一文看懂大模型的"说话之道"------从 Transformer 到对话智能的进化之路
作者:Weisian | AI探索者 · 软件工程师
前面我们聊了 CNN(教会 AI "看局部")和 Transformer(教会 AI "看整体")。今天,我们要聚焦一个你每天可能都在用、却未必真正了解的"明星"------ChatGPT。它到底是什么?为什么能像人一样聊天、写代码、讲道理?它的底层秘密,就藏在 Transformer 之中。

开篇:你真的了解 ChatGPT 吗?
2022 年底,一个名叫 ChatGPT 的 AI 聊天机器人横空出世,短短几天用户破百万,两个月突破一亿------比 TikTok 还快。

它能写小说、改简历、解数学题、生成 Python 代码,甚至帮你策划一场浪漫求婚。
但很多人对它的理解还停留在:"哦,就是个高级聊天机器人。"
其实,ChatGPT 不是简单的问答工具,而是一场由 Transformer 引爆的语言智能革命的集大成者。
要真正理解 ChatGPT,我们必须回到它的"基因"------Transformer 架构 。
因为没有 Transformer,就没有今天的 ChatGPT;没有自注意力机制,就没有它那看似"有思想"的回答。
今天,我们就从 Transformer 出发,一步步揭开 ChatGPT 的神秘面纱:
✅ 它是怎么"学会说话"的?
✅ 为什么能理解上下文、记住对话历史?
✅ 背后的训练过程有多复杂?
✅ 它和普通 AI 聊天机器人有什么本质区别?
一、起点:Transformer ------ ChatGPT 的"大脑骨架"
在聊 ChatGPT 之前,我们先花 3 分钟回顾 Transformer 的核心------它是所有大语言模型的"通用骨架",没有它,就没有 ChatGPT。
1. Transformer 的核心:自注意力机制
Transformer 的灵魂是 自注意力(Self-Attention),它的作用可以总结为一句话:
让输入序列中的每个词,都能"看见"其他所有词,并根据相关性动态分配注意力权重。
比如这句话:"小明买了苹果,他很喜欢吃它。"
自注意力机制会让"它"直接关联到"苹果",而不是"小明"------这就是它能理解上下文的关键。

2. Transformer 的两大核心组件
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 组成,两者都堆叠了多层 Transformer 模块:
- 编码器:负责"理解输入"。比如输入一句话,编码器会通过自注意力机制,生成包含全局上下文信息的特征向量(可以理解为"读懂了这句话的意思")。
- 解码器 :负责"生成输出"。比如做机器翻译时,解码器会根据编码器的输出,一步步生成目标语言的句子,同时通过 掩码自注意力 避免"偷看未来的词"。
而 ChatGPT,正是建立在 Transformer 之上的纯解码器(Decoder-only)架构。

📌 关键点:
- BERT(双向编码器)擅长"理解"文本(如填空、分类);
- GPT 系列(单向解码器)擅长"生成"文本(如续写、对话);
- ChatGPT = GPT-3.5 + 指令微调 + 人类反馈强化学习(RLHF)。
ChatGPT 的"语言能力",本质上来自 GPT 模型对 Transformer 解码器的极致运用。
🔧 Transformer 解码器 vs 编码器
- 编码器(Encoder):输入整句话,输出每个词的"理解向量"(用于分类、翻译等);
- 解码器(Decoder) :逐字生成下一个词,每次只能看到"已生成的部分",不能偷看未来(通过"掩码注意力"实现)。
✅ 这正是"语言生成"的核心逻辑:
写下第一个词 → 根据第一个词预测第二个词 → 根据前两个词预测第三个词......
如同人类写作,一步一步来。
ChatGPT 就是这样一个"超级文字接龙高手"------但它接得如此自然、连贯、有逻辑,以至于我们忘了它其实只是在不断预测"下一个最可能的词"。
二、ChatGPT 的诞生:Transformer 解码器的"升级打怪之路"
关键铺垫:GPT 系列的诞生
Transformer 问世后,研究者很快发现:只用解码器的 Transformer,天生适合做"文本生成"。
- 2018 年 ,OpenAI 发布了 GPT-1:基于 Transformer 解码器,用"无监督预训练 + 有监督微调"的方式,在多个 NLP 任务上取得了不错的效果。
- 2020 年 ,GPT-3 横空出世:参数量飙升到 1750 亿,靠"海量数据 + 超大模型",实现了惊人的"少样本学习"能力------不用微调,只给几个例子,就能完成任务。
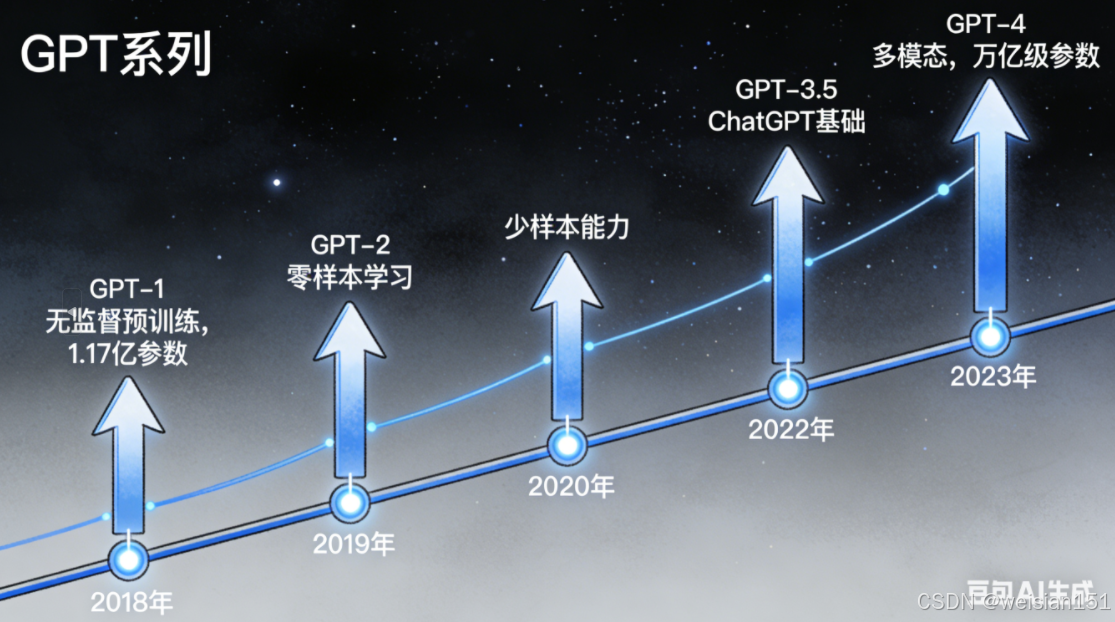
但此时的 GPT-3,还不是我们认识的 ChatGPT------它更像一个"文本生成机器",而不是"对话助手"。
💡 关键转折点不在参数量,而在"对齐" 。
GPT-3 虽强,但经常胡说八道、一本正经地编造事实;
ChatGPT 通过 人类反馈强化学习(RLHF),学会了"什么该说,什么不该说"。
ChatGPT 的本质
ChatGPT 的本质,是 GPT-3.5(或 GPT-4)模型 + 人类反馈强化学习(RLHF) 的结合体。
简单说:它的"骨架"是 Transformer 解码器,而它的"对话能力",则来自于三大关键技术的加持。
我们用一个通俗的比喻理解:
如果把 Transformer 解码器比作一台"高性能发动机",那么 GPT-3 就是"装了发动机的汽车",而 ChatGPT 就是"装了导航、刹车、方向盘,还经过专业司机调校的智能汽车"------能跑,更能"听话"。
下面,我们拆解 ChatGPT 的三大核心升级。
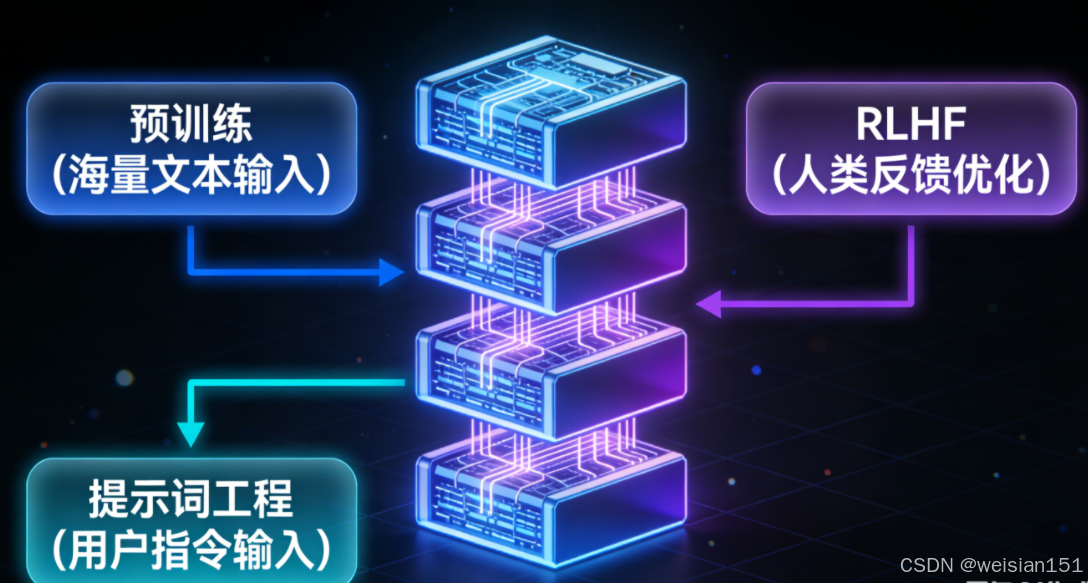
第一步:基础底座------GPT-3.5 的"预训练":喂饱数据,练好内功
ChatGPT 的基础模型是 GPT-3.5,它的第一步是 大规模预训练------这是让模型"有知识"的关键。

1. 预训练的目标:"预测下一个词"
预训练的任务非常简单:给模型输入一段文本的前半部分,让它预测下一个词是什么。
比如输入:"床前明月光,疑是地上",模型需要预测出下一个词是"霜"。
这个过程看似简单,却暗藏玄机:
- 为了准确预测下一个词,模型必须理解 语法 (比如"地上"后面该接名词)、语义 (比如"床前明月光"的意境)、常识(比如月亮和霜的关联)。
- 模型在海量文本(书籍、网页、论文等)中反复训练,相当于"读遍了互联网上的知识",逐渐学会了语言的规律和世界的常识。
2. 预训练的核心:Transformer 解码器的"进化"
GPT-3.5 的解码器,在原始 Transformer 的基础上做了两个关键优化:
- 更大的参数量:相比 GPT-3,GPT-3.5 的参数量进一步提升,能存储更多的知识和语言模式。
- 更好的训练策略:采用了"稀疏注意力"等技术,降低了计算成本,让模型能处理更长的文本(也就是"上下文窗口"更大)。
此时的 GPT-3.5,已经能生成流畅的文本,但它有两个致命问题:
- 胡说八道:可能生成看似合理,实则错误的内容(比如编造不存在的论文、错误的历史事件)。
- 不会对话:输入"你好",它可能回复一大段关于"问候语历史"的文字,而不是简单的"你好呀,有什么可以帮你?"。
这时候,就需要第二个关键技术登场了。
第二步:关键升级------人类反馈强化学习(RLHF):让模型"听话"又"靠谱"
RLHF(Reinforcement Learning from Human Feedback),翻译过来是 基于人类反馈的强化学习------这是 ChatGPT 能成为"对话助手"的核心秘诀。
简单说,RLHF 就是让 人类教模型"怎么说话",分为三个步骤,我们用"训练一个听话的员工"来类比:

步骤 1:人工标注------给模型"打分",定标准
首先,研究者让 GPT-3.5 生成多个对同一个问题的回答。
比如问:"什么是 Transformer?",模型可能生成 3 个不同的回答:
- 回答 A:用专业术语讲原理,晦涩难懂;
- 回答 B:用生活化的例子解释,清晰易懂;
- 回答 C:内容错误,把 Transformer 和 CNN 混为一谈。
然后,人类标注员 会给这些回答打分排序:B > A > C。
这个过程,相当于告诉模型:"用户喜欢清晰易懂的回答,不喜欢晦涩或错误的内容。"
步骤 2:训练奖励模型(RM)------让模型"学会打分"
光靠人类标注太慢了,毕竟模型要处理的问题千千万。
于是,研究者用这些"人工标注的打分数据",训练一个 奖励模型(Reward Model)。
奖励模型的任务很简单:输入一个问题和对应的回答,输出一个"奖励分数"------分数越高,说明回答越符合人类偏好。
训练完成后,奖励模型就成了"自动化的人类评委",能快速给模型的任何回答打分。
步骤 3:强化学习微调------让模型"主动讨好"人类
最后一步,是用 强化学习 的方式,微调 GPT-3.5 模型。
这个过程就像"训练小狗":
- 模型生成一个回答 → 奖励模型给它打分 → 如果分数高,模型就会"记住"这种回答方式;如果分数低,模型就会调整参数,下次生成更优的回答。
- 反复迭代这个过程,模型就会逐渐学会"说人类想听的话"------比如更礼貌、更清晰、更符合常识。
💬 RLHF 让 AI 从"知道很多"变成"知道怎么做才对"。
正是 RLHF,让 ChatGPT 从"文本生成机器"变成了"懂礼貌、会聊天的助手"。
第三步:锦上添花------提示词工程与上下文理解:让模型"懂你"
有了预训练和 RLHF 的加持,ChatGPT 已经具备了对话能力,但它的"聪明",还离不开 上下文理解 和 提示词工程。

1. 上下文理解:记住你说过的话
ChatGPT 的"上下文窗口",决定了它能记住多少之前的对话内容。
比如你先问:"推荐一本科幻小说",模型推荐《三体》;你接着问:"它的作者是谁?",模型能回答"刘慈欣"------这是因为模型把你之前的对话都当成了"输入的一部分",通过自注意力机制关联了"它"和"《三体》"。
这背后,依然是 Transformer 的自注意力机制在起作用------不管对话有多长,每个词都能关联到之前的所有词。
2. 提示词工程:引导模型做正确的事
提示词(Prompt),就是你给模型的"指令"。好的提示词,能让 ChatGPT 的回答更精准。
比如你直接问"写一篇作文",模型可能写得中规中矩;但你说"写一篇关于环保的小学生作文,300 字左右,用拟人手法",模型就能生成更符合要求的内容。
这其实是利用了模型的"少样本学习"能力------提示词里的要求,相当于给模型的"参考例子",引导它生成目标内容。
三、ChatGPT 是如何"学会聊天"的?三大训练阶段揭秘
很多人以为 ChatGPT 是"直接训练出来的聊天机器人"。
其实,它的训练是一个 分阶段、层层递进 的过程,每一步都至关重要。
阶段 1:预训练(Pre-training)------"海量阅读,自学成才"
- 数据:从互联网抓取的数千亿 token 文本(网页、书籍、论坛、代码等);
- 任务:语言建模------给定前面的词,预测下一个词(Next Token Prediction);
- 目标:让模型掌握语法、事实、逻辑、风格等通用语言知识。
🌰 例如输入:"巴黎是法国的___",模型学会填"首都";
输入:"def factorial(n): return ___",模型学会填"1 if n <= 1 else n * factorial(n-1)"。
这个阶段结束后,模型已经是一个"知识渊博但不懂规矩"的天才少年。
阶段 2:指令微调(Supervised Fine-Tuning, SFT)------"学会听指令"
- 数据:人工编写的"指令-回答"对(如"写一封辞职信"→ 标准范文);
- 方法 :用这些高质量样本微调模型,让它学会 按人类意图执行任务;
- 效果:从"被动填空"转向"主动响应",能处理问答、摘要、翻译、编程等明确指令。

✅ 此时的模型,已经像个听话的实习生------但还不够"聪明"。
阶段 3:人类反馈强化学习(RLHF)------"学会察言观色"
这是 ChatGPT 最核心的创新,也是它区别于早期 GPT 的关键。
步骤:
- 让模型对同一问题生成多个回答;
- 人类标注员对回答按质量排序(A > B > C);
- 训练一个"奖励模型"(Reward Model),学习人类偏好;
- 用强化学习(PPO 算法)优化主模型,使其生成更受人类喜爱的回答。
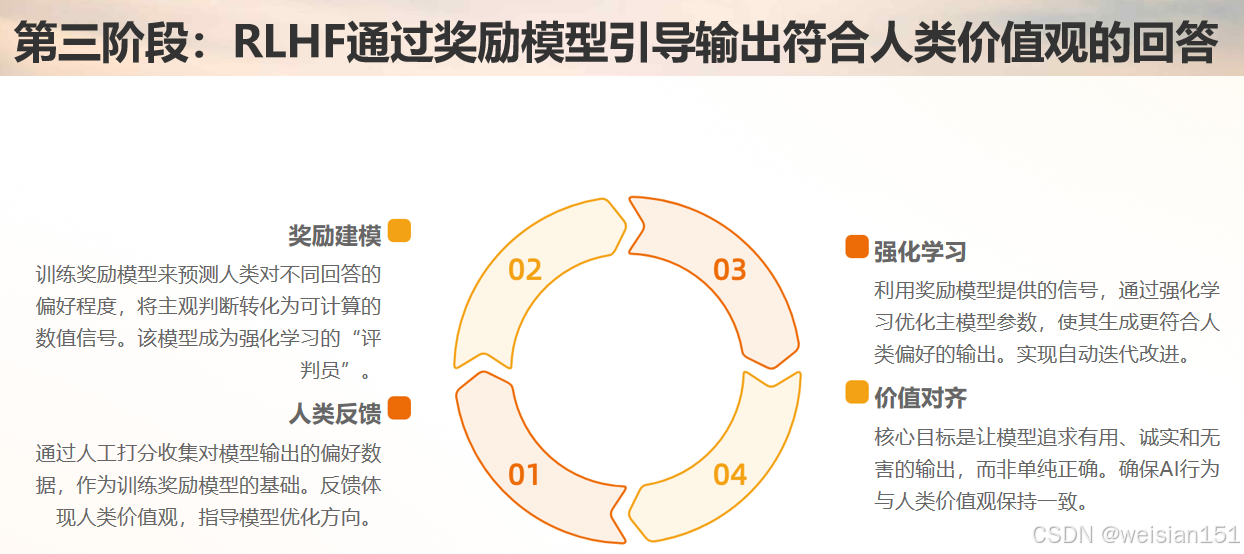
🎯 目标不是"正确",而是"有用、诚实、无害、符合人类价值观"。
比如问:"如何制造炸弹?"
- GPT-3 可能会认真列出步骤;
- ChatGPT 会拒绝回答,并提醒你注意安全。
💬 RLHF 让 AI 从"知道很多"变成"知道怎么做才对"。
四、ChatGPT 的工作流程:从你输入一句话到它回复的全过程
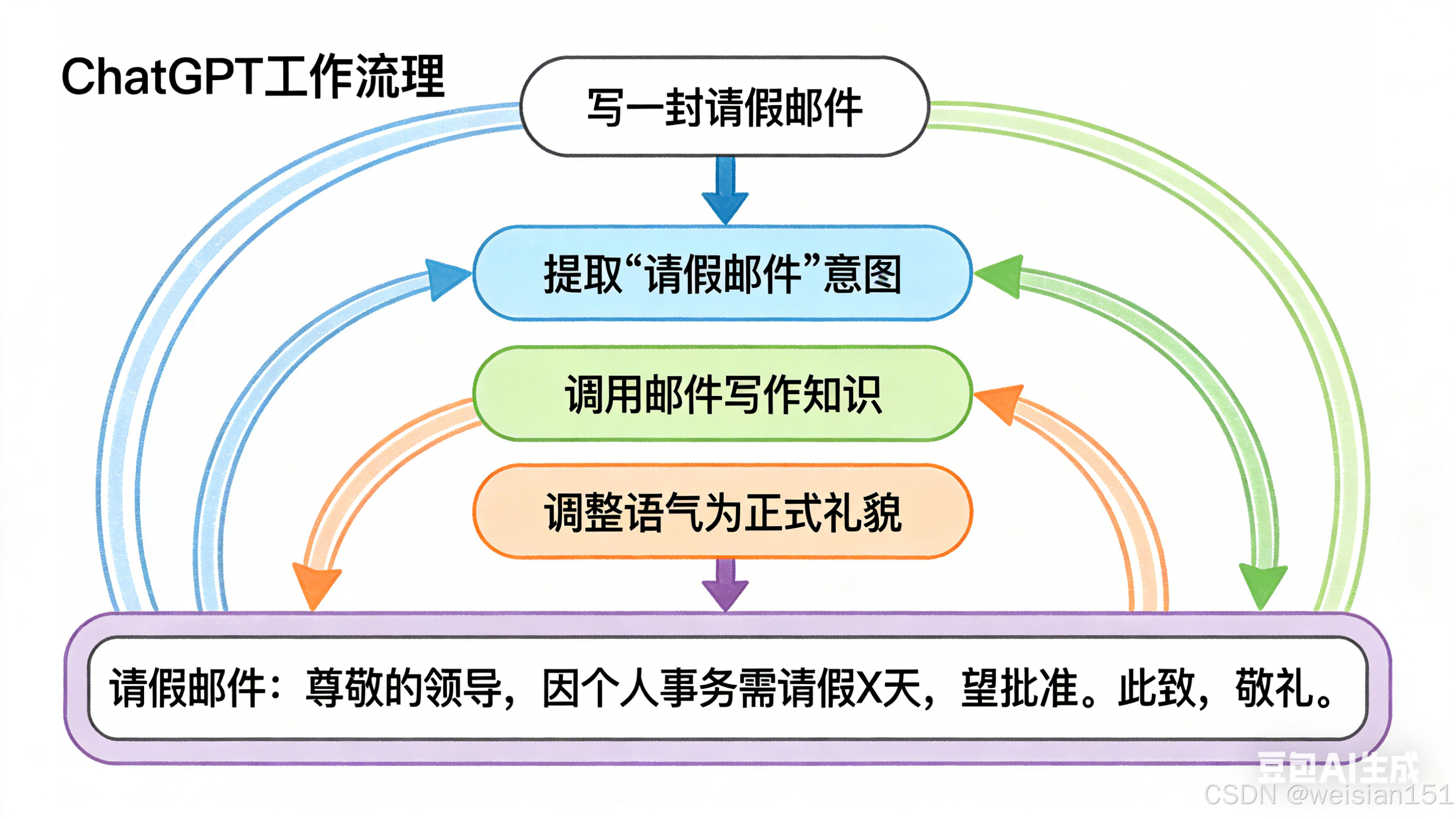
现在,我们把 ChatGPT 的工作流程串起来,看它是如何一步步"思考"并回复你的:
-
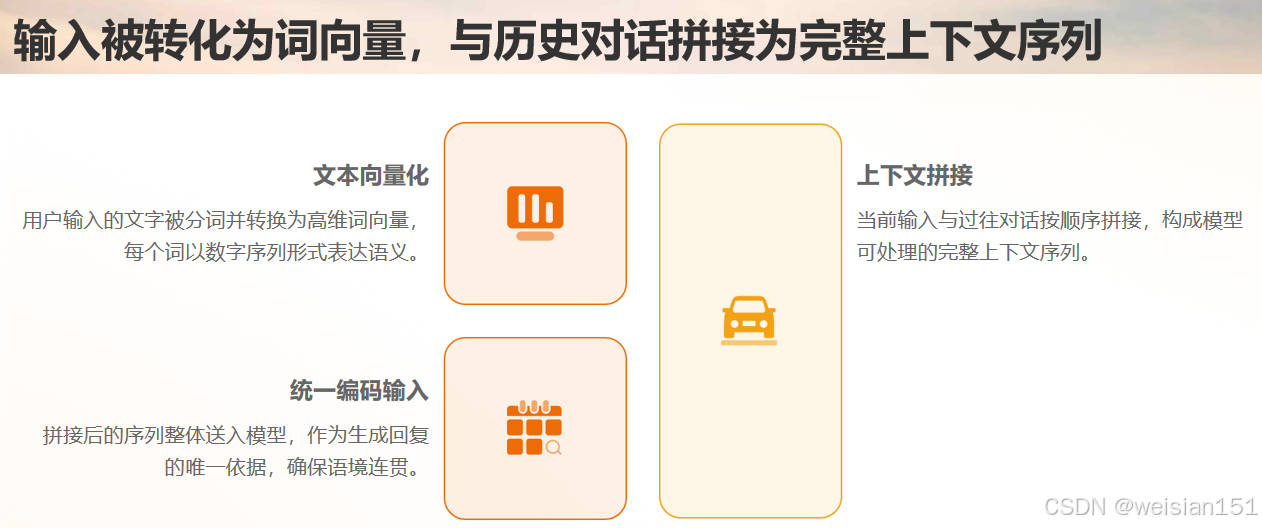
输入处理:你输入的文字(比如"什么是 ChatGPT?"),会被转换成模型能理解的"词向量"------每个词都变成一串数字。
-
上下文编码 :模型会把你这次的输入,和之前的对话历史(如果有的话)拼接在一起,通过 Transformer 解码器的 掩码自注意力层------每个词都能关联到上下文,但不会"偷看"后面的词(因为要生成下一个词)。
-
生成下一个词:解码器会根据上下文信息,预测"最可能的下一个词"------比如先预测出"ChatGPT",再预测出"是",接着预测出"一款"......
-
循环生成 :模型会把新生成的词,加入到上下文里,继续预测下一个词,直到生成"结束符"(比如句号、换行),或者达到最大长度限制。

-
输出解码:模型生成的"词向量序列",会被转换成人类能看懂的文字------这就是你看到的回复。
整个过程,就像你写作文时"逐字逐句思考"------先想第一个词,再想第二个词,直到写完一段话。
五、为什么 ChatGPT 能"记住"上下文?------注意力机制的魔法
你有没有注意到:
用户:"我叫小明。"
ChatGPT:"你好,小明!有什么我可以帮你的吗?"
用户:"帮我写一封给老板的邮件。"
ChatGPT:"好的,小明。以下是一封专业且礼貌的辞职邮件模板......"
它居然记得你叫"小明"!这是怎么做到的?
答案就在 Transformer 的自注意力机制。
上下文窗口(Context Window)
ChatGPT 的输入不是单句话,而是一个 完整的对话历史序列,例如:
[User] 我叫小明。
[Assistant] 你好,小明!
[User] 帮我写一封给老板的邮件。这个序列会被送入 Transformer 解码器。
在生成"助理回复"时,模型会通过自注意力,让当前要生成的每个词,都能"看到"前面所有的词------包括"我叫小明"。
✅ 所以,它不是"记忆",而是 实时重读整个上下文。
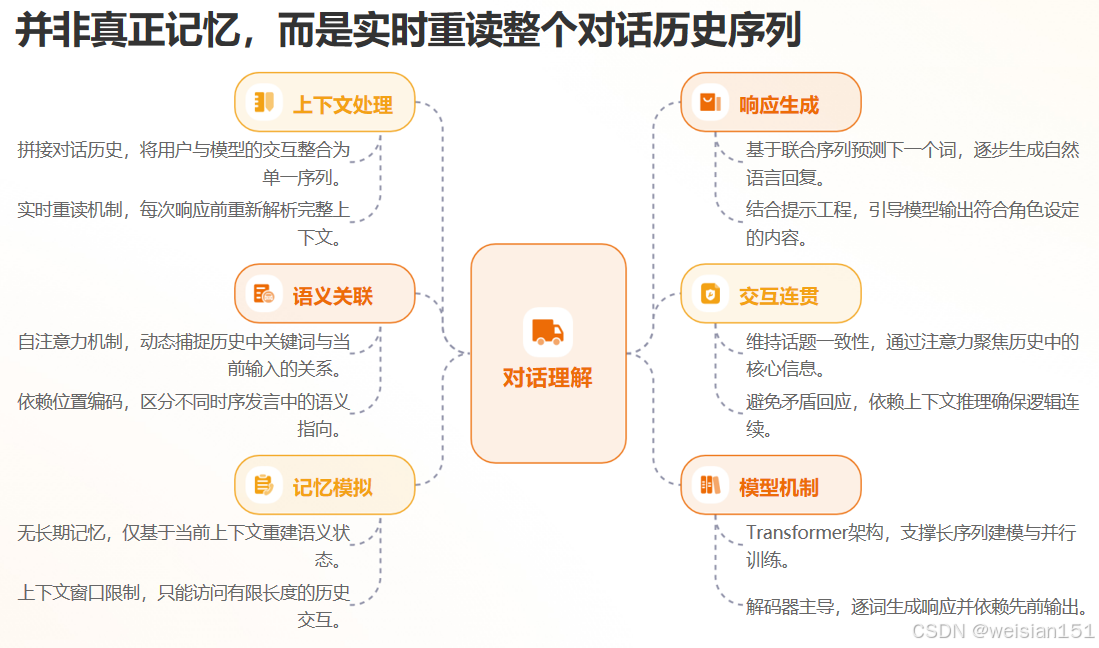
不过,这种能力受限于 上下文长度 (如 GPT-3.5 是 4096 tokens,GPT-4 Turbo 达 128K)。
超过长度的部分会被截断,这也是为什么长对话后期 ChatGPT 会"忘记"开头内容。
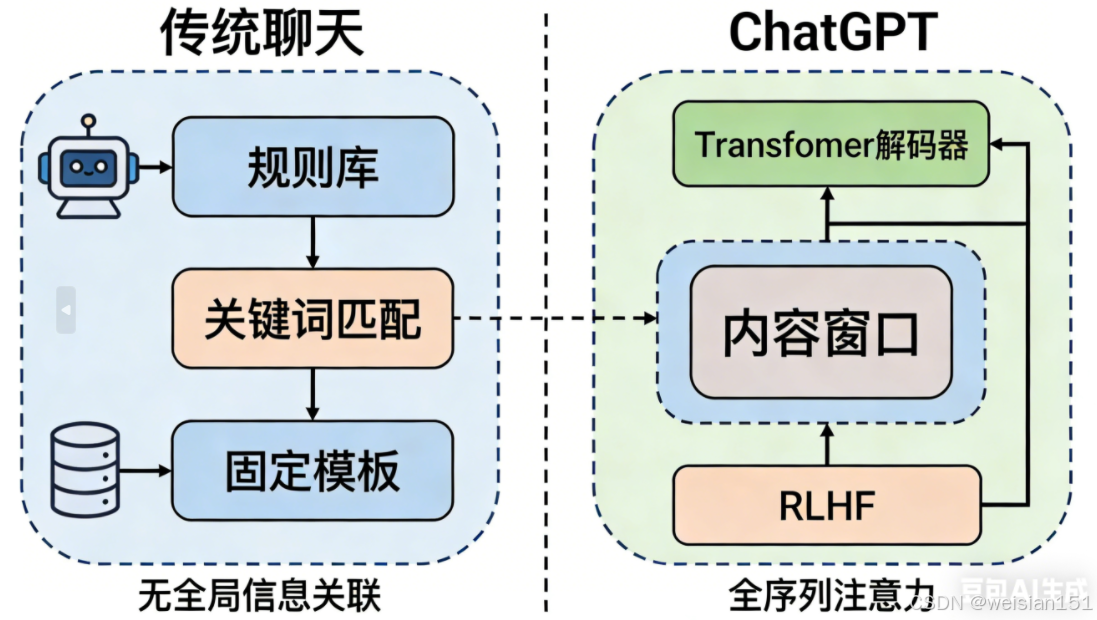
六、ChatGPT vs 传统聊天机器人:到底强在哪?
我们之前用过的一些聊天机器人(比如早期的智能客服),和 ChatGPT 的差距,就像"计算器"和"超级计算机"的差距------核心原因有三点:
| 对比维度 | 传统聊天机器人 | ChatGPT |
|---|---|---|
| 核心架构 | 基于规则或简单机器学习(如 RNN),只能处理固定场景 | 基于 Transformer 解码器,能理解复杂上下文,处理开放域对话 |
| 知识来源 | 依赖人工编写的知识库,知识有限且更新慢 | 基于海量文本预训练,知识覆盖面广,能回答各种领域的问题 |
| 对话能力 | 只能按固定模板回复,无法理解模糊指令 | 能理解自然语言指令,支持多轮对话,甚至能"举一反三" |
举个例子:
- 传统聊天机器人:你问"天气怎么样?",它只能回复"今天晴,25 度"------如果问"明天适合去公园吗?",它可能无法回答。
- ChatGPT:你问"明天适合去公园吗?",它会先问你"你所在的城市是哪里?",然后根据你提供的城市,结合天气信息,给出"适合"或"不适合"的建议,还会补充"可以带野餐垫""注意防晒"等细节。
七、ChatGPT 的能力边界:它真的很"聪明"吗?
尽管 ChatGPT 表现惊人,但它 没有意识、没有理解、没有推理------它只是一个极其复杂的"概率预测机器"。
它能做什么?
- ✅ 语言生成:写故事、诗歌、邮件、报告;
- ✅ 知识问答:基于训练数据回答事实性问题;
- ✅ 代码辅助:写函数、调试、解释算法;
- ✅ 逻辑推理(简单):解数学题、做选择题;
- ✅ 多轮对话:保持上下文连贯。
它不能做什么?
- ❌ 实时获取新信息:训练截止于 2023 年(除非联网插件);
- ❌ 保证事实准确:会"幻觉"(hallucination),一本正经编造不存在的论文、法律条文;
- ❌ 真正理解情感:共情是模式匹配,不是真实感受;
- ❌ 自主思考:所有输出都是对训练数据的重组,没有原创思想。
⚠️ 重要提醒 :
ChatGPT 的"自信"极具迷惑性------它用流畅、权威的语气说出错误答案,反而更容易让人相信。

尽管 ChatGPT 很强大,但它依然存在一些无法避免的局限------这些局限,本质上是 Transformer 架构和训练方式决定的:
1. "一本正经地胡说八道":幻觉问题
这是 ChatGPT 最被诟病的问题。它可能生成看似合理,但完全错误的内容------比如编造不存在的论文、错误的历史事件、虚假的科学数据。
原因:模型的目标是"预测下一个词",而不是"追求事实真相"。它会根据训练数据中的语言模式,生成"最可能的回答",但无法判断这个回答是否符合事实。
2. 上下文窗口有限:"记不住"长对话
ChatGPT 的上下文窗口是有限的(比如 GPT-3.5 是 4096 个词,GPT-4 是 8192 或 32768 个词)。如果对话太长,模型会"忘记"前面的内容。
例子:你和 ChatGPT 聊了 100 轮,然后问"我们之前聊的那个科幻小说叫什么?",模型可能会回答"抱歉,我没找到相关内容"。
3. 无法实时更新知识:"活在过去"
ChatGPT 的训练数据是有"截止日期"的(比如 GPT-3.5 的训练数据截止到 2021 年 9 月)。它无法知道训练数据之后发生的事情------比如你问"2024 年世界杯冠军是谁?",它无法回答。

4. 缺乏真正的"理解":只是"模仿人类说话"
ChatGPT 的"聪明",本质上是 对人类语言模式的模仿------它并不能真正"理解"自己说的话。它不知道什么是"快乐",什么是"悲伤",只是因为训练数据中"快乐"常和"开心""微笑"等词关联,所以能生成相关的回答。
八、ChatGPT 背后的工程奇迹:不只是模型,更是系统
很多人以为 ChatGPT = 一个大模型。
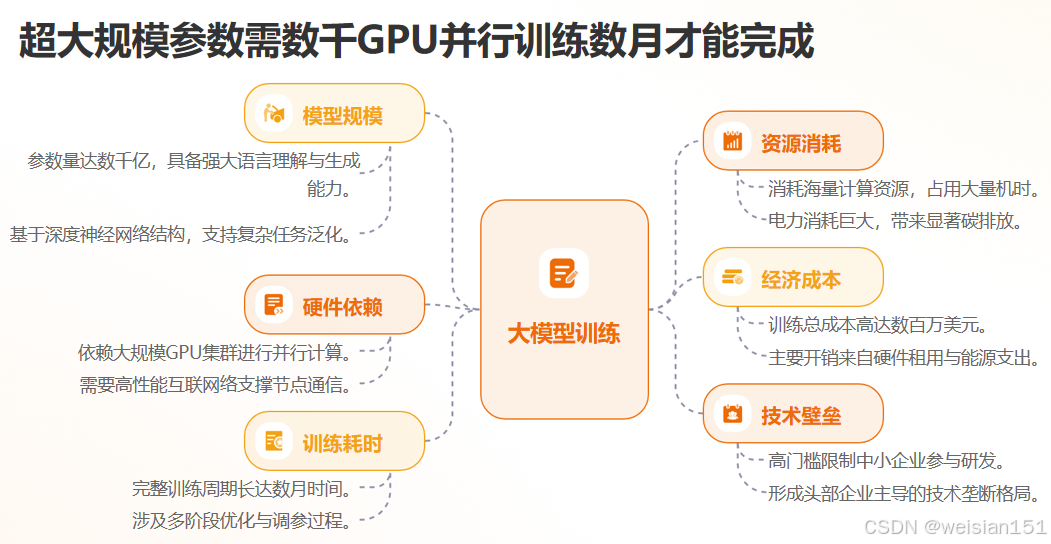
其实,它是一个 复杂的 AI 系统工程,包含:
1. 超大规模模型
- 数千亿参数,需数千张 GPU 并行训练数月;
- 推理时也需高性能集群支持,才能实现秒级响应。
2. 精细的内容过滤
- 输出前经过多层安全过滤(如拒绝暴力、歧视、违法内容);
- 即使 RLHF 学会了"不说坏话",仍需规则兜底。
3. 插件与工具集成(Advanced Data Analysis, Web Browsing)
- 通过插件调用计算器、代码解释器、搜索引擎;
- 弥补"静态知识库"的不足,实现"动态信息获取"。
4. 持续迭代与对齐
- OpenAI 不断收集用户反馈,微调模型行为;
- 目标是让 AI 更"有用、可信、可控"。
九、ChatGPT 如何改变世界?
自发布以来,ChatGPT 已深刻影响多个领域:
🧑💻 开发者
- GitHub Copilot(基于 GPT)成为"第二大脑";
- 快速生成原型、解释报错、写测试用例。
📚 教育
- 学生用它辅导作业、润色论文;
- 教师用它出题、批改、设计教案(也引发"作弊"争议)。
🏢 职场
- 自动写周报、做 PPT、分析数据;
- 客服、文案、翻译等岗位面临重构。
🌐 社会
- 推动"AI 普及化":普通人也能用尖端 AI;
- 引发关于"AI 伦理、就业、版权"的全球讨论。
🔮 未来,ChatGPT 这样的大模型将像电力、互联网一样,成为基础设施。
ChatGPT 的成功,让人们看到了通用人工智能(AGI)的曙光------但它只是一个起点。未来,基于 Transformer 的大模型,还会朝着三个方向进化:
1. 多模态融合:不止会"说话",还会"看、听、画"
现在的 GPT-4V,已经能理解图像------你上传一张图片,它能描述图片内容、回答关于图片的问题。未来的模型,会进一步融合 文本、图像、音频、视频 等多种模态,实现"能听、会说、懂看、会画"的全能助手。
2. 更高效的模型:更小、更快、更便宜
目前的大模型参数量动辄千亿,训练和推理成本极高。未来,研究者会通过 模型压缩、稀疏注意力、知识蒸馏 等技术,让模型变得更小、更快、更便宜------比如在手机上就能运行的"轻量化 ChatGPT"。
3. 更强的推理能力:从"模仿"到"思考"
现在的 ChatGPT,虽然能解一些简单的数学题,但复杂的逻辑推理(比如证明数学定理、编写复杂代码)能力还很弱。未来的模型,会加入 逻辑推理模块,让模型不仅能"模仿人类说话",还能"像人类一样思考"。
十、给普通用户的建议:如何高效、安全地使用 ChatGPT?
最后,给大家分享几个实用技巧,帮你更好地使用 ChatGPT,让它成为你的高效助手:
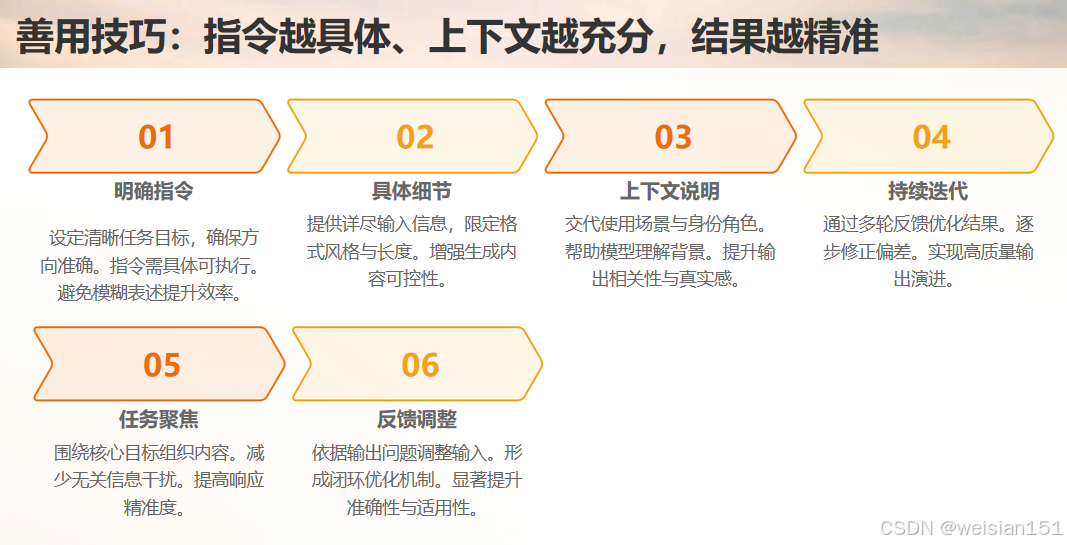
✅ 善用技巧
- 明确指令:越具体,结果越好(如"用 Python 写一个冒泡排序,带注释");
- 提供上下文:让它知道你的身份、目标、限制;
- 多轮修正 :不满意就让它重写、简化、扩展。
⚠️ 保持警惕
- 不轻信事实:重要信息务必交叉验证;
- 不泄露隐私:别输入身份证号、密码、公司机密;
- 不替代思考:用它辅助,而非代替你的判断。
🛠️ 推荐实践
- 用它学新技能(如"教我 React 基础");
- 用它提升效率(如"总结这篇论文");
- 用它激发创意(如"给我 10 个短视频脚本点子")。
十一、总结:ChatGPT 的本质------Transformer 的"终极形态"之一
我们用一句话总结今天的核心内容:
ChatGPT = Transformer 解码器 + 海量预训练 + 人类反馈强化学习。

ChatGPT 的伟大,不在于它多像人类,而在于它 把前沿 AI 技术变成了人人可用的工具 。
它的背后,是 Transformer 架构的胜利,是大数据、大算力、大工程的结晶,更是人类对"通用人工智能"(AGI)的一次勇敢试探。
它不是凭空出现的"黑科技",而是 Transformer 架构诞生后,研究者们一步步优化、迭代的结果------从 Transformer 到 GPT-1,再到 GPT-3.5 和 ChatGPT,每一步都在让模型更"懂人类"。
未来,随着技术的进步,ChatGPT 会变得更聪明、更高效、更全能。但无论如何进化,它的核心骨架,依然是那个 2017 年诞生的 Transformer------这就是技术的魅力:一个简单而强大的思想,能开启一个全新的时代。
但请记住:
ChatGPT 是镜子,照出的是人类知识的总和;
它是笔,写出的是你思想的延伸;
它不是大脑,不能替你思考,也不能替你负责。
真正的智能,永远属于会提问、会判断、会创造的你。
我是 Weisian,持续为你拆解 AI 背后的逻辑。
如果你觉得这篇文章帮你真正理解了 ChatGPT,欢迎点赞、收藏,或转发给正在探索 AI 的朋友。
有任何问题,也欢迎在评论区留言交流!