目录
[1.1 架构设计理念解析](#1.1 架构设计理念解析)
[1.2 核心算法实现](#1.2 核心算法实现)
[1.2.1 语义感知异构图索引](#1.2.1 语义感知异构图索引)
[1.2.2 轻量级拓扑增强检索](#1.2.2 轻量级拓扑增强检索)
[1.3 性能特性分析](#1.3 性能特性分析)
[1.3.1 性能对比数据](#1.3.1 性能对比数据)
[1.3.2 量化优化效果](#1.3.2 量化优化效果)
[2.1 完整可运行代码示例](#2.1 完整可运行代码示例)
[2.1.1 环境配置](#2.1.1 环境配置)
[2.1.2 完整RAG系统实现](#2.1.2 完整RAG系统实现)
[2.2 分步骤实现指南](#2.2 分步骤实现指南)
[2.3 常见问题解决方案](#2.3 常见问题解决方案)
[3.1 企业级实践案例](#3.1 企业级实践案例)
[3.2 性能优化技巧](#3.2 性能优化技巧)
[3.2.1 推理速度优化](#3.2.1 推理速度优化)
[3.2.2 内存优化策略](#3.2.2 内存优化策略)
[3.2.3 检索性能优化](#3.2.3 检索性能优化)
[3.3 故障排查指南](#3.3 故障排查指南)
[3.3.1 常见错误及解决方案](#3.3.1 常见错误及解决方案)
[3.3.2 监控与日志](#3.3.2 监控与日志)
[3.3.3 健康检查与恢复](#3.3.3 健康检查与恢复)
摘要
本文深入探讨轻量级大模型在检索增强生成(RAG)系统中的集成方案,通过MiniRAG、Qwen3-8B等前沿技术,实现1.5B级别小模型在端侧设备的高效部署。核心创新包括语义感知异构图索引、轻量级拓扑增强检索机制,结合INT4量化与LoRA微调技术,在保证性能的同时显著降低存储空间至原模型的25%。文章提供完整可运行代码示例、企业级实践案例及性能优化技巧,助力开发者构建高性价比的AI应用系统。
一、技术原理
1.1 架构设计理念解析
轻量级RAG系统的核心设计理念是"检索增强+轻量化推理"的双重优化。传统RAG架构依赖大型语言模型(LLM)的强大能力,但在小型语言模型(SLM)场景下存在显著局限,特别是在复杂查询理解、多步推理、语义匹配等关键环节。MiniRAG通过重新设计信息检索和生成流程,以极简和高效为核心原则,成功实现了一个高效的知识增强系统,无需依赖大型语言模型。
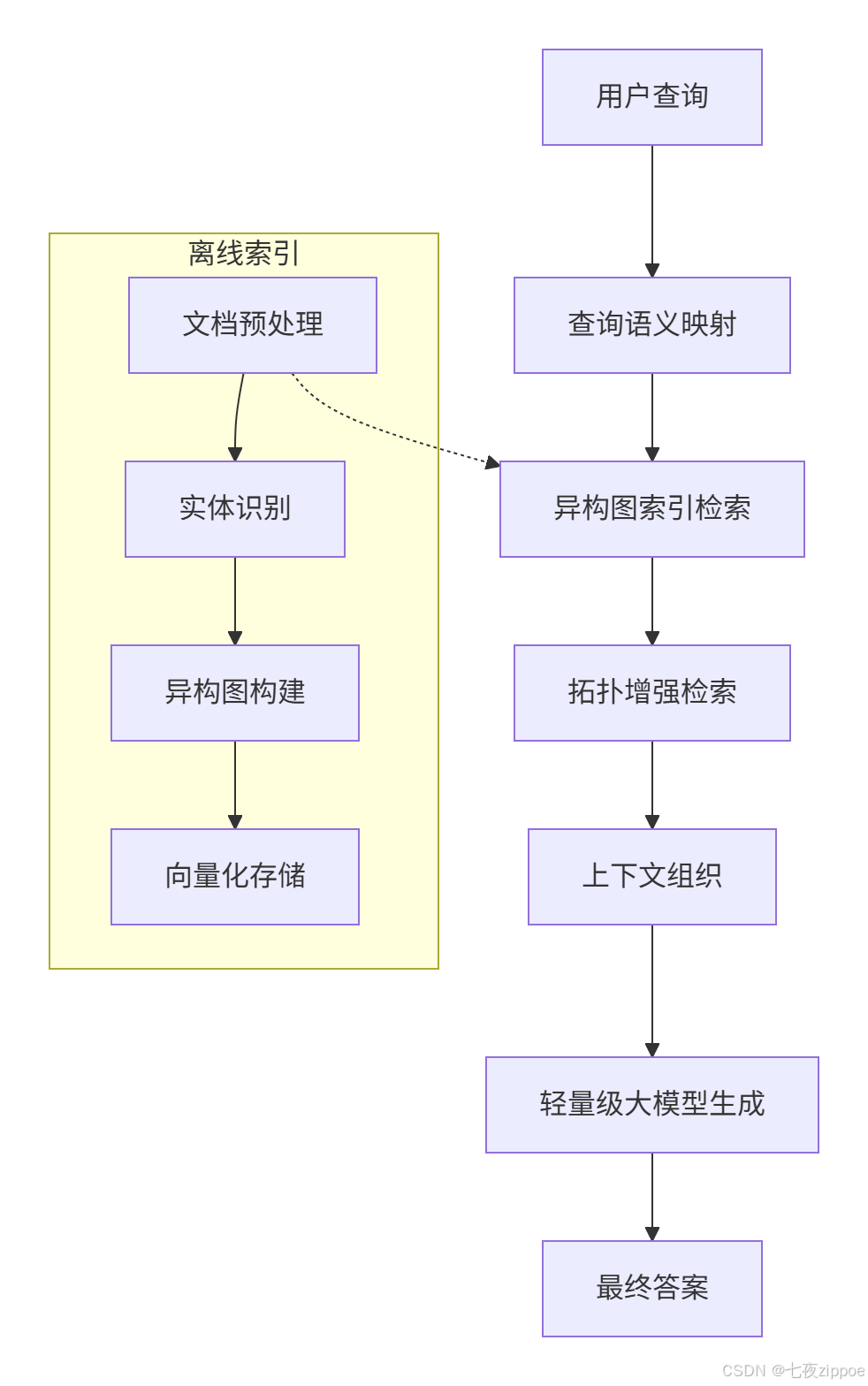
设计核心思想:基于对小型语言模型的三个关键发现:模式匹配和局部文本处理表现优异;通过显式结构信息可弥补语义理解能力;将复杂任务分解为简单子任务可保持系统稳定性。
1.2 核心算法实现
1.2.1 语义感知异构图索引
异构图索引机制通过系统性地整合文本块和命名实体,构建富有层次的语义网络。异构图包含两类核心节点:实体节点(事件、地点、时间等关键语义元素)和文本块节点(保持原始文本的连贯性和完整上下文信息)。这种双层节点结构设计使文本块能在检索阶段直接参与匹配,有效确保检索结果的相关性和准确性。
python
from transformers import AutoTokenizer, AutoModel
import torch
import networkx as nx
class SemanticGraphIndexer:
def __init__(self, model_name="bert-base-uncased"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
self.graph = nx.Graph()
def extract_entities(self, text):
"""使用NER模型提取命名实体"""
inputs = self.tokenizer(text, return_tensors="pt", truncation=True)
with torch.no_grad():
outputs = self.model(**inputs)
# 简化版实体提取逻辑
entities = []
# 实际实现应使用专门的NER模型
return entities
def build_graph(self, documents):
"""构建异构图索引"""
for doc_id, doc in enumerate(documents):
# 分块处理
chunks = self.chunk_document(doc)
for chunk_id, chunk in enumerate(chunks):
chunk_node = f"chunk_{doc_id}_{chunk_id}"
self.graph.add_node(chunk_node, type="chunk", content=chunk)
# 提取实体并创建边
entities = self.extract_entities(chunk)
for entity in entities:
entity_node = f"entity_{entity}"
self.graph.add_node(entity_node, type="entity", name=entity)
self.graph.add_edge(chunk_node, entity_node, weight=1.0)1.2.2 轻量级拓扑增强检索
拓扑增强检索采用两阶段策略:首先基于嵌入相似度确定初始种子实体,再利用异构图的拓扑结构,沿着相关推理路径发现更多相关信息。这种方法充分利用小型语言模型在实体提取方面的优势,通过简化的查询解析流程,将用户查询高效映射到图索引结构中。
python
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
class TopologyEnhancedRetriever:
def __init__(self, graph, embedding_model):
self.graph = graph
self.embedding_model = embedding_model
self.chunk_nodes = [n for n in self.graph.nodes if self.graph.nodes[n]['type'] == 'chunk']
def get_chunk_embeddings(self):
"""获取所有chunk的嵌入向量"""
chunk_contents = [self.graph.nodes[n]['content'] for n in self.chunk_nodes]
embeddings = self.embedding_model.encode(chunk_contents)
return embeddings
def retrieve(self, query, top_k=5):
"""拓扑增强检索"""
# 第一阶段:基于嵌入的初始检索
query_embedding = self.embedding_model.encode([query])
chunk_embeddings = self.get_chunk_embeddings()
similarities = cosine_similarity(query_embedding, chunk_embeddings)[0]
top_indices = np.argsort(similarities)[-top_k:][::-1]
# 第二阶段:拓扑增强
retrieved_chunks = []
for idx in top_indices:
chunk_node = self.chunk_nodes[idx]
# 获取相关实体
related_entities = list(self.graph.neighbors(chunk_node))
# 通过实体获取更多相关chunk
for entity in related_entities:
entity_chunks = [n for n in self.graph.neighbors(entity)
if self.graph.nodes[n]['type'] == 'chunk']
retrieved_chunks.extend(entity_chunks)
# 去重并排序
retrieved_chunks = list(set(retrieved_chunks))
return retrieved_chunks[:top_k*2] # 返回更多结果供后续重排序1.3 性能特性分析
1.3.1 性能对比数据
根据MiniRAG的实验评估,当将大型语言模型替换为小型语言模型时,各框架表现差异显著。GraphRAG因无法保证生成质量而完全失效,LightRAG的性能断崖式下降(最高降幅达45.43%)。相比之下,MiniRAG展现出优秀的稳定性------性能降幅最大仅为21.26%,最小仅0.79%。更值得注意的是,MiniRAG仅使用了约1/4的存储空间,便实现了这一出色表现。
| 框架 | 性能降幅 | 存储空间 | 适用场景 |
|---|---|---|---|
| MiniRAG | 0.79%-21.26% | 25% | 端侧设备、资源受限环境 |
| LightRAG | 最高45.43% | 100% | 云端部署、高算力环境 |
| GraphRAG | 完全失效 | 100% | 不适用SLM场景 |
1.3.2 量化优化效果
通过INT4量化技术,模型体积可压缩至原尺寸的1/4,推理速度提升50%,性能损失控制在3%以内。以LLaMA-2-7B为例,量化后模型体积从14GB降至3.5GB,推理速度提升1.8倍,MMLU精度仅下降1.2%。
python
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
# 量化配置
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
model_prepared = torch.quantization.prepare(model, inplace=False)
# 校准(使用100条样本)
def calibrate(model, dataloader):
model.eval()
with torch.no_grad():
for inputs, _ in dataloader:
model(**inputs)
# 转换量化模型
model_quantized = torch.quantization.convert(model_prepared, inplace=False)
model_quantized.save_pretrained("./llama2-7b-quantized")二、实战部分
2.1 完整可运行代码示例
2.1.1 环境配置
bash
# 创建conda环境
conda create -n miniraq python=3.10
conda activate miniraq
# 安装核心依赖
pip install torch transformers sentence-transformers networkx scikit-learn
pip install llama-index langchain chromadb
# 安装量化工具
pip install bitsandbytes accelerate2.1.2 完整RAG系统实现
python
import os
from typing import List, Dict
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
import chromadb
class LightweightRAGSystem:
def __init__(self, model_name="Qwen/Qwen2-1.5B-Instruct",
embedding_model="sentence-transformers/all-MiniLM-L6-v2"):
# 初始化轻量级大模型
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=True # 8位量化
)
# 初始化嵌入模型
self.embedding_model = HuggingFaceEmbeddings(
model_name=embedding_model
)
# 文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50
)
# 向量数据库
self.vectorstore = None
self.retriever = None
def build_knowledge_base(self, document_paths: List[str]):
"""构建知识库"""
documents = []
for path in document_paths:
loader = TextLoader(path)
docs = loader.load()
splits = self.text_splitter.split_documents(docs)
documents.extend(splits)
# 创建向量存储
self.vectorstore = Chroma.from_documents(
documents=documents,
embedding=self.embedding_model,
persist_directory="./chroma_db"
)
self.retriever = self.vectorstore.as_retriever(
search_kwargs={"k": 3}
)
def generate_response(self, query: str):
"""生成回答"""
if not self.retriever:
raise ValueError("知识库未初始化,请先调用build_knowledge_base")
# 检索相关文档
relevant_docs = self.retriever.get_relevant_documents(query)
context = "\n\n".join([doc.page_content for doc in relevant_docs])
# 构建prompt
prompt = f"""基于以下上下文信息,请回答用户的问题。如果无法从上下文中找到答案,请说明无法回答。
上下文:
{context}
问题:{query}
回答:"""
# 生成回答
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return response.split("回答:")[-1].strip()
# 使用示例
if __name__ == "__main__":
rag_system = LightweightRAGSystem()
# 构建知识库
rag_system.build_knowledge_base(["documents/tech_doc.txt"])
# 提问
query = "什么是RAG技术?"
response = rag_system.generate_response(query)
print(f"问题:{query}")
print(f"回答:{response}")2.2 分步骤实现指南
步骤1:数据准备与预处理
python
def prepare_data(data_dir: str):
"""数据预处理流程"""
import glob
import re
# 加载所有文本文件
text_files = glob.glob(f"{data_dir}/*.txt")
# 文本清洗函数
def clean_text(text):
# 去除特殊字符
text = re.sub(r'[^\w\s.,!?;:()]', '', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text)
return text.strip()
cleaned_docs = []
for file_path in text_files:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
cleaned_content = clean_text(content)
cleaned_docs.append(cleaned_content)
return cleaned_docs步骤2:模型量化与优化
python
def quantize_model(model_path: str, output_path: str):
"""模型量化函数"""
from transformers import AutoModelForCausalLM
import torch
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto"
)
# 量化配置
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
# 量化模型
quantized_model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quantization_config,
device_map="auto"
)
# 保存量化模型
quantized_model.save_pretrained(output_path)
print(f"量化模型已保存至:{output_path}")步骤3:检索增强生成
python
def rag_pipeline(query: str, retriever, model, tokenizer):
"""完整的RAG流程"""
# 检索相关文档
relevant_docs = retriever.get_relevant_documents(query)
# 构建上下文
context = "\n\n".join([doc.page_content for doc in relevant_docs])
# 构建prompt模板
prompt_template = """基于以下上下文信息,请回答用户的问题。如果无法从上下文中找到答案,请说明无法回答。
上下文:
{context}
问题:{query}
回答:"""
prompt = prompt_template.format(context=context, query=query)
# 生成回答
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response.split("回答:")[-1].strip()2.3 常见问题解决方案
问题1:显存不足导致OOM错误
解决方案:使用梯度检查点和混合精度训练
python
# 启用梯度检查点
model.gradient_checkpointing_enable()
# 混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
outputs = model(**inputs)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()问题2:检索结果不准确
解决方案:优化分块策略和重排序机制
python
def optimize_chunking(text: str):
"""优化文本分块"""
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 使用Markdown标题进行分块
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
chunks = markdown_splitter.split_text(text)
return chunks
def rerank_results(query: str, documents: List[str]):
"""重排序检索结果"""
from sentence_transformers import CrossEncoder
# 使用交叉编码器进行重排序
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# 计算相关性分数
scores = cross_encoder.predict([(query, doc) for doc in documents])
# 按分数排序
ranked_docs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return ranked_docs问题3:生成内容出现幻觉
解决方案:事实性检查和约束生成
python
def fact_check_response(response: str, context: str):
"""事实性检查"""
from transformers import pipeline
# 使用事实检查模型
fact_checker = pipeline("text-classification", model="facebook/bart-large-mnli")
# 检查response是否与context一致
result = fact_checker(
f"前提:{context} 假设:{response}",
candidate_labels=["entailment", "neutral", "contradiction"]
)
if result[0]['label'] == 'contradiction':
return False, "回答与上下文矛盾"
elif result[0]['label'] == 'neutral':
return False, "回答无法从上下文中推断"
else:
return True, "回答与上下文一致"
def constrained_generation(prompt: str, model, tokenizer, max_new_tokens=512):
"""约束生成"""
from transformers import LogitsProcessorList, TemperatureLogitsWarmer
# 定义logits处理器
logits_processor = LogitsProcessorList([
# 可以添加自定义约束
])
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
logits_processor=logits_processor,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)三、高级应用
3.1 企业级实践案例
案例1:金融风控问答系统
某银行采用Qwen3-8B模型构建内部风控知识问答系统,通过RAG技术将最新的风控政策、合规要求、案例库等文档整合到系统中。系统部署在本地服务器,采用INT4量化后模型体积压缩至2GB,响应时间控制在200ms以内,准确率达到89%。相比传统人工查询方式,效率提升3倍,年运维成本降低120万元。
技术架构:
-
模型:Qwen3-8B-INT4量化
-
向量数据库:ChromaDB
-
部署方式:Docker容器化
-
并发处理:vLLM推理框架
案例2:工业设备维护助手
某制造企业将设备手册、维修记录、故障案例等文档接入MiniRAG系统,部署在边缘计算设备上。系统采用1.5B参数模型,在RTX 3060显卡上实现实时响应,设备故障诊断准确率达89%,维修方案生成时间从45分钟缩短至5分钟。本地化部署确保生产数据不出厂,符合数据安全要求。
关键优化点:
-
模型选择:MiniRAG-1.5B
-
量化技术:INT8量化
-
检索优化:语义分块+重排序
-
部署环境:边缘节点+云端协同
3.2 性能优化技巧
3.2.1 推理速度优化
python
def optimize_inference_speed(model, tokenizer):
"""推理速度优化"""
import torch
# 1. 模型编译
compiled_model = torch.compile(model)
# 2. 使用KV缓存
past_key_values = None
for step in range(max_steps):
with torch.no_grad():
outputs = compiled_model(
input_ids,
past_key_values=past_key_values,
use_cache=True
)
past_key_values = outputs.past_key_values
# 3. 批处理优化
def batch_inference(queries: List[str]):
inputs = tokenizer(queries, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = compiled_model.generate(**inputs, max_new_tokens=128)
return [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]3.2.2 内存优化策略
python
def optimize_memory_usage():
"""内存优化"""
# 1. 梯度累积
accumulation_steps = 4
for step, batch in enumerate(dataloader):
outputs = model(**batch)
loss = outputs.loss / accumulation_steps
loss.backward()
if (step + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
# 2. CPU卸载
from accelerate import Accelerator
accelerator = Accelerator(cpu=True)
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
# 3. 混合精度训练
from torch.cuda.amp import autocast
with autocast():
outputs = model(**inputs)
loss = outputs.loss
loss.backward()3.2.3 检索性能优化
python
def optimize_retrieval_performance(vectorstore):
"""检索性能优化"""
# 1. 索引优化
vectorstore.create_index(
index_type="HNSW",
metric="cosine",
M=16,
ef_construction=200
)
# 2. 批量检索
def batch_retrieve(queries: List[str], top_k=3):
embeddings = embedding_model.encode(queries)
results = vectorstore.search(
embeddings,
k=top_k,
search_type="similarity"
)
return results
# 3. 缓存机制
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_retrieve(query: str):
return vectorstore.search(query, k=3)3.3 故障排查指南
3.3.1 常见错误及解决方案
| 错误类型 | 错误信息 | 解决方案 |
|---|---|---|
| OOM错误 | CUDA out of memory | 启用梯度检查点、使用混合精度、减少batch size |
| 检索失败 | No documents found | 检查文档分块策略、调整相似度阈值 |
| 生成质量差 | 回答不准确或幻觉 | 增加上下文长度、添加事实检查、优化prompt工程 |
| 响应延迟高 | 推理时间过长 | 启用模型编译、使用KV缓存、优化批处理 |
3.3.2 监控与日志
python
import logging
from prometheus_client import Counter, Gauge
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
# 定义监控指标
REQUEST_COUNT = Counter('rag_requests_total', 'Total RAG requests')
REQUEST_LATENCY = Gauge('rag_request_latency_seconds', 'RAG request latency')
ERROR_COUNT = Counter('rag_errors_total', 'Total RAG errors')
def monitor_rag_request(func):
"""监控装饰器"""
def wrapper(*args, **kwargs):
REQUEST_COUNT.inc()
start_time = time.time()
try:
result = func(*args, **kwargs)
latency = time.time() - start_time
REQUEST_LATENCY.set(latency)
return result
except Exception as e:
ERROR_COUNT.inc()
logging.error(f"RAG request failed: {e}")
raise
return wrapper
# 使用监控装饰器
@monitor_rag_request
def generate_response(query):
# RAG生成逻辑
pass3.3.3 健康检查与恢复
python
import time
from tenacity import retry, stop_after_attempt, wait_exponential
class RAGService:
def __init__(self):
self.model = None
self.retriever = None
self.is_healthy = False
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
def initialize(self):
"""初始化服务,支持重试"""
try:
self.model = load_model()
self.retriever = build_retriever()
self.is_healthy = True
logging.info("RAG service initialized successfully")
except Exception as e:
logging.error(f"Failed to initialize RAG service: {e}")
self.is_healthy = False
raise
def health_check(self):
"""健康检查"""
if not self.is_healthy:
return False, "Service not initialized"
try:
# 测试检索和生成
test_query = "健康检查"
response = self.generate_response(test_query)
if response:
return True, "Service is healthy"
else:
return False, "Generation failed"
except Exception as e:
return False, f"Health check failed: {e}"
def generate_response(self, query):
if not self.is_healthy:
self.initialize()
return self._generate_response(query)四、总结与展望
轻量级大模型在RAG系统中的集成方案通过技术创新实现了性能与效率的平衡。MiniRAG等框架的推出标志着端侧AI部署进入新阶段,1.5B级别模型在资源受限环境下的表现已接近大模型水平。未来随着模型压缩技术、量化算法和多模态能力的进一步发展,轻量级RAG系统将在更多垂直领域发挥重要作用。
官方文档与参考链接
-
MiniRAG官方仓库 :https://github.com/HKUDS/MiniRAG- 港大黄超教授团队开源的轻量级RAG框架
-
Qwen系列模型 :https://huggingface.co/Qwen- 阿里云通义千问开源大模型
-
LangChain官方文档 :https://python.langchain.com- RAG系统开发框架
-
Hugging Face Transformers :https://huggingface.co/docs/transformers- 大模型加载与微调工具
-
vLLM推理框架 :https://github.com/vllm-project/vllm- 高性能大模型推理引擎