在高可用、高性能的数据库架构中,MySQL 主从复制(Replication) 是最核心的技术之一。无论是读写分离、数据备份、容灾恢复,还是构建分布式数据库体系,都离不开主从复制的支撑。但你真的用对了吗?还在手写 MASTER_LOG_FILE 和 MASTER_LOG_POS?是否因主库误删表而彻夜难眠?是否在跨机房部署时被级联延迟折磨?
本文将带你系统性梳理 MySQL 主从复制的核心机制与高级特性,涵盖:
-
✅ 复制原理
-
✅ 五种复制模式(异步/半同步/增强半同步/组复制等)
-
✅ 级联复制、延迟复制、多源复制
-
✅ 点位复制 vs GTID 复制
-
✅ 生产常见问题与避坑指南
- 主从复制基本原理
MySQL主从复制集群的架构如下
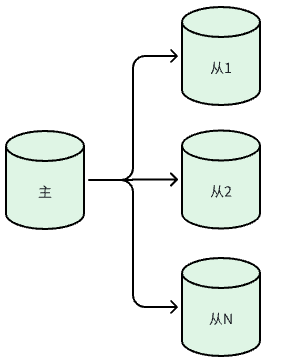
其数据库同步的基本原理如图所示
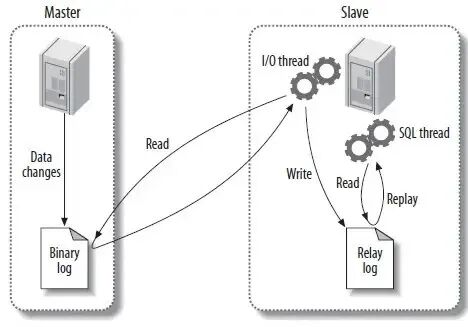
如上图所示,主库及从库中涉及的组件主要做如下动作:
1.1 主库的记录与发送:Binlog 与 Dump 线程
-
二进制日志 (Binlog): 这是复制的基石。主库上任何修改数据的SQL语句(如INSERT, UPDATE, DELETE)都会按顺序被记录到Binlog中。Binlog有三种格式,默认是基于语句的复制 (SBR),记录SQL本身,日志量小但某些函数可能导致主从不一致;基于行的复制 (RBR) 记录每行数据的变化,更安全但日志量大;混合模式复制 (MBR) 由MySQL自动选择最佳格式。
-
Log Dump 线程: 当从库连接后,主库会为每个从库创建一个专用的Log Dump线程。这个线程负责"盯住"Binlog,一旦有新的内容,就主动推送给从库的I/O线程。
1.2 从库的接收与重放:I/O 线程和 SQL 线程
-
I/O 线程: 它负责与主库的Dump线程通信,接收Binlog内容,并将其顺序写入到从库本地的中继日志 (Relay Log) 中。这种设计将数据获取和数据应用解耦,即使SQL线程执行慢,I/O线程也能先快速拉取并保存最新日志。
-
SQL 线程: 这是真正干活儿的线程。它会不间断地读取Relay Log中的指令,解析成SQL语句并在从库上顺序执行,从而保持数据同步
- 主从复制模式
2.1 按照从库确认策略分
根据主库事务提交后等待从库确认的策略可分为异步复制、半同步(增强半同步)复制、全复制,后面新增了组复制(MGR)。
2.1.1 异步复制(Asynchronous Replication)
异步复制是最常见也是默认的复制模式。主库不需要等待任何从库确认就完成事务提交,这使得性能最高,但牺牲了一定程度的数据一致性,当主库宕机后从库可能丢失未同步的数据。
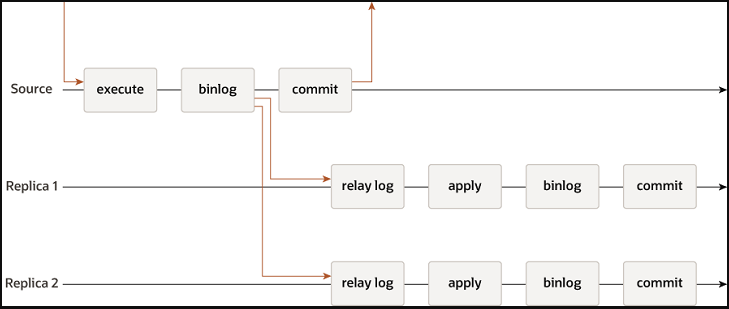
2.1.2 半同步(增强半同步)复制(Semi-Synchronous Replication)
-
半同步复制要求至少一个从库确认已接收到并持久化了二进制日志后,主库才认为事务提交成功。这种方式提高了数据的安全性,但也可能导致一定程度的延迟。
-
增强版的半同步复制确保在事务被提交前,至少有一个从库已经确认接收到了事务的日志。这种模式提供了更高的数据一致性保证。
半同步或增强半同步需要安装插件,模式根据参数rpl_semi_sync_master_wait_point = AFTER_SYNC、AFTER_COMMIT控制
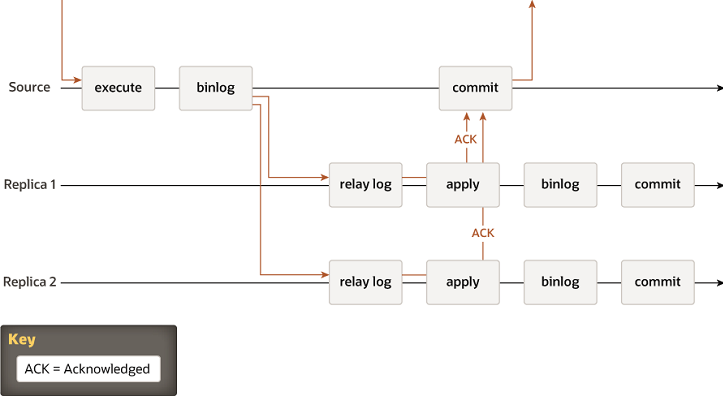
2.1.3 全同步复制
全同步指的是所有节点必须全部确认才能提交(类似 Galera Cluster)。这个模式性能极低,一般不用于生产。MySQL原生不支持全同步模式,所以后续出现了组复制。
2.1.4 组复制(MGR)
MySQL 5.7引入的组复制是一种基于Paxos协议的多主复制解决方案,支持单主或多主模式,自动处理故障转移和冲突检测,提供更强的一致性和高可用性
2.2 按照层级及延迟情况分类
按照层级、延迟情况,又可以分为级联复制、延迟复制及多源复制
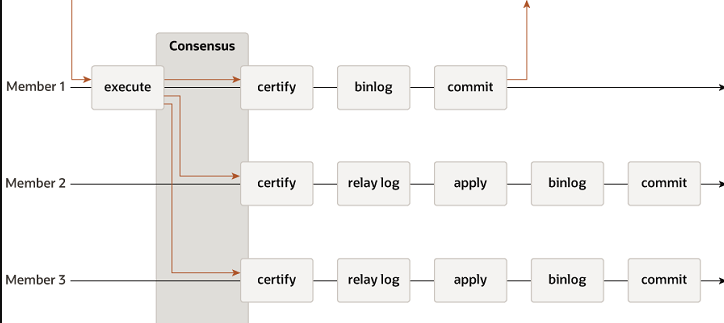
2.2.1 级联复制
主库同步到从库(次级主库),这些从库再同步给其他从库,形成树状结构。
在配置时,关键在于中间层的从库(次级主库)必须开启 log_slave_updates参数,这样它才能将自己从主库接收到的更新记录到自己的二进制日志中,再传递给下一级的从库。
缺点是复制层次增加会累积延迟,对延迟敏感的业务需谨慎选择层级。
级联复制适用场景如下:
-
跨机房/跨地域部署:主库在中心机房,中继从库在区域机房,再分发给本地应用
-
减轻主库压力:避免大量从库直连主库,导致主库 I/O 或网络带宽瓶颈
-
分层读扩展:核心业务读中继从库,边缘业务读叶子从库
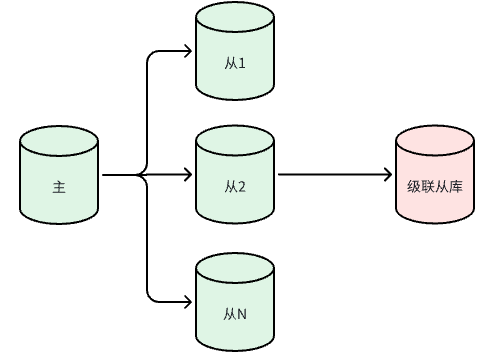
2.2.2 延迟复制
从库故意延迟一段时间再应用主库的二进制日志,提供一个人为的数据恢复窗口,防止误操作。
延迟复制就像一个"时间胶囊"。当主库发生误操作(如误删重要数据),在延迟时间内,从库上的数据还未被更新。这时可以立即停止从库的复制,将其作为正确数据的来源,快速恢复主库数据。其本质是SQL线程在执行中继日志前会等待设定的延迟时间。
延迟复制适用场景如下:
-
防误操作兜底:如 DBA 误删表(DROP TABLE),可在延迟窗口内暂停从库,跳过该语句,快速恢复数据
-
审计回溯:保留历史某一时刻的数据快照,用于合规或分析
-
灰度验证:先在延迟从库上观察变更影响,再决定是否全量发布
关于延迟复制有经典的案例,咱们下次再详细说明。
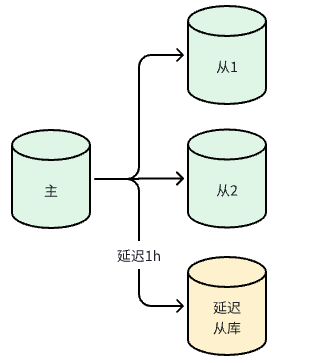
2.2.3 多源复制
一台从库可以同时从多个主库(数据源)进行复制, 将多个实例的数据合并到一个实例,便于统计分析或集中备份。
多源复制 从MySQL 5.7.6版本开始支持,一台从库最多可连接64个主库。配置时,每个主库的连接使用独立的通道(Channel),例如 FOR CHANNEL 'channel_name'。这要求各主库同步到从库的数据库名最好不同,以避免冲突。例如:
sql
-- 配置主库 ACHANGE MASTER TO MASTER_HOST='master_a', MASTER_USER='repl', MASTER_PASSWORD='xxx', MASTER_AUTO_POSITION=1FOR CHANNEL 'master_a';-- 配置主库 BCHANGE MASTER TO MASTER_HOST='master_b', MASTER_USER='repl', MASTER_PASSWORD='xxx', MASTER_AUTO_POSITION=1FOR CHANNEL 'master_b';-- 启动两个通道START SLAVE FOR CHANNEL 'master_a';START SLAVE FOR CHANNEL 'master_b';多源复制适用场景如下:
-
数据聚合:将多个业务系统的数据汇聚到一个分析库
-
分库合并:原有多套独立 MySQL 实例,需统一查询入口
-
灾备整合:多个主库的备份集中到一个从库进行管理
2.3 点位复制>ID复制
在MySQL 5.6引入的GTID(全局事务标识符) 为每个事务分配唯一ID。这在主从切换时非常方便,无需再依赖复杂的Binlog文件名和位置点,复制会自动根据GTID找点同步,简化了运维。
点位复制 vs GTID 复制 对比表如下
| 特性 | 点位复制(Position) | GTID 复制 |
|---|---|---|
| 启用版本 | MySQL 所有版本 | ≥ 5.6(推荐 ≥ 5.7) |
| 配置方式 | 手动指定 file + pos | MASTER_AUTO_POSITION=1 |
| 故障切换 | 需人工计算位置 | 自动同步缺失事务 |
| 数据一致性 | 容易出错 | 强一致性保障 |
| 运维复杂度 | 高 | 低 |
| 是否支持并行复制 | 支持(但需额外配置) | 原生友好支持 |
| 是否支持组复制 | ❌ | ✅(必需) |
| 是否允许非事务 DDL | ✅ | ❌受 enforce_gtid_consistency 限制 |
关于点位复制和GTID复制,有历史文章可以参考
- 常见问题与排查技巧
3.1 复制中断(Error 1062 / 1032)
1062:主键冲突(从库已有数据)
1032:找不到要更新/删除的行
原因:主从数据不一致、跳过事务、手动改从库数据。
解决:
-
跳过错误(临时):SET GLOBAL sql_slave_skip_counter = 1;
-
或者临时改为幂等复制方式(参考历史文章MySQL数据库修改小众参数解决大众问题)
- 当复制正常后再使用 pt-table-sync 工具修复数据(参考历史文章MySQL数据库主从数据对比及修复)。
根本解决:
-
确保只写主库,避免直接操作从库
-
也需要保证参数合理(例如之前讨论过的双1参数问题 "我这显示转账成功了你没收到钱?"--MySQL Redo Log和binlog两阶段提交到底在防什么?)
3.2 主从延迟过大
原因:
-
从库硬件弱(CPU/IO 不足)
-
大事务(如 ALTER TABLE)
-
网络带宽不足
-
单线程 SQL Thread(MySQL 5.6 前)
优化:
- 升级到 MySQL 5.7+,启用 并行复制(parallel replication)
ini
slave_parallel_workers = 8;slave_parallel_type = LOGICAL_CLOCK;-
拆分大事务
-
监控 Seconds_Behind_Master
3.3 GTID 模式下无法切换主库
-
确保新主包含所有 GTID(SELECT @@global.gtid_executed;)
-
使用 MHA mysqlfailover 或 Orchestrator 自动化工具
3.4 主库 binlog 被自动清理
从库还没拉取完,主库就 purge 了 binlog。
解决:设置合理的 expire_logs_days,或使用 PURGE BINARY LOGS TO 'xxx'; 手动清理。