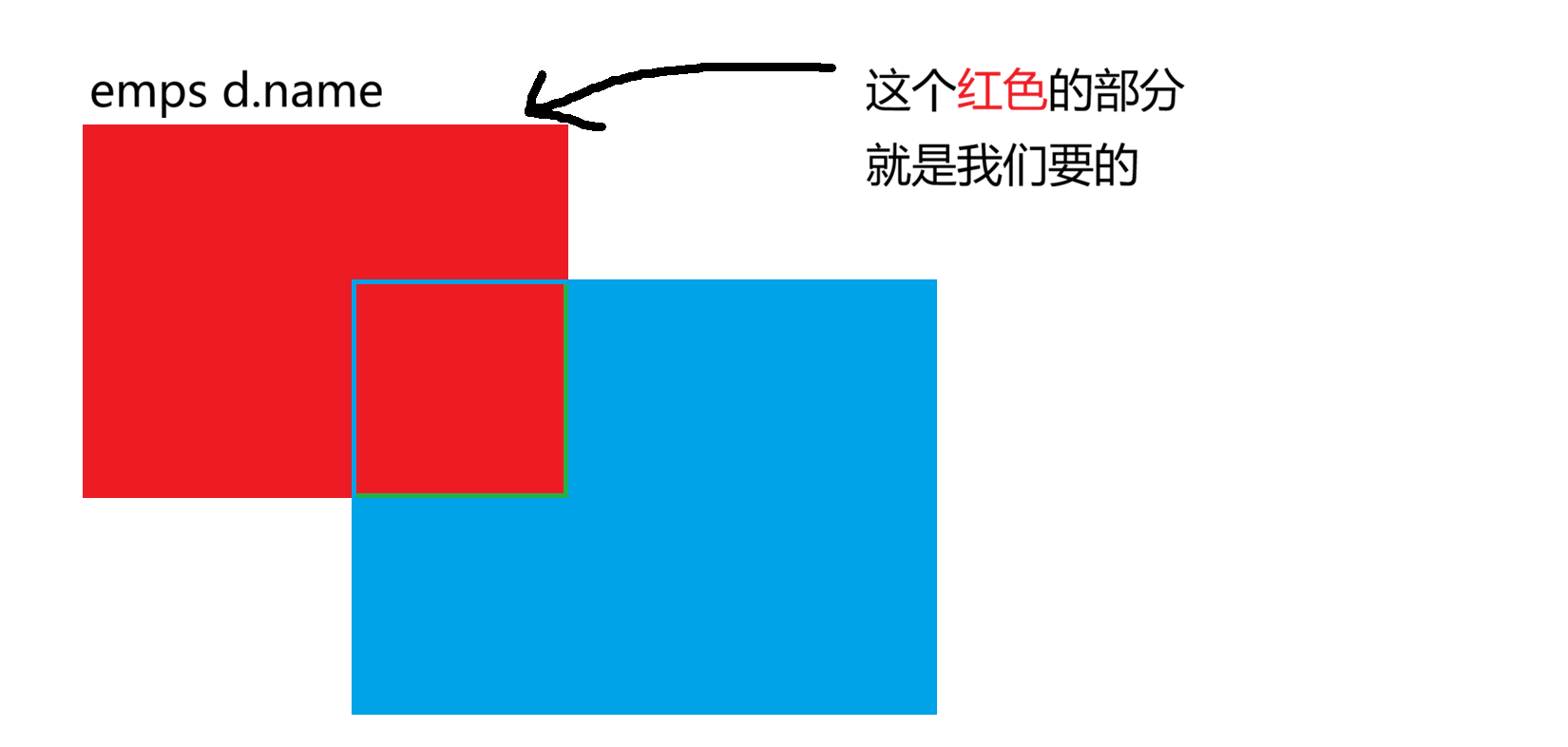
2-2 左连接
左边全部要保留,右边匹配不上就填空 (NULL)
左连接以左表FROM 后面的表,即 emps为主。不管能不能在右边找到对应的部门,左边的员工一个都不能少
sql
SELECT
e.name AS 员工,
d.name AS 部门
FROM emps e
LEFT JOIN depts d ON e.dept_id = d.id;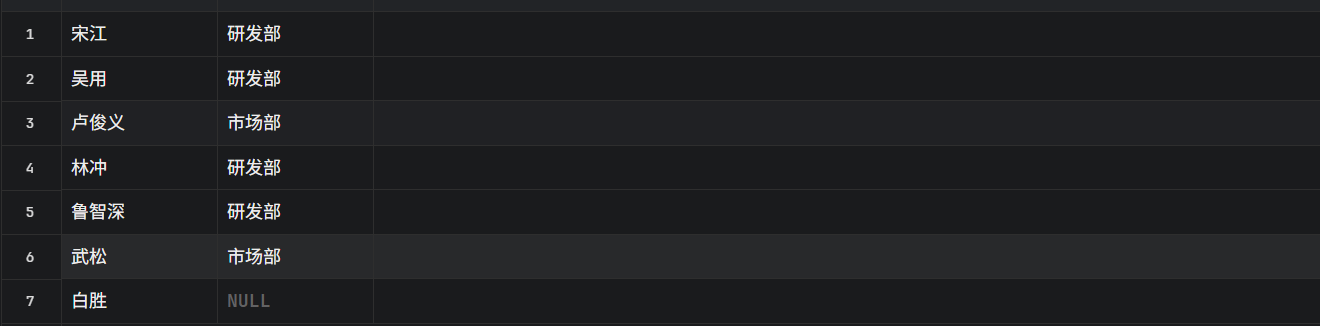
白胜出来了, 虽然他没有部门,但他作为左表的一员,被强制保留了,因为他没有部门,所以部门这一列,数据库自动填入了 NULL,财务部依然不在。因为它是右表的东西,且没被用到,所以不显示,如果你想看所有员工的名单,不管他有没有分配部门,必须用左连接。这是开发中最常用的连接方式
2-3 右连接
右边全部要保留,左边匹配不上就填空 NULL,右连接和左连接逻辑完全相反。它以右表JOIN 后面的表,即 depts为主
sql
SELECT
e.name AS 员工,
d.name AS 部门
FROM emps e
RIGHT JOIN depts d ON e.dept_id = d.id;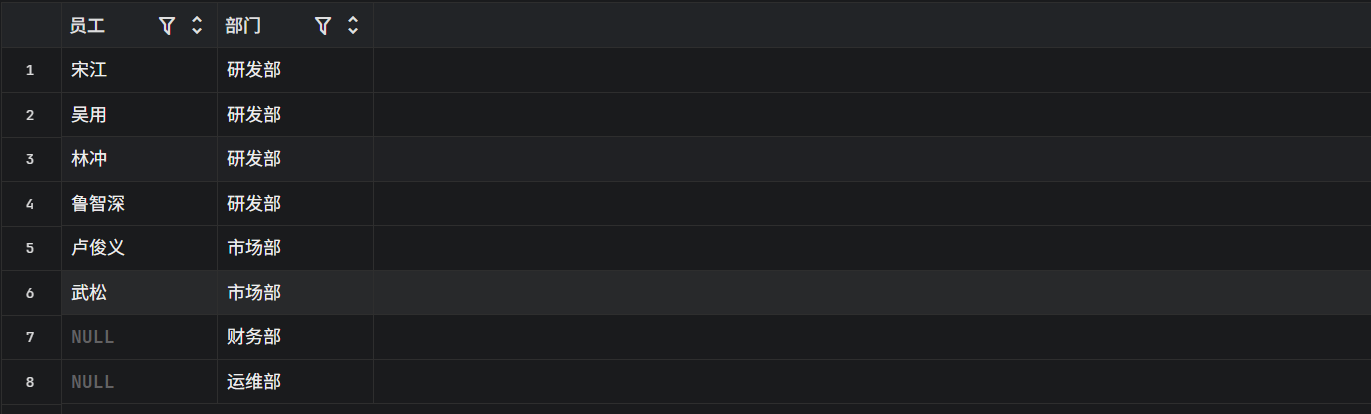
财务部和运维部出来了! 虽然它们下面没人,但作为右表的一员,被保留了,因为它们没人,所以员工这一列,数据库自动填入了 NULL,白胜不见了。因为他在左表,且在右表中没有对应关系,右连接不关心左边多余的数据,如果你想看所有部门的名单,不管下面有没有人,用右连接
左右连接就是看以那个数据表中的数据为核心参照FROM DATA1 LEFT JOIN DATA2 ON 条件,这里就是以左边的数据为核心参照,如果是RIGHT则反过来
三、自查询
自连接是指表自己和自己连接。这通常用于处理层级关系(树状结构),比如菜单目录、上下级关系。
查询员工的姓名,以及他直接上级的姓名
把 emps 表想象成两张表:一张是 员工表 (Worker),一张是 领导表 (Manager),连接条件:员工的 manager_id = 领导的 id
sql
SELECT
worker.name AS 员工,
manager.name AS 上级领导
FROM emps worker
INNER JOIN emps manager ON worker.manager_id = manager.id;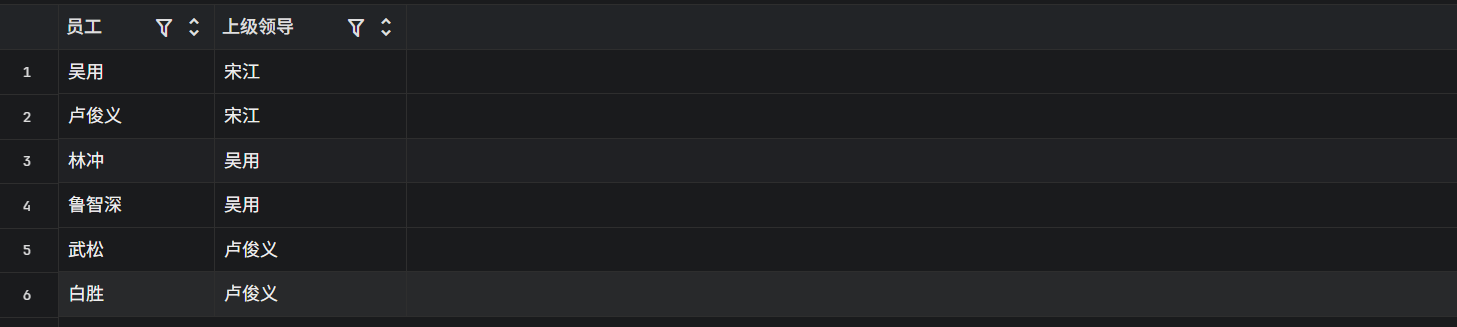
如果你想把 CEO 宋江也查出来(他没有上级,manager_id 是 NULL),应该用LEFT JOIN
sql
SELECT
worker.name AS 员工,
IFNULL(manager.name, '无上级') AS 上级领导
FROM emps worker
LEFT JOIN emps manager ON worker.manager_id = manager.id;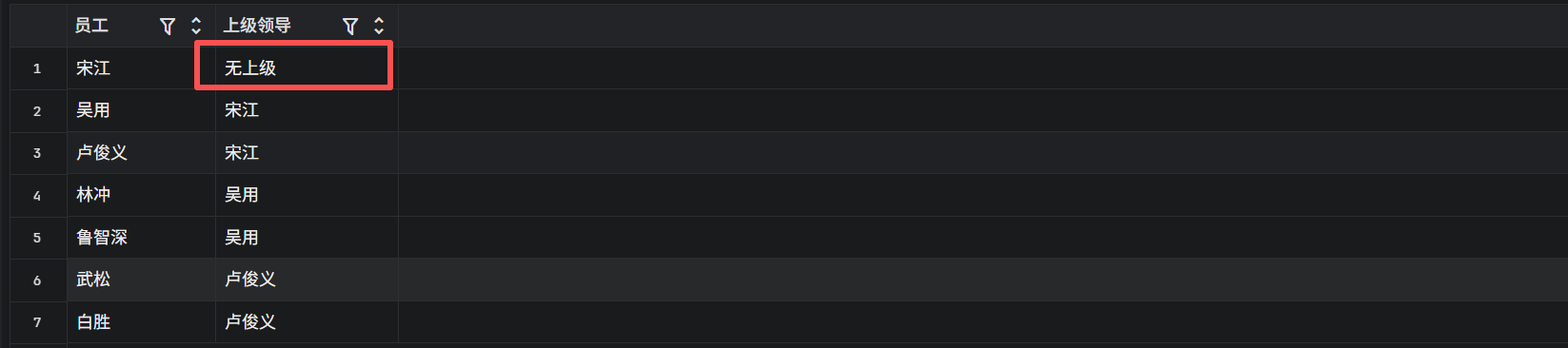
所以这里的自查询和上面的多表查询是一样的,只不过把一个表复制了一份或多份
四、子查询
子查询说白了就是套娃:在一个 SQL 语句内部,再嵌套一个(或多个)完整的 SQL 语句,通常子查询的执行顺序是:先执行里面的(内层),拿到结果后,再执行外面的(外层)。
我们按子查询出现的位置和返回数据的类型,分三个场景来讲解
4-1 标量子查询
出现在 WHERE 后面,通常配合 =, >, < 使用,比如我想找到工资比"林冲"高的所有员工。
-
第一步(内层):我要先知道林冲工资是多少,
SELECT salary FROM emps WHERE name = '林冲';--> 结果是10000。 -
第二步(外层):查询工资大于
10000的人
sql
SELECT name, salary
FROM emps
WHERE salary > (
-- 这一块是子查询,它必须用括号括起来
SELECT salary
FROM emps
WHERE name = '林冲'
);
MySQL 会先算出括号里的数字(10000),然后把外面的语句变成 WHERE salary > 10000 再执行
4-2 列子查询
出现在 WHERE 后面,通常配合 IN 或 NOT IN 使用,查询所有属于"研发部"或"市场部"的员工
- 第一步(内层):我不记得这两个部门的
ID是多少,先去depts表查一下,SELECT id FROM depts WHERE name IN ('研发部', '市场部');--> 结果是1, 2。 - 第二步(外层):去
emps表找dept_id是1或者2的人
sql
SELECT name, job, dept_id
FROM emps
WHERE dept_id IN (
-- 子查询返回一列数据:(1, 2)
SELECT id
FROM depts
WHERE name IN ('研发部', '市场部')
);
这里不能用 =,因为子查询返回了多行数据,必须用 IN
4-3 表子查询
出现在 FROM 后面,把查询结果当成一张新表来用,这是子查询里最实用但最难理解的部分。
查询每个部门的平均工资,然后把平均工资高于 10000 的部门和金额打印出来
- 第一步(内层):先算每个部门的平均工资。这本身就是一个分组查询
sql
SELECT dept_id, AVG(salary) AS avg_sal
FROM emps
GROUP BY dept_id;- 第二步(外层):把上面这张"虚拟表"起个别名叫
tmp_table,然后从里面筛选
sql
SELECT *
FROM (
-- 子查询开始:生成一张临时表
SELECT dept_id, AVG(salary) AS avg_sal
FROM emps
WHERE dept_id IS NOT NULL -- 排除掉没部门的白胜
GROUP BY dept_id
) AS tmp_table -- 必须给子查询的结果取个别名!
WHERE tmp_table.avg_sal > 10000;
以上就是本篇的全部内容了,很感谢你能看到这里