摘要
增强式学习是一种通过与环境的互动来学习最优行为的机器学习方法。与监督学习不同,增强学习并不依赖预先标记的正确答案,而是通过智能体(Actor)在环境中执行动作并获得奖励来逐步优化其行为策略。常见的应用包括游戏AI(如AlphaGo)和机器人控制。增强学习的核心框架包括智能体、环境、状态观测、动作执行和奖励反馈,其目标是通过最大化累积奖励来训练智能体。增强学习通常涉及策略网络的设计、损失函数的定义以及基于策略梯度的优化方法,以解决在动态和不确定环境中学习的问题。
Abstract
Reinforcement Learning is a machine learning method that learns optimal behaviors through interaction with the environment. Unlike supervised learning, reinforcement learning does not rely on pre-labeled correct answers. Instead, an agent (Actor) learns by performing actions in the environment and receiving rewards to gradually optimize its behavioral strategy. Common applications include game AI (e.g., AlphaGo) and robotic control. The core framework of reinforcement learning consists of an agent, environment, state observations, action execution, and reward feedback. The goal is to train the agent by maximizing cumulative rewards. Reinforcement learning typically involves designing a policy network, defining a loss function, and employing optimization methods such as policy gradients to address learning in dynamic and uncertain environments.
一.增强式学习运用环境
对于增强式学习(RL)这个技术并不陌生,因为很多大家熟知的应用如AIphaGo,其背后就用到了RL技术。到目前我们学习的都是监督式学习,就如训练一个图像分类器,我们不只要告诉机器其输入是什么,还要告诉机器应该有怎样的输出,然后就可以去训练应该图像分类器。

这个方法也是基于监督式学习的方法,就算是自监督是学习其实也是用很类似监督式学习的方法,只是不用人工特别的去标记,或者在自动编码器中虽说其是一个非监督式学习的方法,没用用到人工标记标签,但是我们还是要用到一个标签只是这个标签不需要人工产生而已。
而RL则是另外一个问题,当给机器一个输入时我们不知道最佳输出是什么,就如下围棋,看到当前棋局下一部落子到哪里,下到哪里又是最好的呢,我们是不知道的。所以对于这些不知道正确答案的情况下,往往就是RL可以排上用场的时候。

机器也不是一无所知,我们不知道正确答案是什么,但是机器可以通过会与环境互动得到回应,知道什么是好什么不好。
二.增强式学习的定义
1.增强式学习的说明
RL其与我们之前学习的机器学习是有一样的框架的(三个步骤),开始学习机器学习时做的第一件事就是寻找一个函数,RL也不例外。在增强式学习中找的函数中是有一个参与者(Actor)还有一个环境(Environment),两者之间会进行互动,则环境会给参与者一个观测(Observation)的输入,得到这个输入,参与者则会输出一个行动反馈给环境,环境就会产生新的观察,从而如此反复。
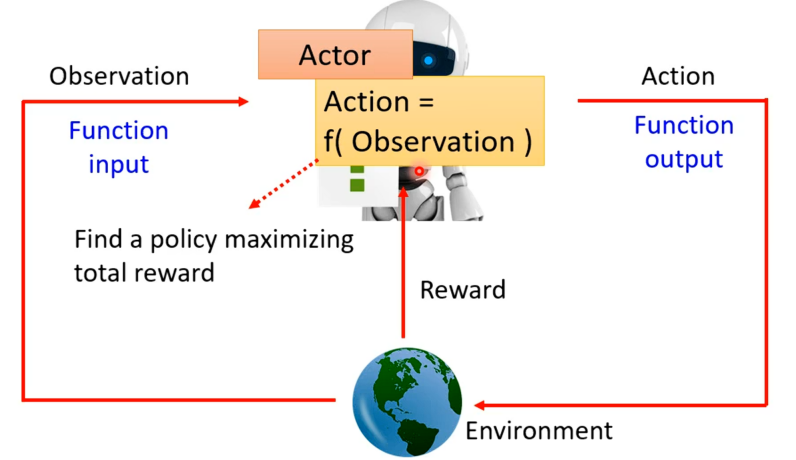
对于参与者,观测就是其输入而其做出的行动就是其输出,所以参与者本身就是我们要找的函数。在这个过程中环境会不断地给参与者一些奖励,让参与者知道其采取的行动的好坏。并且这个函数的目标是最大化从环境中获得奖励总和。
就以下面RL最早几篇论文让机器玩的"太空侵略者"游戏为例。
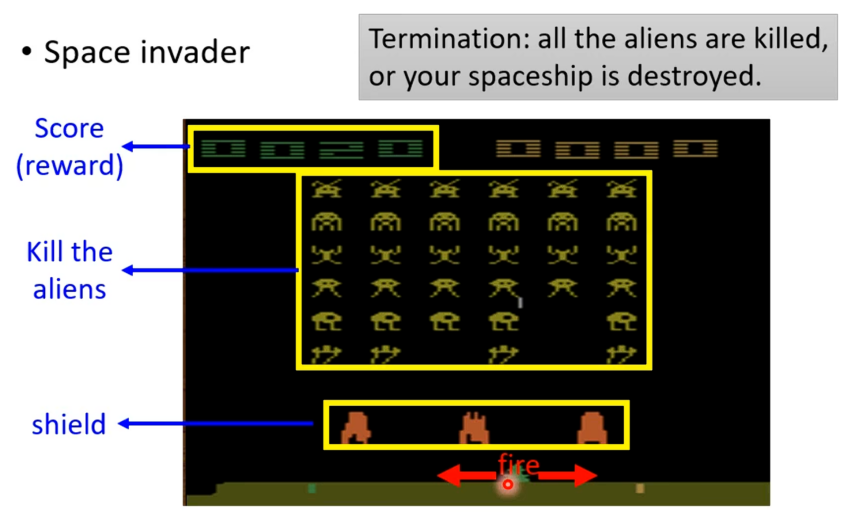
从下往上,依次是飞船、防护罩、外星人有以及得分。飞船是由机器操纵可以左右移动以及开火,防护罩是可以阻挡外星人的攻击但是可以被飞船攻击而消失,外星人就是攻击的目标,分数就是打掉一个外星人就会加对应的分数。游戏中打完所有外星人就会终止或者控制的飞船被打掉也会终止。
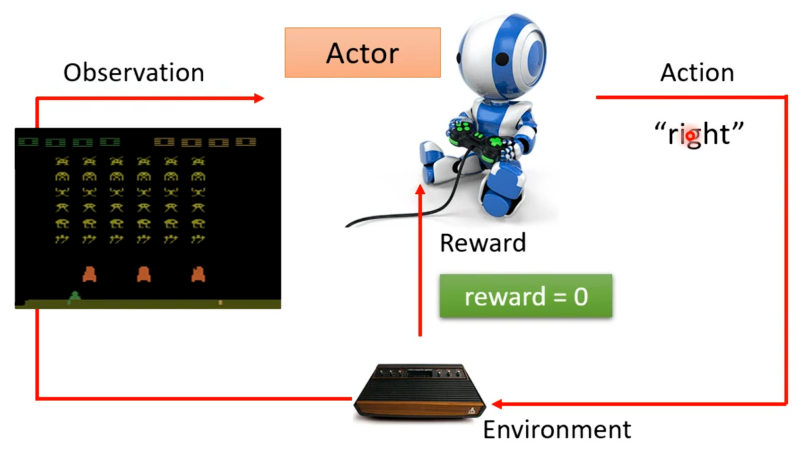
若现在要用参与者去玩这个游戏,其会站在人的角度去控制飞船打击外星人,其环境就是游戏中控制的外星人,观测就是当前的游戏画面,参与者输出就是飞船对应当前画面是左右移动还是开火。若其有移动便会得到分数也就是奖励。
采取一个行动之后,游戏画面就会变化,就代表有新的观测输入,参与者就要决定新的行动如开火,若正好打掉一个外星人就会得到分数。
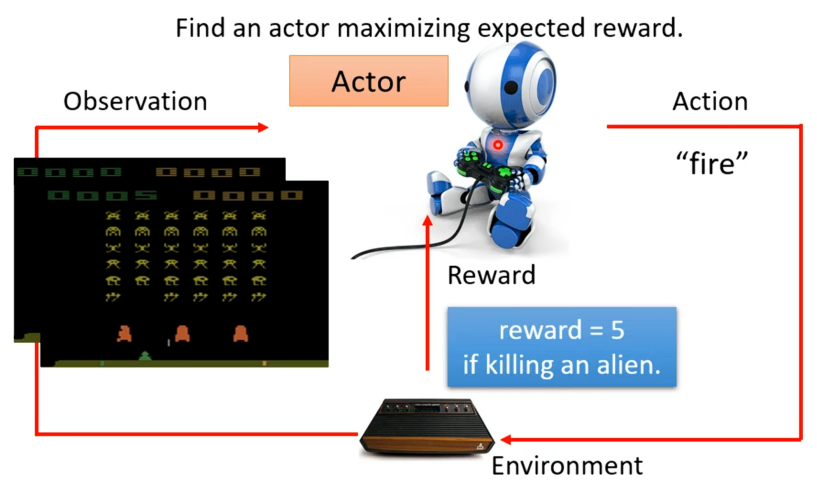
其中参与者想要学习的就是在玩游戏不断得到reward的过程中,要使得最后得到的总奖励最大。
若是拿RL来下围棋,其做的事情跟上面玩小游戏两者之间没有那么大的差别,只是规模以及问题的复杂度不太一样。例如AIphaGo其环境就是人类对手,其输入就是对于当前棋盘上黑白棋子位置的观测,然后得到输出也就是其下一步落子在哪一个位置。然后其行动就会作用到环境上,从而再得到新的观测,AIphaGo又会做出新的动作,如此反复知道得出胜者。
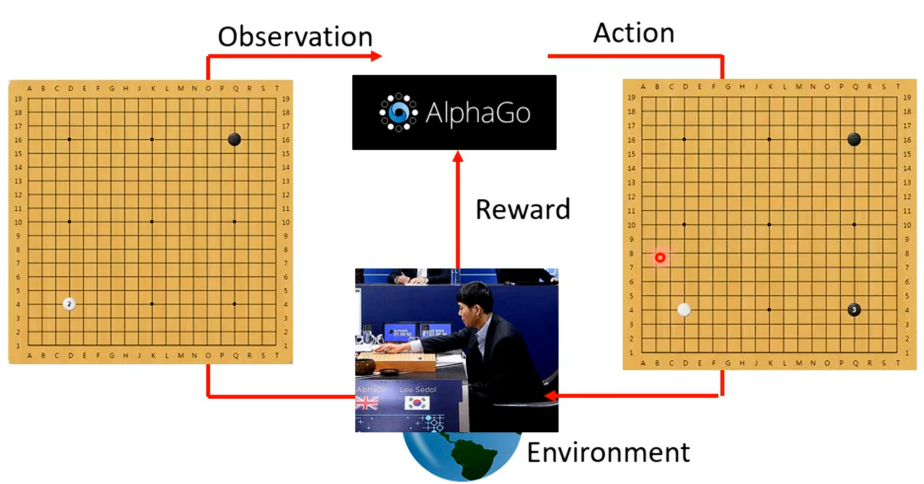
在这个过程中采取的任何行为都没有办法得到奖励,只有到最后赢了就可认为得一分,输了就扣一分。以上就是对于RL最常见得说明。
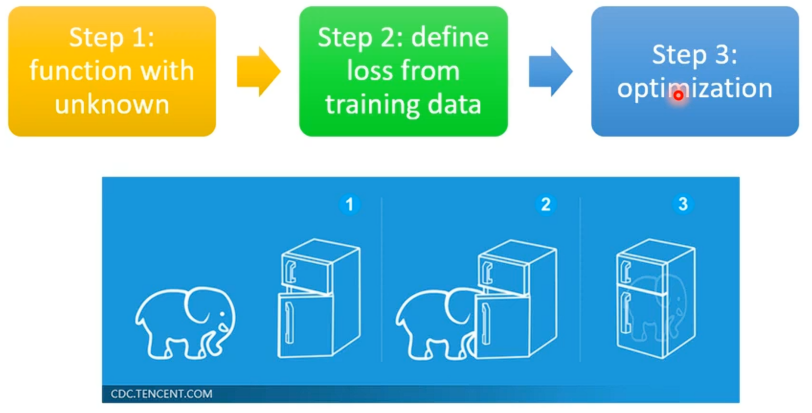
2.有未知数的函数
对于机器学习,其有三个步骤:找到有未知数得函数、定义一个Loss函数以及最后得优化。RL其实也是这样一样的三个步骤。
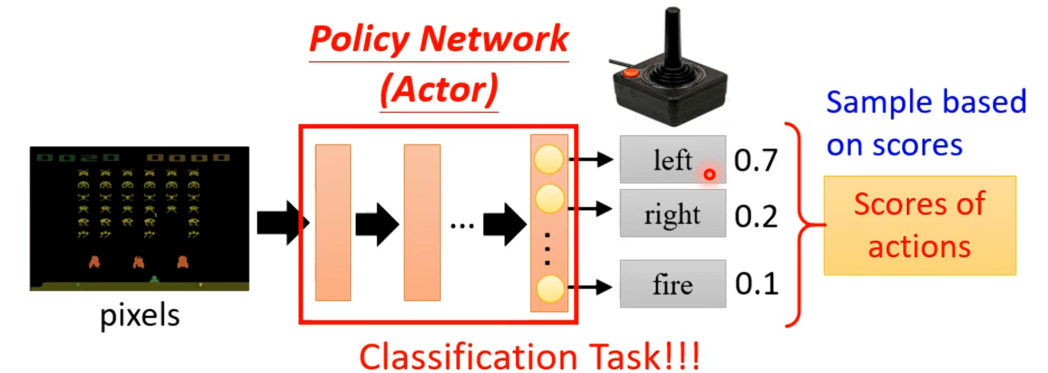
这个有未知数的函数就是前面的Actor,在RL中Actor就是一个网络,一般称之为策略网络。这个复杂的函数的输入就是游戏画面(也就是"太空侵略者"中的像素),其输出就是每一个可以采取的行为的分数,最后机器采取哪一个行动取决于每一个行动对应的分数,常见的的做法就是将分数当作对应行动的几率,然后按照这个几率随机选择。事实上这件事与分类是没有区别的。
3.定义Loss函数
对于增强式学习的Loss函数,我们再重新看下在"太空侵略者"例子中的机器与环境交互的过程,如下,现在有一个初始的游戏画面s1作为参与者的输入,其就输出一个右移的动作a1,便得到一个奖励r1,采取向右移动后变得到新的游戏画面s2,从而actor就会采取新的开火行动a2,若开火杀死一个外星人则得到奖励为5的r2,若此反复下去直到游戏结束。
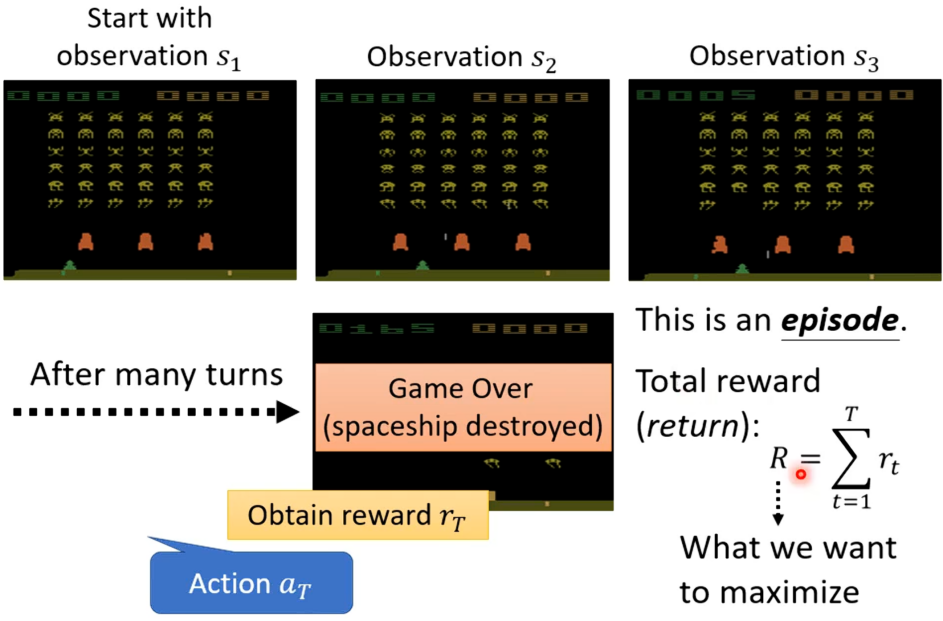
从游戏开始到结束的过程就称之为一个回合(Episode)。在整个游戏过程中,机器会采取很多行为,而每一个行为都可能得到反馈,把所有反馈集合起来就得到整场游戏的反馈R,这个R是我们想要最大化的东西,也就是想要训练的目标。为了符合求Loss的最小,则可以在R前加上负号,这样就得到Loss函数以及想要最小化的目标。
4.优化
将环境与参与者互动的过程用不一样的图像进行表示,Env表示环境,其输出一个观测,并作为参与者的输入,参与者则输出
,
又作为环境的输入,环境又得到
,如此反复直到满足条件为止。
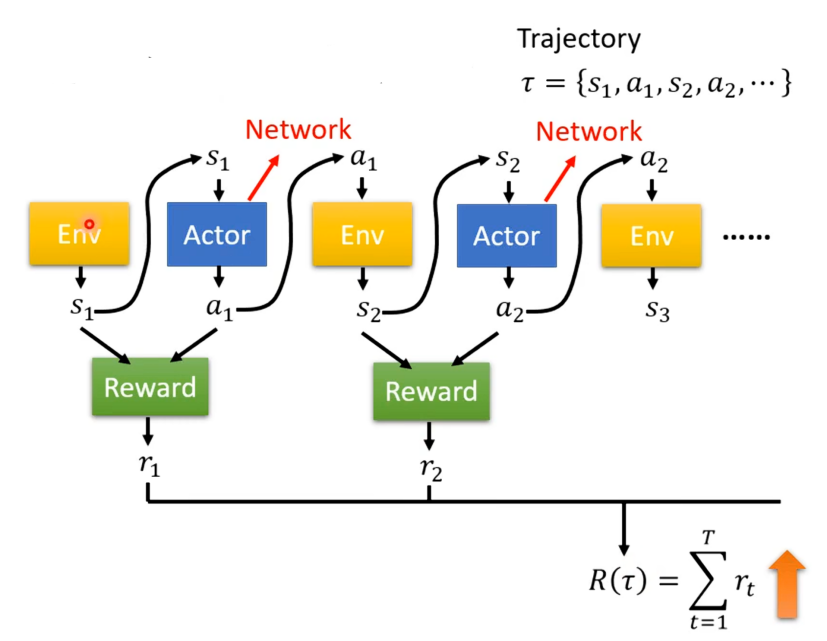
对于,
,
......这些序列称之为轨迹(Trajectory),这里用τ表示。根据该过程机器会得到回馈,这里将回馈也比作一个函数,得到的输出为
,将所有的r集合起来就得到R(τ),是我们要最大化的对象。
所以我们要优化的就是要去确定一个网络中的参数放在actor中其可以使得R越大越好。若对于环境,参与者,反馈当作一个网络则优化是简单的,但是RL并不是一般的优化问题。第一个就是actor的输出是有随机性的,从而使得环境,参与者,反馈当作得网络具有了随机性。另外一个问题就是环境与反馈并不是网络而是黑盒子,同时在游戏中环境也是具有随机性的。
三.策略梯度(Policy Gradient)
在了解策略梯度前,我们先了解如何控制actor的输出,及让actor看到某个特定的观测时采取某一个特定的行为。对于这我们可以将其想象为一个分类问题,就是s作为actor的输入,然后输出a,而a^是我们想要的答案,所以我们可以计算两者之间交叉熵(Cross Entropy)。
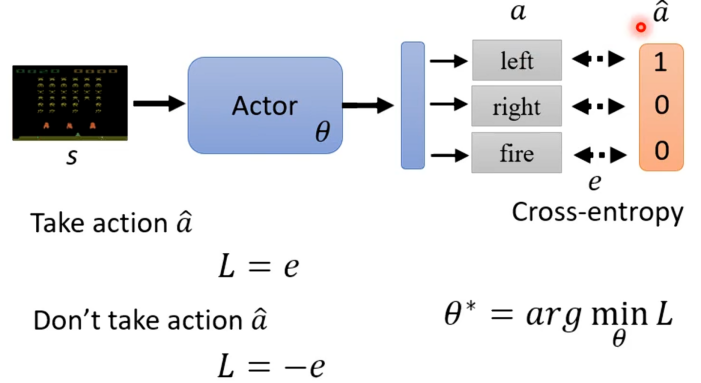
接着定义一个Loss等于交叉熵,然后去学习一个θ*,其可以使得Loss最小,也就是a与a^之间的距离越小越好。但是若是actor看到某个特定观测时不要采取某个行动,则就是将上面Loss的定义反过来就可以。
所以我们可以将上面综合起来如下L=-
。
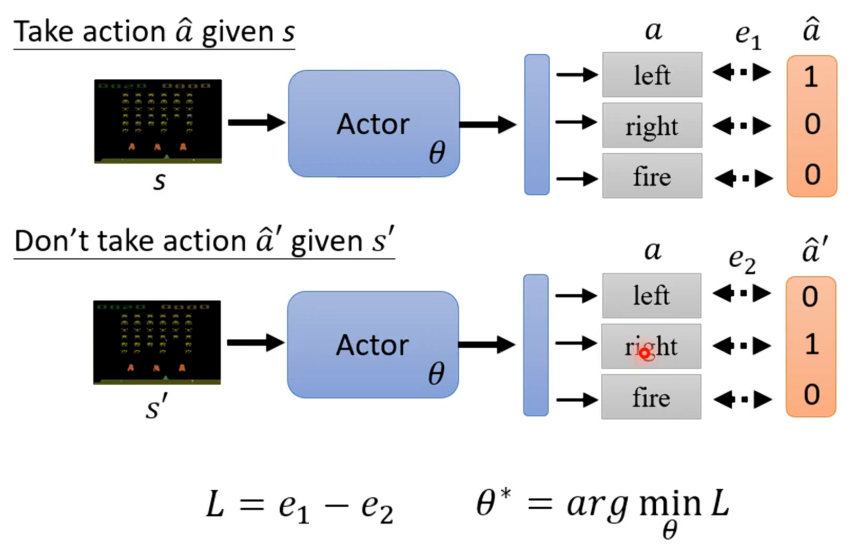
所以我们要训练一个actor就要去收集一些训练资料。

有了这些资料就可以去定义一个Loss函数,有了这个Loss函数就可以去训练actor。
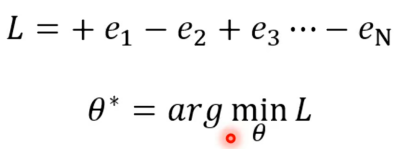
对此我们还可以更近一步,每一个行为并不是只有好还是不好或想要执行与不想要执行,而是有程度差别,有执行的非常好,有正常的,差一点的等等。

有了这些资料,一样可以定义Loss函数,只是变成了L=∑。有了Loss函数就可开始训练actor。
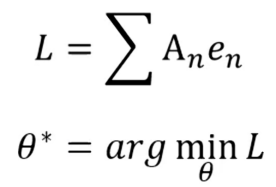
接下来的难点就是要怎么确定A呢?以及si与a^如何对应啥情况下执行或不执行呢?
总结
增强式学习代表了一种与监督学习和无监督学习截然不同的学习范式,其核心在于智能体通过与环境的持续交互来学习如何在未知环境中做出最佳决策。以"太空侵略者"游戏和AlphaGo为例,生动说明了增强学习的基本流程:智能体接收环境状态,输出动作,并根据环境反馈的奖励调整策略,最终实现累积奖励的最大化。增强学习中的关键挑战包括环境的随机性、奖励的稀疏性以及策略优化的复杂性。通过引入策略梯度等方法,可以在一定程度上解决这些挑战,但增强学习仍需要大量的交互数据和计算资源。总体而言,增强学习在复杂决策任务中展现出强大潜力,是推动AI在游戏、控制、自动驾驶等领域应用的重要技术之一。