本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。
在自然语言处理(NLP)和大模型中,Token 是文本处理的基本单位,可以看作是文本的"原子"。简单来说,Token 是将一段原始文本分解后得到的最小有意义的单元。大模型(如 GPT、BERT 等)通过接收和处理这些 Token 序列来理解文本的含义、生成新的文本或完成其他任务。
1. Token 的定义
Token 是文本被分割后的基本组成部分。在自然语言处理中,为了让模型能够理解和处理人类语言,需要将一段连续的文本(如句子或段落)分解成更小的单元,这些单元就是 Token。举个例子:
对于句子 "Hello world",可以分解为两个 Token:"Hello", "world"。 不同的分解方式会产生不同类型的 Token,具体取决于模型的设计和任务需求。
2. Token 的类型
根据分割粒度的不同,Token 通常可以分为以下几种类型:
- 单词级 Token 文本按单词进行分割,每个单词作为一个独立的 Token。 示例:"I love coding" → "I", "love", "coding" 优点:直观,适合理解完整的单词含义。 缺点:词汇量可能很大,无法处理未见过的新词。
- 子词级 Token 将单词进一步分解成更小的有意义的片段,通常用于解决单词级 Token 的局限性。 示例:"unhappiness" → "un", "happi", "ness" 优点:能处理新词或拼写变体,词汇量较小且灵活。 缺点:单个 Token 的含义可能不完整,需要上下文理解。 字符级 Token 文本按单个字符分割,每个字符作为一个 Token。 示例:"Hello" → "H", "e", "l", "l", "o" 优点:词汇量极小,能处理任何文本。 缺点:序列变长,模型需要更多计算资源来捕捉关系。 大模型通常会根据任务需求选择合适的 Token 类型。例如,BERT 使用子词级 Token(如 WordPiece),而一些轻量级模型可能使用字符级 Token。
3. Token 在大模型中的作用
大模型(如基于 Transformer 架构的模型)以 Token 序列为核心进行工作。
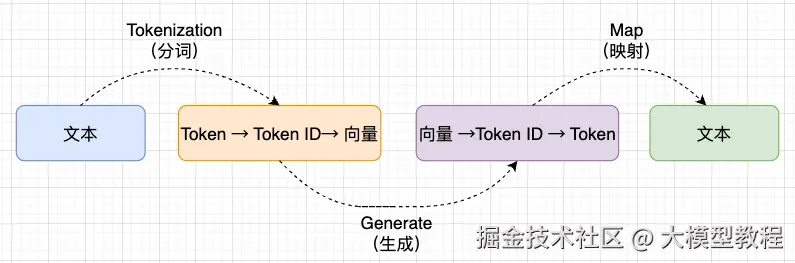
Token 在模型的输入、处理和输出阶段都扮演着关键角色:
- 输入阶段:原始文本被分解为 Token 序列后,再把Token 映射为唯一的
Token ID(通过词表),再通过模型的嵌入层(Embedding Layer) 将 Token ID 映射到一个高维向量(称为 embedding)。这些向量包含了 Token 的语义信息,是模型理解文本的基础。 示例:"Hello", "world" → vector1, vector2 - 处理阶段:模型通过多层结构(如注意力机制和前馈网络)对 Token 的 embedding 进行变换,分析 Token 之间的关系和上下文信息。例如,它可以理解 "I love coding" 中 "love" 和 "coding" 的关联。
- 输出阶段:模型对处理后的 embedding 解码,输出下一个 Token 的概率分布向量,再通过词表将概率最高的向量对应的 Token ID 映射为具体 Token:文本生成时逐 Token 拼接成完整内容,分类任务则聚合结果输出对应标签,是模型将语义转化为结果的关键步骤。
4. Tokenization 过程
将原始文本转换为 Token 序列的过程称为 Tokenization,通常包括以下步骤:
- 规范化 对文本进行清洗和标准化,例如去除多余空格、统一大小写等。 示例:"Hello, World!" → "hello world"
- 分割 根据选定的 Token 类型,将文本分割成 Token。 示例:"hello world" → "hello", "world"(单词级)
- 编码 将 Token 转换为模型可以处理的数值表示,即向量化(embedding)。具体来说,模型将每个 Token 映射到一个高维稠密向量空间。这些向量能够捕捉到词的语义信息和上下文关系。在分词之后通常使用嵌入层(Embedding Layer)来实现这一点。嵌入层会将每个 token 映射到一个高维空间,例如 12288 维 (gpt3)。 假如输入的是" I am a student "这句话,那么 embeding 层会生成一个 4 x 12288 维的矩阵: "I" → x₁, x₂, ..., x₁₂₂₈₈ "am" → y₁, y₂, ..., y₁₂₂₈₈ "a" → z₁, z₂, ..., z₁₂₂₈₈ "student" → w₁, w₂, ..., w₁₂₂₈₈ 作为 encoder 层的输入在 Transformer 架构中,这一步通常是通过一个嵌入层(Embedding Layer)来完成的。嵌入层负责将每个 Token 转换成对应的向量表示。
经过这些步骤,文本就变成了模型能够理解和计算的格式。
不同的大模型可能会选择不同的 tokenization 策略,以适应其架构和应用需求。比如目前主流大模型所使用的 token 类型如下:
- ChatGPT(OpenAI) Token 类型:Byte Pair Encoding(BPE) 说明:ChatGPT 基于 GPT 系列模型,采用 BPE tokenization。BPE 通过合并高频出现的字符对来构建词汇表,能有效处理未见词(OOV),并在词汇量与计算效率之间取得平衡。
- QWen(阿里巴巴) Token 类型:SentencePiece 说明:QWen 使用 SentencePiece,这是一种无监督的 tokenization 方法,支持 BPE 和 unigram language model 两种模式。它特别适合多语言环境,能够灵活适应不同语言的特性。
- DeepSeek Token 类型:WordPiece 说明:DeepSeek 采用 WordPiece tokenization,这是 Google 开发的一种算法,最初用于 BERT 模型。通过最大化语言模型的似然选择子词单元,WordPiece 能有效捕捉词缀和词根等语言特征。
- LLama(Meta) Token 类型:Byte Pair Encoding(BPE) 说明:LLama 使用 BPE tokenization,与 ChatGPT 类似。BPE 在处理大规模、多样化的文本数据时表现出色,确保模型的高效性和泛化能力。
5. Token 数量的影响
Token 序列的长度对大模型的性能有重要影响:
- 序列过长:包含更多信息,但计算复杂度增加,模型可能难以处理(尤其是 Transformer 模型,计算量与序列长度平方相关)。
- 序列过短:信息不足,可能影响模型对上下文的理解。 因此,大模型通常会设置一个最大 Token 长度(如 512 或 2048),并根据任务需求进行优化。
总结
Token 是大模型处理文本的核心概念,可以理解为文本的最小构建块。它通过将复杂文本分解为单词、子词或字符等单元,让模型能够一步步分析和生成语言。Token 的类型和数量直接影响模型的性能和效果,而 Tokenization 则是连接原始文本与模型计算的关键步骤。希望这个解释能让你对 Token 有更清晰的认识!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。