1、&数组名
假设int arr ={1,2,3,4,5}
- arr数组名就表示数组的首元素地址
- &arr0 也表示数组的首元素地址
- 但是&arr 表示取得是整个数组的地址
比如
如果说arr是数组的首元素地址,那arr在x86平台下的大小就是4个字节,为什么sizeof(arr)=40?
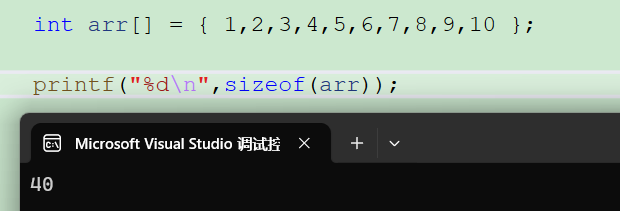
because 这是一种特俗情况:
- sizeof(数组名) 取得是整个数组的地址
- &数组名也是整个数组的地址
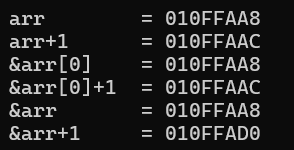
我们对指针进行+1操作,发现arr和arr0,+1都是地址都是+4,那就证明它们都是整型指针,+1跳过一个整型,但是&arr + 1 跳过的是40个字节,A8+28=D0,差0X28换10进制也就是跳了40个字节,那就是证明了&arr 取得是整个数组的地址。
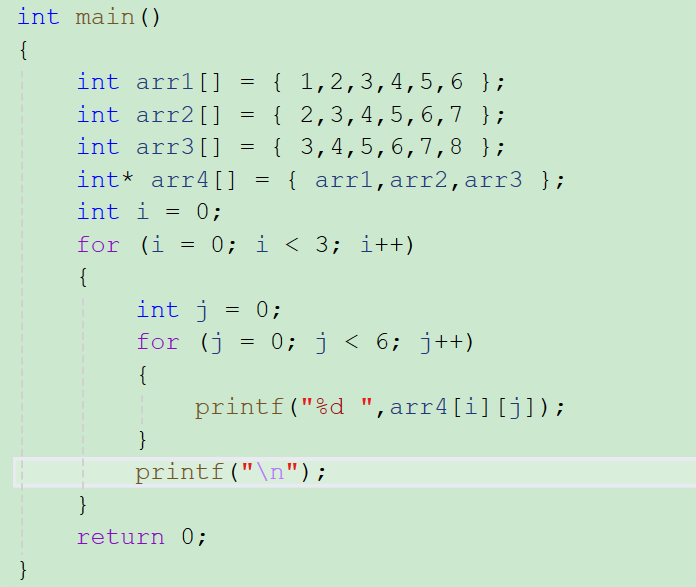
2、指针访问数组
既然我们知道arr就是数组的首元素地址,数组的地址又是一块连续的内存空间,所以用int * p
p + i == 数组下标为i的元素的那块空间
又因为p = arr,所以
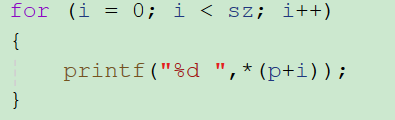
那也可以写成这种形式,它们是完全相等的;
我们正常写代码的话,这里应该写的是arri,但是在编译器里它的形式就是这样的*(arr+i)。

arri -- *(arr+i) -- *(p+i) 它们是一回事情。
还有一种写法,比较特别。
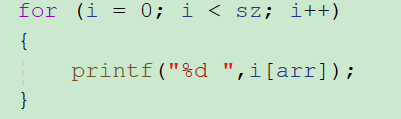
*(arr+i)是支持交换律的,
*(i+arr) == *(arr+i)
*(arr+i) == arri
*(i+arr) == iarr
结果都是一样的,这是写法不一样。
3、一维数组传参
我们把数组传参,传的是什么?
我们传的其实是地址,不难看出来,在主函数里面我们求的元素个数是10,但是在test函数里面求得是1。
在test函数里面,我们已经知道sz2得结果是1,我们反推,sizeof(arr0)肯定是4,那什么/4等于1,那肯定也是4,如果我们数组传参传得是数组,那应该就是数组的大小40/4=10,所以数组传参传的是地址。

既然传的是地址,就不用创建一块数组,也就不用写数组元素的个数了,比如int arr10,那最好用指针的形式来接收,那就用int * p 来接收。
那为什么我们还要写成这种形式 int arr 呢?
为了可读性,给我传数组,那我就要数组的形式来接收,这是为了方便理解。
4、冒泡排序
冒泡排序的思想就是两两相邻的元素互相比较
假设我们排的是升序
第一个我们要解决是躺数的问题,排序一个元素需要一趟,假设这里10个元素,就需要10-1躺,因为排到最后第二个元素的时候就不用排了,最后一个就已经排好了,假设有n个元素,那就需要n-1躺。

第二个问题就是内部细节的问题,就是两个元素相比较,我们比的是升序,降序就反过来,假设arrj>arrj+1,前面的元素大于后面的元素就交换;那交换的过程中,第一趟交换9对,第二天交换8对。。。。以此类推,每一个都在变化,这是我们可以sz-1-i

5、二级指针
- 二级指针就是存放 一级指针变量的地址 的指针;
- 存放地址的指针变量也是变量,内存也会给它内存空间;
- 假设是ppn; 存放的就是pn的地址;
- ppn的类型,*ppn表示是指针变量,int*表示它指向的对象是int*的指针;

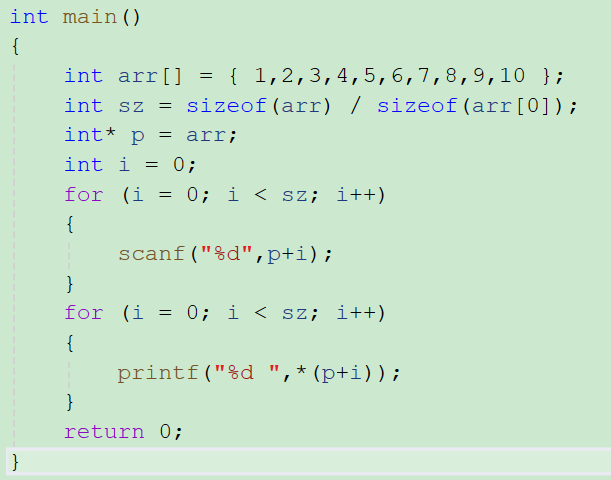
6、指针数组
- 指针数组就是存放指针的数组
- 每个元素就是指针
- 数组每个元素的类型是int*
- 通过元素下标访问地址,再解引用

7、指针二维数组
- 指针二维数组就是把多个一维数组的地址存起来
- 通过下标访问,得到每一行的数组名
- 再通过列下标访问每一列的元素