在增强现实(XR)的理想世界里,数字信息应该与物理环境完美融合。然而,现实往往是残酷的:杂乱的虚拟窗口遮挡视线、突如其来的音频通知干扰对话、复杂的菜单操作打断了现实生活节奏。
感知智能用户界面(Perceptually Intelligent UI:这种界面不再是死板的信息叠加,而是能像人类助手一样,根据你的感知状态、所处环境和实时意图进行"进化"。
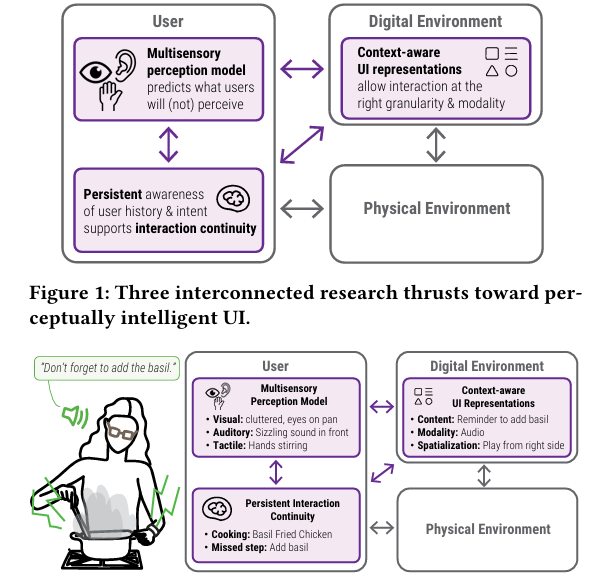
图 1 提出了实现感知智能 UI 的三个核心研究方向(Thrusts):
多感官感知模型 (Multisensory Perception Model): 位于"用户"框内。系统通过模型预测用户在特定时刻能感知到什么(看到、听到、触到),或者由于分心、环境吵闹等原因会错过什么。
持久意识 (Persistent Awareness): 同样位于"用户"框内。系统记录用户的历史行为和意图,以保证交互的连续性。例如,系统记得你刚才在干什么,接下来打算干什么。
情境感知 UI 表现形式 (Context-aware UI Representations): 位于"数字环境"框内。系统根据用户当下的状态,决定以什么方式(文字、声音、触觉)和什么精细程度来呈现数字信息。
建模多感官感知与行为(理解人类的感知极限)
XR 系统首先需要回答一个问题:"用户现在能感知到什么?什么会让他们感到困惑?"
为了解决数字内容与现实感官的冲突,研究者建立了精细的计算模型:
- 优化空间音频布局 (Auptimize): 人类听觉存在"混淆锥"效应(分不清前后声音)和定位模糊。
Auptimize系统通过计算模型预测这些混淆概率,利用整数规划算法自动调整虚拟声源的位置。实验证明,这能减少 25.2% 的感知错误。 - 跨模态反馈 (SonoHaptics): 当视觉被占用时,系统可以利用感官映射。例如,将颜色的亮度映射为音频音调的高低,将物体的大小映射为触觉振动的强度。这让用户在不看屏幕的情况下,仅凭听觉和触觉就能精准选择物体(准确率提升 16.3%)。
核心逻辑: 系统不再盲目输出信息,而是先评估你的感官带宽,选择最不容易出错的通道进行交互。
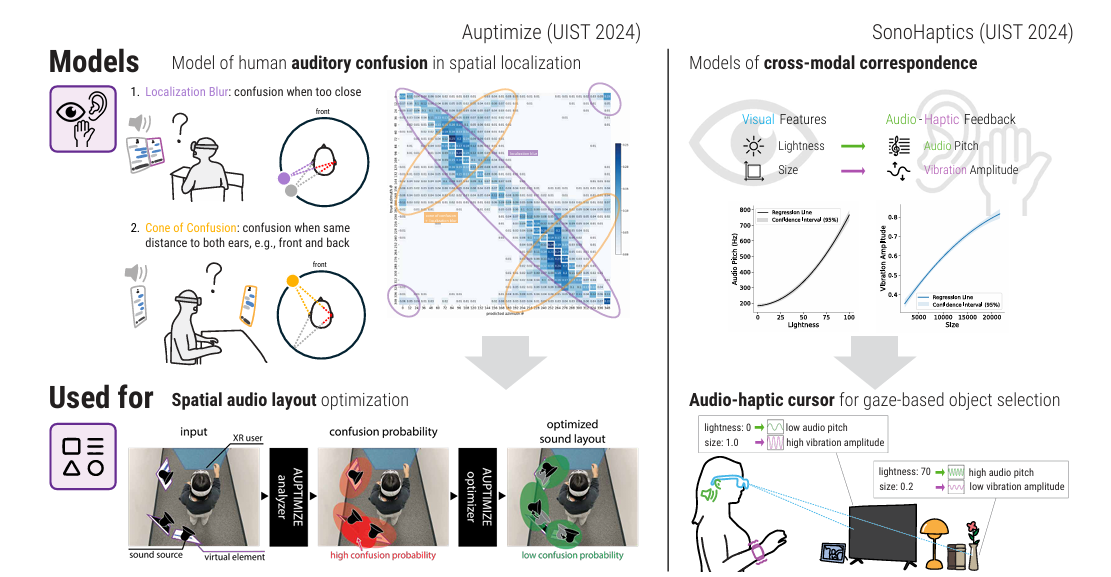
图 2 通过一个具体的烹饪例子展示了这套系统是如何工作的:
场景设定: 一个用户正在做"罗勒炒鸡",但她漏掉了一个步骤:加罗勒。
用户的状态(感知模型):
视觉: 眼睛盯着锅,环境比较杂乱(视觉被占用)。
听觉: 正前方有热油滋滋响的声音(正前方听觉被噪声占用)。
触觉: 双手正在搅拌(触觉/双手被占用)。
系统的判断(持久交互连续性): 系统记得她正在做这道菜,并识别出她错过了"加罗勒"这一步。
系统的响应(情境感知 UI):
内容: 提醒加罗勒。
方式 (Modality): 因为用户眼睛和手都忙,系统选择用音频提醒。
空间化 (Spatialization): 因为正前方有炒菜声,系统特意将声音设置在右侧播放,以确保用户能听清。
最终结果: 系统从侧面发声提醒:"别忘了加罗勒。"
开发情境感知 UI 表现形式(让界面从"死板"变"流动")
传统的 XR 界面直接照搬了手机的"单体 App"逻辑,但在移动场景下,没人想在空气中点开复杂的菜单。
- 原子化功能拆解 (MineXR): 研究发现用户更需要"特定任务的功能组",而非完整的 App。研究者将应用分解为原子化的组件(Widgets)。
- 生成式组件与环境融合: 系统利用视觉语言模型(VLM)实时分析用户的第一视角。
- 动态组合: 如果你在烹饪,系统会自动提取食谱步骤和计时器,组合成一个临时界面。
- 环境化呈现 (BlendMR): 利用环境中的物理表面(如墙面、冰箱面)来展示信息。相比传统的悬浮窗口,这种环境 UI 减少了约 40% 的视觉杂乱感。
核心逻辑: 界面不再是一成不变的,而是根据当前任务动态生成的"功能合集",且能聪明地隐藏在环境背景中。
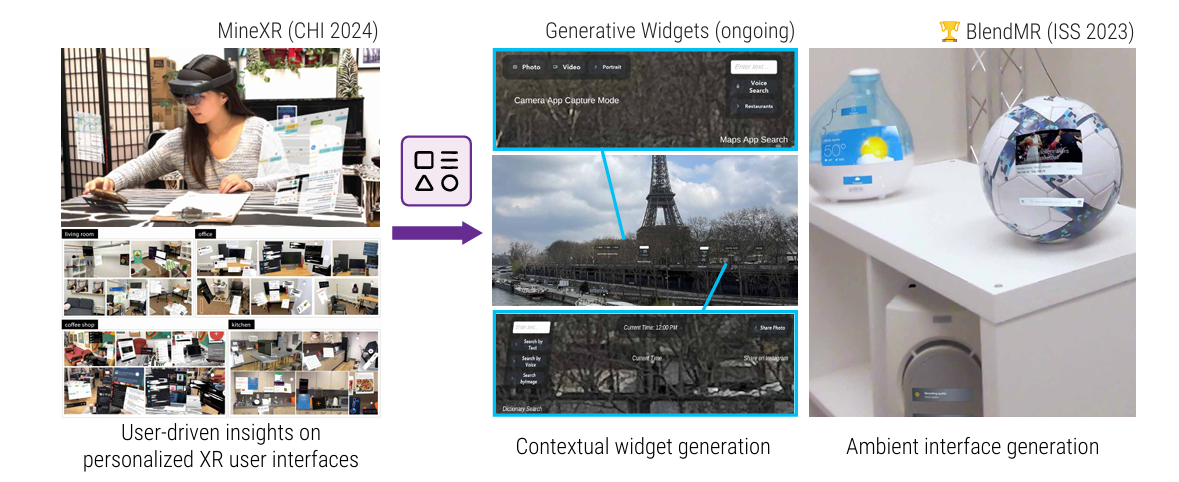
左侧:展示了用户在不同环境(客厅、办公室、咖啡馆、厨房)中如何组织自己的 XR 界面。
中间:Generative Widgets (正在进行中) 展示了系统如何根据用户当前的环境(图中是巴黎埃菲尔铁塔)自动生成界面。实现了界面的原子化和重组。不再需要用户手动去开 App,系统根据用户的意图直接把"功能组合"推送到你面前。
右侧:BlendMR (ISS 2023) ------ 环境融合, 展示了如何将这些生成的组件"贴"在现实世界的物体上。
支持持久交互连续性(赋予系统记忆与意图感)
在这里插入图片描述
当前的 XR 交互往往是断裂的:每次交互都要重新开启,系统不记得你刚才干了什么。
- 数字化历史回放 (RealityReplay): 人的注意力是有限的。
RealityReplay持续记录用户周围 360° 的重要事件(如身后有人走过、刚才错过的通知)。用户可以随时通过"倒带"功能查看由于视觉死角或分心错过的时刻。 - 意图锚定助手 (Persistent Assistant): 传统的语音助手需要反复对话。
- 一站式意图建立: 比如在超市门口只需说一次"帮我找低糖食物",这个意图就被系统"锚定"。
- 本能化交互: 接下来,用户只需注视商品并做一个捏合手势,系统通过毫秒级的触觉震动反馈(行/不行),无需再开口说话。这种交互从"对话式"变成了"本能式"。
核心逻辑: 通过维持对用户历史和意图的感知,系统实现了跨越时间与空间的无缝辅助,消除了反复重新建立情境的摩擦。
总结
感知智能 UI 的出现,标志着 XR 交互从 "人适应机器" 向量 "机器适应人" 的跨越。
通过理解感官极限 、动态重组界面 以及持续锁定意图,未来的 XR 设备将不再是遮挡我们视线的屏障,而是成为我们感知世界的一种延伸。正如 Hyunsung Cho 在论文中所言:科技的终极目标是无缝集成到人类经验中,支持而非淹没我们的自然能力。
本文参考论文:Hyunsung Cho. "Perceptually Intelligent UI for Augmented Everyday Interaction" (UIST '25).