RAD 要点总结(地平线)
核心框架图
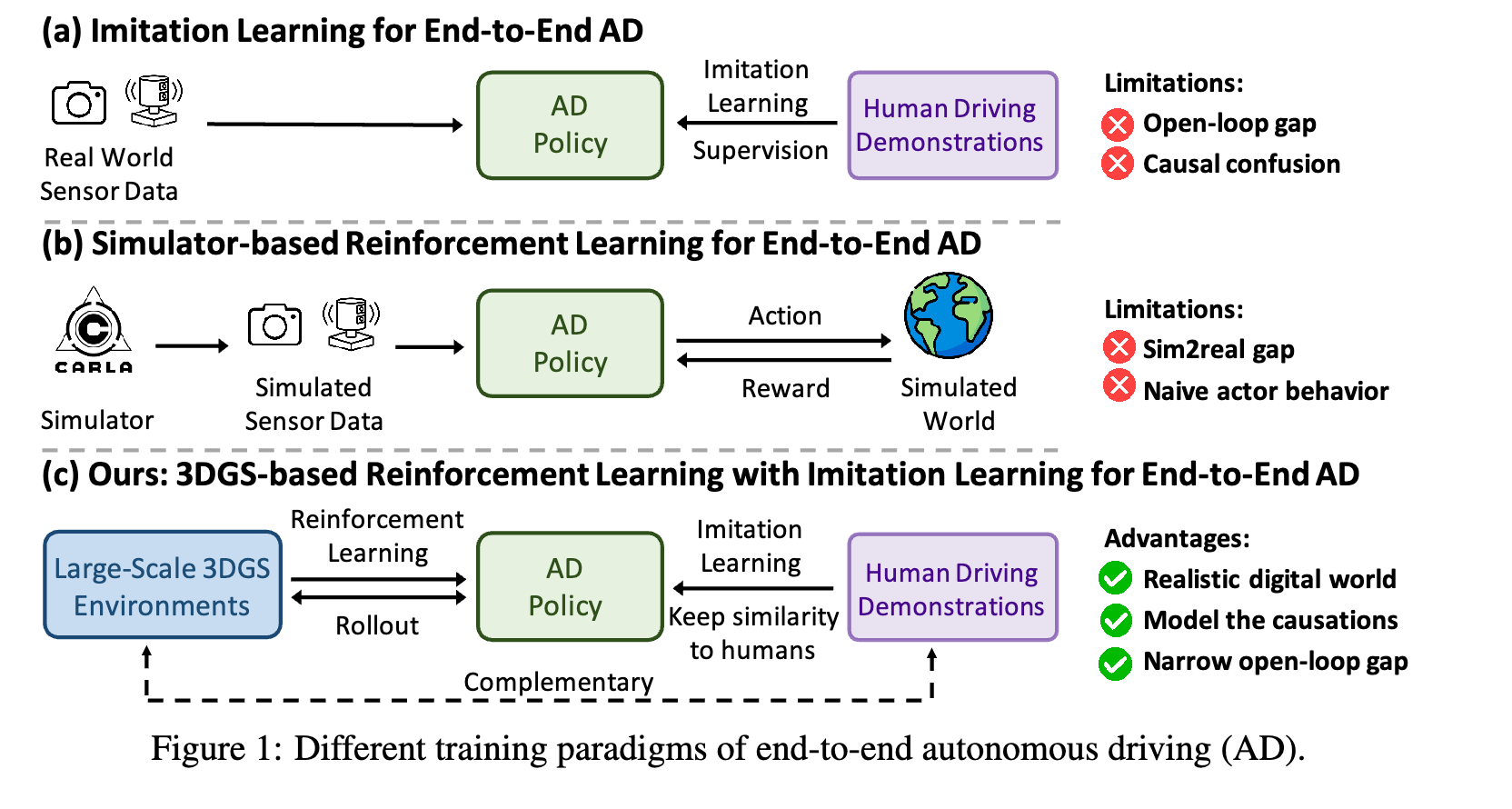
一、相关工作及劣势 (Related Work & Limitations)
1. 端到端自动驾驶相关工作
基于模仿学习的方法
- 代表性工作:UniAD, VAD, GenAD, ParaDrive, HydraMDP, VAD v2, SparseDrive, DiffusionDrive等
- 主要劣势 :
-
因果混淆问题 (Causal Confusion):
- IL方法主要学习观察和动作之间的相关性,而非因果关系
- 容易产生捷径学习(shortcut learning),例如仅从历史轨迹外推未来轨迹
- 难以识别规划决策背后的真正因果因素
-
开环训练与闭环部署的差距 (Open-loop Gap):
- IL策略在开环方式下训练,使用分布良好的驾驶演示数据
- 真实驾驶是闭环过程,每一步的微小轨迹误差会随时间累积
- 导致复合误差和分布外场景,IL训练的策略在这些未见情况下表现不佳
-
长尾分布覆盖不足:
- IL训练数据主要包含常见驾驶行为
- 对安全关键事件(如碰撞)的敏感性不足
- 倾向于收敛到平凡解
-
基于强化学习的方法
- 代表性工作:ROACH, IL Not Enough, GUMP等
- 主要挑战 :
-
真实环境训练的安全风险和成本:在真实世界进行闭环训练存在极高的安全风险和运营成本
-
仿真环境的局限性:
- 基于游戏引擎(如CARLA, CarSim, Unreal Engine, Unity)构建的仿真环境
- 无法提供真实的传感器模拟结果
- 限制了端到端AD策略的训练效果
-
2. 动态场景重建相关工作
隐式神经表示方法
- 代表性工作:UniSim, MARS, NeuRAD
- 特点:利用神经场景图进行结构化分解
- 劣势:渲染速度慢,阻碍实时应用
3D高斯点云方法
- 代表性工作:StreetGaussians, DrivingGaussian, HugSim等
- 特点:基于3D Gaussian Splatting (3DGS)进行动态城市场景重建
- 应用局限:先前工作主要将重建场景用于闭环评估,而非用于RL训练循环
二、核心工作 (Core Work)
1. 整体框架
RAD提出了首个基于3DGS的闭环强化学习框架,用于训练端到端自动驾驶策略。
核心思想:
- 利用3DGS技术构建真实世界的照片级数字副本
- 使AD策略能够广泛探索状态空间
- 通过大规模试错学习处理分布外场景
2. 主要组件
2.1 3DGS环境构建
- 使用3D高斯点云技术重建真实驾驶场景
- 提供照片级的传感器数据模拟
- 支持实时渲染和交互
2.2 奖励设计
- 安全相关奖励:专门设计用于引导策略有效响应安全关键事件
- 理解真实世界因果关系:通过奖励设计帮助策略理解真实世界的因果关系
2.3 RL与IL结合
- RL增强IL:通过建模因果关系和缩小开环差距来增强IL
- IL改进RL:通过确保更好的人类对齐来改进RL
- 协同优化:RL和IL共同优化端到端AD策略
2.4 解决关键挑战
挑战1:人类对齐问题 (Human Alignment Problem)
- 问题:RL的探索过程可能导致策略偏离类人行为,破坏动作序列的平滑性
- 解决方案:在RL训练过程中将模仿学习作为正则化项,帮助保持与人类驾驶行为的相似性
挑战2:稀疏奖励问题 (Sparse Reward Problem)
- 问题:RL经常面临稀疏奖励和收敛缓慢的问题
- 解决方案 :
- 引入与碰撞和偏差相关的密集辅助目标
- 帮助约束完整的动作分布
- 简化和解耦动作空间,减少RL的探索成本
3. 训练流程
3.1 规划预训练 (Planning Pre-Training)
- 使用模仿学习进行初始训练
- 动作空间离散化,使用预定义锚点
- 采用双焦点损失(dual focal loss)作为IL目标
3.2 强化后训练 (Reinforced Post-Training)
- RL和IL交替进行
- 每个完整周期:4轮RL训练 + 1轮IL训练
- RL训练轮次:320次迭代
- 使用滑动窗口机制,保持4个数据片段
三、创新点 (Contributions)
1. 方法创新
首个3DGS-based RL框架
- 首次提出基于3DGS的RL框架用于训练端到端AD策略
- 专门设计奖励、动作空间、优化目标和交互机制
- 提升训练效率和有效性
RL与IL的协同优化
- 创新结合:将RL和IL结合,协同优化端到端AD策略
- 互补优势 :
- RL通过建模因果关系和缩小开环差距来补充IL
- IL通过确保人类对齐来补充RL
安全奖励设计
- 设计专门的安全相关奖励
- 引导策略有效响应安全关键事件
- 帮助理解真实世界的因果关系
密集辅助目标
- 引入与碰撞和偏差相关的密集辅助目标
- 帮助约束完整的动作分布
- 解决稀疏奖励问题
2. 技术创新
动作空间优化
- 简化和解耦动作空间
- 减少RL的探索成本
- 提高训练效率
训练策略
- RL和IL交替训练机制
- 滑动窗口数据管理
- 优化的训练周期设计
四、实验结论 (Experimental Results)
1. 评估基准
闭环评估基准
- 构建了由多样化、未见过的3DGS环境组成的闭环评估基准
- 包含多种驾驶场景和复杂情况
2. 主要性能指标
碰撞率 (Collision Rate, CR)
- RAD相比IL方法 :碰撞率降低 3倍
- 动态碰撞率 (DCR):与动态障碍物碰撞的频率显著降低
- 静态碰撞率 (SCR):与静态障碍物碰撞的频率显著降低
其他关键指标
- 位置偏差率 (PDR):自车对专家轨迹的位置遵循度
- 航向偏差率 (HDR):方向精度评估
- 平均偏差距离 (ADD):无碰撞或偏差时的平均最近距离
- 纵向和横向急动度 (Jerk):车辆运动平滑度测量
3. 性能对比
与IL方法对比
- 大多数闭环指标:RAD表现优于IL方法
- 碰撞率:显著降低(3倍改进)
- 轨迹平滑度:生成更平滑的轨迹
- 碰撞避免:增强的碰撞避免能力
- 复杂环境适应性:在复杂环境中适应性更好
定性结果
论文展示了多种驾驶场景的定性比较:
- 绕行场景 (Detour)
- 密集交通中的爬行 (Crawl in Dense Traffic)
- 交通拥堵 (Traffic Congestion)
- U型转弯 (U-turn)
结果显示RAD在这些场景中都能生成更平滑的轨迹,增强碰撞避免,并提高在复杂环境中的适应性。
4. 实验设置
训练配置
-
规划预训练:
- 学习率:1e-4
- 优化器:AdamW
- 批次大小:512
- 训练步数:30k
- 训练GPU:128 RTX4090
-
强化后训练:
- 学习率:5e-6
- RL工作器数量:32
- RL批次大小:32
- IL批次大小:128
- GAE参数:γ = 0.9, λ = 0.95
- 训练GPU:32 RTX4090
5. 整体结论
- 方法有效性:RAD在闭环评估中实现了比IL方法更强的性能
- 安全性提升:碰撞率降低3倍,显著提升安全性
- 实用性:方法具有实际应用价值,能够支持真实世界的自动驾驶部署
- 创新价值:首次将3DGS与RL结合用于AD训练,为未来研究提供了新方向
论文信息
- 标题:RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
- arXiv:https://arxiv.org/abs/2502.13144v2
- 代码:https://github.com/hustvl/RAD
- 作者:Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, Ying Zhang, Wenyu Liu, Qian Zhang, Xinggang Wang
- 机构:华中科技大学 (Huazhong University of Science & Technology), 地平线机器人 (Horizon Robotics)
关键贡献总结
- 首次提出3DGS-based RL框架用于训练端到端AD策略
- 创新结合RL和IL,实现协同优化,RL补充IL的因果关系建模,IL补充RL的人类对齐
- 设计专门的安全奖励和密集辅助目标,解决稀疏奖励问题
- 在闭环评估基准上验证有效性,碰撞率相比IL方法降低3倍
- 提供完整的训练框架,包括奖励设计、动作空间优化、训练策略等