此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第四课的第三周内容,这一课所有内容的中心只有一个:计算机视觉 。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的"特化",也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第三周的内容将从图像分类 进一步拓展到目标检测(Object Detection) 这一更具挑战性的计算机视觉任务。
与分类任务只需回答"图中有什么"不同,目标检测需要同时解决" 有什么 "以及"在什么位置 "两个问题,因此在模型结构设计、训练方式和评价标准上都更为复杂。
本篇的内容关于目标定位与特征点检测。
1.目标定位
这个标题想必不用解释,在原本的分类算法中,我们构建模型来识别输入的图像""是什么",而现在,我们想进一步进行定位,找到检测内容在图像中的位置。
这并不是另起炉灶,而是在原本的分类基础上的进一步发展,因此在这部分,我们就来看看如何从"是什么"到"在什么位置"。
1.1 图像分类的传播逻辑
图像分类的逻辑对我们来说早就不陌生了,我们再简单梳理一遍,来看这样课程里这样一个例子:
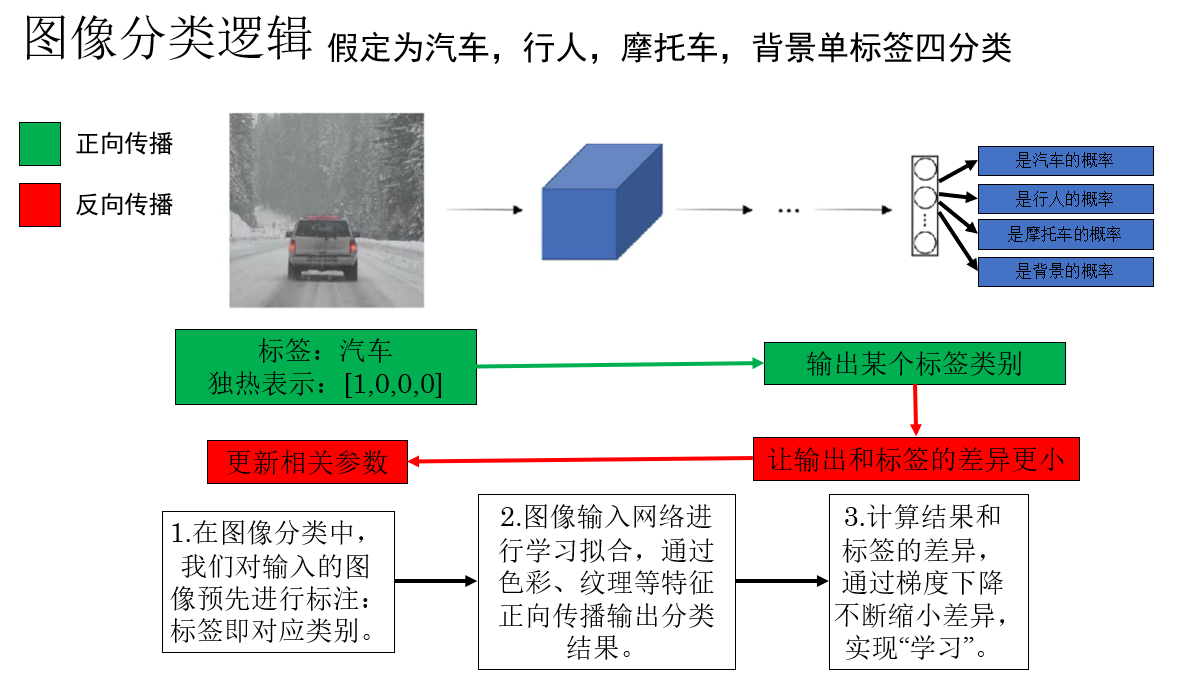
你会发现,在监督学习中,我们对每个样本都规定了它的"标准答案"。
因此,网络才能在"传播------对比------改正"这样的循环中不断学习,最终实现分类。
用通俗的话来说,这其中的一个关键点在于:模型并不知道汽车是什么,但是你通过标签告诉它:这是汽车。
而目标定位也是同样的逻辑:我们不仅要通过标签告诉模型什么是汽车,还要告诉它汽车在哪。
1.2 从分类到定位
通过上一部分的了解,我们知道,要实现从分类到定位的逻辑,首先就要在标签中增加检测目标的位置信息。
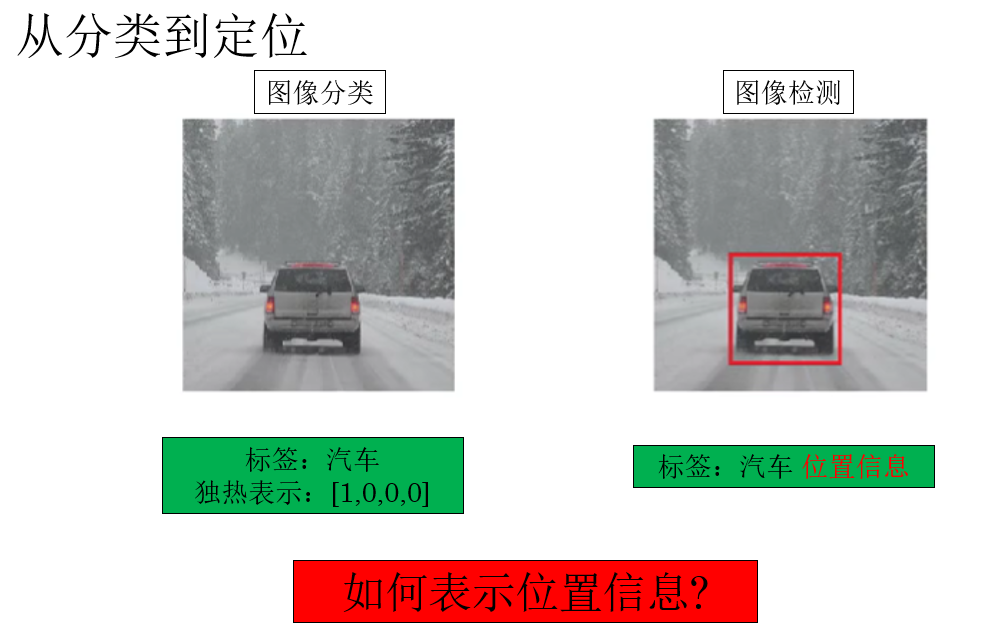
我们知道,在分类问题中,可以用标签 0 和 1 来表示二分类,用独热编码来表示多分类。
但显然,表示目标在图像中的位置是一个更复杂,需要更多参数的问题。
你可能会想,可不可以在标签中增加四个参数对,来表示检测目标的四角?
这的确是一种方法,但实际上,我们使用的是另一种参数量更少且更普适的方法 :
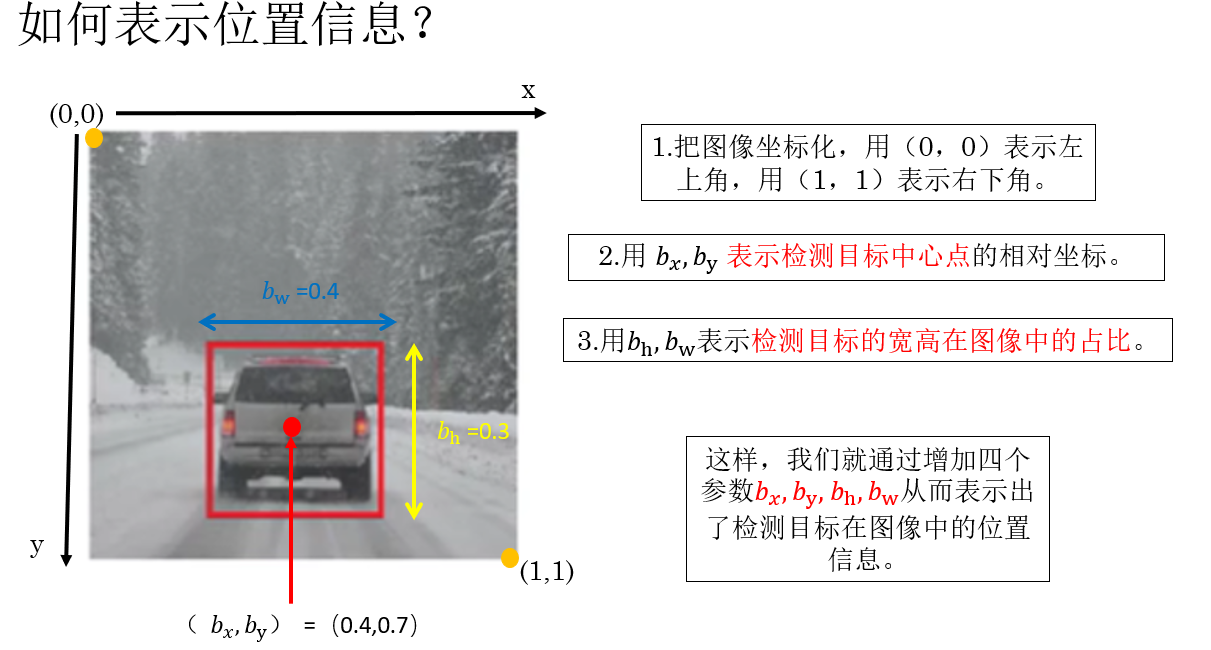
再规范一下:
在目标检测中,通常使用一个边界框(Bounding Box) 来描述目标在图像中的位置与大小。
相比直接记录四个顶点坐标,更常见也更通用的做法是用中心点 + 宽高来表示:
- \(b_x\):表示目标边界框中心点在水平方向上的位置 ,通常是相对于整张图像宽度的归一化坐标,取值范围为 \(0,1\)。
- \(b_y\):表示目标边界框中心点在垂直方向上的位置,同样是相对于图像高度归一化后的坐标。
- \(b_w\):表示目标边界框的宽度,一般以图像宽度为基准进行归一化,用来描述目标在水平方向上所占的比例。
- \(b_h\):表示目标边界框的高度,同样以图像高度为基准归一化,用来描述目标在垂直方向上所占的比例。
通过这四个参数,模型不仅能够判断"是什么 ",还可以同时给出"在什么位置、占多大范围",从而完成最基本的目标定位任务。
1.3 定位问题的完整样本标签
了解了如何表示检测目标在图像中的位置信息后,继续延续上面的例子,来看看如何完整地表示一个样本的标签:
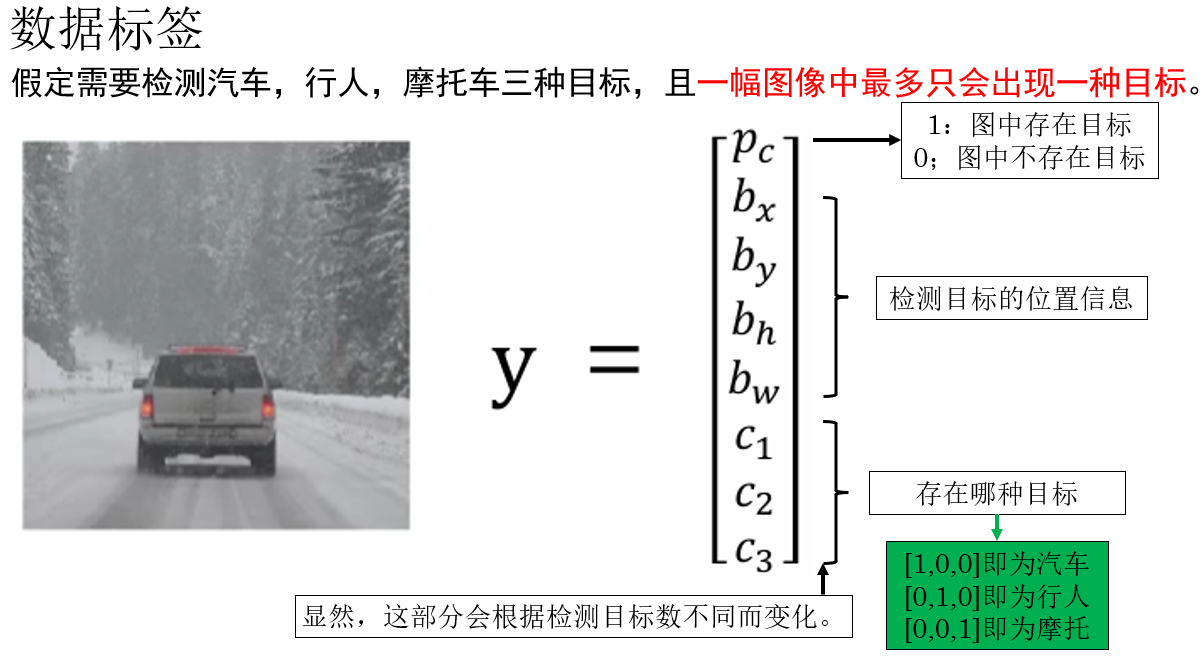
同样再次列举一下:
在单目标检测的设定下,一个样本的标签通常由以下几部分组成:
- \(p_c\):表示当前图像中是否存在需要检测的目标 ,这是一个二值变量,通常取值为 \(0\) 或 \(1\)。
当 \(p_c = 1\) 时,表示图像中确实存在目标,此时后续的位置信息和类别信息才是"有效"的;
当 \(p_c = 0\) 时,表示图像中不存在目标,其余参数通常被忽略或置为 0。 - \(b_x,b_y,b_h,b_w\) :表示检测目标的位置信息。
- \(c_n\):表示目标所属的类别信息 。
在二分类问题中,它可以是一个标量;
在多分类问题中,通常采用独热编码 的形式,用一个向量来表示目标属于哪一类。
因此,在单目标检测任务中,一个完整的标签可以被表示为:
\y=(p_c,b_x,b_y,b_w,b_h,c_1,c_2,...,c_n) \\
它同时包含了是否存在目标、目标的位置与尺度,以及目标的类别信息。
这样,我们就在数据层面上为目标检测问题完成了准备工作。
为了逻辑的完整性,下一步网络如何学习目标检测的问题就放在下一篇来展开。
下面我们简单拓展一下课程里提到的另一项应用:特征点检测。
2.特征点检测(Keypoint Detection)
在我们了解了如何对图像中的目标进行定位后,结合实际,你会发现在很多实际任务中,我们关注的目标并不是汽车、行人这类需要用边界框描述的宏观物体,而是一些更精细、更局部的结构,例如:
- 人的眼角、瞳孔
- 人体的关节位置
- 笔尖的位置
- 面部轮廓上的关键点
这类目标本身几乎不具备"面积"或"尺寸"概念 ,用一个边界框来描述反而显得冗余。
在这种情况下,目标往往可以直接用一个二维坐标点来表示。
因此,与目标检测类似,我们同样可以通过人工标注关键点坐标 ,构建训练样本,让神经网络学习这个关键点是否存在,以及如果存在,它在图像中的具体位置。
从建模角度看,特征点检测本质上是一个对连续坐标进行预测的回归问题 。
这种任务,就叫特征点检测(Keypoint Detection) 。
来看课程里这样一个例子:

我们可以通过检测得到的特征点做进一步应用,比如根据面部特征点分布判断人的表情,根据人的关节特征点位置预测人的动作等等。
3.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 图像分类 | 通过标签告诉模型"输入图像是什么",模型在传播---对比---修正中学习从图像到类别的映射关系 | 像给学生一张照片,并直接告诉他:"这是汽车" |
| 目标定位 | 在分类的基础上,进一步通过标签告诉模型目标在图像中的什么位置 | 不仅说"这是汽车",还用手指指出"汽车在这里" |
| 边界框(Bounding Box) | 用一个矩形区域描述目标的位置与大小,统一表示空间信息 | 在照片上用框把目标圈出来 |
| \(b_x, b_y\) | 描述目标中心点在图像中的相对位置(归一化坐标) | 用"地图坐标"标出目标的中心点 |
| \(b_w, b_h\) | 描述目标在水平方向和垂直方向所占的比例 | 告诉别人这个框"有多宽、多高" |
| 中心点 + 宽高表示法 | 相比四个角坐标,参数更少、形式更统一,便于网络学习 | 不报四个角地址,而是说"在市中心,方圆两公里" |
| \(p_c\)(目标存在性) | 指示图像中是否存在需要检测的目标,决定后续标签是否有效 | 先确认"房间里有没有人",再讨论他站在哪 |
| 类别向量 \(c_1,\dots,c_n\) | 表示目标属于哪一类,可用标量或独热编码 | 给被圈出来的目标贴上"身份标签" |
| 特征点检测 | 不用边界框,而是直接预测关键点的二维坐标 | 不给人画框,只标出"眼睛、关节、笔尖的位置" |